

Deep 3D Volumetric Model Genesis for Efficient Screening of Lung Infection Using Chest CT Scans

 , , , , ,
, , , , ,
Abstract
:1. Introduction
- -
- A sequence-based 3D model called the “dilated shuffle sequential network” (DSS-Net) is proposed for the automatic and robust diagnosis of COVID-19 using a chest CT volume of variable length.
- -
- A dilated shuffle block (DS-Block) is proposed that is based on multiscale dilated convolution and shuffle operation to explore multiscale contextual features from the input CT volume, which ultimately resulted in improved performance. In addition, all convolutional layers in the proposed model take advantage of the grouped convolution operation to achieve lightweight (1.57 million parameters) characteristics in the context of volumetric data analysis without causing performance degradation.
- -
- The network design uses an input CT volume of variable length rather than employing a fixed-length sequence, and it leverages transfer learning in volumetric data analysis without influencing the overall training parameters.
- -
- The proposed DSS-Net is available to the public on request for research and education.
2. Proposed Method
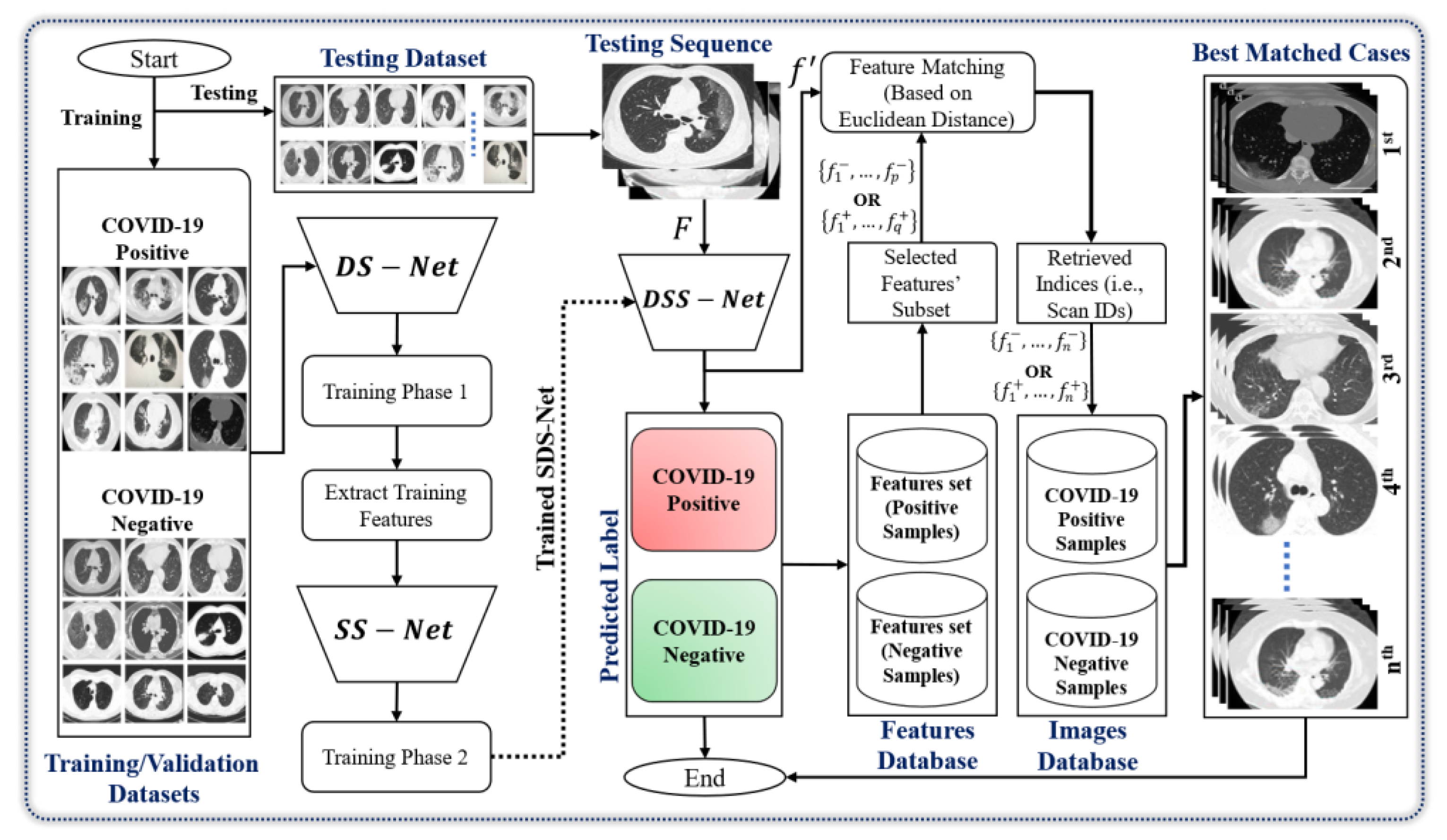
2.1. Workflow Overview
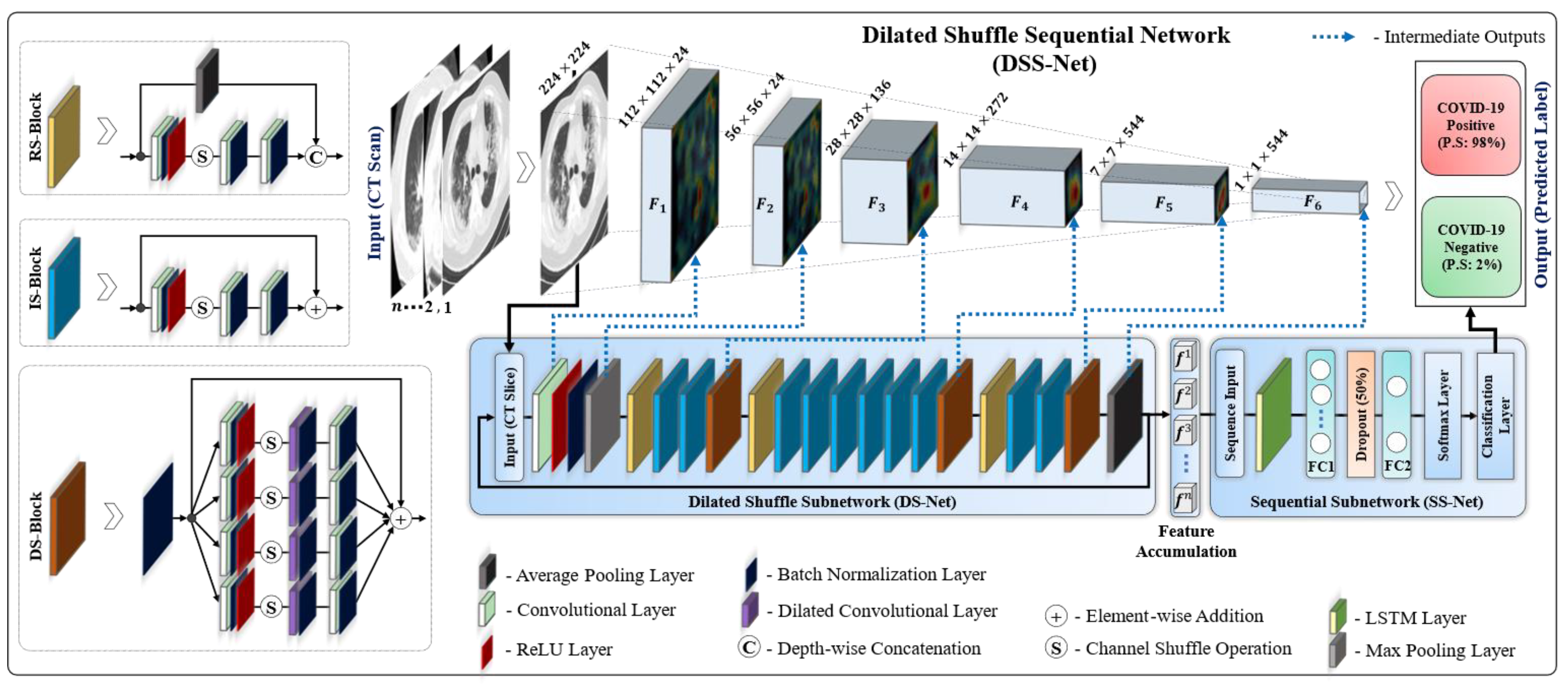
2.2. Dilated Shuffle Sequential Network Structure
2.3. Dilated Shuffle Sequential Network Workflow
2.4. Training Loss
3. Results and Analysis
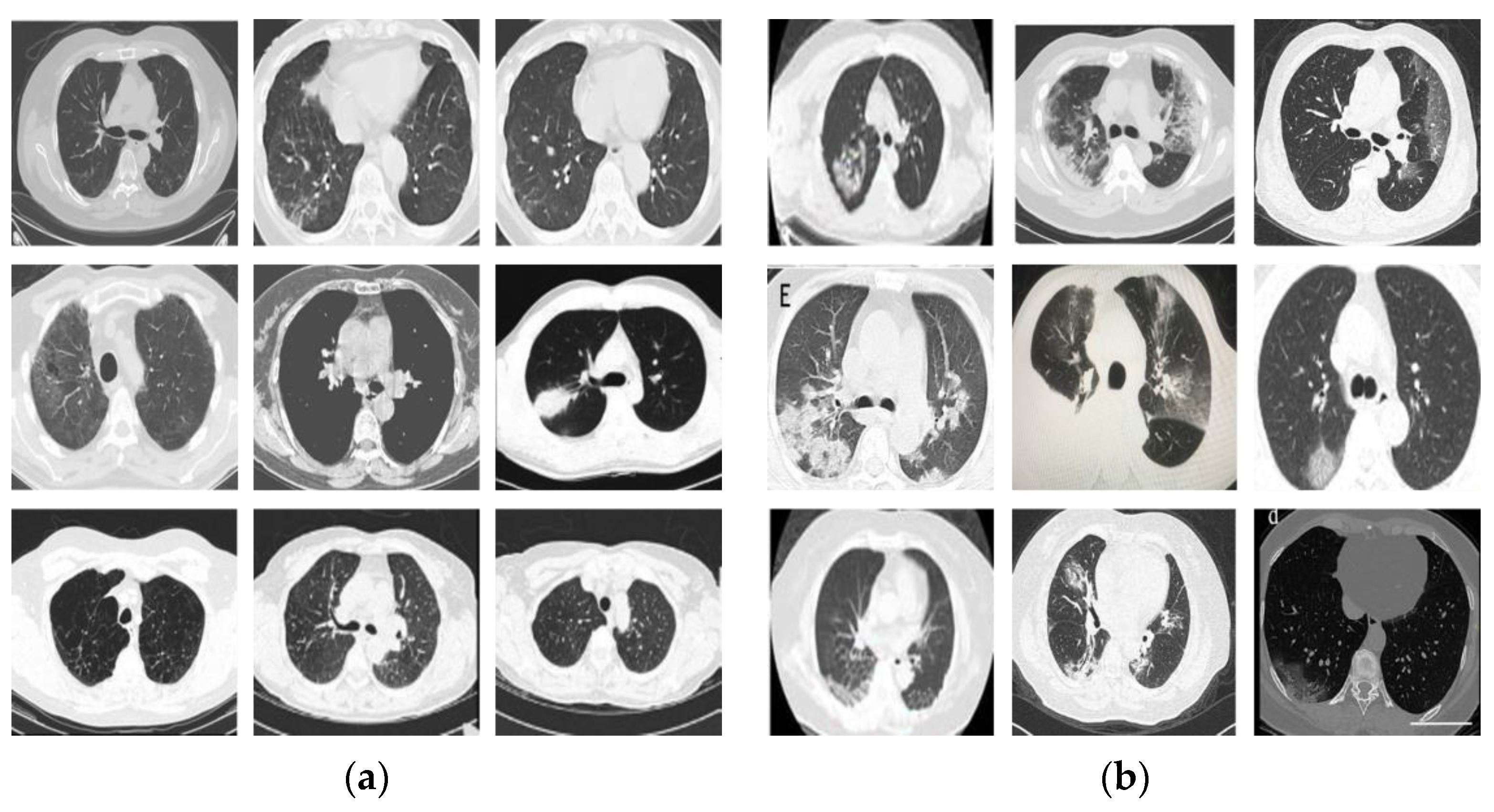
3.1. Dataset and Experimental Setup
| Algorithm 1: Two-step training stop algorithm. | |
| Input: trainable parameters, ,; learning-rate, ; maximum number of epochs, ; training samples denoted as ; and validation samples denoted as | |
| 1 | Initialize trainable parameters (Pretrained weights of [26] for shuffle blocks and Gaussian random weights for remaining blocks/layers), (Gaussian random weights) |
| 2 | /* Step 1: Continue the training of the first DS-Net */ |
| 3 | fordo |
| 4 | get: , |
| 5 | update: |
| 6 | check: if converges do stop the training end |
| 7 | End |
| 8 | Output 1: Learned weights for DS-Net |
| 9 | /* Step 2: Extract features dataset from the avg-pooling layer of DS-Net */ |
| 10 | get: , |
| 11 | Output 2: Training and validation feature dataset:, |
| 12 | /* Step 3: Continue the training of SS-Net */ |
| 13 | fordo |
| 14 | get: , |
| 15 | update: |
| 16 | check: if converges do stop training end |
| 17 | end |
| 18 | Output 3: Learned weights for S-Net |
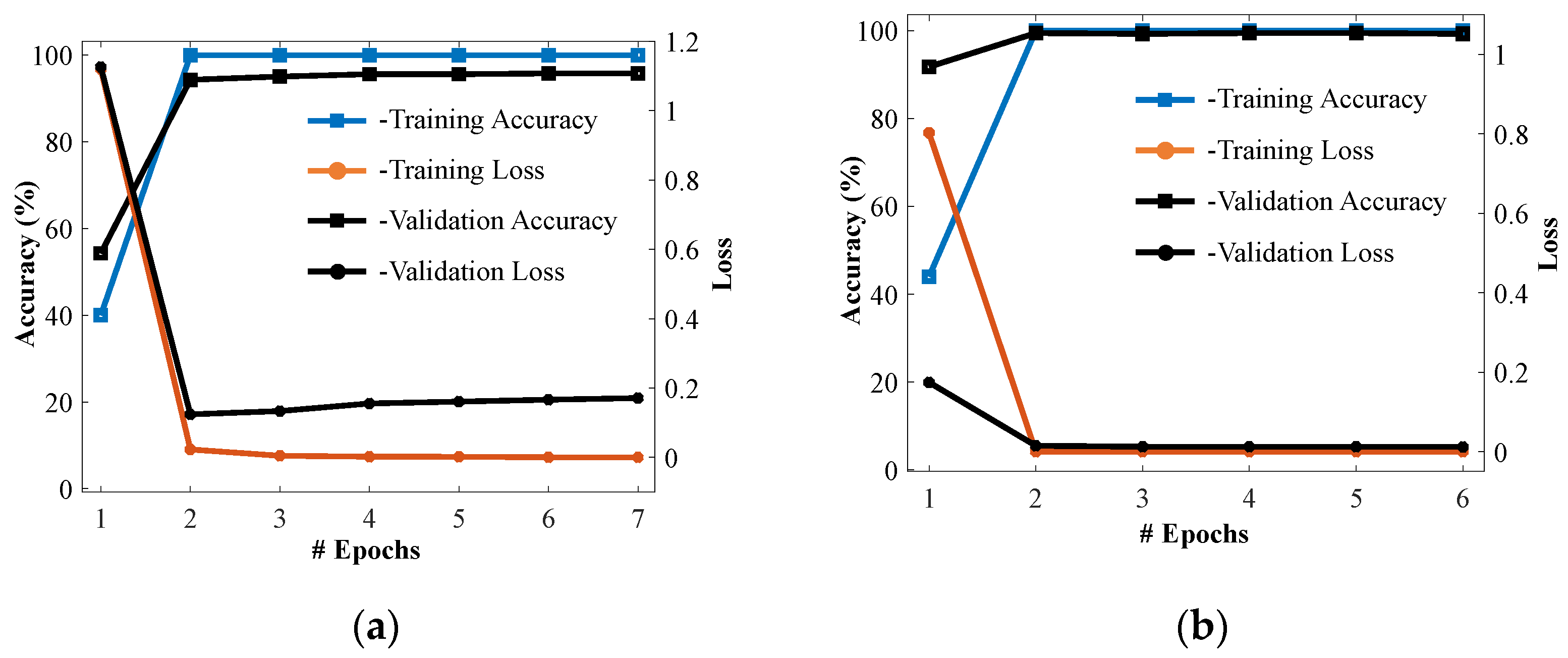
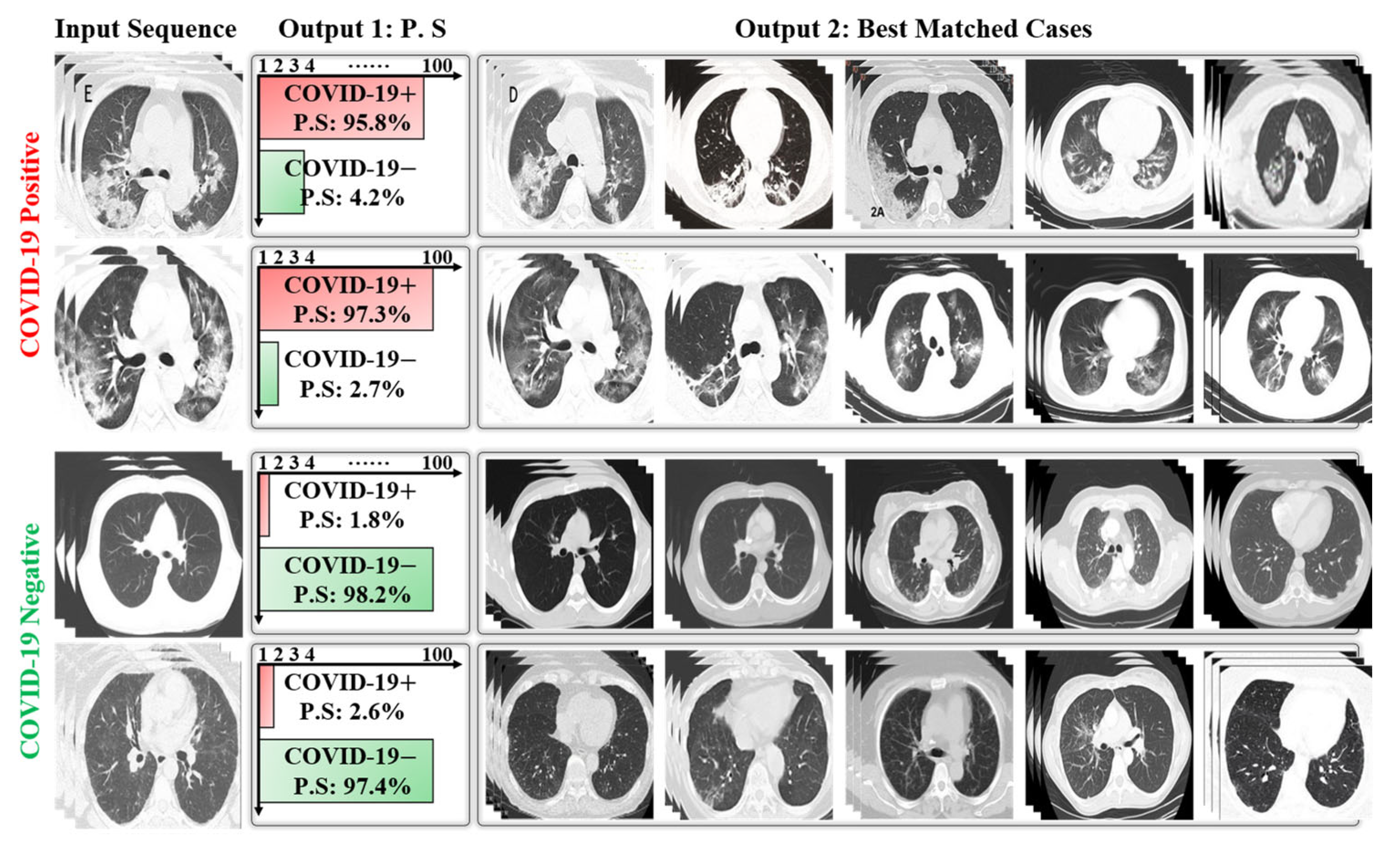
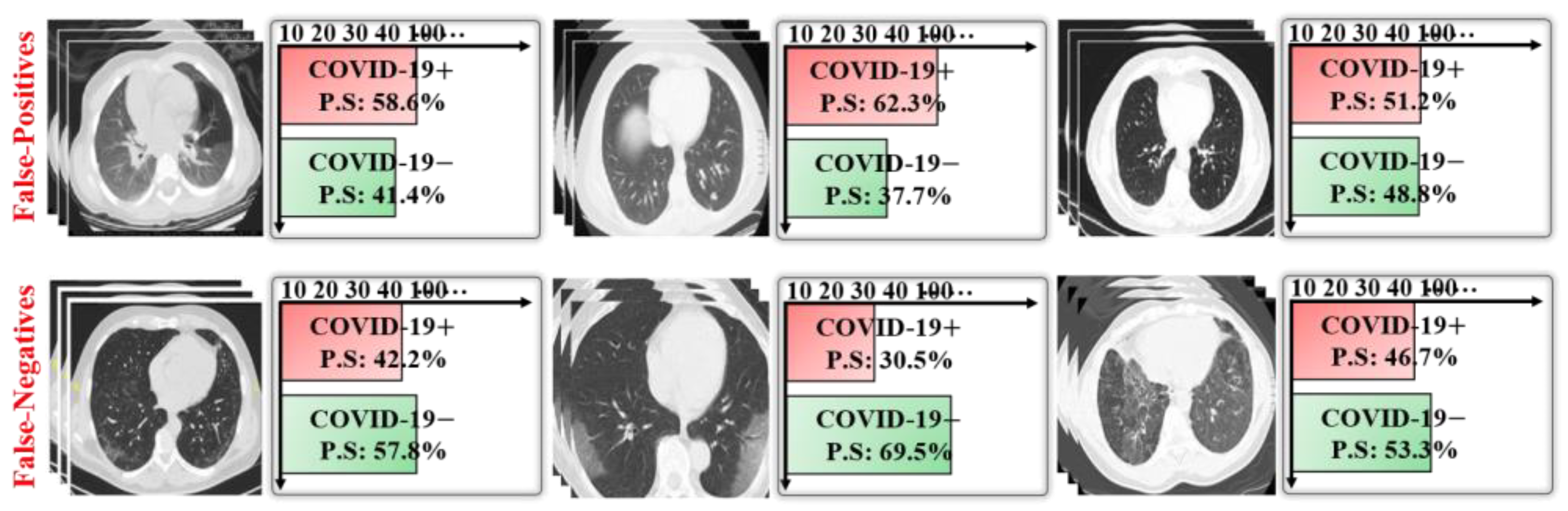
3.2. Testing Results (Ablation Studies)
3.3. Comparison
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Castiglione, A.; Vijayakumar, P.; Nappi, M.; Sadiq, S.; Umer, M. COVID-19: Automatic detection of the novel coronavirus disease from CT images using an optimized convolutional neural network. IEEE Trans. Ind. Inform. 2021, 17, 6480–6488. [Google Scholar] [CrossRef]
- Zhang, M.; Chu, R.; Dong, C.; Wei, J.; Lu, W.; Xiong, N. Residual learning diagnosis detection: An advanced residual learning diagnosis detection system for COVID-19 in industrial internet of things. IEEE Trans. Ind. Inform. 2021, 17, 6510–6518. [Google Scholar] [CrossRef]
- Lan, T.; Cai, Z.; Ye, B. A novel spline algorithm applied to COVID-19 computed tomography image reconstruction. IEEE Trans. Ind. Inform. 2022, 18, 7804–7813. [Google Scholar] [CrossRef]
- Fang, Y.; Zhang, H.; Xie, J.; Lin, M.; Ying, L.; Pang, P.; Ji, W. Sensitivity of chest CT for COVID-19: Comparison to RTPCR. Radiology 2020, 296, 200432. [Google Scholar] [CrossRef]
- Heaton, J. Artificial Intelligence for Humans; Heaton Research, Inc.: Scotts Valley, CA, USA, 2013. [Google Scholar]
- Oh, Y.; Park, S.; Ye, J.C. Deep learning COVID-19 features on CXR using limited training data sets. IEEE Trans Med. Imaging 2020, 39, 2688–2700. [Google Scholar] [CrossRef]
- Singh, D.; Kumar, V.; Kaur, M. Classification of COVID-19 patients from chest CT images using multi-objective differential evolution–based convolutional neural networks. Eur. J. Clin. Microbiol. Infect. Dis. 2020, 39, 1379–1389. [Google Scholar] [CrossRef]
- Jiang, Y.; Chen, H.; Loew, M.H.; Ko, H. COVID-19 CT image synthesis with a conditional generative adversarial network. IEEE J. Biomed. Health Inform. 2021, 25, 441–452. [Google Scholar] [CrossRef]
- Zhang, P.; Zhong, Y.; Deng, Y.; Tang, X.; Li, X. CoSinGAN: Learning COVID-19 infection segmentation from a single radiological image. Diagnostics 2020, 10, 901. [Google Scholar] [CrossRef]
- Fan, D.P.; Zhou, T.; Ji, G.-P.; Zhou, Y.; Chen, G.; Fu, H.; Shen, J.; Shao, L. Inf-net: Automatic COVID-19 lung infection segmentation from CT images. IEEE Trans. Med. Imaging 2020, 39, 2626–2637. [Google Scholar] [CrossRef] [PubMed]
- Tang, S.; Wang, C.; Nie, J.; Kumar, N.; Zhang, Y.; Xiong, Z.; Barnawi, A. EDL-COVID: Ensemble deep learning for COVID-19 case detection from chest x-ray images. IEEE Trans. Ind. Inform. 2021, 17, 6539–6549. [Google Scholar] [CrossRef]
- Kundu, R.; Singh, P.K.; Mirjalili, S.; Sarkar, R. COVID-19 detection from lung CT-Scans using a fuzzy integral-based CNN ensemble. Comput. Biol. Med. 2021, 138, 104895. [Google Scholar] [CrossRef] [PubMed]
- Rajaraman, S.; Siegelman, J.; Alderson, P.O.; Folio, L.S.; Folio, L.R.; Antani, S.K. Iteratively pruned deep learning ensembles for COVID-19 detection in chest X-rays. IEEE Access 2020, 8, 115041–115050. [Google Scholar] [CrossRef]
- Saha, P.; Sadi, M.S.; Islam, M.M. EMCNet: Automated COVID-19 diagnosis from X-ray images using convolutional neural network and ensemble of machine learning classifiers. Inform. Med. Unlocked 2021, 22, 100505. [Google Scholar] [CrossRef]
- El-bana, S.; Al-Kabbany, A.; Sharkas, M. A multi-task pipeline with specialized streams for classification and segmentation of infection manifestations in COVID-19 scans. PeerJ Comput. Sci. 2020, 6, e303. [Google Scholar] [CrossRef]
- Zheng, B.; Liu, Y.; Zhu, Y.; Yu, F.; Jiang, T.; Yang, D.; Xu, T. MSD-Net: Multi-scale discriminative network for COVID-19 lung infection segmentation on CT. IEEE Access 2020, 8, 185786–185795. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Zhou, K.; Zha, M.; Qu, X.; Guo, X.; Chen, H.; Wang, Z.; Xiao, R. An effective deep neural network for lung lesions segmentation from COVID-19 CT images. IEEE Trans. Ind. Inform. 2021, 17, 6528–6538. [Google Scholar] [CrossRef]
- Brunese, L.; Mercaldo, F.; Reginelli, A.; Santone, A. Explainable deep learning for pulmonary disease and coronavirus COVID-19 detection from X-rays. Comput. Meth. Programs Biomed. 2020, 196, 105608. [Google Scholar] [CrossRef] [PubMed]
- Farooq, M.; Hafeez, A. COVID-ResNet: A deep learning framework for screening of COVID19 from radiographs. arXiv 2020, arXiv:2003.14395. [Google Scholar] [CrossRef]
- Minaee, S.; Kafieh, R.; Sonka, M.; Yazdani, S.; Soufi, G.J. Deep-COVID: Predicting COVID-19 from chest X-ray images using deep transfer learning. Med. Image Anal. 2020, 65, 101794. [Google Scholar] [CrossRef]
- Khan, I.U.; Aslam, N. A deep-learning-based framework for automated diagnosis of COVID-19 using X-ray images. Information 2020, 11, 419. [Google Scholar] [CrossRef]
- Alsharman, N.; Jawarneh, I. GoogleNet CNN neural network towards chest CT-coronavirus medical image classification. J. Comput. Sci. 2020, 16, 620–625. [Google Scholar] [CrossRef]
- Misra, S.; Kafieh, R.; Sonka, M.; Yazdani, S.; Soufi, G.J. Multi-channel transfer learning of chest X-ray images for screening of COVID-19. Electronics 2020, 9, 1388. [Google Scholar] [CrossRef]
- Hu, R.; Ruan, G.; Xiang, S.; Huang, M.; Liang, Q.; Li, J. Automated diagnosis of COVID-19 using deep learning and data augmentation on chest CT. medRxiv 2020. [Google Scholar] [CrossRef]
- Ardakani, A.A.; Kanafi, A.R.; Acharya, U.R.; Khadem, N.; Mohammadi, A. Application of deep learning technique to manage COVID-19 in routine clinical practice using CT images: Results of 10 convolutional neural networks. Comput. Biol. Med. 2020, 121, 103795. [Google Scholar] [CrossRef] [PubMed]
- Apostolopoulos, I.D.; Mpesiana, T.A. COVID-19: Automatic detection from X-ray images utilizing transfer learning with convolutional neural networks. Australas. Phys. Eng. Sci. Med. 2020, 43, 635–640. [Google Scholar] [CrossRef] [Green Version]
- Martínez, F.; Martínez, F.; Jacinto, E. Performance evaluation of the NASNet convolutional network in the automatic identification of COVID19. Int. J. Adv. Sci. Eng. Inf. Techn. 2020, 10, 662–667, 662. [Google Scholar] [CrossRef]
- Jaiswal, A.; Gianchandani, N.; Singh, D.; Kumar, V.; Kaur, M. Classification of the COVID-19 infected patients using densenet201 based deep transfer learning. J. Biomol. Struct. Dyn. 2021, 39, 5682–5689. [Google Scholar] [CrossRef]
- Owais, M.; Yoon, H.S.; Mahmood, T.; Haider, A.; Sultan, H.; Park, K.R. Light-weighted ensemble network with multilevel activation visualization for robust diagnosis of COVID19 pneumonia from large-scale chest radiographic database. Appl. Soft Comput. 2021, 108, 107490. [Google Scholar] [CrossRef] [PubMed]
- Tsiknakis, N.; Trivizakis, E.; Vassalou, E.E.; Papadakis, G.Z.; Spandidos, D.A.; Tsatsakis, A.; Sánchez-García, J.; López-González, R.; Papanikolaou, N.; Karantanas, A.H.; et al. Interpretable artificial intelligence framework for COVID-19 screening on chest X-rays. Exp. Ther. Med. 2020, 20, 727–735. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Name | Input Size | Filter Size | Filter Depth(R) | Str. | Itr. | Output Size |
|---|---|---|---|---|---|---|
| Input | 224 × 224 | – | – | – | 1 | – |
| Conv | 224 × 224 × 3 | 3 × 3 | 24 | 2 | 1 | 112 × 112 × 24 |
| Max-pooling | 112 × 112 × 24 | 3 × 3 | 1 | 2 | 1 | 56 × 56 × 24 |
| RS block | 56 × 56 × 24 | 1 × 1, 3 × 3, 1 × 1 3 × 3 | 112, 112, 112 1 | 1, 2, 1 2 | 1 | 28 × 28 × 136 |
| IS block | 28 × 28 × 136 | 1 × 1, 3 × 3, 1 × 1 | 136, 136, 136 | 1, 1, 1 | 2 | 28 × 28 × 136 |
| DS block | 28 × 28 × 136 | 1 × 1, 3 × 3, 1 × 1 1 × 1, 3 × 3, 1 × 1 1 × 1, 3 × 3, 1 × 1 1 × 1, 3 × 3, 1 × 1 | 136, 136, 136(1) 136, 136, 136(3) 136, 136, 136(5) 136, 136, 136(7) | 1, 1, 1 1, 1, 1 1, 1, 1 1, 1, 1 | 1 | 28 × 28 × 136 |
| RS block | 28 × 28 × 136 | 1 × 1, 3 × 3, 1 × 1 3 × 3 | 136, 136, 136 1 | 1, 2, 1 2 | 1 | 14 × 14 × 272 |
| IS block | 14 × 14 × 272 | 1 × 1, 3 × 3, 1 × 1 | 272, 272, 272 | 1, 1, 1 | 6 | 14 × 14 × 272 |
| DS block | 14 × 14 × 272 | 1 × 1, 3 × 3, 1 × 1 1 × 1, 3 × 3, 1 × 1 1 × 1, 3 × 3, 1 × 1 1 × 1, 3 × 3, 1 × 1 | 272, 272, 272(1) 272, 272, 272(3) 272, 272, 272(5) 272, 272, 272(7) | 1, 1, 1 1, 1, 1 1, 1, 1 1, 1, 1 | 1 | 14 × 14 × 272 |
| RS block | 14 × 14 × 272 | 1 × 1, 3 × 3, 1 × 1 3 × 3 | 272, 272, 272 1 | 1, 2, 1 2 | 1 | 7 × 7 × 544 |
| IS block | 7 × 7 × 544 | 1 × 1, 3 × 3, 1 × 1 | 544, 544, 544 | 1, 1, 1 | 2 | 7 × 7 × 544 |
| DS block | 7 × 7 × 544 | 1 × 1, 3 × 3, 1 × 1 1 × 1, 3 × 3, 1 × 1 1 × 1, 3 × 3, 1 × 1 1 × 1, 3 × 3, 1 × 1 | 544, 544, 544(1) 544, 544, 544(3) 544, 544, 544(5) 544, 544, 544(7) | 1, 1, 1 1, 1, 1 1, 1, 1 1, 1, 1 | 1 | 7 × 7 × 544 |
| Avg-pooling | 7 × 7 × 544 | 7 × 7 | 1 | 1 | 1 | 1 × 1 × 544 |
| Sequence Input | 1 × 1 × 544 × n | – | – | – | 1 | – |
| LSTM | 1 × 1 × 544 × n | – | – | – | 1 | 1 × 1 × 600 |
| FC1 | 1 × 1 × 600 | – | 128N | 1 × 1 × 128 | ||
| Dropout (50%) | 1 × 1 × 128 | – | – | – | 1 | 1 × 1 × 128 |
| FC2 | 1 × 1 × 128 | – | 2N | – | 1 | 1 × 1 × 2 |
| Softmax | 1 × 1 × 2 | – | – | – | 1 | 1 × 1 × 2 |
| Classification | 1 × 1 × 2 | – | – | – | 1 | 2 |
| Model | #Fold | ACC | F1 | AP | AR | AUC |
|---|---|---|---|---|---|---|
| Shuffle Network (S-Net) [26] | 1 | 96.07 | 96.02 | 95.63 | 96.4 | 99.46 |
| 2 | 92.69 | 92.41 | 93.03 | 91.8 | 97.94 | |
| 3 | 89.76 | 89.49 | 90.94 | 88.08 | 94.72 | |
| 4 | 97.63 | 97.54 | 97.6 | 97.47 | 99.71 | |
| 5 | 82.1 | 82.16 | 86.23 | 78.47 | 86.23 | |
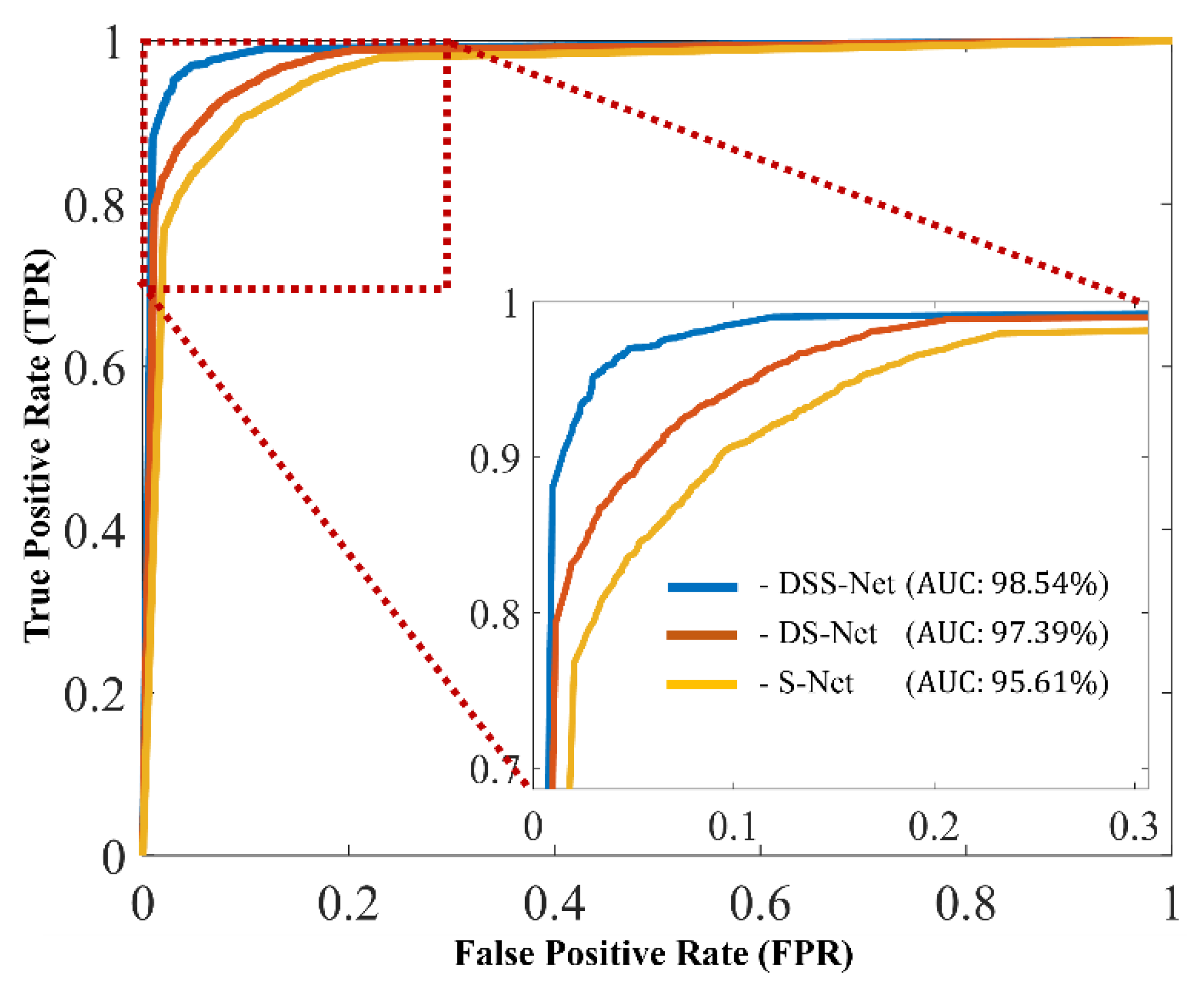
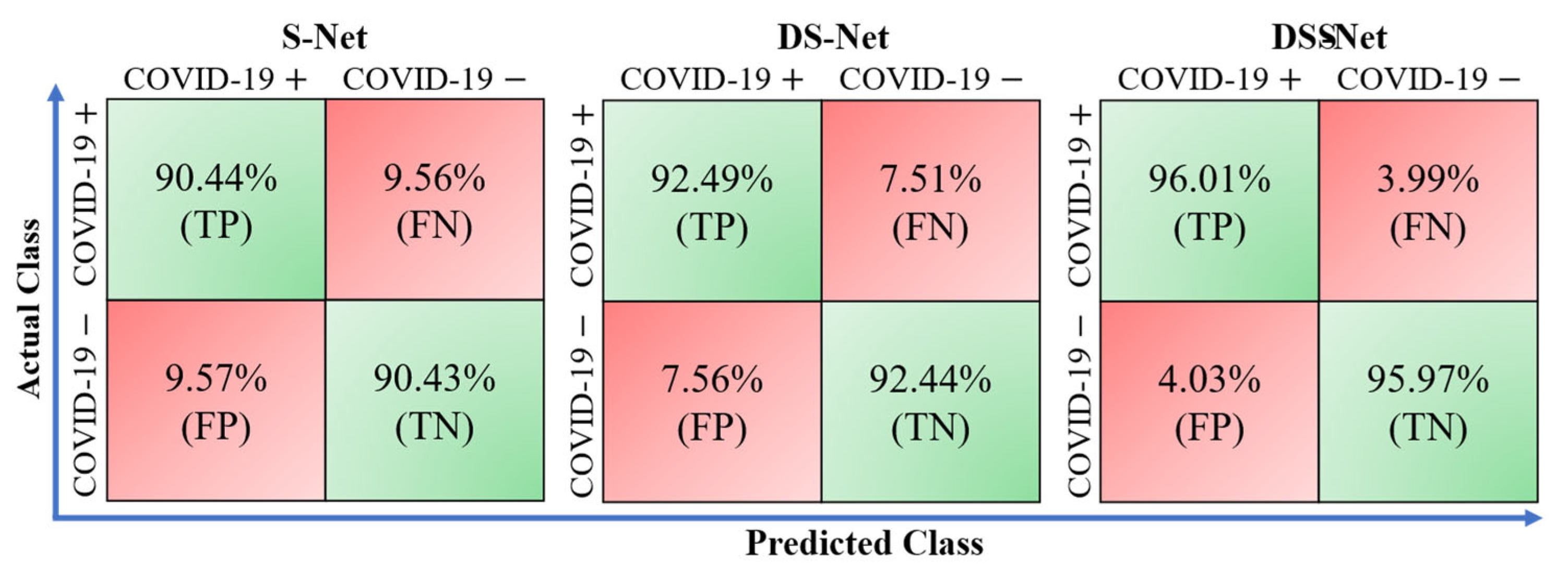
| Avg. (Std) | 91.65 (6.15) | 91.52 (6.10) | 92.69 (4.41) | 90.44 (7.68) | 95.61 (5.61) | |
| Dilated Shuffle Subnetwork (DS-Net) | 1 | 95.79 | 95.66 | 95.5 | 95.81 | 98.64 |
| 2 | 94.33 | 94.16 | 94.89 | 93.44 | 98.54 | |
| 3 | 89.95 | 89.62 | 90.82 | 88.45 | 96.22 | |
| 4 | 96.07 | 95.92 | 96.04 | 95.8 | 99.11 | |
| 5 | 90.41 | 90.13 | 91.36 | 88.93 | 94.43 | |
| Avg. (Std) | 93.31 (2.94) | 93.1 (3.02) | 93.72 (2.44) | 92.49 (3.60) | 97.39 (2.00) | |
| Dilated Shuffle Sequential Network (DSS-Net) | 1 | 99.36 | 99.34 | 99.25 | 99.43 | 99.99 |
| 2 | 97.17 | 97.06 | 97.18 | 96.93 | 99.59 | |
| 3 | 94.88 | 94.77 | 95.65 | 93.9 | 98.24 | |
| 4 | 98.81 | 98.77 | 98.72 | 98.82 | 99.75 | |
| 5 | 92.69 | 92.73 | 94.53 | 90.99 | 95.14 | |
| Avg (Std) | 96.58 (2.79) | 96.53 (2.77) | 97.07 (2.00) | 96.01 (3.54) | 98.54 (2.02) |
| Model | T.L | ACC (Std) | F1 (Std) | AP (Std) | AR (Std) | AUC (Std) |
|---|---|---|---|---|---|---|
| Dilated Shuffle Subnetwork (DS-Net) | ✕ | 83.44 (11.11) | 82.78 (11.53) | 84.82 (9.6) | 80.96 (13.31) | 86.79 (12.53) |
| ✓ | 93.31 (2.94) | 93.1 (3.02) | 93.72 (2.44) | 92.49 (3.60) | 97.39 (2.00) | |
| Dilated Shuffle Sequential Network (DSS-Net) | ✕ | 88.61 (12.91) | 89.06 (12.21) | 92.44 (7.36) | 86.35 (16.17) | 87.69 (16.51) |
| ✓ | 96.58 (2.79) | 96.53 (2.77) | 97.07 (2.00) | 96.01 (3.54) | 98.54 (2.02) |
| Study | #Par. (M) | ACC | F1 | AP | AR | AUC |
|---|---|---|---|---|---|---|
| Brunese et al. [18] | 134.27 | 89.66 | 89.54 | 91.43 | 87.81 | 92.35 |
| Farooq et al. [19] | 23.54 | 90.30 | 90.22 | 92.17 | 88.53 | 92.79 |
| Minaee et al. [20] | 1.24 | 89.84 | 89.48 | 89.91 | 89.06 | 93.86 |
| Khan et al. [21] | 139.58 | 91.54 | 91.33 | 92.26 | 90.47 | 94.54 |
| Alsharman et al. [22] | 5.98 | 89.73 | 89.53 | 90.4 | 88.73 | 94.91 |
| Misra et al. [23] | 11.18 | 92.96 | 92.76 | 93.41 | 92.14 | 95.06 |
| Hu et al. [24] | 0.86 | 91.65 | 91.52 | 92.69 | 90.44 | 95.61 |
| Ardakani et al. [25] | 42.56 | 90.30 | 90.26 | 92.17 | 88.64 | 95.71 |
| Apostolopoulos et al. [26] | 2.24 | 92.95 | 92.85 | 93.81 | 91.94 | 96.51 |
| Martínez et al. [27] | 4.27 | 93.68 | 93.49 | 94.19 | 92.82 | 96.67 |
| Jaiswal et al. [28] | 18.11 | 94.17 | 94.03 | 94.63 | 93.46 | 97.36 |
| Owais et al. [29] | 3.16 | 94.72 | 94.60 | 95.22 | 94.00 | 97.50 |
| Tsiknakis et al. [30] | 21.81 | 94.57 | 94.41 | 94.89 | 93.94 | 97.93 |
| Proposed | 1.57 | 96.58 | 96.53 | 97.07 | 96.01 | 98.54 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Owais, M.; Sultan, H.; Baek, N.R.; Lee, Y.W.; Usman, M.; Nguyen, D.T.; Batchuluun, G.; Park, K.R. Deep 3D Volumetric Model Genesis for Efficient Screening of Lung Infection Using Chest CT Scans. Mathematics 2022, 10, 4160. https://doi.org/10.3390/math10214160
Owais M, Sultan H, Baek NR, Lee YW, Usman M, Nguyen DT, Batchuluun G, Park KR. Deep 3D Volumetric Model Genesis for Efficient Screening of Lung Infection Using Chest CT Scans. Mathematics. 2022; 10(21):4160. https://doi.org/10.3390/math10214160
Chicago/Turabian StyleOwais, Muhammad, Haseeb Sultan, Na Rae Baek, Young Won Lee, Muhammad Usman, Dat Tien Nguyen, Ganbayar Batchuluun, and Kang Ryoung Park. 2022. "Deep 3D Volumetric Model Genesis for Efficient Screening of Lung Infection Using Chest CT Scans" Mathematics 10, no. 21: 4160. https://doi.org/10.3390/math10214160