1. Introduction
The description of social network behavior and information resources is one of the most important areas of mathematical sociology. From a practical point of view, the development of models describing user opinion dynamics and preferences contributes to the development of systems for automated monitoring of the public mood and its changes. Compared to traditional methods of studying public opinion, the advantage of such systems is that of automated information processing. Social surveys require the development of questionnaires and sampling, which is complicated by the necessity to cover all strata of society. In addition, respondents tend to provide socially desirable responses.
Another advantage of automated information processing for social networks and comments to newsfeed is that it identifies straightforward comments related to a socially significant topic and to highly-publicized news. Therefore, the development of automated information processing tools provides feedback between society and government bodies, starting from the municipal level and ending at the level of state authorities.
The development of automated tools assumes that their work should be based on algorithms based on approved mathematical models. In addition, it is of the utmost importance not only to monitor and analyze the processes involved in research but also to predict their evolution, which is necessary to ensure sustainable social development.
The dynamics of the changes in opinions and moods of Internet users can be largely attributed to stochastic processes, but with the possibility of targeted impact. On the one hand, the human factor (many people with different opinions, preferences, and behavior patterns) creates random changes (due to the wide variety of behavioral models of users). On the other hand, elements of opinion consistency are introduced into the dynamics of changes. A detailed description of the use of stochastic methods for modeling the dynamics of social processes can be found in [
1].
In this regard, we consider models based on the Fokker-Planck equation to be the most promising to develop models of the changes in public mood dynamics, which takes into account both ordered and random changes.
The Fokker-Planck equation is widely used for analyzing and modeling the behavior of time series when describing processes in complex systems [
2,
3,
4,
5], for example, when analyzing the dynamics of the non-stationary time series of stock and commodity indices. To predict changes, based on the Fokker-Planck equation and sample data, the distribution functions of the series levels are constructed in the form of a sum of polynomials in which the coefficients of drift and diffusion may depend on a specific parameter, which is the level of the series according to various laws and is empirical.
It should be noted that, apart from the Fokker-Planck equation, other approaches are used for modeling based on differential equations, for example, the Liouville equations [
5,
6], the diffusion equations [
4,
7] and many others. A detailed review of modeling social processes is presented in [
8].
The Fokker-Planck equation is a second-order partial differential equation that not only contains a term responsible for stochastic changes (“diffusion”), but also an element responsible for opinion consistency (“draft”). From the Fokker-Planck equation, it is possible to obtain a probability density function of transitions per unit of time between states of a system. A system can be defined as a blog or newsfeed that users comment on, and its state will be the number of comments that are observed at a given time.
In addition to describing dynamic processes, stationary solutions can be obtained from the Fokker-Planck equation, which can describe the state of a system in a stationary state, when, for example, its evolution has already ended, and changes do not occur. One example of such stationarity may be the final static distribution of newsfeed or blogs by the number of comments on them.
The study of processes occurring in complex systems with the participation of the human factor shows that very often a power law of distribution is performed for the observed characteristics of the parameters of these processes. If we imagine the interconnection of the elements forming a complex system as a diagram, it turns out that the networks that arise in this case—social, communication, Internet link networks, citations, and others—are well described by scale–free models (scale-invariant), in which the degrees of vertices (nodes) are distributed according to the power law
(where
is the characteristic degree) [
9,
10,
11,
12,
13,
14]. Scale-free networks are self-similar, i.e., in any part of the network, the distribution of degrees will be the same.
The power model is widely used in the analysis of processes in complex social systems, but at the same time the issue of the theoretical justification of the possibility for its application requires further study. In our opinion, this justification is very crucial. The identification of the nature of the processes from which the power law arises is necessary for a deeper study of behavior and analysis of complex social systems.
In addition, we are not aware of attempts to apply a theoretical description of processes in social networks and network mass media based on the Fokker-Planck equation from the standpoint of formulating and solving boundary value problems based on it.
The purpose of our work is to investigate the possibility of obtaining from the Fokker-Planck equation, often observed in practice in complex social systems, the power law of the distribution of parameters of the processes occurring, and to show that under certain assumptions this equation can be used to describe both static and dynamic characteristics.
3. A Brief Overview of Existing Studies of the Structure of Complex Social Systems and the Processes Observed
One of the directions in the study of complex networks is the study of their structure, based on the possibility of representing processes at the graph level, using a set of attachments at the level of individual nodes for data aggregation (of the properties of the whole from the properties of the quotient). Aggregation is crucial, since it should, in principle, provide an isomorphism-invariant representation of the graph, i.e., the representation of the graph should be a function of the nodes of the graph, considered as some set.
In [
15], the DeepSets aggregation operator based on self-organizing maps (SOM) is considered. Using SOM allows calculation of representations of nodes that include information about their resemblance. Experimental results on real data sets show that the proposed approach provides improved predictive performance compared to the generally accepted summing aggregation and many modern graph neural network architectures in the literature.
Since, with the growth of the network, the search for similarities between nodes in the network is a time-consuming process, to optimize the process of solving problems of predicting connections and detecting communities’ researchers in [
16] use swarm algorithms. Swarm-based optimization methods used in social network analysis are compared in this article with community analysis and link analysis based on traditionally used approaches.
In [
17], the authors consider the mathematical model of mixed membership in user groups, which are formed stochastically. This preliminary solution the authors base on the method of detecting pairwise measurements, which subsequently show the presence or absence of connections between a pair of nodes. When analyzing the approach for probabilistic changes between pairs of objects, it is usually necessary to introduce assumptions, for example, independence, or assumptions of the inconsistency of this connection (mixed membership in stochastically forming groups). The proposed model allows, under certain assumptions, the tracking of dynamic changes in the number of nodes in the forming of groups and their clustering by groups.
In the presented model, from the development of choice and influence on social networks [
18], the authors consider a model for which the number of nodes and the network topology (structure of connections) are dynamic. A significant disadvantage of this model is that it explicitly considers the connections between all pairs of nodes. This action leads to quadratic difficulty in calculating the change in the number of participants in various social groups and a significant increase in the calculation time. It is worth noting that real social networks and systems are sparse. This means that most participants do not have paired connections, and the number of their connections is itself random. Introducing the concept of sparsity into the model [
18], as well as taking into account the random nature of the number of connections for each node (user) of the network, can significantly increase the speed and efficiency of using this model.
The authors in [
19] use a structure analysis technique that dynamically develops, and therefore has a multimodality of, the graph of the social network. Using this approach to real graph structures in practice shows that there is temporary online regularity in people’s social interactions. Moreover, correlations are found between the occurrence of friendship between participants and the settings of the interactive social network. Separately, it is worth noting that physical contacts between people can be considered as an interactive dynamically changing network.
In article [
20], the authors described methods of structuring and influencing the dissemination of information on mobile social networks. In these networks, a group of users is typically treated as some kind of entity in which individuals can exchange messages. The authors also note that there is a variety of models for analyzing the dissemination of information on mobile social networks, but none of the existing methods considers the concept of information dissemination in the group. Therefore, the authors of the paper used the SIR model, which is used to spread viruses in computer networks, and applied this to the dynamics of the information dissemination process in groups. Simulations using the Monte Carlo method showed that group propagation increases the overall speed of information propagation on the network. In addition, the authors note that the presence of groups with a significant number of participants is most effective in disseminating information than the presence of a huge number of groups but with a small number of participants. This analysis of the impact of the structure on the dissemination of information within it proves that their distribution in the networks of Erdesh-Rennie and Barabashi-Albert does not show any differences. Ref.[
20] analyses the stochastic model of opinion dynamics in social networks. This model is based on a multi-agent approach, for which the opinion of each network member is randomly influenced by the actions of others (its neighboring nodes). Examples were given that, since the number of users (nodes) in the network is not infinite, the model as a result asymptotically creates consensus. The consensus value usually corresponds to one of the absorbing states of the Markov system. However, when the number of nodes is large, some metastable transition states are observed in places. The duration of these transient states may be as long as desired in time, and the state data may be characterized using the mean field approximation for the Markov system. Ultimately, the authors propose a model by which opinion control in the social network is possible.
We can consider several statistical studies [
21,
22,
23] that have widely used the method of studying profiles in social networks. The purpose of these studies is to identify the social mobility of people based on their publications accompanied by geodata. The authors found a large number of such publications, and based on these an approximate map of the user’s movements was compiled, the main centers of activity were identified, and the person’s place of residence was established. According to the data on the place of residence, the people’s names were found. Further, using a database of names distributed by gender, it was possible to determine the gender of more than half of all the accounts studied; according to the surname data, the researchers tried to establish information about the race and age of users, successfully in 38% and 14% of cases, respectively. These studies have shown that it is possible to establish some demographic characteristics, knowing only about the movements of a person or knowing his first and last name.
Using the comparison of time slices, it is possible to determine dynamically changing temporary communities of users of social network structures. The study of these dynamic communities makes it possible to significantly simplify the analysis of the dynamics of a complex system of social interactions as it evolves over time.
Consider [
24], which presents the fundamental structures of dynamic social networks based on a high-resolution dataset describing a tightly connected population of 1000 first-year students at a large European university. The authors of this article consider the physically short interactions that they measured using Bluetooth, supplemented with information received from telecommunications networks (information about calls and messages), social networks and the demographic and geolocation data of users.
Human social communities by their nature overlap due to individuals participating in several different groups (in the theory of complex networks, such nodes are called jumpers). During the week, meetings of the subjects of the created compact structure take place, either a meeting of friends outside the university, or of all students (such structures are called cores). In a network of short physical interactions, all participants are present at the same time and are in physical contact.
The location of the core members can also be forecast. The objects that helps to do this are the kernels themselves. By observing the usual routes of the people who make up the core and their behavioral habits, it is possible to predict the geographical location of a person in the next time interval with high accuracy (on average in 93% of cases), such high accuracy proving that human mobility patterns are regular. It is also worth noting that the members of the core have fewer location states than individuals, which leads to lower values of information entropy on average.
The condition that geospatial studies are conducted for a part of the social group, yet the study is limited to certain time frames, shows any complex interaction between time, place and social context. It also supports the hypothesis that often. when people are most unpredictable in the geospatial domain, they exhibit some predictable social behavior. Linking the results of this article with the literature on dynamic community detection, it can be noted that there are many methods in the literature that would allow the detection gatherings in everyday life, but here the authors used a simple comparison of graph components to emphasize the fact that emerging social structures are natural, and these complex methods are not needed to determine their occurrence.
In fact, Ref.[
24] provides a quantitative assessment of long-term patterns encoded in the micro dynamics for a huge system of interacting nodes, which are characterized by predictability and a high degree of order.
Let us consider another paper on dynamic models [
25]. Recent developments in the field of social networks have shifted the focus from static representations to dynamic ones, requiring new methods of analysis and modeling. Observations in real social systems have revealed two main facts that play a very important role in the evolution of networks and affect the current processes of distribution: the strategies that individuals adopt when choosing between new or old social systems, connections, and the turbulent nature of social activity that sets the pace of these choices. The results are verified using numerical simulation and compared with two observable data sets.
In [
26], methods of assessing public opinion and highlighting the mood of users are carried out using a method based on the use of vocabulary and semantics and inherited from the classical approach to the analysis of public sentiment. Neural networks are used for this method. The task of the neural network is to determine important keywords, which are then checked by experts in this subject area. Formally, the program first analyzes articles and determines how often different words are found in them. Next, the program identifies the most commonly used words and expressions, and makes them significant. Then, on their basis, the program builds a lexicon that characterizes the public mood based on the transmitted news articles.
In [
27], the authors described the workings of the algorithm for analyzing certain topics from the social network. In addition to collecting information, there are methods for processing and sorting information. In addition, the time elapsed between publications is measured so that it is subsequently possible to restore the order of publications and obtain a time scale based on these data. Following from the above, the result is a graph that can be used to track the growth and decline in popularity of certain topics discussed on social networks. You can also trace what moods are accompanied by what events in society. In addition, it is possible to determine the period of active discussion for certain topics.
Article [
28] describes the method of studying political sentiments in society, based on the analysis of the social network. This method is carried out by searching for special words in the text that are previously entered in the program database. The main task of this system is to track by how much different political parties are preferable to citizens, and which are less significant. In addition, which topics are most resonant and most discussed in society are monitored. Additionally, with the help of the program, it is possible to find out how many people in percentage terms support a certain political party.
The subject of [
29] is that of microblogs. The authors of this study used the method of keyword analysis. With the help of such analysis and machine learning, they managed to divide the initial sample into six age groups and identify the topics that participants in each age group most often discuss and on which they most often express their thoughts. Teenagers under 18 most often discuss sports; young people aged 18–25 most often talk about entertainment; people aged 25 to 30 mainly discuss family and business, older people (31–36 years old) are most interested in technology, users aged 26–40 begin to worry about their health and speak about this more often, and those over 40 like to discuss politics. Thus, the most frequent topic for discussion was determined for each age group; this does not mean that each member of this group necessarily discusses this topic, but it is more likely that the person discussing this topic belongs to this age group.
The authors of [
30,
31,
32,
33,
34] proposed a method that evaluates the mass media according to several criteria (topic, evaluation criteria/properties, classes), which combine thematic modeling of context and multi-criteria decision-making. This evaluation system is based on corporate analysis as follows: the conditional distribution of media probabilities by topic, detail and class is calculated after the formation of the thematic model of corporations. Several approaches, including manual labeling, a multi-corporate approach and an automatic approach, are used to obtain coefficients that show the interaction regarding how each topic relates to each evaluation criterion and to each class described in the document. The multi-corporate approach proposed in the study involves assessing the thematic asymmetry of text enclosures to obtain coefficients describing the relationship of each topic to a certain criterion. These factors, in combination with the thematic model, can be used to evaluate each document in the enclosures according to each of the criteria and classes considered. This method was applied to a body of texts consisting of 804,829 news publications from 40 Kazakh sources, published from 1 January 2018 to 31 December 2019 (over a period of 2 years) to classify negative information on socially significant topics. The study produced a BigARTM model (200 topics) and applied this model, including completion of the analytical hierarchical process table (AHP) and all necessary high-level labeling procedures. The experiments carried out confirm the general possibility of evaluating media using the thematic model of text enclosures, since the classification problem achieved an area estimate under the receiver performance curve (ROC AUC) of 0.81, which is comparable to the results obtained for the same task using the BERT model.
The developed system, in which the proposed model was integrated, allows the solution of classic problems, such as simple reports or sentiment analysis. Moreover, it has a number of unique possibilities for use. It provides options such as automatically analyzing a specific topic, event, or object without having to create a keyword-based query. The analysis is based on an arbitrary list of criteria and not limited to sentiment alone. This list includes social significance, popularity, manipulation, propaganda content, attitude to a certain country, attitude to a certain area, analysis of the dynamic behavior of topics, predictive analysis at the thematic level, etc.
In [
35,
36,
37], the KroMFac technique is proposed, which performs community detection using regularized non-negative matrix factorization (NMF) based on the Kronecker graph model. KroMFac combines network analysis and community discovery methods in a single unified structure. This technique connects four areas of research, namely the detection of communities on graphs, of overlapping communities, of communities in incomplete networks with missing edges, and of complete networks.
It is possible to consider several works, close to the subject of our research, on the description of processes in complex social network structures.
Article [
38] considers a model describing the spatial and temporal distribution of information in social networks based on a partial differential equation. In this paper, a non-autonomous diffusion logistic model with Dirichlet boundary conditions was created and investigated, which showed that the diffusion of data is strongly influenced by the diffusion coefficient and internal growth rate (the spread of information or rumors can be considered as a kind of virus that does not have a physical form).
Article [
39] proposes a mathematical model of information dissemination and a mechanism of evolution of the state of the information node using the theory of thermodynamic molecular thermo-diffusion motion in combination with the model of epidemic infection. Four different network topologies are used for the time-varying online social network (OSN) information dissemination process (regular network, small worlds network, random network, and non-scale network).
When distributing OSN information, the concept of information entropy is used. The process of information dissemination determines the transition of the system from one stable state to another. The transfer function is set by such information parameters as information energy, information temperature and energy entropy. The considered model is based on the relationship between the state of microscopic network nodes and the rules of macroevolutionary evolution. The authors of the article conduct simulation experiments and empirical comparative experiments in networks with different topological structures. The proposed model is trained and evaluated using experimental data collected from the Chinese network Baidu.
The authors of article [
40] propose a model for describing the distribution of messages in social networks. This proposal is based on systems described by means of differential equations that show the propagation of various information in a network graph chain. The authors are convinced that this model allows the taking into account of specific mechanisms for transmitting messages. In this model, the vertices of the graph are people who, when a message is received, form their attitude to it. After this, people decide on further transmission of this message over the network, provided that the corresponding interaction potential of the two persons exceeds a certain threshold level.
The authors developed a mathematical method for calculating the timing of the distribution of messages in the corresponding graph chain, which is reduced to solving a number of Cauchy problems for systems of ordinary nonlinear differential equations. Formally, these systems can be simplified, and some equations can be replaced by the Boussinesque or Corteweg de Frieze equations. The presence of soliton solutions for these equations gives us reason to consider social and communicative solitons as an effective tool for modeling the processes of disseminating messages on social networks and studying various influences on their distribution. If certain assumptions are allowed, this model, considered in [
33] has some analogies with the spread of viral epidemics.
In conclusion, it should be noted that almost no one has studied models based on the Fokker-Planck equation to describe processes in complex network social systems.
5. Derivation of the Power Law of the Distribution of Comments from the Stationary Fokker-Planck Equation
The Fokker-Planck equation is widely used for the analysis and modeling of non-stationary processes observed in various complex systems and allows the achievement of good agreement with the predicted behavior and observed data. Therefore, as a testable hypothesis, we assume that the Fokker-Planck equation can be used to analyze and model the appearance of comments on newsfeed and blogs.
In general, the Fokker-Planck equation has the form:
where
is the time-dependent probability density of the distribution over states
(in our case, state
is the number of comments observed at time
is a state–dependent coefficient
that determines a random change in state
is a state-dependent coefficient
that determines a purposeful change in state
.
In relation to our model, can be interpreted as user actions caused by a spontaneous impulse that arose when reading the news or comments on it from other users, when the event described in the newsfeed or blog is not essential, but the user is willing to spend time commenting or responding to another commentator (the user has a spontaneous desire to respond to this news). can be interpreted as purposeful actions caused by the desire to respond to a newsfeed or blog that is essential to the user, as well as to comment on another user’s comment if this touches on a topic that is important from the point of view of this user (the user is constantly interested in this topic).
When analyzing the observed data, at first step we will not consider the dynamics of the appearance of comments over time, but take a static picture formed over a certain period of time (when the changes stop), so we can proceed to the stationary Fokker-Planck equation, which has the form:
Calculate the derivatives in Equation (2):
After substituting the derivatives into Equation (2), we obtain:
Further, to build the model, it is necessary to make assumptions about the dependence of
and
on the state of
and consider two conditions. Firstly, we consider the magnitude of the terms included in Equation (3), and secondly, we can assume that with the growth of state
(the increase in the number of possible comments (the significance of a newsfeed or blog), the values
and
should also increase). Logic suggests that all terms of Equation (3) should have the same magnitude, which has
. Both the first and the second condition will be met if the dependencies
and
on the state
have the form:
and
. In this form, the growth of
and
will be ensured with an increase in the state of x, and on the other hand the condition of preserving the magnitude is fulfilled. Substituting
and
into Equation (3) gives:
Denote
, then:
Equation (5) refers to equations of the Euler equation type and its solution can be found in the form:
, where
are constant coefficients at the corresponding roots of the characteristic equation, which has the form:
This equation has two roots:
and
Thus, for
we obtain:
We find the constant coefficients
and
using the normalization condition of the function
Integral (7) is calculated from 1 to ∞, because there may be users who have made a very large number of comments to the news, but there cannot be commentators who have written less than one comment. Given that for , then and, respectively, . Finally, we get: .
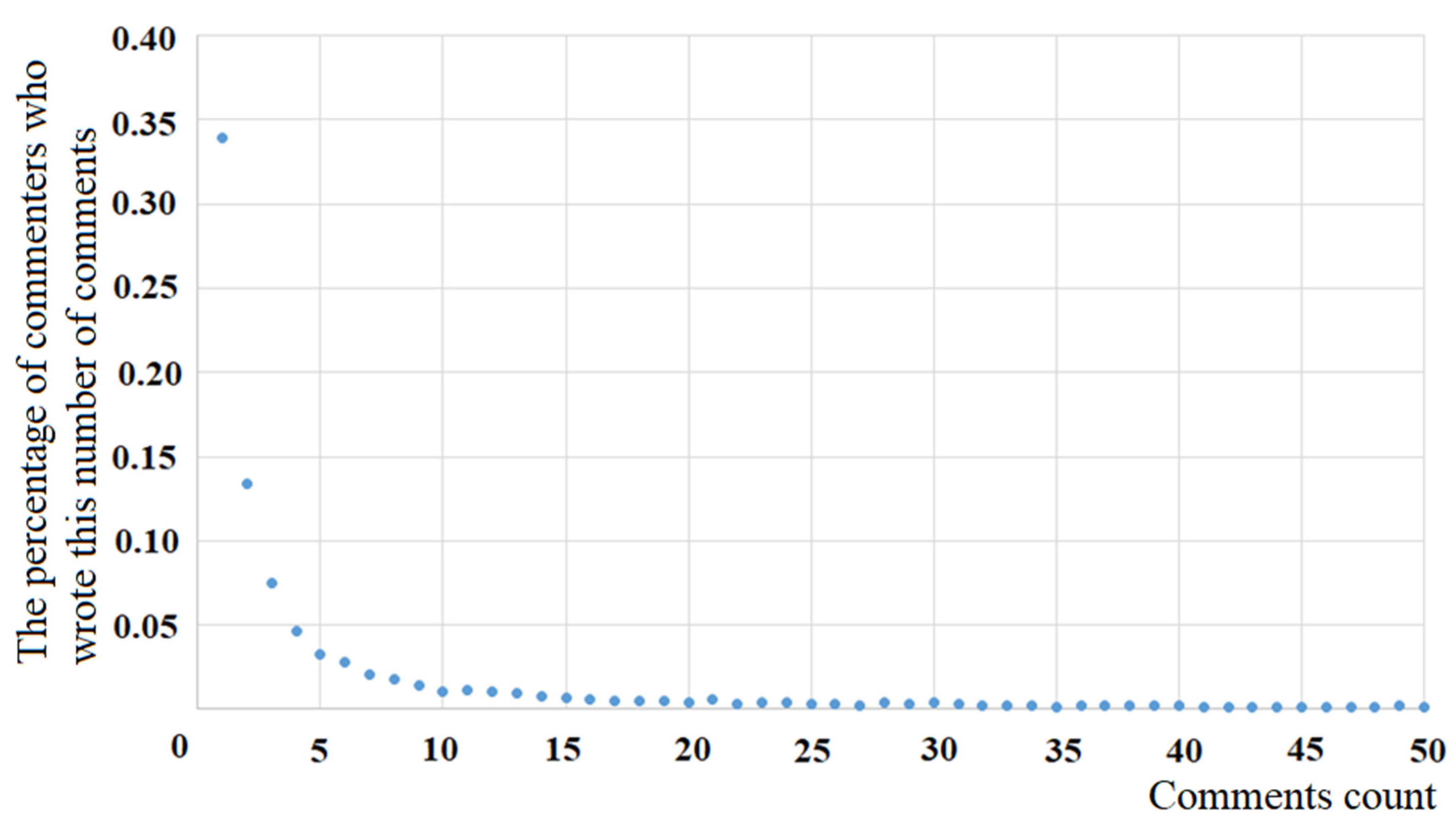
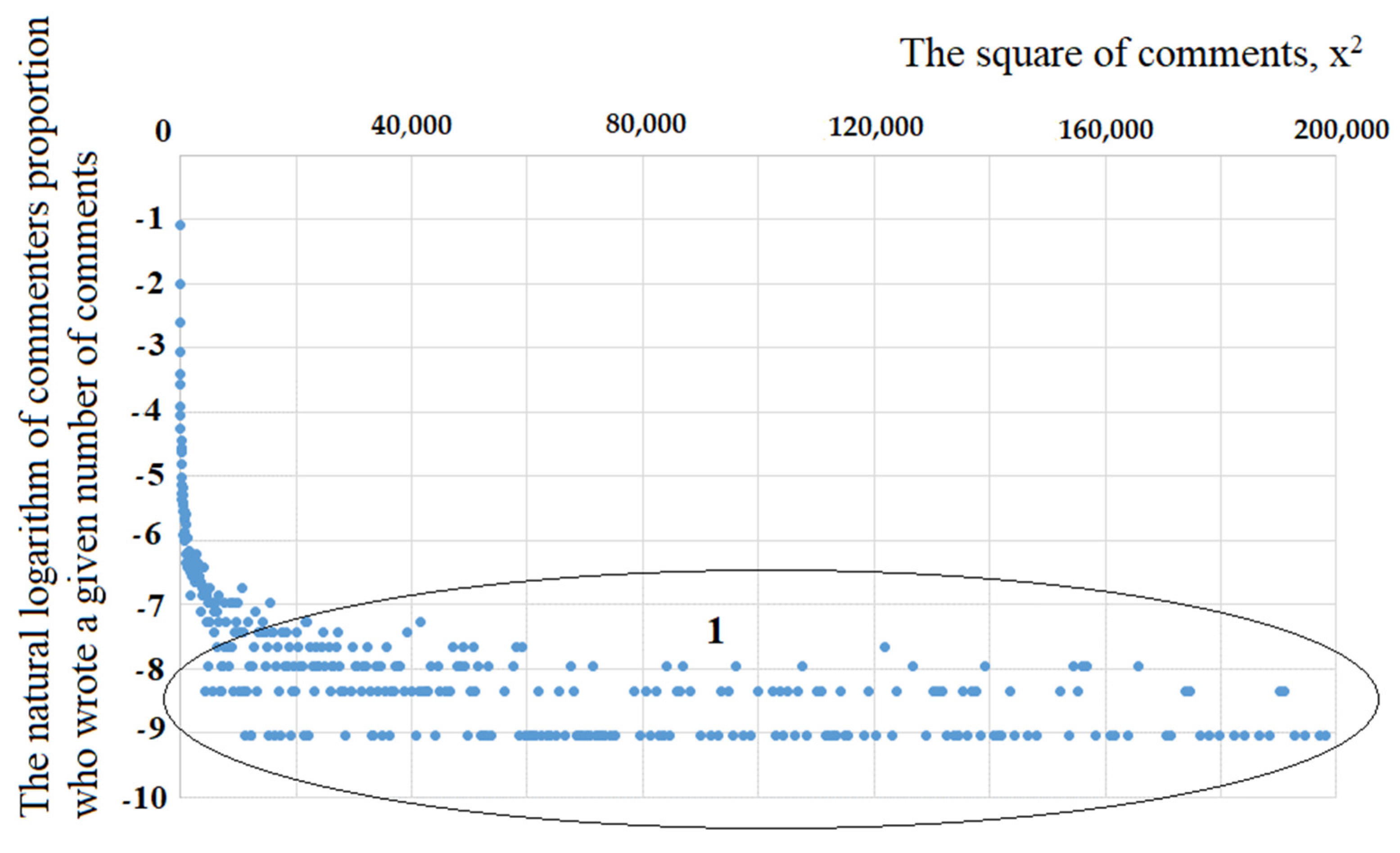
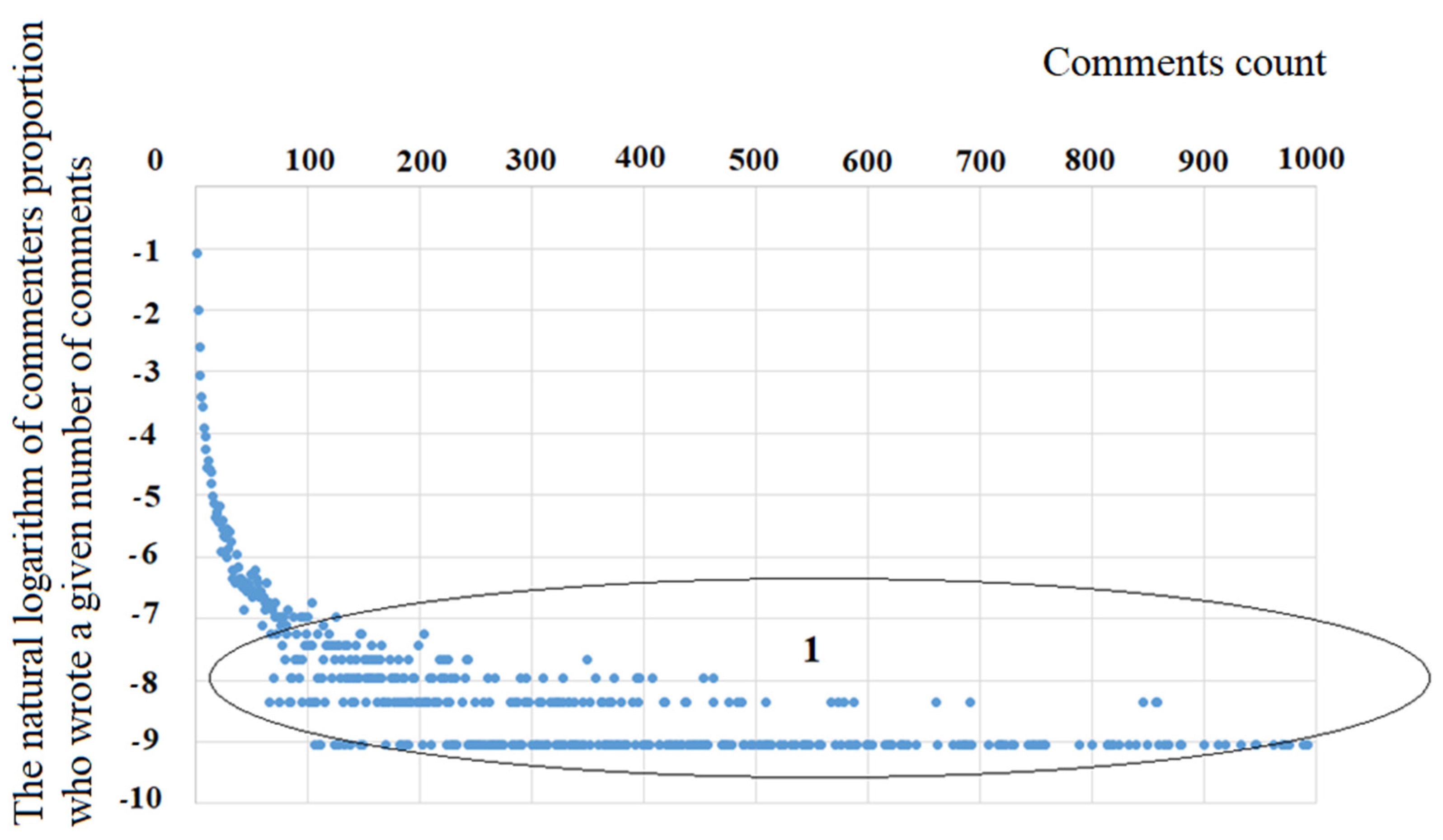
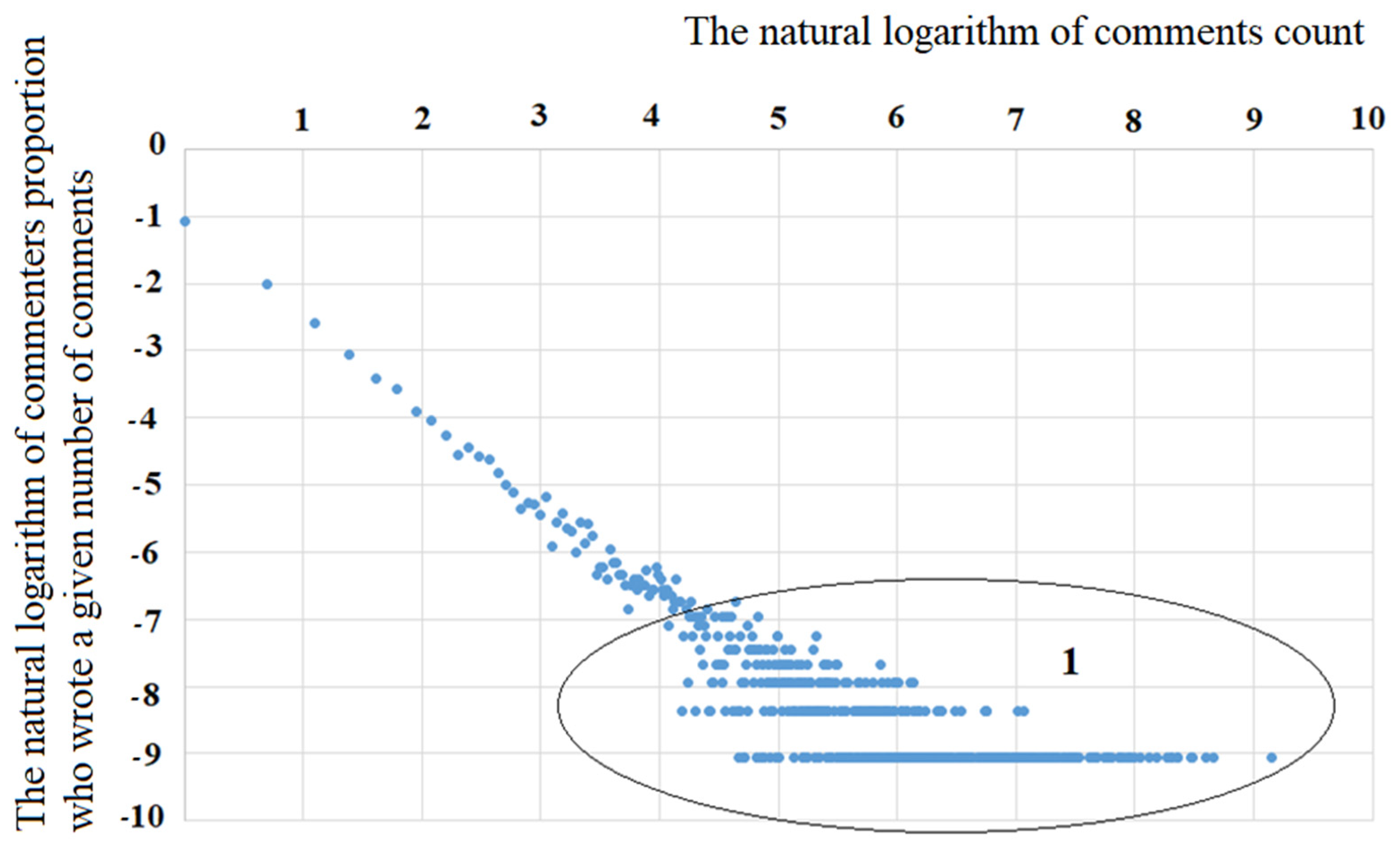
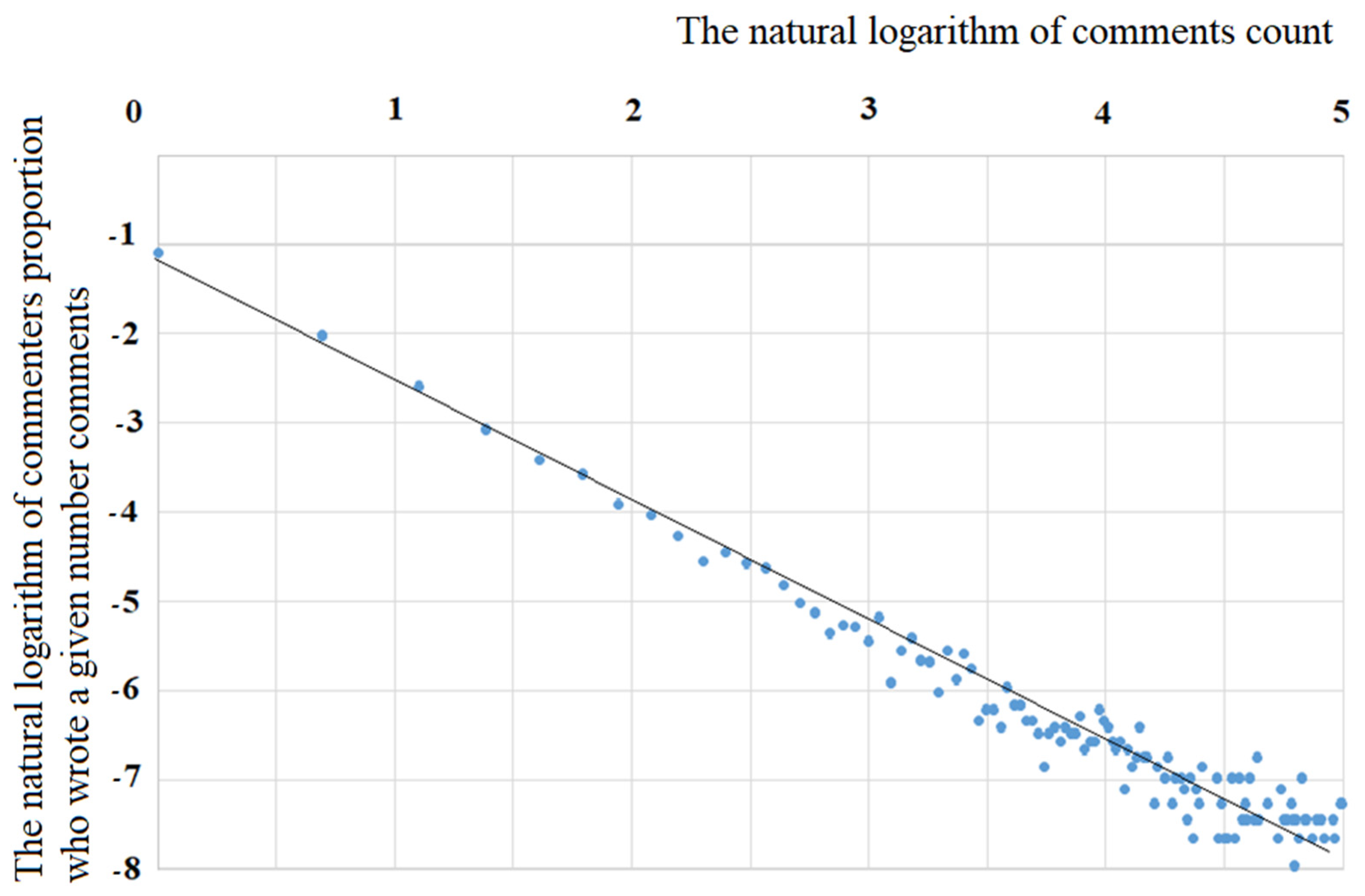
Let us compare the obtained theoretical result with the observed data (see
Figure 5). Linear approximation of the data presented in
Figure 5 allowed us to obtain the equation:
, which must be compared with the equation:
If , then , which shows a very good correspondence between the theory and the observed data.
The results obtained show that, with a linear dependence of on the state of x and a quadratic dependence of on the state of , the power law of dependence is the probability density of the distribution of comments by their number (states of ). This can be obtained from the solution of the stationary Fokker-Planck equation, and the observed data and theoretical calculations have good agreement with each other.
Special attention should be paid to this result. Its importance lies in the fact that the effects of memory and self-organization play an important role in the dynamics of social processes. However, in this case it turns out that from the Fokker-Planck equation (describing the dynamics as a whole at the macro level), the derivation of which considers a completely stochastic Markov approximation, it is possible to obtain theoretical results that are in good agreement with the observed data. We can make an assumption that the multi-directionality of a multitude of local actions and processes, each of which has both memory and self-organization, leads in the total result to the fact that memory can largely disappear as a result of the multi-direction of the ongoing micro-processes.
6. A Model of the Nonlinear Dynamics of the Appearance of Comments Based on the Fokker-Planck Equation
Since the use of the Fokker-Planck equation and the approach described above allow us to obtain the power law of distribution observed in practice, it is advisable to use this equation to describe the dynamics of the observed processes.
Using the method of Laplace transformations for Equation (1), it is possible to obtain (see
Appendix A) the following expression for the distribution function:
The probability that the number of comments by the time it reaches a certain number
can be found by the formula (10):
This determines the probability that the threshold (for example, the maximum possible value of the number of comments) will not be reached by time . The dependence of the number of comments on time t will be described by the equation: .
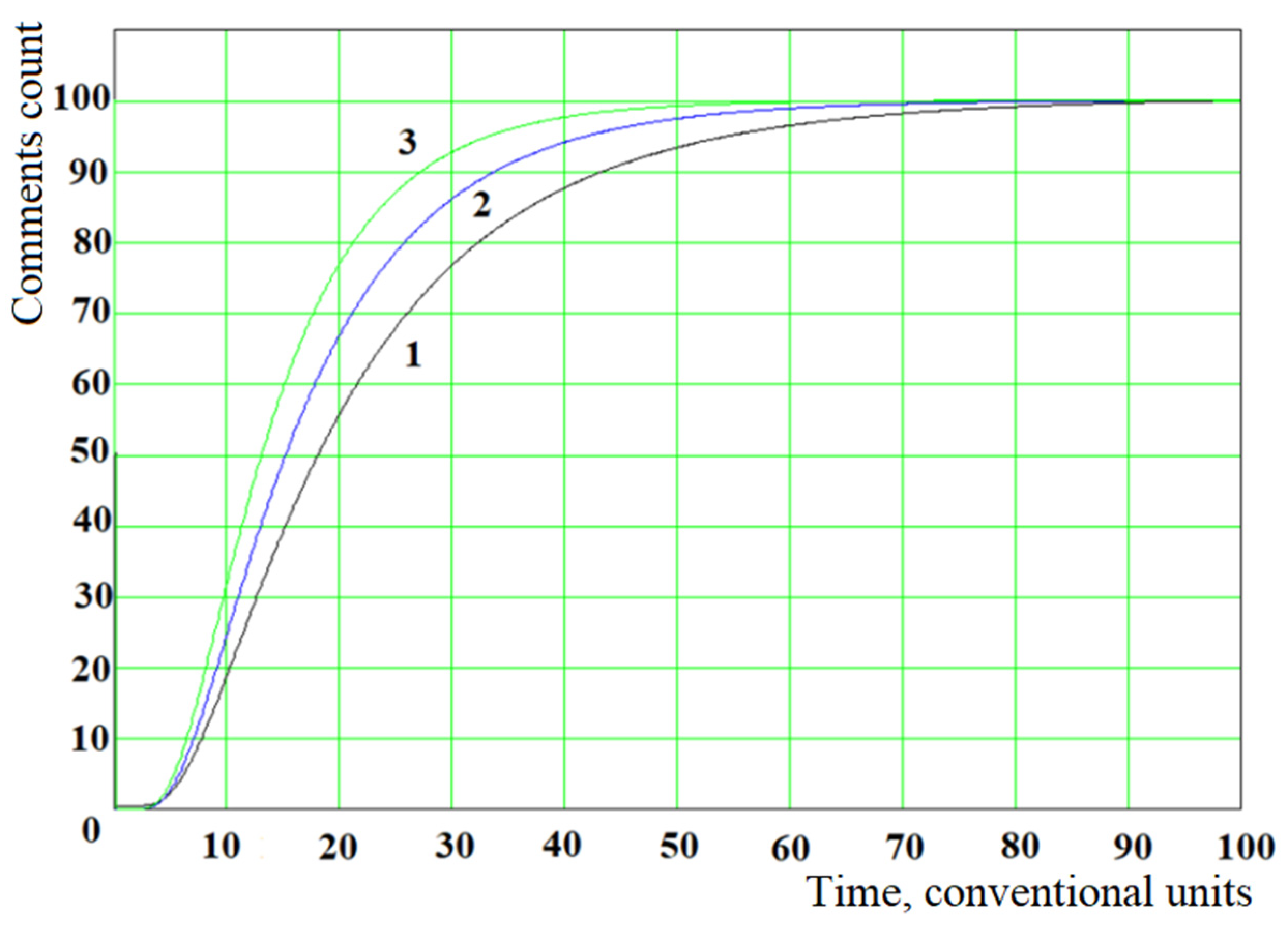
We will conduct simulation modeling and analyze the theoretical results obtained. As an example, we choose
= 100 and three sets of values of
and
(
= 0.45 и
= 0.50 conventional units
see curve 1 in
Figure 11);
= 0.50 и
= 0.50 and
conventional units
see curve 2 in
Figure 11) and
= 0.55 and
= 0.50 conventional units (
>
see curve 3 in
Figure 11)).
Figure 11 shows the results of modeling the dynamics of changes over time in the number of comments
at the selected values of the model parameters
,
and
.
Theoretical calculations show that, with the growth of
relative to
, the growth rate of the curve increases (see
Figure 11).
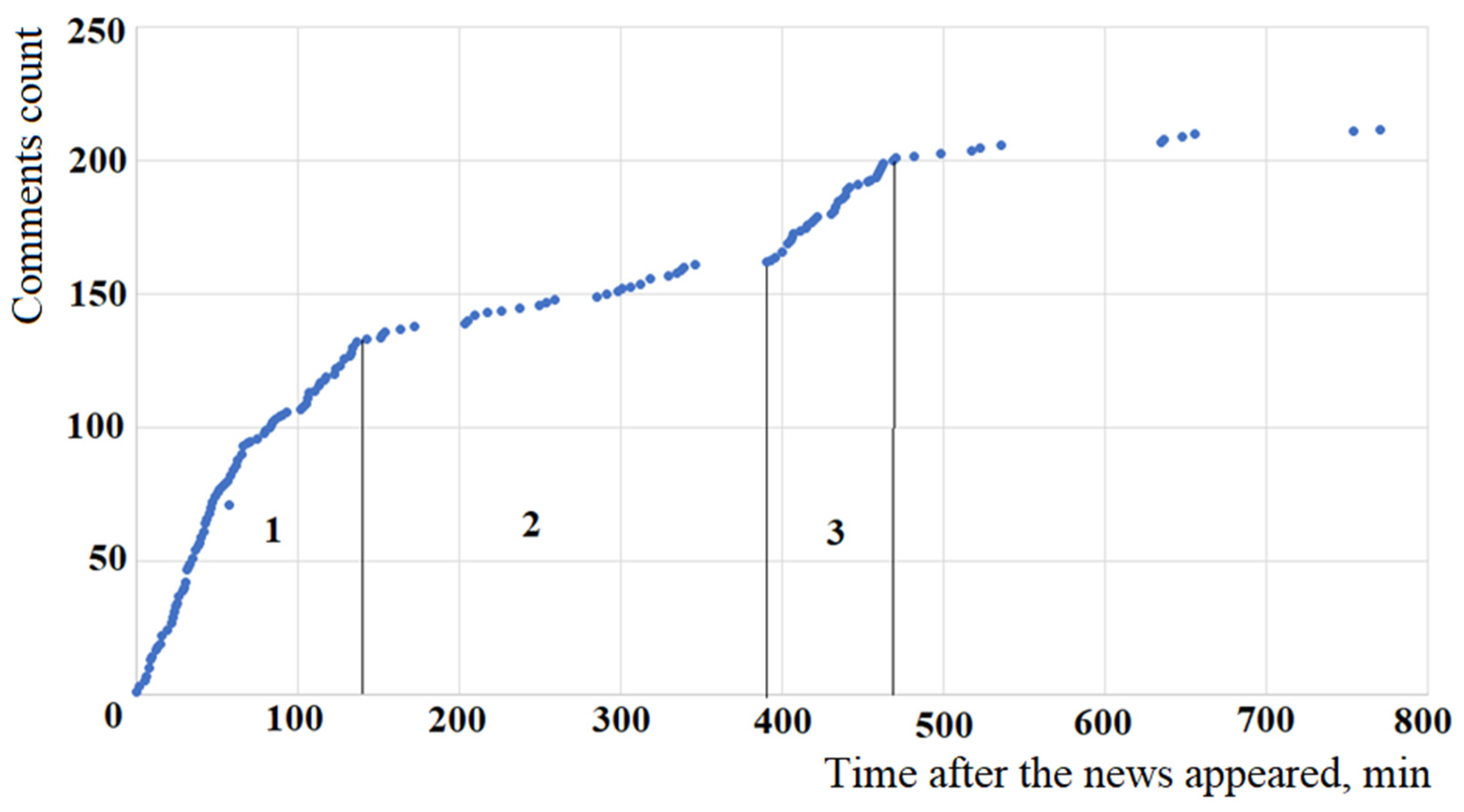
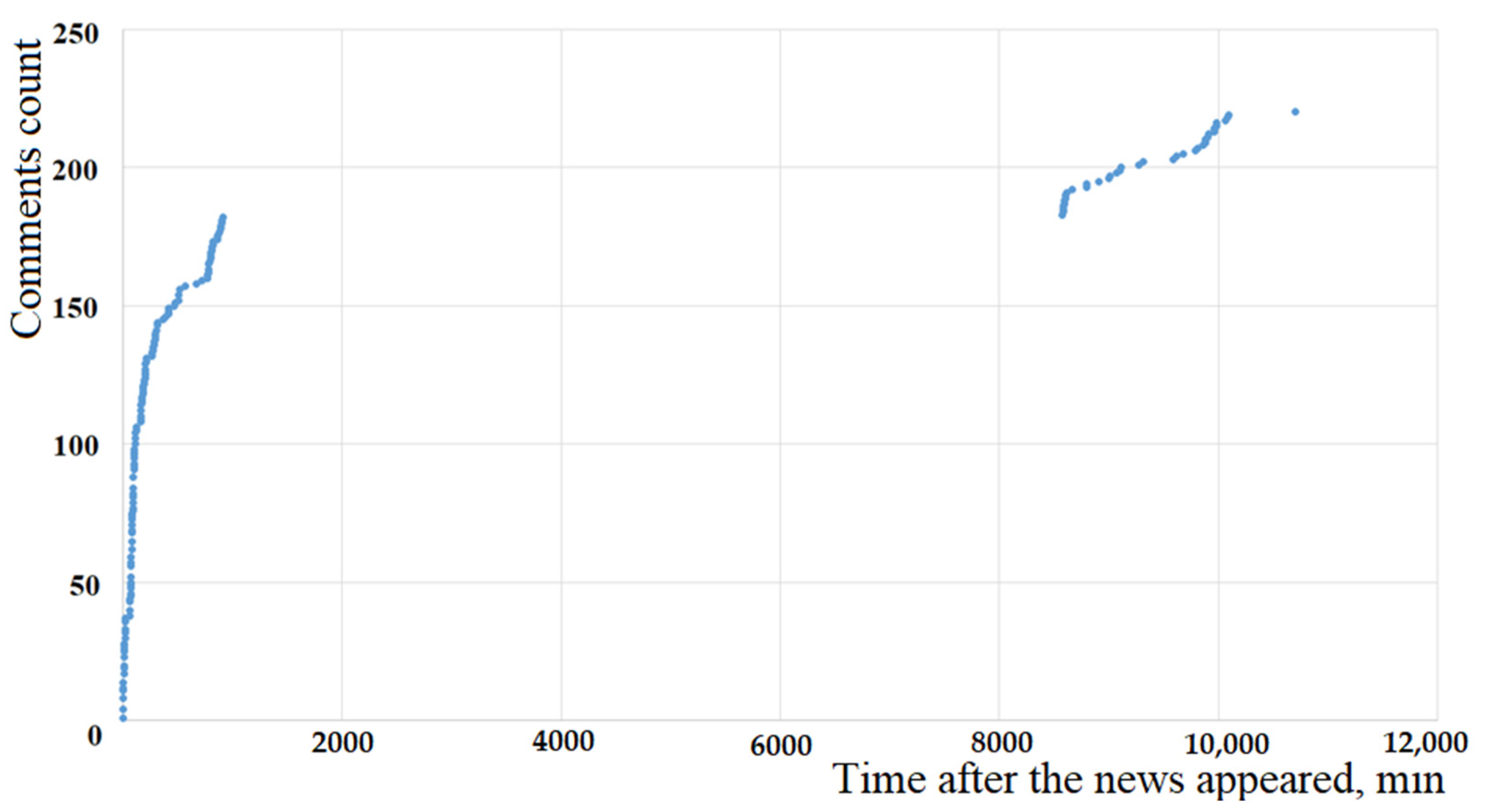
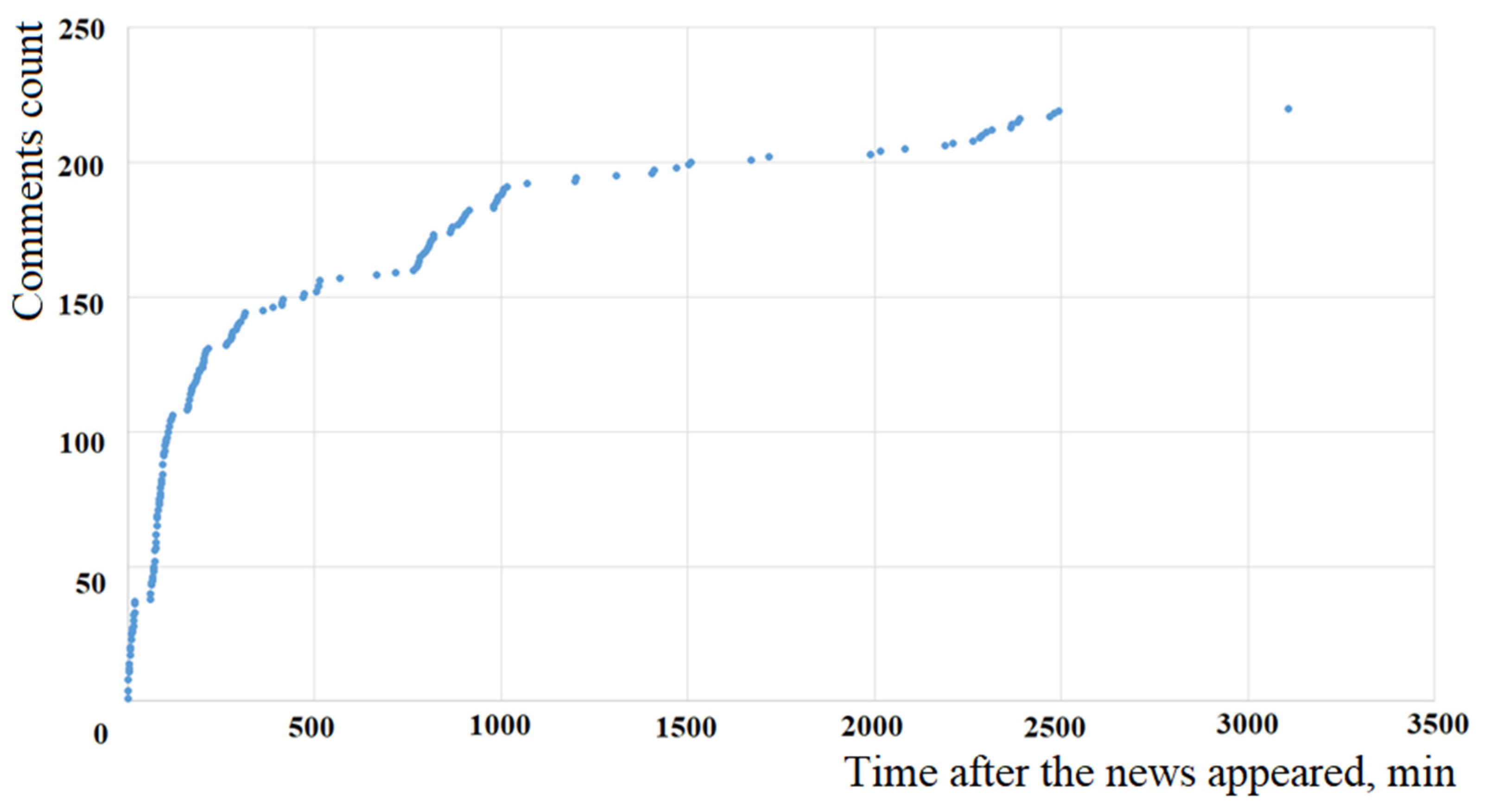
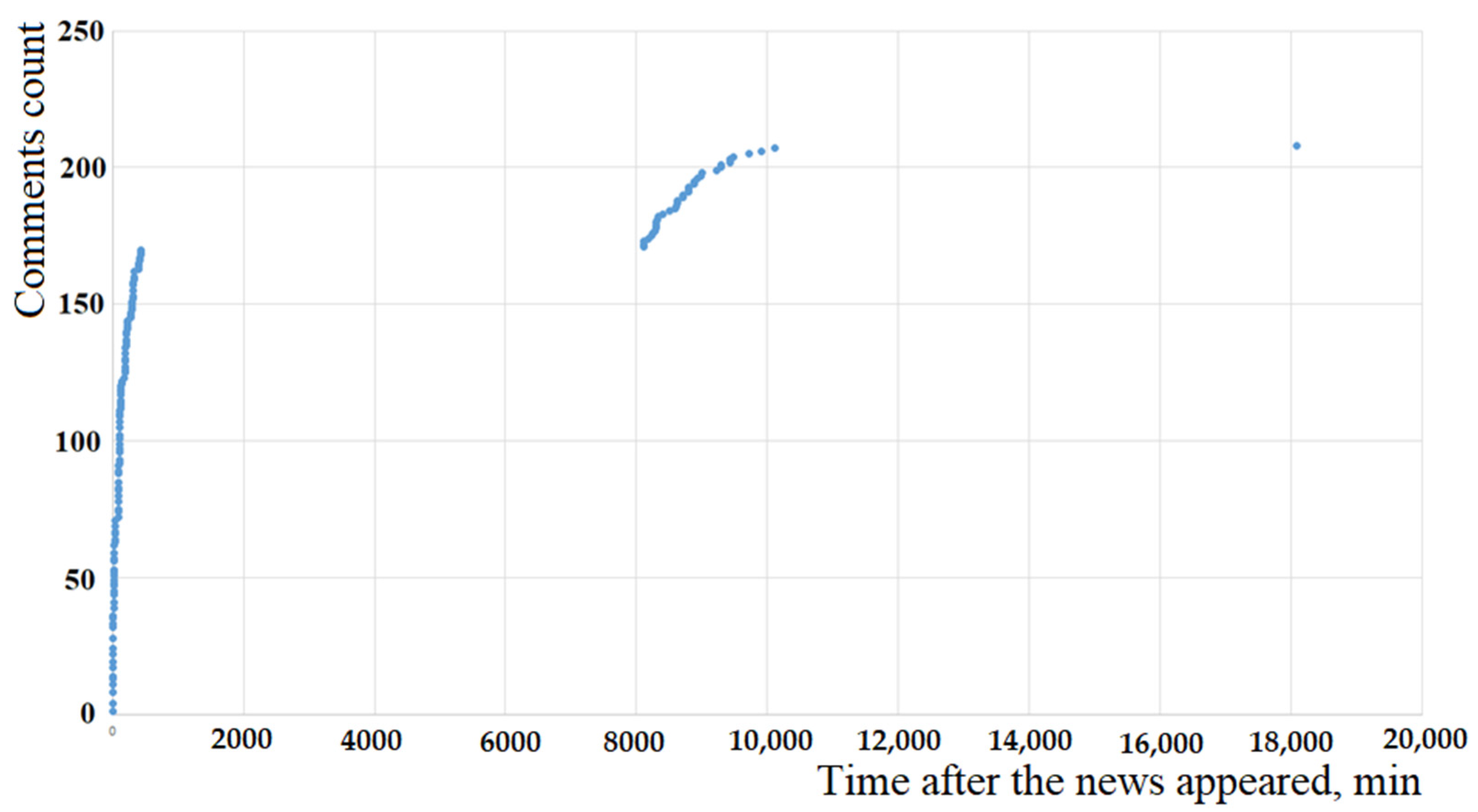
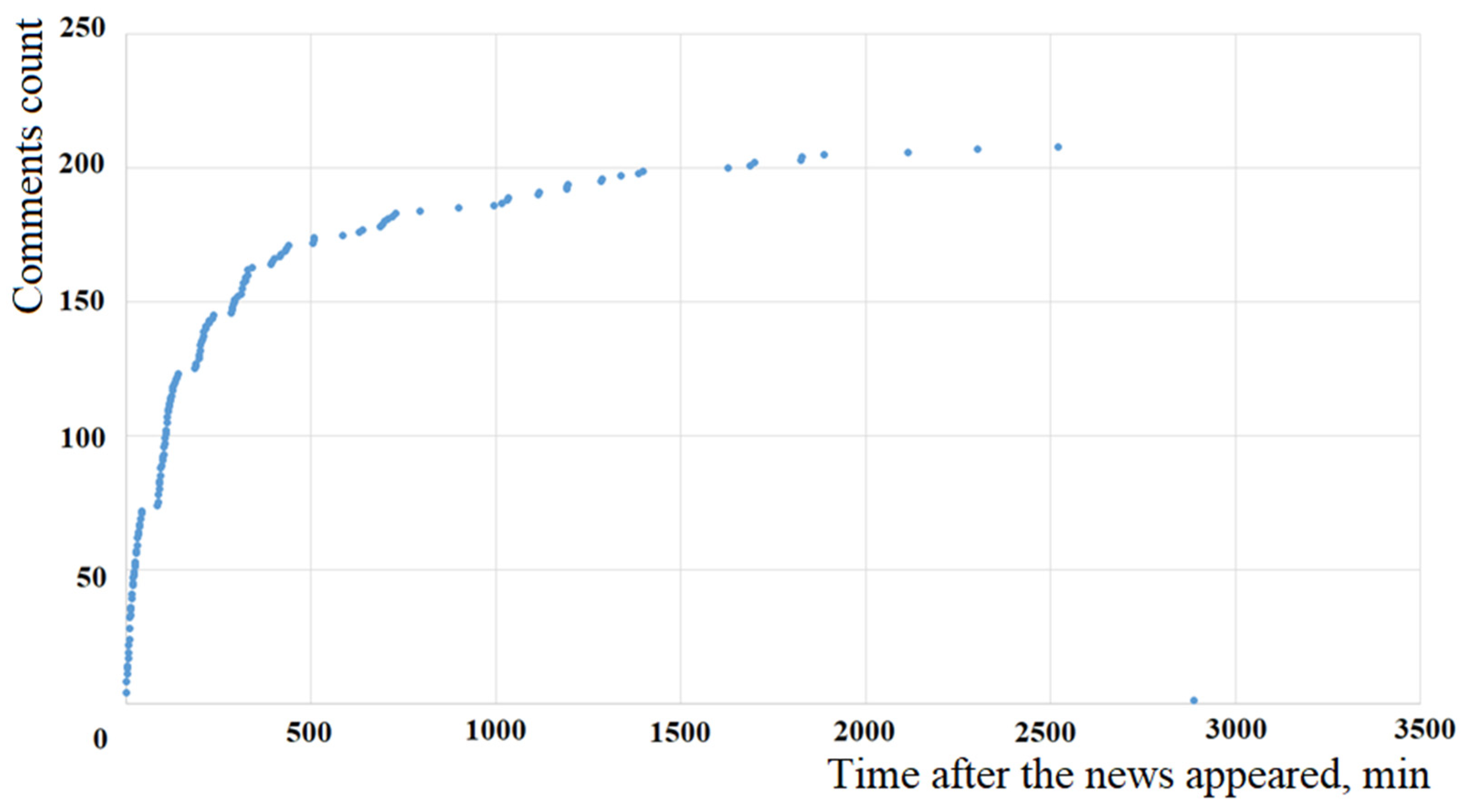
It is important to note that the model based on the Fokker-Planck equation for all values of the parameters
and
shows the S-shaped nature of the dynamics of changes in the number of comments to the news over time, which in many cases is not consistent with the observed data (see
Figure 6 and
Figure 8).
The correspondence of the theoretical model and the observed data (see
Figure 6 and
Figure 8) can be obtained if we assume that two processes with different
and
can occur simultaneously. Moreover, the sum of the partial fractions of the processes should be equal to 1, i.e.,
, where
. At the same time, one of the processes is generated by commenting on the newsfeed or blog itself, and the second by commenting on comments. To describe this, we consider the possible time delay in commenting on comments in the model. If we enter the delay time (denote it
), then the distribution function will take the form:
As we wrote earlier, this may be due to a significant difference in the average time of appearance of second-level comments (the time interval between the appearance of a first-level comment and a comment on this comment), which may lead to the implementation of two-stage dynamics in the appearance of comments.
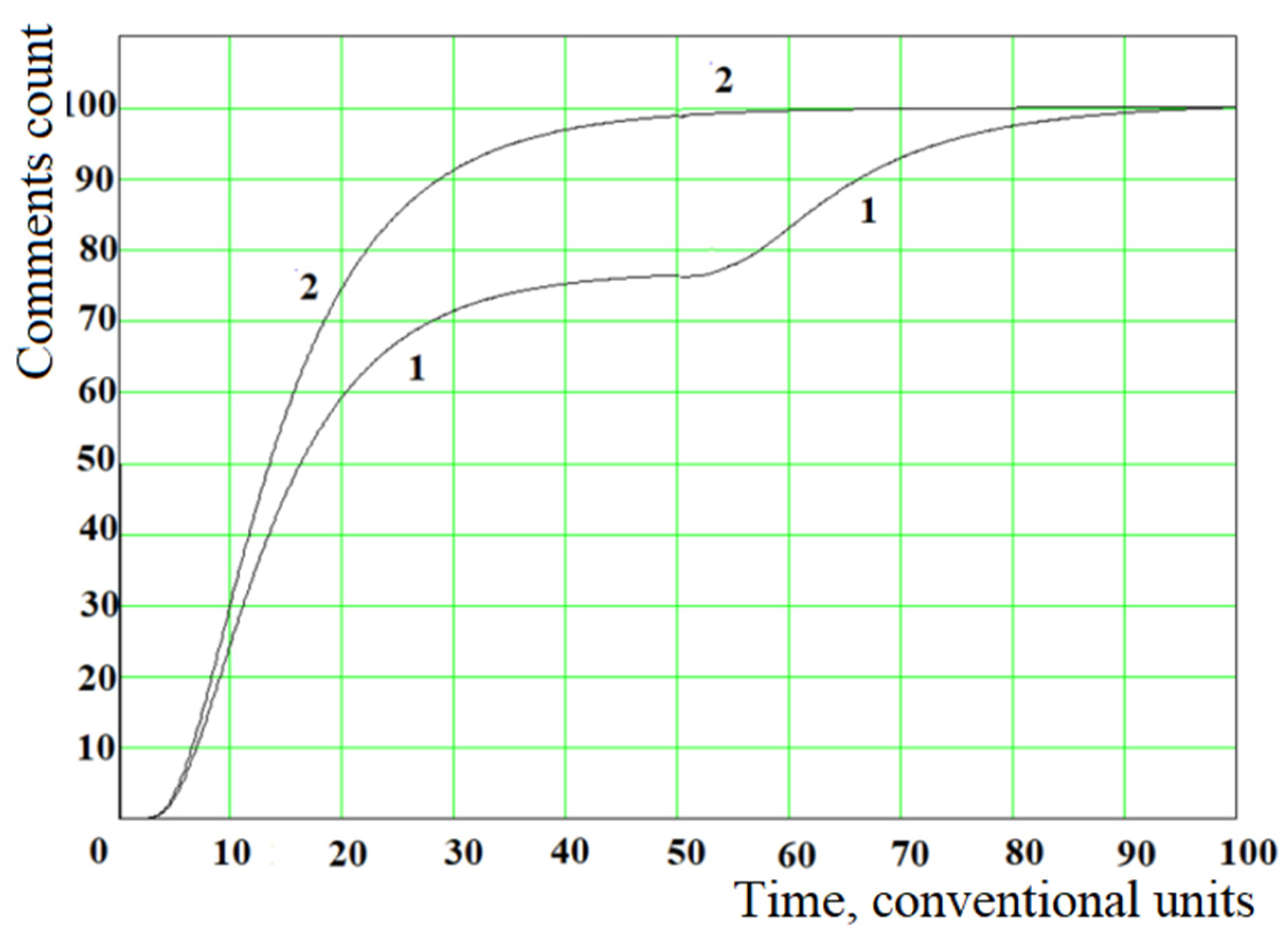
As an example of modeling, we will choose the following model parameters for the process of commenting on the newsfeed or blog itself: = 0.55, = 0.50, and for the second (commenting on comments) = 0.50, = 0.50, = 50 conventional units, = 0.75, = 0.25 and = 100 ( ˃ was chosen based on the assumption that commenting on the news is a more primary process for users than commenting on comments.
Figure 12 shows the results of modeling the dynamics of changes in the number of comments
over time, because two processes can occur in parallel. As can be seen from the simulation results presented in
Figure 12, there is a good coincidence of real data (see
Figure 6 and
Figure 8) and theoretical calculations (curve 1, constructed considering the time delay
). Without considering the delay, the dynamics of the news commenting process is S-shaped (see curve 2 in
Figure 12), which coincides with the observed data presented in
Figure 10 and is consistent with a significant difference in the average time of appearance of second-level comments for news items 1, 2 and 3 selected as an example.
The parallel flow of the two processes does not violate the integrity of the model, because the stationary solution of the modified Fokker-Planck equation (taking into account the delay by ) and the usual equation has the same form, which was described in the section “Derivation of the power law of the distribution of comments from the stationary Fokker-Planck equation”.
7. Discussion
Firstly, it is possible to analyze the topics of news items that gain the largest number of comments (i.e., have the greatest public interest), make a ranking of their popularity, and study their static distributions. Further, within each group, it is possible to determine the exponent of the power law . Then, considering that , it is possible to determine the value of by which it is possible to judge for which types of news and messages purposeful commenting is predominant (an increase in the ratio of ), and for which this is “random” (a decrease in the ratio of ). This will allow prediction in the future as to what news item may cause what user behavior, and how they may influence public opinion.
Secondly, using the dynamic distribution functions obtained in this work, it is possible to analyze the observed processes of commenting on newsfeed and blogs. Further, based on this, it is possible to determine the parameters of the model μ0, D0 and τ for various types of news, which can also allow prediction in the future what news may cause what user behavior, and how this may influence public opinion.
In conclusion, we note that the complex nature of the dynamics of processes in complex social systems can be described, not only based on models created based on the Fokker-Planck equation. For example, in [
41,
42,
43,
44,
45,
46,
47,
48], models were developed by the authors specifically to describe the stochastic dynamics of changes in the state of complex social systems. These models take into account the processes of self-organization and memory availability. To create this model, graphical diagrams of the probabilities of transitions between possible states of the described systems were considered taking into account previous states. This method allows the taking into account memory, and describes not only Markov but also non-Markov processes. Using this approach, a nonlinear differential equation of the second order was derived, which allows the setting and solution of problems for determining the probability density function of the amplitude of deviations of parameters describing the observed processes of a non-stationary time series, depending on the values of the time interval of its determination and the depth of memory accounting. The differential equation obtained during the study contains not only terms responsible for random change (diffusion) and ordered change (destruction), but also a term that is responsible for the possibility of self-organization, which significantly distinguishes it from the Fokker-Planck equation. Within the framework of the models developed by [
41,
42,
43,
44,
45,
46,
47,
48], it is possible to describe processes whose dynamics have both an S-shaped character for changes and a two-stage process.
The novelty of our work in comparison with the works of our predecessors is that, by using a stationary version of the Fokker-Planck equation for the data observed in practice, a power law of the distribution of their parameters can be obtained that is consistent with them. In this case, it can be made a pre-position that the multidirectional nature of many local actions and processes, each of which has both memory and self-organization, leads in summary to the fact that memory can largely disappear and the process in a generalized form becomes Markovsky. This allowed us, under certain assumptions for coefficients in the Fokker-Planck equation, to obtain from its stationary form a power law of distribution for the number of comments on news and blogs. As shown in our paper, the theory aligns well with the data observed in reality.
Secondly, assuming that the Fokker-Planck equation under certain circumstances can be applied to describe the dynamics in the systems in question (for example, based on what is described above) we considered the temporal dependencies of the appearance of comments on various news and found that it can be both S-shaped in nature and have a more complex-two-staged form, which can be explained within the framework of using the Fokker-Planck equation only by the presence of two processes and delay time.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











