1. Introduction
Facts I~III encountered in the application research of information fusion and information retrieval are as follows: is information, is an information element; is the attribute set of ( is the characteristic set of ); and attribute of information element satisfies the “disjunctive normal form”. Information has dynamic characteristics:
Some information elements outside are added to , generates ,;
Some information elements in are deleted from , generates , and ;
Under the condition that I and II exist at the same time, generates and at the same time, and .
Facts I~III have not attracted people’s attention in the application research of information fusion and information retrieval. I is internal information fusion (the information element
outside
is fused into
, and
generates
); II is the external information fusion (the information element
in
is fused outside
, and
generates
); III is internal and external information fusion. I and II are two forms of information fusion. Many authors have studied the theory and applications of information fusion (see [
1,
2,
3,
4,
5,
6,
7]). The following new concepts are obtained by re-understanding and re-studying I~III:
. I is -information segmentation;
. II is -information segmentation;
. III is -information segmentation; “Information segmentation” has become a new concept in the application of information fusion.
A number of authors are focusing to find a mathematical model and method with dynamic characteristics to study I~III; in article [
8], the authors propose an inverse packet sets (p-sets) model is given and it also gives the structure of the model; several applications of inverse p-sets are given in [
8,
9,
10,
11,
12]. The inverse p-sets is obtained by introducing the dynamic characteristics into the finite ordinary element set
and improving the finite ordinary element set
. The characteristics of inverse p-sets are exactly the same as facts I~III. Therefore, inverse p-sets is a new mathematical method to study information fusion, information dynamic retrieval and application. Refs. [
13,
14,
15,
16,
17,
18,
19] presented p-sets that are are dual forms of inverse p-sets, and [
20,
21,
22] presented function inverse p-sets as the functional form of inverse p-sets. Function p-sets are the functional forms of p-sets as given in [
23,
24], and they are widely used in dynamic information systems.
The main results of this paper are as follows:
The structure and characteristics of inverse packet sets are introduced, and the fact of the existence of inverse p-sets and its logical characteristics are given, which are important and indispensable.
The concept of information segmentation is given, and their attribute characteristics are discussed.
The intelligent acquisition theorem of information segmentation is given by using inverse p-augmented matrix reasoning;
The equivalence concept and theorem of information segmentation and information fusion are given;
The information fusion intelligent acquisition–retrieval algorithm and its application are presented. Application examples come from the disease diagnostic–treatment block of “Health Big Data”. The conceptual and theoretical results presented in this paper are new.
2. Inverse P-Sets Mathematical Model and Its Dynamic Structure
Given finite ordinary element set
,
is the attribute set of
, and
is referred to as the internal inverse p-sets generated by
,
is called the F-element supplementary set,
If attribute set
of
meets
here, in (3),
and
changes
into
; in (1),
.
Call
the outer inverse p-sets of
,
is called the
-element deletion set of
,
If attribute set
of
meets
here, in (6),
and
changes
into
; and
; in (4),
.
The element set pairs constituted by internal inverse p-sets
and outer inverse p-sets
are called the inverse p-sets generated by
, inverse p-sets for short, and recorded as
Cantor set is referred to as the ground set of inverse packet sets.
From (1)–(3), we have that if
, then
From (4)–(6), we also have that if
, then
From (8) and (9), we obtain
(11) is referred to as the family of inverse p-sets generated by , and (11) is the general expression of inverse packet sets.
From (1)–(11), we obtain the following theorem.
Theorem 1. In the case of, the inverse p-setsand finite common element setmeet: Proof. 1. If , then we have
in (3), ,
in (2), ,
in (1), .
2. if , then in (6), , in (5), , in (4), .
From 1 and 2, we can complete this theorem. □
Theorem 2. In the case of, the inverse p-sets familyand finite common element setmeet: The proof is similar to Theorem 1, and it is omitted.
Proposition 1. Under static dynamic conditions, finite ordinary element setis a special case of inverse p-sets, and inverse p-setsis the general form of finite ordinary element set.
Proposition 2. The dynamic characteristics of the inverse p-setscome from the attribute supplement and attribute deletion in the attribute setof, the opposite is true.
Remark 1. (1)is a finite element domain andis a finite attribute domain;
(2)andare the family of element (attribute) transfer; are element (attribute) transfer, element (attribute) migration is the concept of transformation or function;
(3) The characteristics ofare that for elementchangesinto; for attributechangesinto;
(4) The characteristics ofare that for elementchangesinto; for attributechangesinto;
(5) The dynamic characteristics of (1) are the same as the dynamic characteristics of accumulator;
(6) The dynamic characteristics of (4) are the same as the dynamic characteristic of down-counter. For example, in (1), let,and so forth.
The fact of the existence of inverse p-sets and its logical characteristics.
is a finite set of common elements composed of five children’s toys, is the attribute set of (the color set of the children’s toys), where denotes red color, denotes yellow color, denotes blue color, denotes blue color, and denotes orange color. The attribute of satisfies the “disjunctive” feature in mathematical logic, or the attribute of satisfies ; and ”“ is a “disjunctive” operation.
1. If the attributes
and
are supplemented in
, among them,
denotes black color,
denotes purple color,
generates
then is supplemented with and ,
generates
, the attribute of
is
2. If the attributes
and
are deleted in
,
generates
, then
and
are deleted in
,
generates
, and the attribute of
is
3. If the supplementary attribute and deletion attribute are carried out simultaneously in , generates and at the same time, generates and , or generates ; the attribute of and the attribute of satisfy . This is a simple fact which can be accepted by ordinary people.
Agreement:
in
Section 2. These marks are used in
Section 3,
Section 4,
Section 5 and
Section 6 without special explanation.
3. Information Segmentation and Its Attribute Characteristics
If there exists
meet
then
is the
-information segmentation of information
.
If there are
meet
then
is the
-information segmentation of information
.
The information segmentation pair composed of
and
is called
-information segmentation of information
, recorded as
called
is the
-information segmentation family of information
, and (16) is a general expression of
-information segmentation.
In (13), is the composition of information element supplemented in information ;
In (14), is the composition of the deleted information element in the information .
From (13)–(16), we obtain the following.
Theorem 3. (-information segmentation attribute theorem) Ifis the-information partition of information,andare the attribute set ofand, respectively, then In (17),consists of the attributeadded to.
Proof. From (1)–(3) and (13) in
Section 2,
is the supplementary attribute set in
, or
, we can directly obtained (17). □
Theorem 4. (-information segmentation attribute theorem) Ifis the-information partition of information,andare the attribute set ofand, respectively, then In (18), is the composition of attribute in .
The proof is similar to Theorem 3, and it is omitted.
From Theorems 3 and 4, we can obtain directly the following.
Inference 1. Ifis the-information segmentation of, the attribute setofand the attribute setofmeet In (19), represents ,.
Theorem 5. (Attribute disjunctive extension theorem of-information segmentation) Ifis the-information partition of information, then the attributeof information elementmeets In (20), is the attribute set of information , and is the attribute set of .
Theorem 6. (Attribute disjunctive contraction theorem of-information segmentation) Ifis the-information partition of information, then the attributeof information elementmeets In (21), is the attribute set of information , and is the attribute set of .
Through the fact and logical characteristics of the existence of inverse p-sets in
Section 2. It is easy to prove theorems 5 and 6, and the proof is omitted.
Inference 2. Ifis the attribute set of-information segmentation, thencomposed of attributeof information elementand attributeofmeets
here, (22) represents; in (20)–(22),.
4. Inverse P-Matrix Reasoning and Intelligent Acquisition of -Information Segmentation
If
and
meet
(23) is referred to as internal inverse packet matrix reasoning generated by an internal inverse packet matrix; is referred to as the condition of the internal inverse packet matrix reasoning, and is referred to as the conclusion of the internal inverse packet matrix reasoning.
If
and
meet
(24) is referred to as the outer inverse packet matrix reasoning generated by an outer inverse packet matrix; is referred to as the condition of outer inverse packet matrix reasoning, and is referred to as the conclusion of the outer inverse packet matrix reasoning.
Here, in (23) and (24), “” is equivalent to “”.
If
and
meet
(25) is referred to as the inverse packet matrix reasoning generated by the inverse packet matrix; is referred to as the condition of inverse packet matrix reasoning, and is referred to as the conclusion of the inverse packet matrix reasoning.
From (23)–(25), we obtain the following.
Theorem 7. (-information segmentation intelligent acquisition theorem)
Ifandmeet (23), then we have the following:
1.is segmented outsidefor intelligent acquisition and meets 2. The attribute setofand the attribute setofmeet Proof. 1. If
and
meet
. From (1)–(3) in
Section 2 and (13), supplement the information element
in
to generate
, or
, under the condition of
,
is segmented and intelligently acquired outside
or
, we get (26).
2. With the help of , and the attribute set of and the attribute set of meet , or , we get (27). □
Theorem 8. (-information segmentation intelligent acquisition theorem)
Ifandmeet (24), then we have the following:
1.is segmented and intelligently acquired inand meets 2. The attribute setofand the attribute setofmeet The proof of Theorem 8 is similar to Theorem 7, and the proof is omitted.
Inference 3. If the reasoning conditionof the inverse P-matrix is met, the information segmentationofand the information segmentationofare obtained intelligently at the same time.
Theorem 9. (-information segmentation relation theorem)
Ifis the-information partition chain generated by, thenand its attribute setmeet Proof. meets , directly obtained (30). The attribute set of meets , directly obtained (31). □
Theorem 10. (-information segmentation relation theorem)
Ifis the-information partition chain generated by, thenand its attribute setmeet Theorem 11. (-information segmentation relation theorem)
If, is the -information partition chain generated by, thenand its attribute setmeet Inference 4. The attribute setofand the attribute setofmeet.
Inference 5. The attribute setofand the attribute setofmeet.
Remark 2. Amatrixis given, and supplementcolumns intocolumns of, wherebecomesandis an ordinary augmented matrix of. In the application research of dynamic information system, we often encounter the following:
(1) If deletingcolumns fromcolumns of,,becomes;
(2) Matrix paircomposed ofand. In ordinary mathematics, we cannot find the definition and name ofand. Using the structure of P-sets, the finite ordinary setis given, andis the attribute set of;is called the internal p-sets generated by,is called the outer p-sets generated by , andis called the p-set generated bywhere. If haselement values, takeas the column, thengenerates matrix. Ref. [
25]
gives the following: generates matrix , and generates matrix ; is called the internal p-augmented matrix of ; is called the outer p-augmented matrix of ; and is called the p-augmented matrix of.
is the same concept as an ordinary augmented matrix, where. In Ref. [
26],
an augmented matrix was applied in the information fusion research. By using the research results of Refs. [
25,
27] gives
.
and
are respectively called the internal inverse p-augmented matrix, outer inverse p-augmented matrix and inverse p-augmented matrix of
. Here,
. The reasoning (23)–(25) in
Section 4 can be easily obtained by using the properties of the inverse p-augmented matrix. The properties and applications of the inverse p-augmented matrix are widely discussed in Refs. [
28,
29,
30].
5. Equivalence of Information Segmentation and Information Fusion
If
is the
-fusion coefficient of
and
meets
then
-information segmentation
is the
-information fusion
generated by
.
If
is the
-fusion coefficient of
and
meets
then
-information segmentation
is
-information fusion
generated by
.
If and form a discrete interval , then -information segmentation is -information fusion generated by .
Here , , ,; in (36), ; in (37), ; ; .
Theorem 12. (Interval outer point theorem of-fusion coefficient)
The-fusion coefficientof-information fusionis the outer point of unit discrete interval, and meets Theorem 13. (Interval interior point theorem of-fusion coefficient)
The-fusion coefficientof-information fusionis the interior point of unit discrete interval, and meets Theorem 14. (Interval relation theorem of-fusion coefficient.) The intervalformed by the fusion coefficient of-information fusionand the unit discrete intervalmeet
here, in (38)–(40),is the unit discrete interval of valuesand, andis the fusion coefficient ofitself. Theorem 15. (Equivalence theorem of-information segmentation and-information fusion)-information segmentationand-information fusionare equivalent classes about attribute set Theorem 16. (Equivalence theorem of-information segmentation and-information fusion)-information segmentationand-information fusionare equivalent classes about attribute set Theorem 17. (Equivalence theorem of-information segmentation and-information fusion)-information segmentationand-information fusionare equivalent classes about attribute set Remark 3. The complete concept of “information fusion” is composed of two sub concepts: external information fusion (orinformation fusion) and internal information fusion (orinformation fusion). Informationis given, under certain conditions, the information elementoutsideis migrated into,generates, andis the external information fusiongenerated by,. Under certain conditions, the information elementinis migrated from insideto outside x, andgenerates;is the internal information fusiongenerated by,. In the application research of information fusion, two basic forms of information fusion: information outer fusion and information internal fusion are often encountered. The inverse p-sets given in Section 2 are a dynamic mathematical model for studying information fusion. The concepts of-information segmentationand-information segmentationgiven in Section 3 are obtained through a new understanding of the concept of information fusion. Obviously,-information segmentation and the external information fusion are two equivalent concepts, and-information segmentation and internal information fusion are two equivalent concepts,-information segmentation and-information segmentation are new concepts to study two kinds of information fusion. 6. -Information Fusion Intelligent Acquisition-Intelligent Retrieval Algorithm and Its Application
6.1. -Information Fusion Intelligent Acquisition Intelligent Retrieval Algorithm
In this section, only the
-intelligent fusion intelligent acquisition intelligent retrieval algorithm is given, which is a part of the
-information fusion intelligent acquisition intelligent retrieval algorithm; the complete
-information fusion intelligent acquisition intelligent retrieval algorithm is composed of the
-information fusion intelligent acquisition intelligent retrieval algorithm and
-intelligent fusion intelligent acquisition intelligent retrieval algorithm. The
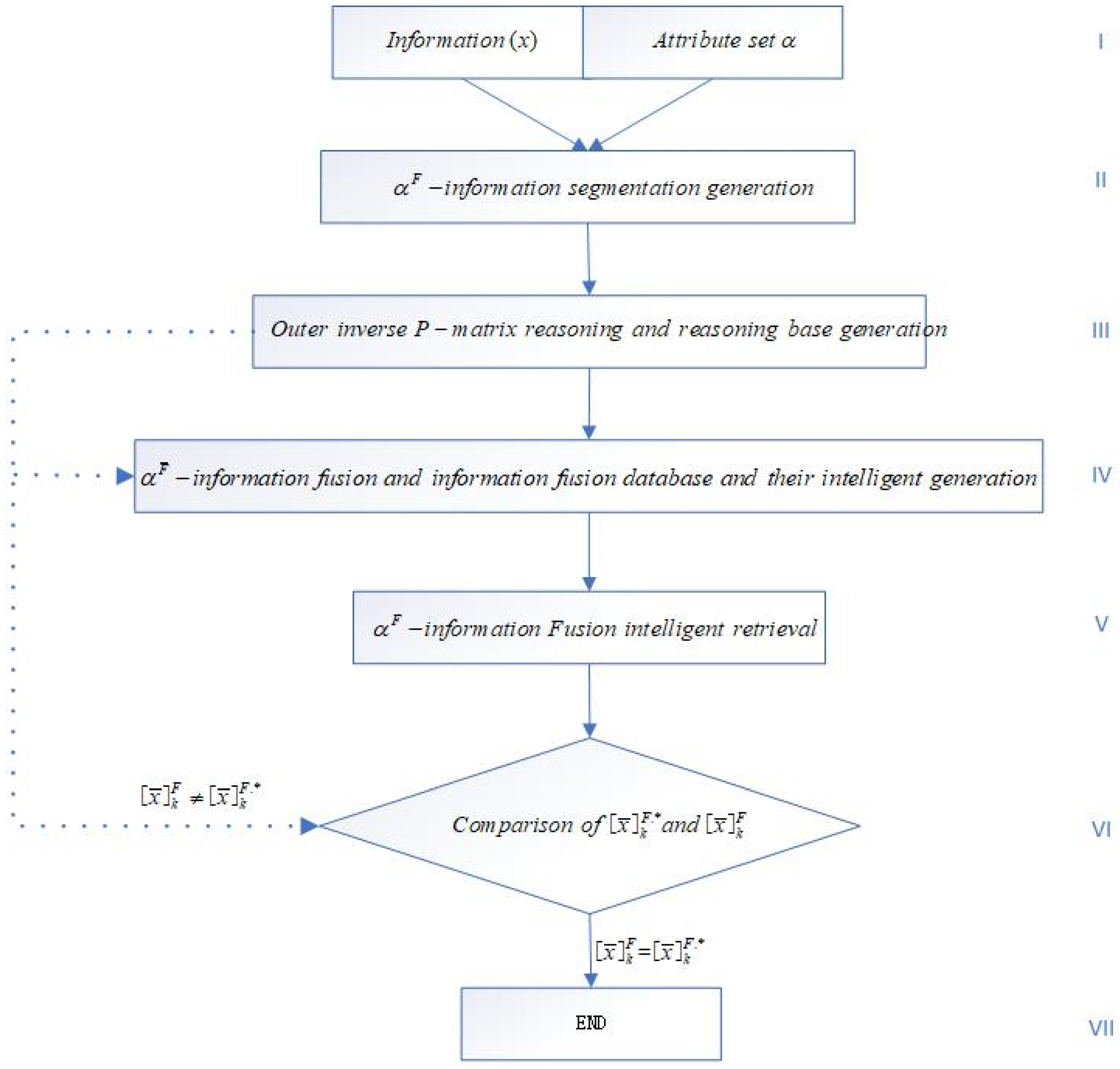
-information fusion intelligent acquisition intelligent retrieval algorithm is shown in
Figure 1.
The detailed process of the algorithm is as follows:
- (1)
Algorithm preparation: information and its attribute set are given;
- (2)
Using information , attribute set generates -information segmentation ;
- (3)
The outer inverse P-matrix reasoning is established: , and the outer inverse P-matrix inference database is generated;
- (4)
-information fusion and the -information fusion database are generated by II and III, ;
- (5)
The -information fusion intelligent retrieval rules are given;
- (6)
Given the standard -information fusion , if , then the algorithm ends; if , return to (3) and (4); repeat (2)–(6). If is satisfied, the algorithm ends.
6.2. Application of -Information Fusion Intelligent Retrieval
In this section, only a simple application of
-information fusion intelligent retrieval is given; the application of
-information fusion intelligent retrieval and
-information fusion intelligent retrieval is omitted; application examples are taken from the “heart disease” block in “health big data”. The concepts and models in
Section 2, the theoretical results in
Section 3,
Section 4 and
Section 5, and the algorithms in
Section 6.1 are applied in this section.
Given information
and its attribute set
,
is the diagnostic value of
(examination value of disease, such as blood pressure, heart rate, etc.).
is composed of patients with “heart disease”, and is the “symptom” (attribute) of ; meets . In order to protect the privacy of patients, patients and symptoms are represented by information element and attribute , respectively; . The attribute of satisfies the attribute disjunctive normal form (22): .
I. In the treatment of
, the symptom
of
disappears and
generates
, where
returns to the standard of healthy people,
disappears from
, and
generates
-information segmentation
, where
generates
in (46), where
and
constitute matrices
and
respectively, from the algorithm in
Section 6.1:
-information segmentation
is intelligently retrieved, obtained in
.
II. In the treatment of
, the symptom
of
disappears and
generates
, where
generates
-information segmentation
, where
-information segmentation is intelligently retrieved and acquired in . entered the ICU ward for treatment.
6.3. Result Authentication in Application Example
The search results (44)–(51) given in the example are accepted and confirmed by medical experts.
7. Discussion
The inverse p-set model with dynamic features and element attributes satisfying attribute extraction feature matches a class of information fusion features. If this kind of information fusion has dynamic characteristics, then the attributes of the information element have the characteristics of attribute extraction. This kind of information fusion is commonly encountered in applied research. The inverse p-set model provides the support of mathematical models and methods for the study of this kind of information fusion and application. Information fusion is a dynamic concept with two forms: internal information fusion and external information fusion. In this paper, a new concept of information segmentation is proposed by using the inverse p-set mathematical model to re-recognize and re-study the concept of information fusion. Many new results can be obtained by using the concept of information segmentation to study information fusion and application, among which what is given in 3–6 is only a part of them.
In this paper, the information fusion intelligent retrieval algorithm and simple application are given on the basis of matrix reasoning. If the results in the paper are further improved, new
-information fusion and
-information fusion are obtained, which are
-information chain fusion and
-information chain fusion, respectively. These new studies are in progress and are obtained from the inverse p-sets family (11) in
Section 2.


{kind=link}
