
Interactive Learning of a Dual Convolution Neural Network for Multi-Modal Action Recognition

Abstract
:1. Introduction
- An effective 2D-ConvNet framework is proposed to extract interactive features from different modalities to recognize human action, which jointly learn features from different modalities for human action recognition.
- We experimentally demonstrate that the constructed VDIs and DDIs can effectively represent spatial-temporal information from the whole RGB-D sequences.
- The proposed ILD-ConvNet recognition framework has been evaluated on large-scale human action datasets. The results show that our proposed ILD-ConvNet achieved better recognition performance and generalization performance, which demonstrated the effectiveness of our ILD-ConvNet.
2. Related Work
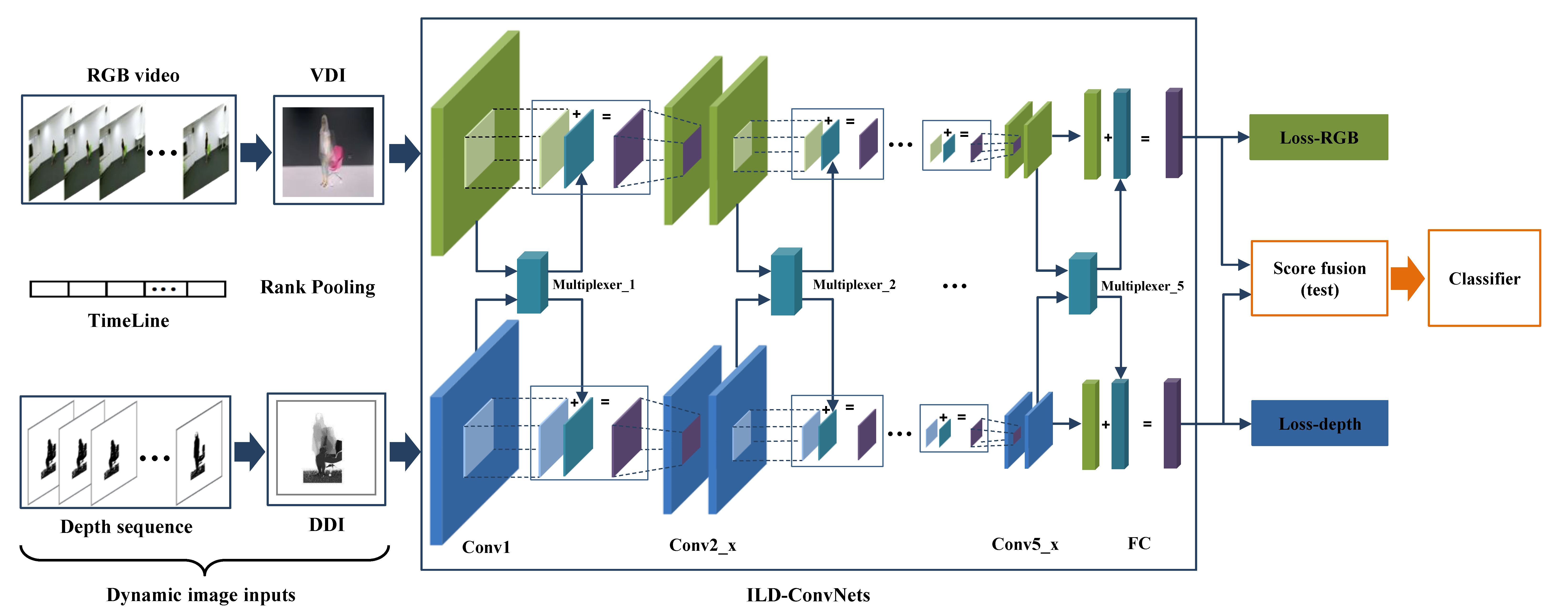
3. The Proposed Method
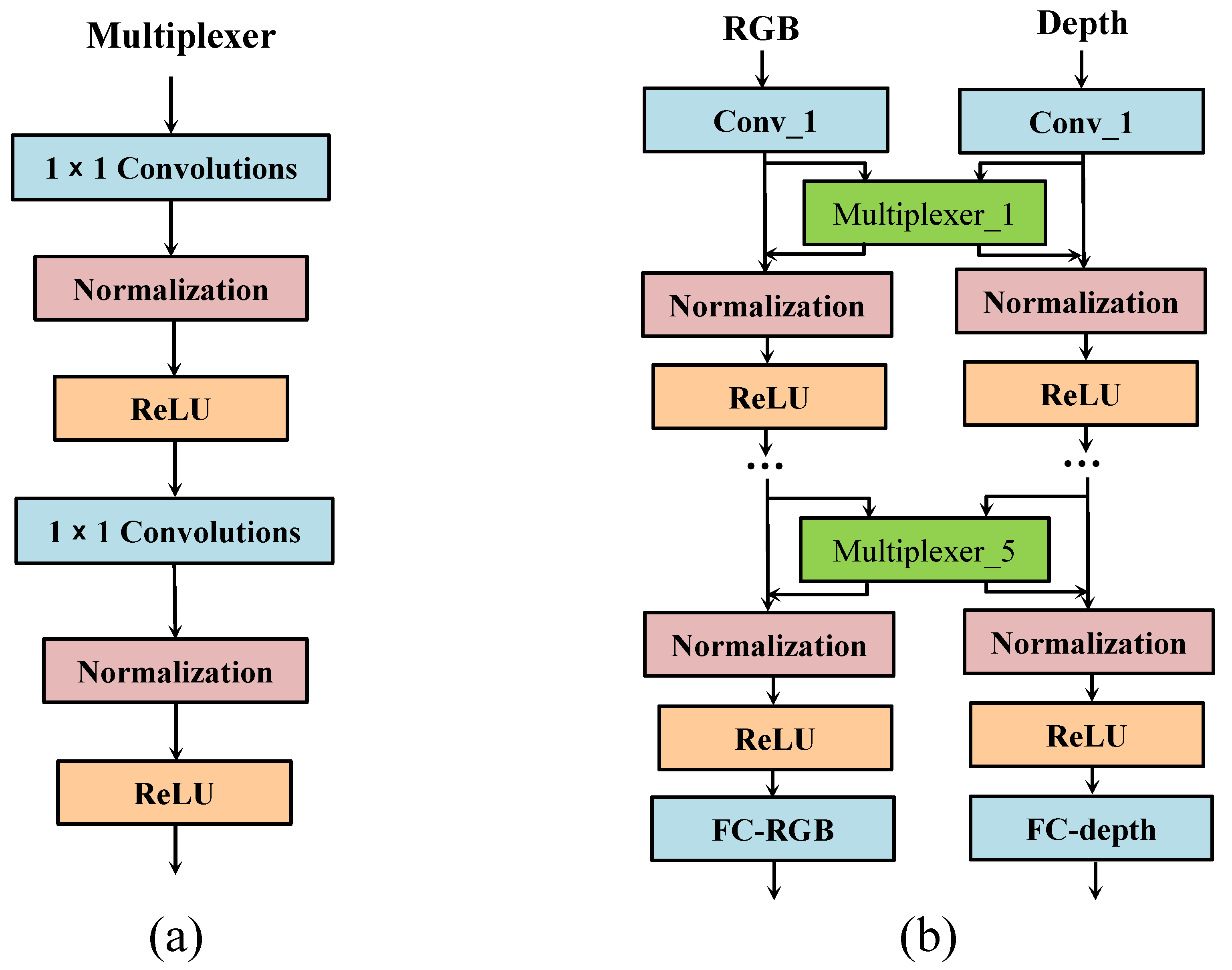
3.1. ILD-ConvNet Framework
3.2. Network Inputs
3.3. Multiplexer Modules
3.4. Optimization Learning
3.5. Datasets Implementation Details
3.5.1. Datasets
3.5.2. Implementation Details
4. Experimental Results and Analysis
4.1. Effectiveness of the Proposed ILD-ConvNet
4.1.1. Effectiveness
4.1.2. Comparison of Different Fusion Methods
4.1.3. Effectiveness of Parameter
4.2. Comparison to the State of the Art
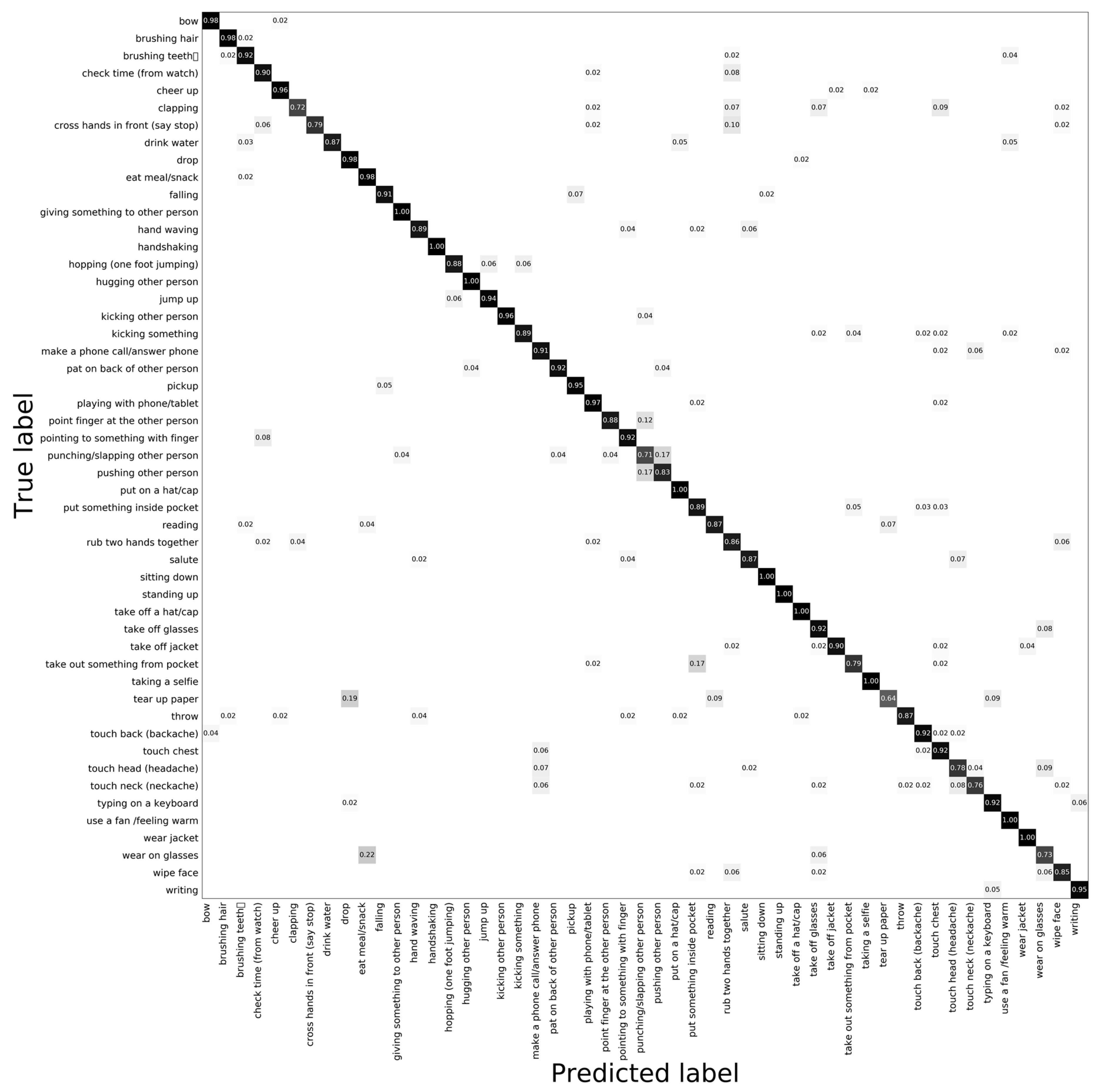
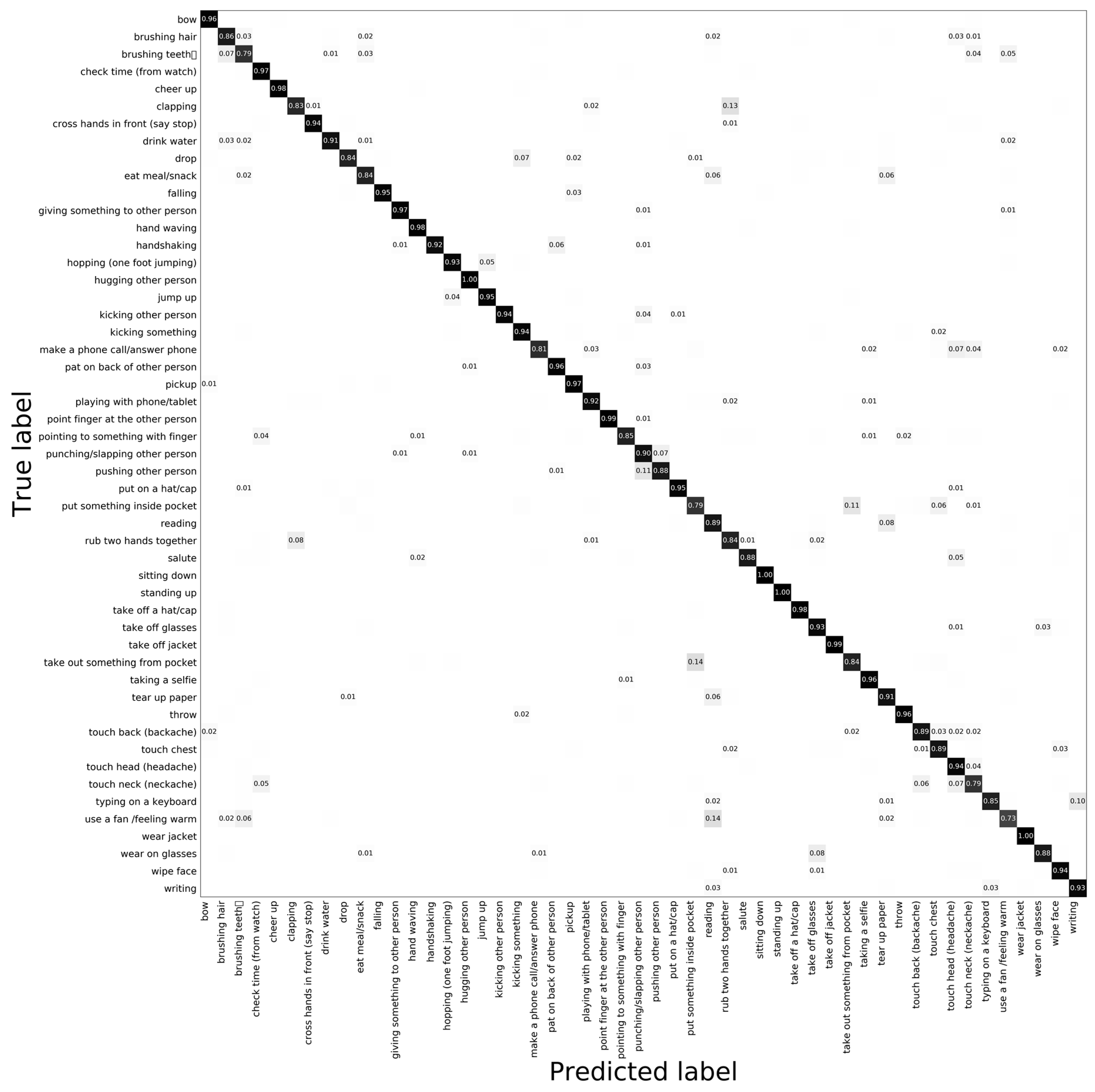
4.2.1. Experimental on the NTU RGB + D Dataset
4.2.2. Experimental on the PKU-MMD Dataset
4.3. Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, Y.; Lu, Z.; Li, J.; Yang, T.; Yao, C. Deep image-to-video adaptation and fusion networks for action recognition. IEEE Trans. Image Process. TIP 2020, 29, 3168–3182. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Shen, F.; Xu, X.; Shen, H.T. Temporal reasoning graph for activity recognition. IEEE Trans. Image Process. TIP 2020, 29, 5491–5506. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rao, H.; Wang, S.; Hu, X.; Tan, M.; Guo, Y.; Cheng, J.; Liu, X.; Hu, B. A self-supervised gait encoding approach with locality-awareness for 3D skeleton based person re-identification. IEEE Trans. Pattern Anal. Mach. Intell. TPAMI 2021, 44, 6649–6666. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Zhang, S.; Jiang, F.; Qi, Y.; Zhang, J.; Guo, Y.; Zhou, H. BoMW: Bag of manifold words for one-shot learning gesture recognition from Kinect. IEEE Trans. Circuits Syst. Vid. Technol. TCSVT 2017, 28, 2562–2573. [Google Scholar] [CrossRef] [Green Version]
- Ji, X.; Zhao, Q.; Cheng, J.; Ma, C. Exploiting spatio-temporal representation for 3D human action recognition from depth map sequences. Knowl.-Based Syst. 2021, 227, 107040. [Google Scholar]
- Ji, Y.; Yang, Y.; Shen, F.; Shen, H.T.; Zheng, W.-S. Arbitrary-View Human Action Recognition: A Varying-view RGB-D Action Dataset. IEEE Trans. Circuits Syst. Video Technol. TCSVT 2021, 31, 289–300. [Google Scholar] [CrossRef]
- Lin, J.; Gan, C.; Han, S. TSM: Temporal shift module for efficient video understanding. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 7083–7093. [Google Scholar]
- Li, Y.; Ji, B.; Shi, X.; Zhang, J.; Kang, B.; Wang, L. TEA: Temporal excitation and aggregation for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 909–918. [Google Scholar]
- Song, X.; Lan, C.; Zeng, W.; Xing, J.; Sun, X.; Yang, J. Temporal–Spatial Mapping for Action Recognition. IEEE Trans. Circuits Syst. Video Technol. TCSVT 2020, 30, 748–759. [Google Scholar] [CrossRef]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. Slow-fast networks for video recognition. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6202–6211. [Google Scholar]
- Song, Y.-F.; Zhang, Z.; Shan, C.; Wang, L. Richly activated graph convolutional network for robust skeleton-based action recognition. IEEE Trans. Circuits Syst. Vid. Technol. TCSVT 2021, 31, 1915–1925. [Google Scholar]
- Ijjina, E.P.; Chalavadi, K.M. Human Action Recognition in RGB-D Videos using Motion Sequence Information and Deep Learning. Pattern Recognit. 2017, 72, 504–516. [Google Scholar]
- Li, C.; Hou, Y.; Wang, P.; Li, W. Multiview-Based 3D Action Recognition using Deep Networks. IEEE Trans. Hum.-Mach. Syst. THMS 2019, 49, 95–104. [Google Scholar] [CrossRef]
- Joze, H.R.V.; Shaban, A.; Iuzzolino, M.L.; Koishida, K. MMTM: Multimodal transfer module for CNN fusion. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 13286–13296. [Google Scholar]
- Abavisani, M.; Joze, H.R.V.; Pate, V.M. Improving the performance of unimodal dynamic hand-gesture recognition with multimodal training. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1165–1174. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Gool, L.V. Temporal segment networks for action recognition in videos. IEEE Trans. Pattern Anal. Mach. Intell. TPAMI 2019, 41, 2740–2755. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fernando, B.; Gavves, E.; Oramas, J.; Ghodrati, A.; Tuytelaars, T. Rank pooling for action recognition. IEEE Trans. Pattern Anal. Mach. Intell. TPAMI 2016, 39, 773–787. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tran, D.; Wang, H.; Feiszli, M.; Torresani, L. Video classification with channel-separated convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 5551–5560. [Google Scholar]
- Wang, H.; Song, Z.; Li, W.; Wang, P. A Hybrid Network for Large-Scale Action Recognition from RGB and Depth Modalities. Sensors 2020, 20, 3305. [Google Scholar] [CrossRef] [PubMed]
- Wu, H.; Ma, X.; Li, Y. Spatio-temporal multimodal learning with CNNs for video action recognition. IEEE Trans. Circuits Syst. Video Technol. TCSVT 2022, 32, 1250–1261. [Google Scholar] [CrossRef]
- Fernando, B.; Anderson, P.; Hutter, M.; Gould, S. Discriminative Hierarchical Rank Pooling for Activity Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Vegas, NV, USA, 27–30 June 2016; pp. 1924–1932. [Google Scholar]
- Bilen, H.; Fernando, B.; Gavves, E.; Vedaldi, A.; Gould, S. Dynamic image networks for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Vegas, NV, USA, 27–30 June 2016; pp. 3034–3042. [Google Scholar]
- Li, N.; Cheng, X.; Zhang, S.; Wu, Z. Realistic human action recognition by fast HOG3D and self-organization feature map. Mach. Vis. Appl. 2014, 25, 1793–1812. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate SHIFT. In Proceedings of the 32nd International Conference on Machine Learning (ICML), Lile, France, 6–11 July 2015; Volume 1, pp. 448–456. [Google Scholar]
- Moghaddam, Z.; Piccardi, M. Training initialization of hidden Markov models in human action recognition. IEEE Trans. Autom. Sci. Eng. TASE 2014, 11, 394–408. [Google Scholar] [CrossRef]
- Sempena, S.; Maulidevi, N.; Aryan, P. Human action recognition using dynamic time warping. In Proceedings of the International Conference on Electrical Engineering and Informatics (ICEEI), Bandung, Indonesia, 17–19 July 2011; pp. 1–5. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. Proc. Adv. Neural Inf. Process. Syst. NIPS 2014, 1, 568–576. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Van Gool, L. Temporal Segment Networks: Towards Good Practices for Deep Action Recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 20–36. [Google Scholar]
- Zhang, J.; Shen, F.; Xu, X.; Shen, H.T. Cooperative cross-stream network for discriminative action representation. arXiv 2019, arXiv:1908.10136. [Google Scholar]
- Wang, L.; Tong, Z.; Ji, B.; Wu, G. TDN: Temporal difference networks for efficient action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 1895–1904. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatio-temporal features with 3D convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Jiang, S.; Qi, Y.; Zhang, H.; Bai, Z.; Lu, X.; Wang, P. D3D: Dual 3-D Convolutional Network for Real-Time Action Recognition. IEEE Trans. Ind. Inform. TII 2021, 17, 584–4593. [Google Scholar] [CrossRef]
- Tao, L.; Wang, X.; Yamasaki, T. Rethinking Motion Representation: Residual Frames With 3D ConvNets. IEEE Trans. Image Process. TIP 2021, 30, 9231–9244. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End to end object detection with transformers. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Girdhar, R.; Carreira, J.; Doersch, C.; Zisserman, A. Video action transformer network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 244–253. [Google Scholar]
- Wang, P.; Li, W.; Gao, Z.; Tang, C.; Ogunbona, P.O. Depth pooling based large-scale 3-D action recognition with convolutional neural networks. IEEE Trans. Multimed. TMM 2018, 20, 1051–1061. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.; Li, W.; Gao, Z.; Zhang, J.; Tang, C.; Ogunbona, P.O. Action recognition from depth maps using deep convolutional neural networks. IEEE Trans. Hum.-Mach. Syst. 2016, 46, 498–509. [Google Scholar] [CrossRef]
- Qi, M.; Wang, Y.; Qin, J.; Li, A.; Luo, J.; Van Gool, L. StagNet: An attentive semantic RNN for group activity and individual action recognition. IEEE Trans. Circuits Syst. Video Technol. TCSVT 2020, 30, 549–565. [Google Scholar] [CrossRef]
- Si, C.; Chen, W.; Wang, W.; Wang, L.; Tan, T. An attention enhanced graph convolutional LSTM network for skeleton-based action recognition. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–17 June 2019; pp. 1227–1236. [Google Scholar]
- Liu, J.; Wang, G.; Duan, L.-Y.; Abdiyeva, K.; Kot, A.C. Skeleton based human action recognition with global context-aware attention LSTM networks. IEEE Trans. Image Process. TIP 2018, 27, 1586–1599. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.; Li, W.; Wan, J.; Ogunbona, P.; Liu, X. Cooperative Training of Deep Aggregation Networks for RGB-D Action Recognition. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence (AAAI), New Orleans, LA, USA, 2–7 February 2018; pp. 7404–7411. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.; Wang, G. NTU RGB+D: A large scale dataset for 3D human activity analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Vegas, NV, USA, 27–30 June 2016; pp. 1010–1019. [Google Scholar]
- Ren, Z.; Zhang, Q.; Cheng, J.; Hao, F.; Gao, X. Segment spatial-temporal representation and cooperative learning of Convolution Neural Networks for multimodal-based action recognition. Neurocomputing 2021, 433, 142–153. [Google Scholar] [CrossRef]
- Cheng, J.; Ren, Z.; Zhang, Q.; Gao, X.; Hao, F. Cross-Modality Compensation Convolutional Neural Networks for RGB-D Action Recognition. IEEE Trans. Circuits Syst. Video Technol. TCSVT 2022, 32, 1498–1509. [Google Scholar] [CrossRef]
- Song, S.; Liu, J.; Li, Y.; Guo, Z. Modality compensation network: Cross-modal adaptation for action recognition. IEEE Trans. Image Process. TIP 2020, 29, 3957–3969. [Google Scholar] [CrossRef] [Green Version]
- Xu, W.; Wu, M.; Zhao, M.; Xia, T. Fusion of skeleton and RGB features for RGB-D human action recognition. IEEE Sens. J. 2021, 21, 19157–19164. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Statist. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Shahroudy, A.; Perez, M.L.; Wang, G.; Duan, L.; Chichung, A.K. NTU RGB+D 120: A large-scale benchmark for 3D human activity understanding. IEEE Trans. Pattern Anal. Mach. Intell. TPAMI 2019, 42, 2684–2701. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Hu, Y.; Li, Y.; Song, S.; Liu, J. PKU-MMD: A large scale benchmark for continuous multi-modal human action understanding. arXiv 2017, arXiv:1703.07475. [Google Scholar]
- Song, S.; Lan, C.; Xing, J.; Zeng, W.; Liu, J. Spatio-temporal attention-based LSTM networks for 3D action recognition and detection. IEEE Trans. Image Process. TIP 2018, 27, 3459–3471. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Name | Output Size | ILD-ConvNet50 | |
|---|---|---|---|
| RGB Stream | Depth Stream | ||
| Conv1 | , 64, stride 2 | , 64, stride 2 | |
| Multiplexer_1 | |||
| Conv2_x | |||
| Multiplexer_2 | |||
| Conv3_x | |||
| Multiplexer_3 | |||
| Conv4_x | |||
| Multiplexer_4 | |||
| Conv5_x | |||
| Multiplexer_5 | |||
| FC | FC-RGB | FC-depth | |
| Methods | Modality | C-Sub | C-Set |
|---|---|---|---|
| ResNet50 | RGB | 40.6% | 39.5% |
| ResNet50 | depth | 43.6% | 42.2% |
| ResNet50 | RGB + depth | 51.4% | 51.3% |
| ResNet50 | 56.7% | 52.5% | |
| ResNet50 | 72.2% | 72.3% | |
| ResNet50 | 73.8% | 74.0% | |
| ILD-ConvNet50 | 55.4% | 55.0% | |
| ILD-ConvNet50 | 75.3% | 75.2% |
| Methods | C-Sub | C-Set |
|---|---|---|
| Average | 75.3% | 75.2% |
| Product | 75.2% | 75.0% |
| Max | 74.9% | 74.9% |
| Methods | Modality | C-Sub | C-Set |
|---|---|---|---|
| BNInception | 52.5% | 53.1% | |
| ResNet50 | 51.4% | 51.3% | |
| ResNet101 | 56.5% | 54.1% | |
| BNInception | 75.4% | 76.2% | |
| ResNet50 | 73.8% | 74.0% | |
| ResNet101 | 77.2% | 78.4% | |
| ILD-ConvNet50 | 55.4% | 55.0% | |
| ILD-ConvNet101 | 57.2% | 56.2% | |
| ILD-ConvNet50 | 75.3% | 75.2% | |
| ILD-ConvNet101 | 82.4% | 83.1% | |
| J-ResNet-CMCB [45] | 82.8% | 83.6% | |
| TSN [16] + SC-ConvNet [44] | 86.9% | 87.7% | |
| TSN [16] + ILD-ConvNet101 | 86.9% | 89.4% |
| Methods | Modality | C-Sub | C-View |
|---|---|---|---|
| SA-LSTM [52] | skeleton | 86.3% | 91.4% |
| TA-LSTM [52] | skeleton | 86.6% | 92.3% |
| STA-LSTM [52] | skeleton | 86.9% | 92.6% |
| ResNet101 | 77.3% | 74.8% | |
| ResNet101 | 81.7% | 79.0% | |
| ResNet101 | 83.6% | 82.7% | |
| ILD-ConvNet101 | RGB + depth | 80.7% | 79.8% |
| J-ResNet-CMCB [45] | 90.4% | 91.4% | |
| TSN [16] + SC-ConvNet [44] | 92.1% | 93.2% | |
| TSN [16] + ILD-ConvNet101 | 92.0% | 93.1% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Q.; Gao, D.; Zhang, Q.; Wei, W.; Ren, Z. Interactive Learning of a Dual Convolution Neural Network for Multi-Modal Action Recognition. Mathematics 2022, 10, 3923. https://doi.org/10.3390/math10213923
Li Q, Gao D, Zhang Q, Wei W, Ren Z. Interactive Learning of a Dual Convolution Neural Network for Multi-Modal Action Recognition. Mathematics. 2022; 10(21):3923. https://doi.org/10.3390/math10213923
Chicago/Turabian StyleLi, Qingxia, Dali Gao, Qieshi Zhang, Wenhong Wei, and Ziliang Ren. 2022. "Interactive Learning of a Dual Convolution Neural Network for Multi-Modal Action Recognition" Mathematics 10, no. 21: 3923. https://doi.org/10.3390/math10213923