1. Introduction
Experiments are conducted to explore or optimize physical phenomena. In some applications, such as national defense, medicine, and manufacturing, the physical experiments may be difficult to be conducted due to economic, technical, or ethical limitations. To reduce the experimental cost, mathematical models, which are also called computer models, are developed to mimic, understand, and predict the physical phenomena in many applications [
1,
2,
3]. The computer models are useful and efficient only if they can approximate the physical process well. Oftentimes, the computer models contain a set of calibration parameters, which are physical unobservable variables. The computer models’ fidelity to physical process relies on the unknown values of calibration parameters. Then, physical data and computer model outputs are combined to estimate the calibration parameters such that the computer model matches the physical process. This procedure is referred to as computer model calibration in the literature.
Numerous models have been proposed in the literature for the problem of computer model calibration, such as [
2,
4,
5,
6,
7]. Among them, the Kennedy and O’Hagan model is the most commonly used. The Kennedy and O’Hagan model integrates the physical data and computer model outputs through a Bayesian framework. Any posterior quantity can serve as the point estimate of calibration parameter depending on the loss function specified. In practice, the most commonly used predictor of the physical process is a calibrated computer model, see [
8,
9]. Since the nonlinear effects from the discrepancy function can be hard to interpret and also may open up the possibility of overfitting with limited physical observations. Ref. [
10] pointed out that an interpretable calibration parameter should allow the computer model to predict the real physical phenomena well even without the discrepancy function.
How to perform the experiments efficiently to tune the calibration parameters accurately under some metrics plays an important role. Although we are not the first to look into the problem of design for calibration, it has not received enough attention. Based on the Kennedy and O’Hagan model, some designs have been proposed in the literature. Ref. [
11] employed the Kullback–Liebler (KL) divergence criterion as a function of the computer model inputs and obtained the estimate of calibration parameters by minimizing this criterion. Ref. [
12] focused on the problem of functional calibration by generating sequential designs for the physical and computer experiments. Ref. [
13] used results from the nonlinear optimal design theory to design such experiments. Ref. [
14], based on the Kennedy and O’Hagan model, proposed an optimal sequential design for both computer and physical experiments by regarding integrated mean squared prediction error. Based on the Bayesian model calibration framework of [
6], a D-optimal design for the physical experiment was proposed by [
15]. Ref. [
16] proposed a follow-up optimal experiment design for computer models calibration. In some practices, no physical experiments can be conducted after the initial design due to limitations. Thus, these designs, considering the physical experiments, are hard and impracticable. Ref. [
17] presented an adaptive design for computer experiments to estimate the calibration parameters by using the expected improvement (EI) algorithm. It aims at reducing the calibration error induced by the uncertainty of the emulator of computer models but not at improving the estimation of calibration parameters. Inspired by this, we divert effort on the designs only considering computer experiments to estimate the calibration parameters. The D-optimal criterion is well known and widely used in the literature, which can help gather more information about the calibration parameters by minimizing the asymptotic variances of estimate. This paper proposes a sequential computer experiment calibration design using the D-optimal criterion and presents a fast algorithm to generate the designs.
The article is organized as follows.
Section 2 reviews the Kennedy and O’Hagan calibration method. In
Section 3, the proposed local D-optimal sequential design is presented. A fast algorithm for generating the corresponding designs is suggested. In
Section 4, some simulation studies are made to demonstrate the performance of the proposed design. Conclusions and remarks are given in
Section 5.
Appendix A shows the derivation of the Fisher Information Matrix (FIM) for the calibration parameters.
2. Calibration of Computer Models
An important reference for computer calibration is the work of [
6]. In this section, we will review some related background about the Kennedy and O’Hagan model. Let
be the observation of physical process and
be the control variables, which are also the set of inputs for physical process. According to [
6], the physical observation
can be modeled as
where
is a computer model,
is the set of calibration parameters,
is the discrepancy function which is independent of the computer model
;
is the observation error and
is the corresponding variance. In the literature, the most popular methods to fit the computer model
and discrepancy function
are the Gaussian processes due to analytical tractability. Thus, the prior information about both
and
is considered as
where
is the mean function of computer model. Assume
and
denote the values of control inputs, and
and
denote the values of calibration inputs. According to the literature [
18,
19],
and
are usually the corresponding separable covariance functions such as
Here,
and
are the variance parameters,
and
In terms of the mean function
, the linear model structure is always considered, i.e.,
where
is a vector of
p known functions over
and
is the corresponding unknown regression coefficients.
Let
be the design for physical experiment with
q points,
be the corresponding physical outputs,
be the design for computer experiment with
n points, and
be the corresponding computer outputs. Thus, the full output
is normally distributed given
, and the corresponding likelihood function can be yielded. In order to express the mean and variance matrix of full output clearly, we define the following notations. Let
,
and
be the augmented design points by calibration parameters
. Then the mean and variance matrix for full output vector
given
can be derived as
and
where
is the variance matrix of
with
element
;
is the matrix with
element
;
and
are defined similar with
; and
is a
identity matrix. Then the posterior for the parameters given the data can be written as
where
is the prior for unknown parameters. The MCMC techniques are usually used to determine the posterior distribution, but require complex computations. To simplify the computations, we adopt the modularization by the literature [
20], namely, first estimate the emulator of the computer model and then the discrepancy.
The modular approach in [
20] is considered here to estimate the parameters in the model, which can be described as follows. The maximum likelihood estimates (MLEs)
of
and
of
can be obtained based on the computer experimental data
. For the calibration parameter
, which is a tuning parameter, there is no “true value”. The goal of calibration is to find out some type of best-fitting value of
. It is easy to obtain the least-squares estimate of
, i.e., the value
that minimizes the differences between the physical outputs and the computer model outputs by regarding fixing the
and
at their MLEs. The bias data
can be employed to compute the MLEs
of
and
of
, where
is the prediction from the surrogate model. Then, considering the MLEs
and
as fixed values, the posterior mean
of the calibration parameters
is deduced according to the prior information and observation data. As pointed out by [
8], despite the maximum likelihood estimate plug-in being only approximately Bayesian, the resulting answers seem to be close to those from a full Bayesian analysis.
4. Simulation Studies
In this section, we investigate the performance of the new proposed sequential D-optimal design using simulation studies. Two numerical simulation examples and one real data analysis are used to compare the performance of the proposed design with the EI [
17] and IMSPE designs [
16]. To make the comparison fair, the IMSPE design is implemented only regarding computer design in the simulation studies. To evaluate the performance of the designs, the following three statistical metrics are considered:
The MSE is used to demonstrate the effectiveness of the estimate of the calibration parameters, which is defined as
where
denotes the corresponding Euclidean distance. Ref. [
26] proved that under certain conditions, the Kennedy–O’Hagan calibration estimator converges to the minimizer of the norm of the residual function
in the reproducing kernel Hilbert space. As a result, we assume that
is the best value of calibration parameter. For more details about the reproducing kernel Hilbert space
, please refer to [
26,
27].
is the estimate of the calibration parameters at the
th replication after
l sequential design points, and
M is the number of the simulation replications. The MPD is considered to assess the predictive performance of the calibrated computer models, which defined as
where
is the prediction of the computer model with
being the estimate of the calibration parameters at the
th replication with
l sequential design points. The MSPE is used to assess the accuracy of the predictions by combining the calibrated computer model and discrepancy, which is defined as
where
is the prediction associated with the physical experiments.
4.1. Case Study I
In this section, an example with one calibration parameter and one control variable is considered, which is formulated as
where
,
,
and
. The best value of the calibration parameter is
in this case. A constant mean
and a product-form Matérn correlation function with
are selected as the prior for
. For the calibration parameter, we select the prior of
to be
. The size of the physical experiment design (uniform design) is set as
. An MmLHD in
with 10 points is generated for the initial computer experiment design, i.e.,
, and the
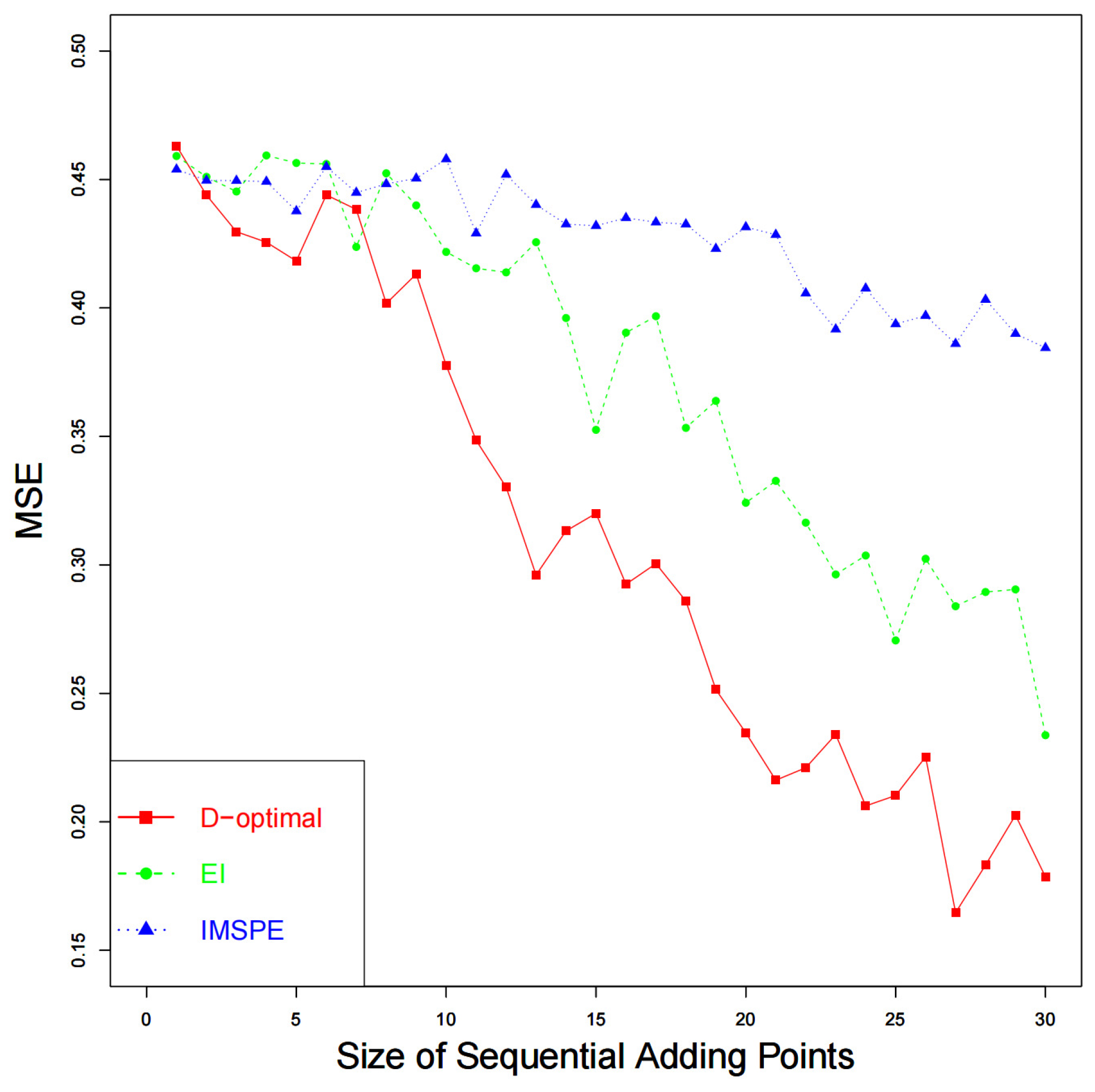
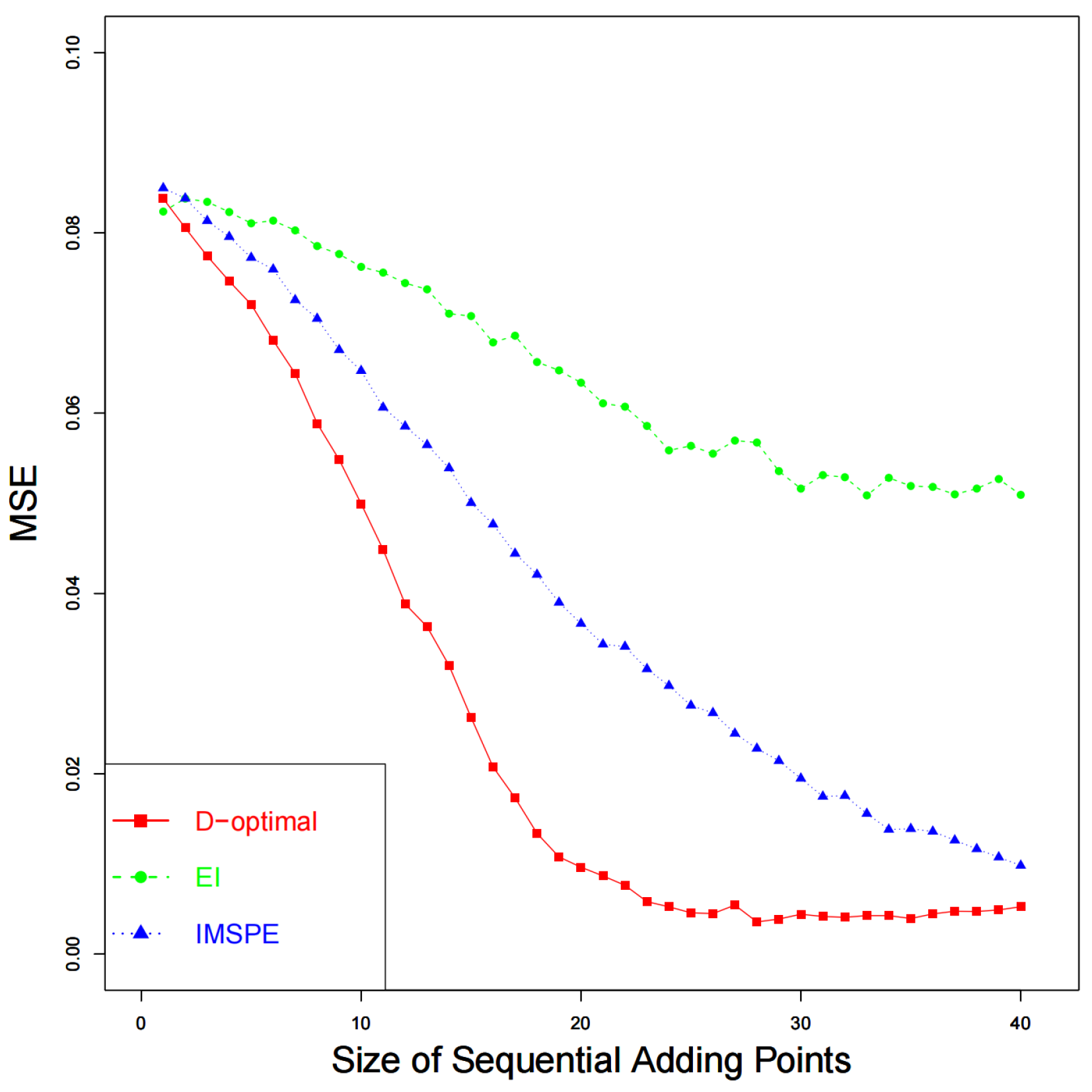
points are to be added sequentially according to Algorithm 1. A total of 100 simulations are performed to calculate the metrics of performance. The results of
are shown in
Figure 1. As the increase in computer experimental points sequentially, the calibration parameter approaches the best value, and the proposed method outperforms the other two designs. The results of
are shown in
Figure 2, which shares a similar trend with
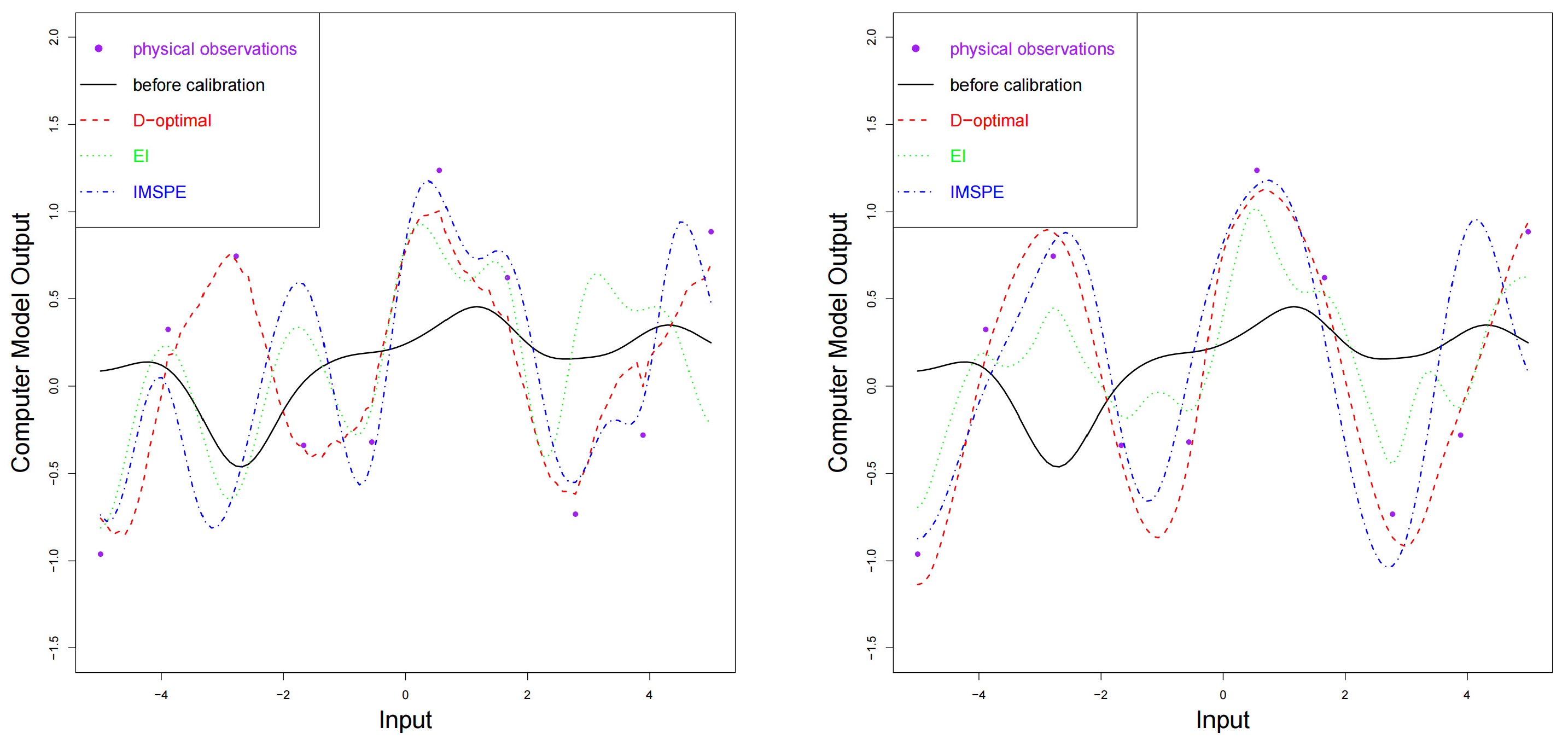
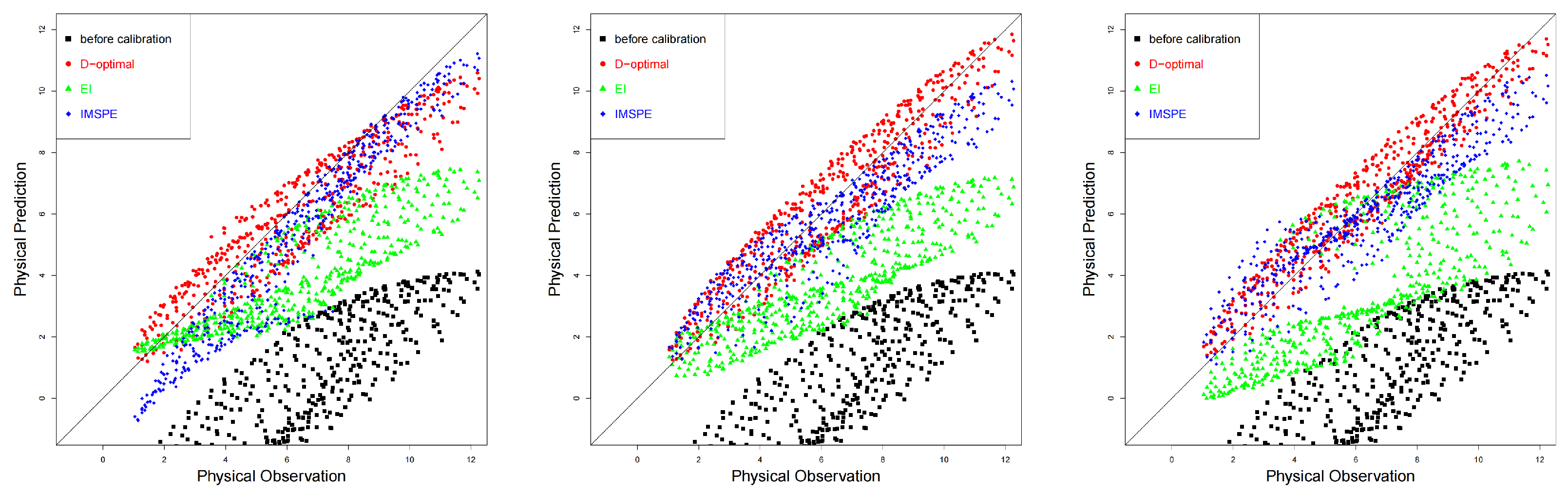
. The comparison between the original computer model and the calibrated computer model is shown in
Figure 3. We can see that the calibrated computer models are closer to the physical observations. As the number of sequential computer experiments increases, the differences between the computer model and physical observations decrease, and the proposed method performs better than the other two designs.
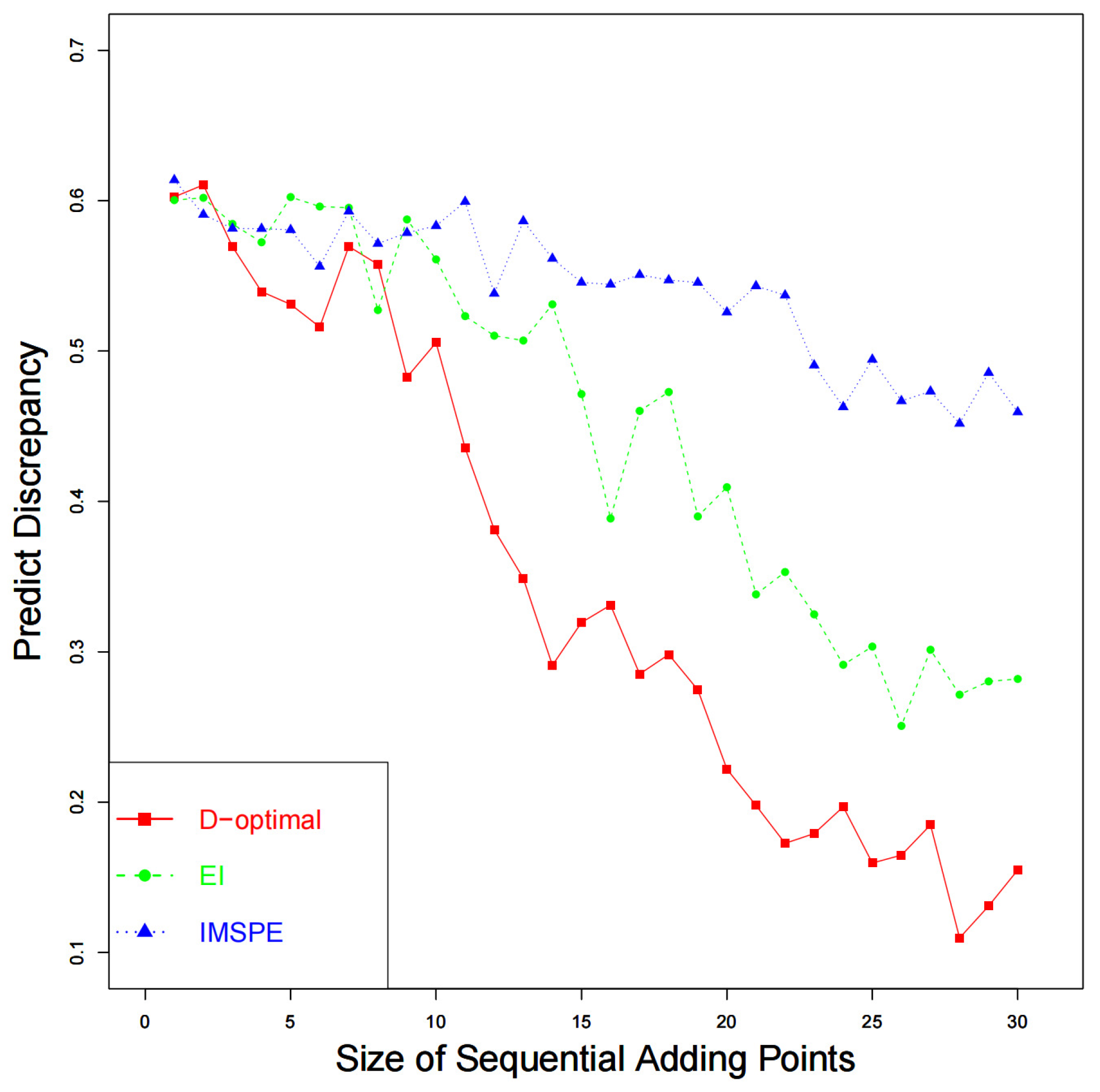
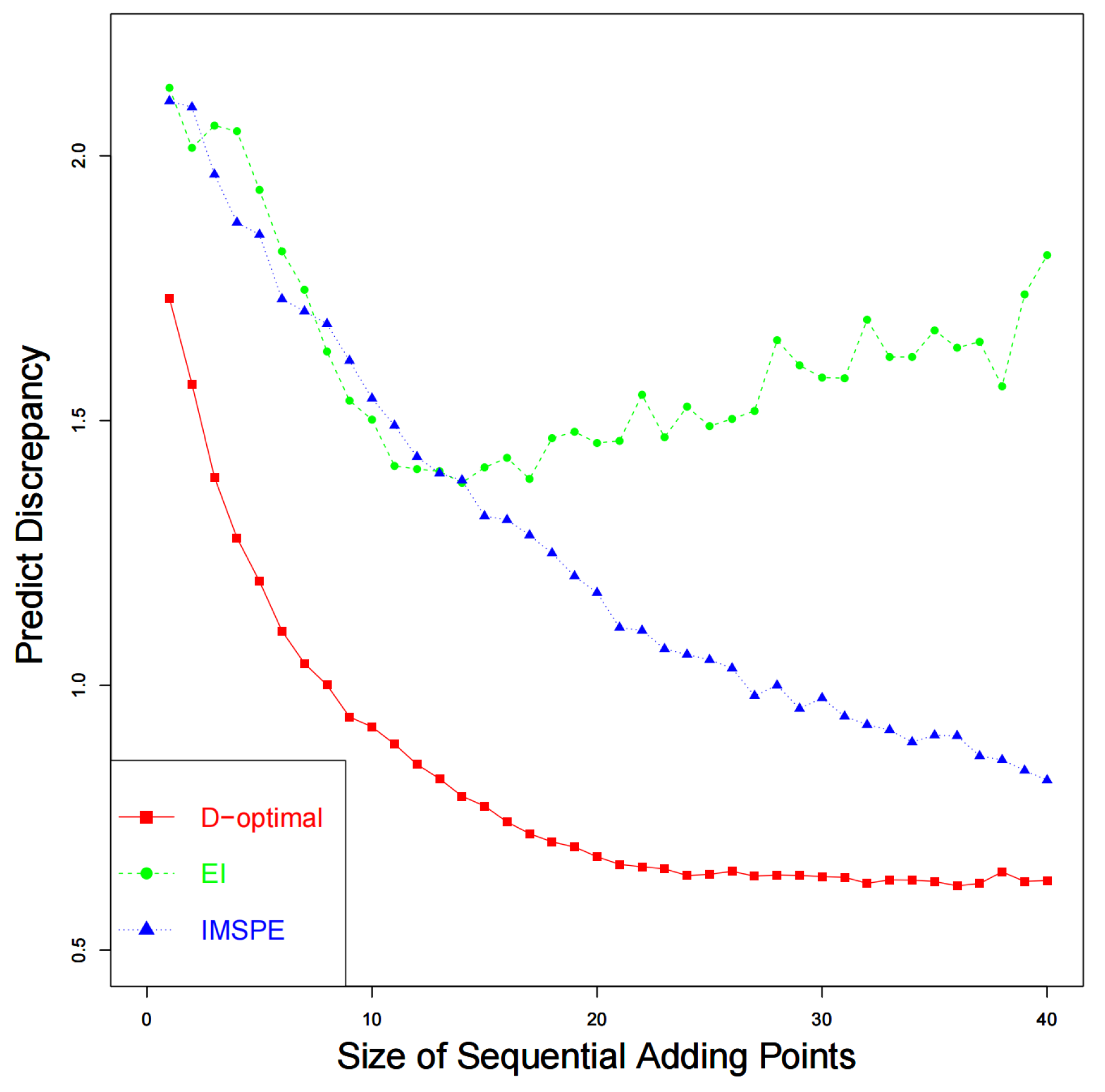
The results of
are summarized in
Table 1, which also shares a similar trend with
and
. The performance of prediction by combining calibrated computer models and discrepancy function is shown in
Figure 4. In
Figure 4, the predictions by using our method approximate the physical observations best.
4.2. Case Study II
In this section, another example which includes three calibration parameters and two control variables and is given in [
28] is considered. In this case study, a discrepancy between computer model outputs and physical outputs is also regarding. The physical process is described as
where,
,
,
,
. The best value of the calibration parameter is
. Assume that the expectation of
is
, and the correlation function of
is Gaussian. The expectation of
is set to be zero, and the correlation function of
is also assumed to be Gaussian. Let the prior for
,
, and
be
,
, and
, respectively. A total of 500 simulations are performed to assess the performances of the sequential designs. A design with 10 points are employed for physical experiments, and a MmLHD with
points over
is utilized as the initial design for computer experiments. In this case, the number of sequential points is set to be
. The results of
are drawn in
Figure 5. As the size of sequential experiment points increases, the calibration parameter approaches the best value. The proposed method has smaller MSEs than the other two methods, which means the proposed method performs better.
Figure 6 shows the results of
, which also demonstrate the effectiveness of the proposed design for calibration.
The simulation results in
Figure 1 and
Figure 5 show that, regardless of whether the discrepancy function exists or not, with the increase in sequential points, the estimate of calibration parameters gradually approaches its best value, indicating that the estimation of calibration parameters converges. However, the strict mathematical proof of this conclusion is a complicated problem, which cannot be solved in this paper and will be paid attention to in a future study.
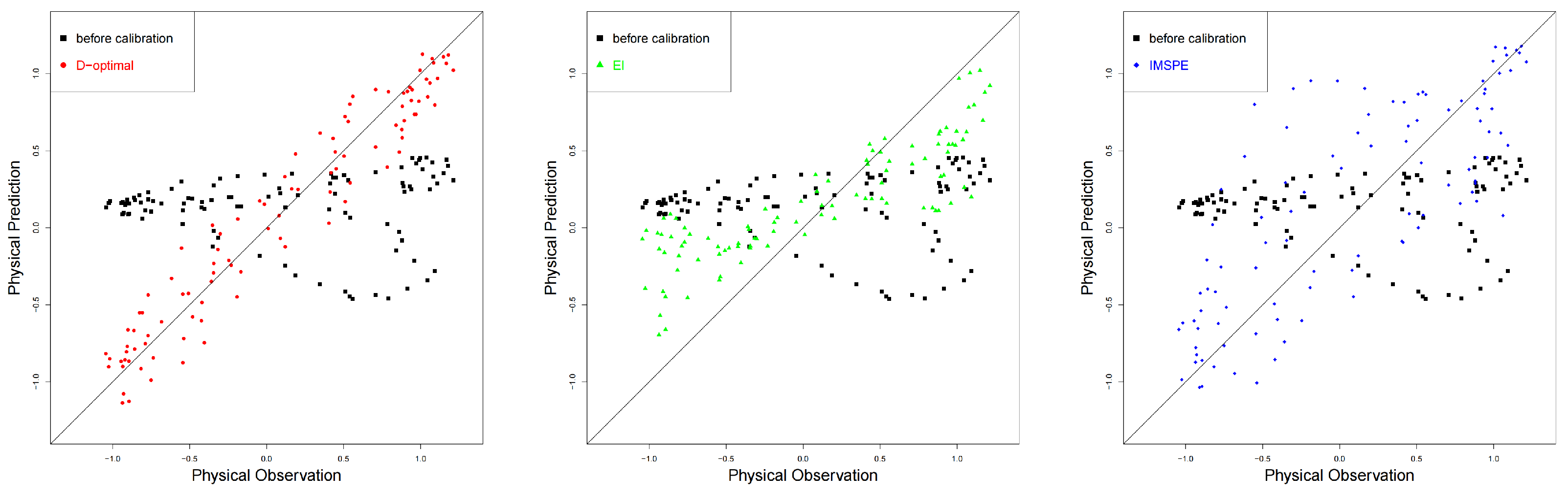
From
Figure 6, we can easily find out that when 20 points are sequentially added, the discrepancy tends to be stable. As shown in
Figure 7, the physical prediction combining discrepancy and calibrated computer model by utilizing the proposed sequential D-optimal method is the closest to the physical observations, followed by the IMSPE method and EI method. The results regarding the MSPE are presented in
Table 2, which shares similar conclusions as those in the case study I.
4.3. Real Data Analysis
In this section, a real data example with three control inputs and one calibration input is considered, which is presented in [
8].
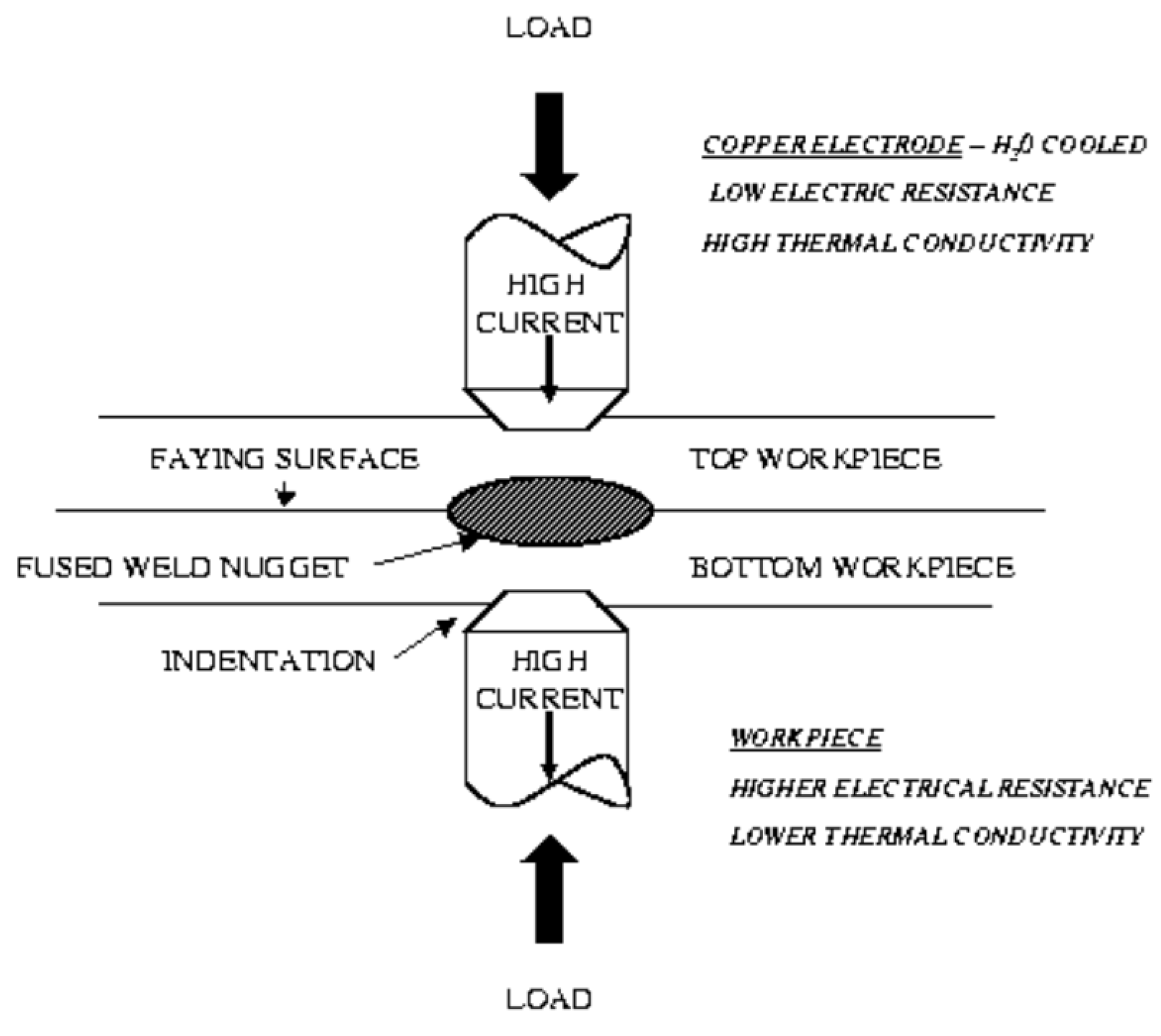
Figure 8 shows a concise description of the resistance spot welding process. Two metal sheets of a particular thickness (thickness) are compressed through two electrodes under a specifically applied load (load). A direct current of a certain magnitude (current) passes through the sheets via the two electrodes, and the heat produced by the current flow causes the welding surfaces to melt. After cooling, a weld nugget with a specific dimension (diameter) is formed, which is of particular interest. In this manner, the two metal plates are welded.
The resistance at the contact surface is particularly critical in determining the magnitude of heat generated. Because the contact resistance at the contact surface is not well understood as a function of temperature, the calibration parameter is specified and adjusted based on the field data. The effect of this calibration parameter on the behavior of the model is a focus in this case. Ref. [
8] comprehensively described the inputs for this example. According to the evaluation of the model developer, the verification experiment focuses on three control inputs (thickness, load, and current).
Table 3 lists the control and calibration inputs and the corresponding intervals.
A constant mean
and the product-form exponential correlation function are considered as the prior for
. As (
2) shows, a zero mean and the Gaussian correlation function are considered as the prior for
, and more details can be found in [
2,
6,
28,
29], etc. We randomly choose 10 physical experiments from the non-replicated 12 physical experiments. An initial computer design with 20 points is generated and the corresponding outputs are simulated according to [
8].
points are added sequentially according to Algorithm 1. The results about the MSPE are summarized in
Table 4, which illustrates the superior of the new proposed method due to the smaller MSPE values.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}