
Do Not Rug on Me: Leveraging Machine Learning Techniques for Automated Scam Detection


Abstract
:1. Introduction
- We provide the most extensive labelled dataset of Uniswap rug pulls to date, including the source code, the liquidity, the prices, the mint/burn, and transfer events. The dataset includes all tokens from 4 May 2020 to 3 September 2021. In total, we labelled 26,957 tokens as scams/rug pulls and 631 tokens as non-malicious.
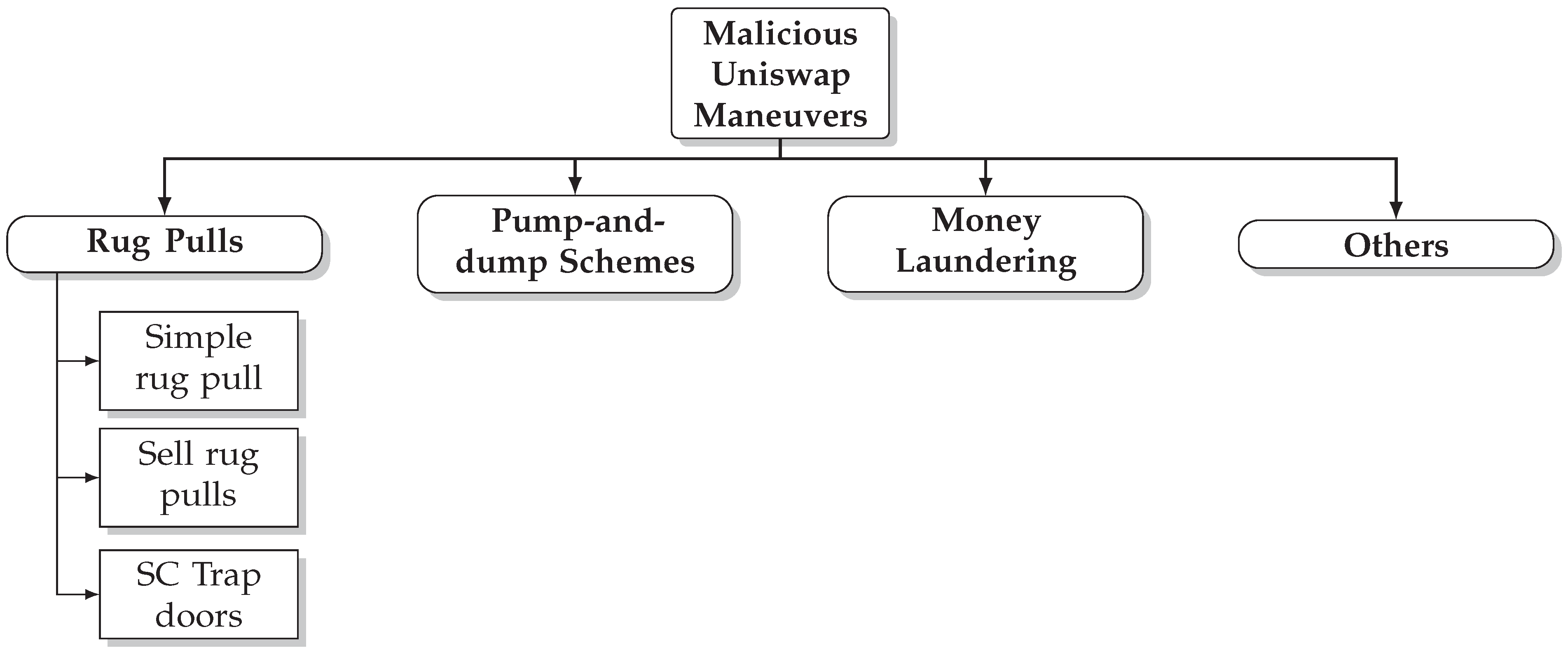
- We provide a theoretical classification of three different types of rug pulls, simple, sell, and trap-door rug pulls, and provide tools to identify them.
- To the best of our knowledge, we are the first to design an accurate automated rug pull detection to predict future rug pulls and scams using relevant features of the pool’s state and the token distribution among the users. More specifically, we used the Herfindahl–Hirschman Index and clustering transaction coefficient as heuristics to measure the distribution of the token among the investors.
- We define two methods that use machine learning models to discriminate between malicious and non-malicious tokens in different scenarios. In the first scenario, tokens can be evaluated at any block prior to the malicious maneuver. In the second scenario, all tokens are evaluated at a certain time after the creation of their respective pools. Specifically, we use a new machine learning algorithm based on attention mechanisms for tabular data called FT-Transformer [6]. Our best model obtains accuracy of 0.9936, recall of 0.9540, and precision of 0.9838 in distinguishing non-malicious tokens from scams in the first scenario and accuracy of 0.992, recall of 0.784, and precision of 0.869 in the second scenario.
2. Related Work
3. Preliminaries
3.1. Ethereum and Smart Contracts
3.2. Decentralized Exchanges
- they permit easy provision of liquidity for minor assets, i.e., any assets can be listed in a DEX;
- they allow any party to become a market maker;
- they are censorship-resilient in highly volatile periods;
- they can be audited by anyone.
- every token can be listed to trade in AMM protocols, making uninformed users fall into different scams or suboptimally performing projects [3].
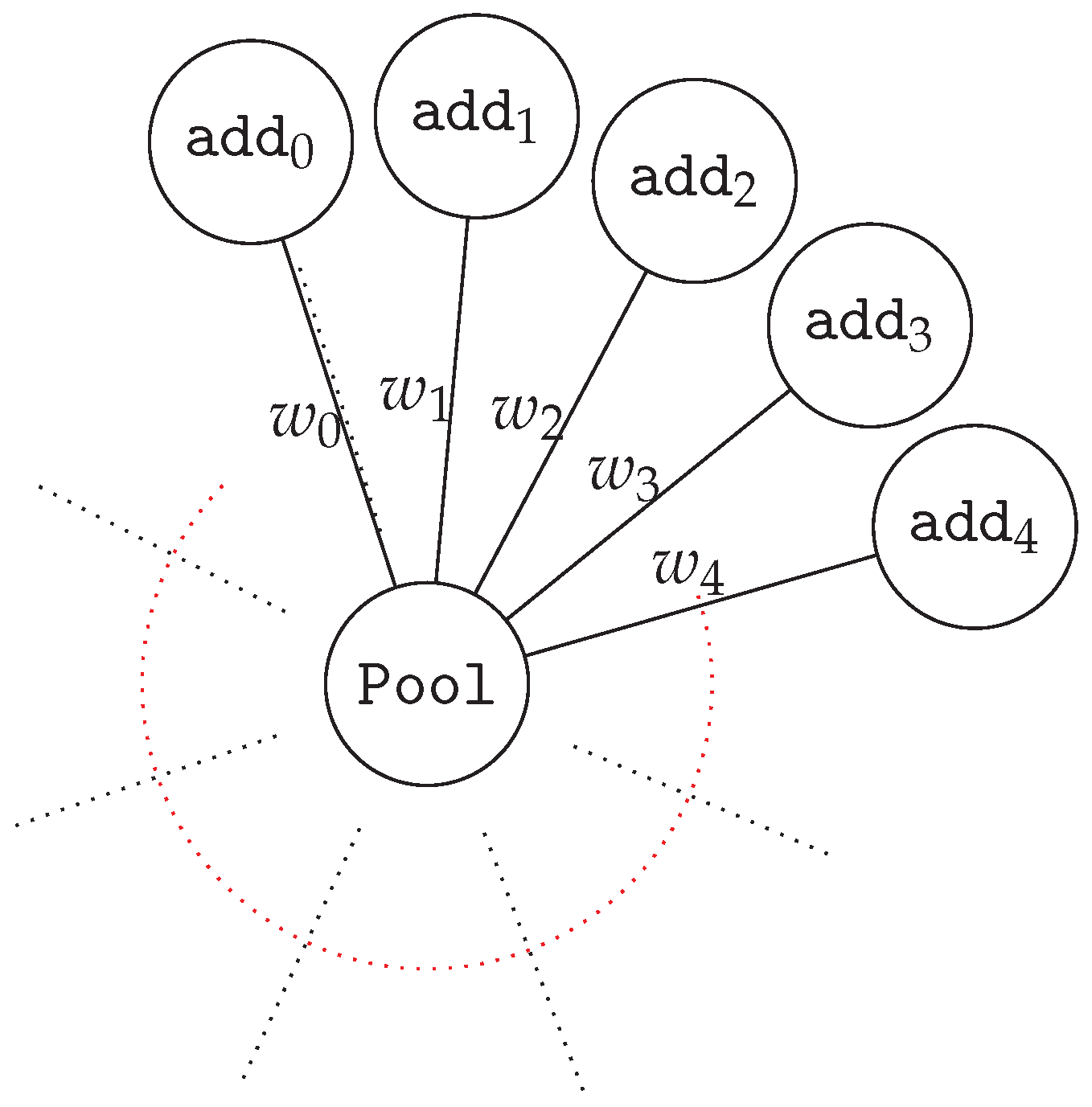
3.3. Uniswap
- PairCreated: It is an event in the UniswapV2 Factory contract. This event emits each time a new pair is created, and outputs the tuple (token0, token1, pair, block_creation) of a new pool created.
- Sync: It is an event in the UniswapV2 PairPool contract. This event emits each time the reserves of the pool change. Every time the balance of the pool updates, the smart contract outputs the tuple (reserves0, reserves1), which is the reserves of the token0 and token1 after the update.
- Mint, Burn & Transfer: These are events in the UniswapV2 PairPool contract that tracks the state of the ERC-20 LP-token.
3.4. Token Propagation
3.4.1. Token Distribution
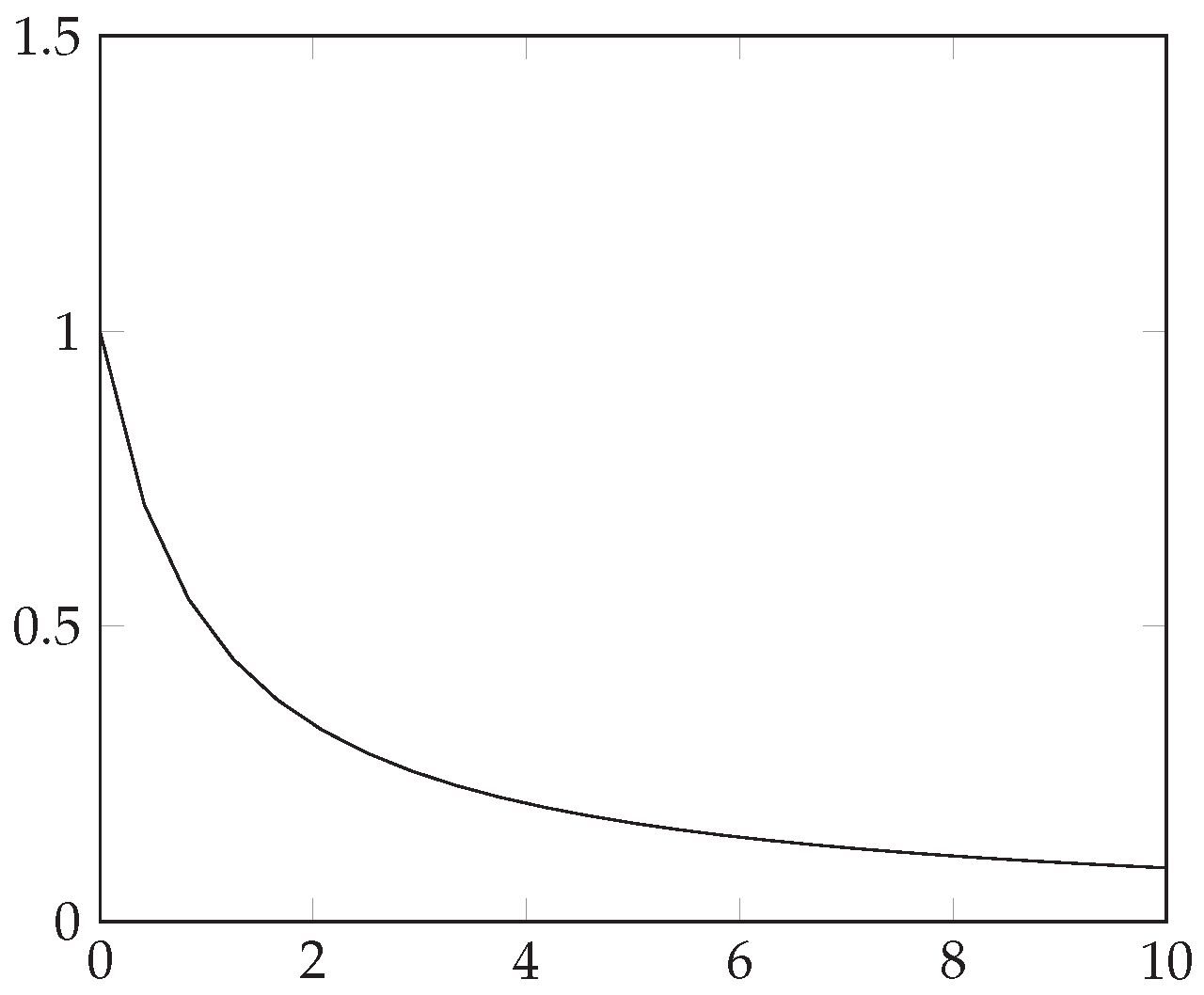
3.4.2. Transaction Graph Analysis
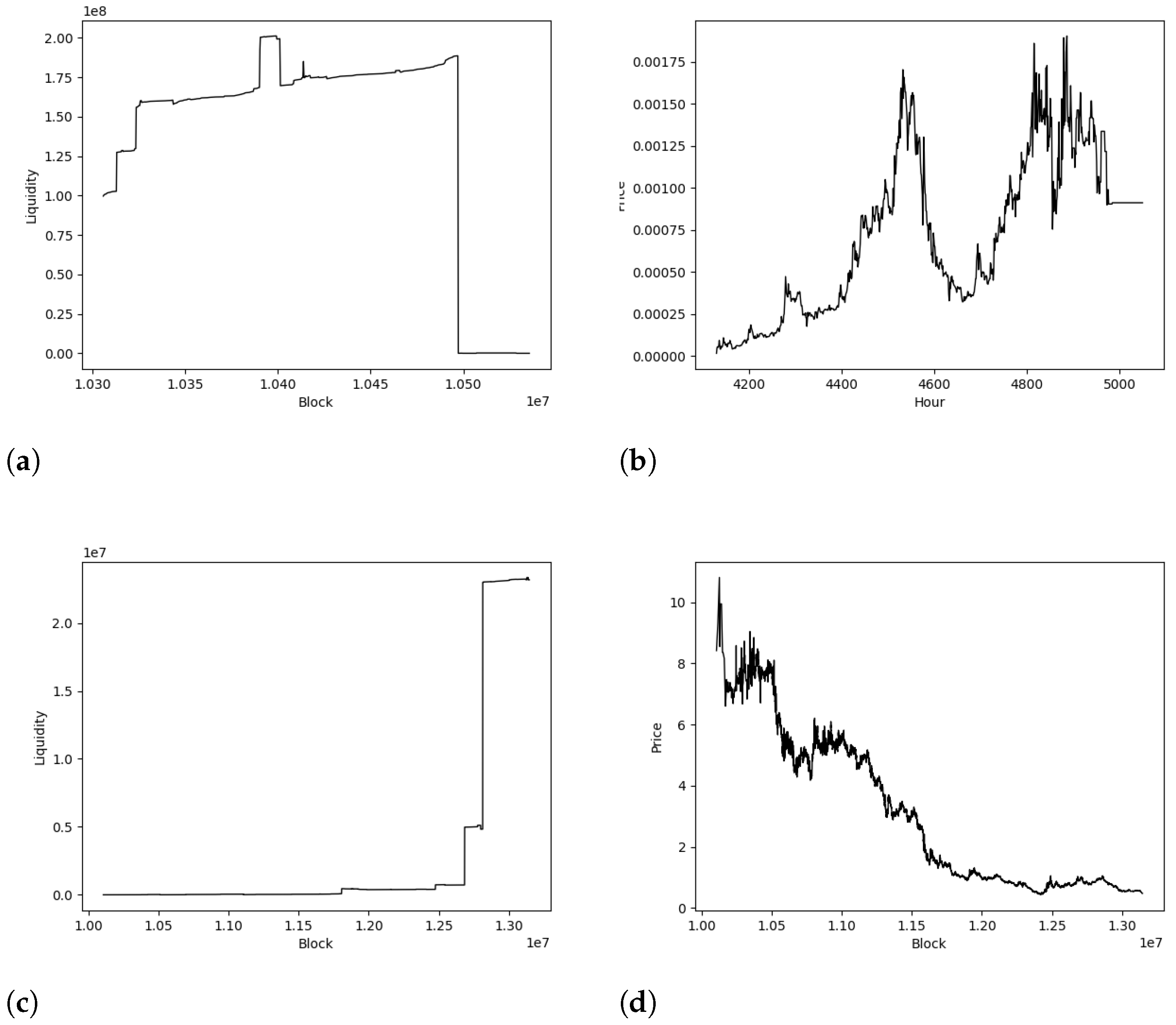
4. Malicious Uniswap Maneuvers
- Mintable is a property shared by many tokens, including non-malicious ones such as USDT (https://tether.to/, accessed on 15 February 2022). In general, we say that a token is mintable if it has a function that allows it to increase the supply of the token with some pre-defined conditions. Usually, mintable tokens give rights to mint new tokens to the developers to a fixed set of addresses. While this functionality can be a useful feature in some contexts, it can also be used by malicious users to subtract all the liquidity of the pull by minting as many tokens as needed.
- TransferFrom/Approve bad design is a property shared by some malicious tokens.TransferFrom is the function that allows a smart contract to transfer assets on behalf of an externally owned account. In the context of Uniswap, a proper design of this function allows tokens to be sold. In other words, arbitrarily changing the TransferFrom function makes the Uniswap Pool behave as a honeypot [18]. There are different means of making this smart contract; however, the most popular example of this kind of scam is the use of tokens that contain the line code require(from == owner to == owner from == UNI) in the TransferFrom function.
- Composability vulnerabilities are the least common ones and the hardest to find. In general, this type of rug pull is not made by the developers but by malicious agents external to the project, who take advantage of the bad design of the smart contract token interacting with Uniswap or other DEXs. Those that we have been able to identify are the tokens with a price oracle vulnerability. Usually, we observed that these tokens have Uniswap integrated in the source code of the smart contract in order to reward holders. However, these rewards depend on the price. The higher the price, the higher the reward. The fundamental problem of this mechanism is that the price is defined through an oracle that, as shown in [22], is easy to manipulate with enough funds or using a flash loan.
5. Data Collection
- Tokens listed: We obtained the history of all tokens listed in the Uniswap V2 from its creation to 3 September 2021, asking for all events of the PairCreated type in the UniswapV2Factory contract.
- Smart contract and features: After obtaining all listed tokens in Uniswap, with the help of Etherscan, we downloaded the transactions in which they were created, their smart contract, their decimals, and their symbol. In order to speed up these calls, we used the multicall contract (https://etherscan.io/address/0xb1f8e55c7f64d203c1400b9d8555d050f94adf39, accessed on 15 February 2022) to batch these calls to the blockchain in a single call. Afterwards, we used Slither [16] to obtain different features of the smart contract, such as pausable and mintable.
- Events: From all the pools of Uniswap obtained in Tokens listed, we collected all events of type Sync, Mint, Burn and Transfer for each of the PairPools obtained. Finally, we downloaded all Transfer events from each of the tokens.
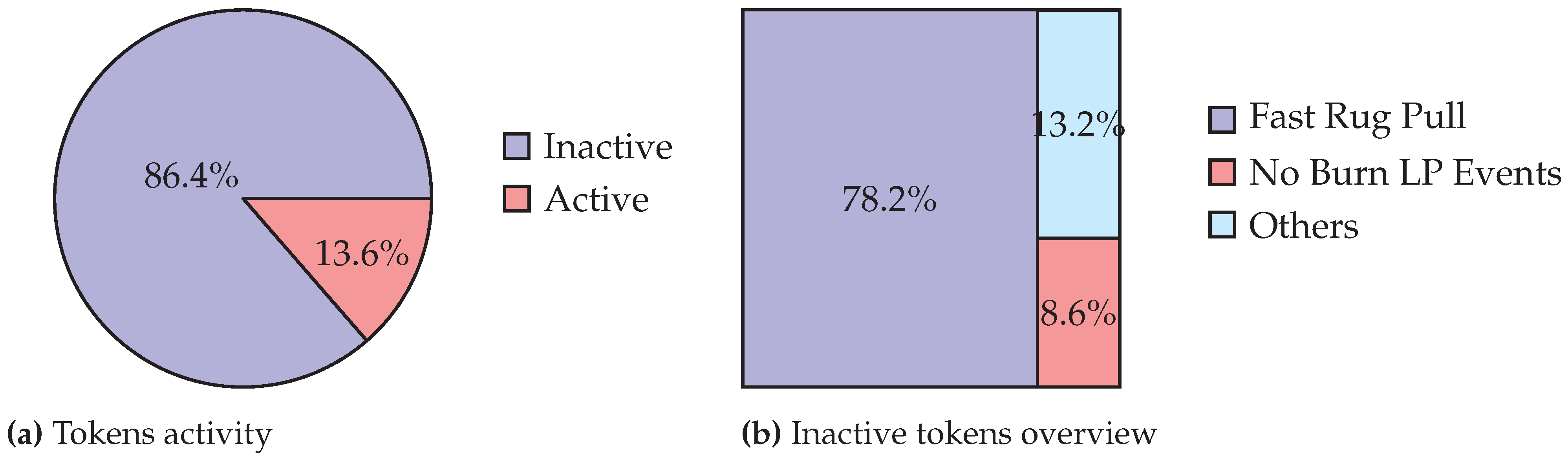
6. Token Labelling
6.1. Ground Truth Labelling
6.1.1. Malicious Token Labelling
6.1.2. Non-Malicious Token Labelling
7. Scam Detection
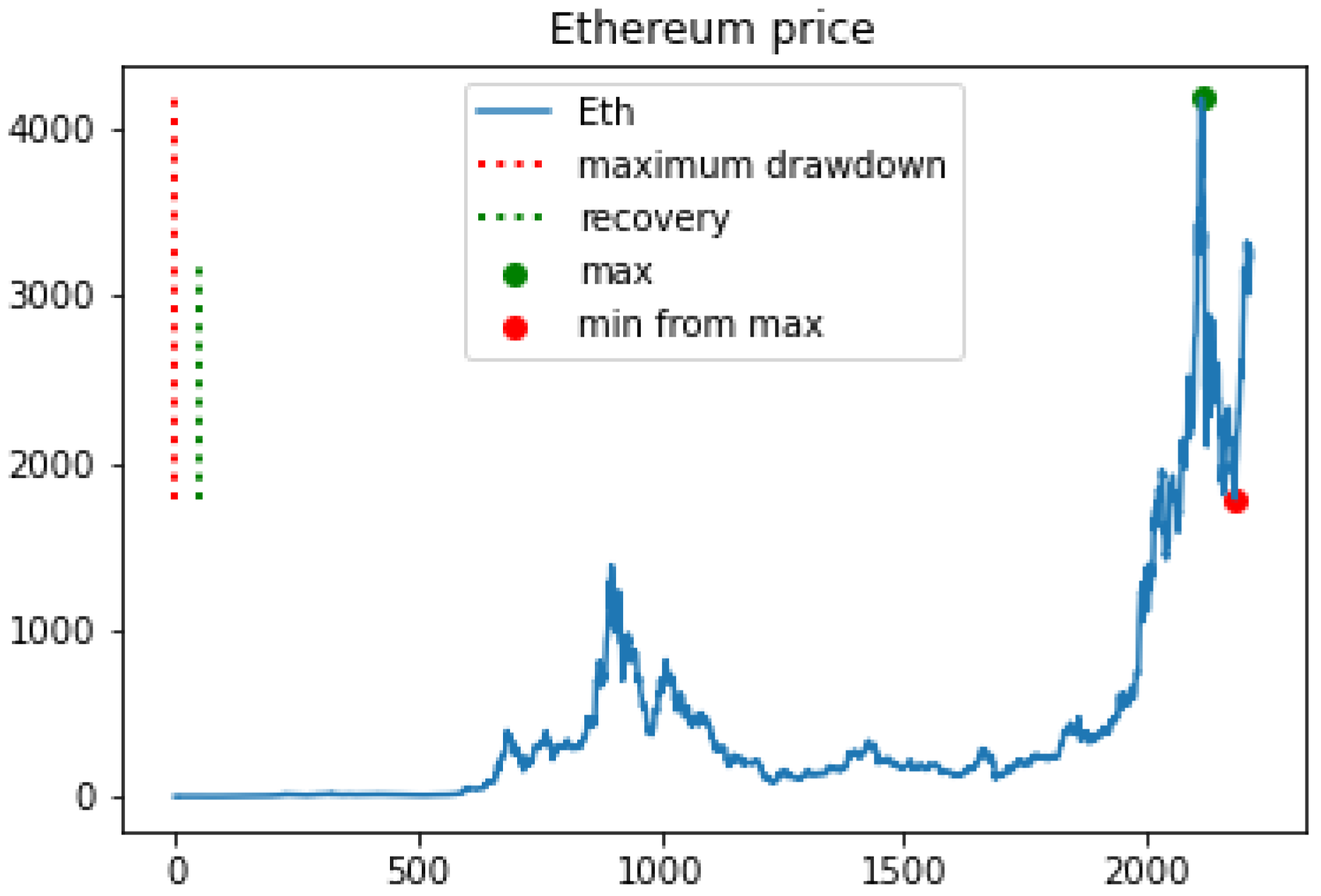
7.1. Activity-Based Method
7.2. 24-Hour Early Method
7.3. Machine Learning and Hyperparameter Optimization
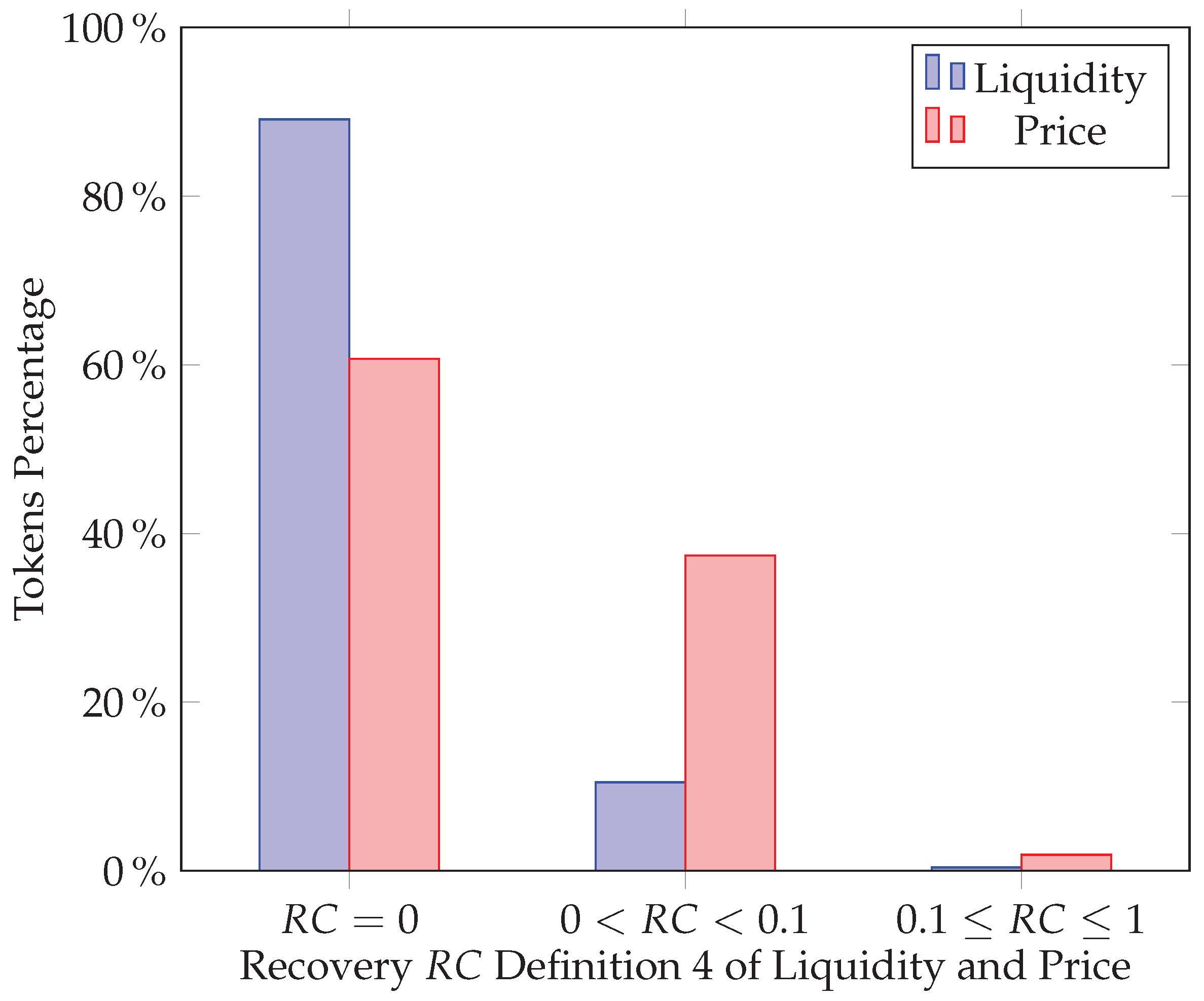
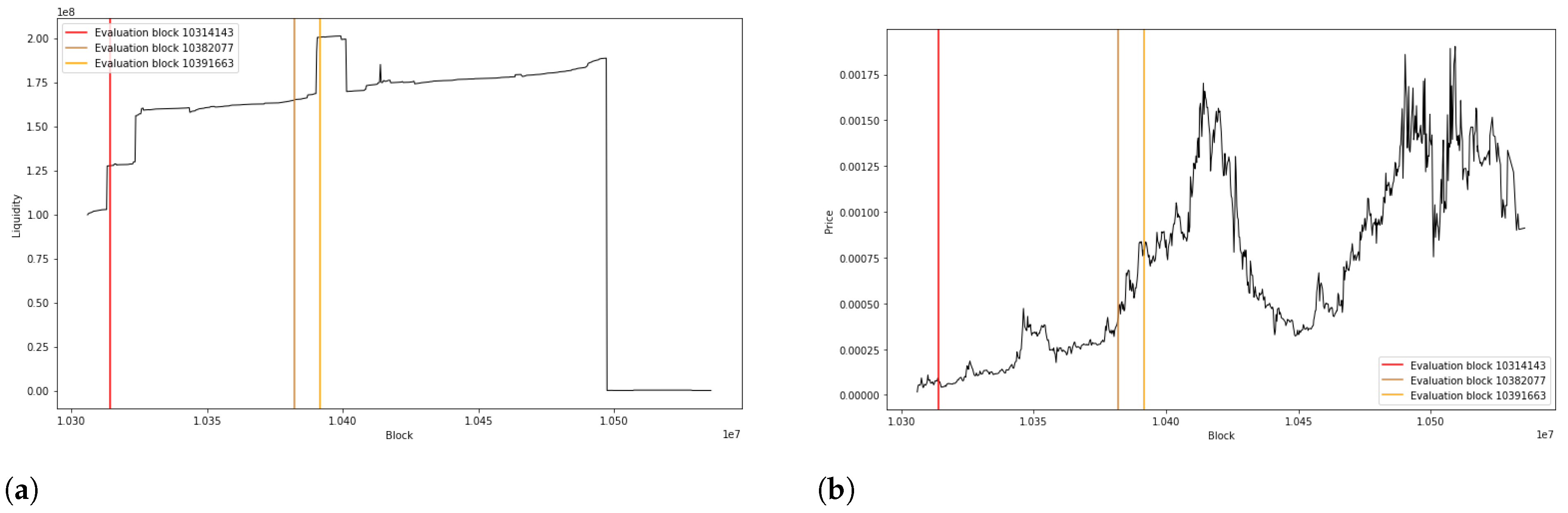
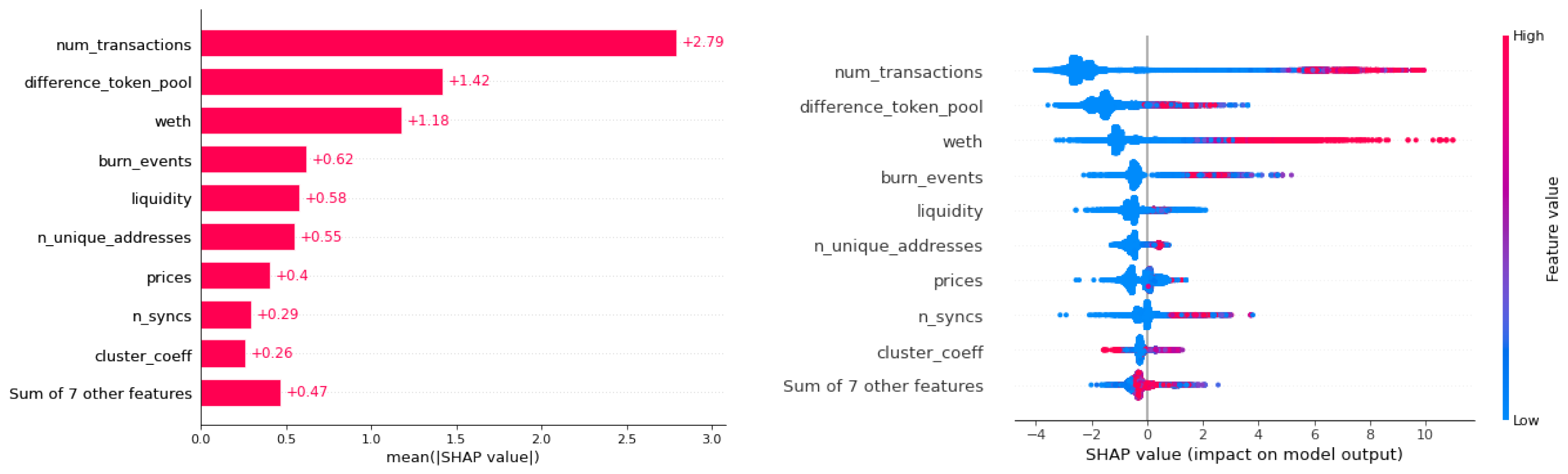
7.4. Results
7.4.1. Activity-Based Method Results
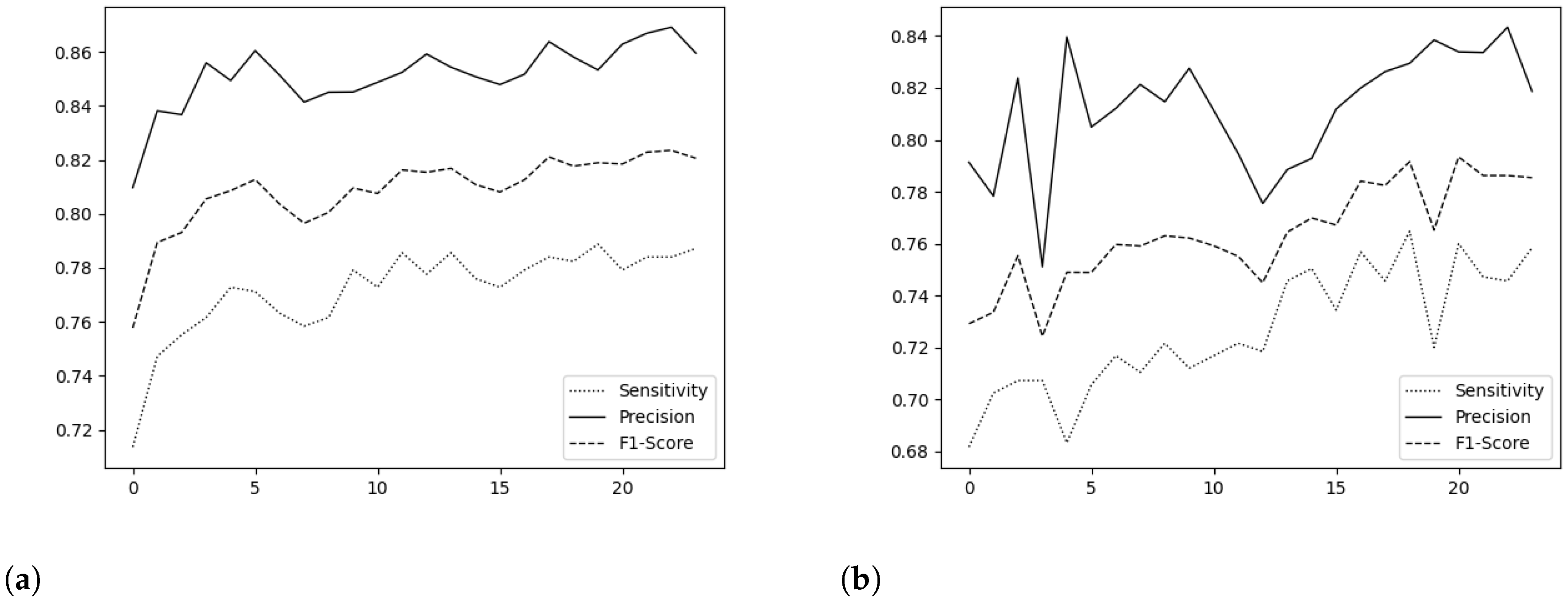
7.4.2. 24-Hour Early Method Results
7.4.3. Unicrypt Results
8. Conclusions
9. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Appendix A. Table of Features

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Group | Name | Description |
|---|---|---|
| HHI index | liq_curve | HHI applied to LP tokens. |
| tx_curve | HHI applied to each token. | |
| Pool | n_pool_syncs | Total sync events. |
| weth | Total weth. | |
| price | Price of token. | |
| liquidity | Total liquidity. | |
| LP-Token | lp_transfer | Total number of LP token transfers. |
| mints | Total number of mint events. | |
| burns | Total number of burn events. | |
| Token transfers | n_transfers | Total number of transfers. |
| n_unique_addresses | Total number of unique addresses. | |
| clus_coeff | Clustering coefficient. | |
| Token | difference_token_pool | Number of blocks between token and pool creation. |
| lock | This feature is 1 if part of the liquidity is locked and 0 otherwise. | |
| yield | This feature is 1 if there is yield farming involved and 0 otherwise. | |
| burn | This feature is 1 if part of the liquidity has been burned and 0 otherwise. |
Appendix B. Hyperparameters
| Model | Parameter | Type | Distribution | Range |
|---|---|---|---|---|
| XGBoost | max_depth | Int | Uniform | [3, 10] |
| subsample | Float | Uniform | [0.5, 1] | |
| learning_rate | Float | Uniform | [1 × 10−5, 1] | |
| gamma | Float | Log-Uniform | [1 × 10−8, 1 × 102] | |
| lambda | Float | Log-Uniform | [1 × 10−8, 1 × 102] | |
| alpha | Float | Log-Uniform | [1 × 10−8, 1 × 102] |
Appendix C. Second Method Results
| XGBoost 24 h | FT-Transformer 24 h | ||||||||
| Hour | Accuracy | Sensitivity | Precision | F1_Score | Hour | Accuracy | Sensitivity | Precision | F1_Score |
| 1 | 0.990 | 0.714 | 0.810 | 0.758 | 1 | 0.989 | 0.682 | 0.791 | 0.729 |
| 2 | 0.991 | 0.747 | 0.838 | 0.789 | 2 | 0.988 | 0.702 | 0.778 | 0.734 |
| 3 | 0.991 | 0.755 | 0.837 | 0.793 | 3 | 0.990 | 0.707 | 0.824 | 0.755 |
| 4 | 0.992 | 0.762 | 0.856 | 0.806 | 4 | 0.987 | 0.707 | 0.751 | 0.724 |
| 5 | 0.992 | 0.773 | 0.849 | 0.809 | 5 | 0.990 | 0.683 | 0.840 | 0.749 |
| 6 | 0.992 | 0.771 | 0.860 | 0.813 | 6 | 0.989 | 0.706 | 0.805 | 0.749 |
| 7 | 0.992 | 0.763 | 0.851 | 0.804 | 7 | 0.990 | 0.717 | 0.812 | 0.760 |
| 8 | 0.991 | 0.758 | 0.841 | 0.797 | 8 | 0.990 | 0.710 | 0.821 | 0.759 |
| 9 | 0.991 | 0.762 | 0.845 | 0.801 | 9 | 0.990 | 0.722 | 0.815 | 0.763 |
| 10 | 0.992 | 0.779 | 0.845 | 0.810 | 10 | 0.990 | 0.712 | 0.828 | 0.762 |
| 11 | 0.992 | 0.773 | 0.849 | 0.808 | 11 | 0.990 | 0.717 | 0.811 | 0.759 |
| 12 | 0.992 | 0.786 | 0.852 | 0.816 | 12 | 0.989 | 0.722 | 0.795 | 0.755 |
| 13 | 0.992 | 0.778 | 0.859 | 0.815 | 13 | 0.989 | 0.718 | 0.775 | 0.745 |
| 14 | 0.992 | 0.786 | 0.854 | 0.817 | 14 | 0.989 | 0.746 | 0.789 | 0.764 |
| 15 | 0.992 | 0.776 | 0.851 | 0.811 | 15 | 0.990 | 0.750 | 0.793 | 0.770 |
| 16 | 0.992 | 0.773 | 0.848 | 0.808 | 16 | 0.990 | 0.734 | 0.812 | 0.767 |
| 17 | 0.992 | 0.779 | 0.852 | 0.813 | 17 | 0.991 | 0.757 | 0.820 | 0.784 |
| 18 | 0.992 | 0.784 | 0.864 | 0.821 | 18 | 0.991 | 0.746 | 0.826 | 0.782 |
| 19 | 0.992 | 0.782 | 0.858 | 0.818 | 19 | 0.991 | 0.765 | 0.829 | 0.792 |
| 20 | 0.992 | 0.789 | 0.853 | 0.819 | 20 | 0.990 | 0.720 | 0.838 | 0.765 |
| 21 | 0.992 | 0.779 | 0.863 | 0.818 | 21 | 0.991 | 0.760 | 0.834 | 0.793 |
| 22 | 0.992 | 0.784 | 0.867 | 0.823 | 22 | 0.991 | 0.747 | 0.834 | 0.786 |
| 23 | 0.992 | 0.784 | 0.869 | 0.824 | 23 | 0.991 | 0.746 | 0.843 | 0.786 |
| 24 | 0.992 | 0.787 | 0.860 | 0.821 | 24 | 0.991 | 0.758 | 0.819 | 0.785 |
References
- Nakamoto, S. Bitcoin: A Peer-to-Peer Electronic Cash System; Technical Report; SSRN: Rochester, NY, USA, 2019. [Google Scholar]
- Werner, S.M.; Perez, D.; Gudgeon, L.; Klages-Mundt, A.; Harz, D.; Knottenbelt, W.J. Sok: Decentralized finance (defi). arXiv 2021, arXiv:2101.08778. [Google Scholar]
- Xia, P.; Gao, B.; Su, W.; Yu, Z.; Luo, X.; Zhang, C.; Xiao, X.; Xu, G. Demystifying Scam Tokens on Uniswap Decentralized Exchange. arXiv 2021, arXiv:2109.00229. [Google Scholar]
- Rug Pull Detector. Available online: http://rugpulldetector.com/ (accessed on 30 September 2021).
- Token Sniffer. Available online: https://tokensniffer.com/ (accessed on 30 September 2021).
- Gorishniy, Y.; Rubachev, I.; Khrulkov, V.; Babenko, A. Revisiting Deep Learning Models for Tabular Data. 2021. Available online: http://xxx.lanl.gov/abs/2106.11959 (accessed on 15 February 2022).
- Zero-Dimensional Scam Detection. Available online: https://github.com/T2Project/RugPullDetection (accessed on 12 December 2021).
- Li, Y.; Islambekov, U.; Akcora, C.; Smirnova, E.; Gel, Y.R.; Kantarcioglu, M. Dissecting ethereum blockchain analytics: What we learn from topology and geometry of the ethereum graph? In Proceedings of the 2020 SIAM International Conference on Data Mining, SIAM, Cincinnati, OH, USA, 7–9 May 2020; pp. 523–531. [Google Scholar]
- Ofori-Boateng, D.; Dominguez, I.S.; Kantarcioglu, M.; Akcora, C.G.; Gel, Y.R. Topological Anomaly Detection in Dynamic Multilayer Blockchain Networks. 2021. Available online: http://xxx.lanl.gov/abs/2106.01806 (accessed on 15 February 2022).
- Onnela, J.P.; Saramäki, J.; Kertész, J.; Kaski, K. Intensity and coherence of motifs in weighted complex networks. Phys. Rev. E 2005, 71, 065103. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Patel, V.; Pan, L.; Rajasegarar, S. Graph Deep Learning Based Anomaly Detection in Ethereum Blockchain Network. In Proceedings of the International Conference on Network and System Security; Springer: Berlin, Germany, 2020; pp. 132–148. [Google Scholar]
- Phillips, R.; Wilder, H. Tracing Cryptocurrency Scams: Clustering Replicated Advance-Fee and Phishing Websites. In Proceedings of the 2020 IEEE International Conference on Blockchain and Cryptocurrency (ICBC), Toronto, ON, Canada, 2–6 May 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Poursafaei, F.; Hamad, G.B.; Zilic, Z. Detecting Malicious Ethereum Entities via Application of Machine Learning Classification. In Proceedings of the 2020 2nd Conference on Blockchain Research Applications for Innovative Networks and Services (BRAINS), Paris, France, 28–30 September 2020; pp. 120–127. [Google Scholar] [CrossRef]
- Seres, I.A.; Nagy, D.A.; Buckland, C.; Burcsi, P. Mixeth: Efficient, trustless coin mixing service for ethereum. In Proceedings of the International Conference on Blockchain Economics, Security and Protocols (Tokenomics 2019), Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik, Paris, France, 6–7 May 2019. [Google Scholar]
- Dika, A.; Nowostawski, M. Security vulnerabilities in ethereum smart contracts. In Proceedings of the 2018 IEEE International Conference on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData) IEEE, Yogyakarta, Indonesia, 19–21 November 2018; pp. 955–962. [Google Scholar]
- Feist, J.; Grieco, G.; Groce, A. Slither: A static analysis framework for smart contracts. In Proceedings of the 2019 IEEE/ACM 2nd International Workshop on Emerging Trends in Software Engineering for Blockchain (WETSEB), IEEE, Montreal, QC, Canada, 27–27 May 2019; pp. 8–15. [Google Scholar]
- Oliva, G.A.; Hassan, A.E.; Jiang, Z.M.J. An exploratory study of smart contracts in the Ethereum blockchain platform. Empir. Softw. Eng. 2020, 25, 1864–1904. [Google Scholar] [CrossRef]
- Torres, C.F.; Steichen, M. The art of the scam: Demystifying honeypots in ethereum smart contracts. In Proceedings of the 28th {USENIX} Security Symposium ({USENIX} Security 19), Santa Clara, CA, USA, 14–16 August 2019; pp. 1591–1607. [Google Scholar]
- Babel, K.; Daian, P.; Kelkar, M.; Juels, A. Clockwork Finance: Automated Analysis of Economic Security in Smart Contracts. arXiv 2021, arXiv:2109.04347. [Google Scholar]
- Caldarelli, G.; Ellul, J. The Blockchain Oracle Problem in Decentralized Finance—A Multivocal Approach. Appl. Sci. 2021, 11, 7572. [Google Scholar] [CrossRef]
- Daian, P.; Goldfeder, S.; Kell, T.; Li, Y.; Zhao, X.; Bentov, I.; Breidenbach, L.; Juels, A. Flash boys 2.0: Frontrunning in decentralized exchanges, miner extractable value, and consensus instability. In Proceedings of the 2020 IEEE Symposium on Security and Privacy (SP) IEEE, San Francisco, CA, USA, 18–21 May 2020; pp. 910–927. [Google Scholar]
- Eskandari, S.; Salehi, M.; Gu, W.C.; Clark, J. SoK: Oracles from the Ground Truth to Market Manipulation. arXiv 2021, arXiv:2106.00667. [Google Scholar]
- Zhou, L.; Qin, K.; Torres, C.F.; Le, D.V.; Gervais, A. High-frequency trading on decentralized on-chain exchanges. In Proceedings of the 2021 IEEE Symposium on Security and Privacy (SP) IEEE, San Francisco, CA, USA, 24–27 May 2021; pp. 428–445. [Google Scholar]
- Chen, W.; Guo, X.; Chen, Z.; Zheng, Z.; Lu, Y. Phishing Scam Detection on Ethereum: Towards Financial Security for Blockchain Ecosystem. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI-20, International Joint Conferences on Artificial Intelligence Organization, Special Track on AI in FinTech, Yokohama, Japan, 11–17 July 2020; Bessiere, C., Ed.; pp. 4506–4512. [Google Scholar]
- Wu, J.; Yuan, Q.; Lin, D.; You, W.; Chen, W.; Chen, C.; Zheng, Z. Who Are the Phishers? Phishing Scam Detection on Ethereum via Network Embedding. IEEE Trans. Syst. Man Cybern. Syst. 2020, 52, 1156–1166. [Google Scholar] [CrossRef]
- Xia, P.; Wang, H.; Luo, X.; Wu, L.; Zhou, Y.; Bai, G.; Xu, G.; Huang, G.; Liu, X. Don’t Fish in Troubled Waters! Characterizing Coronavirus-themed Cryptocurrency Scams. In Proceedings of the 2020 APWG Symposium on Electronic Crime Research (eCrime), Boston, MA, USA, 16–19 November 2020; pp. 1–14. [Google Scholar] [CrossRef]
- Yuan, Q.; Huang, B.; Zhang, J.; Wu, J.; Zhang, H.; Zhang, X. Detecting Phishing Scams on Ethereum Based on Transaction Records. In Proceedings of the 2020 IEEE International Symposium on Circuits and Systems (ISCAS), Seville, Spain, 12–14 October 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Bartoletti, M.; Carta, S.; Cimoli, T.; Saia, R. Dissecting Ponzi schemes on Ethereum: Identification, analysis, and impact. Future Gener. Comput. Syst. 2020, 102, 259–277. [Google Scholar] [CrossRef]
- Chen, W.; Zheng, Z.; Ngai, E.C.H.; Zheng, P.; Zhou, Y. Exploiting Blockchain Data to Detect Smart Ponzi Schemes on Ethereum. IEEE Access 2019, 7, 37575–37586. [Google Scholar] [CrossRef]
- Liebau, D.; Schueffel, P. Crypto-Currencies and Icos: Are They Scams? An Empirical Study; Elsevier: Amsterdam, The Netherlands, 2019. [Google Scholar]
- Badawi, E.; Jourdan, G.V.; Bochmann, G.; Onut, I.V. An Automatic Detection and Analysis of the Bitcoin Generator Scam. In Proceedings of the 2020 IEEE European Symposium on Security and Privacy Workshops (EuroS PW), Genoa, Italy, 7–11 September 2020; pp. 407–416. [Google Scholar] [CrossRef]
- Bian, L.; Zhang, L.; Zhao, K.; Wang, H.; Gong, S. Image-Based Scam Detection Method Using an Attention Capsule Network. IEEE Access 2021, 9, 33654–33665. [Google Scholar] [CrossRef]
- Sureshbhai, P.N.; Bhattacharya, P.; Tanwar, S. KaRuNa: A Blockchain-Based Sentiment Analysis Framework for Fraud Cryptocurrency Schemes. In Proceedings of the 2020 IEEE International Conference on Communications Workshops (ICC Workshops), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Dannen, C. Introducing Ethereum and Solidity; Springer: Berlin, Germany, 2017; Volume 318. [Google Scholar]
- Puljiz, M.; Begušic, S.; Kostanjcar, Z. Market microstructure and order book dynamics in cryptocurrency exchanges. In Proceedings of the Crypto Valley Conference on Blockchain Technology, Rotkreuz, Switzerland, 24–26 June 2019. [Google Scholar]
- Warren, W.; Bandeali, A. 0x: An Open Protocol for Decentralized Exchange on the Ethereum Blockchain. 2017, pp. 4–18. Available online: https://github.com/0xProject/whitepaper (accessed on 15 February 2022).
- Adams, H.; Zinsmeister, N.; Robinson, D. Uniswap v2 Core Whitepaper. Retrieved Oct. 2020, 12, 36. [Google Scholar]
- Angeris, G.; Kao, H.T.; Chiang, R.; Noyes, C.; Chitra, T. An analysis of Uniswap markets. arXiv 2019, arXiv:1911.03380. [Google Scholar] [CrossRef]
- Aigner, A.A.; Dhaliwal, G. UNISWAP: Impermanent Loss and Risk Profile of a Liquidity Provider. arXiv 2021, arXiv:2106.14404. [Google Scholar] [CrossRef]
- Van Vliet, B. An alternative model of Metcalfe’s Law for valuing Bitcoin. Econ. Lett. 2018, 165, 70–72. [Google Scholar] [CrossRef]
- Friedman, J. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2000, 29, 1189–1232. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; ACM: New York, NY, USA, 2016. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. 2017. Available online: http://xxx.lanl.gov/abs/1706.03762 (accessed on 15 February 2022).
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. 2019. Available online: http://xxx.lanl.gov/abs/1810.04805 (accessed on 15 February 2022).
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. 2019. Available online: http://xxx.lanl.gov/abs/1907.11692 (accessed on 15 February 2022).
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. 2021. Available online: http://xxx.lanl.gov/abs/2010.11929 (accessed on 15 February 2022).
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A next-generation hyperparameter optimization framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2623–2631. [Google Scholar]
- Lundberg, S.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. 2017. Available online: http://xxx.lanl.gov/abs/1705.07874 (accessed on 15 February 2022).











| Requirements | Type | Signature |
|---|---|---|
| Required | Method | |
| Event | ||
| Optional | Method | |
| (a) XGBoost metrics. | ||
|---|---|---|
| XGBoost | Mean | Std |
| Accuracy | 0.9936 | 0.0029 |
| Recall | 0.9540 | 0.0297 |
| Precision | 0.9838 | 0.0056 |
| F1 score | 0.9684 | 0.0151 |
| (b) FT-Transformer metrics. | ||
| FT-Transformer | Mean | Std |
| Accuracy | 0.9890 | 0.0036 |
| Recall | 0.9180 | 0.0363 |
| Precision | 0.9752 | 0.0109 |
| F1 score | 0.9454 | 0.0187 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mazorra, B.; Adan, V.; Daza, V. Do Not Rug on Me: Leveraging Machine Learning Techniques for Automated Scam Detection. Mathematics 2022, 10, 949. https://doi.org/10.3390/math10060949
Mazorra B, Adan V, Daza V. Do Not Rug on Me: Leveraging Machine Learning Techniques for Automated Scam Detection. Mathematics. 2022; 10(6):949. https://doi.org/10.3390/math10060949
Chicago/Turabian StyleMazorra, Bruno, Victor Adan, and Vanesa Daza. 2022. "Do Not Rug on Me: Leveraging Machine Learning Techniques for Automated Scam Detection" Mathematics 10, no. 6: 949. https://doi.org/10.3390/math10060949