1. Introduction
Last-mile delivery is a term used to define the transportation of items from a depot to a final customer destination. Last-mile delivery is evolving at a rapid rate and has become a topic of great interest due to the increase in e-commerce in recent years, making it a key differentiator among large competitors in this sector.
We study a business model where the company outsources part of the activity of delivering products to its customers to occasional drivers, also known as crowdshipping, complementing its own fleet. All deliveries are completed at the minimum total cost incurred with the company vehicles and drivers plus the compensation paid to the ODs. The company decides on the best compensation scheme to offer to the ODs at the planning stage.
Crowd-shipped delivery has been adopted as a shortcut to last-mile growth. It has been implemented under different business models depending on how the occasional drivers are engaged and managed. A survey in [
1] indicates that while only 9% of retailers are using crowd-sourced providers now, one in four retailers plans to start using them in the next 12 months. It has been implemented as an enabler to same-day delivery for the last mile as can be seen in recent implementations of large companies as in [
2,
3,
4].
This setting also potentiates greater efficiency by making better use of existing urban traffic flows. For example, the case of crowdshipping with in-store customers taking up delivery tasks on their way home to serve online customers. As a result of fewer freight vehicles being used, the company’s costs are reduced while also benefiting society from the reduced traffic congestion.
Our setup is suitable for a same-day delivery scheme where time windows are fixed, predefined periods during the day and customers with online orders and available occasional drivers can enlist themselves in these time windows.
Crowdshipping last-mile delivery has been modeled as a variation of the vehicle routing problem (VRP) or the traveling salesman problem (TSP), under different deterministic, stochastic, and/or dynamic optimization approaches (e.g., [
5,
6,
7,
8,
9]).
A general topic presented in these works relates to the compensation offered to occasional drivers. Choosing an appropriate compensation scheme is challenging. Different compensation schemes presented in the literature have both advantages and disadvantages associated with them. It can affect the number of available occasional drivers and also which customer locations will be assigned to occasional drivers and not to the company’s drivers, affecting overall cost savings.
In general, all the compensation schemes proposed in the literature so far are static schemes (see
Section 2), in the sense that the decision-maker cannot decide on different compensation rates levels paid to the occasional drivers.
In this work, a flexible compensation scheme is proposed taking into account the occasional driver’s willingness to engage in a delivery task. Flexible pricing systems are still a recent subject under study in the crowdshipping literature and with only a few implementations (e.g., [
10]).
We are interested in analyzing the effect of the compensation level decision not only on the solution provided to our problem but also on the complexity associated with its resolution.
We adopt a data-driven dynamic and stochastic approach where the existence of online customers’ orders to be delivered, as well as the availability of occasional drivers to deliver them, are random and define scenarios on which decisions have to be made.
This problem is complex because decisions, regarding the dispatch of vehicles or occasional drivers, have to be made fast and the space to search for decisions is potentially too large. Here, we extend the work initiated in [
11] and propose a deep reinforcement learning (DRL) method where we model the problem as a sequence of states connected by actions, driven by decisions, and transitions. The DRL method uses a neural network (NN) as an approximation architecture for the problem value function. Our approach is data-driven: we make use of a generative method, exploiting available scenario historical data, to generate additional scenarios, that in turn are used to train the DRL neural network.
Another key feature of our DRL approach is how we search the action (decision) space. Most reinforcement learning (RL) studies on stochastic VRPs face the challenge imposed by the combinatorial nature of state and action spaces by restricting the action space and aggregating the state space based on expert knowledge. Here, we formulate the action selection problem for each state using a recourse in a two-stage decision model where the first-stage decision is formulated as a mixed-integer optimization program. In the first stage, not only the order in which all customers will be delivered is established, as in [
11], but also the best compensation to be paid for the outsourcing of each customer. The second-stage decision is made every time a scenario is revealed, and before any dispatch of fleet vehicles or ODs. The second-stage decision comprises routes defined by the recourse, where the routes follow the first-stage decision ordering but skip customers that have no online orders or customers outsourced for available ODs. Each time the vehicle capacity or the time window limit is reached, a return path to the depot is created and another route restarts from the depot if needed.
The main contributions of the approach above and the results of this work are:
We propose a novel data-driven stochastic and dynamic approach for crowdshipping last-mile delivery, where we introduce a flexible compensation scheme, advancing the state-of-the-art in this topic.
We experiment with generative methods to create new scenarios to train our neural network. Historical data are typically in small amounts and inadequate to evaluate the policies of our DRL approach. We exploit the fact that there is time correlation information hidden between scenarios included in the historical data. We learn this time correlation using conditional generative adversarial networks and use them as a tool to generate scenarios to evaluate our policies.
We present computational results on the capability of the proposed model, assuming a realistic point-of-view of correlated scenarios.
In the sequence of this work, in
Section 2, we present relevant approaches to solve problem variants. In
Section 3, we present our problem description and the defined model. In
Section 4 we introduce the DRL method developed. Next, in
Section 5, we discuss the computational results. Finally, in
Section 6, we present this work’s conclusions.
3. Stochastic Crowd Shipping Last-Mile Delivery with Endogenous Uncertainty
We follow [
11] and define a typical setting for our problem in which a store is the location for in-store customers and also the depot from where online customer orders are dispatched. In-store customers who are available to deliver online customers’ orders on their way back home are potentially offered the service. For their service, they are offered a small compensation and are referred to as ODs.
The store provides delivery services throughout fixed time windows during the day. Before each time window, and respecting a process defined by the store, a scenario is revealed with the available online customer orders, and the customers with available ODs. Based on the scenario revealed, the store decides the routes for its fleet of vehicles and which customer orders will be outsourced to ODs. This decision, in turn, defines the cost associated with that time window. The objective is to minimize the total costs in the long run.
The decision is taken in a two-stage approach, using a recourse model based on the work presented in [
15] under the framework of stochastic optimization. An a priori first-stage decision is made during the store planning process, meaning that we define a solution to our problem offline, and before any delivery is initiated. Not only is the order in which all customers will be delivered established, but also the best compensation to be paid to ODs by each customer order being outsourced. This compensation is a continuous variable and may be restricted to a feasible region defined by the company. The second-stage decision is made every time a scenario is revealed, and before any dispatch of fleet vehicles or ODs. The second-stage decision defines routes that follow the first-stage decision ordering but skips customers that have no online orders and customers outsourced for available ODs. In our recourse model, the store only offers the service to the OD if it is optimal for the scenario being revealed. Additionally, each time the vehicle capacity or the time window limit is reached, a return path to the depot is created and another route restarts from the depot if needed.
The recourse model adopted brings two main advantages to our DRL method presented later in
Section 4. First, it extremely reduces the action space since, in fact, only one decision, defined by the recourse, is possible at each decision point of our model. We recall that RL algorithms in general will require a small action space allowing enumeration or that is continuous. We also note that a very large action space remains to be searched during the first-stage decision, representing possible permutations of customers’ delivery ordering. Second, it presents a solution that is potentially very close to the decision adopted in a reoptimization strategy, where an optimal solution is calculated each time a scenario is revealed. The authors in [
15] show that, for their setup where random events associated with customers are assumed independent, both solutions are close, on average.
An important modeling feature of our implementation is that uncertainty is customer-related. We can model not only uncertainty for customers with no orders but also uncertainty related to the availability of ODs. This is an alternative to current crowdshipping last-mile delivery models, where uncertainty is related to the OD (e.g., [
8,
12]). This way we can reduce the complexity of the problem to beg solved since we do not deal with explicit ODs constraints, such as their quantity, capacity, and routes.
Our approach is data-driven. We assume a set of historical data is available with a sequence of scenarios expressing customer orders and ODs availability conditioned by the compensation offered.
In what follows, we detail our problem and introduce the notation used. Let be a directed graph, where is the set of vertices and is the set of arcs. Set V consists of a depot (vertex 0) and a subset of customers’ represented by their locations. We assume to facilitate our formulations.
A non-negative cost and a duration in time are associated with each arc . We assume that the graph is symmetric, i.e., , and they both satisfy triangular inequalities. We also assume that the company fleet vehicles are identical and can serve up to Q customers per time window and that all time window customers must be delivered within a time limit of D. There is a fixed number of K time windows during a day.
The binary vector defines a scenario. The vector component iff customer i has an online delivery order available and iff customer (i-N) has ODs available. If , customer i will be skipped by the routes defined by the recourse. If , customer i delivery order will be considered to be delivered by an OD. If , customer i delivery order will be served by the fleet of vehicles under routes defined by the recourse.
A compensation fee is defined for customer i outsourcing. We assume the compensation vector, , influences the joint distribution of scenarios . The feasible region F includes restrictions .
We define set as the support of the joint distribution and index scenarios using indicator .
We model our problem as a Markov decision process (MDP) where there is a sequence of states connected by actions, defined by policies, rewards, and transitions, and running through episodes. A decision point is defined at the beginning of each time window of a day. A decision point is when a recourse action is made. In the following we consider:
States : A state comprises all information needed to select an action and for our problem that is represented by the scenario that presents itself right before decision point k.
Actions : Action implements the recourse model at each decision point k, and defines routes and ODs allocation. The actions, together with the first-stage decision vectors and f, define a policy . Element of the first-stage decision z gives the order of delivery of customer i.
Reward function : The reward function expresses the immediate impact of an action on the objective value of our problem. Since action is a recourse under the defined policy, the reward function is dependent on z, f, and . The reward function is defined by the cost of routes and the OD payment is defined by the recourse.
Transitions: Transitions between states are given by exogenous information and related to the time correlation between scenarios. For our model, we assume scenario is conditioned not only by the compensation vector, f, but also by the precedent scenario .
Episodes: An episode for our setup problem is a day at the store, composed of K time windows and K decision points. A total return is defined for each episode.
Value function : A key concept of RL is the use of value functions to drive the search for good policies. In our problem, each policy has an expected or mean total return once z and f are given. The value function , as a function of z and f, expresses the expected total return by applying z and f.
Objective: A solution to our problem is a policy
that assigns an ordering of customers z and a compensation vector f. The optimal solution is a policy
that assigns a tuple
and
and minimizes the expected total return and can be expressed by
The difficulty in dealing with scenarios is to identify the sensitivity of customers to different prices. Indeed, potentially there is not enough available data to evaluate a certain compensation scheme. Additionally, exploring odd prices can lead to unreasonable ODs reactions. On the other hand, exploiting only low prices can have undesirable consequences on the business side. For all that we apply a data augmentation technique to add newly created synthetic data from existing data (see [
43]). We exploit the information contained in the historical data available by using conditional generative adversarial networks [
44] to learn the time correlation between scenarios and to artificially generate the additional scenarios needed, conditioned to the compensation paid to ODs.
Our goal is to forecast new sequences of scenarios. We want to learn the predictive probability distribution over future quantities. For this purpose, we apply a probabilistic forecasting method to quantify the variance in a prediction [
45].
One method for probabilistic forecasting which implies the implementation of neural networks, is the generative adversarial network (GAN). GANs are an approach to generative modeling. Generative modeling is an unsupervised learning task in machine learning that involves automatically learning the patterns in input data and which can generate outputs that could have been drawn from the original dataset. GANs train a generative model by framing the problem as a supervised learning problem with two neural network sub-models: the generator model that is trained to learn the distribution of data, and the discriminator model that tries to classify examples as either real (from the domain) or fake (generated). The two models are trained together in a zero-sum game, adversarial, until the discriminator model is fooled, meaning the generator model is generating plausible examples [
46].
In [
47], the authors introduce the concept of conditional GAN (cGAN) which is a GAN whose generator and discriminator are conditioned during training by using some additional information, named labels. During cGAN training, the generator learns to produce realistic examples for each label in the training dataset, and the discriminator learns to distinguish fake example-label pairs from real example-label pairs. cGAN can be used, for instance, as a method for time series forecasting if the labels are the previous time steps used to define possible realizations of the next time step of the referenced time series.
In [
48], the authors also exploit the capacity of cGANs to learn the distribution of time series data, allowing the generation of synthetic scenarios from the distribution. They argue that modeling synthetic data using a GAN has been a viable response to the challenge in machine learning which is to gain access to a considerable amount of quality data.
We then opt for a probabilistic model for multivariate time-series forecasting with the use of a cGAN. With cGAN, we learn the probability distribution of one step ahead scenario conditioned (labeled) not only to past scenario information, , but also to compensation fee values, , defined as first-stage decisions.
4. Deep Reinforcement Learning for Stochastic Last-Mile Delivery with Crowdshipping
We implement an on-policy and
-greedy policy iteration algorithm for value-based reinforcement learning with combinatorial actions. We leverage the strategy developed in [
31] where the authors model the value function as a small NN with a fully-connected hidden layer and rectified linear unit (ReLU) activations. The NN is reformulated as a mixed-integer program, as in [
32], and combined with the structure of the action space, the customers’ delivery ordering, and OD compensation, for policy improvement. This, together with the recourse model defined, greatly simplifies the complexity of the policy iteration algorithm while maintaining the possibility of searching the entire first-stage decision action space.
Given a randomly chosen starter -soft policy , where the first-stage decision can vary with probability , we repeatedly improve it. In the -th policy evaluation step, using the Monte Carlo method, we repeatedly apply the current -soft policy for episodes and average sample total returns after each episode. The episodes are defined using the sequence of scenarios provided by newly dynamically cGAN generated data, conditioned to the compensation fees defined by the policy. We use the average sample total returns provided using the Monte Carlo method to train the NN and incrementally approximate the value function . The NN learns by minimizing the mean-squared error (MSE) on the cumulative cost among all iterations of our algorithm.
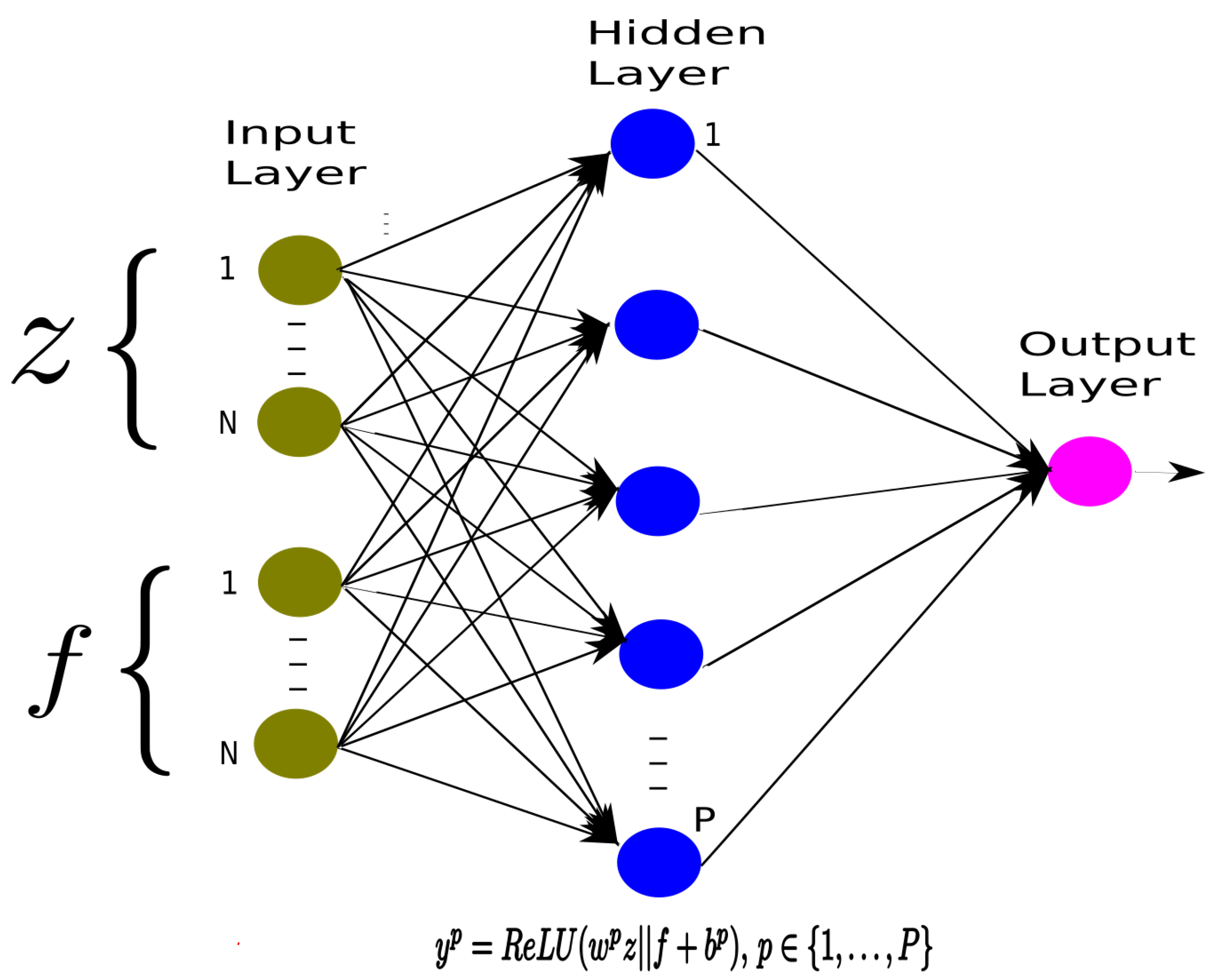
Figure 1 defines the architecture we implement for our DRL NN. The DRL NN has as input the vectors z and f, representing the customers’ delivery ordering and the ODs compensation vector; only one P hidden nodes layer with ReLU activation, and one linear output. Let
represent the weights vector and
the bias term for the p-th hidden node. We define
and
analogously for the output layer.
For the DRL policy evaluation step, we now detail how cGAN data is dynamically generated and used within the Monte Carlo method. We note that the cGAN itself is trained as a previous step, using historical data, as part of the DRL algorithm. The cGAN is trained only once. By doing this, we train the cGAN’s generator model to generate a new sequence of scenarios based on previous scenarios and the compensation fee defined. The cGAN’s generator model is then used as part of the DRL policy evaluation step to dynamically generate a new sequence of scenarios for the execution of the Monte Carlo method at each iteration.
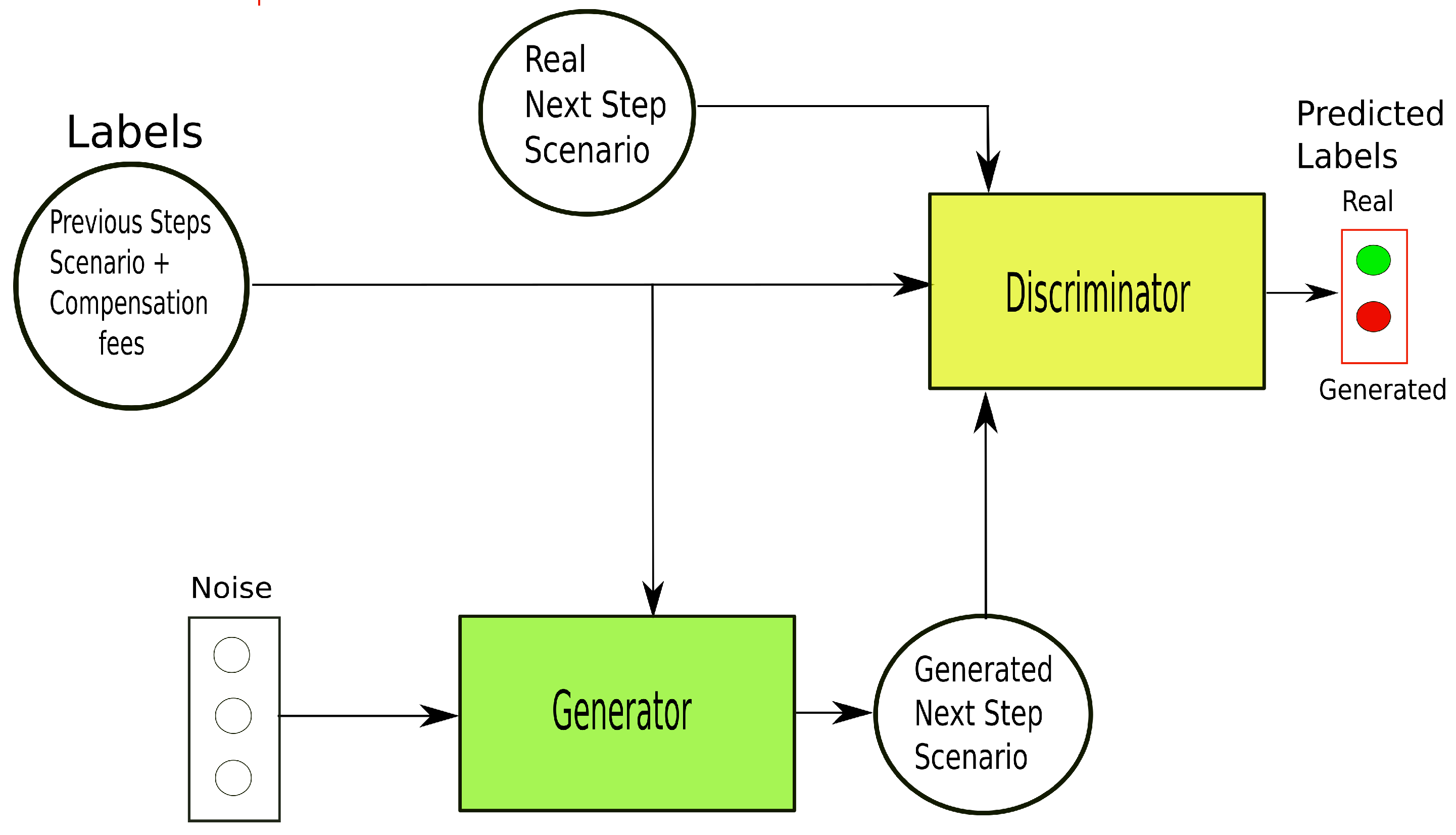
Figure 2 presents an overview of the cGAN. The cGAN englobes two neural networks, the generator and the discriminator. These NNs learn simultaneously in an adversarial process, with a two-player minimax game. First, we perform the conditioning by feeding the label representing the previous scenarios and compensation fees defined, into both the discriminator and generator as an additional input layer. The generator has the noise vector as input, which is sampled from a mean 0 and standard deviation 1 Gaussian distribution and forecasts
with regard to the conditioning label. The discriminator has
as input and verifies whether it is a valid value to follow the label or not. The discriminator is optimized to distinguish between generated data and real data.
The optimal generator NN models the probability distribution of , conditioned to a label. In the end, information regarding any possible outcome can be extracted by sampling.
There are different ways to include conditional information in the neural network. Different approaches can be developed for how this information should be combined, or where in the network it should be included. Here, we include the label only in the input layer for the two networks and the representation data of the label is learned first by passing scenarios through a Long Short-Term Memory (LSTM) layer. LSTM neural networks, as introduced in [
49], are distinguished by their “memory” as they take information from prior inputs to influence the current input and output.
The LSTM output is then concatenated with the compensation fee vector to finally compound the representation data.
Then, the noise vector, concatenated with the label is passed through two dense layers, leading to the predicted value. The discriminator inputs from the generator output or from the historical dataset concatenated with the label. This data passes a dense layer that outputs a single value specifying the output validity.
Our approach has to deal with a multivariate setting. In the multivariate setting, more complex NN architectures are needed to figure out dependencies between features. cGANs also require precise hyperparameter tuning to have a stable training process. It can be cumbersome to find adequate generator and discriminator architecture concurrently to perform adequately. To address this challenge we further adopt the cGAN training strategy of [
44]. They build a probabilistic forecaster based on a deterministic forecaster using the GAN architecture. Namely, the generator model is based on the architecture and hyper- parameters of the deterministic forecaster. They search a generator and discriminator architecture separately, which results in the simplification of the architecture’s overall definition.
We now proceed with the policy improvement step of our DRL method. The
-th policy improvement step involves solving the optimization problem related to (
1), meaning that we find the first-stage decision to our problem that minimizes the expected total return expressed by the current approximation of the value function. Problem (
1) is formulated as (see [
32]):
where
indicates the set of indices i such that
and components
and
are defined as
for and
for .
Formulation’s Big-Ms are set as and , where is the vector resulting from the concatenation of vectors z and f and is the inner product of vectors and . We define the N decision variables , , giving the sequence in which customers will be delivered, a continuous variable defining the compensation paid for each customer outsourced, a continuous variable that models the output of the hidden node p and a binary variable that indicates whether the pre-activation function is positive or negative (i.e., whether the ReLU is active or not). We also introduce variables to define the delivery order: if customer i precedes customer j and 0 otherwise.
This pre-activation function is enforced by the “big-M ” constraints (
4) and (
5). The formulation is not polynomial in size, as there are exponentially many constraints of type (
6), but these constraints simply strengthen the formulation.
Constraints (
7) to (
9) define the feasible region of all possible ordering of customers.
To be able to solve large instances and still have good solutions, we define a time limit of 1800 s to solve problem (
1) at each policy improvement step and use the best solution provided until then. We apply warm start, callbacks to introduce lazy constraints and heuristics, and use only the needed half of
variables, where
.
We warm start not only in an attempt to accelerate resolution but also to guarantee one incumbent solution. We adapt the Almost Nearest Neighbor Heuristic defined in the study of heuristic algorithms for the probabilistic TSP in [
50], which considers independent marginals. We set a solution in an attempt to have a good feasible initial incumbent solution. The ordering of customers is defined by appending the customer with the lowest change in expected length from the last inserted customer to the tour. For a given set T of customers already inserted in a tour, inserting customer j with minimum cost is computed as
where
is the marginal Bernoulli probability of the component
of the uncertain scenario vector given by the historical data. We also set
.
Constraints (
6) are introduced as cutting planes by lazy constraints callbacks using a linear-time separation routine as described in [
32]. Heuristics callbacks introduce simple heuristics by setting variables
as binaries and following the same customer order given by the z relaxed solution.
Algorithm 1 summarizes the steps undertaken in our policy iteration algorithm.
| Algorithm 1: Policy iteration algorithm |
Initialize: an arbitrary -soft policy with Train cGAN using scenarios historical data Initialize empty dataset Repeat for each policy iteration Repeat for each episode: Generate scenarios for episode using cGAN generator model Generate an episode following : Loop for each step of episode, : Append to Use VD to incrementally train the NN and approximate value function Va using Va function MIP formulation Define -soft policy with
|
We define two forms for the reward calculation. Here, we want an optimal assignment of ODs. To perform this exactly we first formulate it as an optimization problem. The formulation for this problem is given as
where we define variables
= 1 if customer i is served by a vehicle right before j, 0 otherwise,
= 1 if customer i is served by an OD, 0 otherwise,
= 1 if customer i is served by a vehicle, 0 otherwise,
as the accumulated capacity loaded between customer i and j and
as the accumulated time spent between customer i and j. The objective is to minimize the total cost of routes plus OD payments. Constraints (
12) and (
13) are route flow conservation and should be considered every time a customer is included in a route,
. Constraints (
14) define that customer i is served by a vehicle, or an OD or none. Constraints (
15) define that customer i is served by a vehicle or an OD if
. Constraints (
16) and (
17) define that customer i is not served by an OD or a vehicle if
. Constraints (
18) define that customer i is served by an OD only if an OD is available. Constraints (
19) to (
22) define the capacity restrictions. Constraints (
23) to (
25) define the time duration restrictions. Constraints (
26) and (
27) guarantee that the order of first-stage decision z is respected. Here, z, f and
are data input to the problem. For our algorithms, we define a time limit of 600 s to solve the problem relative to this formulation and use the best solution provided until then.
As an alternative, we provide a heuristic for reward calculation where the condition to reduce cost by OD assignment is verified only locally. By Algorithm 2, customers are allocated to ODs only if the corresponding OD compensation fee is less than the vehicle cost to route from the previous to the next available customer (customers with delivery orders in the scenario being referenced).
| Algorithm 2: Reward function for variant 2 of recourse model |
Initialize: ; depot ; cost of vehicles route ; accumulated capacity of a vehicle ; accumulated time duration of a vehicle route ; define when to stop algorithm ; should bypass OD available while continue if and or if if elseif cap == Q else if assume 2*time from depot to timelimit always else elseif and find next customer available while and if and elseif and if elseif and elseif and else if if
|
5. Experiments and Computational Results
The experiments have a three-fold objective: (1) analyze the effect of considering a flexible compensation scheme from a solution improvement perspective; (2) analyze the sensitivity of the algorithm’s solution to key parameters; and (3) analyze the performance of the algorithms we have implemented.
To pursue this objective, we present in the sections below, the instances setting and the implemented benchmark algorithms.
Algorithms were developed in Python, with Keras, Tensorflow, and Docplex integrated with Cplex 12.9, running with a machine with 16 GB of RAM and Intel I7 CPU at 2.30 GHz. We present key parameters and additional architectural features defined for the DRL algorithm and used in the experiment:
We define key parameters with default values: number of nodes of the hidden layer of the NN as 16, number of policy iterations as 15, number of historical scenarios in sequence for cGAN as 1500 and number of scenarios generated by cGAN for DRL Monte Carlo Simulation as 800,000. For some of the experiments, when specified, we change default values to analyze the sensitivity of the DRL method to these changes.
Exploration and exploitation during training are performed by setting -soft policies. We set the probability of exploring and exploiting and decay over the policy iterations.
We apply a learning rate with an exponential decay from 0.01 with the base 0.96 and the decay rate 1/6000 for updating weights.
We pass through the entire episodes dataset 100 times (epochs) with a batch size of 100.
5.1. Instances
We generate random test instances having vertices (depot and customers) for different values of . Five instances for each number of customers are generated. Results indicated by the number of customers are an average of the results of all their associated instances.
Customers’ locations for each instance are assigned randomly from a grid of 100 × 100 possible locations. We assume that travel times and costs are deterministic and proportional to the euclidean distances between customers.
The compensation fee limits and for each customer i are set to the minimal and maximal detour considering all pairs of customers plus a small value , to avoid zero compensations, and given by and .
Customers’ orders and OD availability occur randomly around the day and present themselves for each time window as scenarios. We assume there is a sequence of scenarios, conditioned by compensation fee, available as data and that is sufficient to train the cGAN.
We artificially generate these scenarios for our test instances based on two probability vectors that define for each customer , a marginal probability for his/her order, and a marginal probability for the availability of an OD to attend him/her. The marginal probability is dependent on the compensation fee , defined as a pair .
To assure scenario consistency, the OD availability is only assigned when the respective customer is also assigned to a delivery order. To introduce a correlation between scenarios we force customers to have a maximum of one delivery order per day. We generate 1500 scenarios that are used to train the cGAN, plus 1500 scenarios that are used to simulate the solutions provided by the algorithms (out-of-sample performance). Note that the cGAN 1500 scenarios generated to simulate the solutions are, as always with the cGAN, conditioned for the compensation fees defined as first-stage solutions.
We assume that the pairs generated are coherent, in the sense that the compensation fee influences the probability of an OD accepting to outsource.
The values are assigned randomly for each instance in a range smaller than 0.3.
We set three values for , , , . The values of are assigned randomly for each instance, according to the values of . If , then is assigned in a range smaller than 0.1. If , then is assigned in a range greater than 0.3. If , , then is assigned in a range between 0.1 and 0.3.
Each episode is composed of a delivery day with four time windows of 2 h each, and therefore, four scenarios.
The professional fleet vehicle capacity is set to and the time limit of a route is given by the time windows of 2 h.
5.2. Benchmark Algorithms
We present in
Table 1 a general description of the different algorithms we run our instances with.
Besides implementing algorithms
and
for the methods presented in
Section 4, we implement algorithm
to run the same instances.
is the algorithm developed in [
11] for the heuristic recourse. The difference is that the compensation fees are not a decision to be made. They are fixed and set to
.
was implemented to allow us to verify the power of flexible compensation for our instances, running with the other algorithms.
5.3. Initial Insights
We start by gaining qualitative insights into the potential benefits of different compensation levels for crowdshipping the last-mile delivery. We want to understand the sensitivity to problem characteristics and for this, we analyze some specific toy instances.
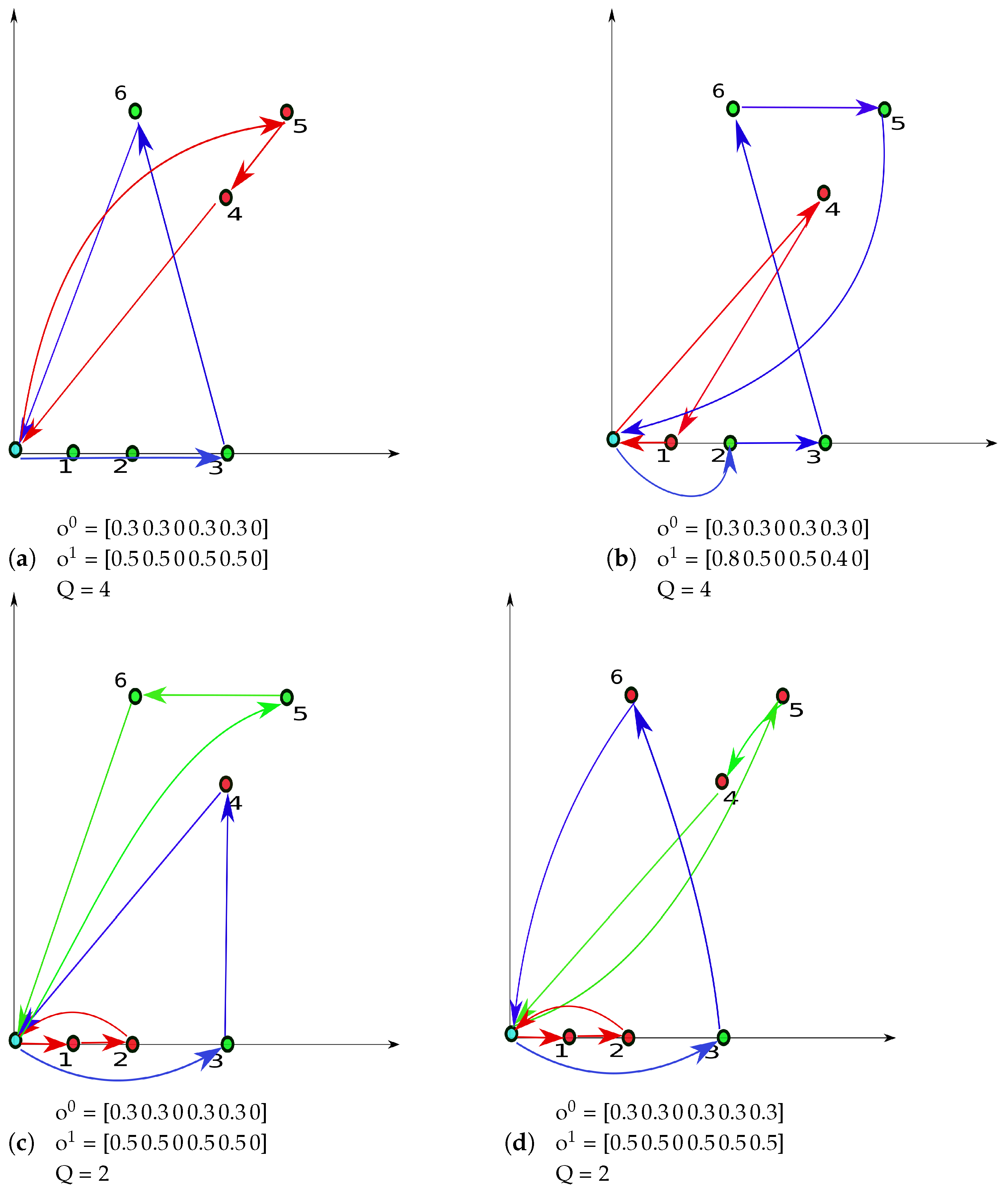
Figure 3 presents four instances indicating six customers’ positions in a graph, the best-constructed routes defined for a scenario where all customers have online orders and no ODs available, and what level of compensation was paid for each customer being outsourced, as in the solution of our
algorithm.
For these toy examples, we assume there exist only two levels of compensation, , for the lower level, and for the higher level. For compensation fees and , we assume the scenarios follow a distribution probability where the Bernoulli marginals of elements are equal to 100 %, and the Bernoulli marginals of elements are equal to and , respectively.
The level of compensation paid for each instance is indicated by the color given to the customer location in the graph, referenced by axes, being red for the higher level of compensation and green for the lower level. The depot is located at the origin of the axes. Each route is indicated also by arrows in different colors.
Below each graph, we indicate the assumptions made for vectors , , and capacity Q.
Our exercise here is to verify how the solution (routes and level of compensation) changes with the assumptions of , , , , and Q.
In
Figure 3a customers 3 and 6 are fixed to be delivered by the professional fleet (
). Since in this case
, the solution creates only two routes and leaves the two fixed customers to be delivered in sequence. We note that, since in this instance, a straight path between the depot and customer 3 can always be performed including customers 1 and 2 with no extra cost, then it was not worth offering customers 1 and 2 a higher compensation fee.
The instance in
Figure 3b has the same assumptions as in
Figure 3a, except that now, for the same
we increase the probability
and decrease
. A naive expectation would be that, in this case, it would continue not to be worth paying extra for customer 1 since we have a straight path to customer 3 still. Different from that, the algorithm is now able to change the route solution and will pay extra for another set of two customers only.
Now in
Figure 3c, we also replicate assumptions of
Figure 3a, except the capacity
. We see that, in this case, three customers are selected to pay extra instead of two, and the route including in sequence customers 1, 2, and 3 is not worth it anymore due to restrictions in vehicle capacity.
For
Figure 3d, we just change the assumption of instance in
Figure 3c and make customer 6 not fixed in this case. By doing this, the solution changes and now it is worth paying extra for all customers except the fixed customer 3.
We verify by analyzing these different examples that many things can happen and are not always intuitive.
Figure 3 shows the sensitivity of the solution not only to the compensation employed but also to the many parameters used and highlights the challenge of defining an adequate compensation scheme.
5.4. Solution Quality
To assess the performance of the solutions provided by the different algorithms, we simulate these solutions through various episodes using the scenarios created for this purpose, providing an out-of-sample estimate. We compare the algorithms’ total cost output of this simulation.
Table 2 reports, for all instances and by the number of customers, the average percentage gap between total cost values when compared to the
algorithm total cost. Overall, we observe that all algorithms provide total costs within a range of 10% of the
total cost for the simulation proposed. This puts in evidence the potential of the flexible compensation scheme to improve savings. As would be expected, we also verify that the
exact solution provided larger cost savings when compared to
.
We also present in
Table 3 the average percentage of ODs not accepted to outsource a customer, among those available. We present these numbers for algorithms
and
. We want to analyze if possibly increasing the compensation fee, as in the case of
, leads to an increase in the percentage of ODs not being accepted for outsourcing. An increase in the percentage of ODs not accepted could affect the success of the proposed business model. We verify by
Table 3 that there is not a direct relationship between flexible compensation and the percentage of ODs accepted to outsource. Results depend on the configuration setup of each instance.
To verify the quality of the solution, we also estimate an upper bound total cost by running the out-of-sample simulation with a randomly generated first-stage solution as input.
Table 4 presents the results as a percentage gap between the upper bound cost (
) and
cost. There is an average improvement of 14.48% by running
solutions when compared to
.
5.5. Sensitivity to Parameters Configuration
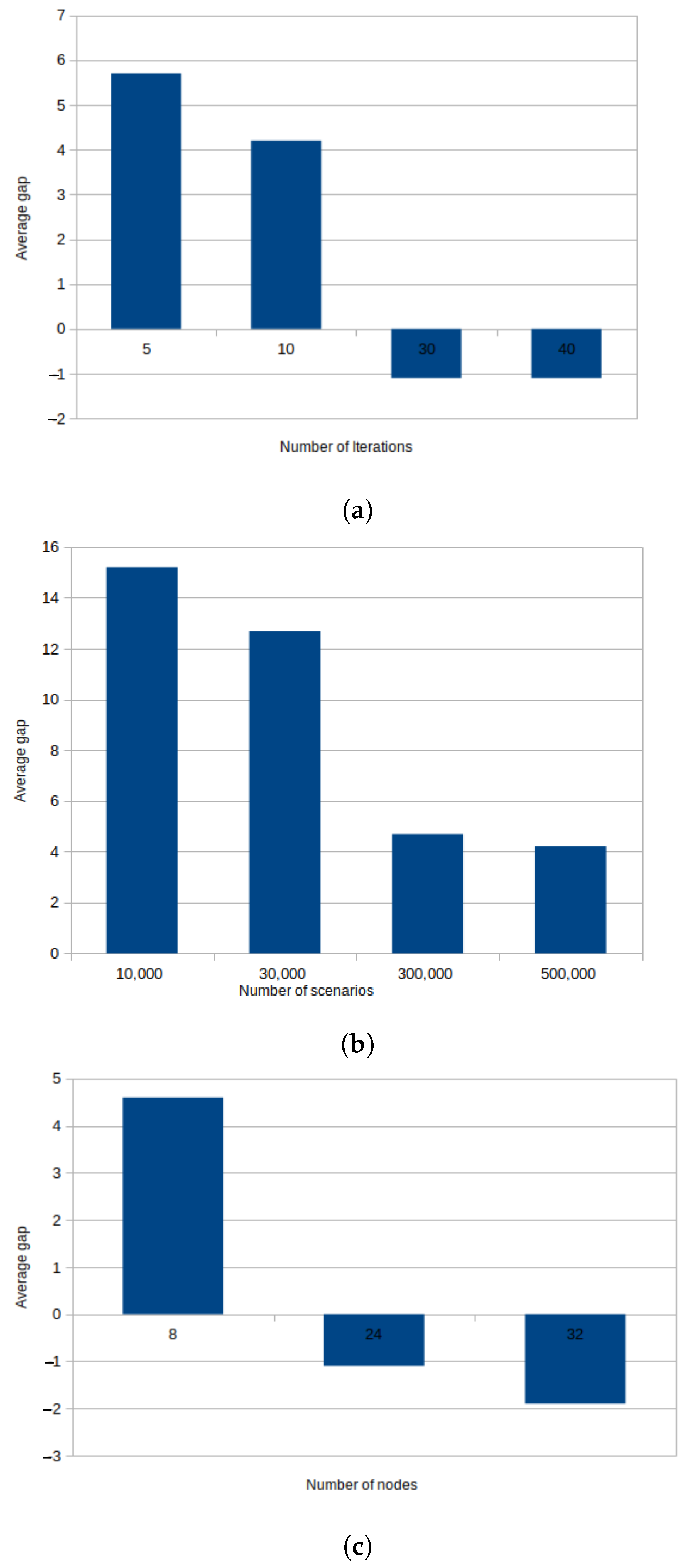
In this section, we analyze the effect of changing the number of policy iterations, the number of training scenarios, and the number of the NN hidden layer nodes on the solution quality presented as the percentage average gap between the total cost output of the simulation running the
first-stage solution provided with new parameters, as compared to
first-stage solution run with default parameters. We change each of the parameters independently while maintaining the other parameters as default. This is reported in
Figure 4a–c, respectively.
In
Figure 4a,b, we note that decreasing the number of training scenarios can be compensated by increasing the number of policy iterations to maintain solution quality and vice versa. It would be a matter of identifying which combination of both provides the best time performance. Since the policy evaluation phase of our algorithm is very fast, due to the simple recourse, we have opted to increase the number of training scenarios as default.
In
Figure 4c, we analyze the effects of increasing NN size on the solution quality. We experience the same effect as with the other experiments. Overall, the number of nodes is a determinant of the solution quality.
5.6. Algorithms Performance
In
Table 5, we present the time performance of algorithms
and
. It reports the average total time to find offline the first-stage solution, by the number of customers
. We note that the time spent by both algorithms can be further altered by adjusting the solution quality through parameters number of policy iterations, number of training episodes, and number of NN nodes.
Both and scale well for the number of customers and can be used to solve large instances. Since both algorithms run offline, they can be used for dynamic routing decisions when the scenarios are revealed. If time performance is not a critical issue, should be preferred since it provides better quality solutions.






{kind=link}
{kind=link}
{kind=link}
{kind=link}