1. Introduction
Support vector machines (SVMs) is a widely used approach in classification that combines ideas from linear classification methods, optimization, and reproducing kernel Hilbert spaces ([
1,
2,
3]), and it has proven to be highly competitive in many real-world applications. However, a disadvantage of SVM is that it is difficult to implement when dealing with large-scale training sets because of its computational and modeling complexities. In small datasets, the computation time required for SVMs may not be significant, although the computational complexity of SVMs is almost cubic. Therefore, in large datasets, the training time increases excessively. Hence, in this scenario, it is necessary to use new algorithms to face this challenge.
The formulation of SVMs is generally stated as a quadratic programming problem (QP) that finds the optimal separating hyperplane of the data. Because this problem involves an unknown function that maps the data to a higher dimensional space, it is usual to solve its dual setting. The associated dual setting has a number of variables equal to the number of training data, and the training kernel matrix grows quadratically with the size of the dataset (being highly dependent on this), which causes SVM training on large datasets to be a slow process. From the computational point of view, treating the convex quadratic problem given by its dual representation can be time and cost-intensive when the dataset is large. Thus, given a significant number of observations, solving the dual problem is expensive, both in memory or computational capacity and training time. Often, the calculation cannot be performed in a reasonable time. The training may be delayed even if the problem matrices can be stored in memory. Standard solvers of the quadratic programming problem SVM can have, in the worst case, a high training time complexity and memory complexity , where n is the number of observations in the training set.
An approach to address this problem is through data selection methods for SVM. These are intended to reduce the size of the datasets by eliminating the points that do not contribute to determining the optimal separation hyperplane, for which it is known that it depends strongly on the observations on the boundary. In particular, subsampling techniques reduce the size of the training sets by selecting support vector (SV) candidates (i.e., trying to select those instances with a high probability of being considered as SVs). These methodologies have shown promising results in recent studies.
The aim of this work stands in the context of subsampling methods for SVM. We have two goals. On the one hand, we want to develop theoretical results that aid in understanding the performance of these techniques. On the other hand, we want to propose a subsampling methodology for SVM that competes favorably with other state-of-the-art methods for SVM and classification. We end this section by detailing our contribution and outlining the remainder of the paper.
1.1. Our Contribution
One of the contributions of the present work is to present theoretical results that help understand why subsampling methodologies can produce acceptable classification errors when training SVMs.
Another contribution of the present work is to propose a new subsampling algorithm by improving the results of Camelo et al. (2015) [
4], at least in a significant number of cases, by enriching the subsample with more candidates to support vectors using bagging and importance sampling. This is achieved by looking simultaneously at different samples and searching for neighbors according to the candidates’ intensity.
By testing on benchmark examples and comparing with state-of-the-art methodologies (such as the ones proposed in [
4], LibSVM [
5], SVM
[
6], and decision trees [
7]), we show that our proposed method achieves a fast solution to the training SVM problem without a significant loss in the performance accuracy. It is important to highlight that one goal of this paper is to compare algorithms using the same working framework in order to conclude about efficiency and effectiveness. This is to say, we do not focus on improving or analyzing the quality of the solution by proving different kernels or performing other changes. Rather than that, we make our comparisons meaningful by using the same environment settings. Further research will consider the improvement of the proposed methodology when applied to different real-life class of problems.
In summary, the main novelty of this article lies in:
A theoretical discussion of results on subsampling methods for SVMs.
Guarantee the existence, with high probability and given certain conditions, of a feasible solution to the SVM problem through a subsampling scheme, which is close enough to the solution with the full training sample.
The development of a new subsampling learning method to improve time efficiency and performance of SVM training.
A comparison with other state-of-the-art methods and methods closer to our approach, based on appropriate statistical learning metrics.
1.2. Outline of the Paper
The rest of this paper is organized as follows.
Section 2 introduces the SVM theory and related work.
Section 3 contains the proof of the theoretical results for the subsampling methods.
Section 4 introduces an importance sampling and bagging subsampling method to extend the nearest-neighbors ideas presented in [
4]. In
Section 5, we report and discuss the results of applying the proposed methodology on benchmark examples and we compare with other methodologies.
2. Background and Related Work
In the context of pattern recognition, classification problems focus on learning the relationship between a set of feature variables and a target “class variable” of interest. Using a set of training data points with known associated class labels, a classifier is fitted to be used on unlabeled test instances. In particular, in the setting of supervised learning, examples are given that comprise pairs, , , where is the dimensional feature or covariate vector and is the corresponding class that belongs to some finite set . Frequently, as in the present work, is assumed to comprise only two classes, which are labeled 1 and .
The diversity of problems that can be addressed using classification algorithms is significant, as these algorithms cover several application domains ([
8] or [
9]). In recent years, different non-linear procedures have been considered for classification problems. These outperform their classical linear counterparts in many important contexts. The main non-linear methods include classification and regression trees (CART) along with its general version, random forests, neural networks, nearest-neighbor classifiers, probabilistic methods and support vector machines (SVMs) ([
9,
10,
11,
12]).
The success of SVM with respect to classification errors in various contexts can be partially explained by its flexibility. The method uses a kernel function as the inner product of new feature variables that originate from a transformation of the original covariates. Another reason for its success is the effort invested in developing efficient solution methods, some of which we discuss below. A broad review of this theory can be found in [
13,
14].
With the notation given above for the training data, the
soft margin classifier SVM problem is stated as follows:
where
is the transformation of the feature vector into a higher-dimensional space induced by a kernel function,
C is a positive constant that expresses the cost of losing the separation margin or misclassification, and
are the slack variables. The
version of the soft margin classifier is obtained by replacing the objective function by
in (
1). The dual problem corresponding to (
1) can be written as
where
is the kernel function associated with the transformation
, that is,
. In the dual problem for the soft margin
problem, the last restriction in (
2),
, does not appear. This fact simplifies the theoretical analysis presented below in the
case. The classifier corresponding to the solution
(
) of (
2) is
with
coming from the corresponding solution of (
1). Thus, given a new observation
x, its corresponding class will be
.
The estimated prediction error for a given dataset is the incorrectly predicted percentage of points from a test set. Observe that the values of exceeding zero are the only ones that matter for the classifier. The corresponding feature vectors are the so-called support vectors. The low-cost techniques of finding or approximating these vectors are key issues addressed in the present article.
Because in (
1), the transformation
is unknown, a conventional approach to find the support vectors is to solve the quadratic programming problem given by (
2). However, note that the number of variables in this problem equals the number
n of training data. Therefore, if the number of observations is large, solving (
2) is expensive both in memory and computing capacity. In fact, standard solvers of this SVM quadratic programming problem can have a high training time complexity of order
.
According to the literature (see [
15,
16] for a broad review), three approaches exist for tackling the task of training SVM with large datasets:
- i.
Decomposition techniques, where sub-problems are raised iteratively to find the solution of the desired problem.
- ii.
Preselection of candidates for support vectors, where from this first approximation, a data reduction is considered to train the SVM algorithm.
- iii.
Sampling procedures, methodologies that reduce the size of the problem using some subsampling selection criteria.
A significant part of the SVM literature is devoted to finding efficient ways to solve problem (
2) by decomposition. Some of the ideas entail solving appropriate sub-problems [
17]. This method relates to the chunking methodology, as explained in [
18], and to the SVM
algorithm of [
6]. The Sequential Minimal Optimization (SMO) is a reasonably successful proposal that considers smaller sub-problems [
19]. In a different direction, [
20] considered the application of Successive Overrelaxation (SOR), which is a method developed initially to solve symmetrical linear complementarity and quadratic programs in solving the SVM problem. The chunking techniques, introduced in [
18], have been considered in different contexts and appear in many real-world problems, such as cancer diagnosis, credit card fraud detection, and terrorist detection. Regarding binary classification, [
21] proposed a cost-sensitive hinge loss support vector machine (CSHL-SVM). This method applies to the the on-line scenario when the data appear as sequential chunks.
All the above approaches seek to solve problem (
2) by efficiently solving sub-problems but considering the whole dataset. To efficiently preselect the support vectors of the training sample, [
22] applied the
k-means clustering algorithm to the training set and evaluated the resulting clusters for homogeneity. Abe [
23] proposed computing a Mahalanobis distance classifier first and using those data points misclassified by this preliminary procedure in the reduced training set. In [
24], the idea of identifying probable support vectors is developed around neighbor properties.
Another strategy to reduce the training set size is the Reduced Support Vector Machines (RSVM) method by [
25], where they select a subset by random selection to represent the original training set. The random sampling algorithm (RSA) by [
26] is a more elaborate technique that assigns a probability to each instance to be chosen.
Recall that data selection methods for SVM intend to decrease the dataset size by removing the instances that do not contribute to the definition of the optimal separating hyperplane (surface). The approach of Cervantes et al. [
27] can be seen as a mixture between data selection and sampling because their proposed method reduces the training set size based on a decision tree and uses a subsample. A similar approach was found in [
28] that entails approximating the decision boundary of SVMs using a decision tree to speed up SVM but in its testing phase.
In a different fashion, but also using subsampling ideas, Camelo et al. [
4] presented a subsampling and nearest-neighbors method in which the support vector set of the solution to the SVM problem for a small subsample is iteratively enriched with nearest neighbors to build a relevant training set significantly smaller than the original training dataset. Therefore, the training time is reduced in comparison to the time needed for solving the problem using the whole dataset but without degrading too much the accuracy obtained with the complete dataset.
Recently, hybrid systems were developed, such as the PNN-SVM combination, which improve in classification accuracy compared to single-stage models. Their implementation proved beneficial when predicting the biocompatibility properties of the material for titanium implant fabrication [
29]. An update of this approach is given by applying the Probabilistic Neural Network (PNN) to the current input to obtain the probability vector of its membership in each of the defined classes of the classification task and introduce the second-degree Ito decomposition on the extended vector in modeling the relationships between the input attributes; then, it is possible to finally perform the classification using a pre-trained SVM with the linear kernel [
30].
Related to our proposal, the method introduced in [
31] corresponds to a core set construction algorithm for accelerating SVM training based on efficient importance sampling. We could also describe it as a hybrid in the sense that it proposes an approach based on the linkage of
k-means clustering together with the solution to the SVM problem. Thus, an efficient reference set structure method is proposed to generate compact representations of large datasets to speed up SVM training.
Other SVM variants speed up the SVM training time at the cost of losing accuracy. Recall that the basis of decomposition methods lies in the fact that the training time can be reduced if only the active constraints of the QP problem are taken into account. This idea is used in SMO and according to Cervantes et al. [
15], one of the best solvers based on SMO is LibSVM [
5], which, unlike other implementations, has a sophisticated working set selection procedure. In the comparative study [
32], it was observed that in small and medium datasets, no solver significantly outperforms LibSVM. Furthermore, it is argued that a combination of LibSVM and subsampling suffices to achieve a good accuracy. For this reason, combined with subsampling it is the routine we selected here.
Finally, we should mention that in [
33], a small subsampling strategy is introduced to improve the accuracy and computational efficiency in support vector regression (SVR). Theoretically, they show that formal statistical inference procedures suggest employing a subset of small subsamples to speed up the computational speed of SVR. First, their resulting estimator is an incomplete
U statistic, and they obtained asymptotically normal results. Second, a subset of subsamples is used, and a distributed set can be easily determined to reduce the computational complexity of SVR.
The subsampling SVMs approaches give an approximate SVM solution formed by some random selection using different criteria. In the present work, besides proposing an alternative subsampling method and in contrast to other previous articles, we develop theoretical results that add understanding of why subsample methodologies can produce good classification errors. Our findings prove that the solution to the soft margin SVM problem is stable under subsampling. In particular, our main theorem states that under some conditions, there exists, with high probability, a feasible solution to the dual SVM problem for the randomly chosen training subsample, with the corresponding classifier as close as desired (in terms of classification error) to the classifier obtained from training with the complete dataset. The conditions for this theorem’s conclusion become much more restrictive in large dimensions, reflecting the well-known curse of dimensionality phenomenon.
3. Theoretical Results
Using the notation established in
Section 2 for the solution of the soft margin
SVM problem, here we consider an independent and identically distributed (i.i.d.) sample of pairs
for
, where
follows a probability distribution
on
,
takes values 1 and
and, given
, the distribution of
is given by
for a measurable function
on the support of
. We assume that
admits a density
f with respect to the Lebesgue measure,
, which is bounded away from zero and infinity on its compact support,
. In addition, we assume that
(at least in the vicinity of support vectors) is bounded away from 0 and 1.
A random subsample,
, of size
for some
is taken, with
denoting the ceiling function. Based on this subsample, the SVM problem is solved, and our purpose is to quantify the similarity of the solution obtained with
to the one given by (
3), in which the whole dataset is employed. In what follows, the expression with high probability means that the probability of the event considered goes to 1, as
.
Let be the set of support vectors for the SVM solution computed with the complete sample of size n and let q be the number of support vectors (i.e., , where # denotes the cardinal of a set). The first thing to verify is that with high probability, the subsample will contain points close enough, at a distance less than of each point in the distinguished set , for any such that is of order .
In addition to the assumptions on the sample distribution stated above, we will assume the following shape conditions on
called weak grid compatibility, which is a relaxed version of a condition considered in [
34], in the context of the theory of clustering algorithms.
Definition 1. Let be the support of the density function f generating the data. We say that f and satisfy the weak grid compatibility condition if there exists a positive number γ such that for all small enough , can be covered, possibly after translation and rotation, by a regular array , of cubes of side l, such thatwhere λ denotes the Lebesgue measure in and a regular array of cubes of side l in means that the vertices of the cubes form a regular grid in , such that the length between the contiguous vertices is constant and equal to l. In this definition, it is assumed that includes only the cubes needed to cover ; that is, if , then . According to [34], d-dimensional balls and ellipsoids in as well as regular polyhedra satisfy this condition. As a condition on the kernel employed in the SVM procedure, we assume that K is Lipschitz continuous, with Lipschitz constant L.
Finally, we make assumptions on the solution of the soft margin problem (
1) on the whole dataset. Thus, we assume the following asymptotic continuity condition on the uncertainty of the classification function for the solution of the SVM problem on the complete dataset: Let
and
be the solution coefficients appearing in (
3). We assume that
where the expression a.s. refers to “almost surely” regarding the product space of infinite samples. Condition (
4) is bounding the level of uncertainty that the solution to the SVM problem admits. Points
for which
holds are points near the boundary of indecision of the SVM solution. The question is whether, as
becomes smaller, this region of
-uncertainty has a probability that goes to zero. The simulations shown in
Appendix B suggest that condition (
4) holds comfortably in real examples.
The final assumptions are technical and more restrictive on the number of support vectors that the solution associated with the complete dataset might have. We suppose that the cardinality
q of the set
of support vectors is
, namely, for each
,
The power
in this bound makes the condition more restrictive in large dimensions, reflecting the curse of dimensionality that frequently appears in pattern recognition literature. In fact, numerical simulations (not included) suggest that (
5) does not hold for the real examples considered in our performance evaluation below. Our theoretical results provide evidence that for problems with a number of support vectors slowly growing to infinity, the solutions on subsamples can achieve performance very close to that achieved for the complete dataset solution. A consequence of assumption (
5) is that the number of support vectors that the solution for the soft margin
problem can have in a small cube is bounded. Assume that when the sample size is
n,
is covered (by weak grid compatibility) with a regular array
such that each cube
has sides of length
for some positive constant
. We assume that there exists a constant
such that
where, again,
is the set of support vectors for the solution of the SVM problem. Although neither of the two last conditions implies the other, (
5) is, by far, more restrictive than (
6) on the total number of support vectors that the problem might admit, as the second condition does not reflect the curse of dimensionality because the bound that it implies on the total number of support vectors is
, which is a bound that does not change with dimension.
As a first result, we prove that for a subsample of size , with high probability, there exist observations with labels of both classes in the subsample, which is close to the support vectors of the complete sample solution. As the support vectors delimit the surface that separates the two classes, it is natural to expect that in a neighborhood of each support vector, points from both classes are to be found, even in a subsample.
Proposition 1. Under the setting described above, there exists a , which is of the order such that for each there are with and with such that, with high probability, The assumptions in Proposition 1 may seem too restrictive, asking that both f and be bounded away from extreme values on the whole domain . Those requirements could be weakened by requiring those conditions to hold only in regions of where support vectors might appear. Then, the argument in the proof would not consider all cubes in but only the collection , that is, those cubes in the grid that contain support vectors.
The following theorem is stated by considering the soft margin SVM problem.
Theorem 1. Fix . Let and be the multipliers appearing in (3) for the solution of the SVM problem associated with the complete training data set. Then, there exists a constant such that the following hold: - (i)
If we replace and by and in (3), with high probability, the new set of coefficients continues to be feasible for problem (2) and the two corresponding classifiers (with the original coefficients and the coefficients divided by M) coincide; that is, they produce always the same classification on new data points. - (ii)
For the soft margin problem on the subsample , there exist multipliers , feasible for the problem (2) on , such that, with high probability, where are the data points in .
- (iii)
Let class be the classifier defined by (3) and obtained from the solution of the soft margin SVM problem for the complete sample and class be the classifier defined by Then, with high probability,
This theorem relates the solution of our algorithm to the complete solution, standardizing the coefficients to satisfy the feasibility condition. In other words, the result says that, with high probability, there exists, in the feasible set of the dual problem for the subsample, a candidate solution whose classification function is as close as desired to the classification function of the solution for the problem with the complete original sample. This does not imply that the new feasible solution will be chosen by the SVM algorithm (as the objective function of the SVM is not classification error), but the feasibility of this solution can help in understanding why subsampling methods can produce very competitive results in terms of classification error in many cases.
Then, the proximity of the decision functions associated with the full sample solution and the solution based on our proposal can be established. Thus, for a set of candidate support vectors from a subsample, the decision functions are sufficiently close. Finally, in addition to ensuring the proximity of the decision functions, it is necessary that both give the same classification. For this, the third statement of the theorem is established, and the result is demonstrated with the hypothesis of
-uncertainty (
4).
In our examples, the cause of poor performance in some kernels can be attributed to the fact that these examples belong to a high dimension, and its error rate is very low. Note that the power
in our bound given in expression (
5) makes the condition more restrictive in large dimensions, reflecting the curse of dimensionality that frequently appears in pattern recognition problems.
4. Bagging and Importance Sampling Algorithm for Support Vectors
As another objective of the present work, we propose a new subsampling algorithm by working with the results of [
4] and using bagging and importance sampling. The novel reasoning is to enrich the subsample with more candidates to support vectors by looking simultaneously at different samples and searching for neighbors according to the candidates’ intensity. The numerical results will show that in relevant examples, this procedure solves problem (
2) in a fraction of the time needed for obtaining the complete dataset solution without significantly deteriorating the classification accuracy.
4.1. Description of the Algorithm
The previous method presented in [
4], based on subsamples and nearest neighbors, can be summarized as follows:
Procedure CGLQ (Camelo, Gonzalez-Lima, Quiroz)
- (i)
Select a random subsample comprising a small fraction of the set of examples.
- (ii)
Solve the SVM problem in that subsample (i.e., identify the support vectors for the subsample). Denote this initial set of support vectors as . Evaluate the classifier’s error on a test sample set.
- (iii)
The set is enriched with the k-nearest neighbors (of each element of ) in the complete sample. is also enriched by adding a new small random subsample of the complete sample. With this new subsample, we return to step (ii). The iteration stops when there is no significant improvement in the classification error.
As reported in [
4], on markedly diverse benchmark examples, this procedure achieves a classification error comparable to that corresponding to solving the SVM problem on the (original) complete training sample with significantly reduced computation time. One interesting feature of the method proposed in [
4] is that the methodology is not restricted to a particular way of solving the SVM problem on the training data.
Based on the original idea, one could consider the following modifications:
- 1.
The initial subsample in step (i) of procedure CGLQ can be substituted with some small subsamples, solving the SVM problem on each one. In this manner, we would have a richer supply of candidates to approximate support vectors. The idea of applying a statistical learning procedure to bootstrap samples taken from the original training sample and then combining the output of those different fitted predictors is called bagging ([
7,
35]).
- 2.
The process of enriching by nearest neighbors can be improved if a certain “intensity of support vectors by region” can be estimated at each point of interest, and a sampling procedure is used that considers this intensity to sample more heavily in regions where more support vectors should be expected. In Monte Carlo simulation, this is called importance sampling [
36].
It turns out that the goal of estimating a local intensity of support vectors can be achieved using bagging. Our proposal in this direction will be to sample and add (to the original set of support vectors) more sample points in those regions where more support vectors are expected. These ideas are embodied in the following procedure. We slightly part from the usual bootstrap practice by making our initial small subsamples disjoint (we are not sampling with replacement as in the original definition of bootstrap). This produces a larger initial set of near support vectors. As in the introduction, the training sample size is
n and is formed by pairs
of feature vectors and class variables, with
. In the following procedure, the letter
L is used with a meaning different from that given in
Section 2.
Procedure of local sampling SVM
- (i)
For a positive integer L and , from the original sample, , select L disjoint subsamples , , each of size , such that , where denotes the floor function. We denote as the set of observations of all the subsamples (i.e., ). represents a fraction of the entire training sample.
- (ii)
On each subsample , solve the SVM problem, finding the set of support vectors associated with that subsample. Let denotes the union of these initial support vector sets, that is, , and let be the size (cardinality) of .
- (iii)
Let . For each , identify its kth-nearest neighbor in . Denote this kth-nearest neighbor by and denote by the distance between and : , where stands for the Euclidean distance. Let denotes the median of the radii .
- (iv)
For a parameter
, let
. Define
Sample a fraction of the points of in the ball with center and radius r. Write for this random sample.
- (v)
Solve the SVM problem for the new sample
Three observations are necessary regarding the procedure just described:
- 1.
To explain the way the importance sample is approximately implemented in our procedure, let us recall the idea of density estimation by “Parzen windows” (see [
12] for details, including a proof of consistency). Given an i.i.d. sample,
in
, obtained from a probability distribution that admits a density
, for an arbitrary
(which could be one of the sample points), if
denotes the Euclidean distance from
x to its
k-th nearest neighbor in the sample, then the density
is consistently estimated by a constant times the reciprocal of the volume of the
k-th nearest neighbor ball. This means that
is proportional to
. In our case, we use the distance
between each
and its
k-th nearest neighbor in
to obtain an estimate of the “support vector density” near
. Then, we set a fixed radius
r and sample in a ball of radius
r around
with an intensity proportional to
. Precise importance sampling would require sampling with an intensity proportional to
, but preliminary experiments revealed that this “exact” importance sampling would be too extreme in the sense of producing heavy sampling in some regions and almost no sampling in others. For this reason, our sampling is proportional to
. Choosing a neighborhood of size proportional to
follows a common practice in the pattern recognition literature. This choice allows for the consistent estimation of local properties, while larger choices of
k could lead to inconsistent results (see the discussion in [
37]).
- 2.
An important difference with the approach proposed in [
4] is that the enrichment of the set
occurs inside the
k-th nearest neighbor balls, whereas in the present method, we use a common fixed radius and change the sampling intensity at each
.
- 3.
The parameter in the procedure just described provides flexibility, allowing the user to vary the radius (and volume) of the balls in which the sampling is performed.
Next, we study the behavior of the local sampling procedure applied to some real-life problems.
4.2. Data Sets
This section presents a performance evaluation of the methodology proposed on benchmark datasets. For the experiments described in this section, we have used the statistical software
R and the
e1071 package (for more details, visit
https://cran.r-project.org/web/packages/e1071/ accessed on 01 May 2022. Procedures are run on a computer with Motherboard EVGA Classified SR-2 with two microprocessors @ 2.67 GHz and RAM of 48 GB 1333 MHz).
For our experiments, we consider the following three kernels for SVMs:
Linear: .
Polynomial with degree p, : )=, .
Radial basis: , .
Table 1 displays the description of the datasets tested. These examples cover different ranges with respect to the sample size and data dimension.
First, we consider a simulation scheme over the domain
introduced in [
38], where it is possible to construct level curves of conditional probability for the class
given the covariates
x in the following way:
Here, is the distance from x to the point (25, 25) in the plane.
The left panel in
Figure 1 shows the behavior of these probabilities using more intense color in regions where the probability is higher. In our case, we simulate
n = 100,000 i.i.d. observations with
x uniformly distributed on
, and the class labels are randomly chosen according to
. Dividing into two sets with 80,000 and 20,000 points for training and the test set, respectively, we fit the SVM classifier using the kernels mentioned above.
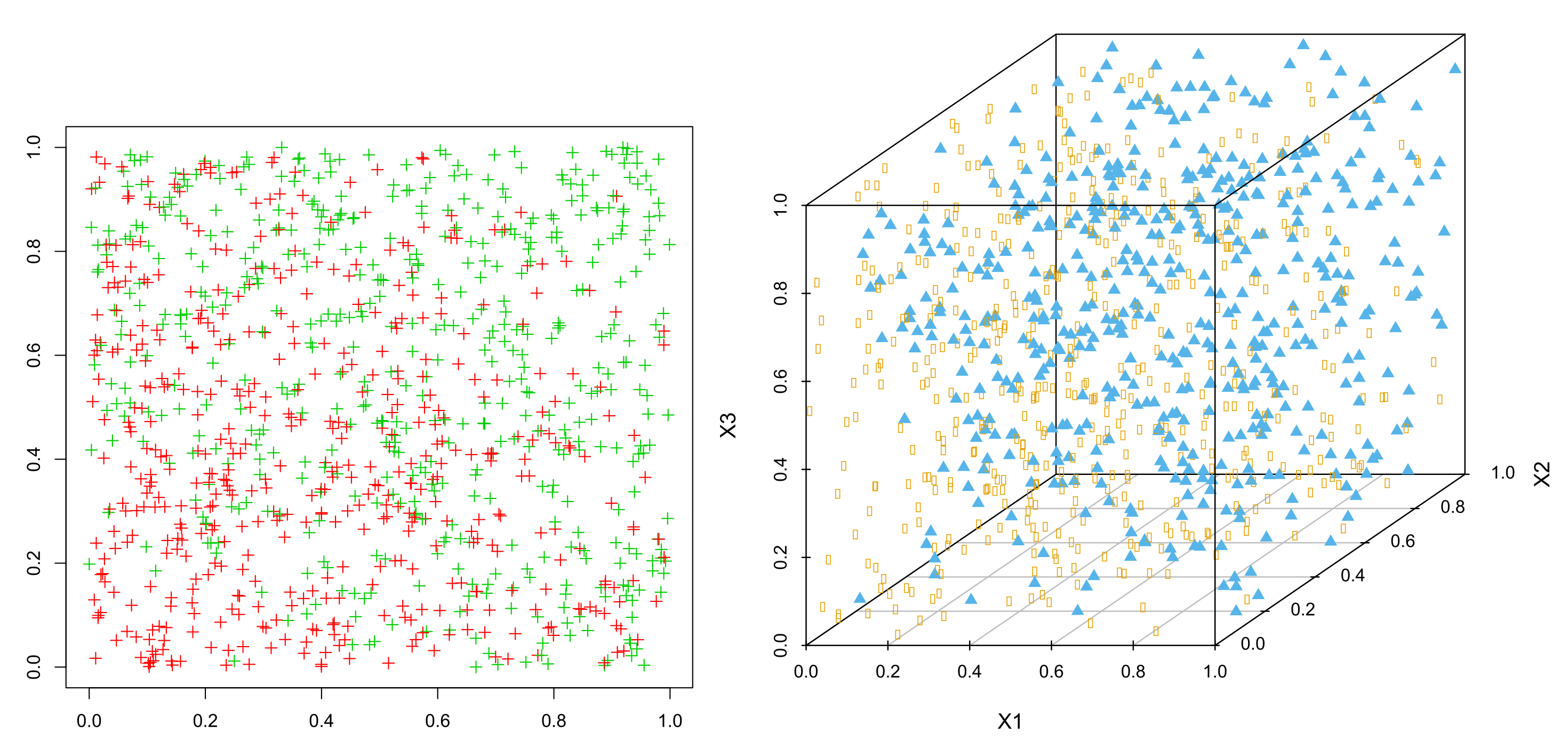
The second dataset corresponds to a simulation scheme for the problem of classifying two classes in a
d-dimensional unit cube; the conditional probability of class
given the
d-dimensional vector
x is
In
Figure 2, the graphical representations in dimension 2 and dimension 3 are shown, labeling the classes with different colors.
For different dimension values d, we simulate 300,000 observations, using 240,000 observations as the training sample and 60,000 observations for testing. To determine parameter values, a cross-validation scheme is considered with an independent sample equal to 1% of the total, i.e., with 3000 observations. For this example, we only present the results for the case .
4.3. Parameter Choices
For each problem and kernel, the choice of parameters is made before the local sampling SVM procedure, as described in the previous section, and it is run on the validation set (exclusive for this task) composed of 1% or 5% of the training data (5% in the smallest datasets) based on the results obtained on a small subsample of the training set. This subsample and the rest of the training set are disjointed from the test set. The parameters to be tuned in advance are the kernel parameters and the cost parameter C for the optimization problem as well as the parameter of our algorithm. The kernel parameters and C are chosen via 10-fold cross-validation of the optimization procedure on the small subsample. Once they are chosen, is selected by dividing the subsample into sets of 80% and 20%, using the larger of these sets to train our procedure for different values of , starting from and incrementing it by 0.1 whenever a significant reduction of the classification error on the 20% part of the subsample is achieved.
With the parameters chosen, the SVM classifier was fitted on the full training sample using the libsvm solver: the number and class identity of support vectors were obtained, and the execution time for the full problem and the test error were obtained for the test set. In the summary tables, each kernel is indicated in the first column. In the second and third columns, we show the optimal parameters C and obtained via cross-validation for each kernel function, the latter separated by row. The fourth column will show the number of support vectors for each kernel, followed by quantities in parentheses, which represent the division of support vectors by class. The accuracy rates obtained in the test set are presented in the fifth column. Finally, in the sixth column, the execution times are presented in seconds.
The local sampling approach was executed for the previously chosen value of
. As part of our analysis, we present the average results for 10 runs of the SVM solution considering our algorithm with the (fixed) optimal parameters
C,
, and
obtained in the preliminary evaluation. We also report the initial amount of support vectors in step (ii) of the procedure, the number of support vectors at the end of the procedure, the number of these vectors that are SVs for the problem solved on the full training data set, the accuracy rate on the test data, and the execution times. In addition, we compare the results obtained using our proposed method and the procedure introduced in [
4].
6. Conclusions
In the present work, theoretical results were presented that help understand the performance of subsampling methods in determining an approximate solution for the SVM problem for big data classification. We proved that under some conditions, there exists, with high probability, a feasible solution of the dual SVM problem for a randomly chosen training subsample, with the corresponding classifier as close as desired (in terms of classification error) to the classifier obtained from training with the complete dataset.
In addition, we introduced a local sampling methodology for SVM classification; this methodology is local because it uses information close to the observations of interest (support vectors). The bagging and local subsampling SVM methodology presented herein attains, in many problems, classification accuracy comparable to that corresponding to the solution of the problem on the full training sample, using a fraction of the training dataset and a smaller number of support vectors, thus producing significant savings on computational time.
Among the aspects to remark on, we highlight the analysis of the measure as a general way of quantifying the training performance of support vector machine algorithms. It defines a tradeoff between accuracy and the number of support vectors used to achieve a given performance. Notice that in our context, it makes sense since we are searching for an optimal subsampling by trying to find the most support vectors. However, with a small proportion of the original support vectors () or observations close to these, it is possible to find a solution close enough to the SVM performance with the full dataset. In the practical implementation, we have that our is the best for almost all datasets: 2D-Circle (0.58), 20D-Cube (0.2318), IJCNN1 (0.9882), W7A (0.9959) and WEBSPAM (0.9919).
In general, the proposed method compares favorably to the subsampling and nearest neighbors enriching methodology proposed in [
4]. The advantages of the proposed methodology depend, to some extend, on the complexity of the problem and the kernel used in the algorithm; however, they are more noticeable when the dimension of the dataset is not very large. In the final comparison, the execution times are lower with respect to the total training time for routines such as LibSVM, where in our case, the highest percentage of time used of the total
libsvm was 10.9% for the 2D-Circle set, whereas the rest are significantly lower, and the lowest was 0.48% in CODRNA. Here, we note that the best competitor in execution times is the algorithm of Cervantes et al. [
27].
As limitations, we may mention the following: some experimental results have lower accuracy compared to other methodologies. This is due to the randomness of the subsampling method, although in most cases, the differences in performance are not significant. In those problems with higher dimensions, a so-called curse of dimensionality effect appears, deteriorating the accuracy. As the dimension increases, the effectiveness of the subsampling decreases, as shown in Equation (
5).
At last, although there is flexibility in the choice of the beta parameter defining the subsampling rate, for some problems, it was not possible to find the best choice. Even extending the execution time, the algorithm did not gain in accuracy. Further research will consider this issue.
Finally, future work should address the following issues:
Determine a theoretical result for quantifying the subsampling rate in terms of efficiency measures and the closeness to the final classification accuracy as well as the number of observations expected to be SV in an optimal search.
An open issue is to explore the general key aspects of subsampling approaches and their potential contribution to training SVM methods involving hybrid-type algorithms.
Consider unbalanced classification problems and their effect on local subsampling. Devote further effort to areas where we can locate observations from both classes. Otherwise, SVM will not be informative.
Extend the discussion to multi-class problems and determine how subsampling schemes can work in such cases.




{kind=link}
{kind=link}

