1. Introduction
Computing the symmetric tridiagonal (ST) eigenvector is an important task in many research fields, such as the computational quantum physics [
1], mathematics [
2,
3], dynamics [
4], computational quantum chemistry [
5], etc. The ST eigenvector problem also arises while solving any symmetric eigenproblem because it is a common practice to reduce the generalized symmetric eigenproblems to an ST one.
The Divide and Conquer (DC) algorithm [
6] has a considerable advantage when calculating all the eigenpairs of an ST matrix. It is quite remarkable that the DC method, which is efficient for parallel computation, can also be faster than other implementations on a serial computer. However, this method does not support computing part eigenpairs or computing eigenvectors only. In practice, it is rare to compute the full eigenvectors of a large ST matrix. The famous QR method [
7] has the same shortage while costing more time and is hard to be parallelized. This paper focuses on modifying the solution of computing part eigenvectors and gives a new method for eigenvectors of good accuracy and orthogonality.
Once an accurate eigenvalue approximation is known, the Inverse Iteration method [
8] always computes an accurate eigenvector with an acceptable time cost. However, it does not guarantee the orthogonality when eigenvalues are close. A commonly used remedy is to reorthogonalize each approximate eigenvector, by the modified Gram–Schmidt method, against previously computed eigenvectors in the cluster. This remedy increases up to
operations if all the eigenvalues cluster, while the time cost for the eigenvectors themselves is only
.
Dhillion proposed the Multiple Relatively Robust Representations (MRRR) algorithm [
9] to avoid reorthogonalization. This is an ambitious attempt as the MRRR algorithm computes all the accurate and numerically orthogonal eigenvectors with a time cost of
. Nevertheless, the MRRR algorithm can fail in calculating severely clustered eigenvalues of a large group, such as the glued Wilkinson matrices [
10]. Dhillion fixed the problem and modified the MRRR method subtly and cleverly [
11], without increasing its time complexity. However, this modified MRRR method, which applies the perturbation to the root representation of the ST matrix, costs even more time than the Inverse Iteration method with the modified Gram–Schmidt process. Even when computing random matrices, the MRRR algorithm has no advantage compared with the Inverse Iteration method. In addition, when computing part eigenvectors, the MRRR algorithm needs considerably accurate eigenvalues to guarantee natural orthogonality and thus calls the time-consuming Bisection method to obtain them. As a consequence, except for those cases with many eigenvalues clusters, the Inverse Iteration method is more efficient. More related details are presented in
Section 6.
Mastronardi and Van Dooreen [
12] proposed an ingenious method to determine the accurate eigenvector of a symmetric tridiagonal matrix once an approximation of the eigenvalue is known. In addition, they applied this method to calculate the weights of the Gaussian quadrature rules [
3].
Our strategy is to improve the Inverse Iteration method with the three main modifications:
We replace the iteration process with a new one that only costs one step to guarantee convergence, similar to the MRRR method;
The envelope vector theory [
13] is utilized to compute accurate and naturally orthogonal eigenvectors when the eigenvalues severely cluster. By combining the new iteration process, the time cost is even less than the cost of calculating isolated eigenvectors. In other words, the severely clustered eigenvalues accelerate the convergence;
We give a new orthogonalization method for the generally clustered groups of severely clustered eigenvalues. For k clustered eigenvalues in such a case, the new orthogonalization method decreases the time cost from to .
The numerical results confirm our promise of accuracy and orthogonality. In addition, our new method supports computing part eigenvectors and embarrassingly parallelization, significantly improving the computational efficiency.
This paper focuses on the symmetric tridiagonal eigenvector problem. According to Weyl’s theorem, the real symmetric eigenvalue problem
is well posed, in an absolute sense because an eigenvalue can change by no more than the spectral norm of the change in the matrix
A [
14]. However, for an unsymmetric matrix
, some of its eigenvalues may be extremely sensitive to uncertainty in the matrix entries. Consequently, the assessment of error becomes a major concern. Some specific conclusions were introduced in [
14]. Readers can also see more unsymmetric examples in [
15,
16].
The organization of the rest of this paper is as follows:
Section 2 gives the modified iteration of the new method and an algorithm to compute an isolated eigenvector.
Section 3 studies the computation of clustered eigenvectors.
Section 4 introduces the general Q iteration and the new orthogonalization method.
Section 5 concerns the overflow and underflow. Several corresponding pseudocodes are provided in the above sections.
Section 6 shows some examples and numerical results. Finally, we discuss and assess the Modified Inverse Iteration method in
Section 7.
3. Computing Severely Clustered Eigenvectors
Now consider the case when eigenvalues clusters severely, for example, p eigenvalues that are equal in finite precision arithmetic. We will define “severely clustering” later in this section.
First, we introduce the two following lemmas from [
13] to state our theorems.
Lemma 1 (The Envelope Vector).
Define , and the envelope vector of is given byFor p clustered eigenvalues, the envelope vector will undulate with p high hills separated by low valleys.
Lemma 2. For an ST matrix A that has p clustered eigenvalues , divide A into p submatrices: , ,…, and . Note that these submatrices can have overlaps. Then, for each submatrix, there exists at least one , among all the possibilities of divisions that satisfies:
- 1
has an isolated sub-eigenvalue ;
- 2
For the 2nd to th submatrices, the corresponding sub-eigenvector (with respect to κ) has small components at both its ends. For , and for , .
Supplement zero components to obtain , , or , which has the size of . Then, the p ’s are approximations to . These eigenvector approximations are numerical orthogonal and satisfy .
See the proofs and more details in [
13].
Let us take a typical example of clustered eigenvalues to illustrate. Let
be a
vector and
and then construct
. Then, repeat
by eight times totally. Finally, we obtain a
vector
. Consider an ST matrix
, which has the diagonal equal to
and all the components on its sub-diagonal equal to 1.
is similar to the glued Wilkinson matrices in [
11] and its biggest eight eigenvalues (
) cluster severely. Let
denote the approximations of the biggest eight eigenvalues of
; it shows
in Matlab, i.e.,
severely clusters.
Let
and calculate
of
. The results are shown in
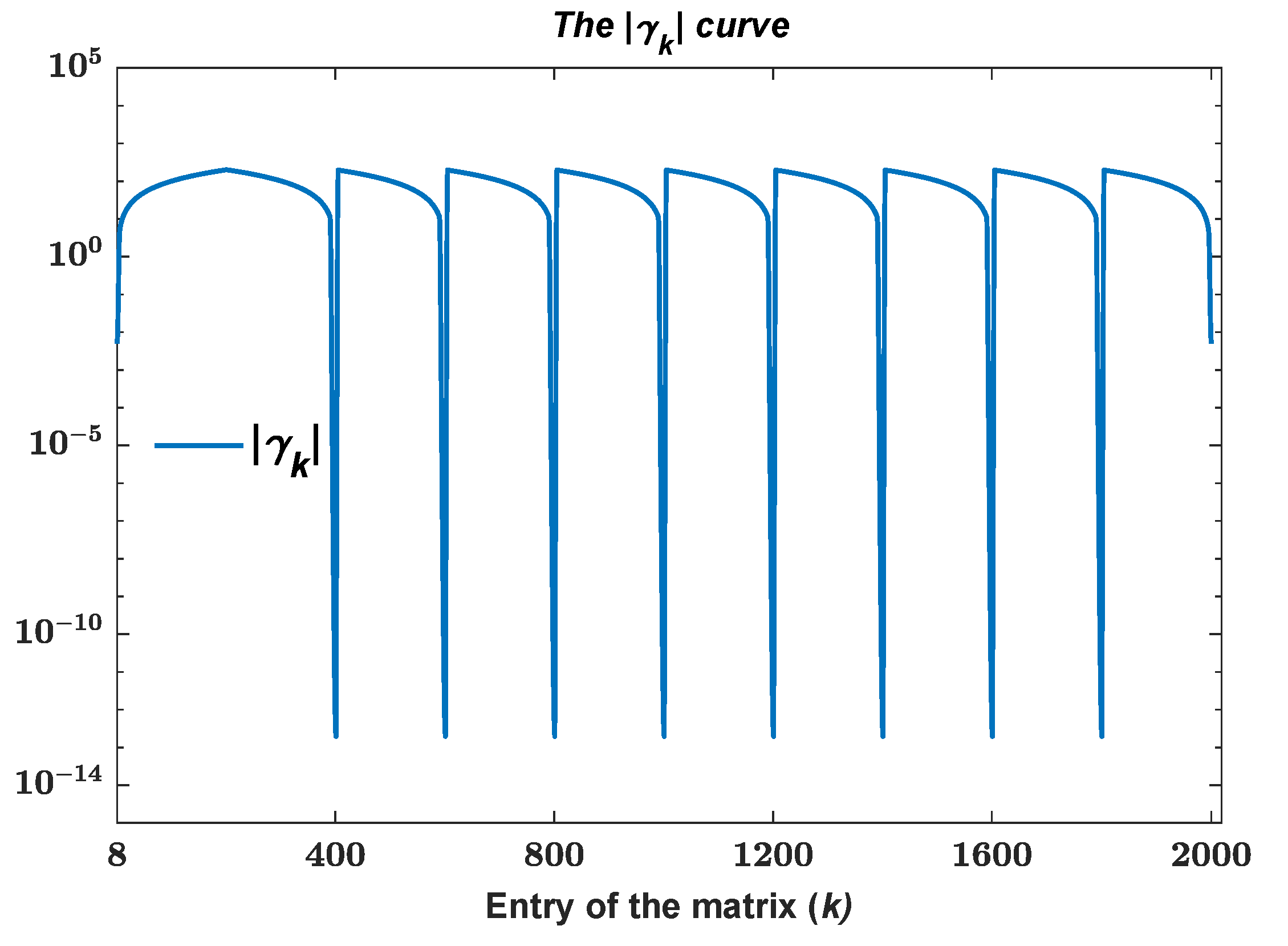
Figure 1. According to Lemma 1, the low valley entries of the envelope vector correspond to small components of
. Note that this means all the
p eigenvectors have small components at this entry, thus the corresponding
must be a big value according to (
4). The case of high hills is similar. In other words, the
curve undulates with
p low valleys separated by
high hills. Note these extreme points may not be exactly the same as the envelope vector. We show
of
in
Figure 1. A logarithmic scale on the
y-axis has been used to emphasize the small entries. The results confirm our point.
We give a method to find the applicable submatrices of Lemma 2 by Theorem 1.
Theorem 1. If a submatrix satisfies Lemma 2, then the corresponding entries contain and only contain one low valley of the curve.
Proof. Take the first submatrix (which is assumed to satisfy Lemma 2) as an example because the proofs of the others are similar.
Let X denote the eigenvector approximation from Lemma 2, and we have . Thus, the corresponding entries of must contain at least one low valley, if not all the ’s will be small values and violate the equation .
If the corresponding entries of
contain more than one low valley, say, two, it will also contain one high hill of the
curve. This means
X has a small component at the corresponding entry of the hill. In addition,
X contains at least two major ingredients of
that has big components at the two valleys, respectively, or
X contains one major ingredient of
that has big components at both entries. According to [
10], if an eigenvector has one part that has both small ends, the corresponding eigenvalue must have a close neighbor. Therefore, if the corresponding entries of
contain more than one low valley,
has clustered sub-eigenvalues that
.
With the above conclusions, the proof is completed. □
To illustrate Theorem 1 more intuitively, and as a complementary argument to the above proof, we performed the following numerical test. We calculated the distances between
of
and the last two sub-eigenvalues of
. Because by the Interlacing Property from [
17], the close sub-eigenvalues to
must be the last ones. The result is shown in
Figure 2. A logarithmic scale on the
y-axis has been used to emphasize the small entries. In
Figure 2,
starts to have one close eigenvalue when
, which is the first low valley of the
curve, and two close eigenvalues when
, which is the second valley. We also present the results of the last eight sub-eigenvalues of
in
Figure 3. It can be seen that, whenever
“crosses” a low valley of
, the clustered sub-eigenvalues are one more.
Figure 2 and
Figure 3 confirm Theorem 1 well. See more and detailed numerical examples and results for accuracy in
Section 6.
According to [
13], we have that (recall
is the envelope vector from Lemma 1)
where
V is independent of
j. This means that a big
corresponds to a small
.
Therefore, our computation strategy of clustered eigenvalues is shown as follows:
- 1.
Every submatrix has one low valley of the curve.
- 2.
The ends of the submatrix are the closest entries to the adjacent valleys.
- 3.
According to Lemma 2, ensures , thus it can be used as the “clustering” threshold.
We show the method for computing severely clustered eigenvalues by the following pseudocode Algorithm 2.
| Algorithm 2: Compute severely clustered eigenvalues. |
![Mathematics 10 03636 i002]() |
Assume that the p valleys are arranged uniformly. The cost calculation of p severely clustered ’s by Algorithm 2 is twice as large as the cost of one isolated by Algorithm 1, while the Inverse Iteration method needs p times cost and a reorthogonalization. This means that Algorithm 2 saves time compared to the Inverse Iteration method even when disregarding its expensive orthogonal cost.
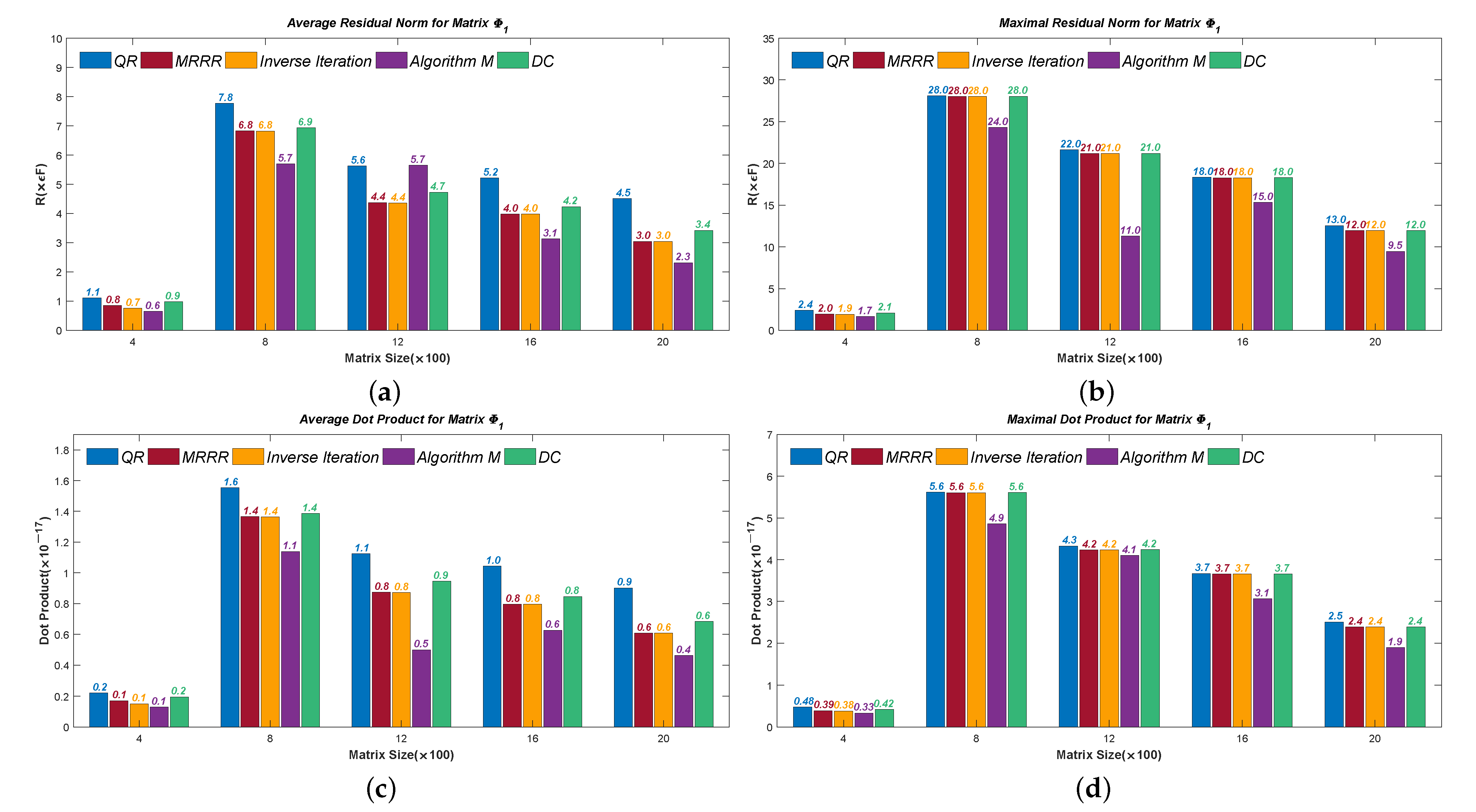
For the matrix
, we calculated
R’s (recall
, the residual norm) and the dot products of its last eight eigenvector approximations obtained by Algorithm 2. We show the mean and maximal results in
Table 1 and compare them to the results of the Inverse Iteration method and the MRRR method. The results were collected on an Intel Core i5-4590 3.3-GHz CPU and a 16-GB RAM machine. All codes were written in Matlab2017a and executed in IEEE double precision. The machine precision is
. It can be seen that all the eight eigenvector approximations are accurate and numerically orthogonal. See more examples and numerical results in
Section 6.
4. Reorthogonalization
4.1. General Q Iteration
For severely clustered eigenvalues, Algorithm 2 saves considerable time and avoids reorthogonalization. However, if the group of clustering p eigenvalues has a close eigenvalue neighbor or another group of clustering eigenvalues with the distance (note is the threshold of severely clustering), Algorithm 2 can not ensure the orthogonality between them. Therefore, a reorthogonalization is needed. This is quite frustrating, not only because of the high cost of orthogonalization but also because using the modified Gram–Schmidt method for orthogonalization destroys the orthogonality of the eigenvectors obtained by Algorithm 2. In other words, the method we proposed in the previous section is meaningless. For example, two groups of severely eigenvalues have approximations and , respectively, while . Each group’s eigenvectors are orthogonal, but Algorithm 2 can not ensure the orthogonality of two from different groups. If one uses the modified Gram–Schmidt method to reorthogonalize them, it makes no difference whether the original vectors are orthogonal in groups. Therefore, we give a new reorthogonalization method in this section.
In [
9], Dhillon introduced the twisted Q factorization. For an
ST matrix
(
is one eigenvalue of
A) and a certain number
, implement the Givens rotation to its columns to eliminated
th components on its super-diagonal and
th components on the sub-diagonal. Finally, a singleton in the
kth column is left. The process is shown in
Figure 4 (from [
9]), where
and
.
Let
W denote the final form of the twisted Q factorization, and we have
where
are Givens rotation matrices. Obviously,
. Therefore, at least one
k satisfies
according to
Section 2.3.
Now, we introduce our so-called general Q iteration. For such a
k that satisfies
, we implement the corresponding Givens rotations to the rows of
W. Using the example from
Figure 4, the process is shown by
where
and
constitutes
, i.e.,
Note that, in the last rotation of (
11), the components on
and
have not changed. We obtain their values according to symmetry.
Finally, we have
and complete one step of the general Q iteration. Obviously,
has the same eigenpairs to
A. As all
’s and
’s are less than 1, all the rest components of the
kth rows and columns of
are less than
. Therefore, deflation can arise as
Thus, B has the numerical equal eigenvalues to and the corresponding eigenvectors can be calculated similarly to the QR method. For example, if is the eigenvector of B with respect to , then . These ’s are certainly orthogonal. Note that B can be transferred to an ST matrix by chasing and eliminating its bulge (for example, the and (4, 2) components of B) with Givens rotations. Therefore, it costs at most 1.5 times operations compared to the QR (or QL) iteration, which is the exceptional case when or 1.
Therefore, the general Q iteration is to fulfill a deflation of a certain
by QR-like transformation. For a normal ST matrix and one accurate approximation to
,
or
n is enough. Thus, the cost of chasing the bulge can be saved. However, in some special cases,
or
can both be small, which means it costs numerous QR-like iterations to converge. This is similar to the solution of (
2) by inverse iterations, considering the strong relationship between the Inverse Iteration method and the QR (or QL) method [
7]. Recall that we give the one-step inverse iteration in
Section 2, and the general Q iteration can be regarded as a one-step QR-like iteration. In our numerical experience, the case that several QR iterations (which use an accurate eigenvalue approximation as the shift) can not obtain convergence is not rare. For example, for a random
ST matrix, its most
’s can ensure one-step converges by QR iteration, but some
’s may cost more than 50 steps. In addition, this case almost arises in every random matrix.
Mastronardi and Van Dooreen discovered this instability when obtaining an ST eigenvector and solved the problem by a modified implicit QR decomposition method [
12]. Their method can ensure an accurate calculation. However, this paper uses a modified inverse iteration method to calculate the eigenvector. The implicit QR decomposition in our paper is used for deflation and guarantee of orthogonality in the case that the eigenvalues cluster generally.
The corresponding pseudocode for computing generally clustered eigenvectors is given in Algorithm 3. The generally clustering denotes that the span of the
p clustered eigenvalues is not big enough to guarantee orthogonality of its corresponding eigenvectors (calculated by the Inverse Iteration method or Algorithms 1 and 2), i.e.,
.
| Algorithm 3: Computing generally clustered eigenvectors. |
![Mathematics 10 03636 i003]() |
4.2. Cost of Reorthogonalization
This subsection concerns the cost of reorthogonalization in Algorithm 3. For
k clustered eigenvalues, the last obtained
v (line 7 in Algorithm 3) is a
vector.
v has to be premultiplied
Givens rotation matrices to transfer to
. Repeat this process until the length reaches
n. For every Givens rotation, the cost is six operations. Therefore, the total cost is
At first sight, (
12) is hardly satisfactory, as the modified Gram–Schmidt method costs only
operations. Only when
k is close to
n, our method matches the efficiency of the modified Gram–Schmidt method. Moreover, those cases where we need to use the general Q iteration (the QR-like iterations cannot converge at one step) have not been considered. However, the cost will slump for cases with many severely clustered eigenvalues within groups.
For example, if
m eigenvalues are severely clustered among the
k eigenvalues, the cost is
which decreases from
to
if
m is close to
k. In addition, the cost for the modified Gram–Schmidt method, in this case, is
.
If the
k eigenvalues can be divided into two severely clustering groups, the cost is
which decreases from
to
. In addition, the cost for the modified Gram–Schmidt method, in this case, is
.
Therefore, Algorithm 3 calls the deflation method with the general Q iteration or the modified Gram–Schmidt method according to an advanced prediction by (
12)–(
14). However, both methods are time-consuming in cases where
k is very close to
n, and the eigenvalues have few severely clustering groups. In this case, the best method is the MRRR method. See more examples and numerical details in
Section 6.
4.3. Modification of QR-Like Iteration
The general Q iteration can be seen as starting a QL iteration from the left of the matrix, stopping it at column k, and then doing a QR iteration from the right of the matrix till there is a singleton in the kth column. We give a subtle modification to the QR or QL iteration with the implicit shift to save some operations. Take the QR iteration as an example, and the traditional process is shown in Algorithm 4.
One step of QR iteration implemented into a
ST matrix is shown as follows:
| Algorithm 4: QR iteration with the implicit shift. |
![Mathematics 10 03636 i004]() |
In (
15),
is updated by
, which corresponds to line 10 in Algorithm 4. This equation can be rewritten as
Without loss of generality, assume that
, then
(recall
is the Sturm sequence from (
8)). Finally, we have
Note all the
’s have been calculated in advance when searching the smallest
in our methods; thus, we can use (
16) to update
’s instead. We show the modified QR iteration algorithm in Algorithm 5.
Algorithm 5 costs
multiplications,
divisions, and
square roots while Algorithm 4 costs
multiplications,
divisions, and
square roots. Thus, our modification saves
multiplications.
| Algorithm 5: Modified QR iteration with the implicit shift. |
![Mathematics 10 03636 i005]() |
5. Avoiding Overflow and Underflow
Our new method obtains an eigenvector essentially by the cumulative products of q’s, as shown in lines 9 and 12 of Algorithm 1. As is well known, the products can grow or decay rapidly; hence, the recurrences to compute them are susceptible to severe overflow and underflow problems. This section gives a relatively cheap algorithm to avoid overflow and underflow.
Let f denotes the overflow threshold, for example, in IEEE double precision arithmetic. Whenever one intermediate product during the recurrences exceeds f, multiply it by to normalize and continue the iteration. Similarly, whenever one , multiply it by f. At the same time, we save the corresponding entry and mark 1 for overflow and for underflow.
Assume y positions, which divide the eigenvector approximation into parts, are marked when the iteration is completed. Then, we have a vector Y, with components of 1’s and ’s. For any certain position, the mark 1 means the components of from it to the end are shrunk by a factor of f compared to v. In addition, the mark means amplification by f. The mark before the first component of is zero. Thus, we have .
Calculate the cumulative sums of Y from the first component to everyone and save the results at each entry. In this way, each component of Y corresponds to each part of , and its value represents the specific degree to which the corresponding part has been enlarged or reduced. A positive value of m means that this part has been reduced by times, while a negative value means enlarged. The corresponding part is not enlarged or reduced when the value is zero.
Revisiting , all the components have not overflowed but are just to be restored to their true values. In addition, the biggest part after restoration corresponds to the biggest component of Y (recall each component of Y corresponds to each part of ) because it is reduced by the most significant times. Since is ultimately normalized, we take the biggest part as the benchmark. Thus, the second biggest component of Y corresponds to the second biggest part of after restoration, which should be divided by f. The rest parts, if they exist, need to be divided by or more, thus directly taking zeros as its components.
We give the corresponding pseudocode in Algorithm 6, which corresponds to the details of lines 9 and 12 of Algorithm 1.
| Algorithm 6: Compute without overflow and underflow. |
![Mathematics 10 03636 i006]() |
Finally, we give the complete modified Inverse Iteration method by Algorithm 7.
| Algorithm 7: Modified Inverse Iteration method. |
![Mathematics 10 03636 i007]() |
6. Numerical Results
In this section, we present a numerical comparison among the modified Inverse Iteration method and four other widely used algorithms for computing eigenvectors:
- 1.
the Inverse Iteration method, by calling subroutine “dstein” from LAPACK in Matlab;
- 2.
the MRRR method, by calling subroutine “dstegr” from LAPACK in Matlab;
- 3.
the QR method, by calling subroutine “dsteqr” from LAPACK in Matlab;
- 4.
the DC method, by calling subroutine “dstedc” from LAPACK in Matlab.
Since the MRRR, QR, and DC methods compute the eigenpairs instead of only eigenvectors, we compared the total cost for eigenpairs in this section. To obtain eigenvalues for Algorithm 7 and the Inverse Iteration method, we use the PWK version of the QR method (by calling subroutine ‘dsterf’ from LAPACK in Matlab) when calculating more than eigenpairs, otherwise use the Bisection method (by calling subroutine ‘dstebz’ from LAPACK in Matlab). Note the QR and DC methods are only available when computing all the eigenpairs and thus will not be compared in the cases when computing parts of the eigenpairs.
We use the following five types of matrices for tests:
- 1.
Matrix
, which is constructed similarly to
in
Section 3 with
(1:200). We change the repeat times of
to adjust the size of Matrix
. Note this matrix has many groups of clustered eigenvalues (severely and generally clusterings both exist) and has overflow issues if calculated directly.
- 2.
Matrix , which is constructed similarly to with (1:80). This matrix also has many groups of clustered eigenvalues (severely and generally clusterings both exist) but has no overflow issue if calculated directly.
- 3.
Matrix , the famous Wilkinson matrix, which has the ith diagonal component equal to (n is odd) and all off-diagonal components equal to 1. All its eigenvalues severely cluster in pairs.
- 4.
Matrix , another form of the Wilkinson matrix, which has the ith () diagonal component equal to (n is odd), the ith () diagonal component equal to and all off-diagonal components equal to 1. Its eigenvalues do not cluster if the size is less than 2000.
- 5.
Random Matrix with both diagonal and off-diagonal elements being uniformly distributed random numbers in [−1, 1]. Note that all the Random Matrix results in this section are mean data of 20 times tests.
The results were collected on an Intel Core i5-4590 3.3-GHz CPU and 16-GB RAM machine. All codes were written in Matlab2017a and executed in IEEE double precision. The machine precision is .
6.1. Accuracy Test
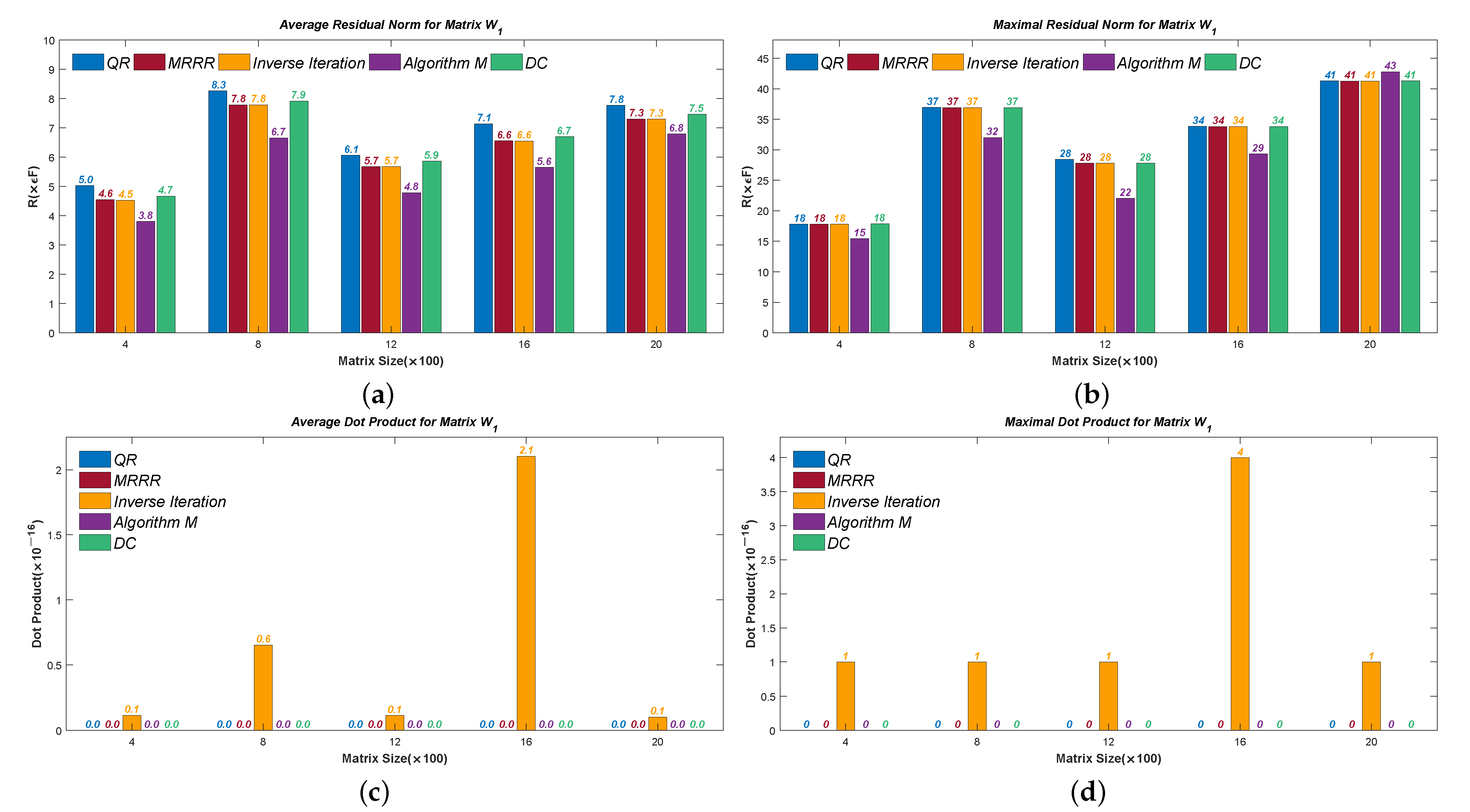
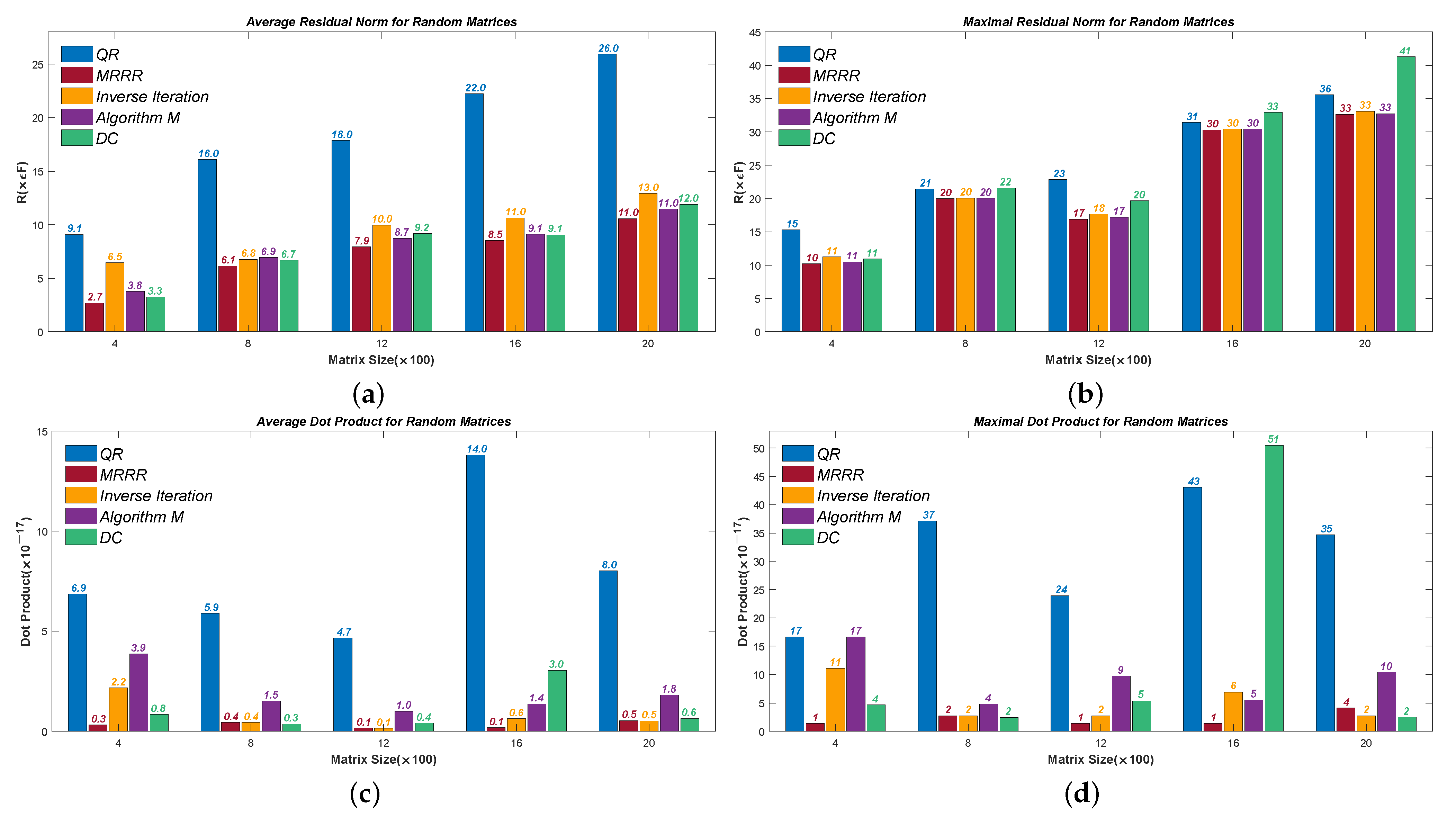
Figure 5,
Figure 6,
Figure 7,
Figure 8 and
Figure 9 present the results of the residual norms, i.e.,
, where the Average Errors denote the means of
R’s of all the calculated eigenvectors and the Maximal Errors denote the maximum. The results of dot products of the calculated eigenvectors are also presented to show orthogonality. Different sizes are used in our test, from
to
. We denote the corresponding 2-norm of the tested matrix, for example,
in
Figure 5. The results confirm that Algorithm 7 computes accurate and numerical orthogonal eigenvectors.
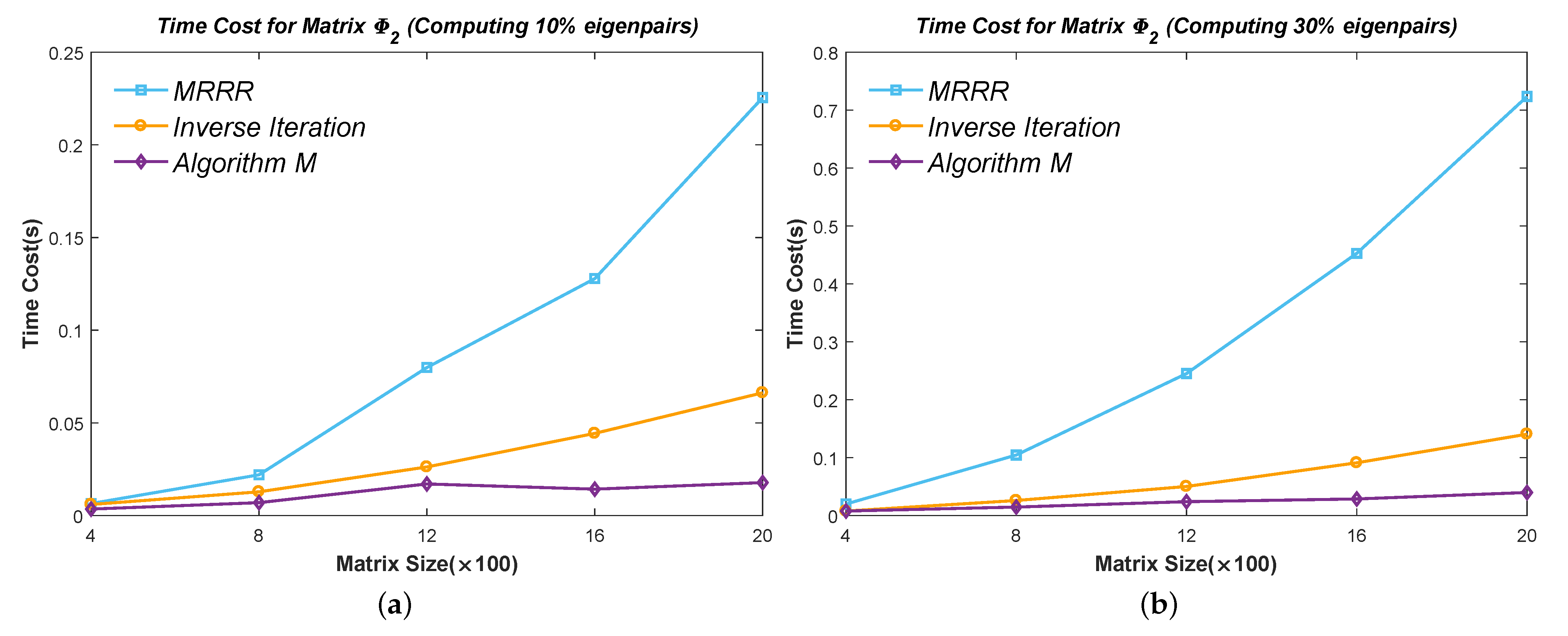
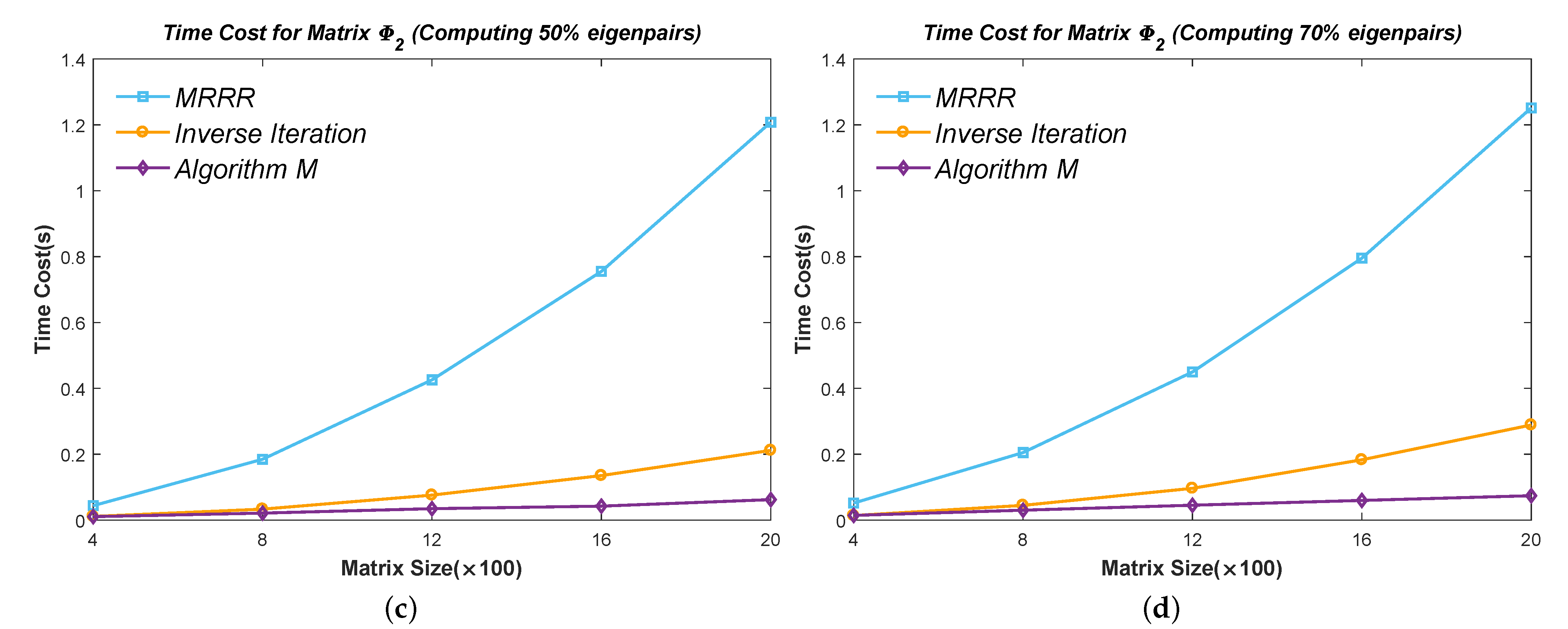
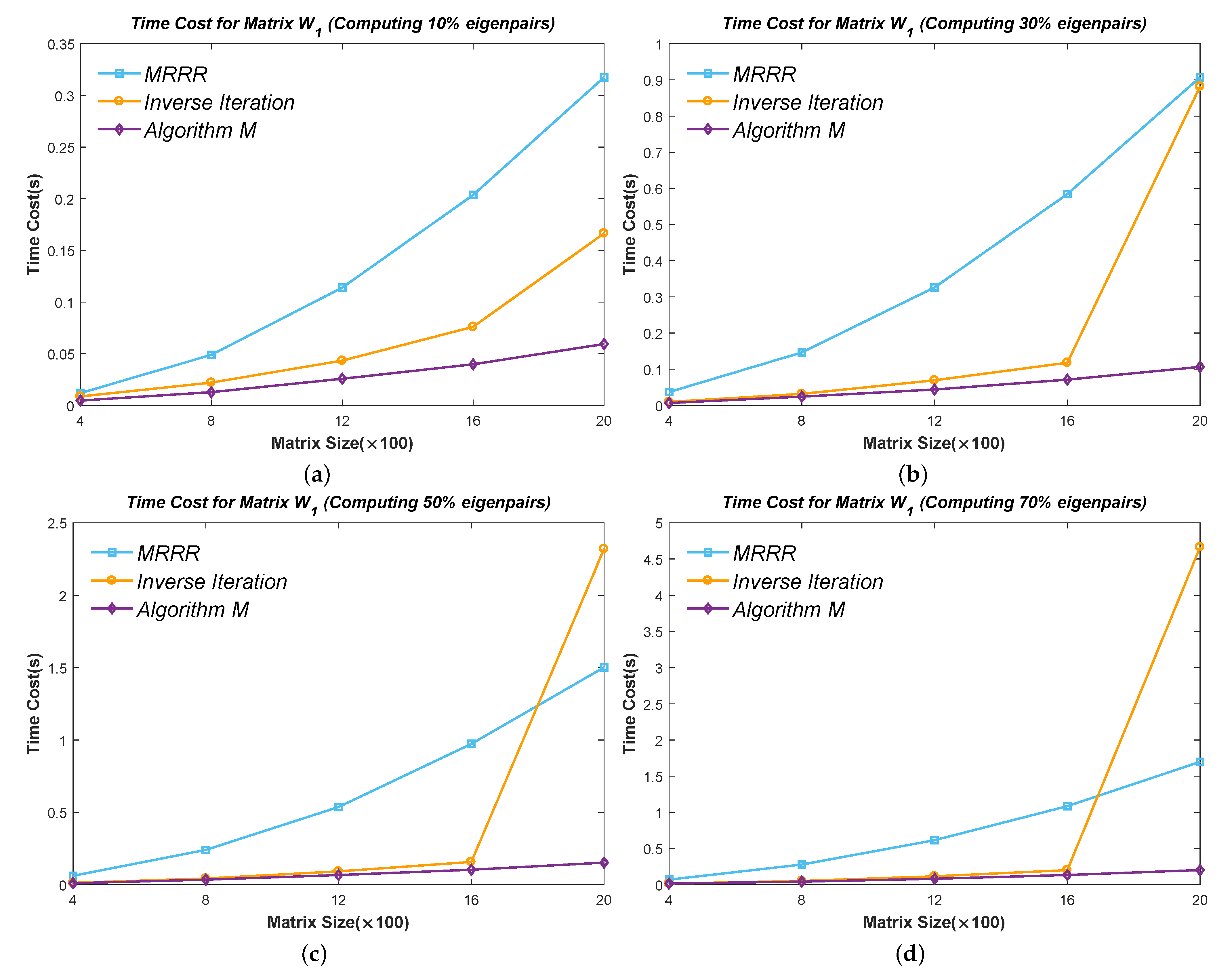
6.2. Efficiency Test of Part Eigenpairs
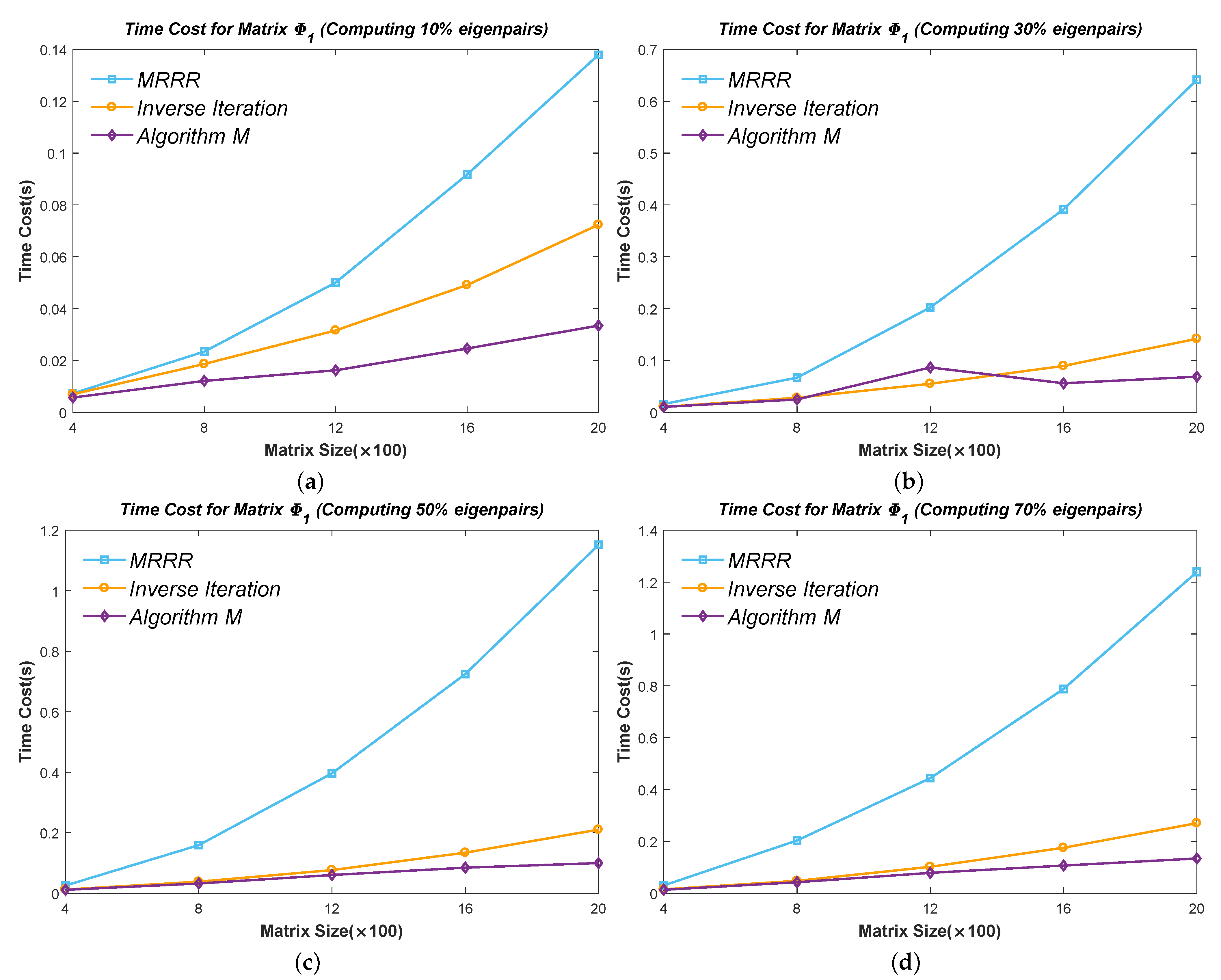
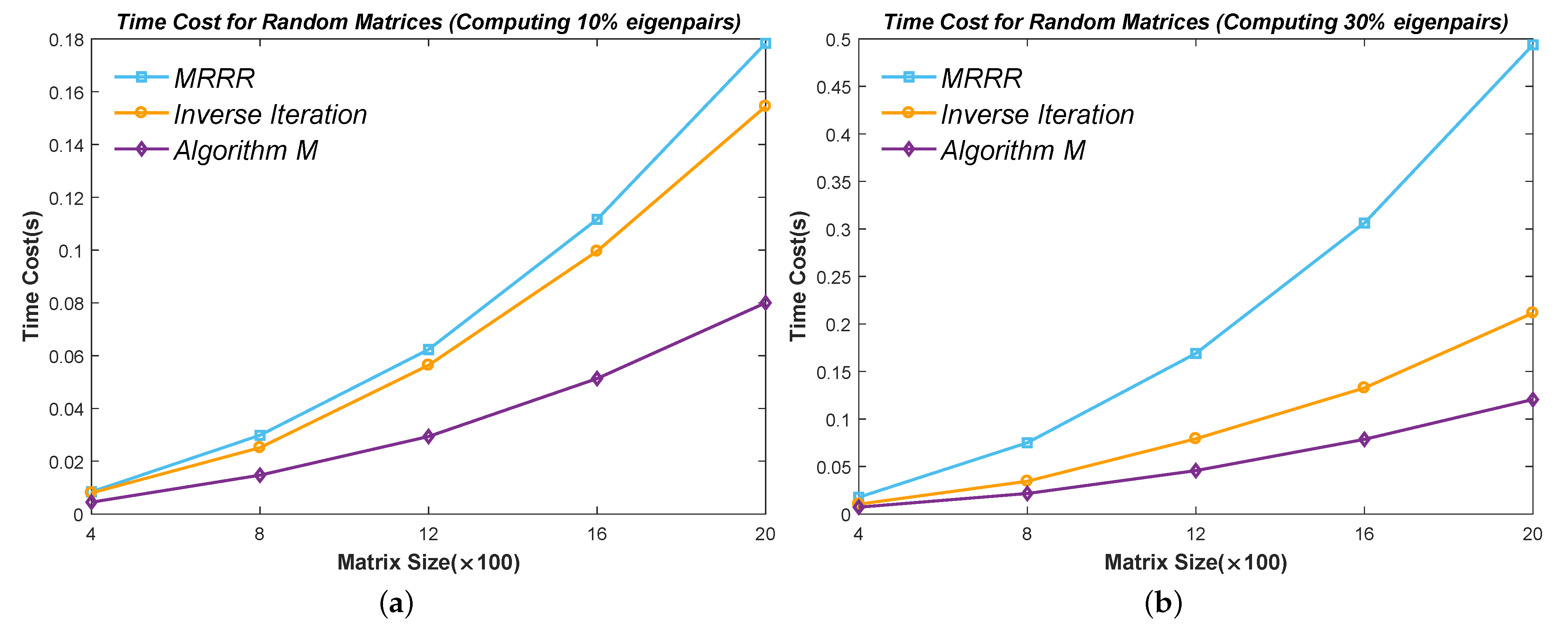
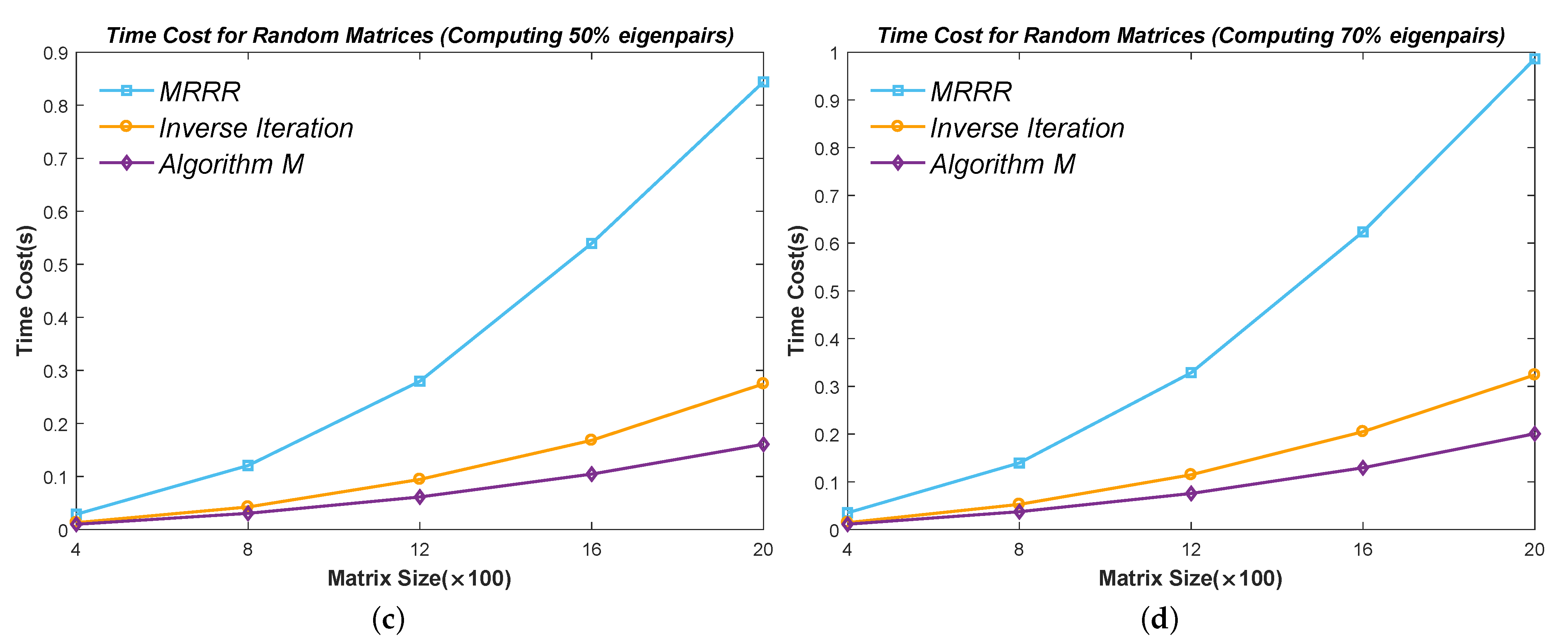
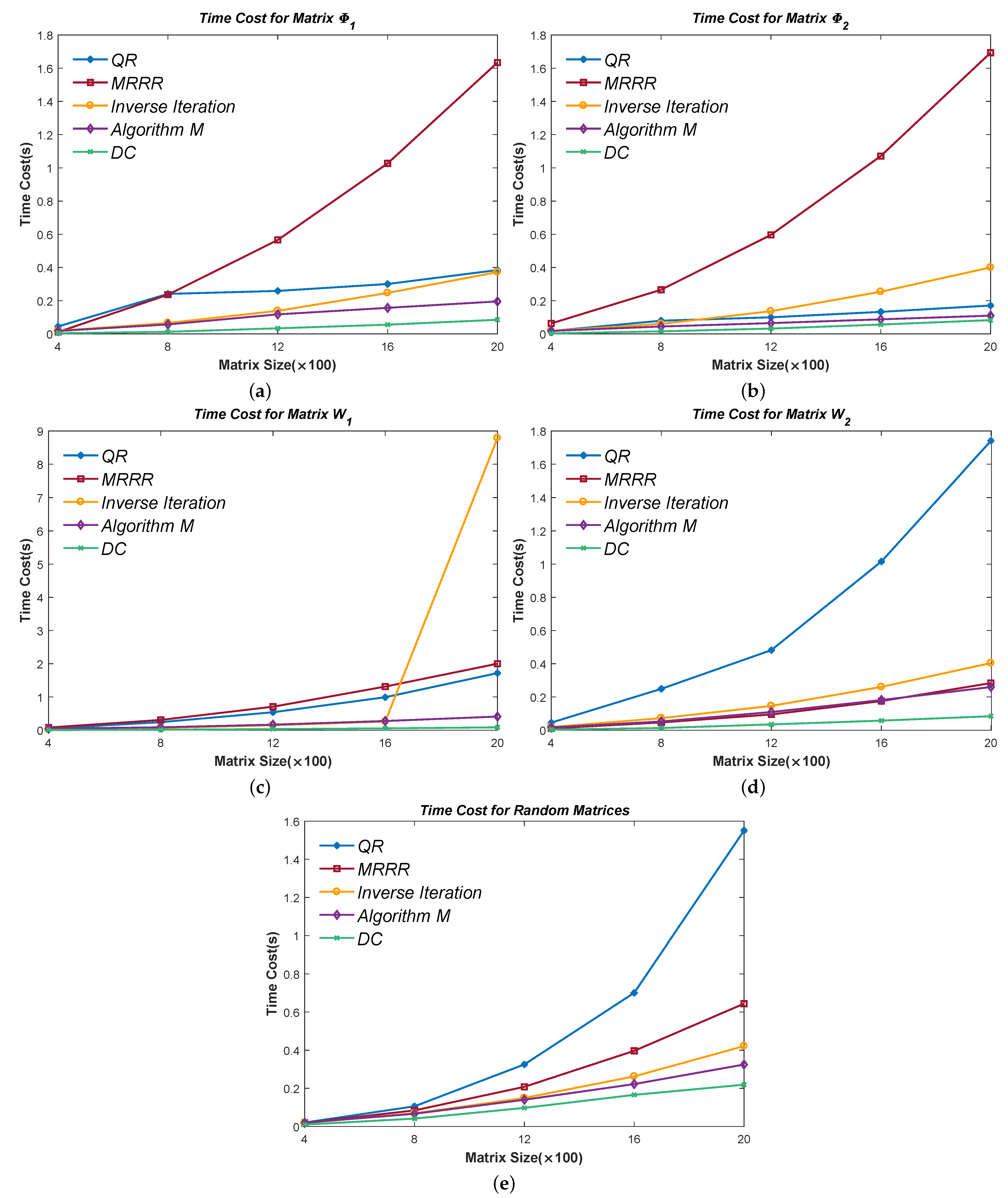
Figure 10,
Figure 11,
Figure 12,
Figure 13 and
Figure 14 show the time cost for computing
,
,
, and
eigenpairs of the above five types of matrices in each size. Note the cost of the Inverse Iteration method surges in
Figure 12 because the eigenvalues start to cluster and need an expensive reorthogonalization by the modified Gram–Schmidt method as the size of Matrix
rises. The MRRR method costs the most in every matrix because it needs more accurate eigenvalues and calls the Bisection method, while the Inverse Iteration and Algorithm 7 call the PWK version of the QR method to obtain all eigenvalues. Finally, the results show that the modified Inverse Iteration method always costs the least time and has a surpassing efficiency when eigenvalues severely cluster, which confirms our points in
Section 3.
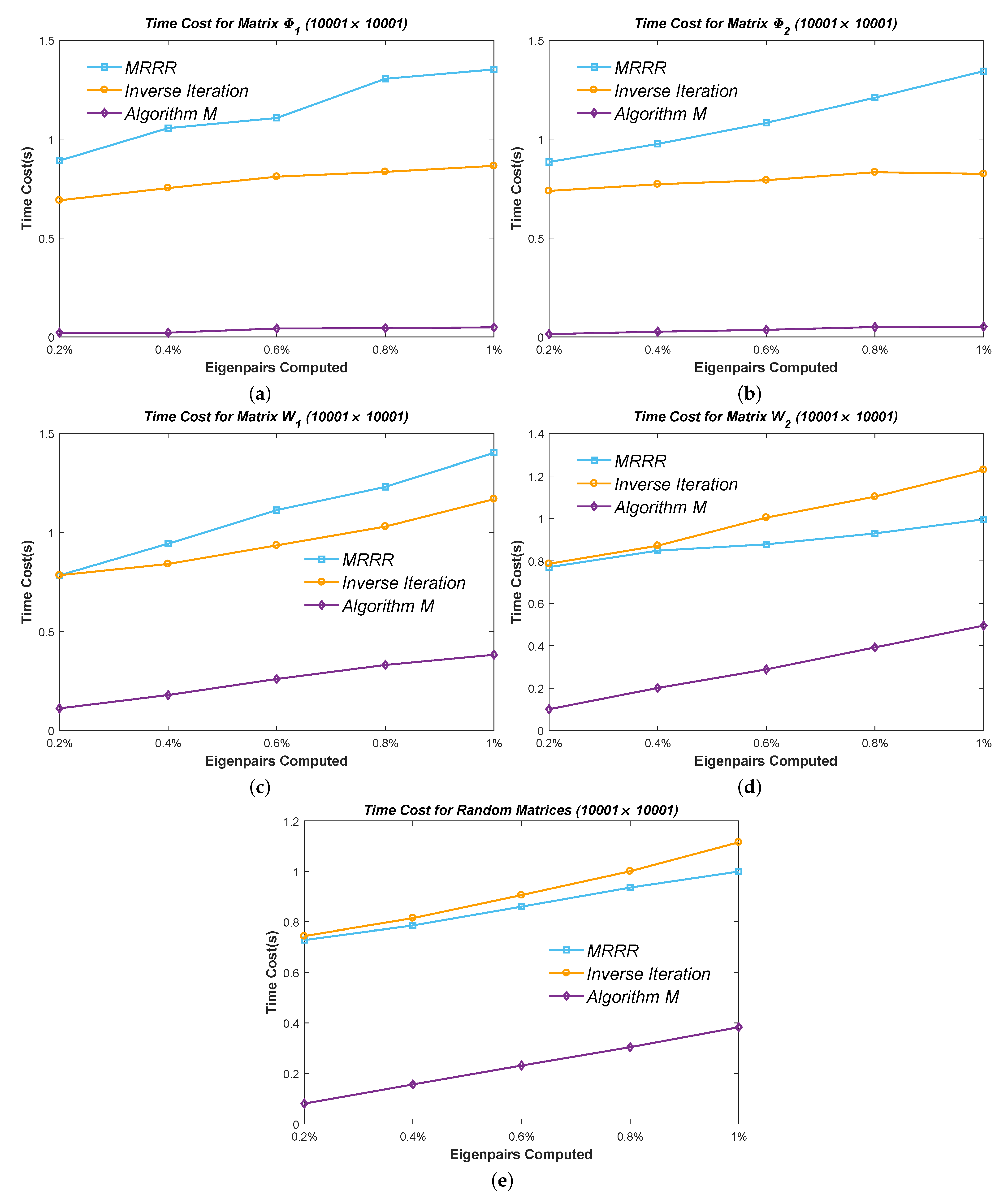
6.3. Efficiency Test of Minor Eigenpairs
When it comes to a minor set of eigenpairs, it is inadvisable to calculate all the eigenvalues by the PWK version of the QR method for the Inverse Iteration and Algorithm 7. We use the Bisection method instead, similar to the MRRR algorithm. Thus, the result is more convictive in this case because all the methods obtain the eigenvalues at an identical cost.
We calculated
,
,
,
, and
eigenpairs of the above five types of matrices and used two sizes:
and
. The results are presented in
Figure 15 and
Figure 16. It can be seen that the cost of the MRRR method is close to the Inverse Iteration method when computing clustered eigenpairs but higher in other cases. Once again, the modified Inverse Iteration prevails in all cases.
6.4. Efficiency Test of All Eigenpairs
As discussed in previous sections, Algorithm 7 is not suitable for computing all the eigenvectors because the DC method has a significant advantage in this case. Nevertheless, we also performed the corresponding test and show the results in
Figure 17. It can be seen in
Figure 17b,c that the modified Inverse Iteration method has a close time cost to the DC method. The efficiency increase comes from the computation process for severely clustered eigenvectors, which is recurrent in Matrix
and
. The acceleration is not that distinct in
Figure 17a (where many eigenvectors also cluster severely) because it takes extra operations to avoid overflows and underflows in Matrix
, which will not arise in Matrix
. However, the DC method is still recommended when computing all the eigenpairs.
6.5. Comparing with Mastronardi’s Method
Mastronardi [
3,
12] developed a procedure for computing an eigenvector of a symmetric tridiagonal matrix once its associate eigenvalue is known and gave the corresponding Matlab codes in [
12].
We tested the Matlab routine, collected the residual norm errors (denoted by
R), dot product errors, and time cost on the test matrices, and compared them with our new method. The results are shown in
Table 2. Note that Mastronardi’s method is for one ST eigenvector; thus, we calculated the maximal eigenpairs of the test matrices. All the matrices in
Table 2 have a size of 2001. The residual norm data have been scaled by the product of the machine precision and the 2-norm of the tested matrix.
Table 2 shows that Mastronardi’s method can provide a better result in Matrix
when considering orthogonality. However, Algorithm 7 has a significant advantage in time cost. In addition, Mastronardi seems unstable when computing the eigenvector (corresponding to the maximal eigenvalue) of Matrix
and
: the Matlab routine provided in [
12] failed to converge. The instability also arises in computing some eigenvectors of the random matrices. As a consequence, we did not present the corresponding results of Matrix
and
in
Table 2.
The test for calculating all eigenvectors stuck because of the instability too. However, the time cost of Mastronardi’s method is easy to conclude to be much more expensive than Algorithm 7, as the costs for one eigenvector have such a significant difference as shown in
Table 2. In addition, Mastronardi’s method is unsuitable for computing all the eigenvectors, as the deflation process costs
operations [
12] while it could not benefit from the sub-diagonal “zero”s like the traditional QR method.
7. Discussion
Algorithm 7 is a modified version of the MRRR, certainly of the Inverse Iteration method essentially, as the MRRR method implements inverse iterations in bidiagonal forms. The key improvements are:
- 1.
the one-step iteration method with Algorithm 6 to avoid overflow and underflow. Although the MRRR method uses another version of one-step iteration, the accompanying operations of square and square root slow down the routine.
- 2.
computing severely eigenvectors by the envelope vector theory. The severely clustering eigenvalues, which make the cost of the MRRR and Inverse Iteration method surge, bring a significant acceleration, on the contrary, for our new method. The scheme of the MRRR method for clustered eigenvalues is ingenious with time complexity of , but costs too many operations when searching the so-called “Relatively Robust Representation”. In terms of results, it is even the slowest when severely clustering eigenvalues arise.
- 3.
the novel reorthogonalization method. Dhillion also tried the envelope vectors when the MRRR method was stuck by the glued Wilkinson Matrices [
11] but gave up because of the general clustering of severely clustered groups. This paper solves the problem by the general Q iteration. Note we also accelerate the QR-like iteration itself by Algorithm 5.
The results in
Section 6 show that the modified Inverse Iteration method is suitable for computing part eigenpairs, especially the severely clustered ones. When computing a minor set, our new method is significantly faster. As the computations for every eigenpair are independent, our new method is flexible in calculating in any given order. However, when eigenvalues generally cluster without severely clustering groups, one should use the MRRR method. In addition, the DC method is absolutely the champion for computing all the eigenpairs in almost every type of matrix. Nevertheless, considering it is rare to calculate all the eigenpairs of a large matrix in practice, this paper provides a novel, practical, flexible, and fast method.
Algorithm 7 can be divided into roughly three steps: finding the smallest ; computing the isolated or clustered eigenvectors; reorthogonalizing by premultiplying Givens’ rotation matrices. The consumption of the other calculation parts is not comparable to these three steps. Note that all these main steps can be implemented in parallel. Therefore, Algorithm 7 is suitable for parallel computation. We will focus on the parallel version of the modified Inverse Iteration method in our future research work.






























{kind=link}
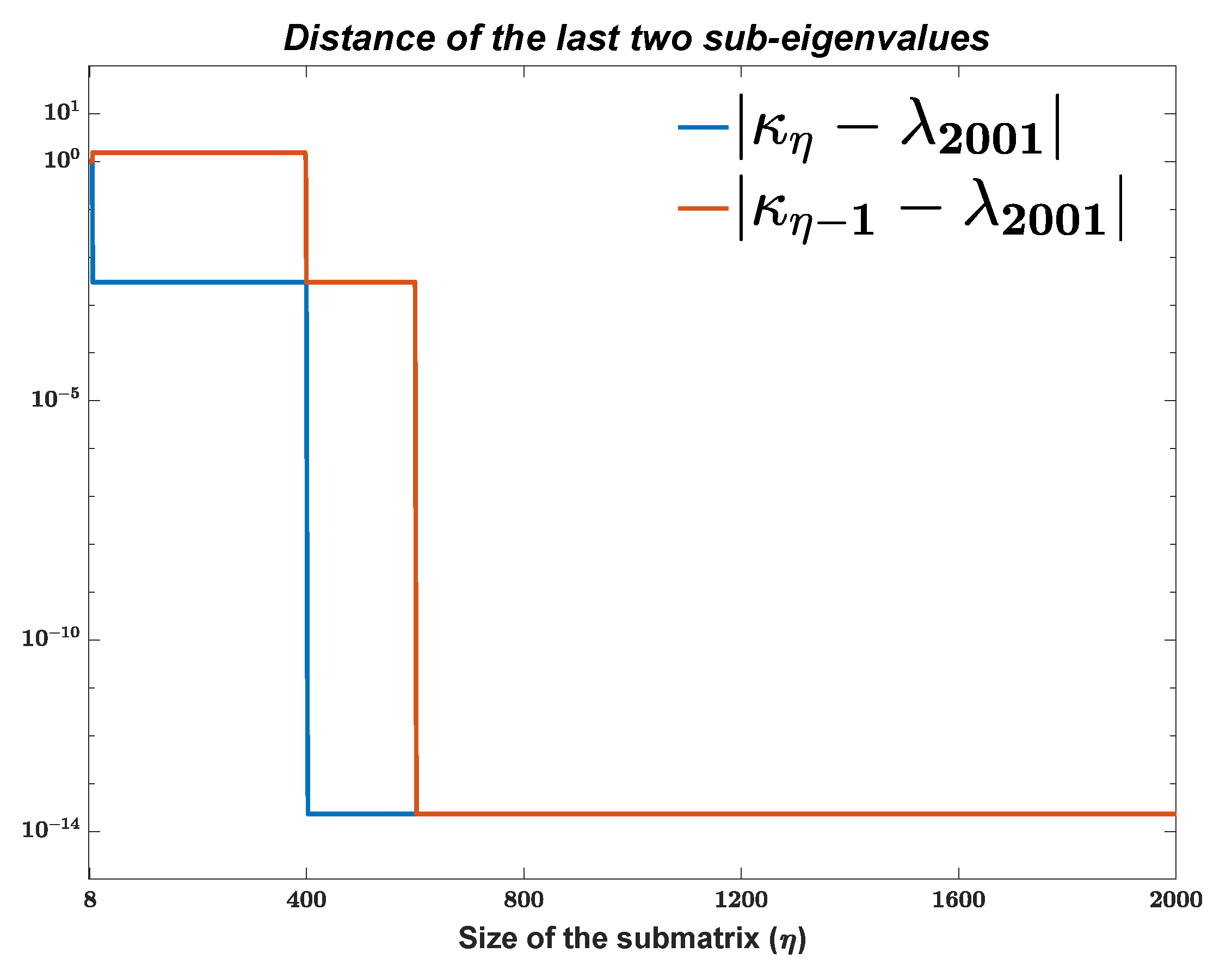{kind=link}
{kind=link}
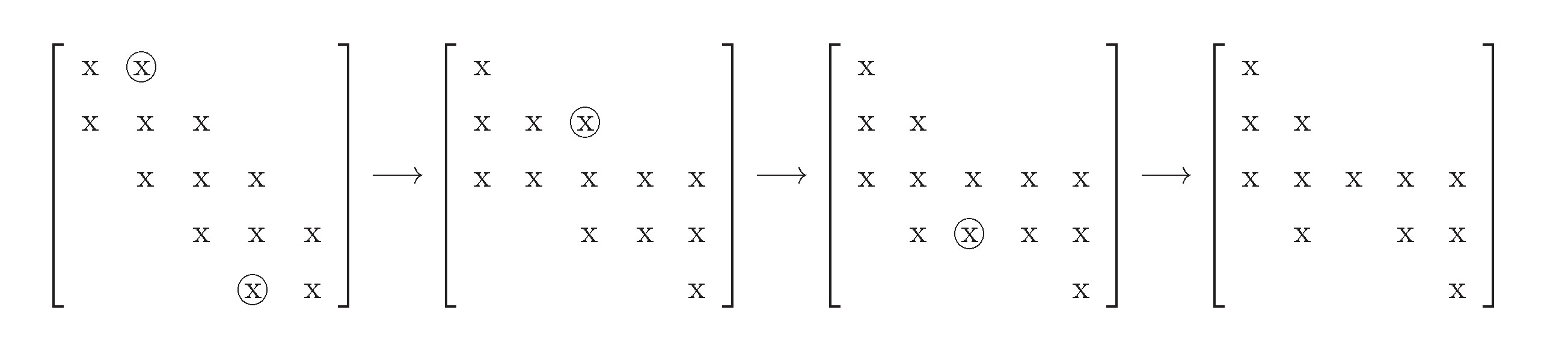{kind=link}
{kind=link}
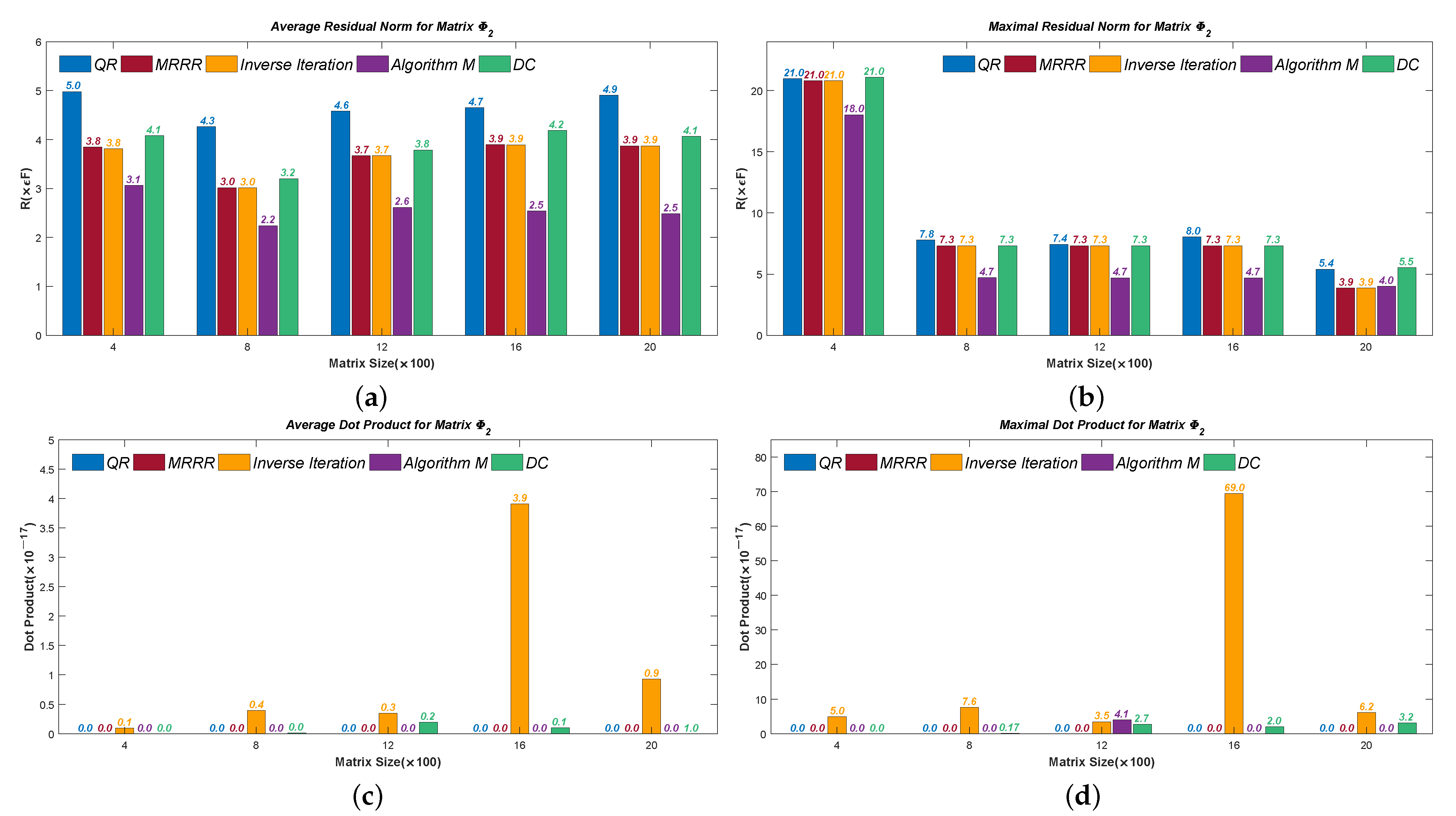{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
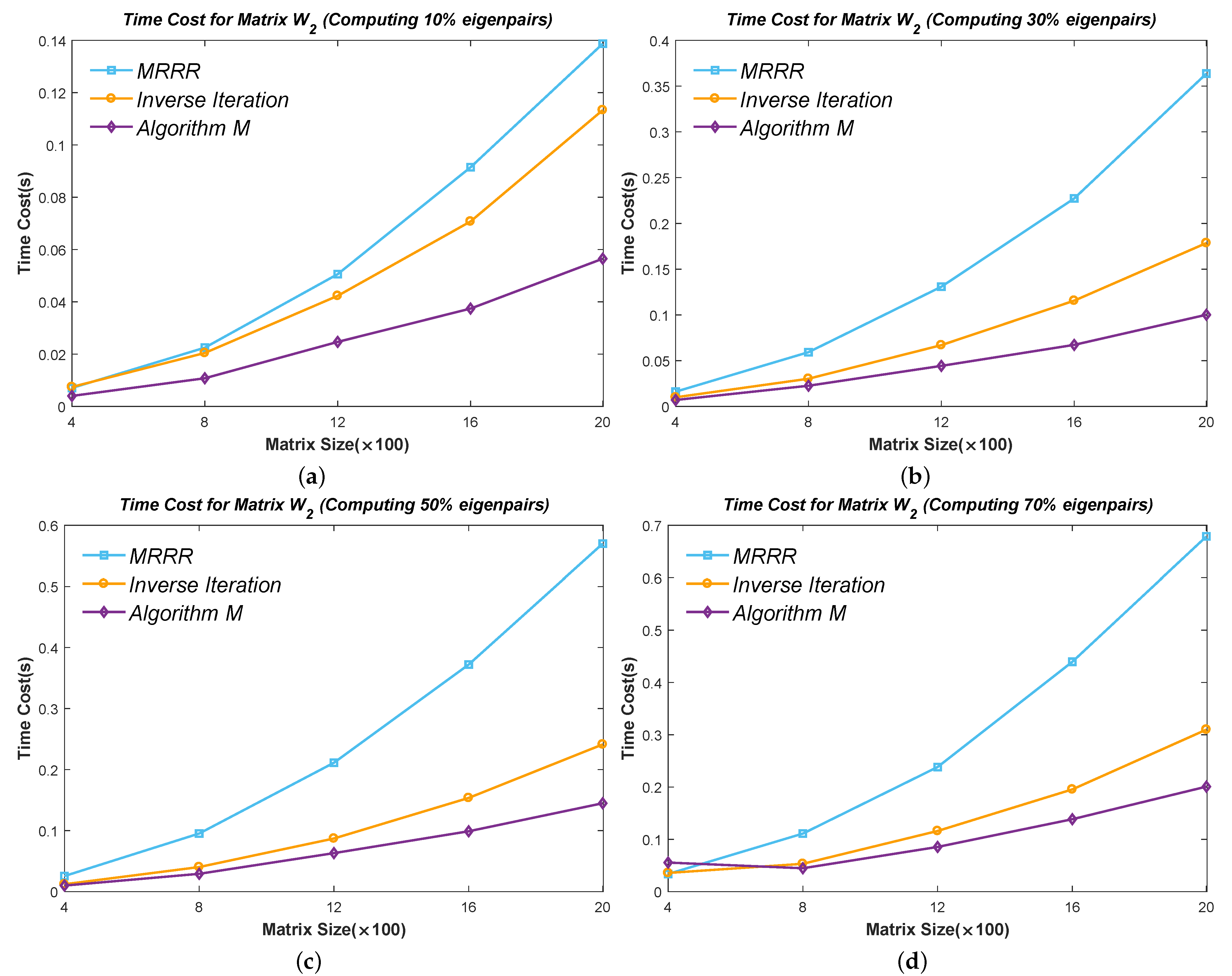{kind=link}
{kind=link}
{kind=link}
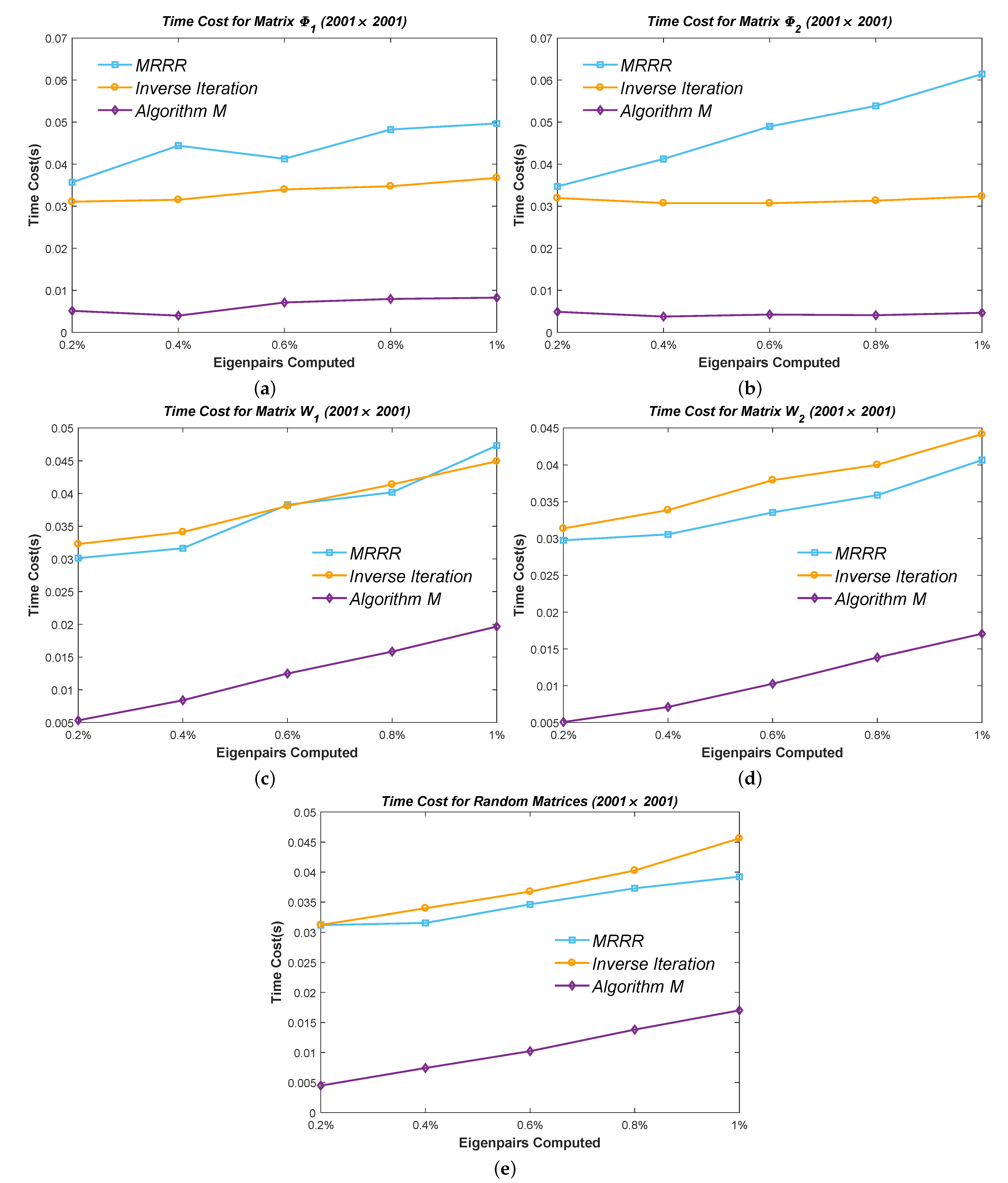{kind=link}
{kind=link}
{kind=link}