1. Introduction
In theory of survival models, the distributions are often attributed to time intervals and different structures of regression models have been constructed. Recently, many distributions and regression models have been developed based on extended Weibull distributions, for example, the log-odd log-logistic location-scale regression model [
1], the bivariate odd-log-logistic-Weibull regression model [
2], the Weibull zero-inflated right-censored regression model [
3], the inverted Weibull regression model [
4], and the Weibull quantile regression model [
5], among many others. The importance of such extensions is remarkable and some important results can be found in the field of medicine. For example, in a study of patients with colorectal cancer, Moamer et al. (2017) [
6] assessed the survival and prognostic factors based on the Weibull competing-risks model and showed that the body mass index and some stages of disease influenced survival, and Yoosefi et al. (2018) [
7], using exponentiated Weibull distribution, found that the age of patients at diagnosis was the most important influencing factor for increasing survival and reducing the mortality rate. The results of the risks associated with breast cancer using a mixture cure fraction model based on the generalized modified Weibull model can be seen in Naseri et al. (2018) [
8] where covariates, such as the number of metastatic lymph nodes and histologic grade, were statistically significant and the estimated cure fraction was 58%. Pavisic et al. (2020) [
9] determined the factors that influenced the survival of patients with autosomal dominant familial Alzheimer disease (ADAD) using multilevel mixed-effects Weibull survival models, which proved to be longer for successive generations and in individuals with atypical presentations. In this context, we propose the
odd log-logistic Weibull (OLLW) regression model for censored data, which is different from the log-linear regression model addressed by da Cruz et al. (2016) [
1].
The new regression model has an extra shape parameter that enables greater flexibility for modeling the risk rate function in the four most common shapes. It is a possible alternative to mixture models since the hazard rate can be bimodal. We define two systematic components for the shape and scale parameters of the Weibull using the logarithmic link function to measure the effects of the covariables. We provide some simulations to evaluate the precision of the maximum likelihood estimators (MLEs) and the empirical distribution of the deviance residuals.
We also present an application for hospitalized patients diagnosed with COVID-19 (SARS-CoV-2 B.1.1.529) in the city of Campinas (Brazil). Although its mortality rate (
) was lower than other variants in earlier periods of the pandemic (about
), its transmissibility was considered to be extremely high in Brazil, causing a high number of hospitalizations and deaths (Xavier et al., 2022 [
10]). In this context, studies are necessary to investigate the variables that increase the risk of death, which can vary according to the pandemic scenario and demographic and epidemiological factors of each region. Knowledge of the progression of the disease can support more timely and effective medical interventions (see Lu et al. (2021) [
11], Giacomelli et al. (2020) [
12], and Zheng et al. (2020) [
13]. In previous survival analyses, some risk factors were frequently mentioned, such as high age [
12,
14,
15], diabetes [
12,
16,
17], and obesity [
12,
16,
17]. In addition to these, some interesting factors were verified, such as neurological diseases [
18] and sex [
16,
19]. Lu et al. (2021) [
11] revealed that lower lymphocyte counts in a hemogram, lowplatelet count and serum albumin, high C-reactive protein level, and renal dysfunction may be risk factors. Nijman et al. (2021) [
15] found that immunocompromised patients who used anticoagulants or antiplatelet medication had increased risk of death. Zheng et al. (2020) [
13] also found cardiovascular disease, hypertension, and smoking as factors that could greatly affect the prognosis of COVID-19.
The present work aims to study the factors that increase the risk of death of hospitalized patients diagnosed with COVID-19 using the odd log-logistic Weibull regression model and to provide new mathematical properties. Motivated by the pandemic scenarios and given the notable contributions of the Weibull distribution and its extensions, the results obtained with the application are considered the main contributions of this work, whereas information and prior knowledge of the impact of such factors on survival can also be decisive in treatment [
20]. In addition, the new mathematical properties provided bring more information and can help future research. In addition, the use of this dataset can motivate the future use of this model in lifetime data, thus showing that it can be an interesting and efficient alternative.
The rest of the paper presents the following topics.
Section 2 provides a brief summary of the OLLW distribution and some new mathematical properties.
Section 3 defines the OLLW regression model for censored data and presents diagnostic measures and residuals. Some simulations for the new regression model are described in
Section 4. The usefulness of our results is illustrated through their application to COVID-19 data in
Section 5. Finally, some conclusions are cited in
Section 6.
2. New OLLW Properties
The Weibull distribution is mostly used in reliability and lifetime modeling, and it encompasses both increasing and decreasing failure rate functions. Its cumulative distribution function (cdf) is
where
is the shape,
is the scale, and
.
The quantile function (qf) of the Weibull by inverting (
1) is
for
.
Based on the idea of Gleaton and Lynch (2006) [
21], the OLLW cdf
(for
) comes from (
1)
where
is an extra shape parameter.
By differentiating (
2), the OLLW probability density function (pdf) becomes
Let the random variable
have pdf (
3). Plots of the pdf of
T are reported in
Figure 1, thus showing flexibility for modeling skewness, kurtosis, and bimodality.
By inverting (
2), the qf of the OLLW distrubution is given in terms of the Weibull counterpart
where
.
We provide below new structural properties of the OLLW distribution.
2.1. Modes
Every mode
of the OLLW satisfies the equation
, where
By taking
,
and
can be written as
Hence, every mode
of the OLLW density satisfies
It is an arduous task to obtain analytically the roots of this equation. Graphically, it has at most three roots from which the bimodality of the OLLW density is guaranteed (
Figure 1).
2.2. Stochastic Representation
Proposition 1. The stochastic representation of holds:where S has the Burr Type XII distribution, say . Proof. Note that the cdf
in (
2) can be rewritten as
where
is given by (
1). Since
(for
), we obtain
(for
), i.e., the function
is increasing, hence,
In other words,
T and
are equal in distribution. The proof follows based on the Weibull qf. □
2.3. Closure under Changes of Scale and of Power
Proposition 2. - 1.
If , then , .
- 2.
If , then , .
Proof. Let
. By (
5),
, with
. Since
and
, the proof is complete. □
2.4. Identifiability
The concept of identifiability of a distribution means that distinct values of the parameters should correspond to distinct probability distributions: if
, then also
,
, where
,
, is defined by (
2).
Proposition 3. The OLLW distribution is identifiable.
Proof. Let us suposse that
,
. By (
5), it is equivalent to
where
and
,
. For
, it is well-known that
. So, this equation reduces to
Setting
, we obtain
Equivalently, we have
Since the only real solutions of
are
and
, it follows from Equation (
7) that
and
. Using these identities in (
6),
, and the proof is complete. □
2.5. Existence of Real Moments
Proposition 4. If and , then Proof. Since
we have
. By using this inequality and the stochastic representation of
T (see Proposition 1), we obtain
Taking the expectations on both sides of the above inequality and then using the well-known identity
the proof follows. □
2.6. Tail Behavior
The continuous univariate distribution
F (on
) has an upper light tail if (for
)
whereas it has an upper heavy tail if (for
)
Proposition 5. The OLLW distribution has a transition from heavy-tailed to light-tailed. In other words,
- (a)
For , the OLLW distribution has an upper heavy tail.
- (b)
For , the OLLW distribution has an upper light tail.
- (c)
For , the OLLW distribution does not have a defined tail behavior.
Proof. A simple algebraic manipulation leads to (for
and
)
This completes the proof. □
3. The OLLW Regression Model
The OLLW regression model is defined by two systematic components for and (for ), as follows
Equation added
where
(
) are vectors of length (
) of unknown coefficients functionally independent,
is the number of explanatory variables related to the
jth parameter,
are the linear predictors, and
are observations on
and
known regressors. The functions
and
defined from
should be strictly monotone and at least twice differentiable. The functions satisfy
and
, where
is the inverse function of
. So, in the following sections, we consider the logarithmic link function for
:
The case leads to the exponential regression model.
Let
and
be the lifetime and censoring time for the
ith individual. The survival function of
given
comes from (
1) as
Consider the independent observations
, where
under the independence of
and
. The log-likelihood function for
from Equation (
9) is
where
r is the number of failures,
F and
C refer to the sets of lifetimes and censoring times, respectively, and
.
The maximum likelihood estimate (MLE)
of
is found to maximize (
10). The gamlss and AdequacyModel packages of the R software and the SAS procedure NLMixed can be used to find
. These packages have been widely adopted in many applied statistics papers.
3.1. Checking Model
The diagnosis of anomalies of the fitted regression is important after the parameter estimation. An analysis that can be carried out is based on the influence measures from the exclusion of observations.
The influence of the
ith observation on the MLE
of
when it is deleted is measured by the (maximized)
likelihood distance (Cook, 1986 [
22])
The
generalized distance (Cook et al., 1988 [
23]) is another influence measure
where
is the observed information matrix.
The deviance residuals used in survival analysis when there are censored observations (Escobar and Meeker, 1992 [
24]) are given by
where
is the censoring indicator and
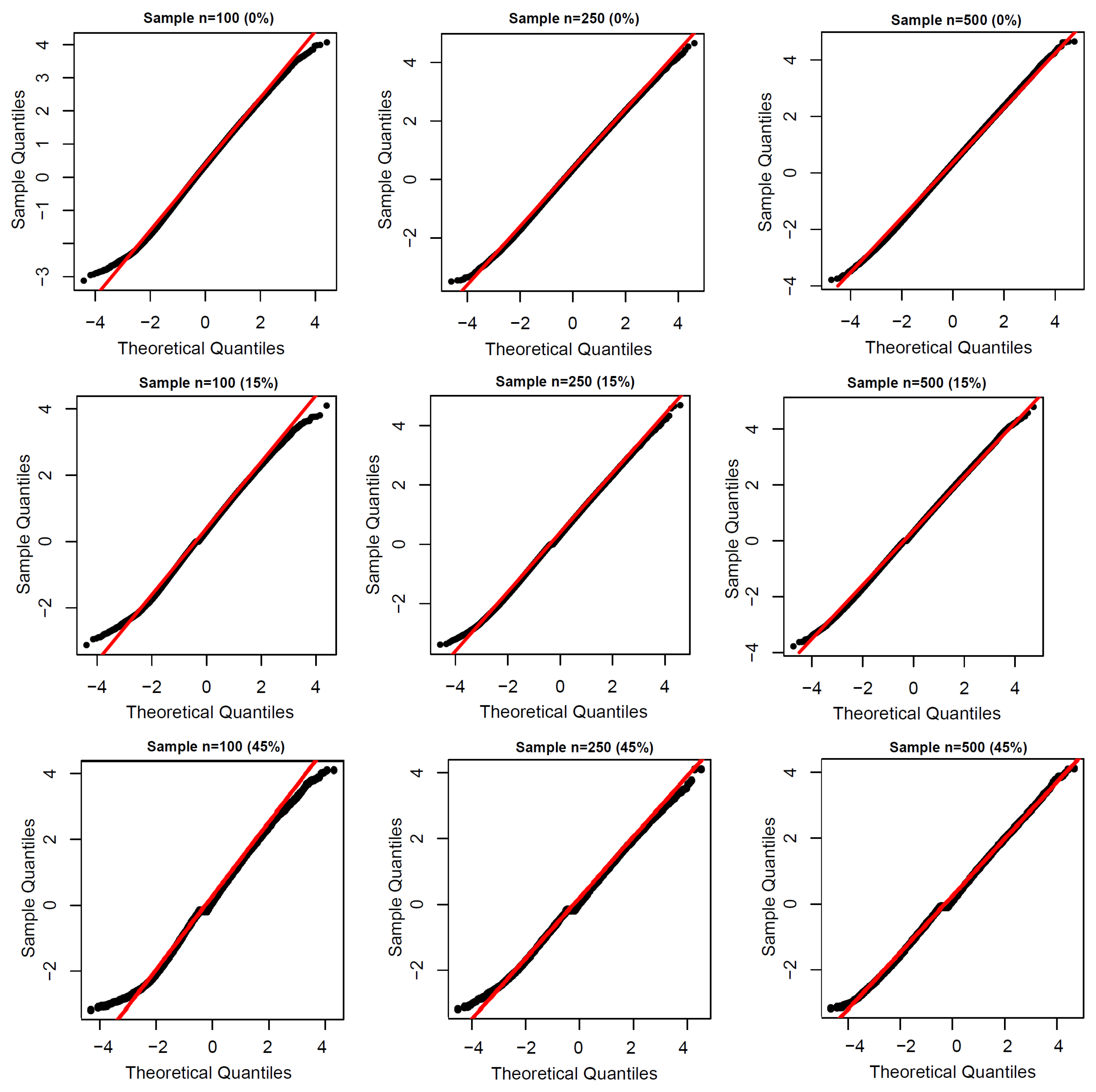
4. Simulation Study
Monte Carlo simulations examined the precision of the MLEs in the new regression model and evaluated the empirical distribution of the deviance residuals using the function
optim in R software for some values of
n and censoring the percentages. One thousand replicates were carried out for each configuration. The lifetimes
were generated from the OLLW
distribution and the censoring times
from a uniform distribution
, where
controls the censoring percentages. Just two covariates
and
were included in the systematic componentes:
where the true parameter values are taken as
,
,
,
,
,
and
.
The simulation process follows the six steps:
- (i)
Generate and ;
- (ii)
Calculate
,
and
from Equation (
12);
- (iii)
Generate ;
- (iv)
Repeat previous steps to obtain
from Equation (
4).
- (v)
Generate and determine survival times . If , then ; otherwise, (for );
- (vi)
Calculate the deviance residuals.
Table 1 reveals that the (Averages) estimates tended to the true parameters and their biases and mean square errors (MSEs) decayed to zero when
n became large. So, the consistency of the estimators holds. We also checked the model through the empirical coverage probabilities (CPs) of the 95% confidence intervals of the estimates.
Table 2 shows that the CPs were close to the nominal level.
Figure 2 proves that the empirical distribution of the deviance residuals approximated the standard normal. So, the normal probability plot can be used with simulated envelopes.
5. Application to COVID-19 Data
We investigated the risk factors associated with death of diagnosed COVID-19 patients in the city of Campinas, Brazil. The sample was composed of hospitalized patients living in the city of Campinas or the northeastern area of the neighboring city of São Paulo in Brazil’s southeast region (
Figure 3). A total of 322 patients infected with the virus (confirmed by RT-PCR screening) and classified as having Severe Acute Respiratory Syndrome 2 (SARS) were included in the study. The model was implemented in the gamlss script in the R software. The dataset and application codes can be accessed at
https://github.com/gabrielamrodrigues/OLLW (accessed on 10 September 2022).
From an economic standpoint, Campinas has the eleventh largest municipal gross domestic product (GDP) in the country and was the first Brazilian city other than state capitals to be classified as a metropolis. It thus has significant national influence. In 2011, it was responsible for at least 15% of the nation’s scientific production and is the third-leading Brazilian city in terms of research and development. For these reasons and accuracy of the data, Campinas was selected in this study.
The response time (in days) is the period from the first symptoms until death due to COVID-19. In this sample, approximately 66.45% of the observations are censored, corresponding to patients who died for other reasons and patients who survived until the end of the study. The associated explanatory variables (for ) are: : censoring indicator (0 = censored, 1 = time of life observed); : sex (0 = female, 1 = male); : age (in years); : chronic cardiovascular disease (1 = yes, 0 = no or not informed); : asthma (1 = yes, 0 = no or not informed); : diabetes mellitus (1 = yes, 0 = no or not informed); : chronic neurological disease (1 = yes, 0 = no or not informed); and : obesity (1 = yes, 0 = no or not informed).
Descriptive Analysis
As in all statistical studies, we began with exploratory analysis of the data by studying the behavior of the response variable and its respective covariables. The Kaplan–Meier survival curves are presented in
Figure 4, where it is possible to observe the existence of a higher risk of death among individuals suffering from diabetes or chronic neurological disease. In addition,
Figure 5 clearly shows that patients aged from 65 to 90 years had the highest hospitalization frequency, as expected.
The MLEs and their standard errors (SEs) (in parentheses), as well as the Global Deviance (GD), Akaike Information Criterion (AIC), and Bayesian Information Criterion (BIC) from two fitted distributions to these data are given in
Table 3.
The likelihood ratio (LR) statistic for comparing the OLLW and Weibull distributions (
,
p-value
) supports the first distribution. The estimated survival functions in
Figure 6 also reveal this fact.
Further, the results from the fitted complete OLLW regression model
are reported in
Table 4.
The variables age, asthma, diabetes mellitus, and chronic neurological disease are significant (at the level of 5%) for
. For the parameter
, the age, asthma, diabetes, chronic neurological disease, and obesity variables are significant and hence the reduced OLLW regression model is
whose estimation results are given in
Table 5. Some interpretations on the numbers in this table are addressed at the end of this section.
The influence measures in
Section 3.1 are calculated in
R and displayed in
Figure 7. They show that the 26th and 270th observations (referring to the patients below) are possibly influential:
26th: A 64-year-old woman with comorbidities (cardiovascular disease, diabetes, and obesity) died in 6 days.
270th: An 11-month-old baby with a neurological disease died in 5 days, and is the only patient younger than 1 year.
Figure 8a displays the index plot of the residuals (
) in Equation (
11), thus revealing that they have a random behavior.
Figure 8b reports the normal probability plot with a simulated envelope (Atkinson, 1987 [
25]), thus revealing that the reduced OLLW regression model is appropriate for these data.
The plots of the empirical and estimated survival functions for the two categorical variables in
Figure 9 confirm the adequacy of the fitted regression.
Interpretation for
The survival time declines when the age increases.
Diabetes mellitus has a significant effect in reducing the survival time of COVID-19 patients.
The patients with chronic neurological disease have a significant reduction in survival time.
Interpretation for
The patient age is also significant in terms of survival time variability.
The variability of survival time depends on whether the patient is obese or not.
The variability of survival time depends on whether the patient has chronic neurological disease or not.
Finally, we obtain
from Equation (
9). In
Figure 10, the estimated survival and hazard rates are plotted for the four hypothetical patients described earlier.
Figure 10a reveals that patients with diabetes mellitus and chronic neurological diseases have a shorter survival time than those who do not have these diseases. Similarly,
Figure 10b shows that patients with diabetes and chronic neurological diseases are at higher risk compared to patients who do not have these pathologies.
We can obtain the survival probabilities and median times from Equations (
9) and (
4), respectively. Then, we consider
fixed at 0 and
and
, as shown in
Table 6.
Table 7 and
Table 8 show the probability of hospitalized patients surviving 20 days after the first symptom and the median time for some ages, respectively.
6. Conclusions
This work studied the factors that increase the risk of death of hospitalized patients diagnosed with COVID-19 using the odd log-logistic Weibull regression model with two systematic components. Some new general structural properties of this model were provided such as its stochastic representation, identifiability, and moments, among others. A simulation study was carried out to evaluate the proposed regression model, which revealed the consistency of the maximum likelihood estimators and showed that the empirical coverage probabilities were close to the nominal level and that the empirical distribution of the deviance modified residuals approached the standard normal.
The application to COVID-19 data revealed some important results. The older age group was a predictor of a higher death rate from COVID-19, corroborating studies by Giacomelli et al. (2020) [
12] and Atlam et al. (2021) [
14], and diabetes and obesity were also evidenced in this work as determinants for the survival of infected patients, as discussed in Giacomelli et al. (2020) [
12], Albitar et al. (2020) [
16], and Noor et al. (2020) [
17]. Chronic neurological diseases were also identified as risk factors, but we emphasize that few studies have obtained these results (García-Azorín et al. (2020) [
18] and Noor et al. (2020) [
17]). Therefore, it is recommended to consider the presence of this comorbidity in future studies in the assessment of mortality risk, as well as verify its significance in other datasets. Several studies have also indicated that men are at greater risk of death (see Albitar et al. (2020) [
16] and Liu et al. (2020) [
19]). However, no significant differences were found between the sexes. Chronic cardiovascular disease and asthma also did not prove to be determinants for the survival of individuals in this study.
It is suggested that future works verify the current datasets and those from other cities, as well as verify whether the same covariates would be significant in a lifetime analysis.
It is possible to conclude that the proposed regression proved to be efficient in identifying the factors that influenced the survival of individuals in this dataset, which can help more timely and efficient medical interventions. Finally, this model can be considered an interesting alternative for future works that evaluate censored lifetimes.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
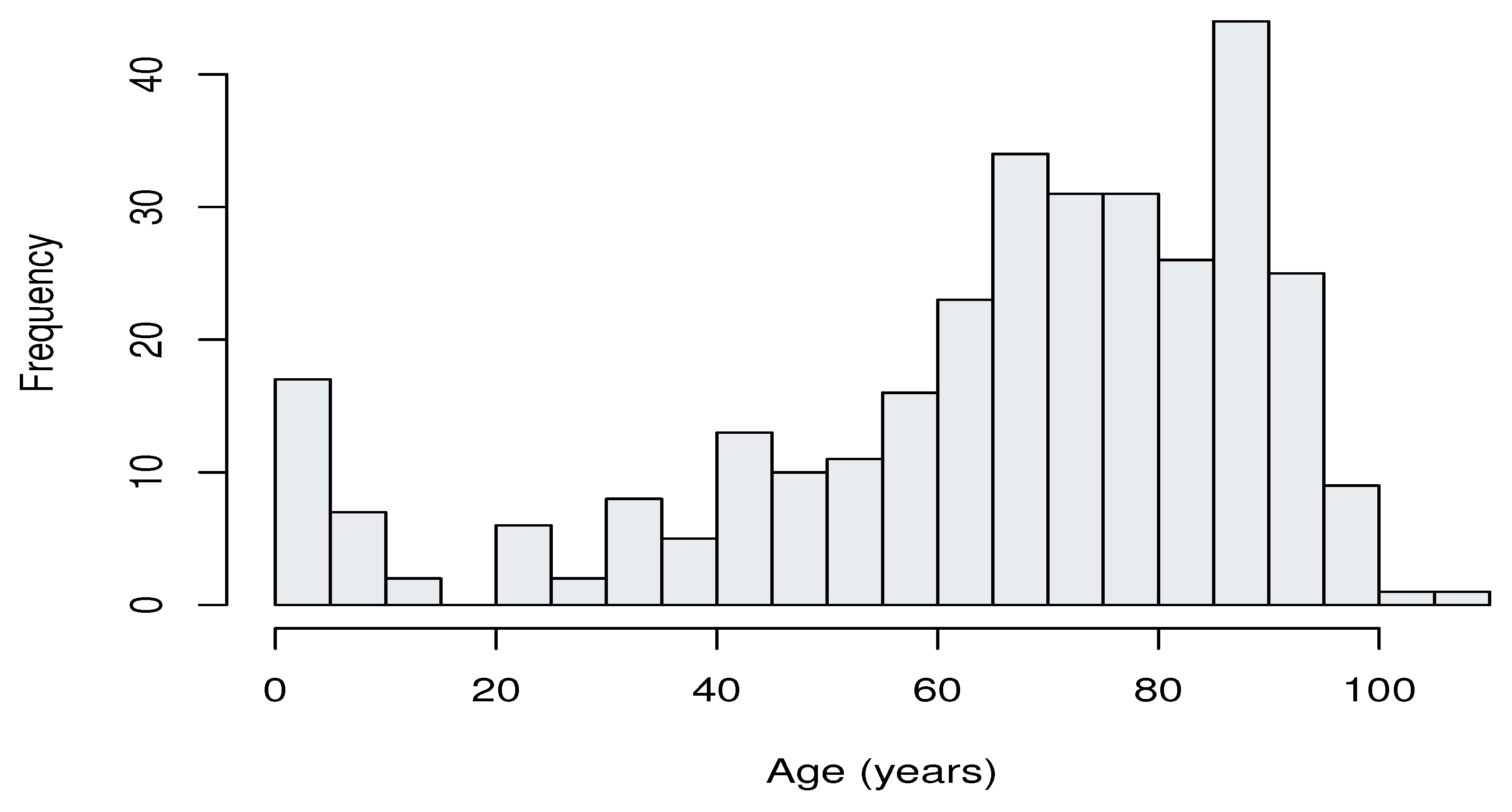{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}