
DFM-GCN: A Multi-Task Learning Recommendation Based on a Deep Graph Neural Network

Abstract
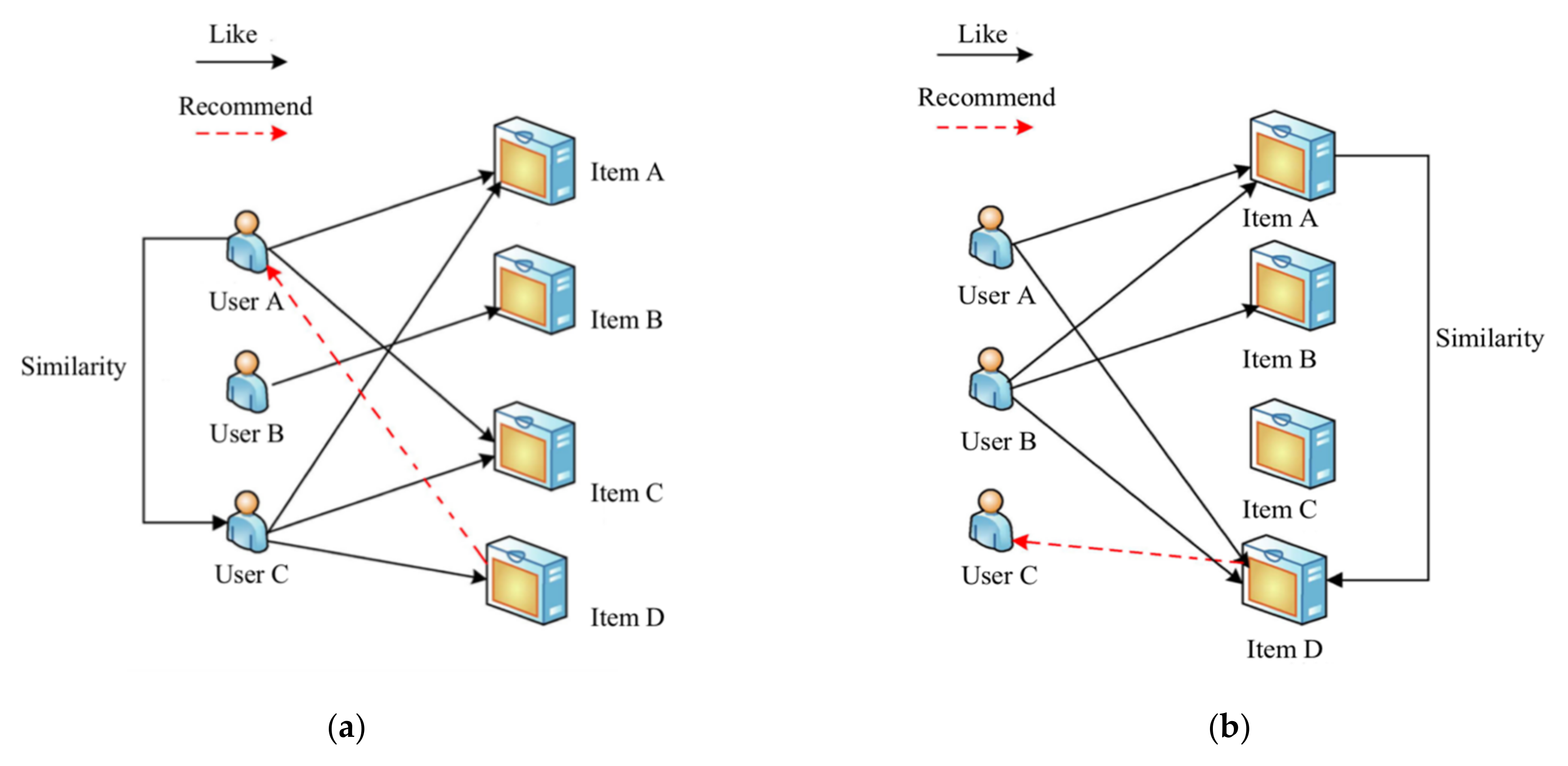
:1. Introduction
- (1)
- The DeepFM algorithm was used as the backbone because it can compensate for the dimension transformation and data compression problems brought by the collaborative filtering algorithm.
- (2)
- The GCN was employed to learn the representation of each node and relationship in the knowledge graph, which could inject more reliable item knowledge into the recommendation algorithm.
- (3)
- Using deep neural networks to model the connection between DeepFM and the GCN, we adopted a deep cross-compression unit to capture the high dimension features in the interaction.
1.1. Existing Related Works
1.1.1. Traditional Recommendation Algorithms
1.1.2. Recommendation Algorithms Based on Deep Learning
1.1.3. Recommendation Algorithms Based on a Graph Neural Network
1.1.4. Recommendation Algorithms Incorporating External Knowledge
2. Method
2.1. Problem Definition
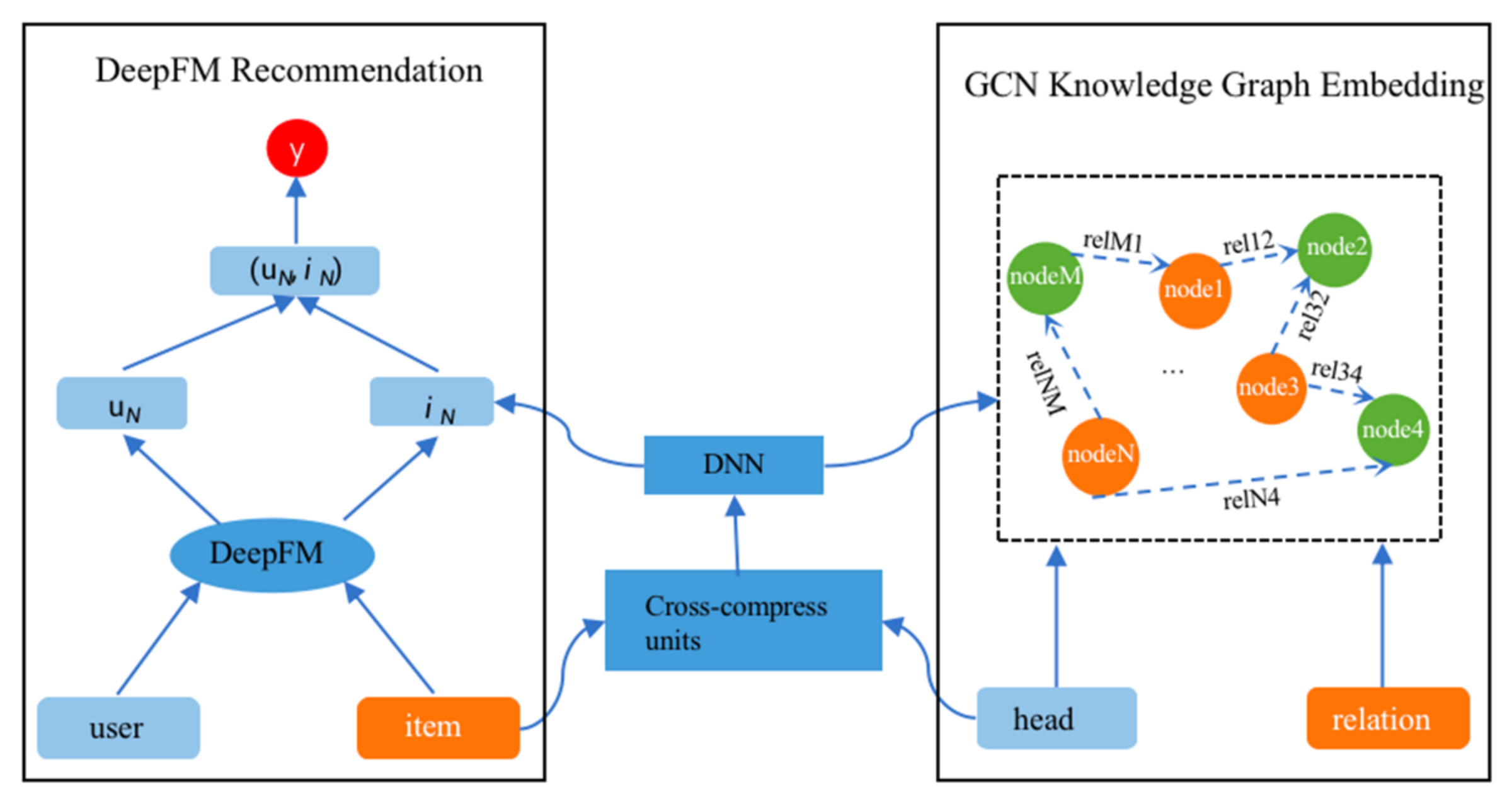
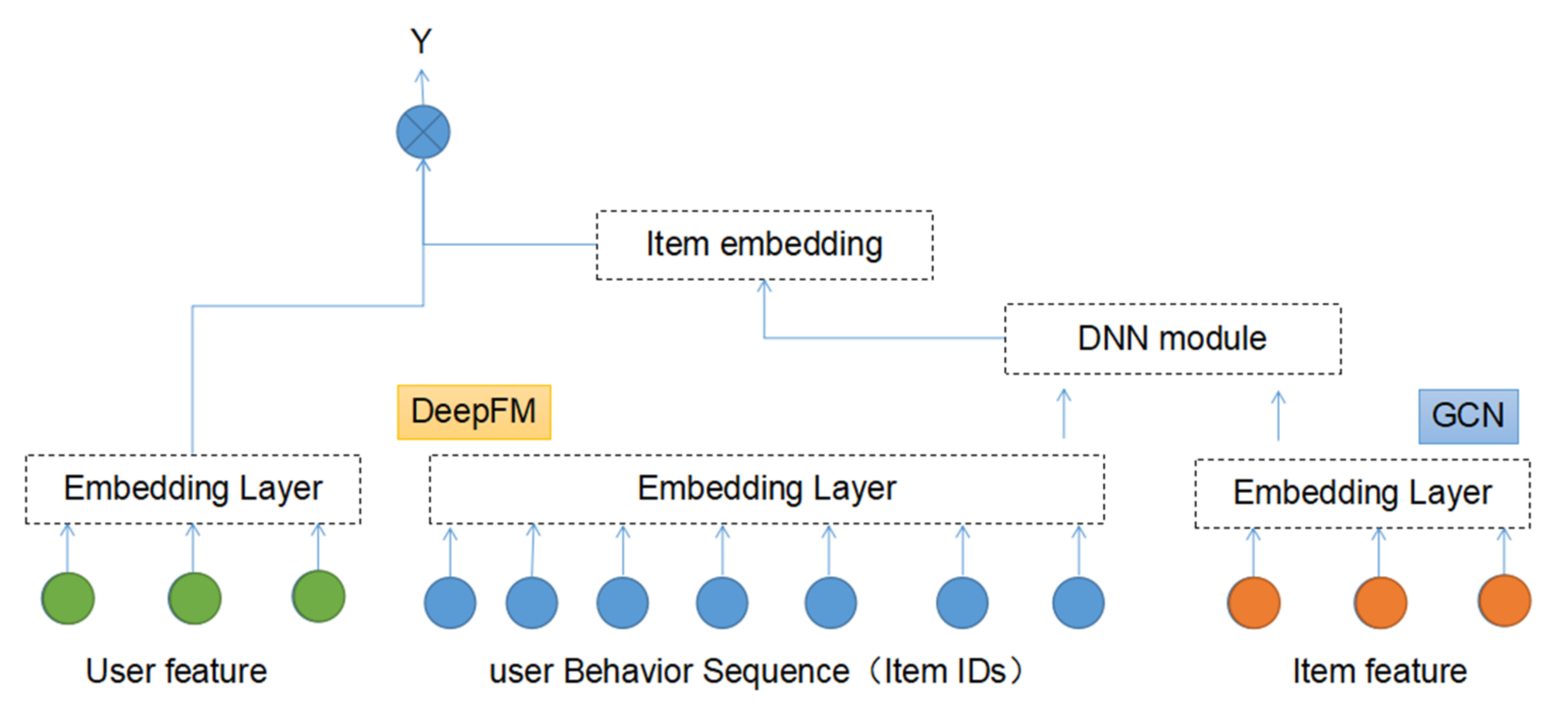
2.2. Model
2.2.1. DeepFM Recommendation
2.2.2. Embedding of the GCN Knowledge Graph
2.2.3. DNN Cross and Compress Units
2.2.4. Optimized Objective Function
3. Experiment and Analysis
3.1. Datasets
3.2. Baselines
3.3. Experiment Settings
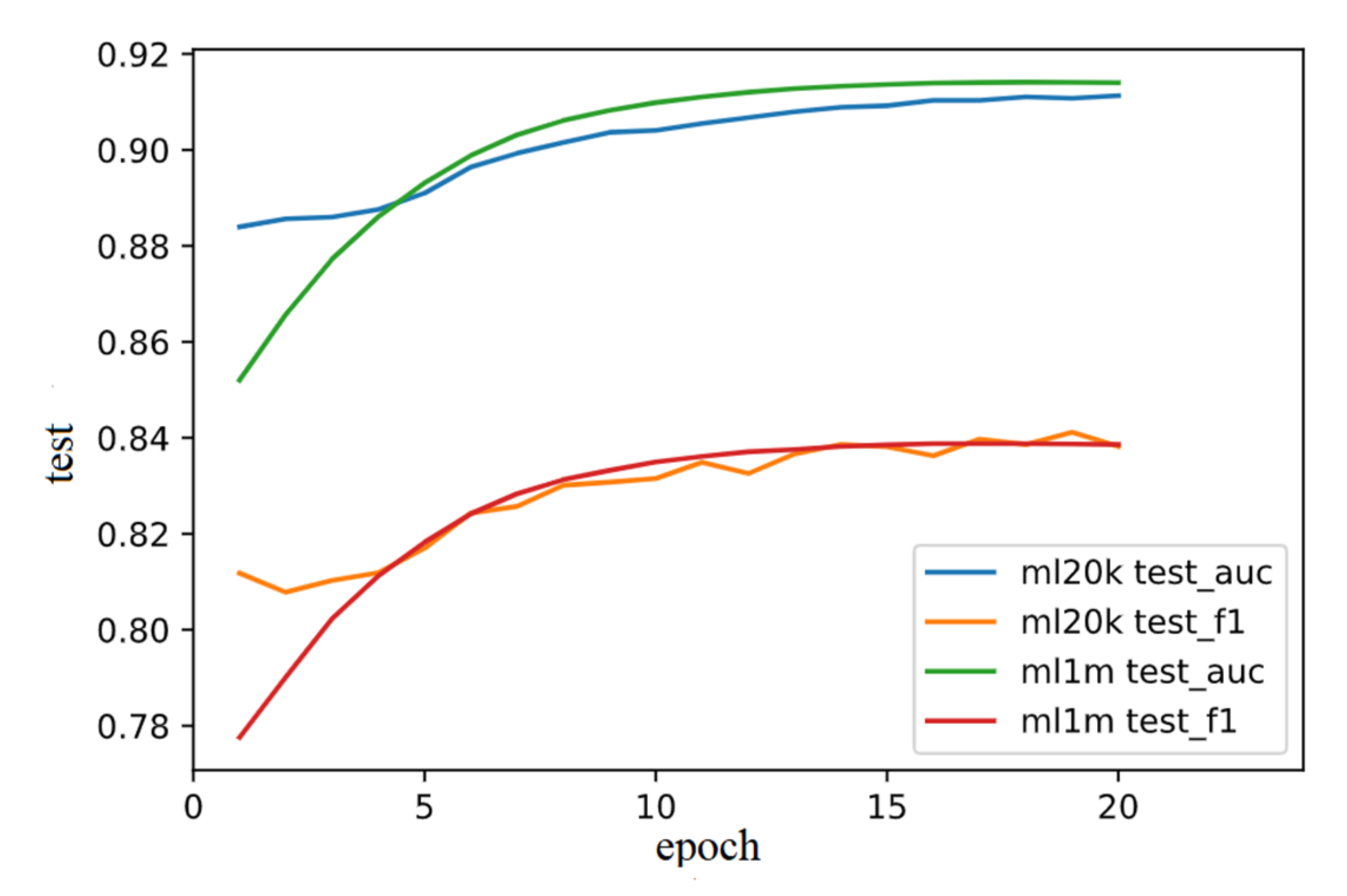
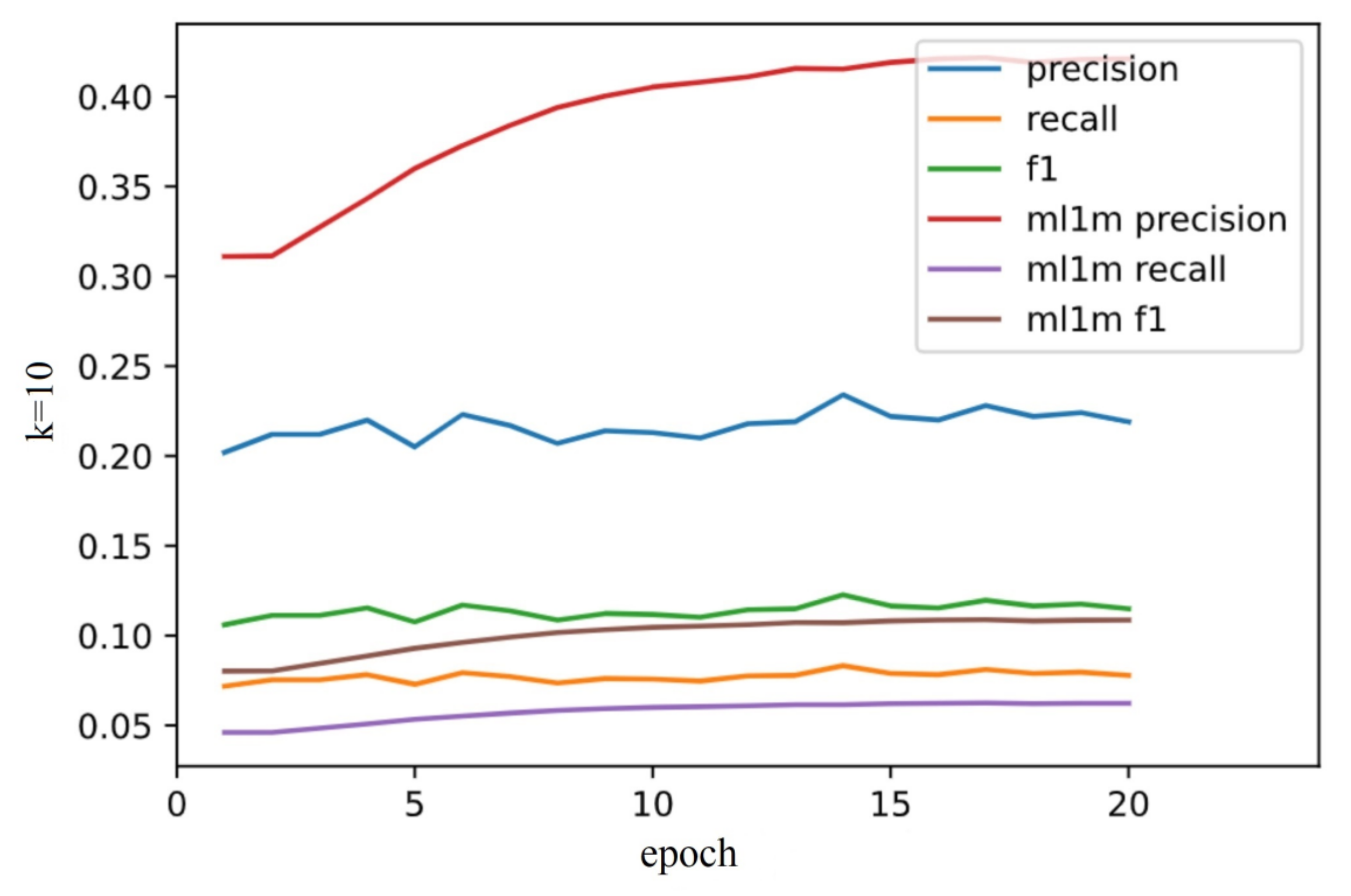
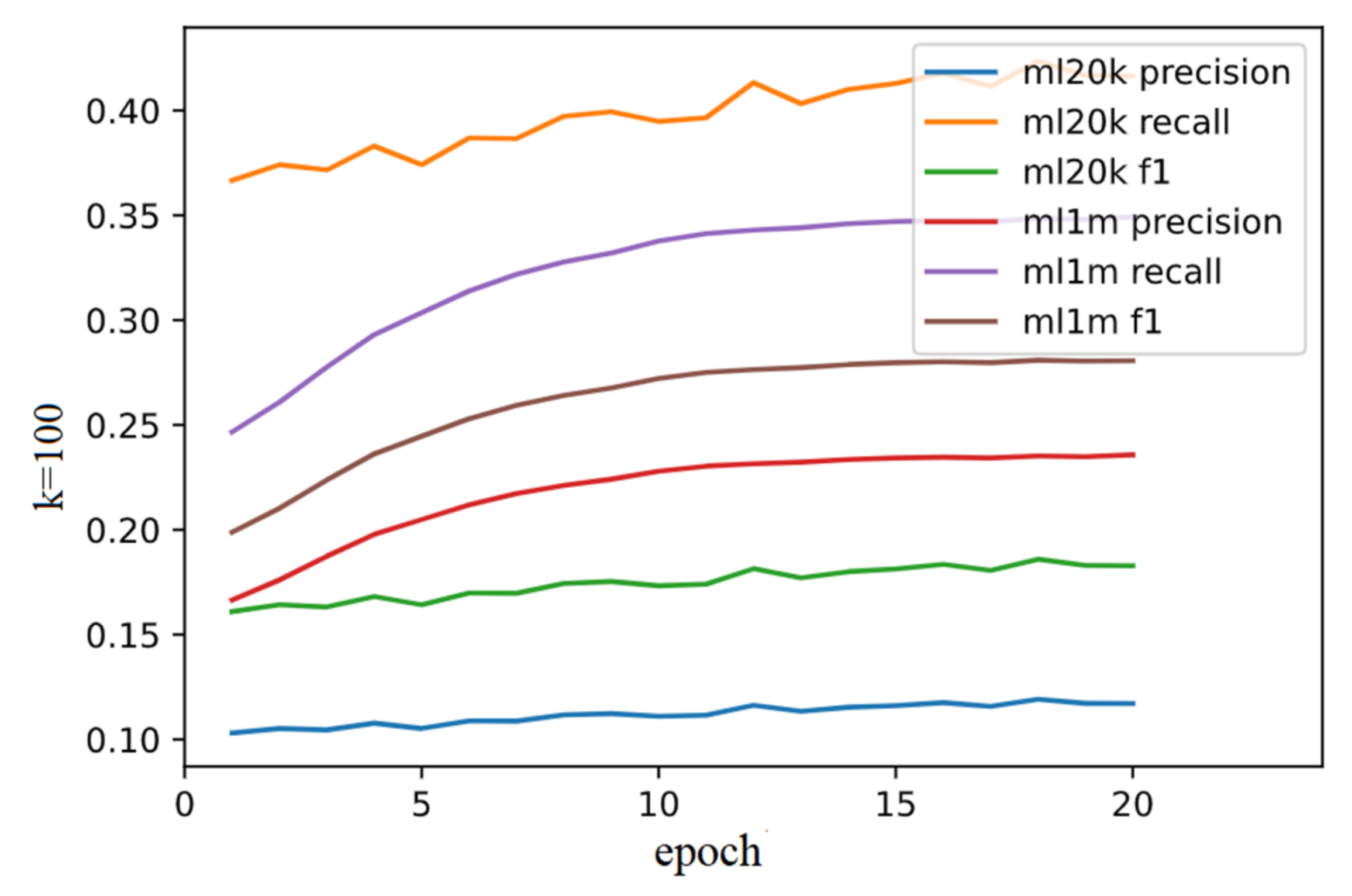
3.4. Experiment Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jamali, M.; Ester, M. A matrix factorization technique with trust propagation for recommendation in social networks. In Proceedings of the Fourth ACM Conference on Recommender Systems, Barcelona, Spain, 26–30 September 2010; pp. 135–142. [Google Scholar]
- Wang, H.; Zhang, F.; Hou, M.; Xie, X.; Guo, M.; Liu, Q. SHINE: Signed Heterogeneous Information Network Embedding for Sentiment Link Prediction. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Marina Del Rey, CA, USA, 5–9 February 2018; pp. 592–600. [Google Scholar]
- Wang, H.; Wang, N.; Yeung, D.-Y. Collaborative Deep Learning for Recommender Systems. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015. [Google Scholar]
- Zhang, F.; Yuan, N.J.; Lian, D.; Xie, X.; Ma, W.-Y. Collaborative Knowledge Base Embedding for Recommender Systems. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 353–362. [Google Scholar]
- Wang, H.; Zhang, F.; Zhao, M.; Li, W.; Xie, X.; Guo, M. Multi-Task Feature Learning for Knowledge Graph Enhanced Recommendation. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 2000–2010. [Google Scholar]
- Su, X.; Khoshgoftaar, T.M. A Survey of Collaborative Filtering Techniques. Adv. Artif. Intell. 2009, 2009, 421425. [Google Scholar] [CrossRef]
- Xiao, Y.; Li, C.D.; Song, L.J.; Yang, J.; Su, J.F. A Multidimensional Information Fusion-Based Matching Decision Method for Manufacturing Service Resource. IEEE Access 2021, 9, 39839–39851. [Google Scholar] [CrossRef]
- Bengio, Y. Learning Deep Architectures for AI; Foundation and Trends® in Machine Learning: Hanover, MA, USA, 2009; Volume 2, pp. 1–127. [Google Scholar]
- Dezfouli, P.A.B.; Momtazi, S.; Dehghan, M. Deep neural review text interaction for recommendation systems. Appl. Soft Comput. 2020, 100, 106985. [Google Scholar] [CrossRef]
- Donkers, T.; Loepp, B.; Ziegler, J. Sequential User-based Recurrent Neural Network Recommendations. In Proceedings of the Eleventh ACM Conference on Recommender Systems, Como, Italy, 27–31 August 2017; pp. 152–160. [Google Scholar]
- Sahoo, B.B.; Jha, R.; Singh, A.; Kumar, D. Long short-term memory (LSTM) recurrent neural network for low-flow hydrological time series forecasting. Acta Geophys. 2019, 67, 1471–1481. [Google Scholar] [CrossRef]
- Scarselli, F.; Gori, M.; Tsoi, A.; Hagenbuchner, M.; Monfardini, G. The Graph Neural Network Model. IEEE Trans. Neural Netw. 2009, 20, 61–80. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, M.; Beutel, A.; Covington, P.; Jain, S.; Belletti, F.; Chi, E.H. Top-K Off-Policy Correction for a REINFORCE Recommender System; ACM: New York, NY, USA, 2019; pp. 456–464. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Luo, T.; Zhang, F.; Wu, Y. A Recommendation Model Based on Deep Neural Network. IEEE Access 2018, 6, 9454–9463. [Google Scholar] [CrossRef]
- Liu, J.; Yuan, Q.; Wu, G.; Yu, X. Review of convolutional neural networks. Comput. Era 2018, 19–23. [Google Scholar]
- Tang, J.X.; Wang, K. Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding; ACM: New York, NY, USA, 2018; pp. 565–573. [Google Scholar] [CrossRef] [Green Version]
- Kim, D.; Park, C.; Oh, J.; Lee, S.; Yu, H. Convolutional Matrix Factorization for Document Context-Aware Recommendation. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 233–240. [Google Scholar]
- Santos, J.F.; Falk, T.H. Speech Dereverberation with Context-Aware Recurrent Neural Networks. IEEE ACM Trans. Audio Speech Lang. Process. 2018, 26, 1232–1242. [Google Scholar] [CrossRef]
- Manotumruksa, J.; Macdonald, C.; Ounis, I. A Contextual Attention Recurrent Architecture for Context-Aware Venue Recommendation. In Proceedings of the The 41st International ACM SIGIR Conference on Research and Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 555–564. [Google Scholar]
- Yang, L.B.; Zheng, Y.; Cai, X.Y.; Dai, H.; Mu, D.J.; Guo, L.T.; Dai, T. A LSTM Based Model for Personalized Context-Aware Citation Recommendation. IEEE Access 2018, 6, 59618–59627. [Google Scholar] [CrossRef]
- Kang, W.-C.; McAuley, J. Self-attentive sequential recommendation. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 197–206. [Google Scholar]
- Sun, F.; Liu, J.; Wu, J.; Pei, C.; Lin, X.; Ou, W.; Jiang, P. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 1441–1450. [Google Scholar]
- Ying, R.; He, R.; Chen, K.; Eksombatchai, P.; Hamilton, W.L.; Leskovec, J. Graph Convolutional Neural Networks for Web-Scale Recommender Systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, London, UK, 19–23 August 2018; pp. 974–983. [Google Scholar]
- Wang, H.; Zhao, M.; Xie, X.; Li, W.; Guo, M. Knowledge Graph Convolutional Networks for Recommender Systems. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 3307–3313. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ml1m_kg1m | ml1m_kg20m | |||||
|---|---|---|---|---|---|---|
| UserID | MovieID | Score | UserID | MovieID | Score | |
| Count | 1,000,209 | 1,000,209 | 1,000,209 | 20,000,263 | 20,000,263 | 20,000,263 |
| Mean | 3024.51 | 1865.54 | 3.58 | 69,045.87 | 9041.57 | 3.53 |
| Std | 1728.41 | 1096.04 | 1.12 | 40,038.62 | 19,789.48 | 1.05 |
| Min | 1 | 1 | 1 | 1 | 1 | 0.5 |
| 25% | 1506 | 1030 | 3 | 34,395 | 902 | 3 |
| 50% | 3070 | 1835 | 4 | 69,141 | 2167 | 3.5 |
| 75% | 4476 | 2770 | 4 | 103,637 | 4770 | 4 |
| Max | 6040 | 3952 | 5 | 138,493 | 131,262 | 5 |
| AUC | F1 | Top 100 (Precision) | Top 100 (Recall) | Top 100 (F1) | |
|---|---|---|---|---|---|
| MKR | 0.82777 | 0.66641 | 8.080 | 20.076 | 11.523 |
| FM_MKR | 0.89637 | 0.82169 | 10.760 | 43.793 | 17.275 |
| DFM + GCN | 0.91435 | 0.8441 | 20.693 | 49.364 | 29.162 |
| AUC | F1 | Top 100 (Precision) | Top 100 (Recall) | Top 100 (F1) | |
|---|---|---|---|---|---|
| MKR | 0.83786 | 0.65432 | 8.981 | 22.163 | 12.782 |
| FM_MKR | 0.91123 | 0.84011 | 12.364 | 43.865 | 19.291 |
| DFM + GCN | 0.91781 | 0.84773 | 21.003 | 49.847 | 29.554 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, Y.; Li, C.; Liu, V. DFM-GCN: A Multi-Task Learning Recommendation Based on a Deep Graph Neural Network. Mathematics 2022, 10, 721. https://doi.org/10.3390/math10050721
Xiao Y, Li C, Liu V. DFM-GCN: A Multi-Task Learning Recommendation Based on a Deep Graph Neural Network. Mathematics. 2022; 10(5):721. https://doi.org/10.3390/math10050721
Chicago/Turabian StyleXiao, Yan, Congdong Li, and Vincenzo Liu. 2022. "DFM-GCN: A Multi-Task Learning Recommendation Based on a Deep Graph Neural Network" Mathematics 10, no. 5: 721. https://doi.org/10.3390/math10050721