
Cross-Lingual Transfer Learning for Arabic Task-Oriented Dialogue Systems Using Multilingual Transformer Model mT5


Abstract
:1. Introduction
- -
- To what extent is cross-lingual transfer learning effective in end-to-end Arabic task-oriented DS using the mT5 model?
- -
- To what extent does the size of the training dataset affect the quality of Arabic task-oriented DS in few-shot scenarios?
2. Related Works
3. Methodology
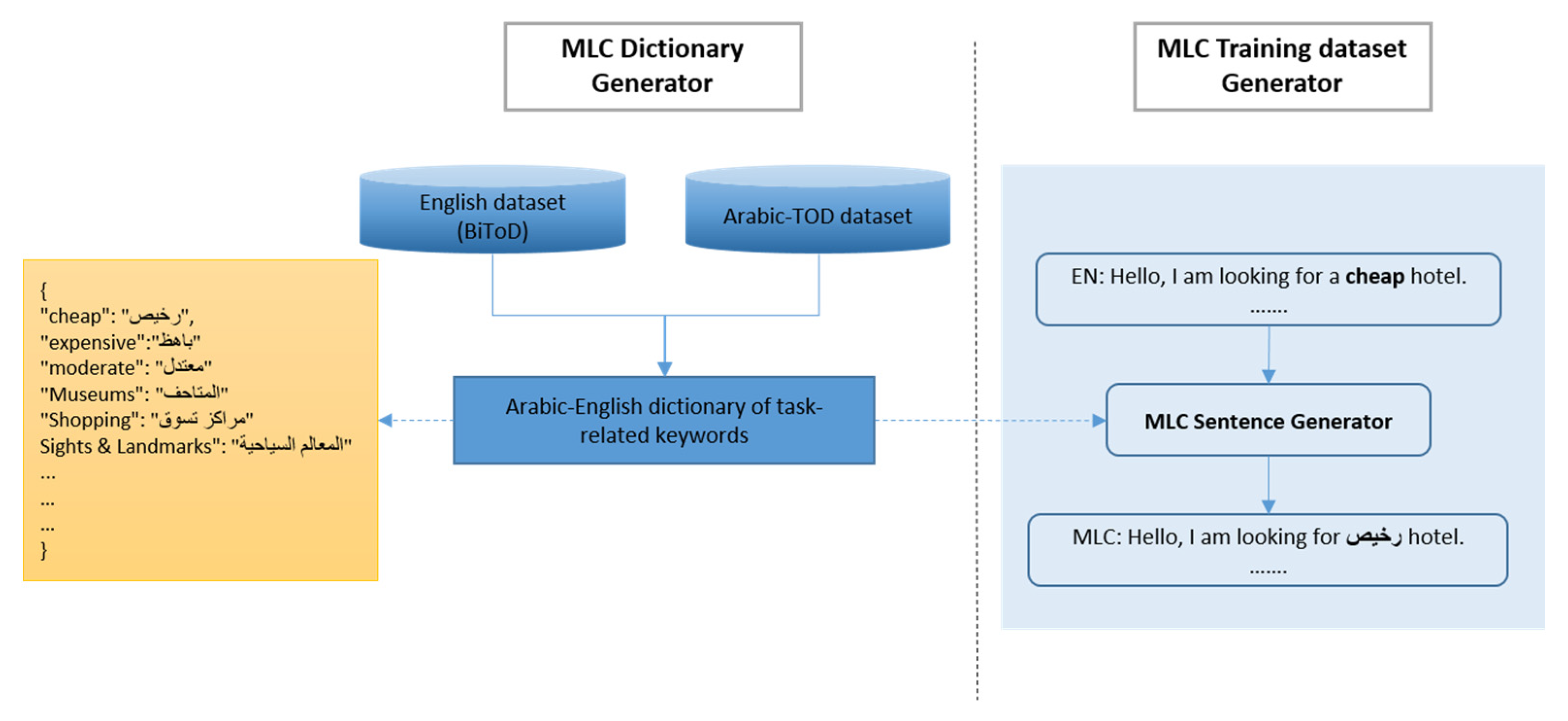
3.1. Dataset
3.2. Evaluation Metrics
4. Experiments
Experiment Setup
5. Results and Discussion
Impact of Arabic-TOD Dataset Size on Arabic Task-Oriented DS Performance
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- McTear, M. Conversational AI: Dialogue Systems, Conversational Agents, and Chatbots; Morgan & Claypool Publishers LLC: San Rafael, CA, USA, 2020; Volume 13. [Google Scholar]
- Wu, C.S.; Madotto, A.; Hosseini-Asl, E.; Xiong, C.; Socher, R.; Fung, P. Transferable multi-domain state generator for task-oriented dialogue systems. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 808–819. [Google Scholar] [CrossRef] [Green Version]
- Peng, B.; Zhu, C.; Li, C.; Li, X.; Li, J.; Zeng, M.; Gao, J. Few-shot Natural Language Generation for Task-Oriented Dialog. arXiv 2020, arXiv:2002.12328. [Google Scholar] [CrossRef]
- Yang, Y.; Li, Y.; Quan, X. UBAR: Towards Fully End-to-End Task-Oriented Dialog Systems with GPT-2. arXiv 2020, arXiv:2012.03539. [Google Scholar]
- Hosseini-Asl, E.; McCann, B.; Wu, C.S.; Yavuz, S.; Socher, R. A simple language model for task-oriented dialogue. Adv. Neural Inf. Process. Syst. 2020, 33, 20179–20191. [Google Scholar]
- AlHagbani, E.S.; Khan, M.B. Challenges facing the development of the Arabic chatbot. In Proceedings of the First International Workshop on Pattern Recognition 2016, Tokyo, Japan, 11–13 May 2016; Volume 10011, p. 7. [Google Scholar] [CrossRef]
- Liu, Z.; Shin, J.; Xu, Y.; Winata, G.I.; Xu, P.; Madotto, A.; Fung, P. Zero-shot cross-lingual dialogue systems with transferable latent variables. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 1297–1303. [Google Scholar] [CrossRef]
- Schuster, S.; Shah, R.; Gupta, S.; Lewis, M. Cross-lingual transfer learning for multilingual task oriented dialog. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 3795–3805. [Google Scholar] [CrossRef] [Green Version]
- Zhou, X.; Dong, D.; Wu, H.; Zhao, S.; Yu, D.; Tian, H.; Liu, X.; Yan, R. Multi-view response selection for human-computer conversation. In Proceedings of the EMNLP 2016—Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 372–381. [Google Scholar]
- Xue, L.; Constant, N.; Roberts, A.; Kale, M.; Al-Rfou, R.; Siddhant, A.; Barua, A.; Raffel, C. mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2020; pp. 483–498. [Google Scholar] [CrossRef]
- Liu, Z.; Winata, G.I.; Lin, Z.; Xu, P.; Fung, P. Attention-informed mixed-language training for zero-shot cross-lingual task-oriented dialogue systems. In Proceedings of the AAAI 2020—34th Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 8433–8440. [Google Scholar] [CrossRef]
- Lin, Z.; Madotto, A.; Winata, G.I.; Xu, P.; Jiang, F.; Hu, Y.; Shi, C.; Fung, P. BiToD: A Bilingual Multi-Domain Dataset For Task-Oriented Dialogue Modeling. arXiv 2021, arXiv:2106.02787. [Google Scholar]
- Liu, Y.; Gu, J.; Goyal, N.; Li, X.; Edunov, S.; Ghazvininejad, M.; Lewis, M.; Zettlemoyer, L. Multilingual denoising pre-training for neural machine translation. Trans. Assoc. Comput. Linguist. 2020, 8, 726–742. [Google Scholar] [CrossRef]
- Sitaram, S.; Chandu, K.R.; Rallabandi, S.K.; Black, A.W. A Survey of Code-switched Speech and Language Processing. arXiv 2019, arXiv:1904.00784. [Google Scholar]
- Louvan, S.; Magnini, B. Simple data augmentation for multilingual NLU in task oriented dialogue systems. In Proceedings of the Seventh Italian Conference on Computational Linguistics CLIC-IT 2020, Bologna, Italy, 30 November–2 December 2020; Volume 2769. [Google Scholar] [CrossRef]
- Henderson, M.; Thomson, B.; Williams, J. The second dialog state tracking challenge. In Proceedings of the 15th Annual Meeting of the Special Interest Group on Discourse and Dialogue (SIGDIAL), Philadelphia, PA, USA, 18–20 June 2014; pp. 263–272. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.-J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2001; pp. 311–318. [Google Scholar] [CrossRef] [Green Version]
- PyTorch. Available online: https://pytorch.org/ (accessed on 17 November 2021).
- Huggingface/Transformers: Transformers: State-of-the-Art Natural Language Processing for Pytorch, TensorFlow, and JAX. Available online: https://github.com/huggingface/transformers (accessed on 17 November 2021).
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. In Proceedings of the 7th International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2017. [Google Scholar]


{kind=link}
| Study | Dataset | Dataset Size (Train/Validate/Test) | Metrics | |
|---|---|---|---|---|
| [8] Cross-lingual settings using cross-lingual pre-trained embeddings | Their own dataset across three domains: weather, alarm and reminder. | English (43k) 30,521/4181/8621 | — | |
| Spanish (8.6k) 3617/1983/3043 | Exact match = 75.96, Domain accuracy (acc.) = 99.47, Intent acc. = 97.51, Slot F1 = 83.38 | |||
| Thai (5k) 2156/1235/1692 | Exact match = 86.12, Domain acc. = 99.33, Intent acc. = 9.87, Slot F1 = 91.51 | |||
| [8] Cross-lingual settings using translating the training data | English (43k) 30,521/4181/8621 | — | ||
| Spanish (8.6k) 3617/1983/3043 | Exact match = 72.49, Domain acc. = 99.65, Intent acc. = 98.47, Slot F1 = 80.60 | |||
| Thai (5k) 2156/1235/1692 | Exact match = 73.37, Domain acc. = 99.37, Intent acc. = 97.41, Slot F1 = 80.38 | |||
| [11] Zero-shot setting using mBERT + transformer | Multilingual WOZ 2.0 | English (1k) 600/200/400 | — | |
| German (1k) 600/200/400 | Slot acc. = 70.77, JGA. = 34.36, Request acc. = 86.97 | |||
| Italian (1k) 600/200/400 | Slot acc. = 71.45, JGA = 33.35, Request acc. = 84.96 | |||
| BiToD [12] cross-lingual | BiToD (cross-lingual) (ZH → EN) | English (EN) (3.6k) 2952/295/442 | mT5 | TSR = 6.78, DSR = 1.36, APIAcc = 17.75, BLEU = 10.35, JGA = 19.86 |
| mBART | TSR = 1.11, DSR = 0.23, APIAcc = 0.60, BLEU = 3.17, JGA = 4.64 | |||
| mT5 + CPT | TSR = 44.94, DSR = 24.66, APIAcc = 47.60, BLEU = 29.53, JGA = 48.77 | |||
| mBART + CPT | TSR = 36.19, DSR = 16.06, APIAcc = 41.51, BLEU = 22.50, JGA = 42.84 | |||
| mT5 + MLT | TSR = 56.78, DSR = 33.71, APIAcc = 56.78, BLEU = 32.43, JGA = 58.3 | |||
| mBART + MLT | TSR = 33.62, DSR = 11.99, APIAcc = 41.08, BLEU = 20.01, JGA = 55.39 | |||
| BiToD (EN → ZH) | Chinese (ZH) (3.5k) 2835/248/460 | mT5 | TSR = 4.16, DSR = 2.20, APIAcc = 6.67, BLEU = 3.30, JGA = 12.63 | |
| mBART | TSR = 0.00, DSR = 0.00, APIAcc = 0.00, BLEU = 0.01, JGA = 2.14 | |||
| mT5 + CPT | TSR = 43.27, DSR = 23.70, APIAcc = 49.70, BLEU = 13.89, JGA = 51.40 | |||
| mBART + CPT | TSR = 24.64, DSR = 11.96, APIAcc = 29.04, BLEU = 8.29, JGA = 28.57 | |||
| mT5 + MLT | TSR = 49.20, DSR = 27.17, APIAcc = 50.55, BLEU = 14.44, JGA = 55.05 | |||
| mBART + MLT | TSR = 44.71, DSR = 21.96, APIAcc = 54.87, BLEU = 14.19, JGA = 60.71 | |||
| mSeq2Seq Approach | |||||
| TSR | DSR | APIAcc | BLEU | JGA | |
| AR | 18.63 | 3.72 | 15.26 | 9.55 | 17.67 |
| ZH [12] | 4.16 | 2.20 | 6.67 | 3.30 | 12.63 |
| CPT Approach | |||||
| AR | 42.16 | 14.18 | 46.63 | 23.09 | 32.71 |
| ZH [12] | 43.27 | 23.70 | 49.70 | 13.89 | 51.40 |
| MLT Approach | |||||
| AR | 42.16 | 14.49 | 46.77 | 23.98 | 32.75 |
| ZH [12] | 49.20 | 27.17 | 50.55 | 14.44 | 55.05 |
| Evaluation Metrics | TSR | DSR | APIAcc | BLEU | JGA | |
|---|---|---|---|---|---|---|
| Approach | ||||||
| AR (mseq2seq) | 42.88 | 13.95 | 48.68 | 29.28 | 35.74 | |
| AR (CPT) | 47.18 | 18.14 | 52.10 | 31.16 | 36.32 | |
| AR (MLT) | 48.10 | 18.84 | 52.58 | 31.74 | 37.17 | |
| Evaluation Metrics | TSR | DSR | APIAcc | BLEU | JGA | |
|---|---|---|---|---|---|---|
| Dataset Size | ||||||
| 5% | 30.09 | 10.23 | 33.07 | 20.26 | 24.85 | |
| 10% | 34.90 | 11.86 | 37.89 | 20.87 | 28.26 | |
| 20% | 40.73 | 14.42 | 44.47 | 23.84 | 32.05 | |
| 50% | 42.16 | 14.88 | 48.51 | 24.94 | 34.03 | |
| 100% | 48.10 | 18.84 | 52.58 | 31.74 | 37.17 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fuad, A.; Al-Yahya, M. Cross-Lingual Transfer Learning for Arabic Task-Oriented Dialogue Systems Using Multilingual Transformer Model mT5. Mathematics 2022, 10, 746. https://doi.org/10.3390/math10050746
Fuad A, Al-Yahya M. Cross-Lingual Transfer Learning for Arabic Task-Oriented Dialogue Systems Using Multilingual Transformer Model mT5. Mathematics. 2022; 10(5):746. https://doi.org/10.3390/math10050746
Chicago/Turabian StyleFuad, Ahlam, and Maha Al-Yahya. 2022. "Cross-Lingual Transfer Learning for Arabic Task-Oriented Dialogue Systems Using Multilingual Transformer Model mT5" Mathematics 10, no. 5: 746. https://doi.org/10.3390/math10050746