
A Method for Predicting the Academic Performances of College Students Based on Education System Data

Abstract
:1. Introduction
- This paper processed real student and course data from a university in Shenyang and used it for the training and testing of the predicted model.
- A feedforward spiking neural network model is proposed to predict students’ grades; the simulation results show the advantages of the proposed model using student grade data and course information data in predicting real students’ grades.
- It is helpful for teachers to implement timely intervention and for students to adjust their learning statuses, which is of great significance to the harmonious development of teaching and learning.
2. Related Works
2.1. Student Achievement Prediction
2.2. Pattern Classification
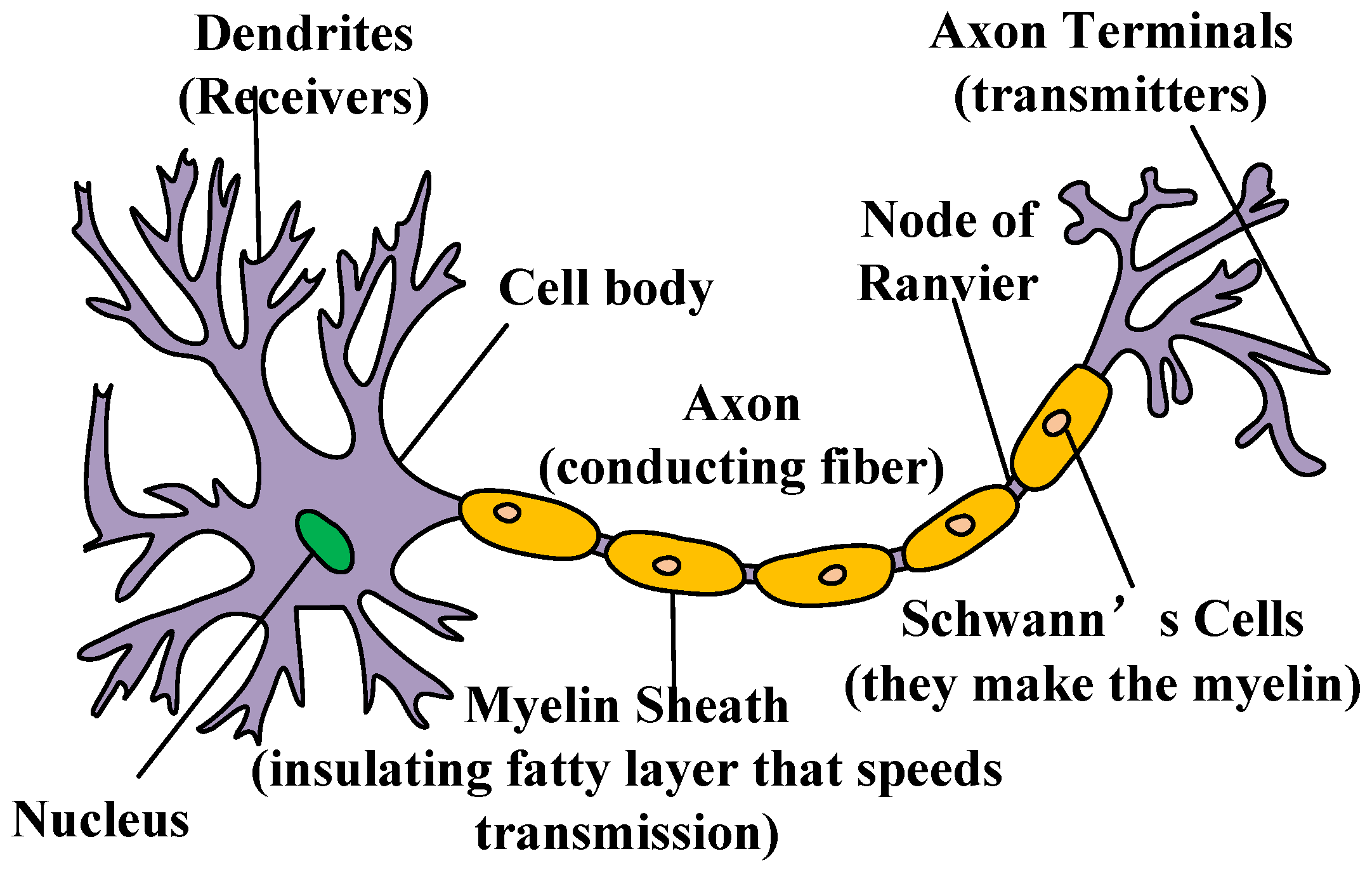
2.3. Spiking Neural Network
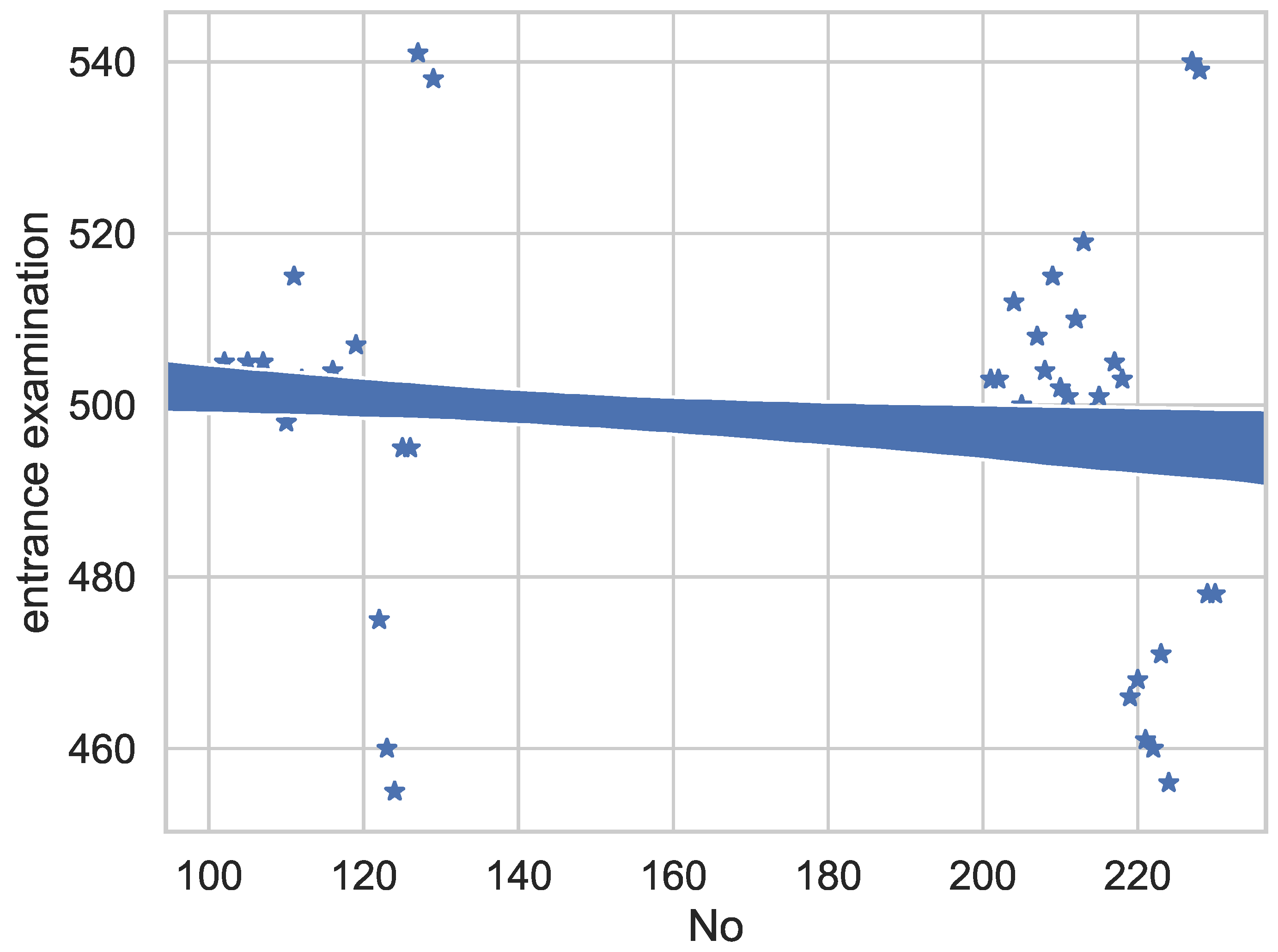
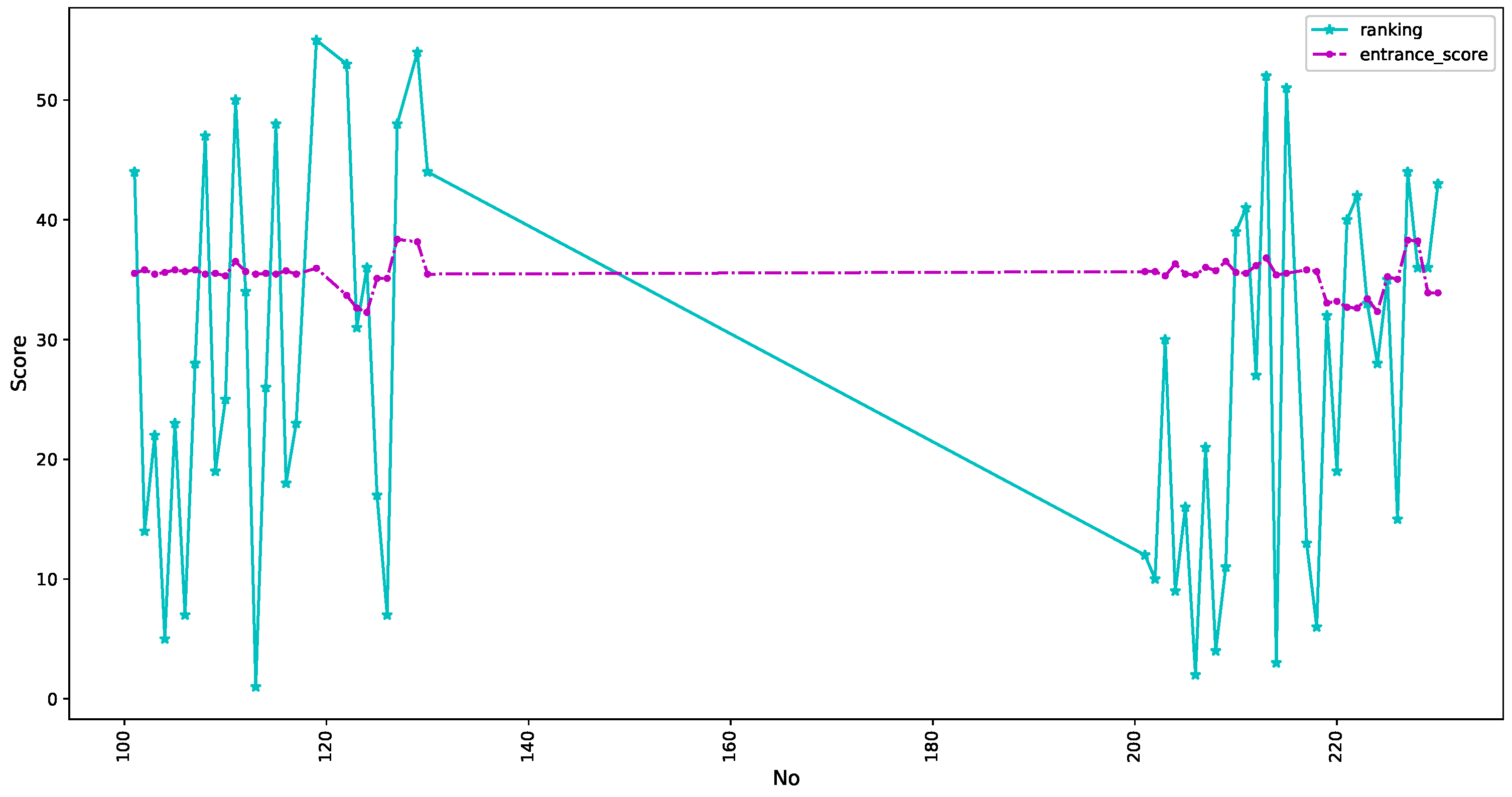
3. Real Datasets in Education Systems
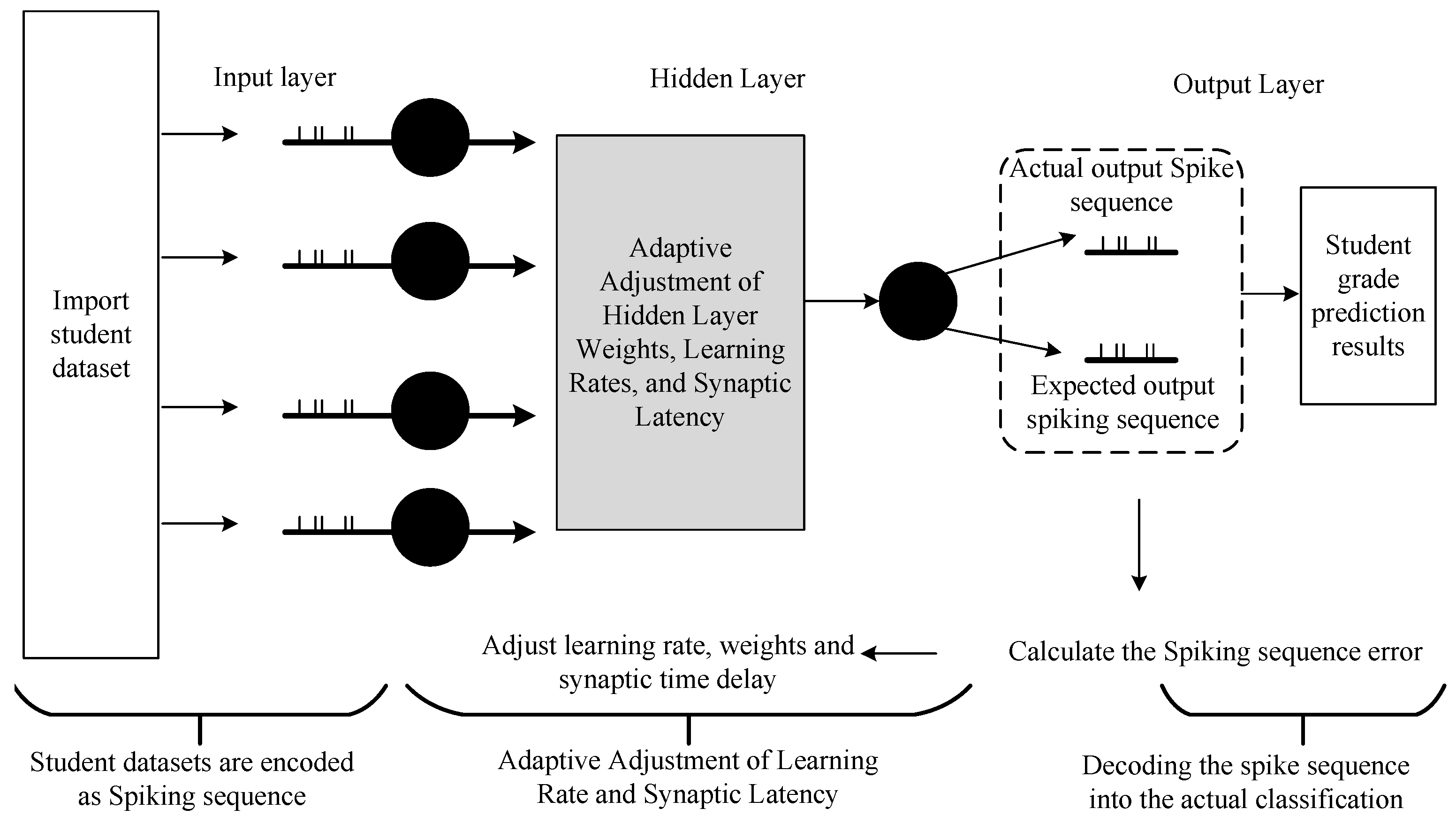
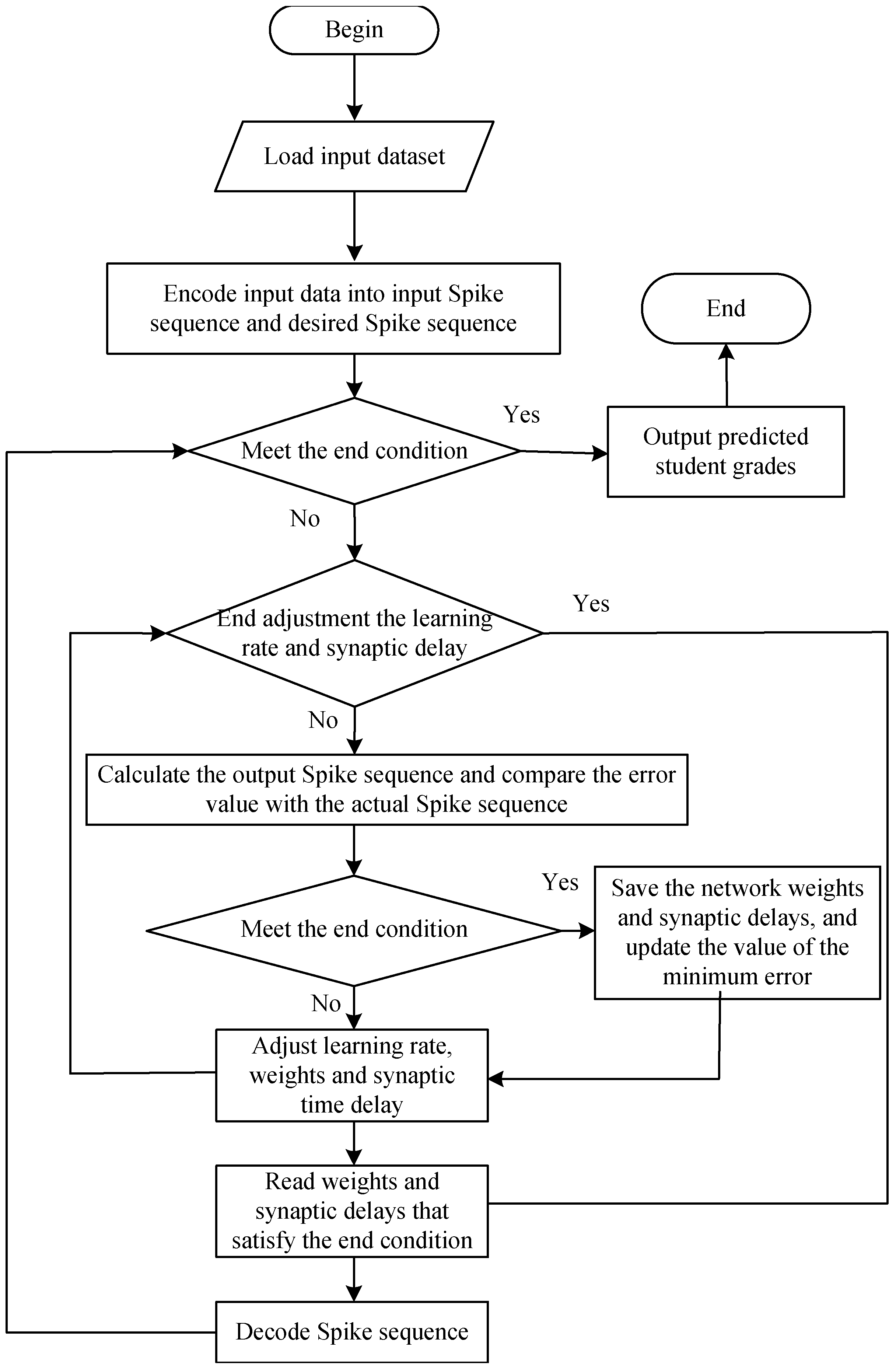
4. Proposed Method
| Algorithm 1 The pseudo-code of the proposed algorithm for student achievement prediction. |
| Require: Student dataset and course dataset. Ensure: Predicted results.
|
5. Experimental Studies
5.1. Experimental Datasets and Experimental Conditions
5.1.1. Datasets
5.1.2. Experimental Conditions
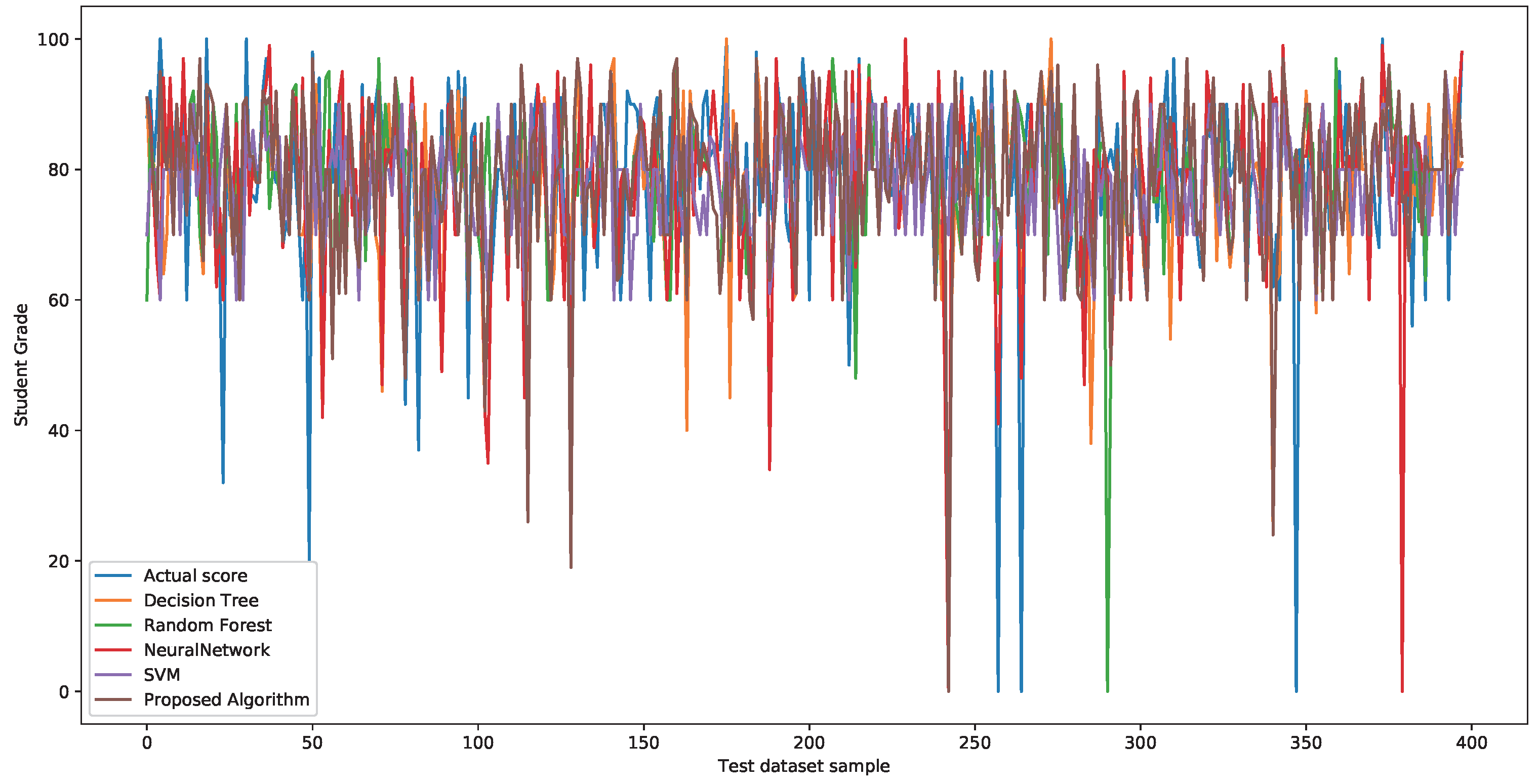
5.2. Comparing the Results of All Experimental Algorithms
5.2.1. Comparing Results with All Experimental Models on the Real Educational Datasets
5.2.2. Discussions
- We carried out a study on the prediction of academic performances on the basis of the feedforward spike neural network but did not try more new intelligent analysis techniques; the selected case samples are expected to be further expanded and judged through more evaluation index comparisons, the accuracy, and validity of the learning performance prediction model, and the practical value of teaching.
- The deep relationship between portrait application and academic performance prediction is expected to be further explored. Since this study focused on building a learning performance prediction model, the dimensions of the learner portrait construction and the corresponding data indicators were very rich (which affect the accuracy of learning achievement prediction). On the one hand, it still needed to be further verified and revised to improve the support efficiency of learner portraits for teaching and learning; on the other hand, the prediction effect of academic performance can be improved by optimizing the spiking neural network model, and the key factors of academic performance prediction can be further explored to help teachers and students. It can provide more accurate and personalized learning services.
- Experimental data samples were limited since the learner samples selected in this study were from two classes in one grade; for six-semester courses, the acquisition of learning data was also limited by the online learning platform and educational administration system. These data were still shallow and single, and the data amounts were limited. They were also relatively sparse, so the prediction accuracy of student grades still needed to be further improved. In the follow-up, on the one hand, we will combine the latest research results of behavioral science and brain science to collect more data on the learning processes of learners.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Okewu, E.; Adewole, P.; Misra, S.; Maskeliunas, R.; Damasevicius, R. Artificial Neural Networks for Educational Data Mining in Higher Education: A Systematic Literature Review. Appl. Artif. Intell. 2021, 35, 983–1021. [Google Scholar] [CrossRef]
- Asif, R.; Merceron, A.; Ali, S.A.; Haider, N.G. Analyzing undergraduate students’ performance using educational data mining. Comput. Educ. 2017, 113, 177–194. [Google Scholar] [CrossRef]
- You, J.W. Identifying significant indicators using LMS data to predict course achievement in online learning. Internet High. Educ. 2016, 29, 23–30. [Google Scholar] [CrossRef]
- González-Calatayud, V.; Prendes-Espinosa, P.; Roig-Vila, R. Artificial Intelligence for Student Assessment: A Systematic Review. Appl. Sci. 2021, 11, 5467. [Google Scholar] [CrossRef]
- Yang, F.; Li, F.W.B. Study on student performance estimation, student progress analysis, and student potential prediction based on data mining. Comput. Educ. 2018, 123, 97–108. [Google Scholar] [CrossRef] [Green Version]
- Dutt, A.; Ismail, M.A.; Herawan, T. A Systematic Review on Educational Data Mining. IEEE Access 2017, 5, 15991–16005. [Google Scholar] [CrossRef]
- Tomasevic, N.; Gvozdenovic, N.; Vranes, S. An overview and comparison of supervised data mining techniques for student exam performance prediction. Comput. Educ. 2020, 143, 103676. [Google Scholar] [CrossRef]
- Qu, S.; Li, K.; Zhang, S.; Wang, Y. Predicting Achievement of Students in Smart Campus. IEEE Access 2018, 6, 60264–60273. [Google Scholar] [CrossRef]
- Kostopoulos, G.; Kotsiantis, S.; Fazakis, N.; Koutsonikos, G.; Pierrakeas, C. A Semi-Supervised Regression Algorithm for Grade Prediction of Students in Distance Learning Courses. Int. J. Artif. Intell. Tools 2019, 28, 1940001. [Google Scholar] [CrossRef]
- Yang, Y.; Hooshyar, D.; Pedaste, M.; Wang, M.; Huang, Y.M.; Lim, H. Predicting course achievement of university students based on their procrastination behaviour on Moodle. Soft Comput. 2020, 24, 18777–18793. [Google Scholar] [CrossRef]
- Nieto-Reyes, A.; Duque, R.; Francisci, G. A Method to Automate the Prediction of Student Academic Performance from Early Stages of the Course. Mathematics 2021, 9, 2677. [Google Scholar] [CrossRef]
- Miao, J. A hybrid model for student grade prediction using support vector machine and neural network. J. Intell. Fuzzy Syst. 2021, 40, 2673–2683. [Google Scholar] [CrossRef]
- Ali, A.D.; Hanna, W.K. Predicting Students’ Achievement in a Hybrid Environment Through Self-Regulated Learning, Log Data, and Course Engagement: A Data Mining Approach. J. Educ. Comput. Res. 2022, 60, 960–985. [Google Scholar] [CrossRef]
- Baashar, Y.; Alkawsi, G.; Mustafa, A.; Alkahtani, A.A.; Alsariera, Y.A.; Ali, A.Q.; Hashim, W.; Tiong, S.K. Toward Predicting Student’s Academic Performance Using Artificial Neural Networks (ANNs). Appl. Sci. 2022, 12, 1289. [Google Scholar] [CrossRef]
- Li, X.; Zhang, Y.; Cheng, H.; Li, M.; Yin, B. Student achievement prediction using deep neural network from multi-source campus data. Complex Intell. Syst. 2022, 1–14. [Google Scholar] [CrossRef]
- Liu, C.; Wang, H.; Du, Y.; Yuan, Z. A Predictive Model for Student Achievement Using Spiking Neural Networks Based on Educational Data. Appl. Sci. 2022, 12, 3841. [Google Scholar] [CrossRef]
- Sekeroglu, B.; Abiyev, R.; Ilhan, A.; Arslan, M.; Idoko, J.B. Systematic Literature Review on Machine Learning and Student Performance Prediction: Critical Gaps and Possible Remedies. Appl. Sci. 2021, 11, 10907. [Google Scholar] [CrossRef]
- Cogliano, M.; Bernacki, M.L.; Hilpert, J.C.; Strong, C.L. A Self-Regulated Learning Analytics Prediction-and-Intervention Design: Detecting and Supporting Struggling Biology Students. J. Educ. Psychol. 2022. [Google Scholar] [CrossRef]
- Tsai, Y.h.; Lin, C.h.; Hong, J.c.; Tai, K.h. The effects of metacognition on online learning interest and continuance to learn with MOOCs. Comput. Educ. 2018, 121, 18–29. [Google Scholar] [CrossRef]
- Steinmayr, R.; Weidinger, A.F.; Wigfield, A. Does students’ grit predict their school achievement above and beyond their personality, motivation, and engagement? Contemp. Educ. Psychol. 2018, 53, 106–122. [Google Scholar] [CrossRef]
- Fahd, K.; Venkatraman, S.; Miah, S.J.; Ahmed, K. Application of machine learning in higher education to assess student academic performance, at-risk, and attrition: A meta-analysis of literature. Educ. Inf. Technol. 2022, 27, 3743–3775. [Google Scholar] [CrossRef]
- Ahmad, S.; El-Affendi, M.A.; Anwar, M.S.; Iqbal, R. Potential Future Directions in Optimization of Students’ Performance Prediction System. Comput. Intell. Neurosci. 2022, 2022. [Google Scholar] [CrossRef]
- Alhassan, A.M.; Wan Zainon, W.M.N. Review of Feature Selection, Dimensionality Reduction and Classification for Chronic Disease Diagnosis. IEEE Access 2021, 9, 87310–87317. [Google Scholar] [CrossRef]
- Gupta, A.; Gupta, H.P.; Biswas, B.; Dutta, T. Approaches and Applications of Early Classification of Time Series: A Review. IEEE Trans. Artif. Intell. 2020, 1, 47–61. [Google Scholar] [CrossRef]
- Chamola, V.; Hassija, V.; Gupta, S.; Goyal, A.; Guizani, M.; Sikdar, B. Disaster and Pandemic Management Using Machine Learning: A Survey. IEEE Internet Things J. 2021, 8, 16047–16071. [Google Scholar] [CrossRef] [PubMed]
- Taherkhani, A.; Belatreche, A.; Li, Y.; Cosma, G.; Maguire, L.P.; McGinnity, T.M. A review of learning in biologically plausible spiking neural networks. Neural Netw. 2020, 122, 253–272. [Google Scholar] [CrossRef] [PubMed]
- Javanshir, A.; Nguyen, T.T.; Mahmud, M.A.P.; Kouzani, A.Z. Advancements in Algorithms and Neuromorphic Hardware for Spiking Neural Networks. Neural Comput. 2022, 34, 1289–1328. [Google Scholar] [CrossRef] [PubMed]
- Faraz, S.; Mellal, I.; Lankarany, M. Impact of Synaptic Strength on Propagation of Asynchronous Spikes in Biologically Realistic Feed-Forward Neural Network. IEEE J. Sel. Top. Signal Process. 2020, 14, 646–653. [Google Scholar] [CrossRef]
- Zahra, O.; Tolu, S.; Navarro-Alarcon, D. Differential mapping spiking neural network for sensor-based robot control. Bioinspiration Biomimetics 2021, 16, 036008. [Google Scholar] [CrossRef]
- Liu, C.; Wang, H.; Liu, N.; Yuan, Z. Optimizing the Neural Structure and Hyperparameters of Liquid State Machines Based on Evolutionary Membrane Algorithm. Mathematics 2022, 10, 1844. [Google Scholar] [CrossRef]
- Soffer, T.; Cohen, A. Students’ engagement characteristics predict success and completion of online courses. J. Comput. Assist. Learn. 2019, 35, 378–389. [Google Scholar] [CrossRef]
- Roschelle, J.; Feng, M.; Murphy, R.F.; Mason, C.A. Online Mathematics Homework Increases Student Achievement. Aera Open 2016, 2, 2332858416673968. [Google Scholar] [CrossRef] [Green Version]
- Muenks, K.; Wigfield, A.; Yang, J.S.; O’Neal, C.R. How True Is Grit? Assessing Its Relations to High School and College Students’ Personality Characteristics, Self-Regulation, Engagement, and Achievement. J. Educ. Psychol. 2017, 109, 599–620. [Google Scholar] [CrossRef]
- Hooda, M.; Rana, C.; Dahiya, O.; Rizwan, A.; Hossain, M.S. Artificial Intelligence for Assessment and Feedback to Enhance Student Success in Higher Education. Math. Probl. Eng. 2022, 2022, 5215722. [Google Scholar] [CrossRef]
- Comsa, I.M.; Potempa, K.; Versari, L.; Fischbacher, T.; Gesmundo, A.; Alakuijala, J. Temporal Coding in Spiking Neural Networks With Alpha Synaptic Function: Learning With Backpropagation. IEEE Trans. Neural Netw. Learn. Syst. 2022, 2022, 5215722. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.J.; Hong, A.J.; Song, H.D. The roles of academic engagement and digital readiness in students’ achievements in university e-learning environments. Int. J. Educ. Technol. High. Educ. 2019, 16, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Friedrich, A.; Flunger, B.; Nagengast, B.; Jonkmann, K.; Trautwein, U. Pygmalion effects in the classroom: Teacher expectancy effects on students’ math achievement. Contemp. Educ. Psychol. 2015, 41, 1–12. [Google Scholar] [CrossRef]
- Aldowah, H.; Al-Samarraie, H.; Fauzy, W.M. Educational data mining and learning analytics for 21st century higher education: A review and synthesis. Telemat. Inform. 2019, 37, 13–49. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
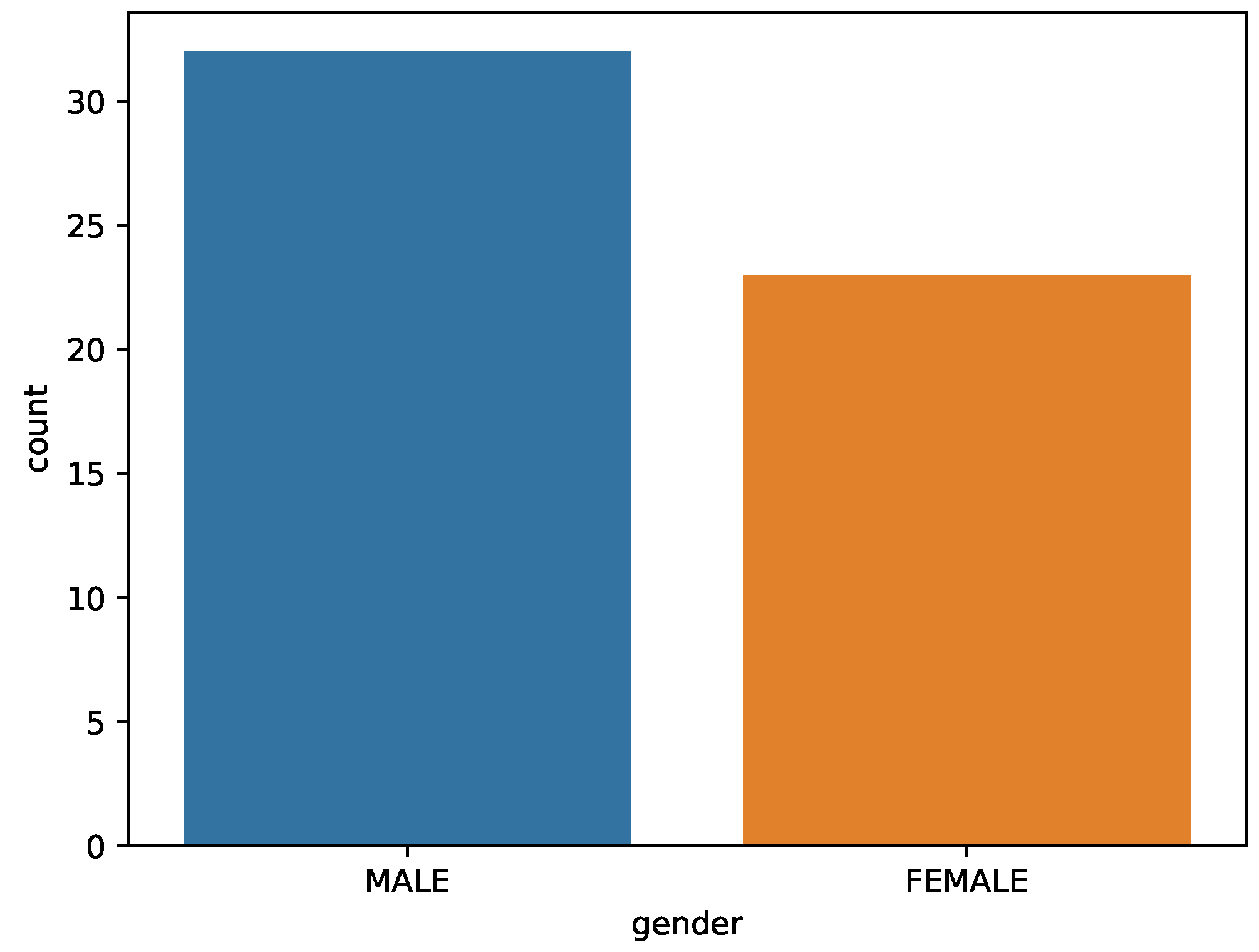{kind=link}
{kind=link}
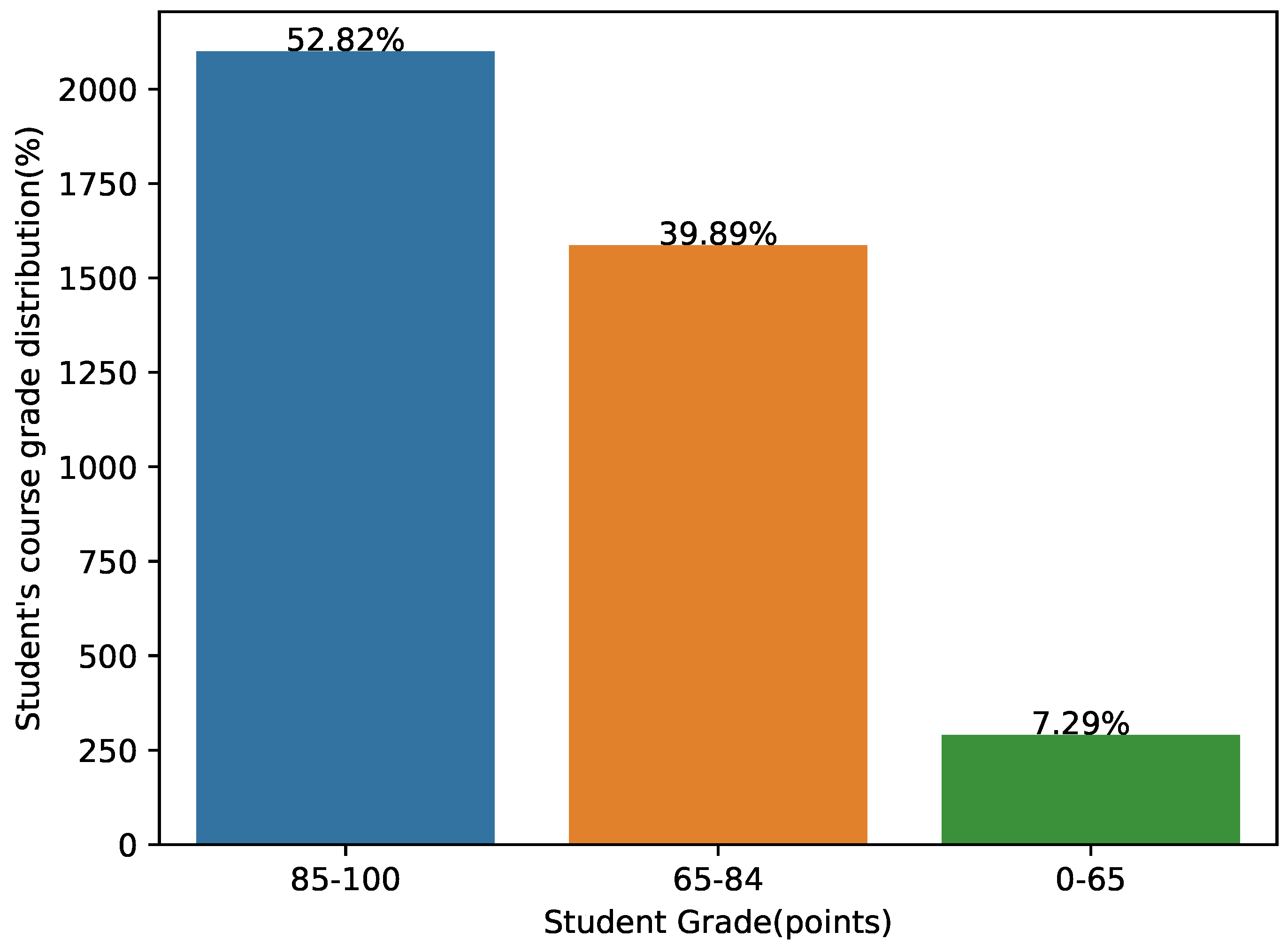{kind=link}
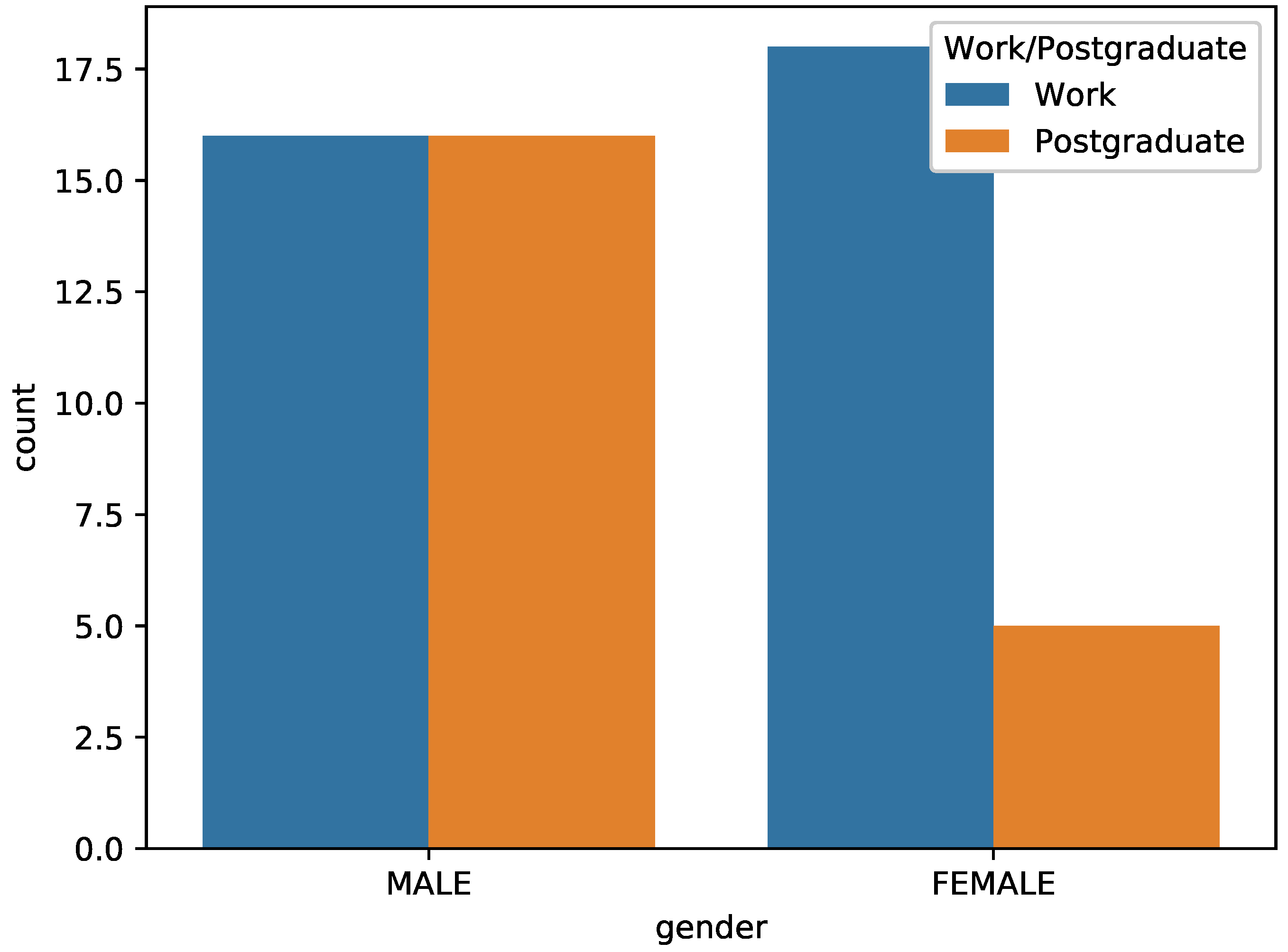{kind=link}
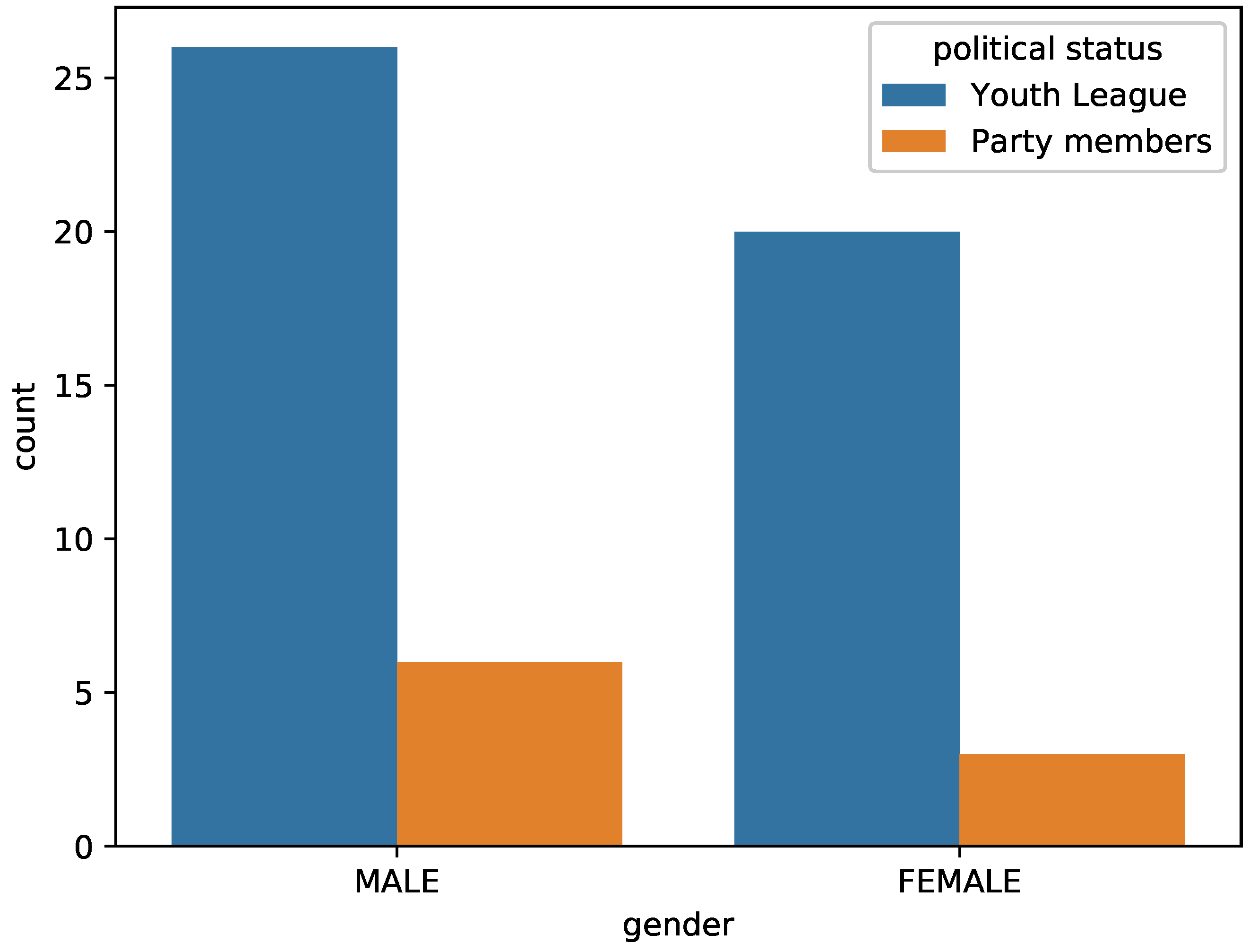{kind=link}
{kind=link}
{kind=link}
| Number of Students | Boys/Girls | Number of Semesters | Number of Courses |
|---|---|---|---|
| 55 | 32/23 | 6 | 62 |
| Category | Excellent | Satisfactory | Fail |
|---|---|---|---|
| Original value | 85–100 | 65–84 | 0–64 |
| Classification | H | M | L |
| Encoding | 1 | 2 | 3 |
| Datasets | Number |
|---|---|
| Training dataset | 3578 |
| Test dataset | 398 |
| Algorithm | Classification | Precision | Recall | F1-Score | Support | Accuracy |
|---|---|---|---|---|---|---|
| Decision Tree | H | 0.70 | 0.74 | 0.72 | 224 | 0.625628 |
| M | 0.54 | 0.53 | 0.53 | 148 | ||
| L | 0.28 | 0.19 | 0.23 | 26 | ||
| Random Forest | H | 0.70 | 0.73 | 0.71 | 224 | 0.610553 |
| M | 0.51 | 0.51 | 0.51 | 148 | ||
| L | 0.27 | 0.15 | 0.20 | 26 | ||
| Neural Network | H | 0.72 | 0.79 | 0.75 | 224 | 0.655779 |
| M | 0.56 | 0.57 | 0.57 | 148 | ||
| L | 0.00 | 0.00 | 0.00 | 26 | ||
| XGBoost | H | 0.77 | 0.77 | 0.77 | 224 | 0.670854 |
| M | 0.58 | 0.61 | 0.59 | 148 | ||
| L | 0.24 | 0.15 | 0.19 | 26 | ||
| SVM | H | 0.72 | 0.79 | 0.75 | 224 | 0.663317 |
| M | 0.58 | 0.59 | 0.58 | 148 | ||
| L | 0.00 | 0.00 | 0.00 | 26 | ||
| Proposed Algorithm | H | 0.79 | 0.78 | 0.79 | 224 | 0.708543 |
| M | 0.61 | 0.70 | 0.65 | 148 | ||
| L | 0.50 | 0.15 | 0.24 | 26 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, C.; Wang, H.; Yuan, Z. A Method for Predicting the Academic Performances of College Students Based on Education System Data. Mathematics 2022, 10, 3737. https://doi.org/10.3390/math10203737
Liu C, Wang H, Yuan Z. A Method for Predicting the Academic Performances of College Students Based on Education System Data. Mathematics. 2022; 10(20):3737. https://doi.org/10.3390/math10203737
Chicago/Turabian StyleLiu, Chuang, Haojie Wang, and Zhonghu Yuan. 2022. "A Method for Predicting the Academic Performances of College Students Based on Education System Data" Mathematics 10, no. 20: 3737. https://doi.org/10.3390/math10203737