
aSGD: Stochastic Gradient Descent with Adaptive Batch Size for Every Parameter


Abstract
:1. Introduction
2. Materials and Methods
2.1. Gradient Descent
| Algorithm 1: Stochastic gradient descent |
 |
2.2. The Role of Samples in Parameter Updating
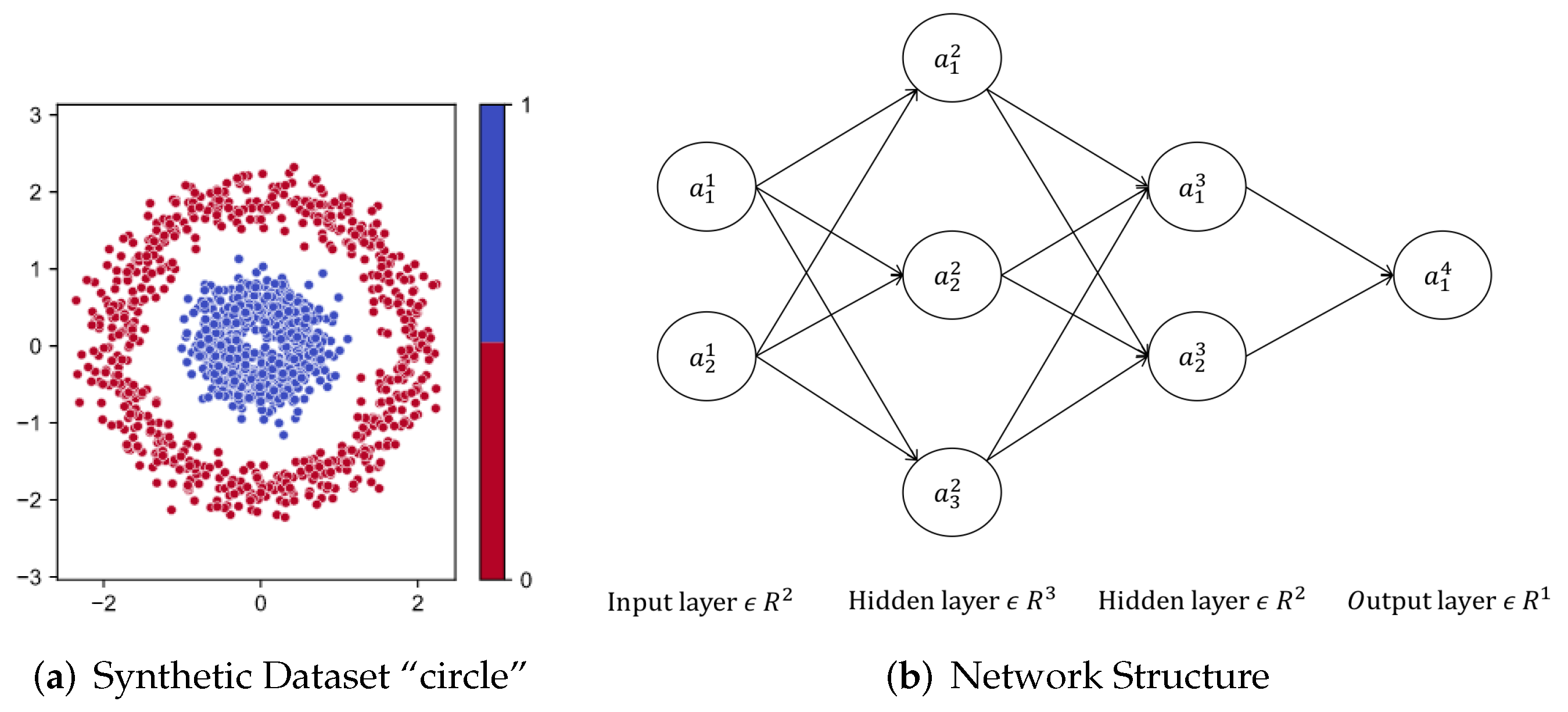
2.2.1. Notations
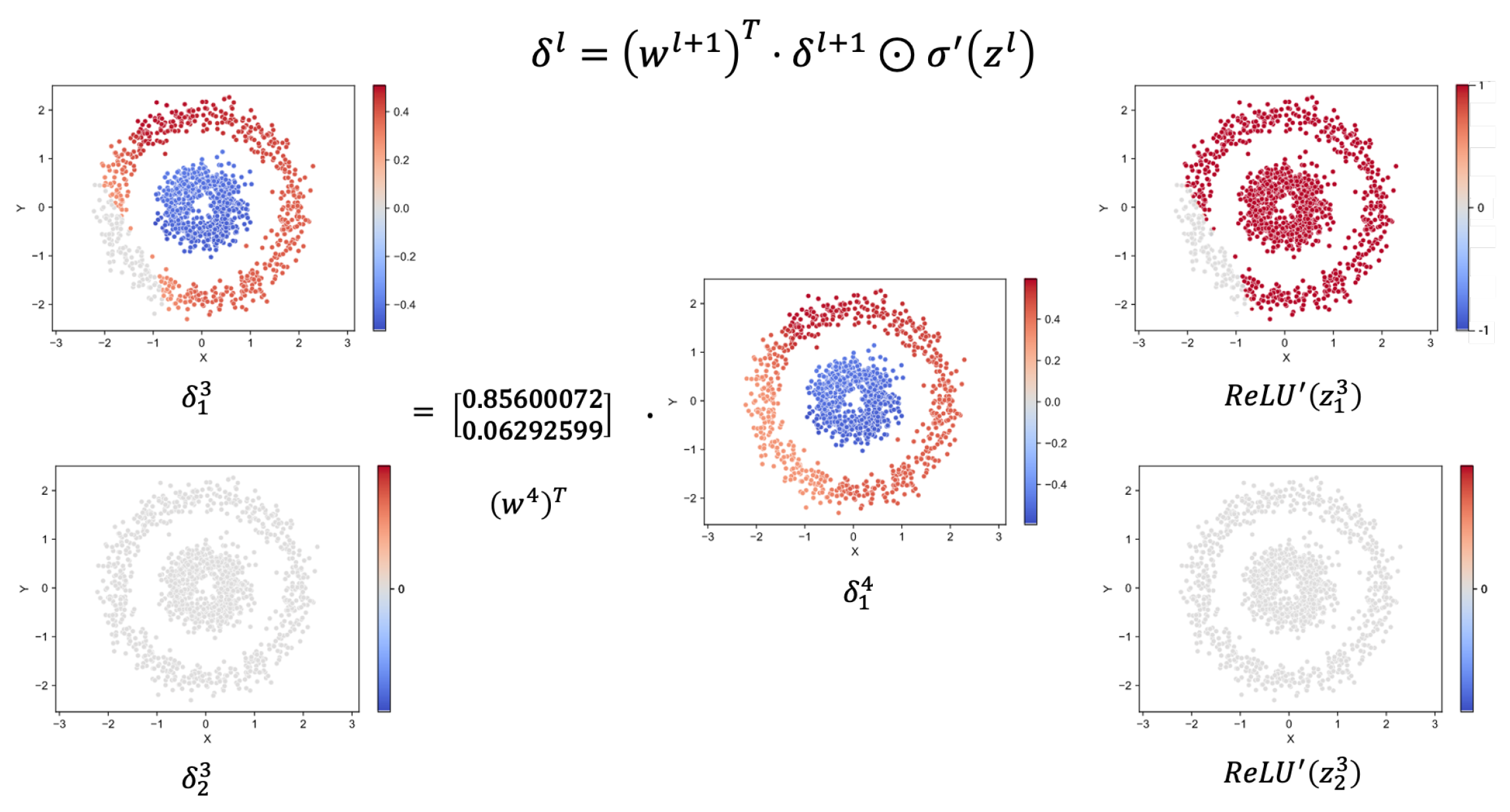
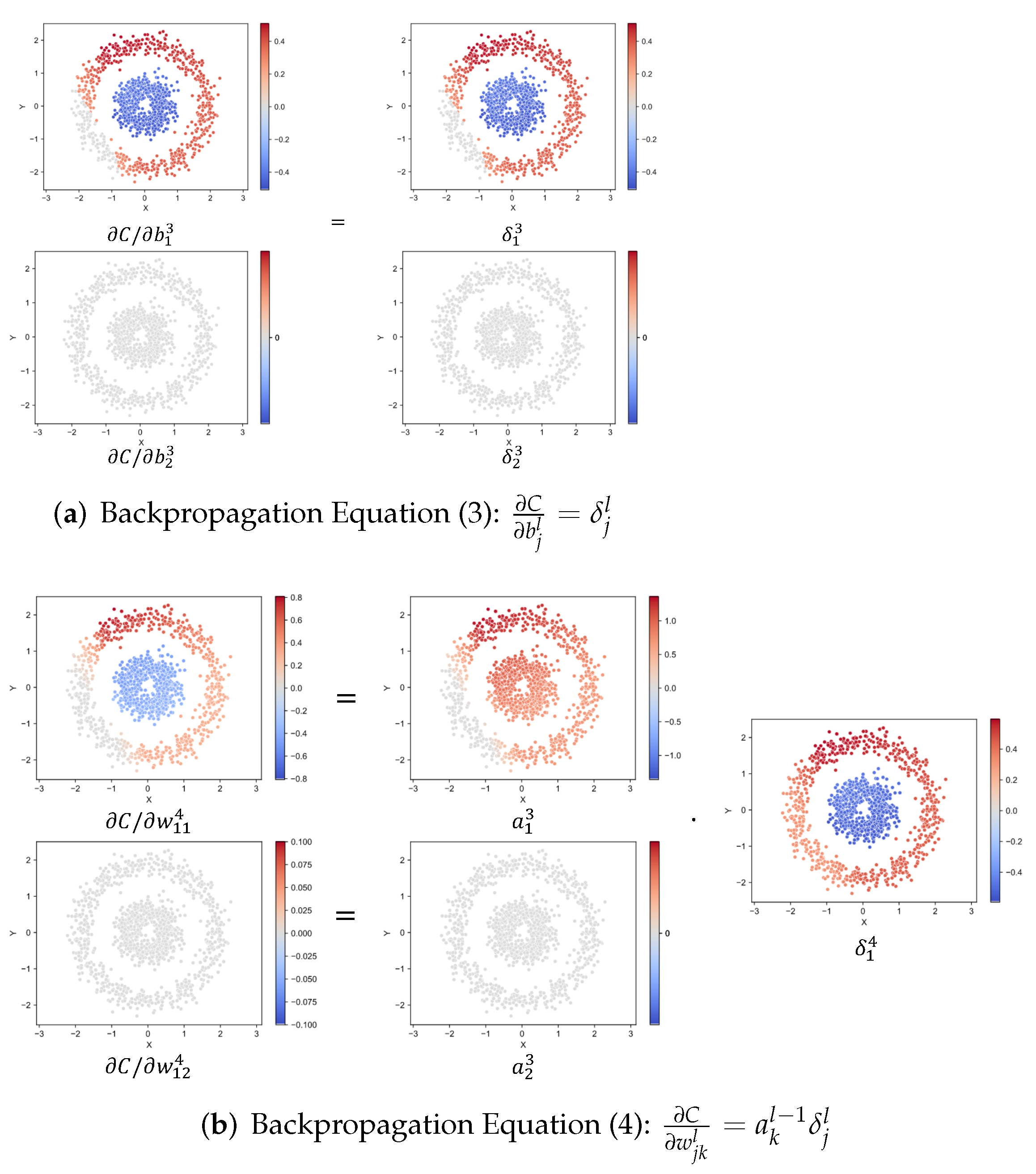
2.2.2. Back Propagation Visualization
2.2.3. Dummy Node
2.3. Sample-Based Adaptive Batch Size Gradient Descent
| Algorithm 2: Sample-based adaptive batch size gradient descent |
 |
3. Experiments
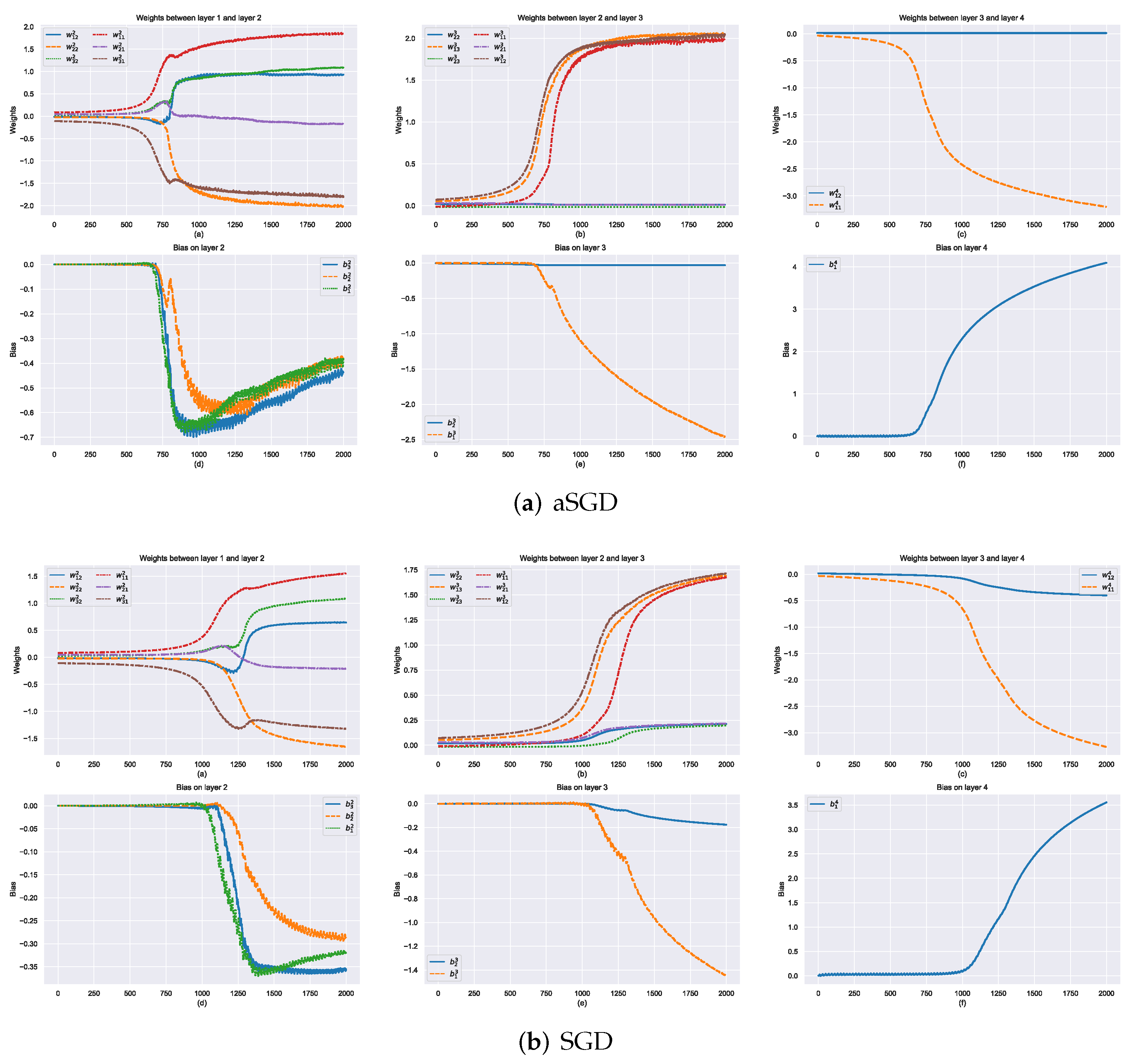
3.1. Properties of aSGD
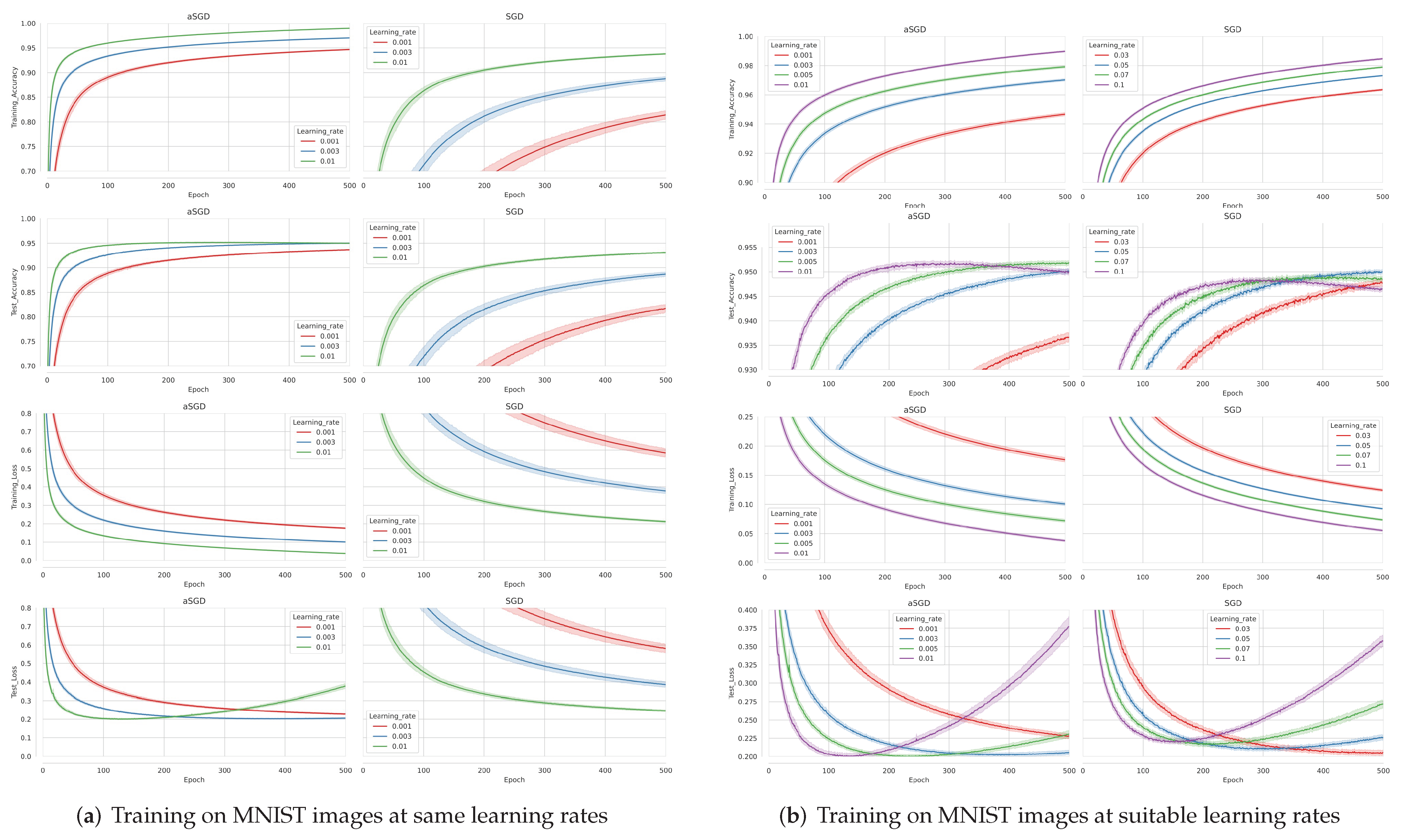
3.1.1. Accelerating Training Process
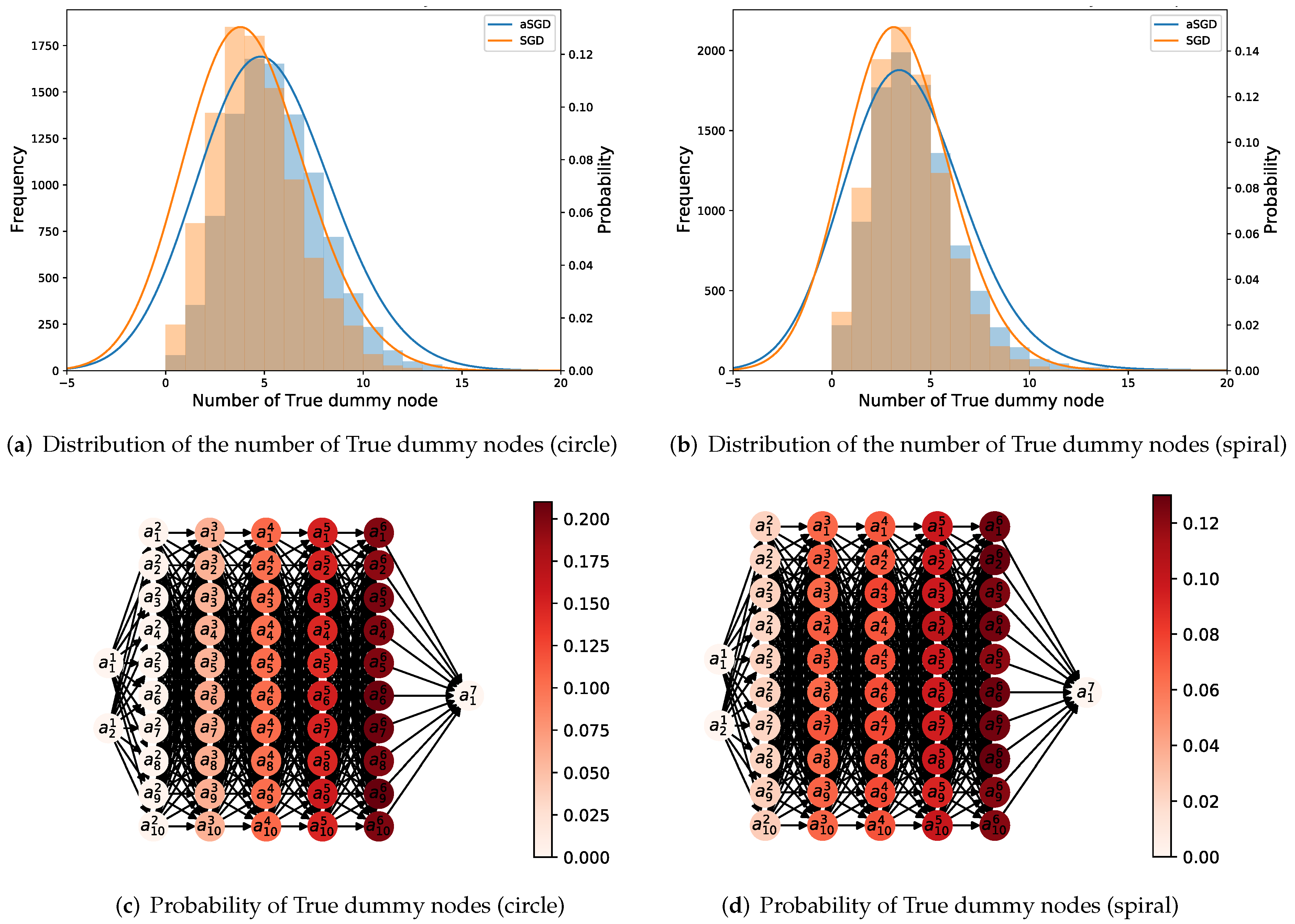
3.1.2. Increasing the Probability of True Dummy Nodes
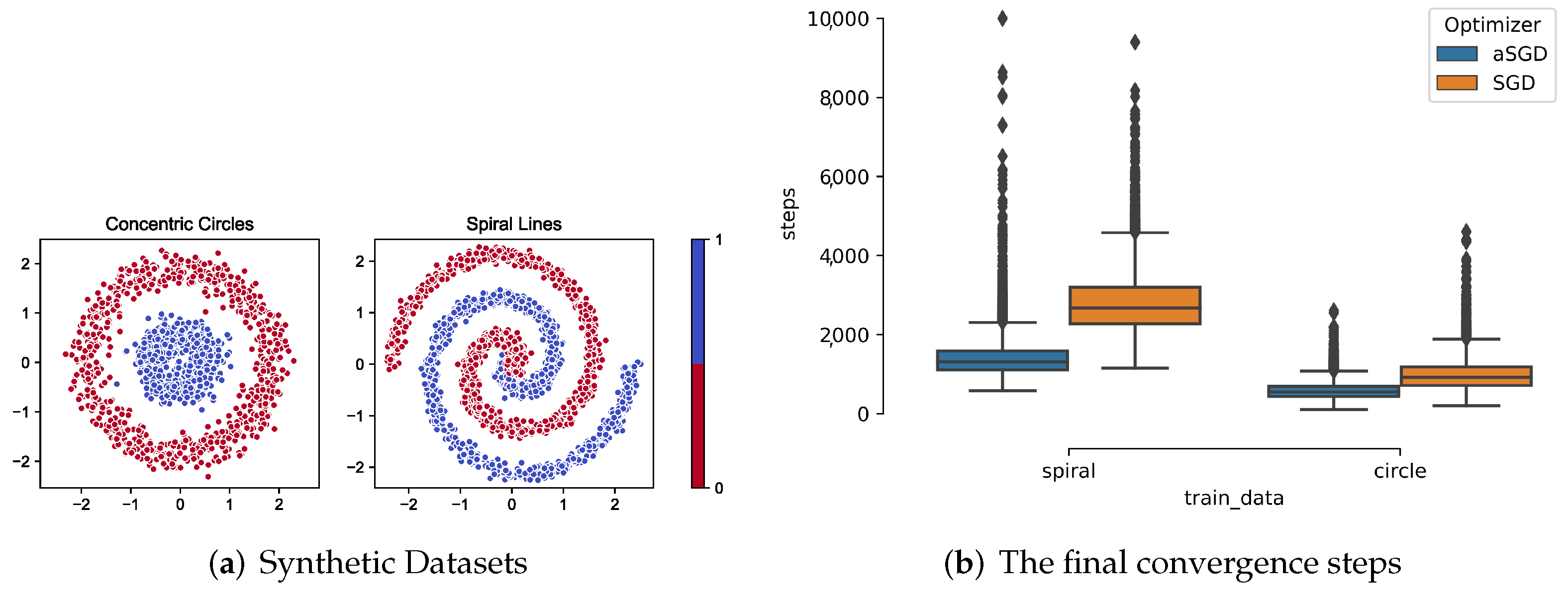
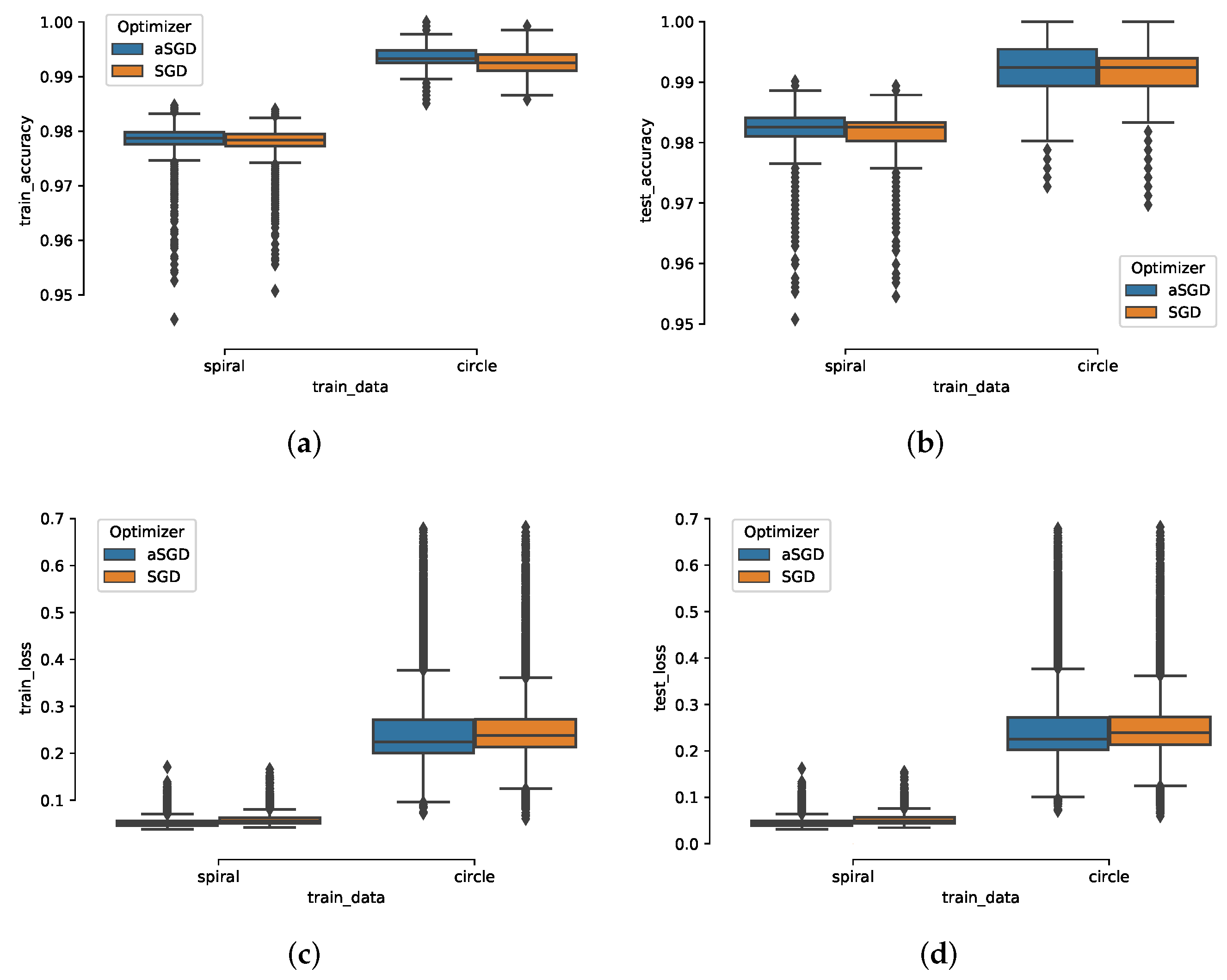
3.2. Synthetic Datasets
3.3. MNIST Handwritten Digit Dataset
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ciregan, D.; Meier, U.; Schmidhuber, J. Multi-column deep neural networks for image classification. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE: Manhattan, New York, NY, USA, 2012; pp. 3642–3649. [Google Scholar]
- Dahl, G.E.; Yu, D.; Deng, L.; Acero, A. Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition. IEEE Trans. Audio Speech Lang. Process. 2011, 20, 30–42. [Google Scholar] [CrossRef] [Green Version]
- Fakoor, R.; Ladhak, F.; Nazi, A.; Huber, M. Using deep learning to enhance cancer diagnosis and classification. In Proceedings of the International Conference on Machine Learning; ACM: New York, NY, USA, 2013; Volume 28, pp. 3937–3949. [Google Scholar]
- Munir, K.; Elahi, H.; Ayub, A.; Frezza, F.; Rizzi, A. Cancer diagnosis using deep learning: A bibliographic review. Cancers 2019, 11, 1235. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Devi, S.R.; Arulmozhivarman, P.; Venkatesh, C.; Agarwal, P. Performance comparison of artificial neural network models for daily rainfall prediction. Int. J. Autom. Comput. 2016, 13, 417–427. [Google Scholar] [CrossRef]
- Hashim, F.; Daud, N.N.; Ahmad, K.; Adnan, J.; Rizman, Z. Prediction of rainfall based on weather parameter using artificial neural network. J. Fundam. Appl. Sci. 2017, 9, 493–502. [Google Scholar] [CrossRef] [Green Version]
- Chattopadhyay, S.; Chattopadhyay, G. Conjugate gradient descent learned ANN for Indian summer monsoon rainfall and efficiency assessment through Shannon-Fano coding. J. Atmos. Sol.-Terr. Phys. 2018, 179, 202–205. [Google Scholar] [CrossRef]
- Bojarski, M.; Del Testa, D.; Dworakowski, D.; Firner, B.; Flepp, B.; Goyal, P.; Jackel, L.D.; Monfort, M.; Muller, U.; Zhang, J.; et al. End to end learning for self-driving cars. arXiv 2016, arXiv:1604.07316. [Google Scholar]
- Rao, Q.; Frtunikj, J. Deep learning for self-driving cars: Chances and challenges. In Proceedings of the 1st International Workshop on Software Engineering for AI in Autonomous Systems, Gothenburg, Sweden, 28 May 2018; pp. 35–38. [Google Scholar]
- Han, J.; Moraga, C. The influence of the sigmoid function parameters on the speed of backpropagation learning. In International Workshop on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 1995; pp. 195–201. [Google Scholar]
- Agarap, A.F. Deep learning using rectified linear units (relu). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Nwankpa, C.; Ijomah, W.; Gachagan, A.; Marshall, S. Activation functions: Comparison of trends in practice and research for deep learning. arXiv 2018, arXiv:1811.03378. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning internal representations by error propagation. In Report, California Univ San Diego La Jolla Inst for Cognitive Science; MIT Press: Cambridge, MA, USA, 1985. [Google Scholar]
- Geyer, C.J. Markov Chain Monte Carlo Maximum Likelihood; Interface Foundation of North America: Fairfax Sta, VA, USA, 1991. [Google Scholar]
- Bäck, T.; Schwefel, H.P. An overview of evolutionary algorithms for parameter optimization. Evol. Comput. 1993, 1, 1–23. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Dauphin, Y.; Pascanu, R.; Gulcehre, C.; Cho, K.; Ganguli, S.; Bengio, Y. Identifying and attacking the saddle point problem in high-dimensional non-convex optimization. arXiv 2014, arXiv:1406.2572. [Google Scholar]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the importance of initialization and momentum in deep learning. In International Conference on Machine Learning; PMLR: Atlanta, GA, USA, 2013; pp. 1139–1147. [Google Scholar]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Zeiler, M.D. Adadelta: An adaptive learning rate method. arXiv 2012, arXiv:1212.5701. [Google Scholar]
- Tieleman, T.; Hinton, G. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. Coursera Neural Netw. Mach. Learn. 2012, 4, 26–31. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Bergstra, J.S.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for hyper-parameter optimization. In Advances in Neural Information Processing Systems; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2011; pp. 2546–2554. [Google Scholar]
- Smith, S.L.; Kindermans, P.J.; Ying, C.; Le, Q.V. Don’t decay the learning rate, increase the batch size. arXiv 2017, arXiv:1711.00489. [Google Scholar]
- Radiuk, P.M. Impact of training set batch size on the performance of convolutional neural networks for diverse datasets. Inf. Technol. Manag. Sci. 2017, 20, 20–24. [Google Scholar] [CrossRef]
- Bengio, Y.; Senécal, J.S. Quick Training of Probabilistic Neural Nets by Importance Sampling; AISTATS: Key West, FL, USA, 2003; pp. 1–9. [Google Scholar]
- Zhao, P.; Zhang, T. Accelerating minibatch stochastic gradient descent using stratified sampling. arXiv 2014, arXiv:1405.3080. [Google Scholar]
- Yang, N.; Tang, H.; Yue, J.; Yang, X.; Xu, Z. Accelerating the Training Process of Convolutional Neural Networks for Image Classification by Dropping Training Samples Out. IEEE Access 2020, 8, 142393–142403. [Google Scholar] [CrossRef]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 3–15 May 2010; pp. 249–256. [Google Scholar]
- Canziani, A.; Paszke, A.; Culurciello, E. An analysis of deep neural network models for practical applications. arXiv 2016, arXiv:1605.07678. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines; ICML: Haifa, Israel, 2010. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, UK, 2016; Volume 1. [Google Scholar]
- Ji Chao, T.H. Visualization and Coding of Original Feature Space Partitioning Process Based on Fully Connected Neural Network. J. Signal Process. 2020, 36, 486–494. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Machine learning basics. Deep Learn. 2016, 1, 98–164. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Yao, Y.; Rosasco, L.; Caponnetto, A. On early stopping in gradient descent learning. Constr. Approx. 2007, 26, 289–315. [Google Scholar] [CrossRef]
- Robbins, H.; Monro, S. A stochastic approximation method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Learning Rate | Train Accuracy | Train Loss | Test Accuracy | Test Loss |
|---|---|---|---|---|---|
| aSGD | 0.001 | 0.9464 ± 0.0055 | 0.1774 ± 0.0194 | 0.9372 ± 0.0044 | 0.2253 ± 0.0172 |
| SGD | 0.001 | 0.8137 ± 0.0438 | 0.5859 ± 0.1174 | 0.8186 ± 0.0430 | 0.5783 ± 0.1189 |
| aSGD | 0.003 | 0.9645 ± 0.0033 | 0.1189 ± 0.0117 | 0.9488 ± 0.0027 | 0.1965 ± 0.0126 |
| SGD | 0.003 | 0.8874 ± 0.0234 | 0.3787 ± 0.0774 | 0.8876 ± 0.0231 | 0.3834 ± 0.0778 |
| aSGD | 0.01 | 0.9652 ± 0.0039 | 0.1168 ± 0.0135 | 0.9498 ± 0.0034 | 0.1922 ± 0.0164 |
| SGD | 0.01 | 0.9376 ± 0.0063 | 0.2131 ± 0.0252 | 0.9317 ± 0.0062 | 0.2423 ± 0.0257 |
| Method | Learning Rate | Train Accuracy | Train Loss | Test Accuracy | Test Loss |
|---|---|---|---|---|---|
| 0.001 | 0.9464 ± 0.0055 | 0.1774 ± 0.0194 | 0.9372 ± 0.0044 | 0.2253 ± 0.0172 | |
| aSGD | 0.003 | 0.9645 ± 0.0033 | 0.1189 ± 0.0117 | 0.9488 ± 0.0027 | 0.1965 ± 0.0126 |
| 0.005 | 0.9652 ± 0.0039 | 0.1168 ± 0.0135 | 0.9498 ± 0.0034 | 0.1922 ± 0.0164 | |
| 0.01 | 0.9662 ± 0.0032 | 0.1135 ± 0.0102 | 0.9493 ± 0.0029 | 0.1937 ± 0.0112 | |
| 0.01 | 0.9376 ± 0.0063 | 0.2131 ± 0.0252 | 0.9317 ± 0.0062 | 0.2423 ± 0.0257 | |
| 0.03 | 0.9615 ± 0.0036 | 0.1311 ± 0.0129 | 0.9484 ± 0.0034 | 0.1984 ± 0.0176 | |
| SGD | 0.05 | 0.9625 ± 0.0033 | 0.1276 ± 0.0111 | 0.9484 ± 0.0026 | 0.2023 ± 0.0141 |
| 0.07 | 0.9611 ± 0.0043 | 0.1326 ± 0.0145 | 0.9474 ± 0.0036 | 0.2074 ± 0.0164 | |
| 0.1 | 0.9599 ± 0.0039 | 0.1374 ± 0.0137 | 0.9465 ± 0.0029 | 0.2099 ± 0.0126 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, H.; Yang, N.; Tang, H.; Yang, X. aSGD: Stochastic Gradient Descent with Adaptive Batch Size for Every Parameter. Mathematics 2022, 10, 863. https://doi.org/10.3390/math10060863
Shi H, Yang N, Tang H, Yang X. aSGD: Stochastic Gradient Descent with Adaptive Batch Size for Every Parameter. Mathematics. 2022; 10(6):863. https://doi.org/10.3390/math10060863
Chicago/Turabian StyleShi, Haoze, Naisen Yang, Hong Tang, and Xin Yang. 2022. "aSGD: Stochastic Gradient Descent with Adaptive Batch Size for Every Parameter" Mathematics 10, no. 6: 863. https://doi.org/10.3390/math10060863