1. Introduction
Lately, numerous statistical models have been presented by many researchers. The need to formulate new models arises due to empirical studies, theoretical situations, or both. Considerable applications in disciplines including reliability and clinical investigations, among others, have demonstrated in recent years that datasets that can be modelled employing traditional distributions are the exception more often than the rule. As a result, significant improvement has been produced in the modification of many traditional distributions and their efficient utilization in different domains. One of the widespread statistical distributions which can be used as an extension of the usual exponential distribution was introduced by Nadarajah and Haghighi [
1] and was recently named the Nadarajah–Haghighi (NH) distribution as an abbreviation of the authors’ names. Suppose that the lifetime
X of a testing unit follows the two-parameter
, where
and
are the shape and scale parameters, respectively. Then, the probability density function (PDF)
, cumulative distribution function (CDF)
, reliability function (RF)
, and hazard rate function (HRF)
for a given mission time
t are respectively provided by
where the exponential distribution is introduced as a special case when
.
Nadarajah and Haghighi [
1] showed that the density of the NH distribution can be decreasing and that unimodal shapes as well as its HRF have an increasing, decreasing, or constant shape similar to gamma, Weibull, and generalized-exponential distributions. Many authors have investigated the estimations problems of the NH distribution. For example, Mohie El-Din et al. [
2] studied constant-stress accelerated life tests of the NH distribution based on progressive censoring. Mohie El-Din et al. [
3] also investigated a progressive-stress accelerated life test using progressive Type-II censoring NH data. Dey et al. [
4] studied the different estimation procedures of the NH distribution. Selim [
5] considered estimation and prediction for the NH distribution using record values. Ashour et al. [
6] considered the NH distribution based on progressively first-failure censored data and studied the estimation problems in this case.
On the other hand, censored data is a familiar topic in reliability and life-testing studies. Time and failure censoring schemes are the most frequently employed censoring schemes in life-testing and reliability investigations. One of the main shortcomings of these schemes is that they do not allow units to be removed from the experiment at any moment other than the end point; for more details, see Balakrishnan and Aggarwala [
7]. To avoid this drawback, the progressive Type-II censoring scheme (PT-II-CS) is suggested. To discuss the mechanism of this scheme, let
n units be placed on an experiment and let
m be the prefixed number of failed units. Suppose that
denotes the time of the
failure. Then,
units are randomly removed from the remaining units at
. Again,
units are randomly removed from the remaining units at
, and so forth. At
, all the remaining
units are withdrawn. For more information about PT-II-CS, see Balakrishnan [
8]. In the context of hybrid censoring, Kundu and Joarder [
9] proposed a progressive Type-I hybrid censoring scheme in which
n units are tested employing a specified progressive censoring plan
and the experiment is terminated at
, where
T is a predetermined time. This scheme has the drawback that the statistical inference method is inefficient due to the small observed sample size.
To solve this problem, Ng et al. [
10] proposed a new scheme to increase the efficiency of statistical inference called the adaptive progressive Type-II hybrid censoring (AP-II-HC) scheme. Let
m be predetermined before starting the experiment and permit the total test time to run over
T with a progressive censoring scheme
which is predetermined but has values that may be adjusted during the experiment. The mechanism of this scheme is similar to that in the case of PT-II-CS, except that the stopping rule is different. Employing the AP-II-HC scheme, if the
failure happens before
T, the experiment stops at
. Otherwise, if
, where
and
represent the
failure time observed before
T, then the researcher does not remove any live units from the experiment by placing
and then
. This process guarantees control of the experiment when the needed number of failures
m is obtained. Let
be an AP-II-HC sample from a continuous population with PDF and CDF. By setting
for the sake of simplicity, the likelihood function of the AP-II-HC data can be expressed as
where
and
is the vector of the unknown parameters.
Different investigations based on AP-II-HC have been performed; readers are directed to the studies of Nassar and Abo-Kasem [
11], Ateya and Mohammed [
12], Mohie El-Din et al. [
13], Liu and Gui [
14], Elshahhat and Nassar [
15], Kohansal and Bakouch [
16], Alotaibi et al. [
17], and the references cited therein.
Despite the flexibility of the NH distribution in modelling different types of data and the importance of the AP-II-HC scheme in reliability analysis and life-testing studies, no study, to the best of our knowledge, has investigated the classical and Bayesian estimation methods of the parameters and reliability characteristics of the NH distribution in the presence of AP-II-HC data. To fill this gap, the essential role of this study is threefold. The first is to study the classical point and interval estimations of the unknown parameters and some reliability characteristics of the NH distribution employing the AP-II-HC samples through the maximum likelihood approach. The second is to investigate the Bayesian estimation via the squared error (SE) and general entropy (GE) loss functions of the same unknown parameters utilizing the Monte Carlo Markov Chain (MCMC) technique. In this regard, the Bayes point and highest posterior density (HPD) credible intervals of the unknown parameters and some reliability characteristics are obtained based on the assumption of independent gamma priors. The third is to compare the efficiency of the different point and interval estimators. To achieve this goal, an extensive simulation study is implemented and two real data sets are examined. Before progressing further, it is of interest to mention that the various inferential procedures discussed in the next sections are developed based on the assumption that the quantity d is greater than or equal to one. In addition, it is assumed that the parameters and a number of of their related parametric functions, such as RF and HRF, are always unknown.
The remainder of the paper is organized as follows. The maximum likelihood inference of the NH distribution using AP-II-HC data is presented in
Section 2. Inference through the Bayesian estimation approach is considered in
Section 3.
Section 4 presents the outcomes of a simulation study. Two example applications are provided in
Section 5, and
Section 6 concludes the paper.
3. Bayes MCMC Paradigm
In this section, the Bayesian estimators and associated HPD credible interval estimators of , , , and are obtained. Due to the complex form of the joint likelihood function, the Bayes estimators are obtained in a complex form; for this reason, we use MCMC approximation techniques.
Under the assumption that the unknown parameters are independent and have gamma distributions, i.e.,
and
, the Bayes MCMC estimates are developed. Hence, the joint prior distribution of
and
is provided by
where the hyper-parameters
are known and non-negative.
Substituting (6) and (12) into the continuous Bayes’ theorem, the joint posterior PDF of
and
can be expressed as
where
K is the normalized constant and is provided by
Now, based on the SE loss, which is the most common symmetric loss function, the Bayes estimator
of any function of the unknown parameters
and
, say,
, is provided by the posterior expectation. The SE loss (say,
) and its Bayes estimator (say,
) are respectively provided by
and
for more details, see Martz and Waller [
18].
On the other hand, one of the useful asymmetric losses is called the GE loss function, and is provided by
It is clear, from (15) that the lowest errors occurs at
and that when setting
, the Bayes estimator via the GE loss function coincides with the Bayes estimator via the SE loss function. When
, a positive error has a more serious effect than a negative error, whereas for
, a negative error has a more serious effect than a positive error. From (15), the Bayes estimator
of
is provided by
For more details, see Dey et al. [
19].
Obviously, due to the nonlinear expression of (13), there is no closed-form solution for the Bayes estimators of , , , or using the SE and GE loss functions. As a result, we propose using the MCMC approach to obtain the Bayes estimates and construct the associated HPD Bayes credible intervals.
To produce samples via the MCMC approach, conditional posterior distributions of the unknown NH parameters
and
must first be obtained:
and
respectively.
It is clear from (16) and (17) that the full conditional distributions of and cannot be reduced to any familiar density. Therefore, generating and straightforwardly from and is unattainable by the standard methods. Therefore, we consider the Metropolis–Hastings (M-H) algorithm with normal proposal distribution to obtain the Bayes point/interval estimates of the unknown parameters and , as well as the reliability characteristics and . We use the following procedure to collect MCMC samples from (16) and (17):
- Step 1.
Set the start values of , say, .
- Step 2.
Set .
- Step 3.
Simulate and from (16) and (17) from and , respectively.
- Step 4.
Calculate = and =.
- Step 5.
Generate and from the uniform distribution.
- Step 6.
If , set ; otherwise, .
- Step 7.
If , set ; otherwise, .
- Step 8.
Replace and in (3) and (4) with their respective and to compute and for .
- Step 9.
Repeat Steps 2–8 times and obtain , , , and for , then discard the first samples as burn-in.
- Step 10.
Compute the Bayes estimates of
,
,
, or
(for brevity, say
) under the SE and GE loss functions, respectively, as follows:
and
- Step 11.
Create the HPD Bayes credible interval of
by sorting its MCMC samples in ascending order as
. Thus, following Chen and Shao [
20], the
HPD Bayes credible interval estimator for
is provided by
where
is chosen such that
where the highest integer less than or equal to
x is symbolized by
.
4. Monte Carlo Simulation
To examine the performance of the acquired (classical/Bayesian) estimators of
,
,
, and
, we conducted a simulation study. The simulation results were obtained with the actual values of
and
selected as 0.5 and 1.5, respectively, and 1000 AP-II-HC samples were drawn from the NH distribution based on various choices of
n,
m,
T, and different progressive censoring schemes. For mission time
, the actual values of the reliability characteristics
and
were 0.930 and 0.699, respectively, and the values of
n,
m, and
T were chosen such that
and 100 for each threshold time
and 1. According to the proposed censoring, taking the failure percentage
and
, the experiment was terminated when the number of failed items reached a particular value of
m. Moreover, in order to evaluate the behavior of removal designs, several designs of the progressive censoring scheme
were operated as follows:
To generate an AP-II-HC sample from the NH distribution for given values of n, m, T, and R, we offer the following steps:
- Step 1:
Applying the simple algorithm of Balakrishnan and Sandhu [
21], simulate an ordinary progressive Type-II censored sample as follows:
- i
Create independent observations of size m as .
- ii
For specific n, m, T, and , put
.
- iii
Let for . Then, is a progressively Type-II censored sample of size m from a distribution .
- iv
Set to be the progressively Type-II censored sample from .
- Step 2:
Determine d, where , and remove the remaining sample .
- Step 3:
From , generate the first order statistics with size as .
To see the consequences of the prior information on the Bayesian estimators, two separate informative sets of the hyperparameters
are used, i.e., Prior-1:
and
and Prior-2:
and
. Clearly, the suggested hyperparameter values are assigned in such a manner that the prior mean becomes the expected value of the model parameter. It is known that when improper gamma information is available, i.e.,
, the posterior PDF is reduced to the likelihood function. In this case, we advise using the frequentist technique rather than the Bayesian approach, as the latter is computationally more costly. Using the M-H algorithm presented in
Section 3, 12,000 MCMC samples are generated and the first 2000 variates are overlooked as burn-in. Thus, after gathering 10,000 MCMC samples, the Bayes estimates of
,
,
, and
using both the SE and GE (for
) loss functions can be computed, along with the associated 95% HPD credible intervals.
Comparison between point estimates of
,
,
or
(say
) is carried out based on their root mean square errors (RMSEs) and mean relative absolute biases (MRABs), respectively, as follows:
and
where
is the calculated estimate of
at the
ith simulated sample using any estimation method,
,
,
, and
. Additionally, the comparison between interval estimates of
is performed using their average confidence lengths (ACLs) and coverage percentages (CPs), respectively, as follows:
and
where
is the indicator function and
and
denote the respective lower and upper bounds of the
asymptotic (or HPD Bayes credible) interval of
. All numerical evaluations were carried out using
4.1.2 software with the ‘maxLik’ and ‘coda’ packages proposed by Henningsen and Toomet [
22] and Plummer et al. [
23], respectively. The simulated (point/interval) outcomes of
,
,
, and
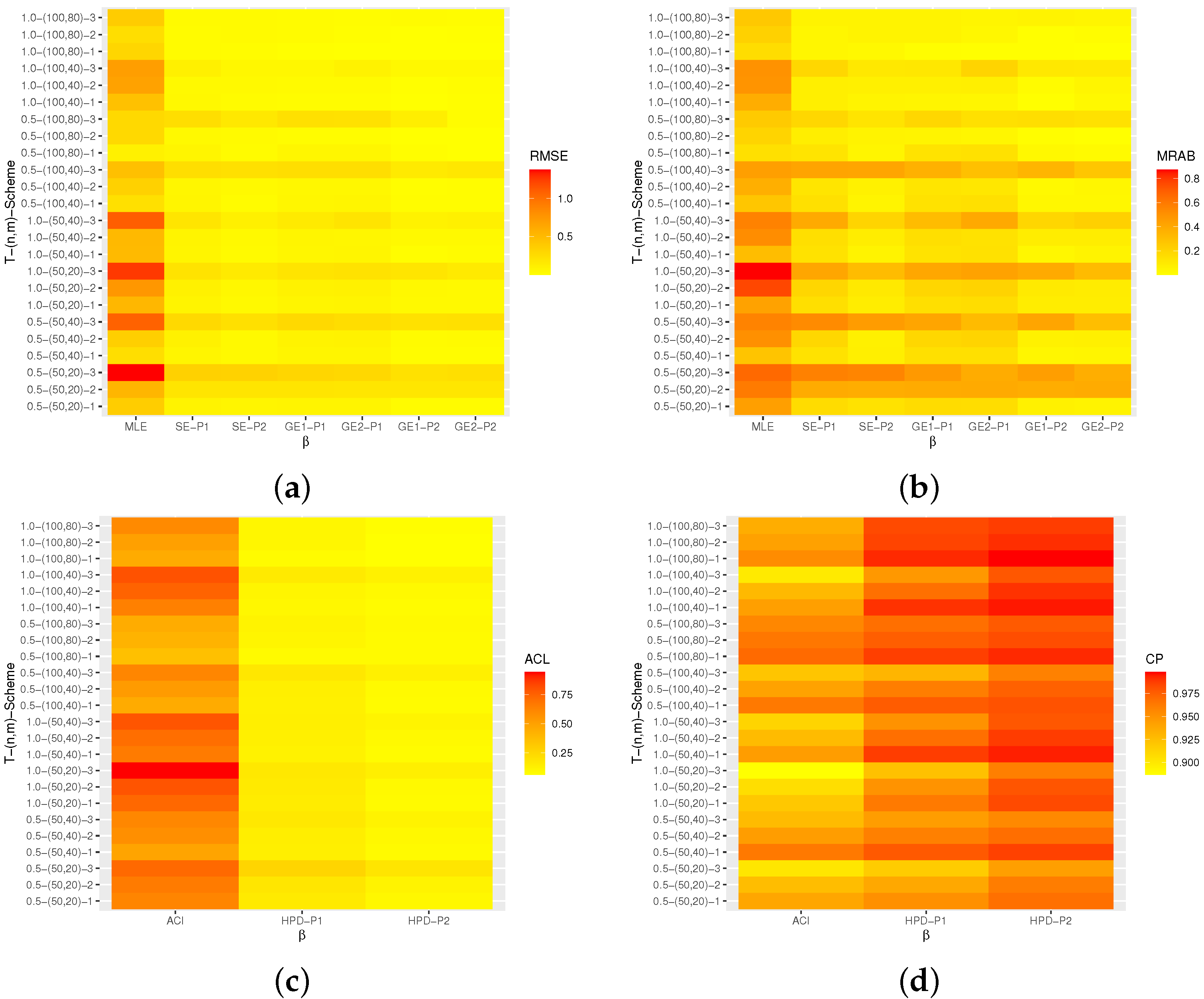
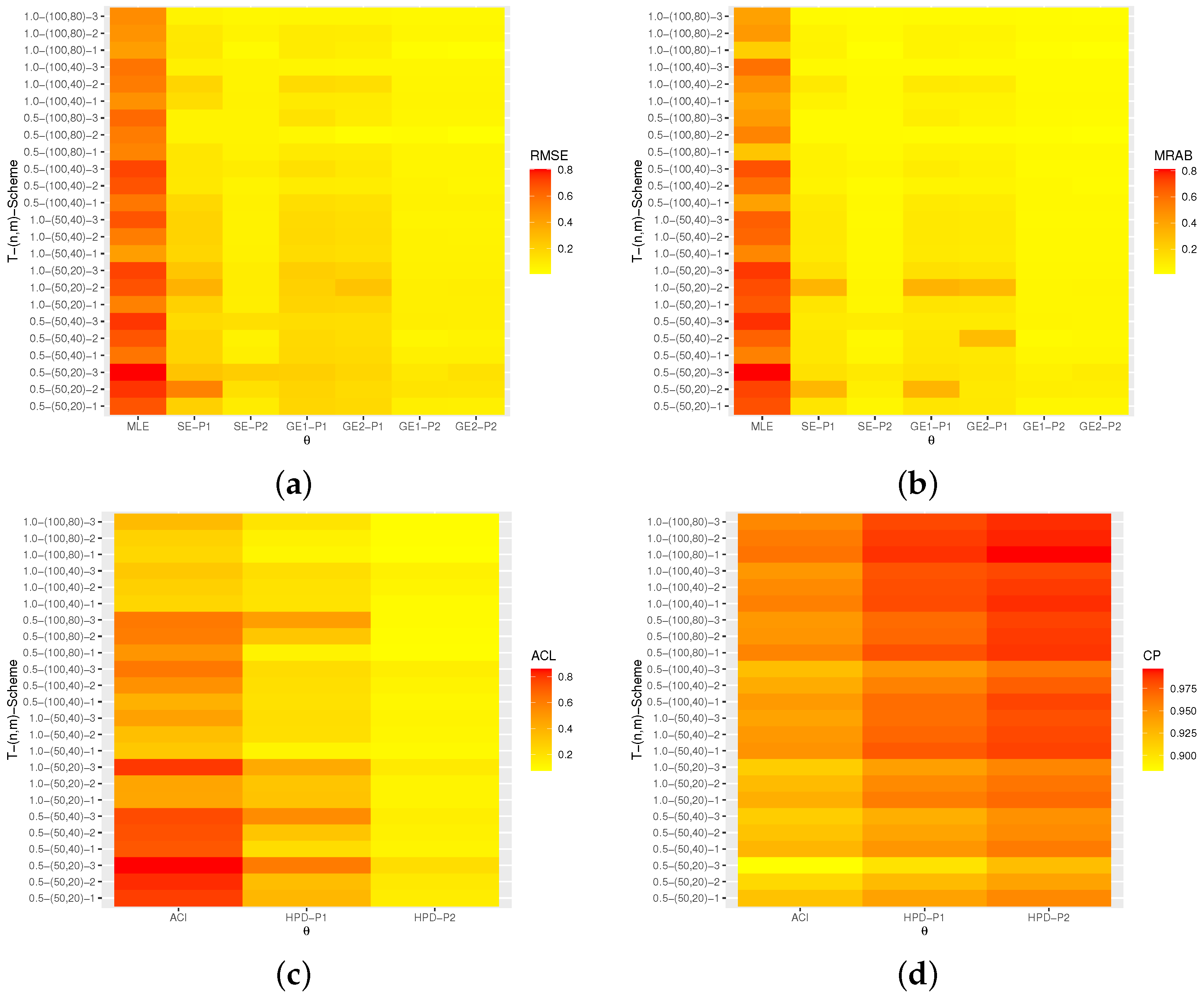
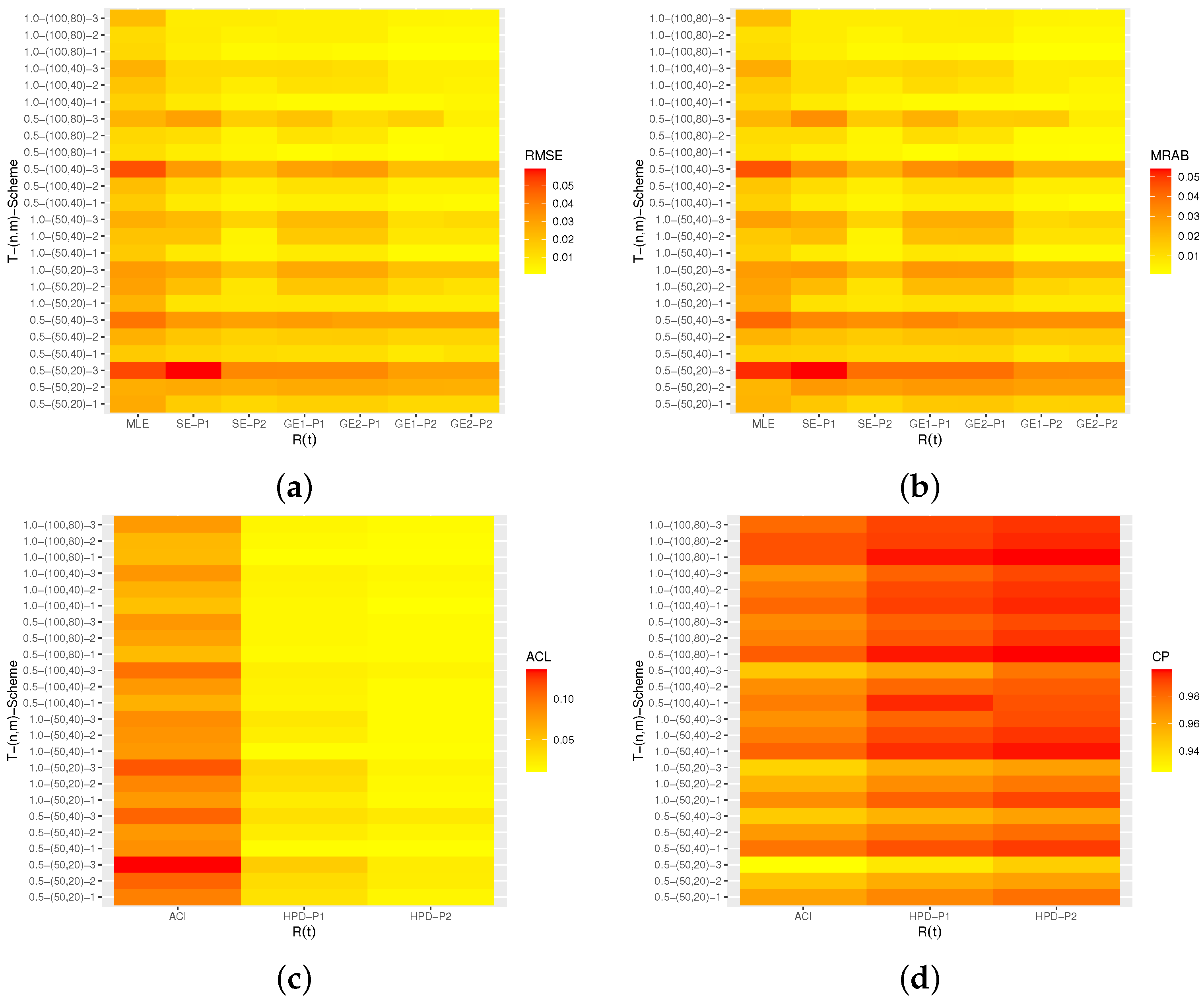
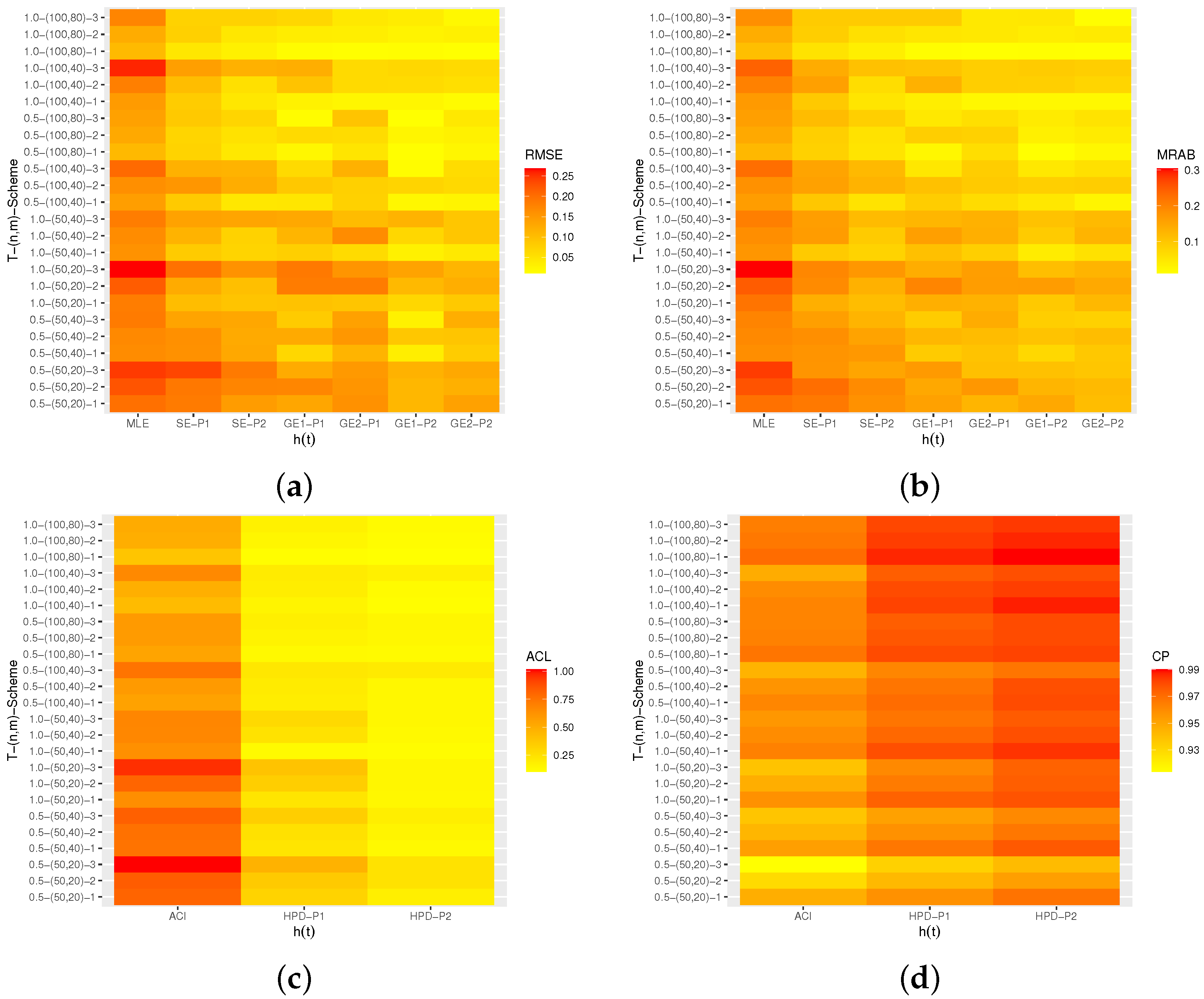
(including RMSEs, MRABs, ACLs, and CPs) are delivered with heatmap plots in
Figure 1,
Figure 2,
Figure 3, and
Figure 4, respectively, while all numerical tables are documented in the
Supplementary Materials. For specification, notes have been reported in heatmaps (for Prior-1 (say, P1) as an example), such as the Bayes estimates based on SE loss (referenced as ‘‘SE-P1’’), the Bayes estimates based on GE loss for
and +2 (mentioned as ‘‘GE1-P1’’ and ‘‘GE2-P1’’, respectively), and the HPD Bayes credible interval estimates (referenced as ‘‘HPD-P1’’). From
Figure 1,
Figure 2,
Figure 3 and
Figure 4, in terms of RMSEs, MRABs, ACLs, and CPs, the following conclusions about the different estimates can be stated.
All estimates perform better with an increase in the total (or effective) sample size. A similar performance pattern is observed when decreases.
The Bayes estimates of all unknown parameters have the lowest overall RMSE, MRAB, and ACL values as well as the highest CPs as compared to the frequentist estimates, as expected. Furthermore, the Bayes estimates relative to GE loss perform better than those based on SE loss.
The Bayes (point/interval) estimates based on Prior-2 perform more satisfactorily than those developed based on Prior-1. This is because Prior-2 has a smaller variance than Prior-1.
As T increases in the point estimation, it can be seen that (i) the RMSEs and MRABs decrease for , , and and (ii) the RMSEs and MRABs increase for in the case of likelihood estimation and decrease in the case of Bayesian estimation.
As T increases in the interval estimation, it can be observed that (i) the ACLs decrease for , , and , whereas the associated CPs increase and (ii) the ACLs increase for when using the ACIs and decrease in the case of HPD Bayes credible intervals.
Comparing Schemes 1–3, it can be noted that the point/interval estimates of , , , and obtained based on Scheme 1 are more efficient than those computed using the other schemes in terms of their RMSE, MRAB, ACL, and CP values.
In summary, the Bayesian approach to estimating the unknown parameters and/or the reliability characteristics of the NH based on AP-II-HC samples is recommended.
6. Concluding Remarks
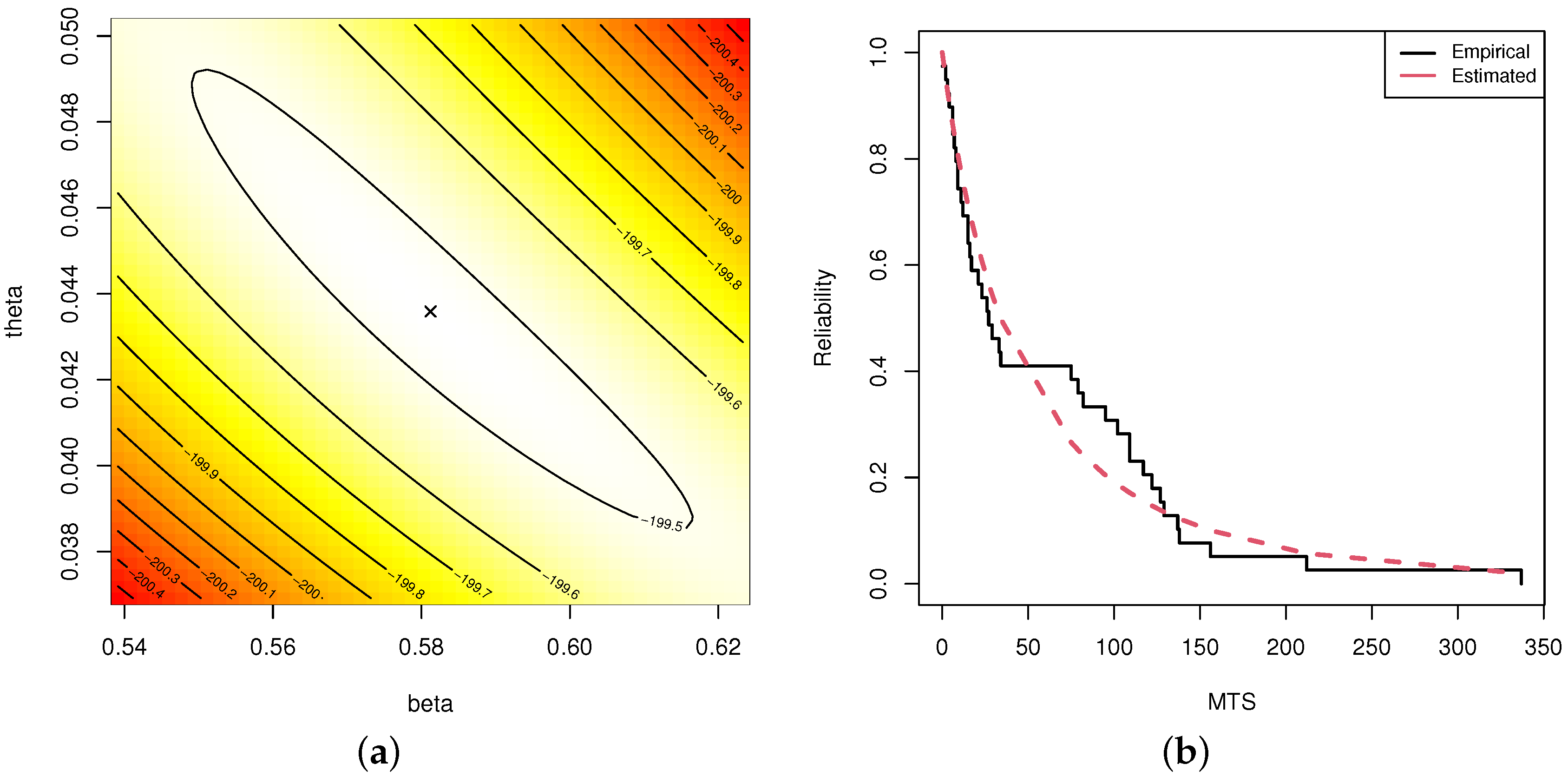
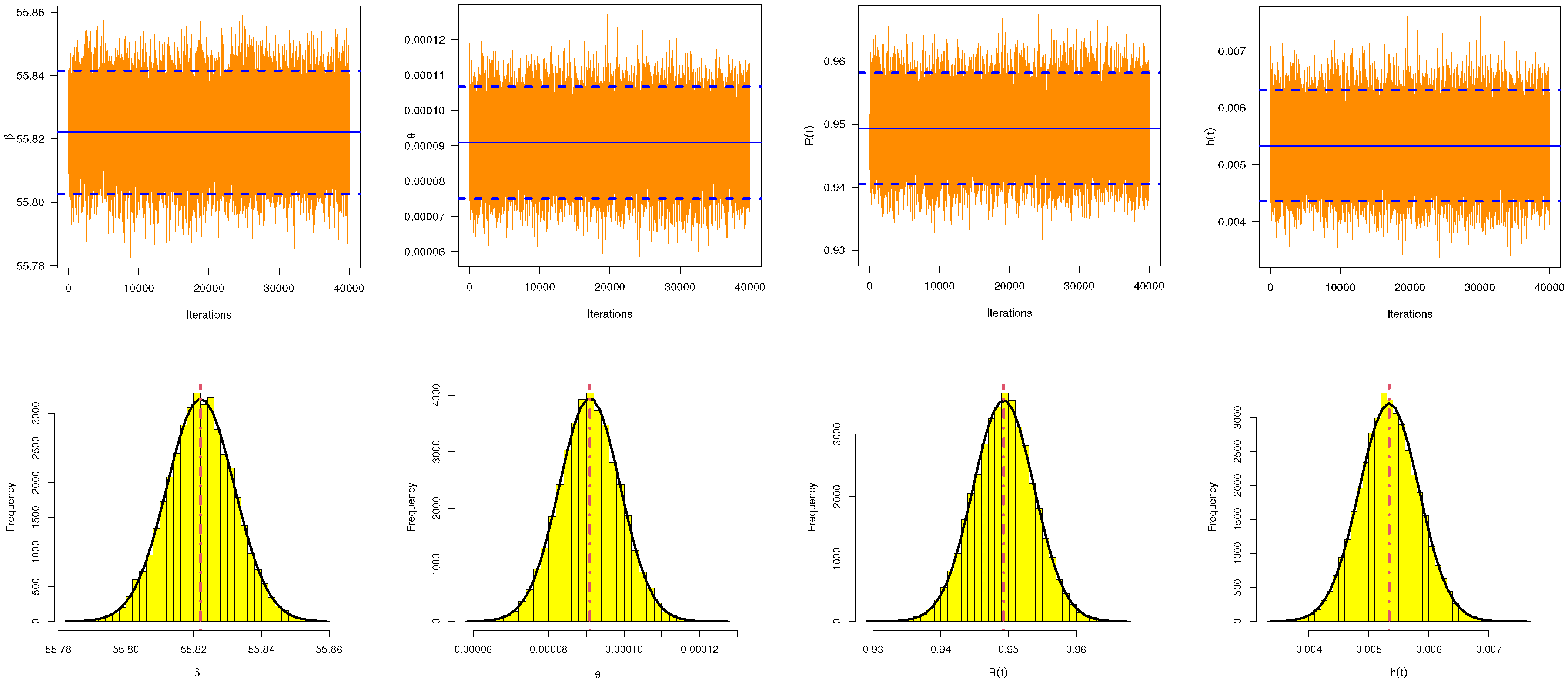
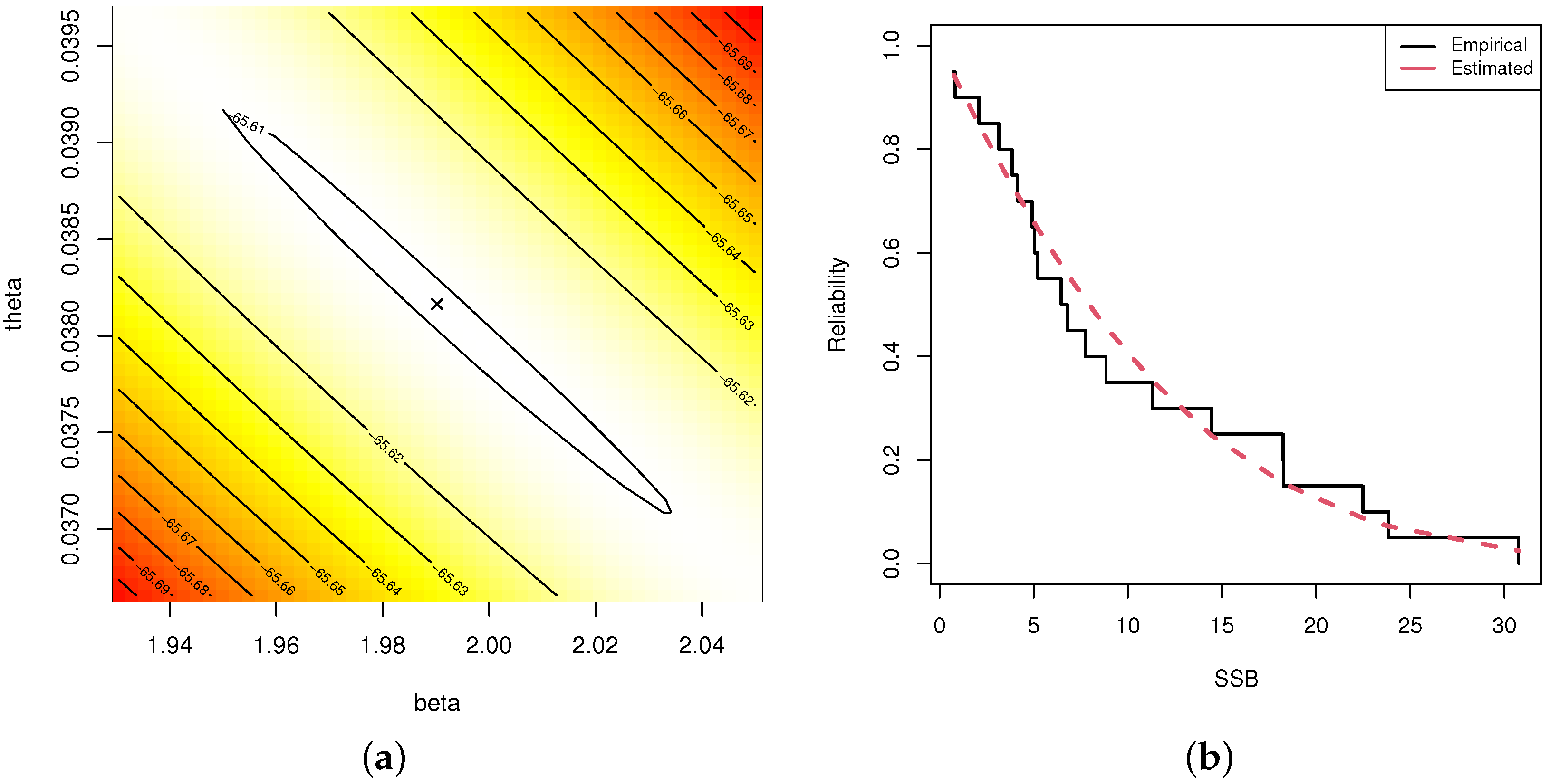
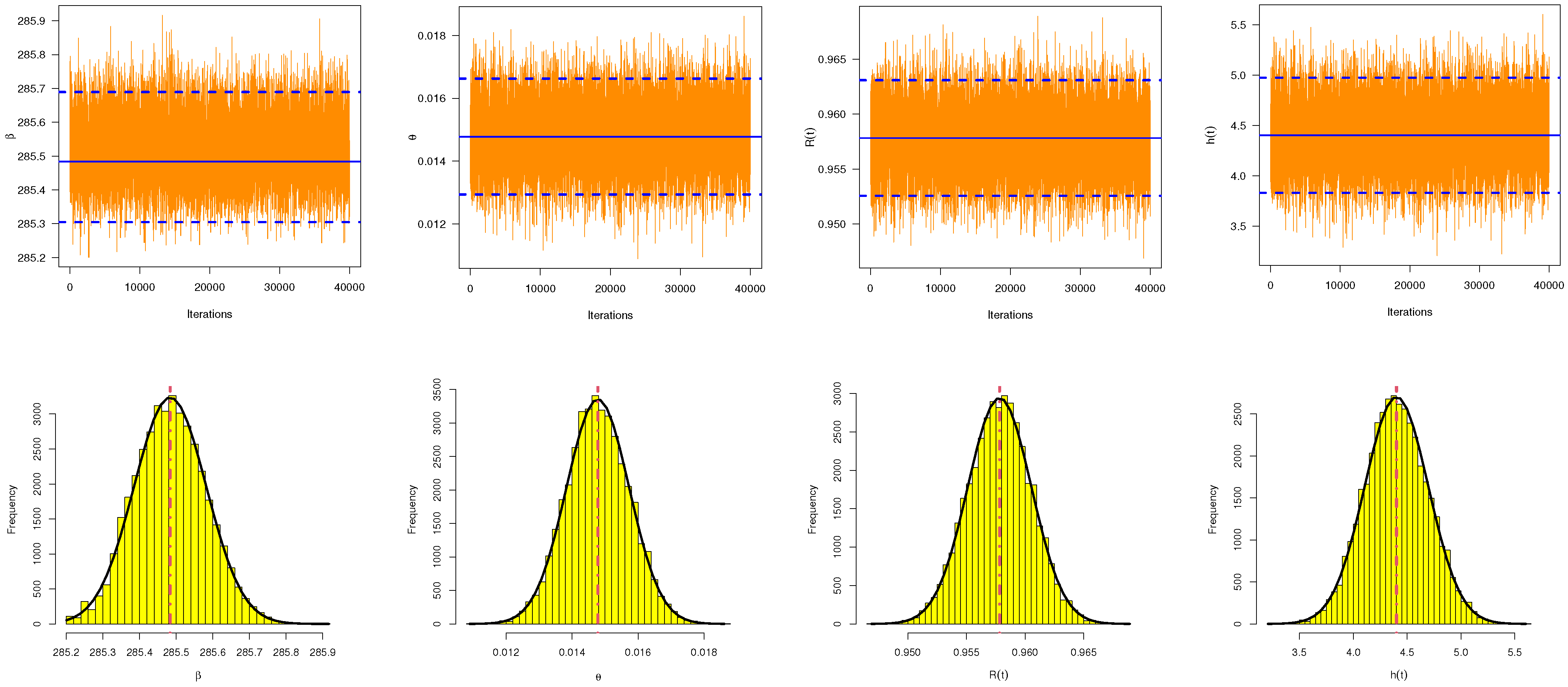
In this paper, we have investigated maximum likelihood and Bayesian inference for the Nadarajah–Haghighi distribution based on an adaptive progressive Type II censoring scheme. Due to the complex forms of the maximum likelihood equations, the maximum likelihood estimates of the unknown parameters are obtained through numerical methods. Based on the invariance property of the maximum likelihood estimates, the estimates of the reliability and hazard rate functions are derived as well. Utilizing the asymptotic properties of the maximum likelihood estimates, both the approximate confidence intervals of the unknown parameters and the reliability and hazard rate functions are acquired. On the other hand, we evaluate Bayesian estimation using two loss functions, namely, the squared error and general entropy loss functions, with the estimates obtained via the Monte Carlo Markov Chain technique. Meanwhile, we establish the highest posterior density Bayes credible intervals of the different unknown parameters. To check the performance of the various estimates, we carried out a simulation study. In the simulation part of this paper, the average values of the root mean square errors and relative absolute biases are computed to examine the performance of the point estimates, while the average interval lengths and coverage probabilities are evaluated for the interval estimates. Based on the simulation outcomes, it is evident that Bayesian estimation, which retains appropriate informative priors, is more reasonable than the maximum likelihood estimates in all cases. To be more specific, the Bayesian estimates using the general entropy loss function perform better than all other estimates. In addition, the highest posterior density Bayes credible intervals possess the smallest average interval lengths with the highest coverage probabilities when compared with the approximate confidence intervals. Finally, two real datasets, one involving patients with malignant tumors of the sternum and one involving sodium sulphur batteries, are analyzed in order to demonstrate the practicality of the different studied methodologies. In future work, it may prove essential to extend the proposed methods to include the competing risks model or accelerated life tests.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}