1. Introduction
When studying several characteristics from a group of experimental units, one of the main concerns is the independence of the obtained data, since most of the usual techniques assume independence between the observations. However, this assumption may be difficult to maintain when observing different variables of a specific subject through time. In this situation, at least two kind of covariance structures may arise, one between the different types of observations taken on the same subject at every temporal point and another one between the values of a specific type of characteristic observed through time [
1,
2]. This may be a complex problem even when only one experimental unit is observed. Considering a group of units in the study means the addition of another layer to the structure, a problem that will be addressed in the present work.
The origin was the study of small children’s capacity of solving mathematical problems and the evolution of this skill in students through the years they spent in primary school. This variable is very often related with some others that could be observed as well in the same students in order to check the kind of relationship or estimate the model linking the variables. However, obtaining the data has certain costs, especially those coming from the time that teachers and administrative personal will spend in designing and performing the tests, correction, the translation of the outcomes to a computer program, and analyzing the results. It will be very difficult to have these tests performed very often, or even once a year. For this reason, a design plan stating the conditions under which these observations should be taken is quite convenient.
In this work, such designs will be studied for a general case in which some variables will be observed on a cohort of subjects at different time periods, trying to decide the most informative time-points where observations/tests should be collected using optimal experimental design techniques.
In
Section 2, the main concepts and latest results of the optimal design of experiments theory applied to models describing several response variables for one subject will be outlined, and new analytical results for a general case with N subjects and k variables of interest will be obtained. In
Section 3, the theory will be applied to the joint study of the variables ’Ability in problem solving’ (PS) and ’Mental representation capacity’ (MR) of the primary school students [
3], and the results will be commented on in
Section 4. Finally, the main conclusions and further applications will be addressed in
Section 5.
2. Background and New Results
Let
x denote the experimental conditions, with possible values in the experimental domain
Χ. An exact design
is a collection of points
where samples are to be taken. For
n observations
of the one-response linear model
, the system can be expressed in matrix notation as
where
is the
m-parameter vector,
the vector of error terms, and
the design matrix, with
and the
linearly independent in Χ. When there exists a correlation structure
between the samples, the estimator of the parameters for normal-distributed errors is
. One of the most important tools in the optimal design of experiments framework is the information matrix of the design
;
which is proportional to the inverse of the variance of
Usually the objective of practitioners is to find
optimal designs that produce precise estimators of the model parameters, thus minimizing
or equivalently maximizing
. Different
criterion functions may be considered, usually convex functions of
. The most popular criterion is
-optimality, which pays attention to the determinant of
, and that will be the criterion used in this work. When a design is
-optimal, it minimizes the volume of the confidence ellipsoid of the estimators of the model parameters. For non-linear models, the information matrix will depend on the unknown parameters. In this case, nominal values are needed for them, and
locally optimal designs will be obtained. Reference books on the topic are, for instance, [
4,
5,
6]. To compute optimal designs, from the analytical expression of the model the linearized version is obtained by computing the derivatives with respect to the parameters. When it is not possible to obtain the analytical expression, alternative methods for computing the derivatives can be employed [
7].
When the observations are correlated, the size of the design (number of samples to be taken) should be decided in advance. Furthermore, for an evolution study, the design variable is time, and thus it will be assumed that
for all
,
because there is no reason to take several observations on the same subject at the same time. When different responses are of interest (
multiresponse models), the usual assumption was to consider that the
k responses observed on the same experimental unit under the conditions
x,
were correlated, but the measures taken at different points,
and
, were independent. However, when the design variable is time, this last assumption is no longer valid [
2], and two types of correlation should be considered: a
static or
intra covariance structure between different responses observed at the same time and a
longitudinal or
inter correlation between the same type of response obtained at different times.
Thus, let us assume that we observe
characteristics of one subject at different times, and for each time
let
denote the covariance matrix of the
sample , that is,
. It is usual to assume that the relation between the different variables is similar for every
; thus, following that, a constant covariance
will be considered (intra correlation). On the other hand, the covariance between the same type of observations taken at different points will be assumed to be dependent only on the distance between points, that is,
where
is a known stationary covariance kernel (different proposals of these functions can be found, for instance, in [
8,
9]; thus, the longitudinal covariance will be the same for the
different responses,
. The assumption of a known covariance function may be a controversial issue; however, it becomes more acceptable when restricting to a local consideration of the model, thus finally obtaining locally optimal designs.
In previous studies [
1,
2], the double (inter and intra) covariance structure has been taken into account for measures over a single experimental unit through time. Now, a multisubject scenario will be considered, observing
subjects at different times
, (design
). Balanced designs will be considered, that is, for each
in
several variables,
will be observed for every subject; for unbalanced designs, a procedure similar to the one employed in Example 2 of [
1] can the employed. The aim will be to select the most informative design for the models describing the evolution of the variables.
The Kronecker product of the different covariance structures can be used to express the covariance matrix of the
observations. Throughout this work, a non-trivial
(but constant for every variable
) will be assumed; therefore, for each subject it will be more convenient to use the order
, getting the covariance matrix
. Furthermore, it is quite usual to assume as well that the
subjects are independent, thus the covariance matrix of the
observations can be expressed as
where
is the identity matrix of order
. That is,
is the block-diagonal (
BD) matrix
.
In particular, and
If both and are square matrices, then .
with , , , , , and having the right dimensions for the product of matrices.
The aim is to obtain
D-optimal designs for fitting the models of the
variables involved, assuming
-parameter linear models with the same structure. The setup is somehow similar to that in [
11], where the double covariance structure was applied to a compositional-response model. That case was roughly equivalent to a one-subject model, and the samples of the same variable were assumed independent, while here a non-trivial correlation is considered between the different observations of the same variable, and multiple subjects are observed. Two scenarios will be considered:
Model I.—Different models of the variables for each subject (
models):
with
,
.
Model II.—The model of each variable is valid for all the subjects (
models):
with
,
.
In the following, analytical results will be obtained for the two scenarios, beginning with Model I:
Theorem 1. The -optimal designs for the individual models of each variable in each subject are also -optimal for Model I, given by Equation (4).
Proof. If
observations are taken for each variable and subject at times
, the model can be expressed as (1) with
,
, and
), and the design matrix is
where
is the design matrix for each individual model. Then, the information matrix (2) is given by
where
is the information matrix of the model of each variable for each subject. Thus
, which finishes the proof since
does not depend on the design. □
Theorem 2. The parameters of the individual models (4) can be estimated independently and do not depend on . However, the variance of the set of the parameter estimators for each subject does depend on because .
Proof. The estimator of the parameter vector is:
where
is such that
for all
,
, and
. □
Let us now pay attention to Model II given in (5). In this case the parameter vector is
, with
. There are only
x
parameters since the model of each variable
is the same for all the subjects. For this reason, it will be convenient to place together all the observations of each variable, that is, consider the following observations vector:
The following results can be derived, the first one similar to that of Theorem 1, but now consider the second model:
Theorem 3. The -optimal designs for the individual models of each variable in each subject are also -optimal for Model II, given by Equation (5).
Proof. The design matrix
corresponding to the ordering given by
will be
with
, where
denotes a column vector of ‘1′s of length
.
Let
be the
permutation matrix that turns
into
, that is,
. Since
permutes in fact the vectors of observations
, it can be expressed as
, with
the
permutation matrix expressed by vector
,
meaning that for every row
of
(
), we have
and
if
.
Now the covariance matrix of
is
and the information matrix can be computed as
With the last expression obtained using that . Then, . □
Theorem 4. Regarding Model II given by (5), the estimation of the parameters of the -th response is the average of the corresponding estimations for each subject and does not depend on (but their covariance matrix, which is proportional to the inverse of the information matrix, does depend on ).
Proof. The estimator of the parameter vector is
where the last equality comes from
Let us have a close look at this expression. It means that
which, taking into account that
is the estimation of the parameters of the model of the variable
for the
-th subject, finishes the proof. □
3. Optimal Designs for Evolution of MR and PS
There is a general agreement that problem solving should be the main objective in school mathematics instruction [
12,
13]. It seems clear that this ability may be related with the capability of understanding the semantic structure of the mathematical problems statements and increases with age. Children could be able to solve real world problems at early age [
14], but the acquisition of academic language comes later, after they dominate everyday language [
15]. The relation between problem solving and linguistic comprehension is explored in [
16]. However, apart from understanding the statement of the problem, the students must be able to construct a mental representation of it [
17,
18,
19].
All these facts are discussed in [
3], where a test on additive problems using expressions close to practical everyday language is proposed. That work studied the influence of mental representation (
) in the ability of the resolution of additive problems (PS) for children from
to
years old and found a model relating the two variables. Once this relationship has been stablished, the next step should be to find a convenient design plan for a follow-up study of the evolution of both characteristics. To this end, the results of
Section 2 will be employed for obtaining an optimal design plan for the observation of these two variables through time. The design points
can denote any convenient temporal unit (school level, semester, etc.).
A constant variance
will be assumed for the observations of the two variables. Should they have different variances
and
, the covariance structure would depend (by a constant term) on the ratio
that has no influence on the computation of the optimal designs (see the discussion at the end of Section 2.1 of [
2], and in this situation (constant variance), for the easiness of computations,
will be assumed without loss of generality. Assuming constant covariance between
,
for every
may be arguable, mainly because the
variables may refer to quite different characteristics and even use different scales. An alternative that may soften this problem would be using normalized values of the variables. However, the case
of this example is not controversial, since for
k = 2 the intra-covariance matrix
S will have this shape:
with
, an assumed constant for all
. Thus, when observing
and
, the covariance matrix for (the observations taken at) each student will be
and the previous results can be applied. From Theorems 1 to 4, the
-optimal designs can be computed assuming just one variable and one subject. An inter-correlation structure usually employed when the measurements are taken on the same individual is the exponential covariance [
20], decreasing with the increasing distance in time between measurements,
where the parameter
is characteristic of the individual. When there is no reason to think that the parameter may vary very much between individuals, the same characteristic (reference individual) is used for every of them. In this work,
will be assumed, which is a typical choice.
Two types of evolution models will be considered:
Linear regression model: ,
that is, . Since there are parameters, at least two observations are needed
- ○
If
n = 2, it will be convenient to express the design as ξ = {
t, t + d}, where
t is the first observation and
d > 0 the distance between the two samples, with
t + d ≤ tmax, the maximum value for performing the tests. Then, assuming the inter-correlation R given by (7),
and
Thus,
is an increasing function of
, and the optimal design will be the one having the maximum distance
between the observations, therefore taking the samples at the beginning and at the end of the period of study.
- ○
When
, let us consider the design
, with
and
. Now
and
Assuming a minimum distance
between consecutive sample points, the maximum is attained for
, and
. Thus, the first test should be taken at the beginning and the rest at the end, with the minimum possible distance
between these last ones.
Exponential regression model: .
After linearizing, the model can be expressed as
, which depends on the unknown values of the parameters. In this case, the
D-optimal designs will depend as well on these values; thus, they will be in fact locally optimal, that is, good for (or near to) those nominal values used in the computation. It is well known that the optimal designs will not depend on the parameters that ‘appear linearly’ in the model [
21], that is,
in this case, while they will depend on the ‘non-linear parameter’
. Thus, an initial value will be needed just for this last one. Again, the cases of two and three observations will be studied:
- ○
. The determinant of the information matrix is
and it is clear that the values
and
maximizing this determinant will not depend on
.
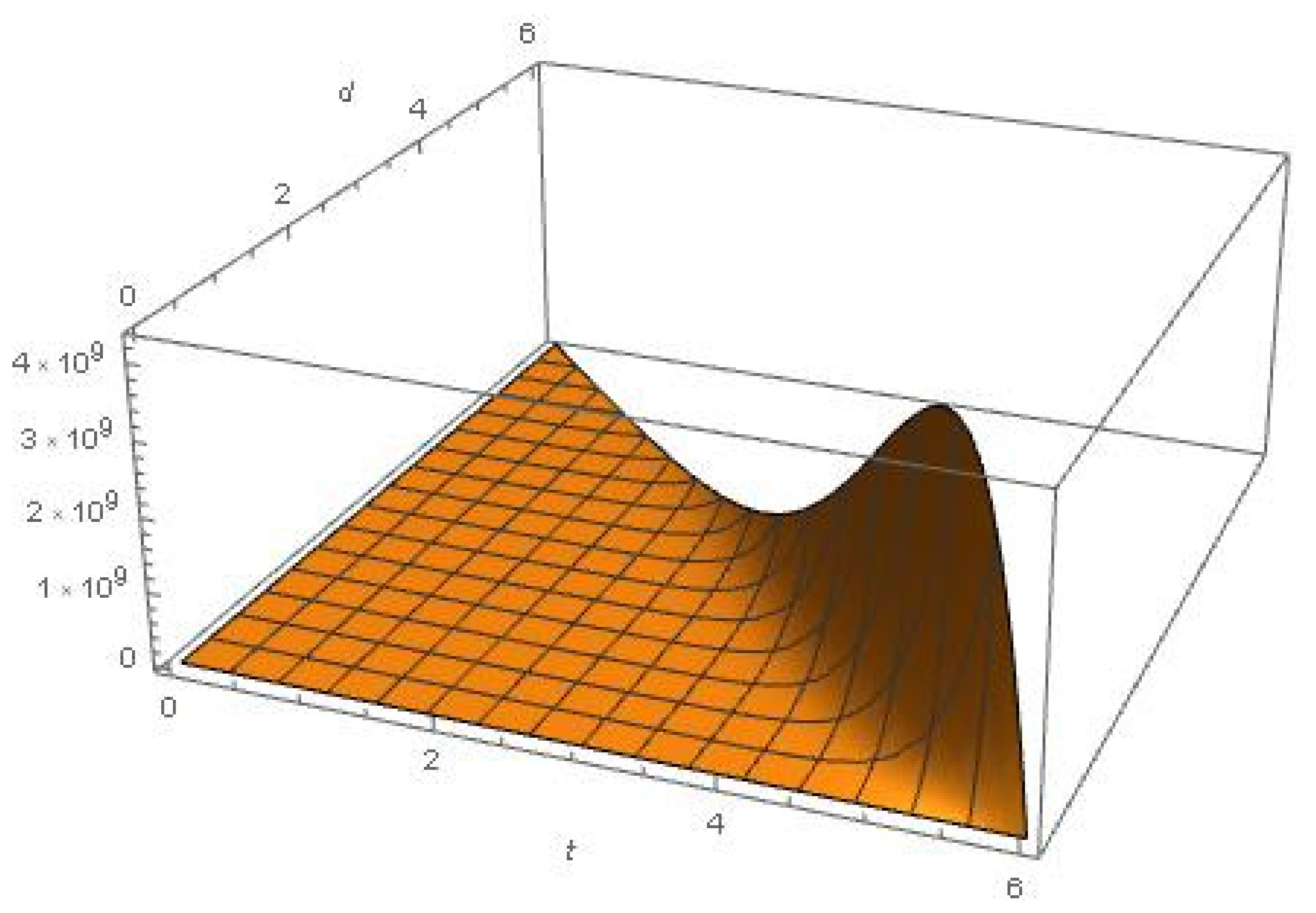
Figure 1 shows the determinant of the information matrix after removing
and using the nominal value
for the non-linear parameter. For primary school levels (
) and assuming a minimum distance
between tests, the recommended design uses
and
, that is, making the tests the last two years.
- ○
. The determinant of
is
and when removing
β02 and assuming
tmax = 6 and
d0 = 1, the maximum for
β10 = 1 is attained when
t = 4,
d1 = 1, and
d2 = 1, that is, testing the students the last three courses.
4. Discussion
In the last few years, there has seen a remarkable increase in the relevance of the design of experiments in social science areas [
22]. Major issues in the education research area must be treated on a sequential multiscale temporal level. Educational policies such as curricula, reduction in class size, programs for students’ support, etc. are developed considering educational theories based on solid experimentation [
23]. In addition, large-scale experiments may be unattainable, and some authors alert about extracting generalized conclusions from experiments in education [
24]. There is a general agreement in trying to “maximize the scientific benefit using the resources available for an investigation” [
25]; thus, the optimal design of experiments becomes a key piece on the research process.
Randomized experiments with multilevel implications have been used by educational researchers in order to determine the effect of some treatment through time. One of the most used techniques in this line is the sequential multiple assignment randomized trials (SMART) [
23,
26,
27]. This approach gives information about the effectiveness of some intervention or treatment through time, but it does not discriminate factor variables [
25,
28]. As an alternative, factorial designs, with the feature of determining the influence of factors, have also been applied for similar purposes [
25,
29]. These factorial designs have been used as well to provide a relation between four different mathematical problem representations and the problem solving abilities of elementary school students from grades 1 to 3 [
30]. Nevertheless, some limitations regarding to the independence of the variables, the quantity of considered factors, or the presence of more than two levels by factor are addressed [
25]. Most of these studies assume independent observations; few consider some kind of relation between samples (for example, the intraclass-correlation between observations within a cluster in [
25,
31], but not complex correlation structures like the ones derived from the consideration of multiresponse models such as the ones studied in this work.
In educational research, observations are rarely independent, as pointed out in [
32]. Mixed-effect regression models cover this and other issues, such as correlated data organized in a multilevel or hierarchical structure, missing data, variability, etc. [
33,
34,
35]. Applications of these models in educational projects can be found in [
32] where the correlation between the results of two tests taken before and after a treatment is studied, controlled for a variable with three levels. The levels correspond to three selected difficult topics to study, and a selection model based on AIC criterion is applied to conclude. In [
36], mixed linear regression analysis is applied to a large database to establish the correlation between the student’s relationship and their academic performance. Finally, ref. [
37] evaluated the impact of sequences of parents’ input on children’s language outcomes. Although all these applications are longitudinal or level studies, they are focused on selecting the best model for prediction, but no one addresses the issue of optimizing data recollection along time.
Despite being less known in the education area, generalized estimating equations (GEEs) are introduced in [
38] as an alternative for the analysis of cross sectional clustered data with repeated measurements along time [
39,
40,
41]. It shows GEEs as a generalization of linear general models and that its performance is similar to multilevel models (random effects or mixed model) and ordinary least squares. However, some limitations have to be considered, for example the impossibility of applying classical selection model techniques based on likelihood estimation, the lack of non-random data, and the amount of missing data. In addition, the number of clusters should be relatively high, and the observations in different clusters must be independent, although within-cluster observations may be correlated, as it is refereed in [
40].
Again, it is necessary to highlight that none of these approaches seem to be fully appropriate to conduct experiments involving multiresponse and multisubject models with repeated observations in time, with potential correlation structures as the ones described in this paper. The novel approach presented here seems the most convenient for studies that could be similar to the one described in the example.
The relation between the variables ’Mental Representation’ and ’Mathematical Problem Resolution’ in primary school students was extensively studied in [
3]. Now, the theory developed in
Section 2 has been applied to that case for finding the best design (times when perform the tests to the students) in order to obtain an insight of the evolution of the two variables.
Assuming a sensible hypothesis about the correlation structure, two scenarios have been considered, one with different models of the variables for each subject and another one assuming the same model of each variable for every subject, obtaining interesting theoretical results especially in the second case. Two types of evolution models have been considered as well in order to stress that the optimal allocation of the tests may depend very much on the assumed model. The best design when assuming the linear regression model is making the tests near the extremes of the evaluation period. However, when the evolution is described by an exponential model, the results may be quite different since the optimal designs are very sensitive to the initial value of the parameters. The widely used exponential inter-correlation has been assumed. The preliminary study in [
3] discovered that the group of the small (first year) students had a great variability, and thus it was not very informative. For this reason, when a design contains any temporal point belonging to the first school year (for instance when assuming a linear trend evolution), it will be convenient to delay these tests so that the analysis interval starts the second year of the primary school period.
A robustness study has been carried out for the exponential evolution model in order to check whether the optimal designs obtained are sensitive to the choice of the nominal value of . It has been found that in fact the optimal designs can vary very much; for instance if , the best designs found vary from the ones that take the extremes of the design interval when or the school years 4 and 6 when to those choosing the last temporal points when . A similar variability of results is obtained for : when , the proposal is to make one test at the beginning of the design interval and the other two at the end, and when assuming , the most convenient school years to perform the tests are 3, 4, and 6.
Optimal designs have been computed for the -optimality criterion, which is the most used, and two popular 2-parameter evolution models have been considered assuming always exponential inter-correlation. However, the procedure can be immediately extended to other optimality criteria, evolution models, and correlation kernels, provided that these can be assumed similar for all the variables.
5. Conclusions
The need to study the problem solving ability of primary school students, its relation with other variables, and the evolution of all of them was the inspiration of this work, from a previous study of [
3]. In order to choose the best temporal points where samples should be taken to maximize the information of the collected data, a general procedure for several variables and subjects has been developed from the point of view of optimal design of experiments theory.
It should be noted that the results obtained in
Section 2 are quite general and could be applied in other type of studies involving several subjects, with a
number of variables of interest. Depending on the cost of every type of measure and the available budget, sometimes it might be convenient to select the variables that will be observed at a specific point instead of sampling all of them. The reason may be to save the cost of those measurements that are not considered so important or informative. Cost constraints could be incorporated into the model in a similar way as described in Chapter 5 of [
42]. For instance, when two types of variables are to be observed, the problem can be stated as follows: two types of measurements
,
can be made for every experimental unit, with costs
and
, respectively. In the general case, every time that a subject is measured entails some cost
. For the total cost there are three possibilities:
Measure , with cost . Total cost: ;
Measure , with cost . Total cost: ;
Measure both and . Now the overall cost is .
Possible scenarios are described by
, with
and
,
in
and
, where
when test
is made at a time
, and
otherwise. The best designs fitting this budget may be non-balanced. In this case, the covariance matrices could be obtained as described in Example 2 of [
1]. Ref. [
42] discusses a procedure for studying this issue, but only for one subject and considering intra-correlation and not inter-correlation between samples, which are assumed independent. When there are more subjects and the two types of correlation are non-trivial, the problem becomes far more complex to deal with.
For this study, it has been assumed that the evolution models were similar in the different variables. Should these models be different, the covariance and information matrices would be much more complex, as would the computation of the optimal designs. The assumptions of equal intracorrelation in all the design points and equal intercorrelation for all the variables are quite sensible. In case that any of them (or both) were not true, the covariance matrices could not be expressed by Kronecker products, and the optimal designs for the global model would not be the same as the ones for the individual models of each variable for each subject; in fact, this global optimal design may be extremely difficult to compute.




{kind=link}
