
Deep Neural Network Memory Performance and Throughput Modeling and Simulation Framework

Abstract
:1. Introduction
- While GPU processing elements are programable and execute the same operation simultaneously, SA processing elements can only execute a fixed operation (usually a multiply-and-accumulate).
- Unlike the SA, however, the processing elements in GPUs cannot pass data directly but, rather, must exchange data via memory. This introduces a major benefit for the SA, since it utilizes memory bandwidth more efficiently.
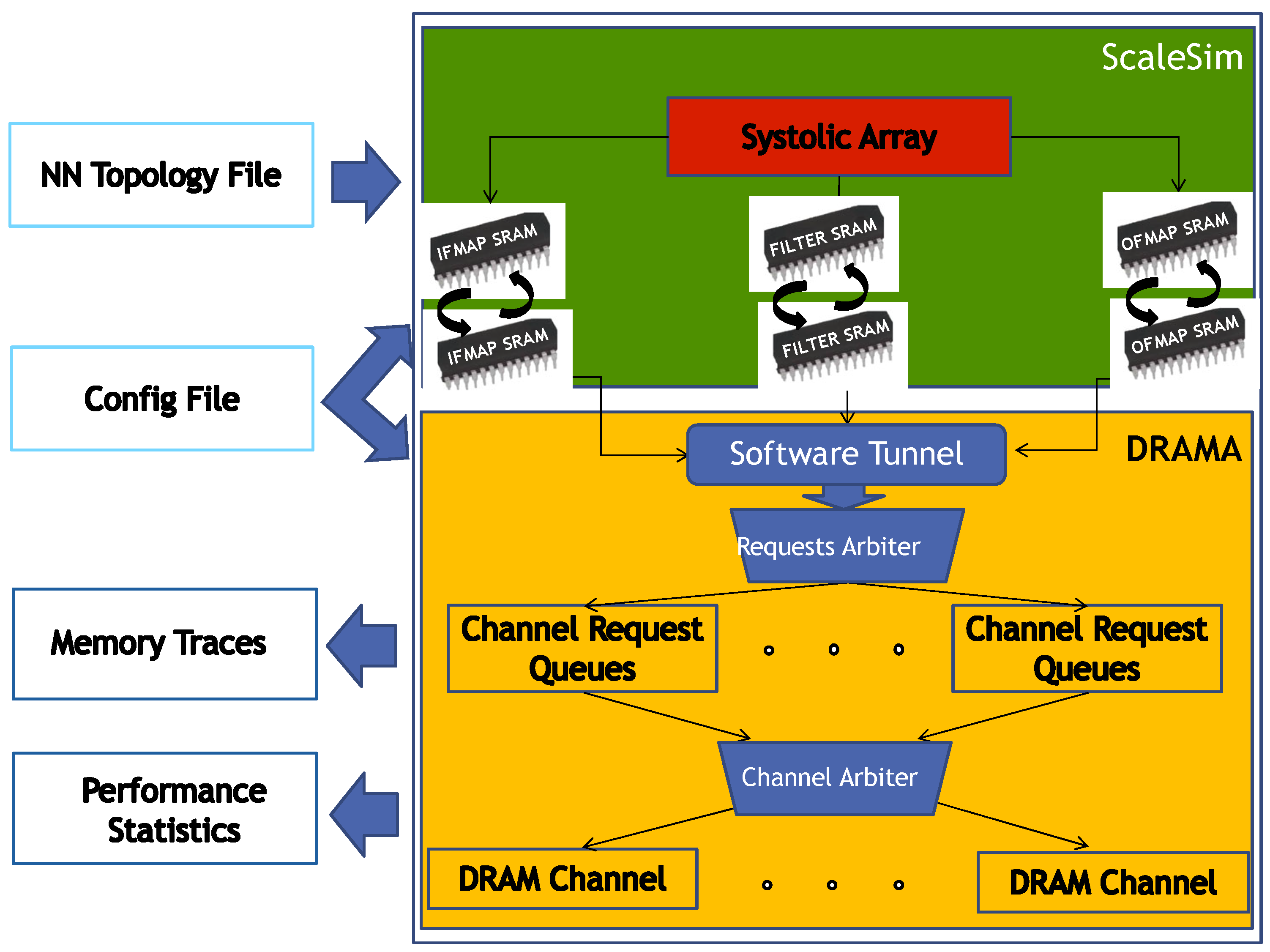
- We introduce DRAMA, a novel open-source simulation environment that can perform detailed, accurate, and extensive simulation of SA memory systems.
- DRAMA can run either as an extension to the SCALE-Sim simulator to model the entire memory system accurately or as a standalone main memory simulator.
- DRAMA offers a broad range of configuration parameters, which can help to perform an accurate memory system exploration for DNNs and to understand the interplay between key memory system parameters.
- DRAMA generates an accurate main memory trace file that takes into account main memory system configuration and related timing parameters.
- We demonstrate the impact of memory system parameters on SA performance and memory system throughput through an experimental analysis of several case studies.
2. Background and Prior Works
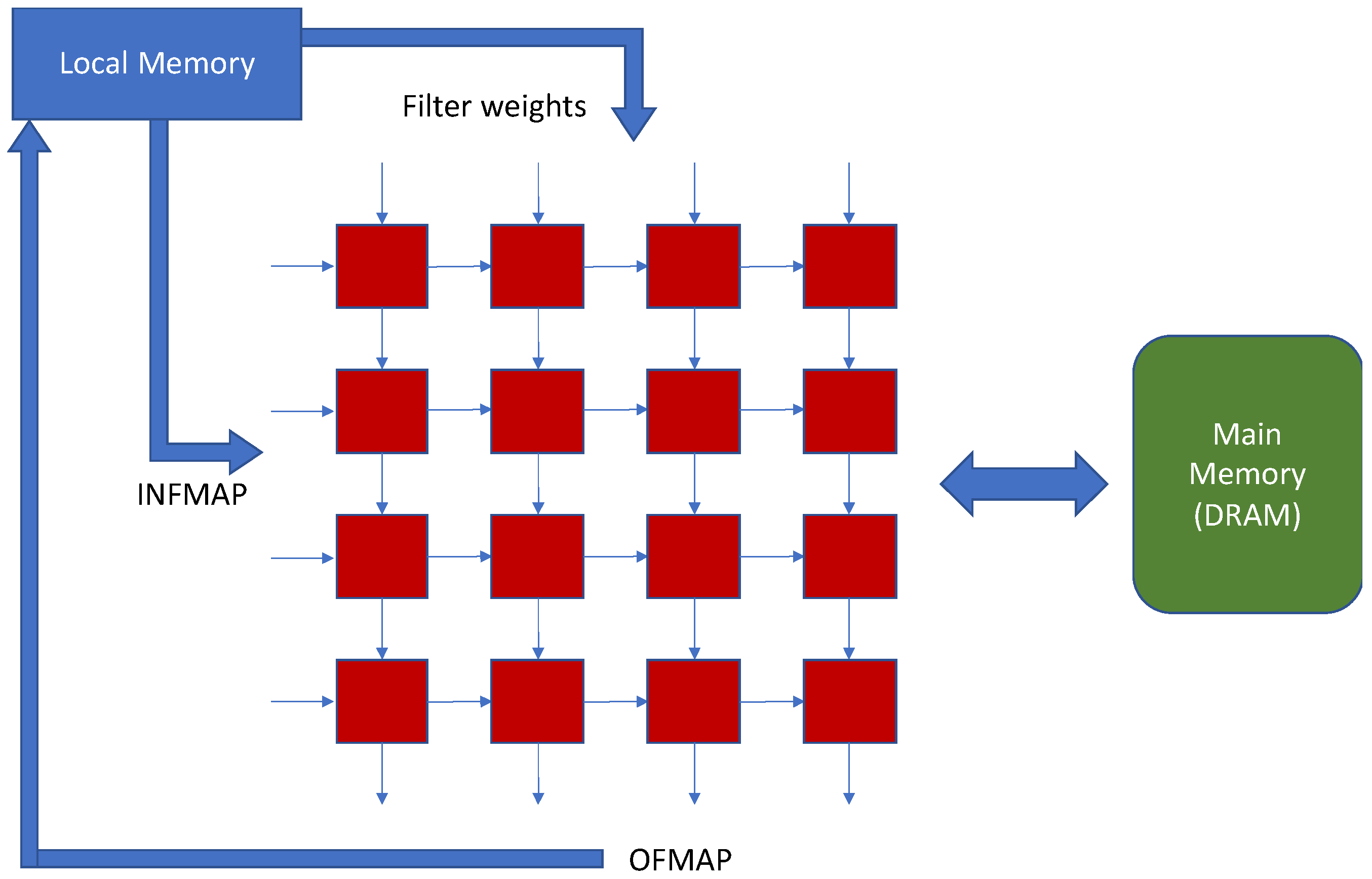
2.1. Systolic Arrays
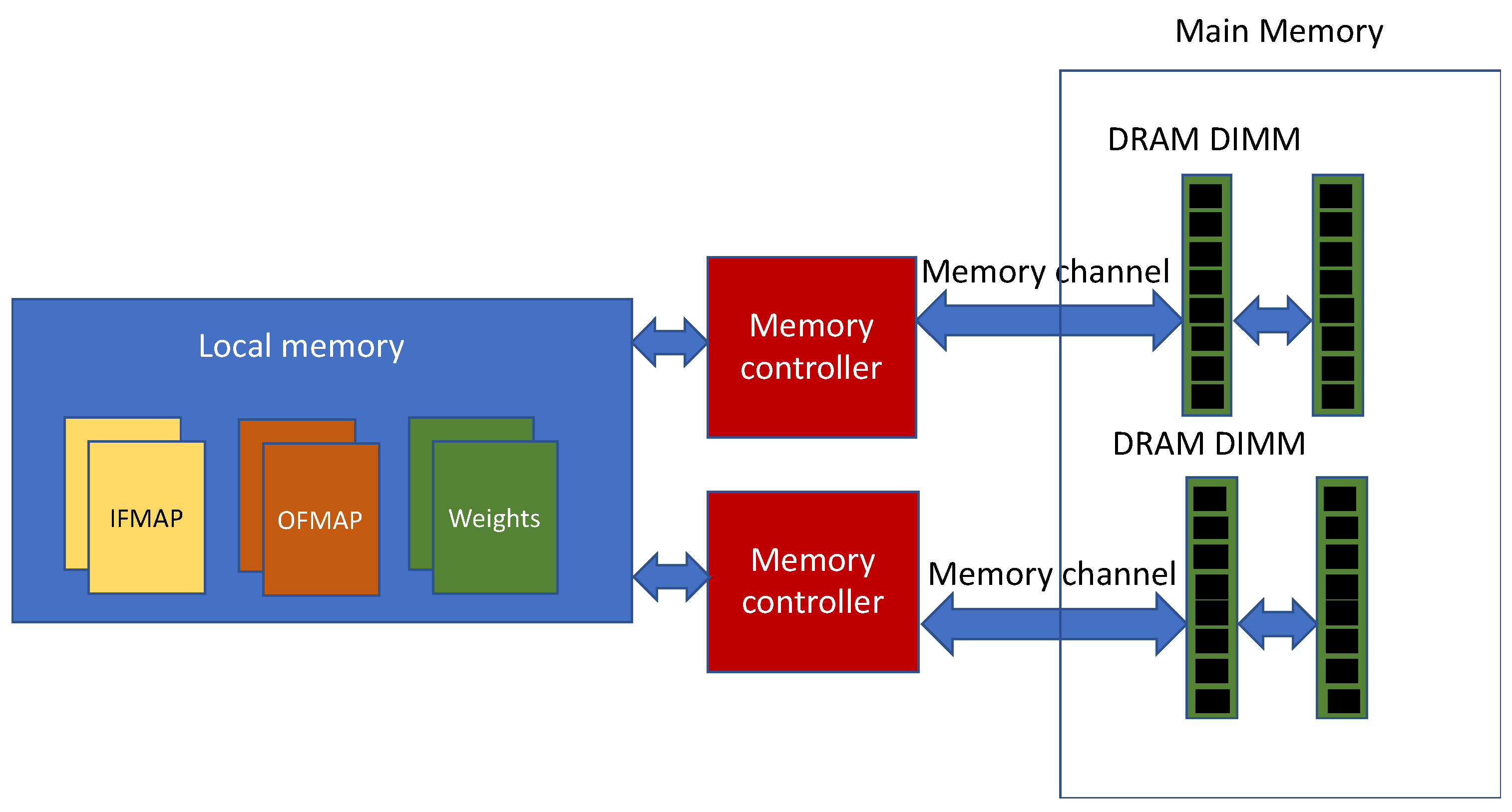
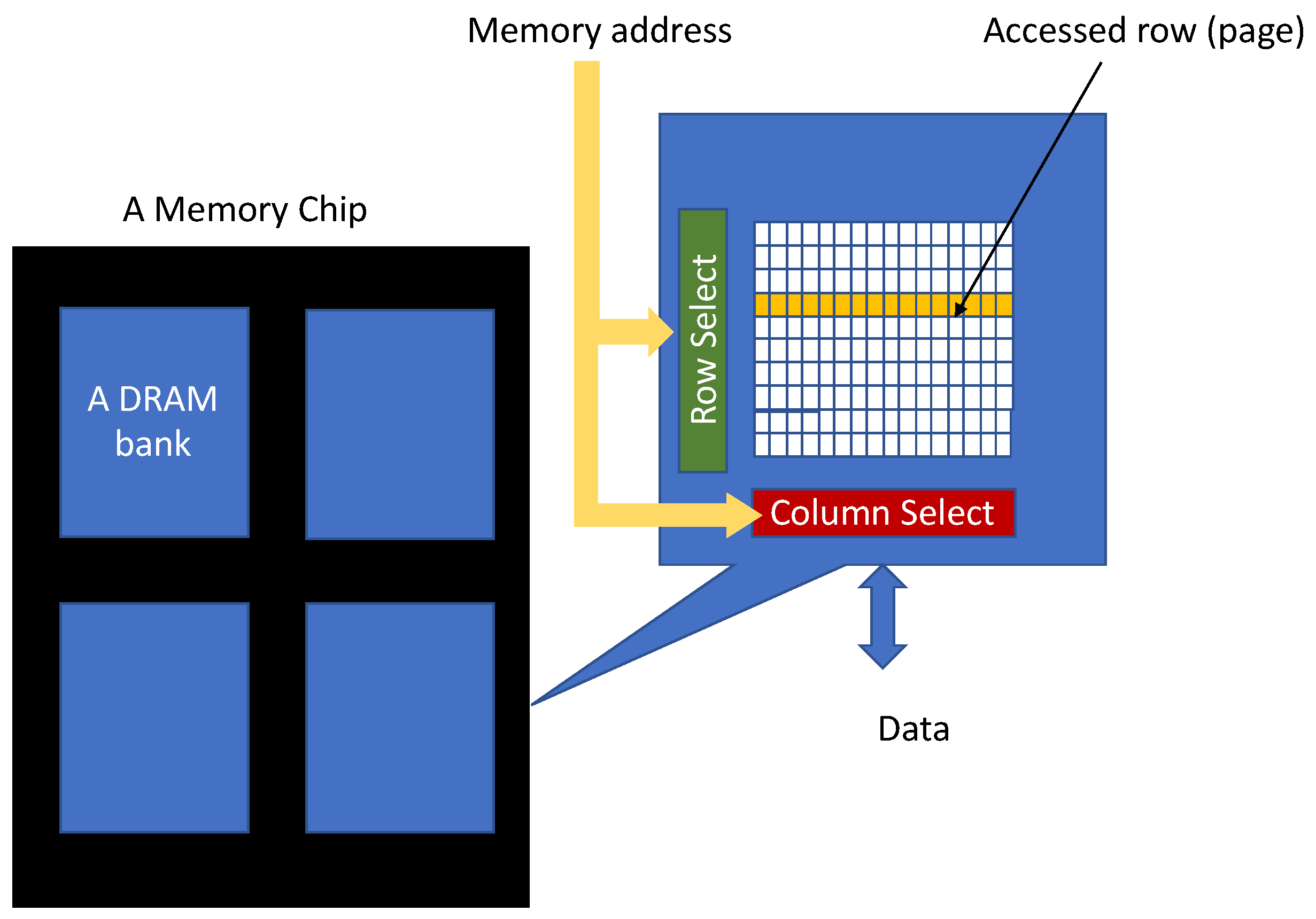
2.2. Memory System
2.3. SCALE-Sim
2.4. Prior Related Simulation Environments
- DRAM can be integrated with SA simulators, such as SCALE-Sim.
- While many of the existing simulators are tightly coupled to specific standards, DRAMA allows flexible memory system configuration.
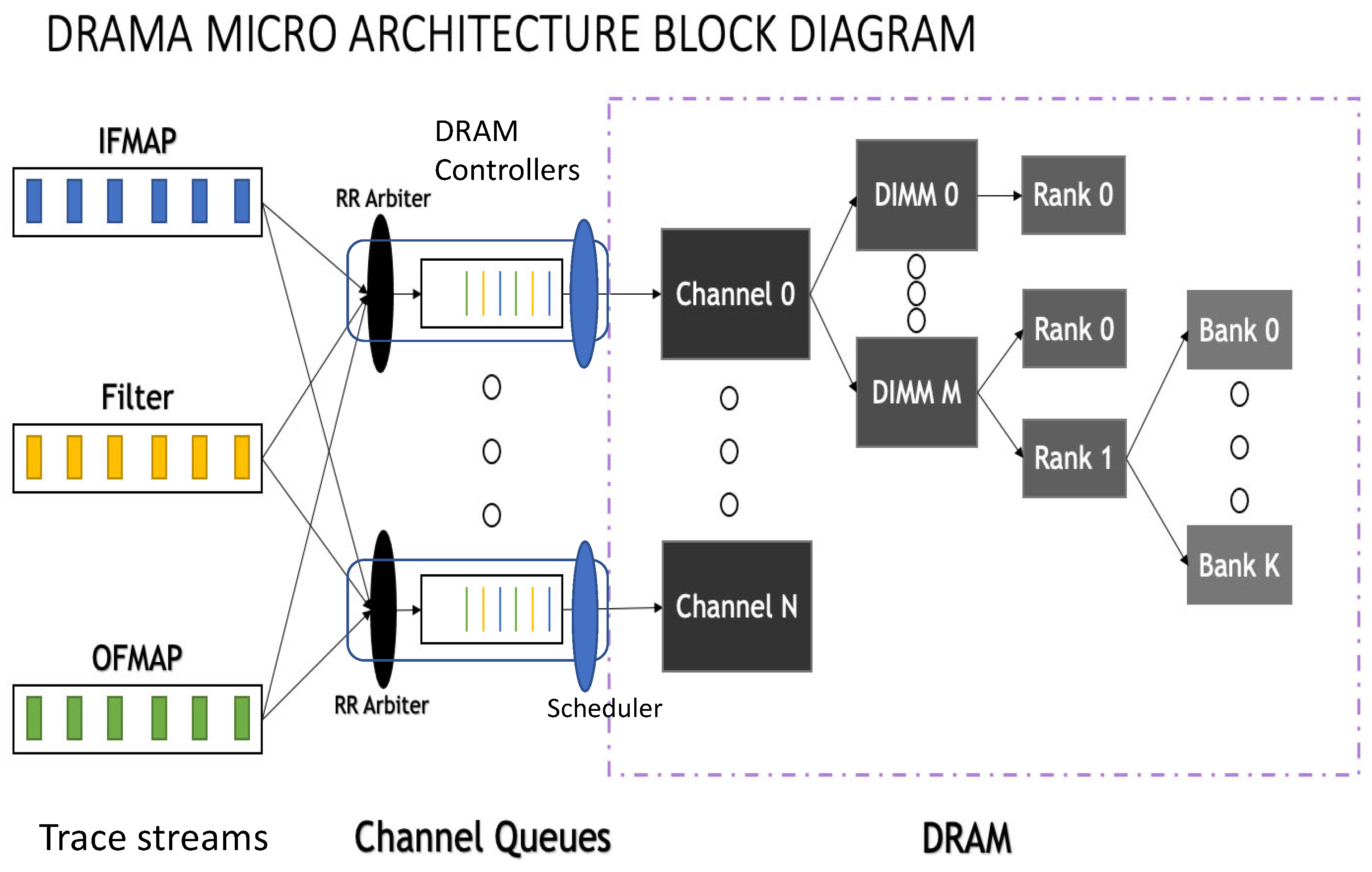
- DRAMA supports multiple memory channels topology, while many of the prior work simulation environments are limited to a single channel or a single DRAM.
3. DRAMA Simulation Environment Framework
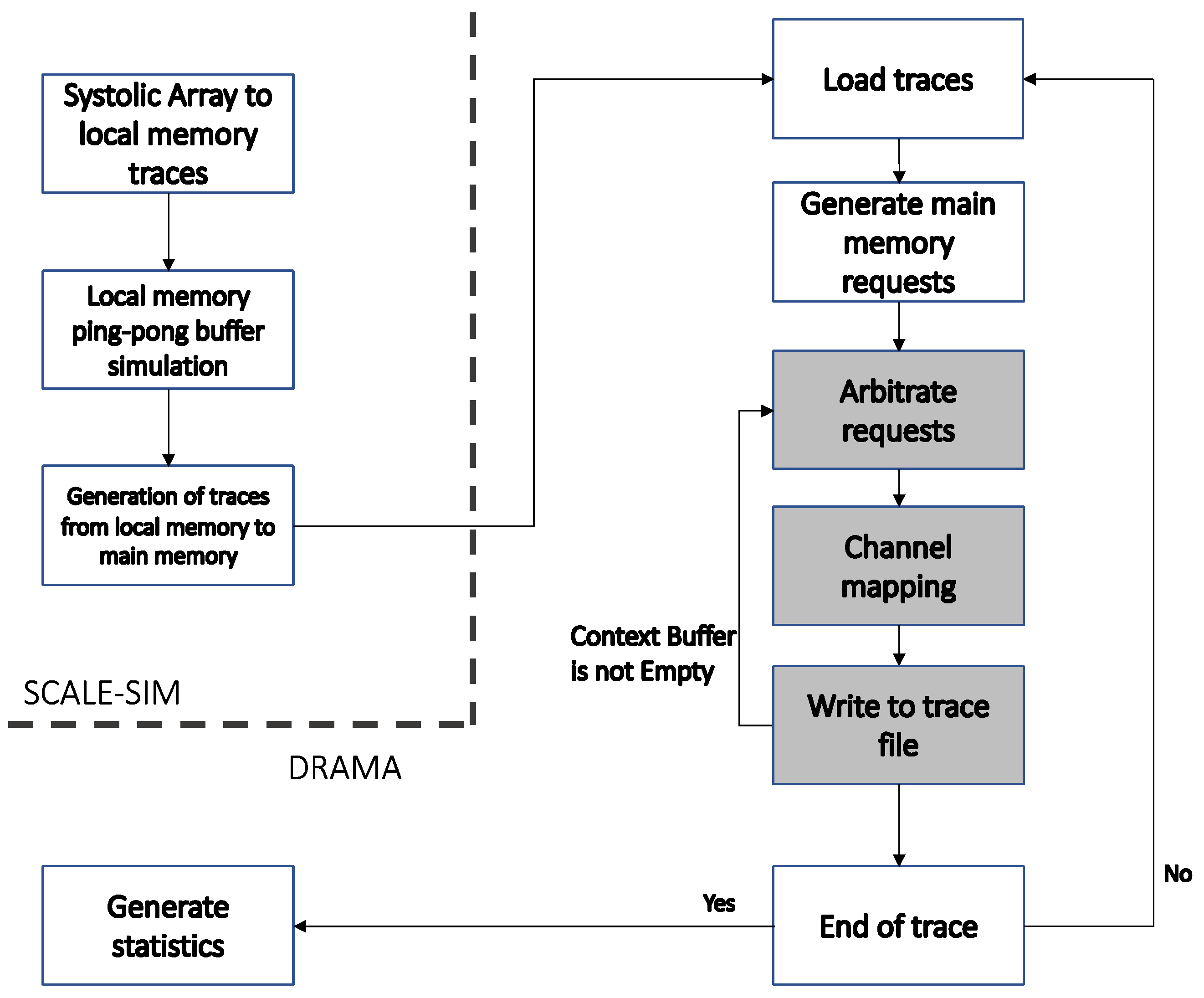
3.1. DRAMA Architecture
- A simulation of the SA processing and generation of local memory access traces.
- A simulation of the requests targeted to the local memory ping-pong buffers.
- Generation of the trace to the main memory for prefetching the next INFMAPs and filter weights and for writing the previous OFMAPs.
- It calculates the overall time required by the DRAM channel to serve the request.
- It updates the simulator performance statistics counters.
- It removes the request from the channel queue.
- An arbiter, which arbitrates the stream of memory requests destined for the DRAM channel. The arbiter operates in a round-robin (RR) manner and adds the requests to the request queue.
- A request queue, which includes all pending requests. The queue is managed in a first-in-first-out (FIFO) manner.
- A scheduler, which schedules the request in the head of queue to be served by the DRAM channel as soon as it becomes available. The scheduler removes the served request from the memory controller queue.
3.2. DRAMA Configuration Settings
3.3. DRAMA Outputs
- Channel memory bandwidth, measured in bytes per cycle.
- Average number of clock cycles per memory request.
- The percentage of time the SA was idle.
- The total number of pages open in a DRAM channel.
- Busy cycles—the number of cycles when the memory channel was busy.
- Total number of requests.
- Total number of bytes read by the SA.
4. Experimental Results and Discussion
4.1. Experimental Use Case
4.2. Case Studies Analysis
5. Conclusions
- We introduced a DRAMA simulation environment that can accurately perform detailed main memory system simulation of DNNs. DRAMA can accurately model main memory channels, DIMMs, ranks, banks, and related timing parameters.
- DRAMA can measure memory system throughput, SA throughput, idle time of both SA and memory system, and memory system average access latency.
- DRAMA is an open-source tool written in python and can be seamlessly integrated into other simulation environments or operate as a standalone simulator. DRAMA is designed in a modular manner offering a scalable and configurable simulation platform. It can be extended or adjusted to comply with various memory systems models, such as CPUs or GPUs, in order to examine the interplay between key memory system parameters.
- DRAMA can generate an accurate main memory trace file that can help system debugging and performance tuning by presenting the sequence of memory system events and their relation to the processing performed by the SA.
- The impact of the main memory system on the inference latency is out of the scope of this study. Our main focus in this study is on the main memory throughput and its impact on the SA throughput.
- The modeling of the main memory system accesses through DNN training is beyond the framework of this study. This limitation is due to the fact that SCALE-Sim can simulate inference only.
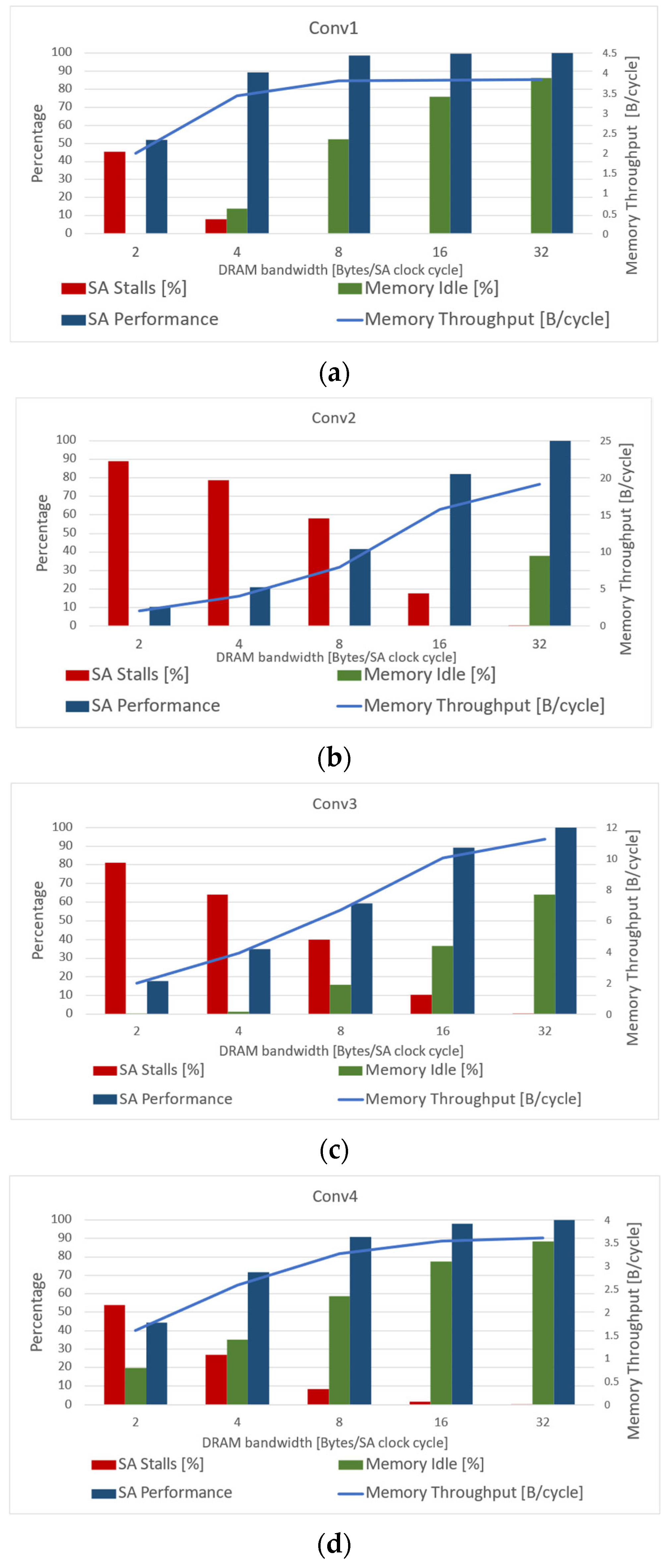
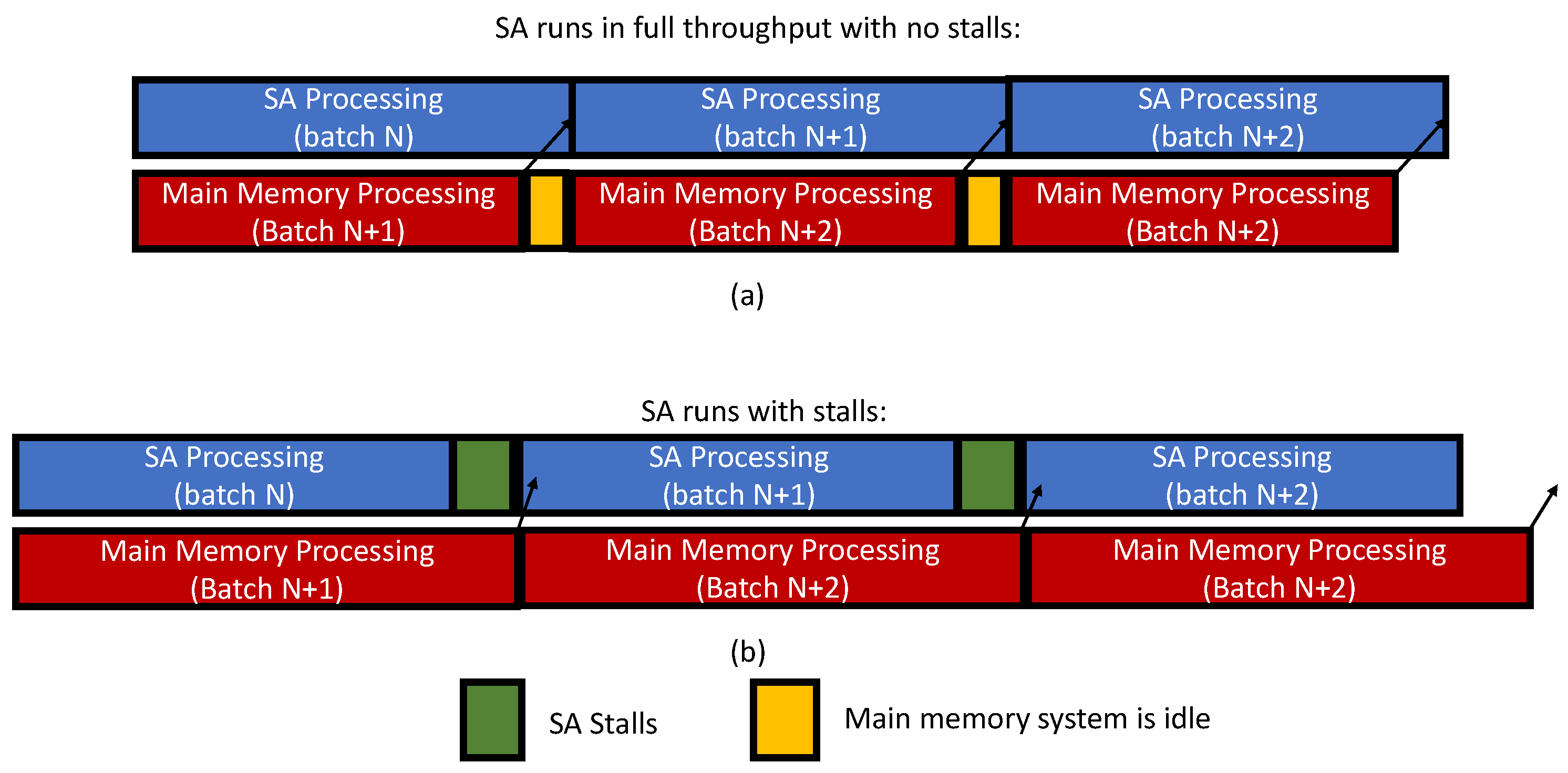
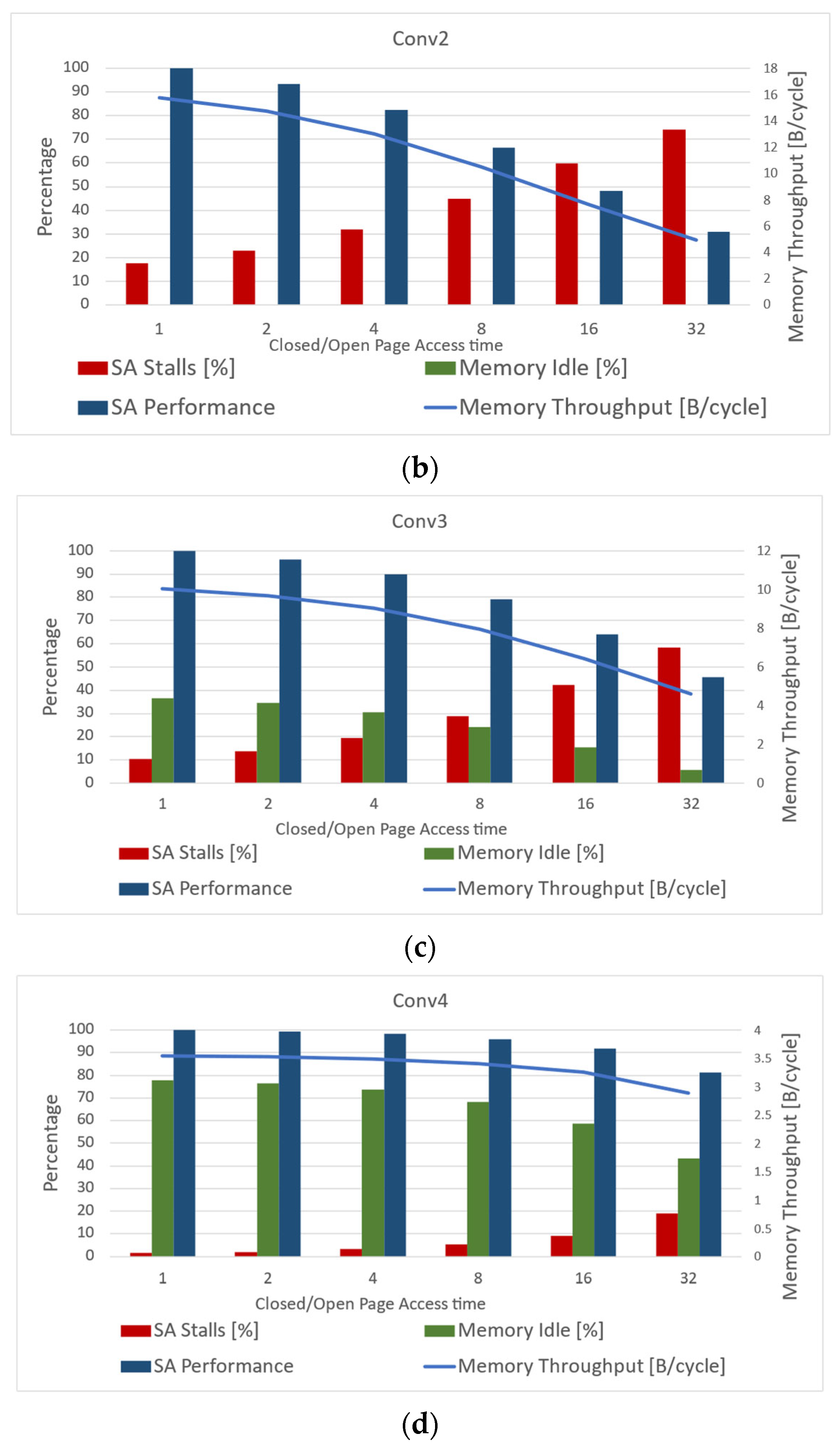
- As the DRAM bandwidth increases, the percentage of time the SA is stalled decreases. This finding is governed by the SA timing constraints that allow main memory batch to be started as soon as the ping-pong buffers are switched and must be completed before the SA starts the next batch. The increase in the main memory throughput increases the likelihood that the memory system will meet the SA deadline.
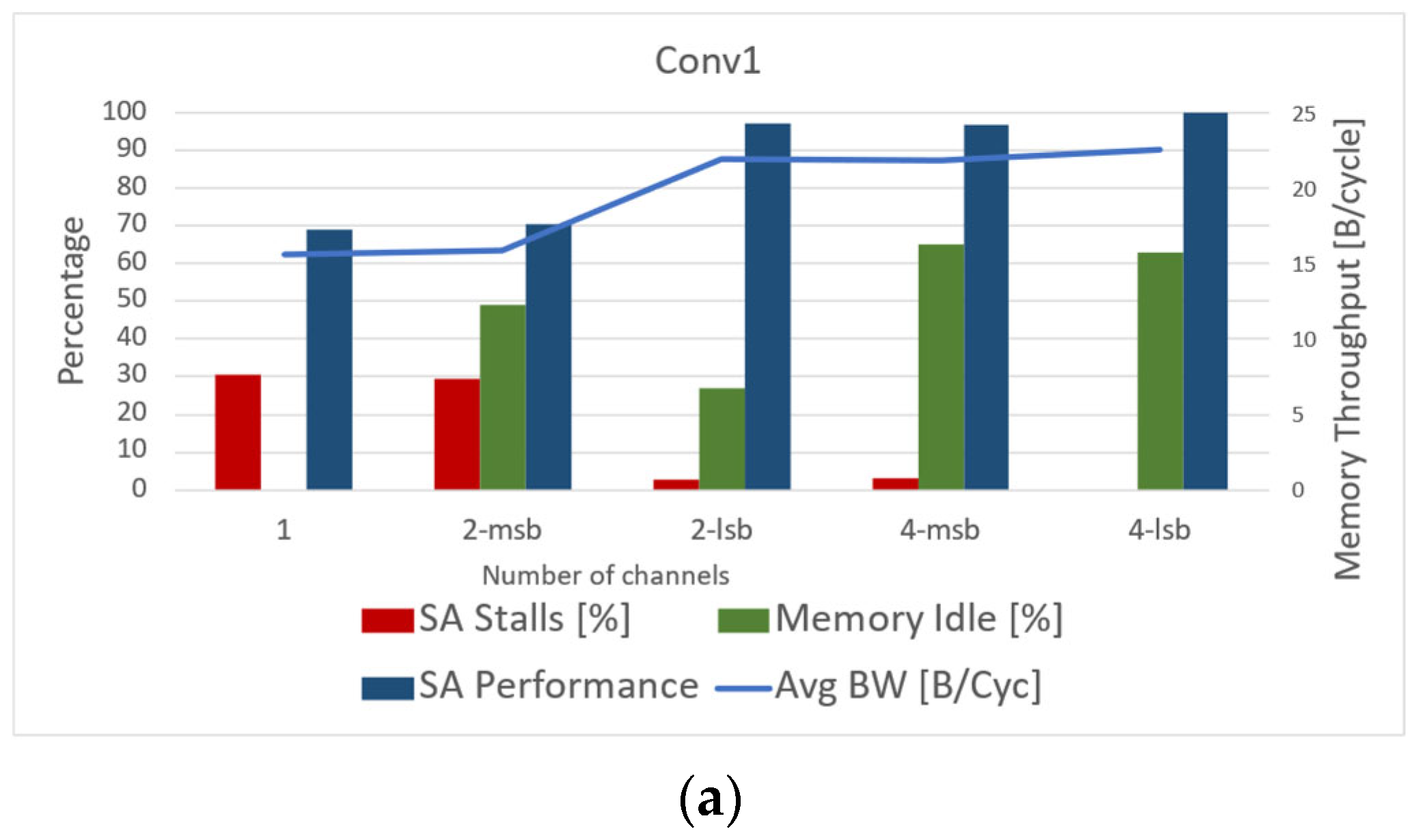
- Different convolution layers introduce diverse memory system requirements. When a convolution layer is able to better utilize the local SA memory, it can employ a significantly smaller main memory batch. In addition, when the increasing number of channels encourages more frequent swaps in the local memory ping-pong buffer, a large amount of data is needed to be prefetched from main memory.
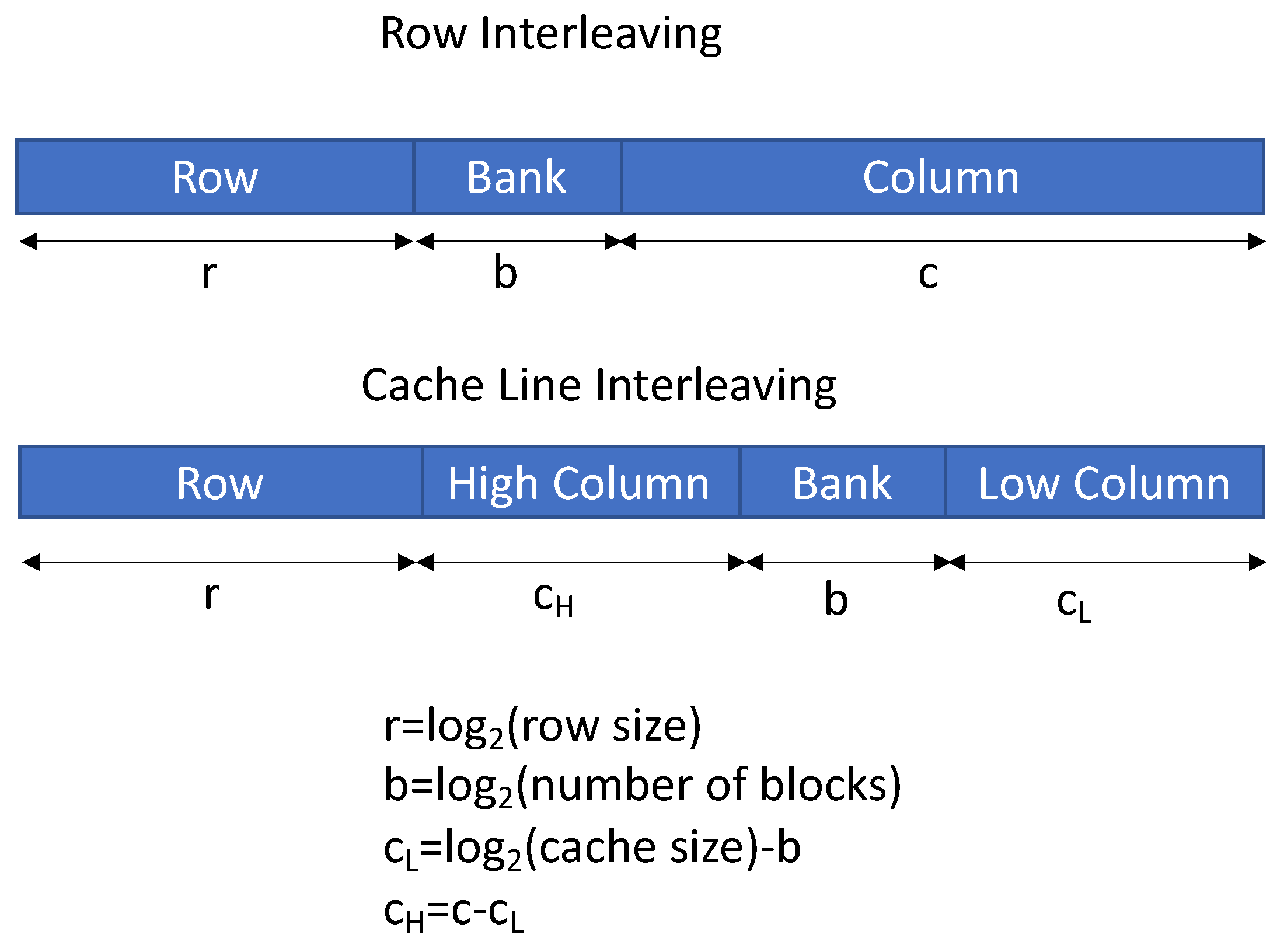
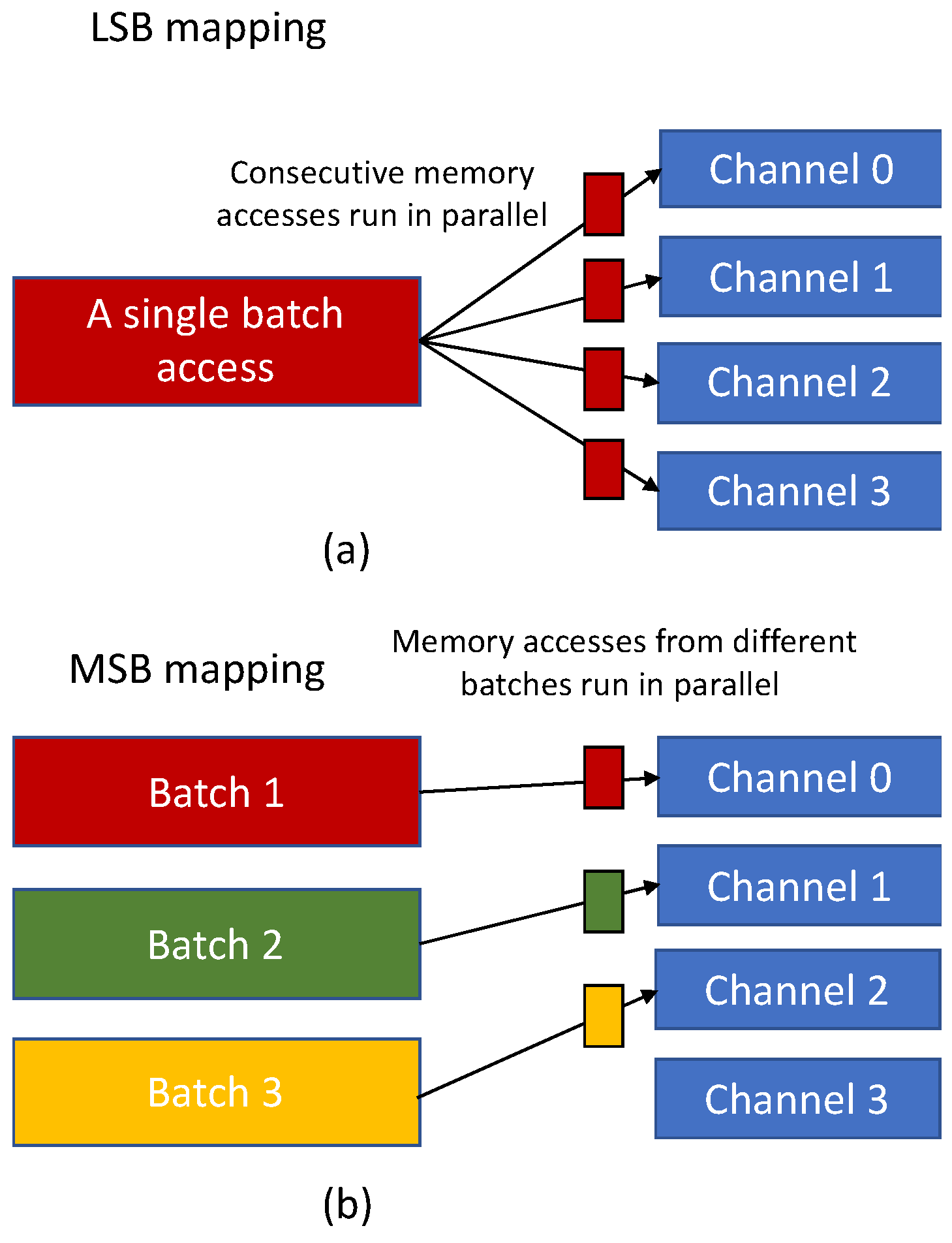
- LSB bank mapping improves the main memory throughput at batch level, while MSB mapping is useful when batches are mapped into different channels, and, as a result, it reduces the likelihood of batch conflicts.
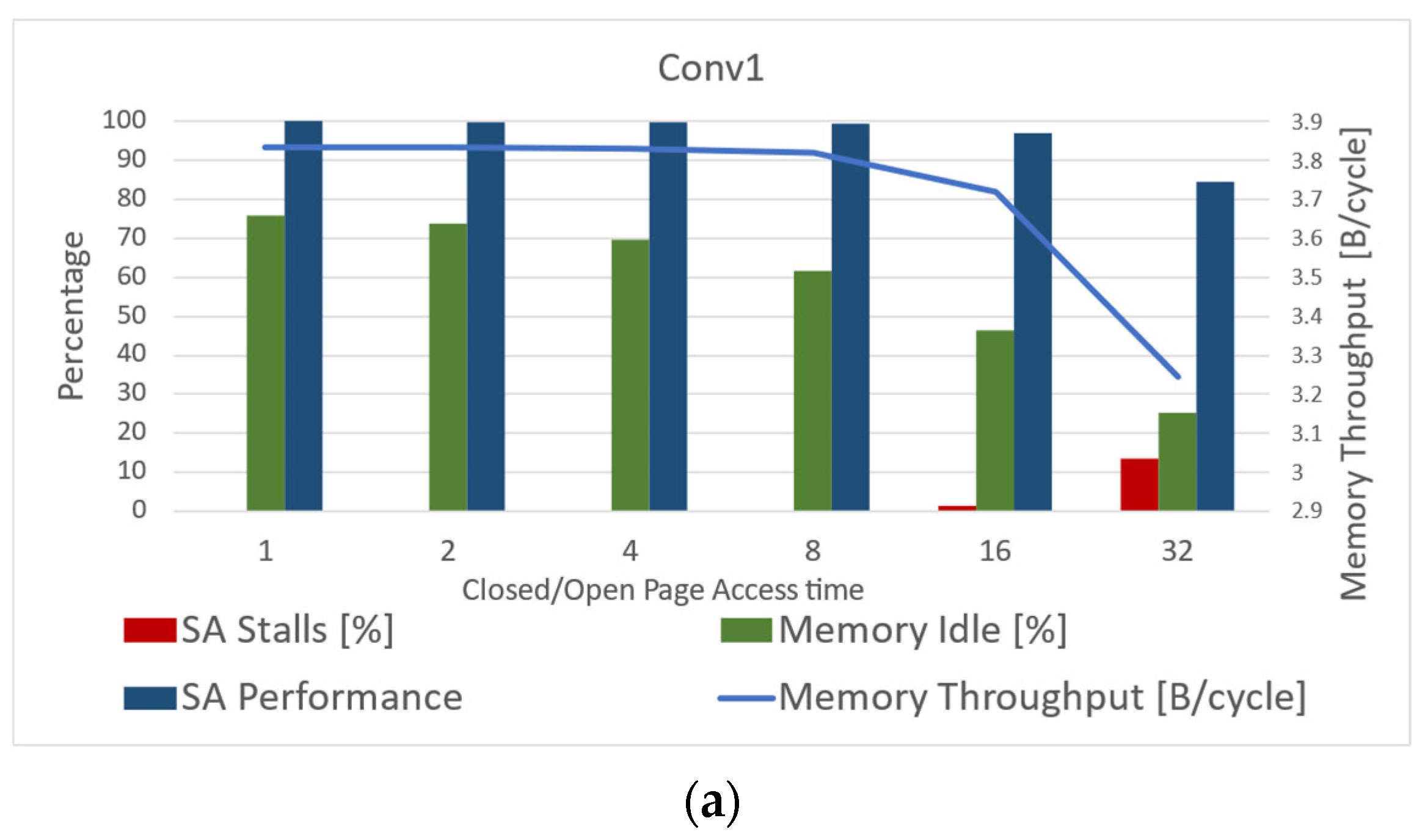
- As the ratio of closed-page access time to open-page access time increases, the main memory throughput decreases. This is due to the fact that the longer it takes to access a closed page, the likelihood of the main memory system to meet the SA deadline decreases.
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sze, V.; Chen, Y.; Yang, T.; Emer, J.S. Efficient Processing of Deep Neural Networks: A Tutorial and Survey. Proc. IEEE 2017, 105, 2295–2329. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the 26th Annual Conference on Neural Information Processing Systems 2012, Lake Tahove, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Sun, G.; Cong, Y.; Wang, Q.; Zhong, B.; Fu, Y. Representative Task Self-Selection for Flexible Clustered Lifelong Learning. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 1467–1481. [Google Scholar] [CrossRef]
- Covington, P.; Adams, J.; Sargin, E. Deep neural networks for YouTube recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems 2016 (RecSys’16), Boston, MA, USA, 15–19 September 2016; Association for Computing Machinery: New York, NY, USA; pp. 191–198. [Google Scholar] [CrossRef] [Green Version]
- Zhang, M.; Chen, Y.; Lin, J. A privacy-preserving optimization of neighborhood-based recommendation for medical-aided diagnosis and treatment. IEEE Internet Things J. 2021, 8, 10830–10842. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, G.; Li, J.; Shi, G.; Zhou, M.; Huang, B.; Tang, Y.; Song, X.; Yang, W. Deep Learning for Feynman’s Path Integral in Strong-Field Time-Dependent Dynamics. Phys. Rev. Lett. 2020, 124, 113202. [Google Scholar] [CrossRef] [Green Version]
- Zhong, T.; Cheng, M.; Lu, S.; Dong, X.; Li, Y. RCEN: A Deep-Learning-Based Background Noise Suppression Method for DAS-VSP Records. IEEE Geosci. Remote Sens. Lett. 2022, 19, 3004905. [Google Scholar] [CrossRef]
- Zhang, Z.; Tian, J.; Huang, W.; Yin, L.; Zheng, W.; Liu, S. A Haze Prediction Method Based on One-Dimensional Convolutional Neural Network. Atmosphere 2021, 12, 1327. [Google Scholar] [CrossRef]
- Shang, K.; Chen, Z.; Liu, Z.; Song, L.; Zheng, W.; Yang, B.; Liu, S.; Yin, L. Haze Prediction Model Using Deep Recurrent Neural Network. Atmosphere 2021, 12, 1625. [Google Scholar] [CrossRef]
- Jouppi, N.P.; Young, C.; Patil, N.; Patterson, D.; Agrawal, G.; Bajwa, R.; Bates, S.; Bhatia, S.; Boden, N.; Borchers, A.; et al. In-datacenter performance analysis of a tensor processing unit. arXiv 2017, arXiv:1704.04760. [Google Scholar]
- Morgan, T.P. Nvidia Pushes Deep Learning Inference with New Pascal GPUs; Next Platform: Boone, NC, USA, 2016. [Google Scholar]
- Carvalho, C. The gap between processor and memory speeds. In Proceedings of the IEEE International Conference on Control and Automation, Washington, DC, USA, 11–15 May 2002. [Google Scholar]
- Samajdar, A.; Zhu, Y.; Whatmough, P.; Mattina, M.; Krishna, T. SCALE-Sim: Systolic CNN accelerator simulator. arXiv 2018, arXiv:1811.02883. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Jacob, B. The Memory System: You Can’t Avoid It, You Can’t Ignore It, You Can’t Fake It; Morgan and Claypool Publishers: San Rafael, CA, USA, 2009. [Google Scholar]
- Carter, J.; Hsieh, W.; Stoller, L.; Swanson, M.; Zhang, L.; Brunvand, E.; Davis, A.; Kuo, C.C.; Kuramkote, R.; Parker, M.; et al. Impulse: Building a smarter memory controller. In Proceedings of the International Symposium on High-Performance Computer Architecture, Washington, DC, USA, 9–12 January 1999. [Google Scholar]
- JESD79F; Double Data Rate (DDR) SDRAM Standard. JEDEC: Arlington, VA, USA, 2008.
- Li, S.; Jacob, B. Statistical DRAM modeling. In Proceedings of the International Symposium on Memory Systems, MEMSYS’19, Washington, DC, USA, 30 September–3 October 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 521–530. [Google Scholar] [CrossRef]
- Jung, M.; Feldmann, J.; Kraft, K.; Steiner, L.; Wehn, N. Fast and accurate DRAM simulation: Can we further accelerate it? In Proceedings of the IEEE Conference on Design, Automation and Test in Europe (DATE), Grenoble, France, 9–13 March 2020; pp. 364–369. [Google Scholar]
- Todorov, V.; Mueller-Gritschneder, D.; Reinig, H.; Schlichtmann, U. Automated construction of a cycle-approximate transaction level model of a memory controller. In Proceedings of the Conference on Design, Automation and Test in Europe, DATE’12, Dresden, Germany, 12–16 March 2012; EDA Consortium: San Jose, CA, USA, 2012; pp. 1066–1071. Available online: http://dl.acm.org/citation.cfm?id=2492708.2492972 (accessed on 5 November 2022).
- Rosenfeld, P.; Cooper-Balis, E.; Jacob, B. DRAMSim2: A cycle accurate memory system simulator. IEEE Comput. Archit. Lett. 2011, 10, 16–19. [Google Scholar] [CrossRef]
- Li, S.; Yang, Z.; Reddy, D.; Srivastava, A.; Jacob, B. DRAMsim3: A cycle-accurate, thermal-capable DRAM simulator. IEEE Comput. Archit. Lett. 2020, 19, 106–109. [Google Scholar] [CrossRef]
- Kim, Y.; Yang, W.; Mutlu, O. Ramulator: A fast and extensible DRAM simulator. IEEE Comput. Archit. Lett. 2015, 15, 45–49. [Google Scholar] [CrossRef]
- Jeong, M.K.; Yoon, D.H.; Erez, M. DrSim: A Platform for Flexible DRAM System Research. Available online: http://lph.ece.utexas.edu/public/DrSim (accessed on 15 August 2022).
- Chatterjee, N.; Balasubramonian, R.; Shevgoor, M.; Pugsley, S.H.; Udipi, A.N.; Shafiee, A.; Sudan, K.; Awasthi, M.; Chishti, Z. USIMM: The Utah SImulated Memory Module, a Simulation Infrastructure for the JWAC Memory Scheduling Championship; Utah and Intel Corp.: Riverton, UT, USA, 2012. [Google Scholar]
- Jung, M.; Weis, C.; Wehn, N. DRAMSys: A flexible DRAM Subsystem Design Space Exploration Framework. IPSJ Trans. Syst. LSI Des. Methodol. (T-SLDM) 2015, 8, 63–74. [Google Scholar] [CrossRef] [Green Version]
- Steiner, L.; Jung, M.; Prado, F.S.; Bykov, K.; Wehn, N. DRAMSys4.0: An Open-Source Simulation Framework for In-depth DRAM Analyses. Int. J. Parallel. Prog. 2022, 50, 217–242. [Google Scholar] [CrossRef]
- Binkert, N.; Beckmann, B.; Black, G.; Reinhardt, S.K.; Saidi, A.; Basu, A.; Hestness, J.; Hower, D.R.; Krishna, T.; Sardashti, S.; et al. The gem5 simulator. SIGARCH Comput. Archit. News 2011, 39, 1–7. [Google Scholar] [CrossRef]
- Rodrigues, A.F.; Hemmert, K.S.; Barrett, B.W.; Kersey, C.; Oldfield, R.; Weston, M.; Risen, R.; Cook, J.; Rosenfeld, P.; Cooper-Balis, E.; et al. The structural simulation toolkit. SIGMETRICS Perform. Eval. Rev. 2011, 38, 37–42. [Google Scholar] [CrossRef] [Green Version]
- Sanchez, D.; Kozyrakis, C. ZSim: Fast and accurate microarchitectural simulation of thousand-core systems. SIGARCH Comput. Archit. News 2013, 41, 475. [Google Scholar] [CrossRef]
- Sudarshan, C.; Lappas, J.; Weis, C.; Mathew, D.M.; Jung, M.; Wehn, N. A lean, low power, low latency DRAM memory controller for transprecision computing. In Embedded Computer Systems: Architectures, Modeling, and Simulation; Pnevmatikatos, D.N., Pelcat, M., Jung, M., Eds.; Springer: Cham, Switzerland, 2019; pp. 429–441. [Google Scholar]
- Zhang, Z.; Zhu, Z.; Zhang, X. A permutation-based page interleaving scheme to reduce row-buffer conflicts and exploit data locality. In Proceedings of the 33rd Annual IEEE/ACM International Symposium on Microarchitecture, MICRO-33 2000, Monterey, CA, USA, 10–13 December 2000; pp. 32–41. [Google Scholar] [CrossRef]
- Peng, I.B.; Gioiosa, R.; Kestor, G.; Cicotti, P.; Laure, E.; Markidis, S. Exploring the performance benefit of hybrid memory system on hpc environments. In Proceedings of the Parallel and Distributed Processing Symposium Workshops (IPDPSW), 2017 IEEE International, Lake Buena Vista, FL, USA, 29 May–2 June 2017; pp. 683–692. [Google Scholar]
- Jun, H.; Cho, J.; Lee, K.; Son, H.Y.; Kim, K.; Jin, H.; Kim, K. HBM (High Bandwidth Memory) DRAM technology and architecture. In Proceedings of the 2017 IEEE International Memory Workshop (IMW), Monterey, CA, USA, 14–17 May 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Lee, C. NVDIMM-C: A byte-addressable non-volatile memory module for compatibility with standard DDR memory interfaces. In Proceedings of the 26th IEEE International Symposium on High-Performance Computer Architecture, San Diego, CA, USA, 22–26 February 2020. [Google Scholar]
- Le Gallo, M.; Sebastian, A. An overview of phase-change memory device physics. J. Phys. D Appl. Phys. 2020, 53, 213002. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Simulation Environment | Scope | Memory System Level of Modeling | DRAM Technology | Simulation Method |
|---|---|---|---|---|
| Statistical DRAM simulator [21] | DRAM access latency | Single channel, DIMMs, ranks, banks, timing parameters | Not specified | Statistical modeling using machine learning models trained by synthetic traces. |
| Statistical DRAM simulator [23] | DRAM access latency | Memory controller | Not specified | Statistical modeling based on conditional distribution function. |
| DRAMSim2 [24] | Performance measurement, design verification, power measurement | Single channel, DIMMs, ranks, banks, timing parameters | DDR2 and DDR3 | Standalone transaction-based model. Co-simulation with ModelSim |
| USIMM [28] | Memory access scheduling, power modeling | Multiple channels with no detailed modeling of DRAM subsystem. | Not specified | Standalone trace driven. |
| Gem5 [31] | Full system performance simulation | A CPU Memory hierarchy with DRAM controller | LPDDR3/4/5, DDR3/4, GDDR5, HBM1/2/3, HMC, WideIO1/2 | Integrated CPU and memory system event driven simulator. Co-simulation with SystemC. |
| DRAMSys 3.0 [29] | DRAM compliance, temperature, waveforms, errors, bus monitor | Single channel | DDR3, DDR4, LPDDR3, WIDE I/O, HMC | Standalone SystemC Transaction-Level modeling (TLM) |
| DRAMSys 3.0+ [22] | DRAM latency only | Single channel | Not specified | Standalone DRAM using lookup tables and neural network for latency estimation. |
| DRAMsim3 [25] | Power and thermal simulations | Multiple channels, DIMMs, ranks, banks, timing parameters | DDR3/4, LPDDR3/4, GDDR5, WIDIO, HBM1 | Standalone DRAM with system-level interfaces to interact with a CPU simulator or a trace frontend. |
| Ramulator [26] | Instruction per clock (IPC) and DRAM throughput | Multiple channels, DIMMs, ranks, banks, timing parameters | DDR3/4, LPDDR3/4, GDDR5/6, HBM1/2 | Standalone simulator or integrated with gem5. |
| DrSim [27] | Instruction per clock (IPC) and DRAM throughput | Multiple channels, DIMMs, ranks, banks, timing parameters | DDR2/3, LPDD2 | Standalone simulator or integrated with gem5. |
| DRAMSys4.0 [30] | Trace analyzer, power and thermal simulations | Multiple channels, DIMMs, ranks, banks, timing parameters | DDR3/4/5, LPDDR4/5, WIDO I/O, GDDR5/6, HBM1/2 | Standalone with trace players, gem5-coupled, and transaction-level modeling (TLM) |
| DRAMA | DRAM latency, throughput, idle time, SA performance | Multiple channels, DIMMs, ranks, banks, timing parameters | Explicitly designed to support a wide variety of standards with different architectures | Standalone simulator, integrated with SCALE-Sim or other simulators |
| Configuration Parameters | |
|---|---|
| NumerOfChannels | The number of DRAM channels. |
| ChannelMapping | Defines the mapping of memory address to a DRAM channel. The address mapping can be based on the least significant bits or the most significant bits of the memory address. |
| NumerOfDIMMs | The number of DIMMs per memory channel. |
| NumberOfRanks | The number of DIMM ranks. |
| NumberOfBanks | The number of banks. |
| BusSize | Memory channel data bus width. |
| PageSize | DRAM page size. |
| ChannelMemorySize | The memory size of a channel. |
| AddressMapping | The DRAM address mapping mode: row interleaving or cache block interleaving. |
| CacheBlockSize | The cache block size when AddressMapping is set to cache interleaving. |
| OpenPageAccessTime | The access time (in clock cycles) to an open page (FPM). |
| ClosedPageAccessTime | The access time (in clock cycles) to a closed page. |
| Configuration Parameters | IFMAP Dimensions | Filter Dimensions | Number of Channels | Number of Filters | Stride |
|---|---|---|---|---|---|
| Conv1 | 56 × 56 | 3 × 3 | 64 | 64 | 1 |
| Conv2 | 28 × 28 | 3 × 3 | 128 | 128 | 1 |
| Conv3 | 14 × 14 | 3 × 3 | 256 | 256 | 1 |
| Conv4 | 7 × 7 | 3 × 3 | 512 | 512 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gabbay, F.; Lev Aharoni, R.; Schweitzer, O. Deep Neural Network Memory Performance and Throughput Modeling and Simulation Framework. Mathematics 2022, 10, 4144. https://doi.org/10.3390/math10214144
Gabbay F, Lev Aharoni R, Schweitzer O. Deep Neural Network Memory Performance and Throughput Modeling and Simulation Framework. Mathematics. 2022; 10(21):4144. https://doi.org/10.3390/math10214144
Chicago/Turabian StyleGabbay, Freddy, Rotem Lev Aharoni, and Ori Schweitzer. 2022. "Deep Neural Network Memory Performance and Throughput Modeling and Simulation Framework" Mathematics 10, no. 21: 4144. https://doi.org/10.3390/math10214144