1. Introduction
Machine learning is becoming more and more common in statistical modeling and data analysis, along with the increasing concerns about the privacy disclosure of data. Therefore, we urgently need to develop algorithms which can provide privacy protection for personal data. In turn, the demand for data privacy protection has stimulated the establishment of formal standards on data privacy and the development of privacy framework. Among them, differential privacy (DP) [
1,
2] is the most widely discussed and developed technique in theory [
3,
4,
5,
6], and the feasibility of adopting these theories is shown among others by [
7,
8,
9]. The framework of DP makes it convenient for us to construct privacy protection algorithms. However, these privacy protection algorithms may also need to pay a price of sacrificing the rate of convergence in statistical accuracy. Therefore, we need to develop differential privacy distributed learning algorithms that do not sacrifice statistical accuracy as much as possible for large-scale distributed data.
Distributed machine learning can disassemble the original huge training task into multiple sub-tasks, that is, transforming large-scale learning that one machine can not afford during collaborative learning with multiple machines. Recently, ref. [
10] gave a sparse distributed learning solution for high-dimensional problems; ref. [
11] proposed a distributed learning algorithm which segments features in a high-dimensional sparse additive model and proved the consistency of the sparse patterns for each additive component; ref. [
12] provided a more flexible framework using the communication-efficient surrogate likelihood (CSL) procedure, which can solve different settings such as
M-estimation for low- and high-dimensional problems and Bayesian inference. Ref. [
13] extended the CSL method to distributed quantile regression and then established some statistical properties under quantile loss, which does not satisfy the smoothness condition of CSL method. In distributed learning, each sub-task is executed separately on an independent machine. It allows each machine to complete a collective learning objective, which is usually a standardized empirical risk minimization problem. The individual data that do not need to be disclosed will be calculated in a local iterative algorithm, and the parameters will be transferred between the central machine and each local machine. At present, the widely used algorithms for the decentralized distributed learning problems mainly include subgradient-based algorithms [
14,
15], alternating direction method of multipliers(ADMM) [
16,
17,
18,
19], and the combination algorithms of these methods [
20]. Ref. [
21] proved that ADMM-based algorithms converge at the rate of
, while subgradient-based algorithms usually converge at the rate of
, where
L is the number of iterations. Therefore, in this paper, we adopt an ADMM-based distributed learning algorithm against privacy disclosure and keep a statistical guarantee.
We know that sensitive individual information may be leaked in optimization algorithms as a result of sharing information such as parameters and/or gradients of the model between machines, as presented in [
22,
23]. The same problem exists in our ADMM-based distributed algorithm: how to avoid privacy leakage. So, we need to protect privacy via a DP mechanism while maintaining statistical accuracy in our distributed learning. Ref. [
24] studied a class of regularized empirical risk minimization machine learning problems via ADMM and proposed the dual variable perturbation and the primal variable perturbation methods for dynamic differential privacy. Ref. [
25] proposed a privacy-preserving cooperative learning scheme, where users are allowed to train independently using their own data and only share some updated model parameters. They used an asynchronous ADMM approach to accelerate learning. In addition, their algorithm integrates secure computing and distributed noise generation to ensure the confidentiality of shared parameters during the asynchronous ADMM algorithm process. Ref. [
26] applied a new privacy-preserving distributed machine learning (PS-ADMM) algorithm based on stochastic ADMM, which provides a privacy guarantee by perturbing the gradient and has a low computational cost. In the paper, we focus on a functional linear regression model for functional data analysis via ADMM-based distributing learning to keep DP and statistical efficiency.
Functional data are natural generalizations of multivariate data from finite dimensional to infinite dimensional which are obtained by observing a number of subjects over time, space, and other continua. In practice, functional data are frequently recorded by an instrument, which involves a large number of repeated measurements per subject. They can be curves, surfaces, images, or other complex objects; see some real data sets in the monographs [
27,
28,
29]. All in all, a functional datum is not a single observation but rather a set of measurements along a continuum; taken together, they are regarded as a single entity, curve, or image. In recent decades, functional data analysis has drawn considerable attention because advanced technology makes functional data easier to collect in applied fields such as medical studies, speech recognition, biological growth, climatology, online auctions, and so on. Time series data are treated as multivariate data because they are given as a finite discrete time series. In addition, longitudinal data, which are often observed in biomedical follow-up studies, are strongly linked with functional data; however, their use often involves several (few) measurements per subject taken intermittently at different time points for different subjects. Therefore, functional data and longitudinal data are also intrinsically different. In addition, some classic multivariate data analysis tools, applied to time series and longitudinal data analysis, cannot be directly applied to functional data analysis because they ignore the fact that the underlying object of the measurements of a subject is a function such as curve or surface. We know that functional data are intrinsically infinite dimensional, and our analysis methods cannot be based on the assumption that the values observed at different times for a single subject are independent because of the intra-observation dependence. The high intrinsic dimensionality and the intra-observation dependence of functional data pose challenges both for theory and computation.
Recently, various approaches and statistical models for the analysis of functional data have been developed. For an introduction and summary, see [
27,
28,
29,
30]. Ref. [
31] firstly proposed a linear regression model and analyzed the effects of functional independent variables on the scalar response variables through the inner product of functional independent variables and unknown nonparametric coefficient function. Ref. [
32] gave a functional linear semiparametric quantile regression model, which has been used to analyze ADHD-200 patients data. Ref. [
33] studied the estimation problem of a functional partial quantile regression model, and proved the asymptotic normality of the finite dimensional parameter estimation. The conventional method of functional data analysis is principal component analysis (PCA), such as [
34,
35]. Ref. [
35] gave the optimal convergence rates of PCA. We will consider functional principal components analysis (FPCA) for our functional linear regression model and investigate the distributed learning with privacy.
In this paper, we propose a new ADMM-based distributed learning algorithm with differential privacy to handle large amounts of functional data. We call it the FDP-ADMM algorithm. Our proposed FDP-ADMM algorithm has good properties such as a faster rate of convergence, lower communication and computation costs, and better utility–privacy tradeoffs. In the FDP-ADMM algorithm, we consider a more robust quantile loss function, combine an approximate augmented Lagrange function, and integrate time-varying Gaussian noise into local learning on each machine. These techniques allow the FDP-ADMM algorithm to be adversarial while protecting privacy.
The main contributions of this paper are summarized as follows:
We propose a distributed learning algorithm (FDP-ADMM) that can process large-scale distributed functional data and protect privacy. For the large-scale functional data, we adopt functional principal component analysis to reduce the dimensions of the data, improve the quality of data information, and promote the efficiency of functional data analysis using distributed learning.
We introduce a quantile loss function for functional linear model such that our models are adaptive to heavy-tail data or outliers. Thus, our ADMM-based distributed learning algorithm is more robust compared with ordinary least square procedure.
The privacy and theoretical convergence guarantees of the FDP-ADMM algorithm are derived, and a privacy–utility trade-off is demonstrated: a weaker privacy guarantee would result in better utility.
We conduct numerical experiments to illustrate the effectiveness of FDP-ADMM in the framework of distributed learning. The results of experiments are consistent with our theoretical analysis.
The rest of this paper, is organized as follows. In
Section 2, we state our problem formulation by introducing the functional linear regression model, the penalized quantile regression, the ADMM algorithm, and DP. In
Section 3, we propose an ADMM-based distributed learning algorithm with privacy protection for distributed functional data analysis. In
Section 4, we present the utility analysis of our algorithm, FDP-ADMM, including the convergence and privacy guarantee. In
Section 5, we give some numerical experiments to verify our theoretical results. Some conclusions are given in
Section 6. The proofs of the main results are collected in
Appendix A.
Notations
For any positive integer n, we define . , and are denoted as the Euclidean norm, -norm, and -norm, respectively. is the quantile loss function for a scalar . and denotes the indicator function. For a vector , we define . Throughout this paper, the constant C denotes positive constant whose value may change from line to line. For any function f and a positive function , f means for some positive constants a and b.
3. Distributed Learning with DP for Functional Data via ADMM
In this section, we propose the ADMM-based distributed learning algorithm with DP for functional data, which is called FDP-ADMM. We will transfer the functional regression model (
1) into a linear regression model (
2) by using FPCA. Because quantile regression has better performance in estimation and prediction for non-Gaussian distribution error, such as heavy-tailed distribution or outliers, we consider quantile regression for the models (
1) and (
2). First, based on data
, the functional quantile linear regression model we consider is
where
is a given quantile level, and
are random errors. Without loss of generality, we assume that the
th quantile of
is equal to zero. The model can be written as
. Our goal is to learn the functional coefficient
by
The problem is difficult because of the term
. By the FPCA introduced in
Section 2.1, we have the model (
2):
That is, functional quantile linear regression is transformed as an ordinary quantile linear regression. We suppress the dependency of
on
for simplicity. Then, for the quantile linear regression, we propose penalized quantile regression learning, which is formulated as
It has been introduced in
Section 2.2.
However, our dataset
cannot be collected on one machine, but distributed over
M machines. That is, we have the distributed data
, where
M is the number of worker machines, and
is the size of sample on the
ith machine. Thus, based on FPCA,
is transformed as
, where
is the score of the
jth sample on the
ith worker machine. So, based on the distributed data
and the model (
2), we have the following QR estimation in the distributed framework:
where
is the loss function of quantile regression, and
w is the unknown coefficient. Furthermore, we modify QR as penalized QR estimator for achieving faster shrinking, that is:
Note that in (
12), there exist two type of tuning parameters,
K and
, where
K controls the number of scores to characterize the decomposition level of FPCA and
controls the fitness of the model.
When facing big data, that is, when
n is very large, it is hard for one machine to learn
w in (
12). So, it is necessary to distributed storage and learning. Next, we will demonstrate the ADMM-based distributed learning for penalized QR. We provide a sketch of our FDP-ADMM algorithm based on the distributed data.
3.1. ADMM-Based Distributed Learning Algorithm
Assume we have
M machines, and the
ith machine has
local data samples. Applying the ADMM algorithm, we re-formulate the problem (
12) as:
where
is the local model parameters, and
is the global ones. Then, the augmented Lagrangian function for the
ith machine is:
The objective (
14) is decoupled and each worker only needs to minimize the sub-problem based on its local data set. Constraints (
15) enforce all the local models to consensus. It results in the following iteration:
Note that each machine transfers its
to a central machine. The central machine gathers them to update
and then broadcasts it to each machine. Details for the algorithm are present in Algorithm 1. Based on output
, we obtain:
| Algorithm 1:ADMM for PQR of Functional Data (F-ADMM) |
![Mathematics 10 02954 i001]() |
3.2. ADMM-Based Distributed Learning with DP
For achieving faster optimization, we make use of the first-order approximation to the penalized objective function. Then,
in (
14) becomes:
where
is the time-varying step size which decreases as the iteration
l grows,
is the subgradient of the quantile loss function, and
is the subgradient of the penalty. So, we have the following optimization problem:
Here, we give the ADMM-based distributed learning algorithm with DF (FDP-ADMM) as follows:
where
in (
22) are sampled from
, and
in (
23) is computed on the central machine. The rest are processed at each local machine. Details on FDP-ADMM algorithm are presented in Algorithm 2. Based on output
of Algorithm 2, we obtain:
Note that the central machine initializes the global
, while each worker machine initializes their own variables: the noisy primal variables
and the dual variables
for
.
is Gaussian noise with zero-mean and variance
, where
is obtained based on the Gaussian mechanism of DP, which is given in Theorem 1. Each worker machine updates its noisy primal variable
based on (
22). Then, the central machine receives all noisy primal variables
and the dual variables
from the worker machine, and updates a global variable
. In addition,
on central machine broadcasts to every worker machine to update the final dual variables
using (
24). It is an iterative cycle.
We set the variance for obtaining the -DP of the FDP-ADMM algorithm, which is set based on the Gaussian mechanism of DP. is time-varying; that is, it decreases as iteration l increases. The motivation of using time-varying variance in the Gaussian mechanism is to reduce the negative impact of noise and ensure the convergence of the algorithm. We find that the negative impact will be mitigated by the method of decreasing noise and can achieve a stable solution.
For the communication and computation costs of our algorithms 1 and 2, here are some remarks. We know that it is unrealistic to send the estimator of
,
on a worker machine to the central machine because it is infinite dimensional. In Algorithms 1 and 2, we only transmit the
K-dimensional
w in each round of communication, so the communication complexity is only
. In practice of functional data analysis,
K is usually a small number such as 5, 10, etc. Therefore, our algorithms are communication-efficient because of the low communication costs. In addition, in each round of learning, each worker machine learns its own low-dimensional parameter
w based on its local data, then the central machine is responsible for summarizing these parameters from worker machines. This working mechanism greatly reduces the computational costs.
| Algorithm 2:ADMM-based distributed learning with DP for PQR of Functional Data (FDP-ADMM) |
![Mathematics 10 02954 i002]() |
5. Simulation Study
In this section, we illustrate the performance of the proposed privacy-protection FDP-ADMM algorithm using a simulated study.
The simulation design is described as follows:
where
n is the sample size on all worker machines;
with
,
for
,
and
for
;
where
’s are independent and normal
; and the errors
where
is the distribution function of
, take
. Note that
is subtracted from
to make the
th quantile of
zero for identifiability. The datasets
are distributed on
M worker machines, and each machine has the same sample size
m. So,
.
In the simulation, we set samples, and randomly split the dataset into , 20, and 50 groups to simulate the distributed learning condition. We take the penalty parameter , and the regularized parameter . We set the level of quantile , and set privacy budget per iteration and . For each scenario, we run the algorithm 100 times. We consider our FDP-ADMM algorithm with typical -norm and -norm penalties and then assess it in terms of convergence and accuracy.
First, we report the mean integrated squared error (MISE) of the estimator
computed on a grid of 100 equally spaced points on
, that is:
Second, based on
and
, we evaluate the convergence properties of the FDP-ADMM algorithm with respect to the augmented objective value, which measures the loss as well as the constraint penalty and is defined as:
Third, we evaluate the accuracy by empirical loss:
5.1. L1-Regularized Quantile Regression
We obtain the FDP-ADMM steps for the
-norm quantile regression by:
where
is the sign function. Since the objective function is convex but non-smooth, we use Theorem 2 to set
and apply Theorem 1 to set
.
First, we list MISEs for the number of local machines,
, 20, 50, in
Table 1,
Table 2 and
Table 3, respectively. From
Table 1,
Table 2 and
Table 3, we observe that (i) Our approach with larger
and larger
has better convergence for all quantile levels because their MISEs are smaller, which also implies weaker privacy protection. When
and
, the MISEs of our FDP-ADMM algorithm with privacy policy are comparable to the ones of non-DP algorithm (
), that is, our FDP-ADMM algorithm does not sacrifice the estimation accuracy under weak privacy protection. (ii) For strong privacy protection, such as
, the accuracy of our training model decreases as the number of machines increases. Because the size of the local dataset is smaller for a larger number of working machines, more noise should be added into the FDP-ADMM algorithm to obtain a higher privacy guarantee. For the large number of machines, a high estimation accuracy can be achieved by reducing privacy protection, for example,
. (iii) Our FDP-ADMM algorithm has a trade off between privacy and accuracy, i.e., the stronger the privacy protection, the lower the estimation accuracy. (iv) When
, this FDP-ADMM is a robust distributed learning algorithm for all parameters of privacy and number of machines we set. Because
is farther from 0.5, its MISE is worse.
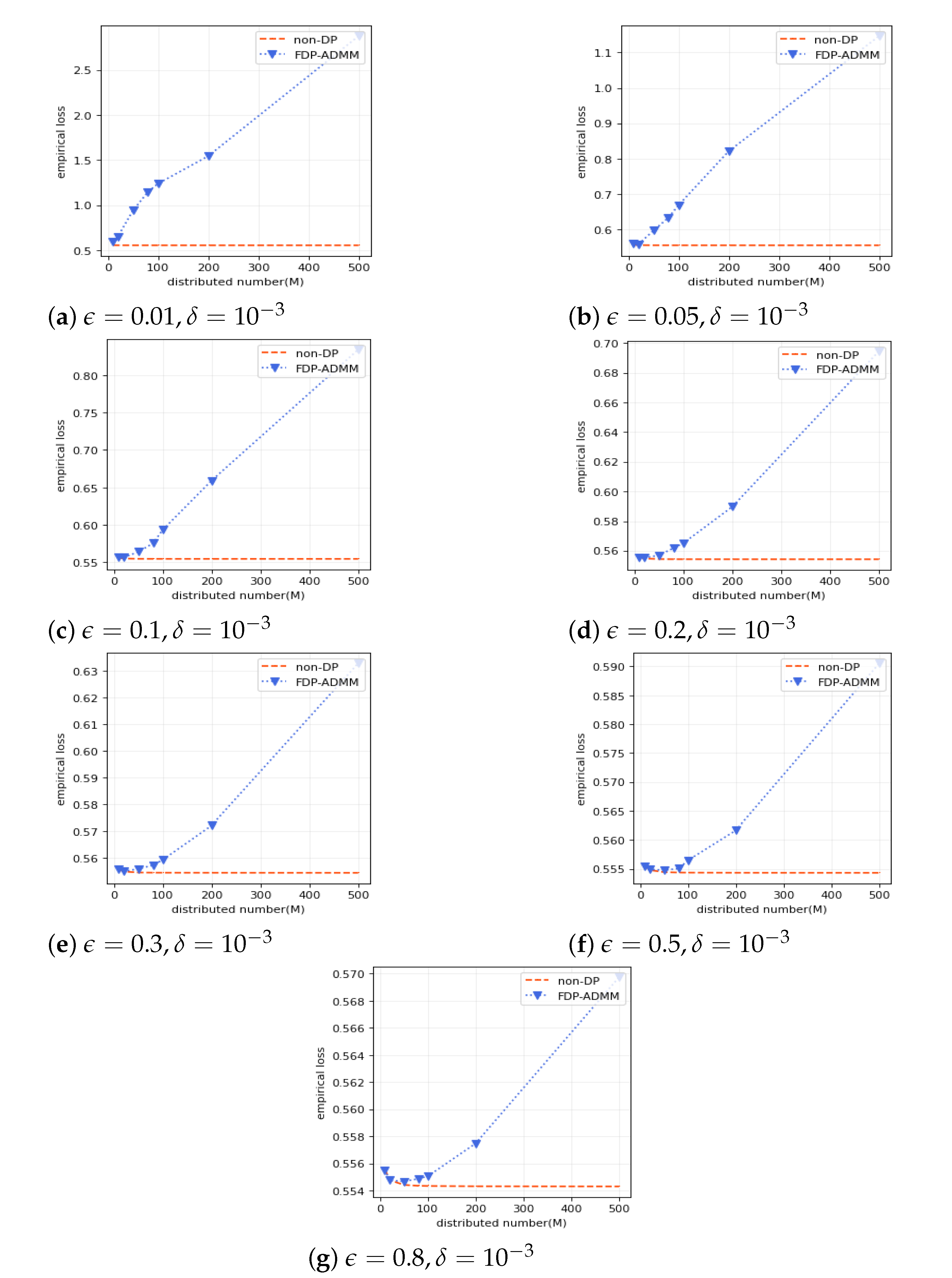
Second, we study the training performance (empirical loss) v.s. different number of distributed data sources under different levels of privacy protection when
. See
Figure 1.
Figure 1 shows that the accuracy of our training model will be reduced if more local machines are used. Since the number of agents is larger the smaller the size of the local dataset is, more noise should be added to guarantee the same level of differential privacy. Thus, it results in reducing the performance of the trained model. This is consistent with Theorem 1 that the standard deviation of noises is scaled by
. From another perspective, when more local machines participate, a weaker privacy protection can obtain a higher estimation accuracy.
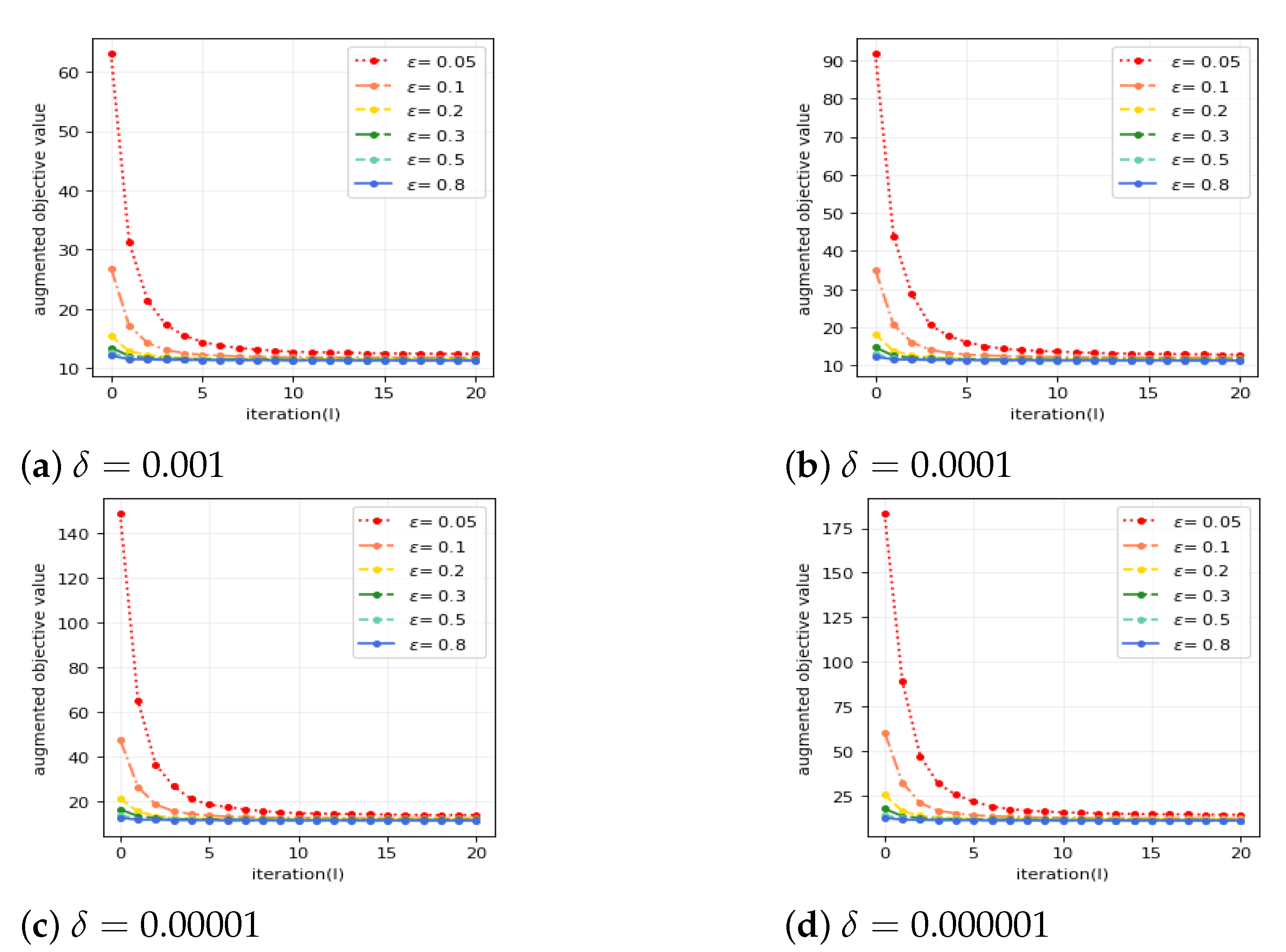
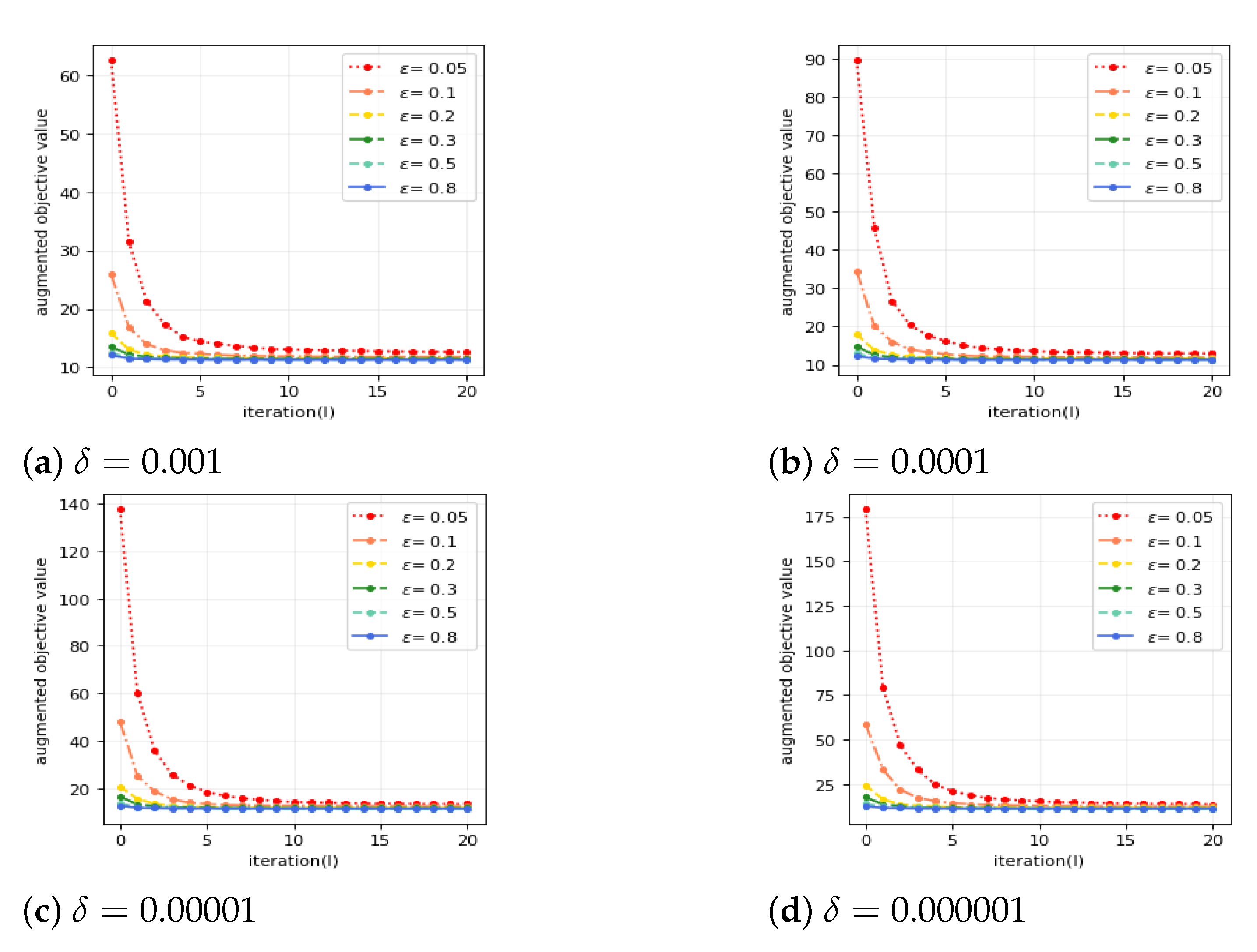
Third, we illustrate the convergence of the FDP-ADMM algorithm by demonstrating how the augmented objective value converges for different values of
and
. See
Figure 2.
Figure 2 shows our algorithm with larger
and
(which implies the weaker privacy protection) has better convergence. This result is consistent with Theorem 2.
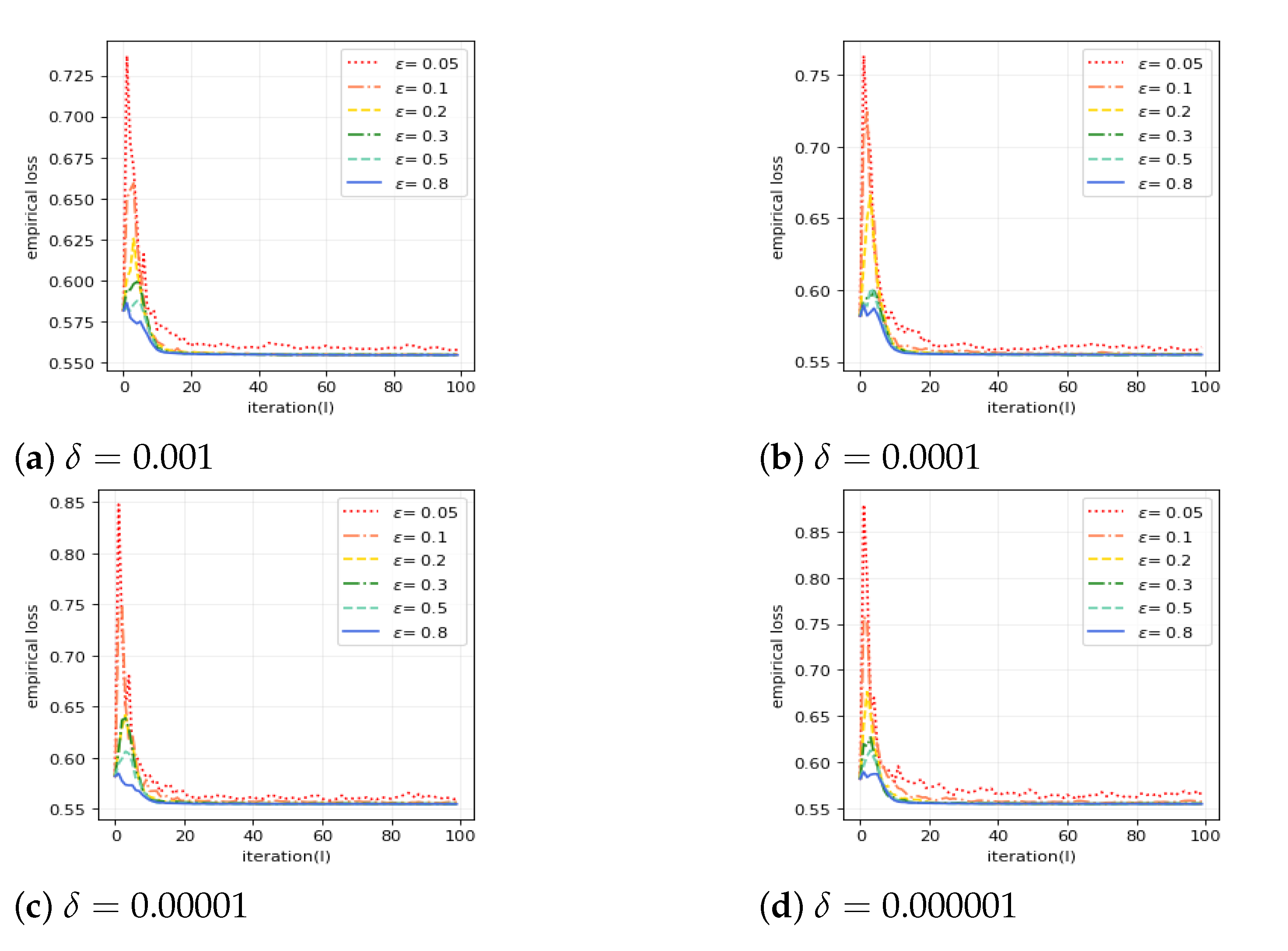
Finally, we evaluate the performance of FDP-ADMM by empirical loss for different levels of privacy protection. See
Figure 3.
Figure 3 shows our approach has fast convergence property for all privacy policies. In addition, all results we obtained show the privacy–utility trade-off of our FDP-ADMM: better utility is achieved when privacy leakage increases.
5.2. L2-Regularized Quantile Regression
We obtain the FDP-ADMM steps for
-norm quantile regression as follows:












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}