


Optimizing Echo State Networks for Enhancing Large Prediction Horizons of Chaotic Time Series

 , , and
, , and
Abstract
:1. Introduction
2. ESN and PSO Algorithms
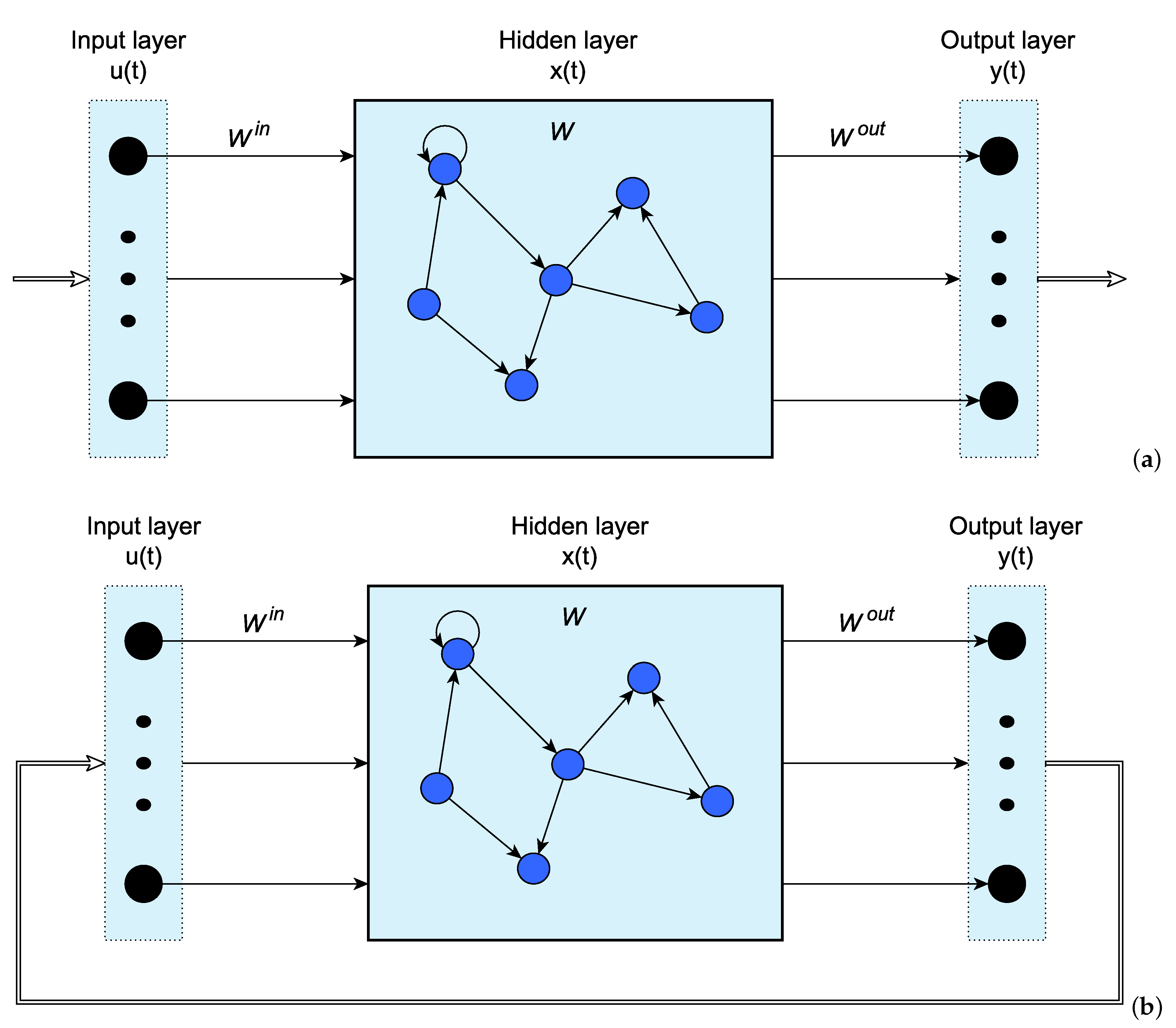
2.1. Echo State Network
2.2. Particle Swarm Optimization (PSO) Algorithm
- 1.
- Initialize a population of particles with random positions and velocities on D-dimensions in the problem space.
- 2.
- For each particle, evaluate the desired optimization fitness function in D-variables.
- 3.
- Compare the particle’s fitness evaluation with its . If the current value is better than , then set equal to the current value, and equals the current location in the D-dimensional space.
- 4.
- Identify the particle in the neighborhood with the best success so far and assign its index to the variable g.
- 5.
- Change the velocity and position of the particle according to the following equation:
- 6.
- Loop to step 2 until a criterion is met, usually a sufficiently good fitness or a maximum number of iterations [34].
3. Datasets of Lorenz System and HRN
3.1. Lorenz System
3.2. Hindmarsh–Rose Neuron
3.3. Decimation of the Chaotic Time Series
4. Prediction Using ESNs
4.1. Lorenz System
4.2. Hindmarsh–Rose Neuron
5. ESN Optimization Using PSO
5.1. Echo State Network Optimization
5.2. Enhanced Prediction of Lorenz System Using Optimized ESN
5.3. Enhanced Prediction of Hindmarsh–Rose Neuron Using Optimized ESN
5.4. Prediction Results and Comparison with Related Works
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Nadiga, B.T. Reservoir Computing as a Tool for Climate Predictability Studies. J. Adv. Model. Earth Syst. 2021, 13, e2020MS002290. [Google Scholar] [CrossRef]
- Dueben, P.D.; Bauer, P. Challenges and design choices for global weather and climate models based on machine learning. Geosci. Model Dev. 2018, 11, 3999–4009. [Google Scholar] [CrossRef] [Green Version]
- Scher, S. Toward Data-Driven Weather and Climate Forecasting: Approximating a Simple General Circulation Model With Deep Learning. Geophys. Res. Lett. 2018, 45, 12616–12622. [Google Scholar] [CrossRef] [Green Version]
- Shahi, S.; Marcotte, C.D.; Herndon, C.J.; Fenton, F.H.; Shiferaw, Y.; Cherry, E.M. Long-Time Prediction of Arrhythmic Cardiac Action Potentials Using Recurrent Neural Networks and Reservoir Computing. Front. Physiol. 2021, 12, 734178. [Google Scholar] [CrossRef] [PubMed]
- Kim, K.j. Financial time series forecasting using support vector machines. Neurocomputing 2003, 55, 307–319. [Google Scholar] [CrossRef]
- Chattopadhyay, A.; Hassanzadeh, P.; Subramanian, D. Data-driven predictions of a multiscale Lorenz 96 chaotic system using machine-learning methods: Reservoir computing, artificial neural network, and long short-term memory network. Nonlinear Process. Geophys. 2020, 27, 373–389. [Google Scholar] [CrossRef]
- Munir, F.A.; Zia, M.; Mahmood, H. Designing multi-dimensional logistic map with fixed-point finite precision. Nonlinear Dyn. 2019, 97, 2147–2158. [Google Scholar] [CrossRef]
- Valencia-Ponce, M.A.; Tlelo-Cuautle, E.; de la Fraga, L.G. Estimating the Highest Time-Step in Numerical Methods to Enhance the Optimization of Chaotic Oscillators. Mathematics 2021, 9, 1938. [Google Scholar] [CrossRef]
- Pathak, J.; Hunt, B.; Girvan, M.; Lu, Z.; Ott, E. Model-Free Prediction of Large Spatiotemporally Chaotic Systems from Data: A Reservoir Computing Approach. Phys. Rev. Lett. 2018, 120, 024102. [Google Scholar] [CrossRef] [Green Version]
- Thissen, U.; van Brakel, R.; de Weijer, A.P.; Melssen, W.J.; Buydens, L.M.C. Using support vector machines for time series prediction. Chemom. Intell. Lab. Syst. 2003, 69, 35–49. [Google Scholar] [CrossRef]
- Scher, S.; Messori, G. Generalization properties of feed-forward neural networks trained on Lorenz systems. Nonlinear Process. Geophys. 2019, 26, 381–399. [Google Scholar] [CrossRef] [Green Version]
- Amil, P.; Soriano, M.C.; Masoller, C. Machine learning algorithms for predicting the amplitude of chaotic laser pulses. Chaos Interdiscip. J. Nonlinear Sci. 2019, 29, 113111. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Antonik, P.; Gulina, M.; Pauwels, J.; Massar, S. Using a reservoir computer to learn chaotic attractors, with applications to chaos synchronization and cryptography. Phys. Rev. E 2018, 98, 012215. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vlachas, P.R.; Pathak, J.; Hunt, B.R.; Sapsis, T.P.; Girvan, M.; Ott, E.; Koumoutsakos, P. Backpropagation algorithms and Reservoir Computing in Recurrent Neural Networks for the forecasting of complex spatiotemporal dynamics. Neural Netw. 2020, 126, 191–217. [Google Scholar] [CrossRef] [Green Version]
- Lu, Z.; Hunt, B.R.; Ott, E. Attractor reconstruction by machine learning. Chaos Interdiscip. J. Nonlinear Sci. 2018, 28, 061104. [Google Scholar] [CrossRef] [Green Version]
- Arcomano, T.; Szunyogh, I.; Pathak, J.; Wikner, A.; Hunt, B.R.; Ott, E. A Machine Learning-Based Global Atmospheric Forecast Model. Geophys. Res. Lett. 2020, 47, e2020GL087776. [Google Scholar] [CrossRef]
- Tian, Z. Echo state network based on improved fruit fly optimization algorithm for chaotic time series prediction. J. Ambient. Intell. Humaniz. Comput. 2022, 13, 3483–3502. [Google Scholar] [CrossRef]
- Pano-Azucena, A.D.; Tlelo-Cuautle, E.; Ovilla-Martinez, B.; de la Fraga, L.G.; Li, R. Pipeline FPGA-Based Implementations of ANNs for the Prediction of up to 600-Steps-Ahead of Chaotic Time Series. J. Circuits Syst. Comput. 2021, 30, 2150164. [Google Scholar] [CrossRef]
- Pathak, J.; Wikner, A.; Fussell, R.; Chandra, S.; Hunt, B.R.; Girvan, M.; Ott, E. Hybrid forecasting of chaotic processes: Using machine learning in conjunction with a knowledge-based model. Chaos Interdiscip. J. Nonlinear Sci. 2018, 28, 041101. [Google Scholar] [CrossRef] [Green Version]
- Li, D.; Han, M.; Wang, J. Chaotic Time Series Prediction Based on a Novel Robust Echo State Network. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 787–799. [Google Scholar] [CrossRef]
- Griffith, A.; Pomerance, A.; Gauthier, D.J. Forecasting chaotic systems with very low connectivity reservoir computers. Chaos Interdiscip. J. Nonlinear Sci. 2019, 29, 123108. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Racca, A.; Magri, L. Robust Optimization and Validation of Echo State Networks for learning chaotic dynamics. Neural Netw. 2021, 142, 252–268. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Zeng, Y.R.; Wang, S.; Wang, L. Optimizing echo state network with backtracking search optimization algorithm for time series forecasting. Eng. Appl. Artif. Intell. 2019, 81, 117–132. [Google Scholar] [CrossRef]
- Chen, H.C.; Wei, D.Q. Chaotic time series prediction using echo state network based on selective opposition grey wolf optimizer. Nonlinear Dyn. 2021, 104, 3925–3935. [Google Scholar] [CrossRef]
- Pathak, J.; Lu, Z.; Hunt, B.R.; Girvan, M.; Ott, E. Using machine learning to replicate chaotic attractors and calculate Lyapunov exponents from data. Chaos Interdiscip. J. Nonlinear Sci. 2017, 27, 121102. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Bi, F.; Yang, X.; Bi, X. An Echo State Network with Improved Topology for Time Series Prediction. IEEE Sensors J. 2022, 22, 5869–5878. [Google Scholar] [CrossRef]
- Strogatz, S. Nonlinear Dynamics and Chaos (Studies in Nonlinearity); CRC Press: Boca Raton, FL, USA, 1994. [Google Scholar] [CrossRef]
- Wang, T.; Wang, D.; Wu, K. Chaotic Adaptive Synchronization Control and Application in Chaotic Secure Communication for Industrial Internet of Things. IEEE Access 2018, 6, 8584–8590. [Google Scholar] [CrossRef]
- Jaeger, H. A Tutorial on Training Recurrent Neural Networks, Covering BPPT, RTRL, EKF and the “Echo State Network” Approach; GMD Report 159; German National Research Center for Information Technology: St. Augustin, Germany, 2002; p. 46. [Google Scholar]
- Bala, A.; Ismail, I.; Ibrahim, R.; Sait, S.M. Applications of Metaheuristics in Reservoir Computing Techniques: A Review. IEEE Access 2018, 6, 58012–58029. [Google Scholar] [CrossRef]
- Jaeger, H.; Lukoševičius, M.; Popovici, D.; Siewert, U. Optimization and applications of echo state networks with leaky- integrator neurons. Neural Netw. 2007, 20, 335–352. [Google Scholar] [CrossRef]
- Yildiz, I.B.; Jaeger, H.; Kiebel, S.J. Re-visiting the echo state property. Neural Netw. 2012, 35, 1–9. [Google Scholar] [CrossRef]
- Bai, Q. Analysis of particle swarm optimization algorithm. Comput. Inf. Sci. 2010, 3, 180. [Google Scholar] [CrossRef] [Green Version]
- Shi, Y. Particle swarm optimization. IEEE Connect. 2004, 2, 8–13. [Google Scholar]
- Tsaneva-Atanasova, K.; Osinga, H.M.; Rieß, T.; Sherman, A. Full system bifurcation analysis of endocrine bursting models. J. Theor. Biol. 2010, 264, 1133–1146. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dolecek, G.J. Advances in Multirate Systems; Springer: New York, NY, USA, 2017. [Google Scholar]
- Chlouverakis, K.E.; Sprott, J.C. A comparison of correlation and Lyapunov dimensions. Phys. D Nonlinear Phenom. 2005, 200, 156–164. [Google Scholar] [CrossRef]
- Zhang, Y.; Yu, Y.; Liu, D. The Application of modified ESN in chaotic time series prediction. In Proceedings of the 2013 25th Chinese Control and Decision Conference (CCDC), Guiyang, China, 25–27 May 2013; pp. 2213–2218. [Google Scholar] [CrossRef]
- Xu, D.; Lan, J.; Principe, J. Direct adaptive control: An echo state network and genetic algorithm approach. In Proceedings of the 2005 IEEE International Joint Conference on Neural Networks, Montreal, QC, Canada, 31 July–4 August 2005; Volume 3, pp. 1483–1486. [Google Scholar] [CrossRef] [Green Version]
- Chouikhi, N.; Ammar, B.; Rokbani, N.; Alimi, A.M. PSO-based analysis of Echo State Network parameters for time series forecasting. Appl. Soft Comput. 2017, 55, 211–225. [Google Scholar] [CrossRef]
- Yusoff, M.H.; Chrol-Cannon, J.; Jin, Y. Modeling neural plasticity in echo state networks for classification and regression. Inf. Sci. 2016, 364–365, 184–196. [Google Scholar] [CrossRef]
- Bompas, S.; Georgeot, B.; Guéry-Odelin, D. Accuracy of neural networks for the simulation of chaotic dynamics: Precision of training data vs precision of the algorithm. Chaos Interdiscip. J. Nonlinear Sci. 2020, 30, 113118. [Google Scholar] [CrossRef] [PubMed]
- Tlelo-Cuautle, E.; González-Zapata, A.M.; Díaz-Muñoz, J.D.; de la Fraga, L.G.; Cruz-Vega, I. Optimization of fractional-order chaotic cellular neural networks by metaheuristics. Eur. Phys. J. Spec. Top. 2022, 231, 2037–2043. [Google Scholar] [CrossRef]
- Tlelo-Cuautle, E.; Díaz-Muñoz, J.D.; González-Zapata, A.M.; Li, R.; León-Salas, W.D.; Fernández, F.V.; Guillén-Fernández, O.; Cruz-Vega, I. Chaotic Image Encryption Using Hopfield and Hindmarsh–Rose Neurons Implemented on FPGA. Sensors 2020, 20, 1326. [Google Scholar] [CrossRef] [Green Version]
- González-Zapata, A.M.; Tlelo-Cuautle, E.; Cruz-Vega, I.; León-Salas, W.D. Synchronization of chaotic artificial neurons and its application to secure image transmission under MQTT for IoT protocol. Nonlinear Dyn. 2021, 104, 4581–4600. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| D | None | 10 | 25 | 50 |
|---|---|---|---|---|
| LE+ | ||||
| D | Steps Ahead | Total Steps Ahead | Steps Predicted | RMSE | CC |
|---|---|---|---|---|---|
| None | 250 | 250 | 5000 | ||
| 10 | 80 | 800 | 5040 | ||
| 25 | 60 | 1500 | 5040 | ||
| 50 | 30 | 1500 | 5010 |
| D | None | 10 | 25 | 50 |
|---|---|---|---|---|
| LE+ | ||||
| D | Steps Ahead | Total Steps Ahead | Steps Predicted | RMSE | CC |
|---|---|---|---|---|---|
| None | 350 | 350 | 10,150 | ||
| 10 | 100 | 1000 | 10,000 | ||
| 25 | 45 | 1125 | 10,035 | ||
| 50 | 7 | 350 | 10,000 |
| Run | D | Steps Ahead | Total Steps Ahead | Steps Predicted | RMSE |
|---|---|---|---|---|---|
| 1 | 25 | 250 | 6250 | 5000 | |
| 2 | |||||
| 3 | |||||
| 4 | |||||
| 5 | |||||
| 6 | |||||
| 1 | 50 | 200 | 10,000 | 5000 | |
| 2 | |||||
| 3 | |||||
| 4 | |||||
| 5 | |||||
| 6 |
| Run | D | Steps Ahead | Total Steps Ahead | Steps Predicted | RMSE |
|---|---|---|---|---|---|
| 1 | 10 | 700 | 7000 | 5600 | |
| 2 | |||||
| 3 | |||||
| 4 | |||||
| 5 | |||||
| 6 | |||||
| 1 | 25 | 300 | 7500 | 5100 | |
| 2 | |||||
| 3 | |||||
| 4 | |||||
| 5 | |||||
| 6 |
| Method | Lorenz | HRN | ||||||
|---|---|---|---|---|---|---|---|---|
| Steps Ahead | RMSE | Neurons | Steps Ahead | RMSE | Neurons | |||
| ESN | 250 | 100 | 350 | 100 | ||||
| ESN + D10 | 800 | 100 | 1000 | 100 | ||||
| ESN + D25 | 1500 | 100 | 1125 | 100 | ||||
| ESN + D50 | 1500 | 100 | 350 | 100 | ||||
| ESN + PSO + D10 | — | — | — | — | 7000 | 100 | ||
| ESN + PSO + D25 | 6250 | 100 | 7500 | 100 | ||||
| ESN + PSO + D50 | 10,000 | 100 | — | — | — | — | ||
| ESN [25] | 300 | — | 300 | — | — | — | — | |
| ESN [6] | 460 | — | 5000 | — | — | — | — | |
| RNN-LSTM [6] | 180 | — | 5000 | — | — | — | — | |
| ANN [6] | 120 | — | 5000 | — | — | — | — | |
| ESN [42] | 700 | — | 300 | — | — | — | — | |
| RESN [20] | 500 | 200 | — | — | — | — | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
González-Zapata, A.M.; Tlelo-Cuautle, E.; Ovilla-Martinez, B.; Cruz-Vega, I.; De la Fraga, L.G. Optimizing Echo State Networks for Enhancing Large Prediction Horizons of Chaotic Time Series. Mathematics 2022, 10, 3886. https://doi.org/10.3390/math10203886
González-Zapata AM, Tlelo-Cuautle E, Ovilla-Martinez B, Cruz-Vega I, De la Fraga LG. Optimizing Echo State Networks for Enhancing Large Prediction Horizons of Chaotic Time Series. Mathematics. 2022; 10(20):3886. https://doi.org/10.3390/math10203886
Chicago/Turabian StyleGonzález-Zapata, Astrid Maritza, Esteban Tlelo-Cuautle, Brisbane Ovilla-Martinez, Israel Cruz-Vega, and Luis Gerardo De la Fraga. 2022. "Optimizing Echo State Networks for Enhancing Large Prediction Horizons of Chaotic Time Series" Mathematics 10, no. 20: 3886. https://doi.org/10.3390/math10203886