
Steganography with High Reconstruction Robustness: Hiding of Encrypted Secret Images



Abstract
:1. Introduction
2. Related Work and Evaluation Indexes
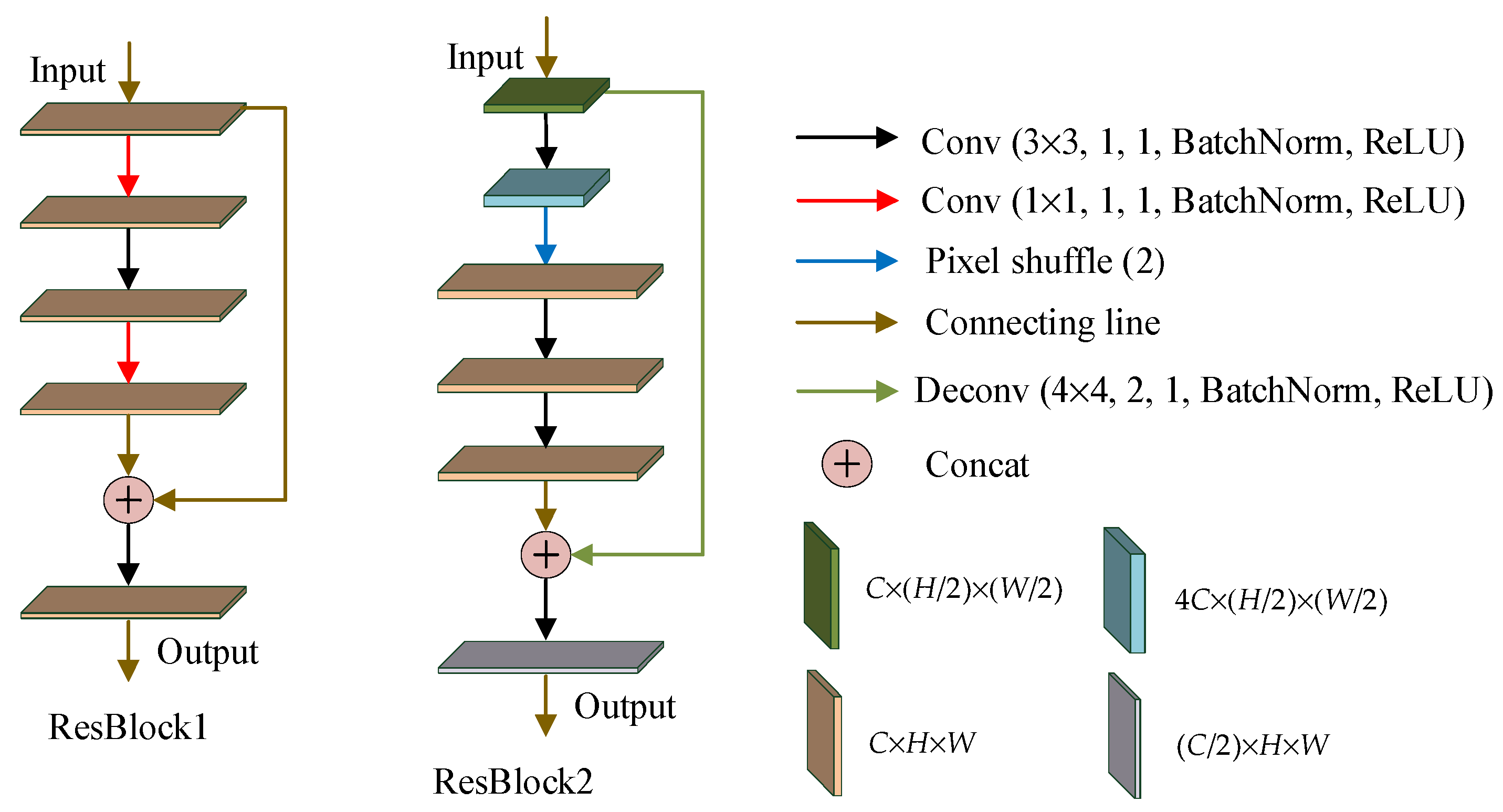
2.1. Residual Convolutional Neural Network (RCNN)
2.2. Pixel Shuffle
2.3. Image Encryption Algorithm
2.4. Evaluation Indexes
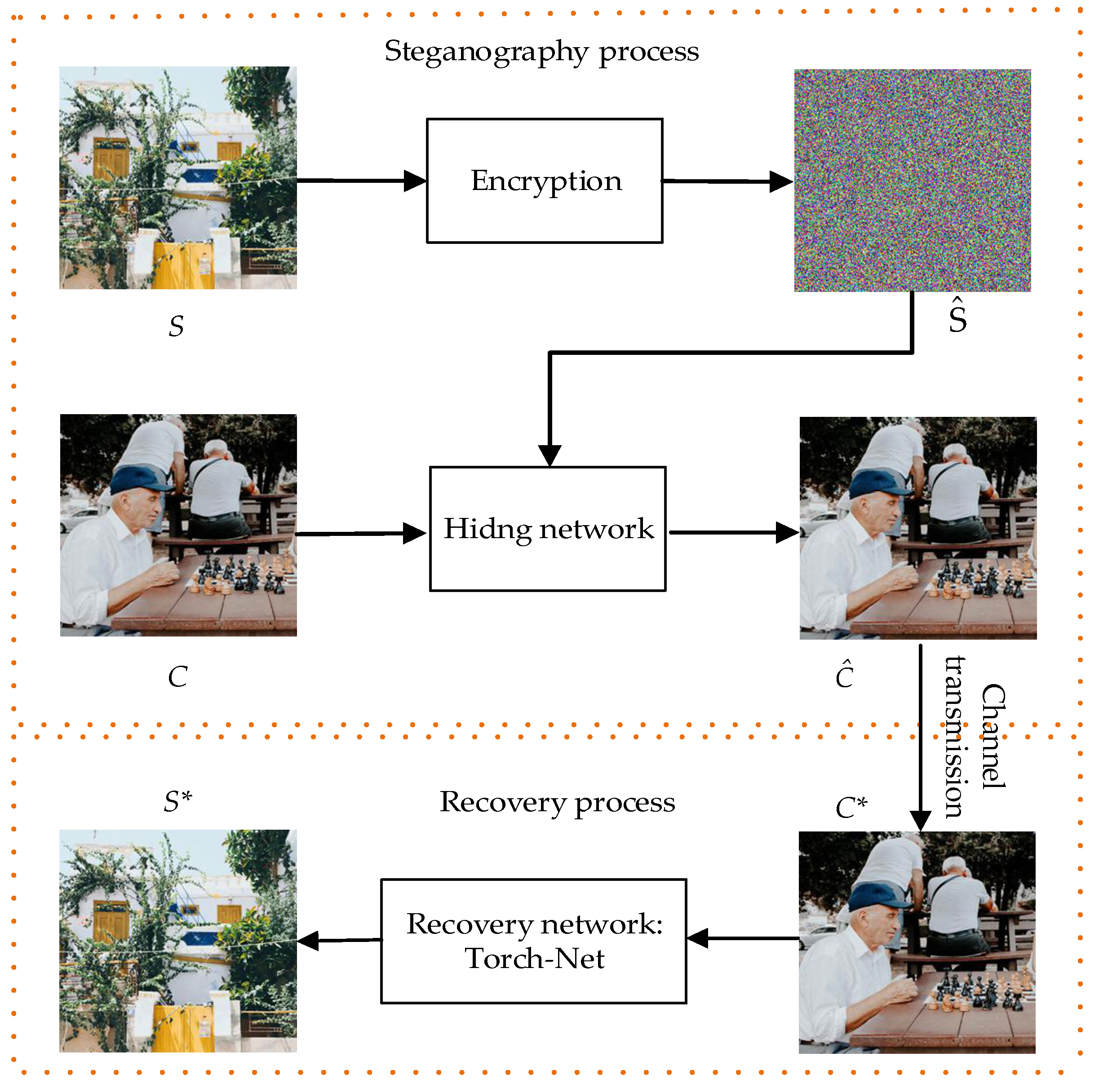
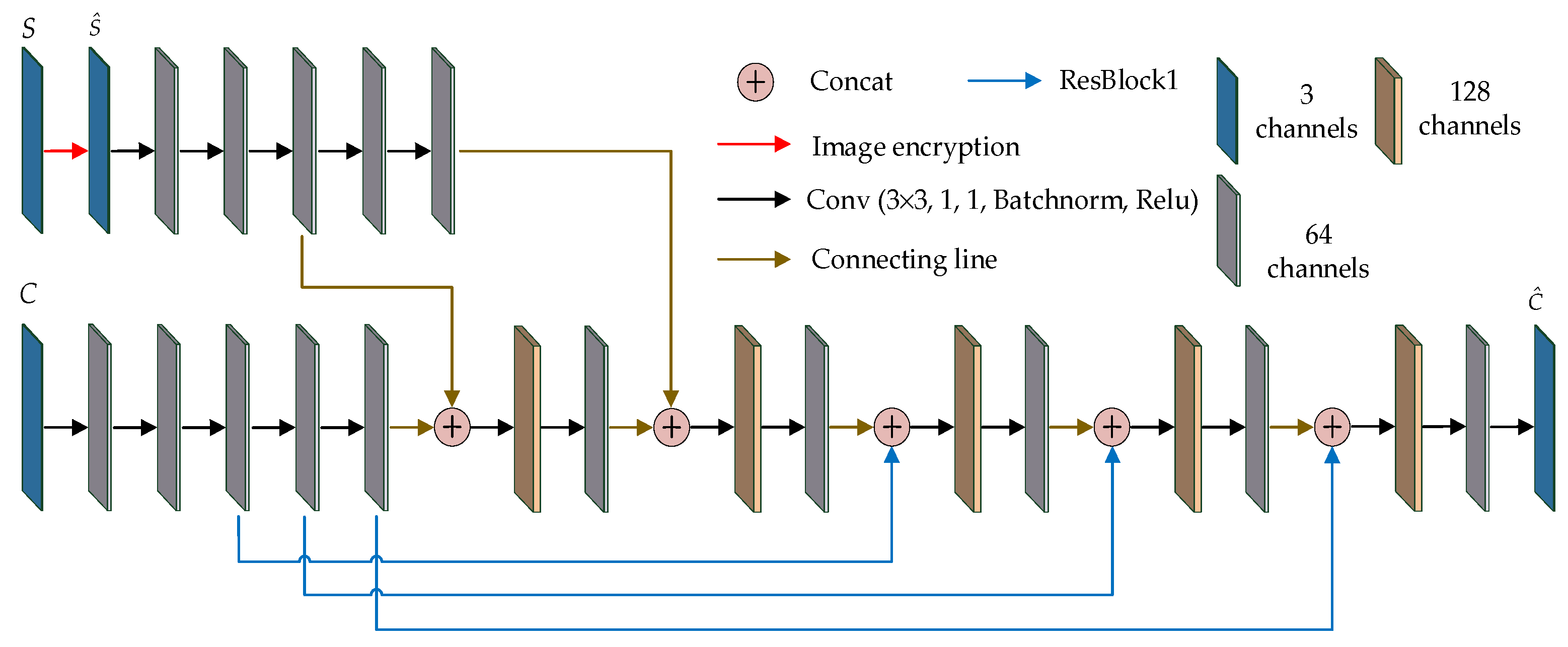
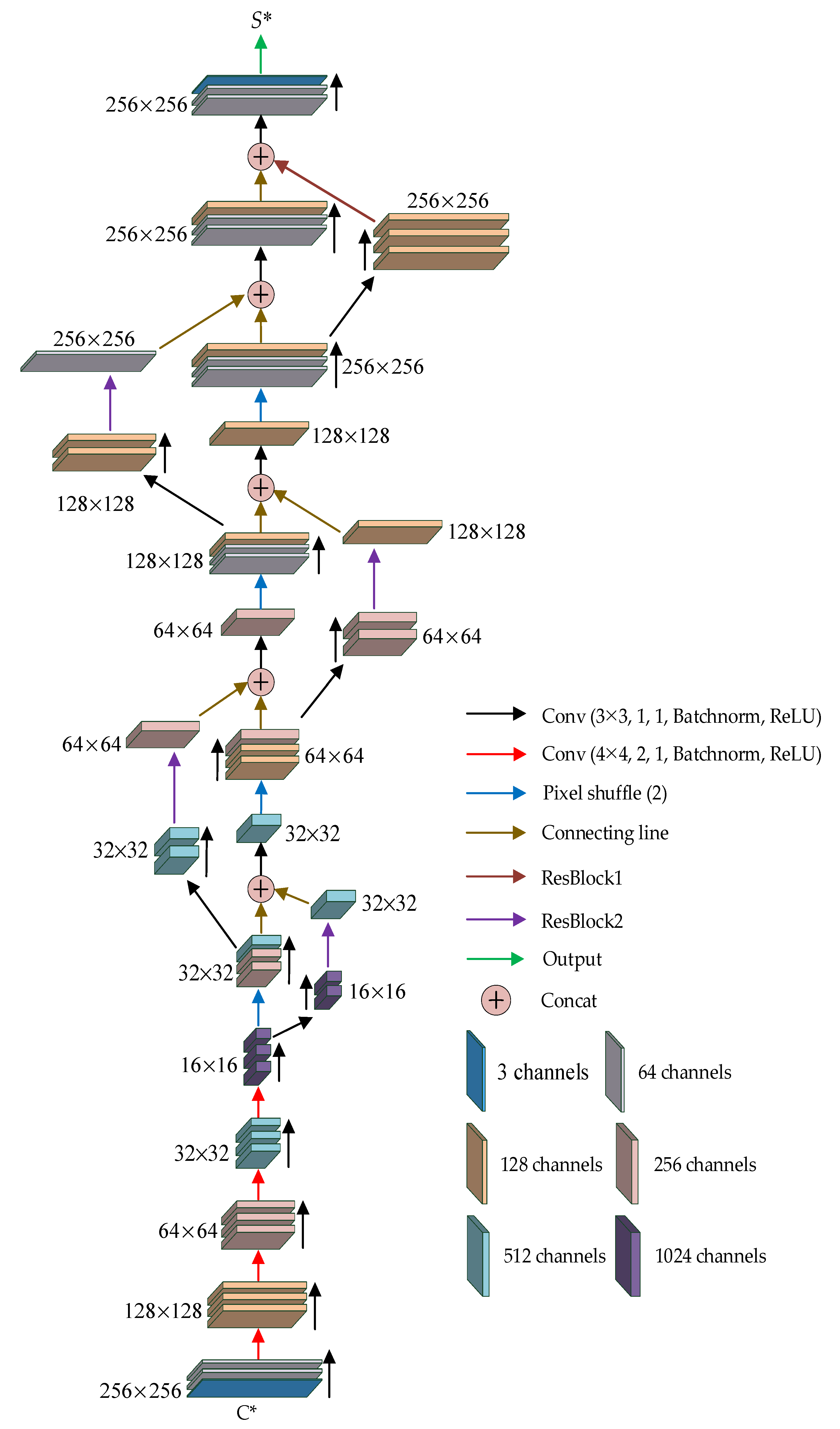
3. The Proposed Resen-Hi-Net
3.1. Hiding Network
3.2. Recovery Network
4. Experimental Results
4.1. Developmental Environment and Dataset
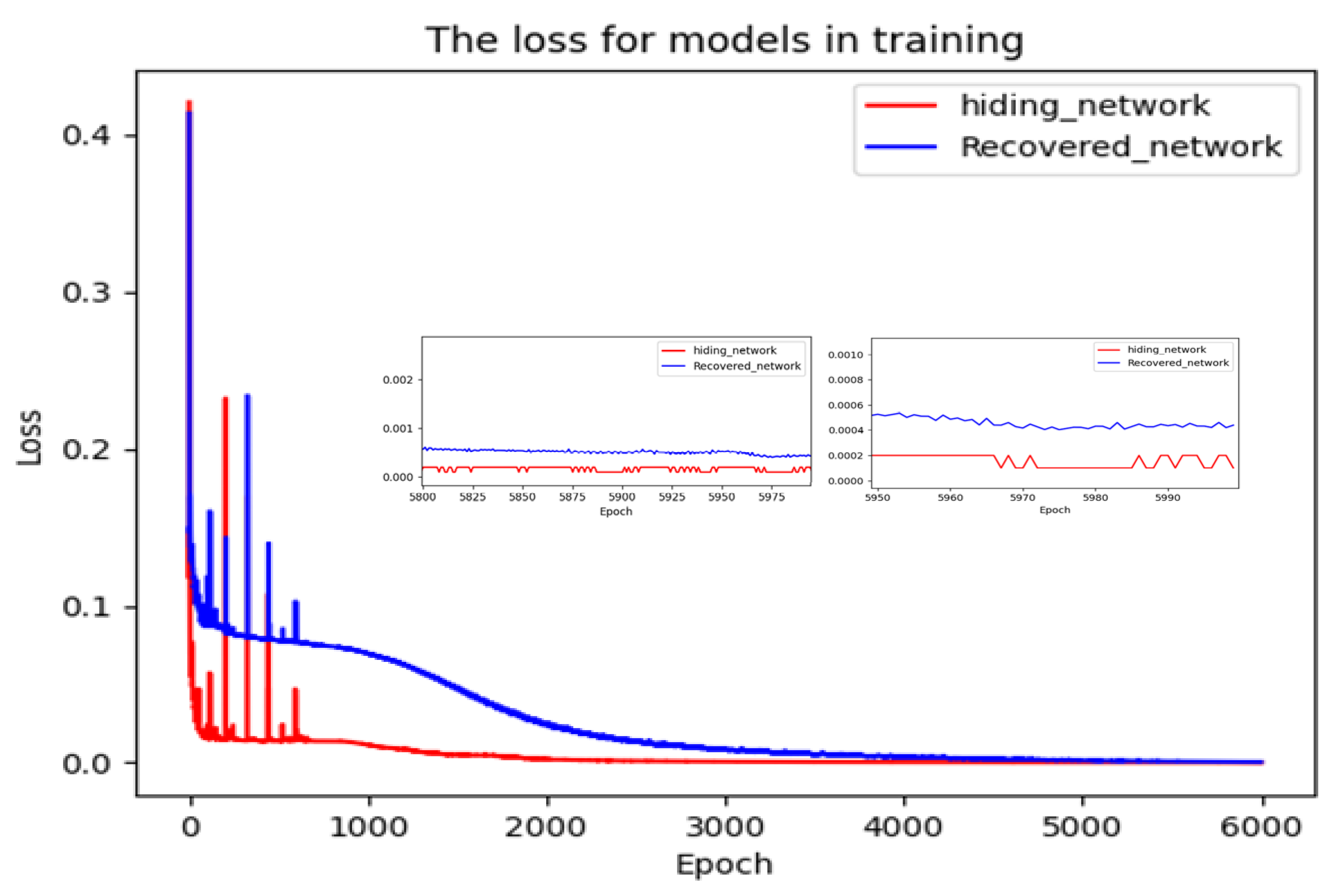
4.2. Training Process
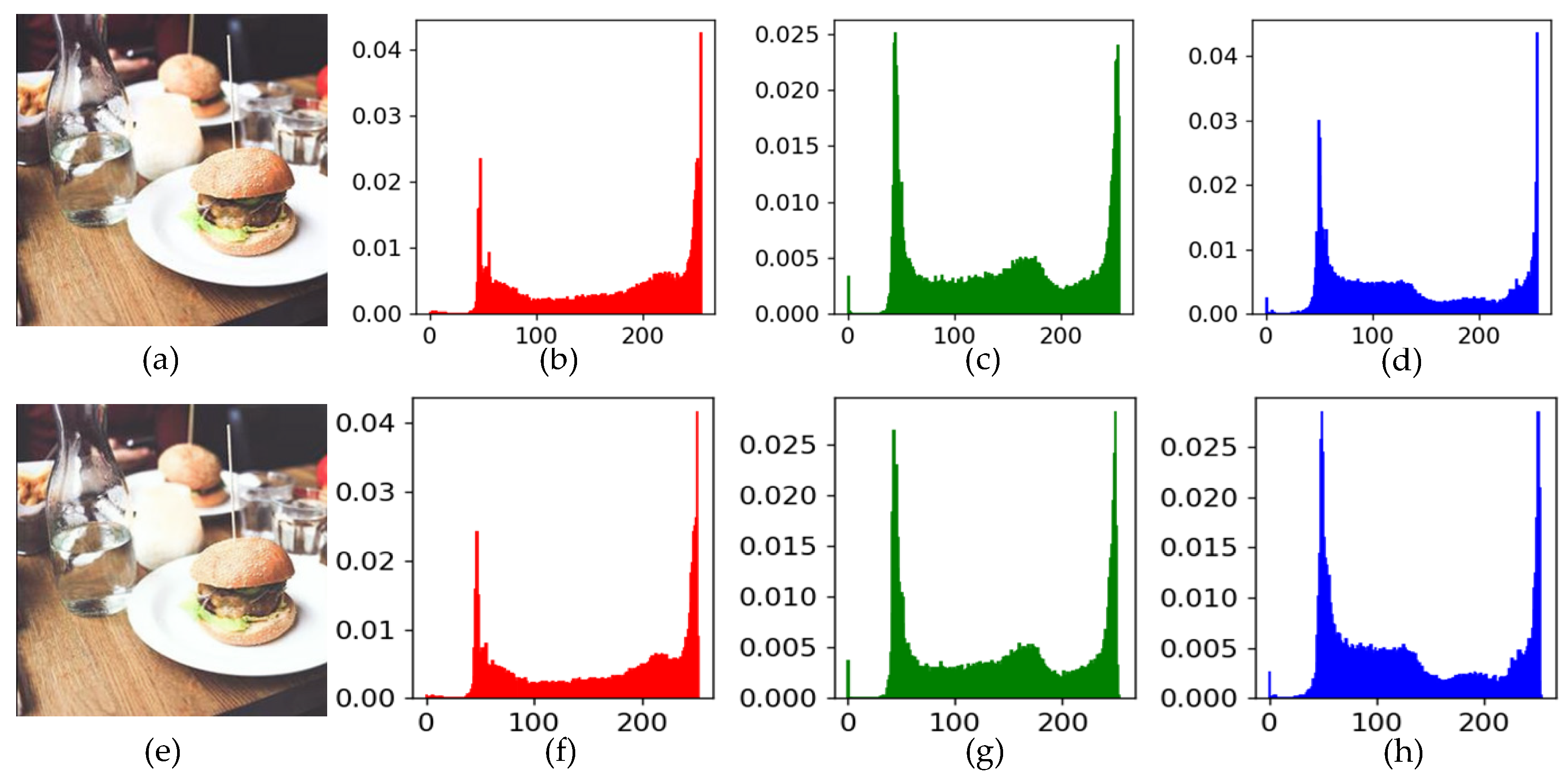
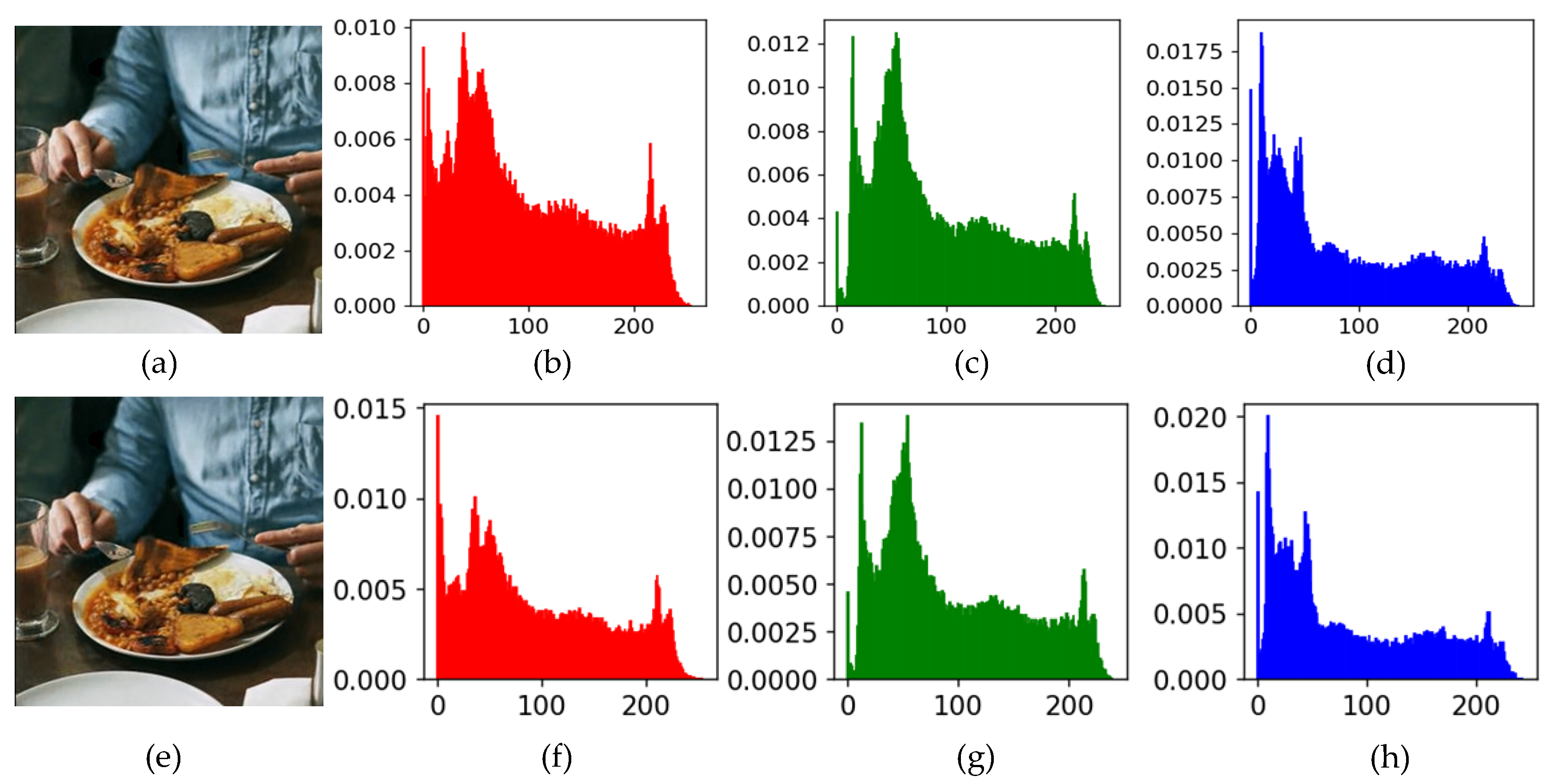
4.3. Results of Image Hiding and Recovery
4.4. Performance of Resistance to Cropping and Noise Attacks
4.5. Performance of Resistance to Cropping and Compression Attacks
4.6. Resistance to Steganalyses
4.7. Ablation Study
4.8. Comparison with Other State-of-the-Art CNN Steganography Approaches
5. Conclusions and Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Piao, Y.R.; Shin, D.H.; Kim, E.S. Robust image encryption by combined use of integral imaging and pixel scrambling techniques. Opt. Lasers Eng. 2009, 47, 1273–1281. [Google Scholar] [CrossRef]
- Ye, G.D. Image scrambling encryption algorithm of pixel bit based on chaos map. Pattern Recognit. Lett. 2010, 31, 347–354. [Google Scholar] [CrossRef]
- Zhou, Y.; Li, C.L.; Li, W.; Li, H.; Feng, W.; Qian, K. Image encryption algorithm with circle index table scrambling and partition diffusion. Nonlinear Dyn. 2021, 103, 2043–2061. [Google Scholar] [CrossRef]
- Cariolaro, G.; Erseghe, T.; Kraniauskas, P. The fractional discrete cosine transform. IEEE Trans. Signal Process. 2002, 50, 902–911. [Google Scholar] [CrossRef]
- Wu, J.H.; Zhang, L.; Zhou, N.R. Image encryption based on the multiple-order discrete fractional cosine transform. Opt. Commun. 2010, 283, 1720–1725. [Google Scholar] [CrossRef]
- Wu, J.H.; Guo, F.F.; Zeng, P.P. Image encryption based on a reality-preserving fractional discrete cosine transform and a chaos-based generating sequence. J. Mod. Opt. 2013, 60, 1760–1771. [Google Scholar] [CrossRef]
- Xu, Y.; Wang, H.; Li, Y.G.; Pei, B. Image encryption based on synchronization of fractional chaotic systems. Commun. Nonlinear Sci. 2014, 19, 3735–3744. [Google Scholar] [CrossRef]
- Chen, L.F.; Zhao, D.M. Optical image encryption based on fractional wavelet transform. Opt. Commun. 2005, 254, 361–367. [Google Scholar] [CrossRef]
- Tao, R.; Meng, X.Y.; Wang, Y. Image encryption with multi orders of fractional Fourier transforms. IEEE Trans. Inf. Forensics Secur. 2010, 5, 734–738. [Google Scholar] [CrossRef]
- Hennelly, B.M.; Sheridan, J.T. Image encryption and the fractional Fourier transform. Optik 2003, 114, 251–265. [Google Scholar] [CrossRef]
- Zhou, N.R.; Dong, T.J.; Wu, J.H. Novel image encryption algorithm based on multiple-parameter discrete fractional random transform. Opt. Commun. 2010, 283, 3037–3042. [Google Scholar] [CrossRef]
- Hussain, M.; Wahab, A.W.A.; Idris, Y.I.B.; Ho, A.T.; Jung, K.H. Image steganography in spatial domain: A survey. Signal Process. Image 2018, 65, 46–66. [Google Scholar] [CrossRef]
- Djebbar, F.; Ayad, B.; Hamam, H.; Abed-Meraim, K. A view on latest audio steganography techniques. In Proceedings of the International Conference on Innovations in Information Technology, Abu Dhabi, United Arab Emirates, 25–27 April 2011. [Google Scholar] [CrossRef]
- Fang, T.; Jaggi, M.; Argyraki, K. Generating steganographic text with LSTMs. arXiv 2017, arXiv:1705.10742v1. [Google Scholar]
- Balaji, R.; Naveen, G. Secure data transmission using video steganography. In Proceedings of the Asia International Conference on Modelling & Simulation, Mankato, MN, USA, 15–17 May 2011. [Google Scholar] [CrossRef]
- Wang, Z.H.; Yang, H.R.; Cheng, T.F.; Chang, C.C. A high-performance reversible data-hiding scheme for LZW codes. Appl. Res. Comput. 2013, 86, 2771–2778. [Google Scholar] [CrossRef]
- Bender, W.R.; Gruhl, D.; Morimoto, N. Techniques for data hiding, storage and retrieval for image and video databases III. Int. Soc. Opt. Photonics 1996, 35, 313–336. [Google Scholar] [CrossRef]
- Westfeld, A.; Pfitzmann, A. Attacks on steganographic systems-breaking the steganographic utilities EzStego, Jsteg, Steganos, and s-tools-and some lessons learned. In Proceedings of the International Workshop on Information Hiding, Dresden, Germany, 29 September–1 October 1999. [Google Scholar] [CrossRef]
- Westfeld, A. F5–a steganographic algorithm. In Proceedings of the International Workshop on Information Hiding, Pittsburgh, PA, USA, 25–27 April 2001. [Google Scholar] [CrossRef]
- Filler, T.; Judas, J.; Fridrich, J. Minimizing additive distortion in steganography using syndrome-trellis codes. IEEE Trans. Inf. Forensics Secur. 2011, 6, 920–935. [Google Scholar] [CrossRef]
- Pevný, T.; Filler, T.; Bas, P. Using high-dimensional image models to perform highly undetectable steganography. In Proceedings of the International Conference, Calgary, AB, Canada, 28 June 2010; Available online: http://boss.gipsa-lab.grenoble-inp.fr/BOSSRank/ (accessed on 1 July 2010).
- Holub, V.; Fridrich, J. Designing steganographic distortion using directional filters. In Proceedings of the Information Forensics and Security, Costa Adeje, Spain, 2–5 December 2012. [Google Scholar] [CrossRef]
- Holub, V.; Fridrich, J. Digital image steganography using universal distortion. In Proceedings of the First ACM Workshop on Information Hiding and Multimedia Security, Montpellier, France, 17–19 June 2013. [Google Scholar] [CrossRef]
- Volkhonskiy, D.; Borisenko, B.; Burnaev, E. Generative adversarial networks for image steganography. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016; Available online: https://openreview.net/pdf?id=H1hoFU9xe (accessed on 1 June 2016).
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Adv. Neural Inf. Processing Syst. 2014, 3, 2672–2680. Available online: https://arxiv.org/pdf/1406.2661.pdf (accessed on 10 June 2014). [CrossRef]
- Shi, H.; Dong, J.; Wang, W.; Qian, Y.; Zhang, X. SSGAN: Secure steganography based on generative adversarial networks. In Advances in Multimedia Information Processing; Springer: Cham, Switzerland, 10 May 2017. [Google Scholar] [CrossRef]
- Yang, J.; Kai, L.; Kang, X.; Wong, E.K.; Shi, Y.Q. Spatial image steganography based on generative adversarial network. arXiv 2018, arXiv:1804.07939. [Google Scholar]
- Wang, Z.; Gao, N.; Wang, X.; Xiang, J.; Zha, D.; Li, L. Hiding GAN: High-capacity information hiding with generative adversarial network. Comput. Graph. Forum. 2019, 38, 393–401. [Google Scholar] [CrossRef]
- Li, C.; Jiang, Y.; Cheslyar, M. Embedding image through generated intermediate medium using deep convolutional generative adversarial network. Comput. Mater. Continua. 2018, 56, 313–324. [Google Scholar] [CrossRef]
- Qin, J.; Wang, J.; Tan, Y. He, Z. Coverless image steganography based on generative adversarial network. Mathematics 2020, 8, 1394. [Google Scholar] [CrossRef]
- Baluja, S. Hiding images in plain sight: Deep steganography. In Proceedings of the Advances in Neural Information Proceeding Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar] [CrossRef]
- Rehman, A.U.; MSNadeem, R.R.; Su, H. End-to-end trained CNN encode-decoder networks for image steganography. arXiv 2017, arXiv:1711.07201v1. [Google Scholar]
- Wang, Z.; Gao, N.; Wang, X.; Xiang, J.; Liu, G. Stnet: A style transformation network for deep image steganography. In Proceedings of the International Conference on Neural Information Processing, Sydney, NSW, Australia, 12–15 December 2019. [Google Scholar] [CrossRef]
- Baluja, S. Hiding images within images. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 1685–1697. [Google Scholar] [CrossRef] [PubMed]
- Lu, S.P.; Wang, R.; Zhong, T.; Rosin, P.L. Large-capacity image steganography based on invertible neural networks. In Proceedings of the 34th IEEE Conference on Computer Vision and Pattern Recognition, Kuala Lumpur, Malaysia, 19–25 June 2021. [Google Scholar] [CrossRef]
- Zhu, X.; Lai, Z.; Liang, Y.; Xiong, J.; Wu, J. Generative high-capacity image hiding based on residual CNN in wavelet domain. Appl. Soft Comput. 2022, 115, 108170. [Google Scholar] [CrossRef]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Wang, G.; Zeng, G.D.; Cui, X.Y.; Feng, S. Dispersion analysis of the gradient weighted finite element method for acoustic problems in one, two, and three dimensions. Int. J. Numer. Meth. Eng. 2019, 120, 473–497. [Google Scholar] [CrossRef]
- Yue, L.; Shen, H.; Li, J.; Yuan, Q.; Zhang, H.; Zhang, L. Image super-resolution: The techniques, applications, and future. Signal Proces. 2016, 128, 389–408. [Google Scholar] [CrossRef]
- Wu, J.; Xia, W.; Zhu, G.; Liu, H.; Ma, L.; Xiong, J. Image encryption based on adversarial neural cryptography and SHA controlled chaos. J. Mod. Opt. 2021, 68, 409–418. [Google Scholar] [CrossRef]
- Welstead, S.T. Fractal and wavelet image compression techniques. SPIE Opt. Eng. Press. 1999, 155–156. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Bas, P.; Filler, T.; Pevny, T. Break our steganographic system: The ins and outs of organizing BOSS. In Proceedings of the 13th International Conference on Information Hiding, Prague, Czech Republic, 18–20 May 2011. [Google Scholar] [CrossRef]
- Fridrich, J.; Kodovský, J. Rich models for steganalysis of digital images. IEEE Trans. Inf. Forensics Secur. 2012, 7, 868–882. [Google Scholar] [CrossRef]
- Denemark, T.; Sedighi, V.; Holub, V.; Holub, V.; Cogranne, R.; Fridrich, J. Selection-channel-aware rich model for steganalysis of digital image. IEEE Trans. Inf. Forensics Secur. 2014, 48–53. [Google Scholar] [CrossRef]
- Ye, J.; Ni, J.Q.; Yi, Y. Deep learning hierarchical representations for image steganalysis. IEEE Trans. Inf. Foren. Sec. 2017, 12, 2545–2557. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image Group | Container vs. Carrier PSNR (dB), MSSIM, MSE | Reconstructed vs. Secret PSNR (dB), MSSIM, MSE | Container vs. Carrier APE (R, G, B) | Reconstructed vs. Secret APE (R, G, B) |
|---|---|---|---|---|
| a | 39.67, 0.99, 14.76 | 35.34, 0.96, 35.98 | 0.75, 0.78, 0.76 | 3.34,3.70, 3.73 |
| b | 40.51, 0.99, 10.78 | 32.30, 0.92, 114.91 | 0.45, 0.46, 0.55 | 5.29, 5.47, 6.32 |
| c | 40.22, 0.99, 11.34 | 35.29, 0.97, 45.86 | 0.53, 0.52, 0.54 | 3.91, 4.12, 4.58 |
| d | 40.34, 0.99, 12.31 | 34.61, 0.96, 53.57 | 0.64, 0.67, 0.66 | 4.00, 4.19, 4.61 |
| Average | 40.19, 0.99, 12.29 | 34.39, 0.95, 62.58 | 0.59, 0.61, 0.63 | 4.14, 4.37, 4.81 |
| Attack Mode | Attack Intensity | PSNR | MSSIM | MSE | APE (R, G, B) |
|---|---|---|---|---|---|
| Gaussian noise attack (power/dBW) | 0.01 | 27.17 | 0.893 | 373 | 8.23, 7.88, 8.30 |
| 0.04 | 26.75 | 0.875 | 415 | 8.87, 9.09, 9.52 | |
| 0.08 | 26.56 | 0.869 | 412 | 9.70, 8.60, 8.89 | |
| 0.12 | 26.31 | 0.857 | 455 | 9.85, 9.53, 9.84 | |
| Salt and pepper noise attack (power/dBW) | 0.01 | 28.41 | 0.900 | 281 | 7.32, 7.22, 7.50 |
| 0.05 | 27.86 | 0.893 | 320 | 7.77, 8.05, 8.41 | |
| 0.1 | 27.43 | 0.887 | 418 | 8.10, 8.27, 8.55 | |
| 0.2 | 25.03 | 0.863 | 612 | 9.51, 8.53, 9.06 |
| Attack Mode | Attack Intensity | PSNR (dB) | MSSIM | MSE | APE(R,G,B) |
|---|---|---|---|---|---|
| Cropping attacks (pixels) | 10 × 10 | 31.98 | 0.963 | 126 | 3.43,3.33,3.53 |
| 25 × 30 | 28.73 | 0.913 | 217 | 5.23,5.67,5.15 | |
| Two of 25 × 30 | 25.56 | 0.844 | 588 | 9.98,9.08,10.56 | |
| Three of 25 × 30 | 25.12 | 0.832 | 751 | 11.89,11,34,12.20 | |
| PCA compression (compression ratio) | 1.53 | 24.32 | 0.835 | 1237 | 16.72,17.66,17.60 |
| 2.98 | 23.14 | 0.822 | 1594 | 18.81,18.73,19,21 | |
| 5.88 | 21.51 | 0.806 | 1874 | 21.14,22.84,22.83 | |
| 11.77 | 20.63 | 0.783 | 2325 | 22.36,24.21,24.27 |
| Container vs. Carrier | Reconstructed vs. Secret | AUC | |||||
|---|---|---|---|---|---|---|---|
| PSNR (dB) | MSSIM | PSNR (dB) | MSSIM | SRM | MaxSRM | Ye-Net | |
| 1 | 37.98 | 0.973 | 37.68 | 0.971 | 0.67 | 0.76 | 0.81 |
| 0.8 | 38.73 | 0.978 | 36.42 | 0.968 | 0.66 | 0.73 | 0.79 |
| 0.6 | 39.16 | 0.984 | 36.13 | 0.964 | 0.63 | 0.69 | 0.76 |
| 0.4 | 39.75 | 0.988 | 35.53 | 0.963 | 0.57 | 0.63 | 0.73 |
| 0.2 | 40.60 | 0.993 | 34.23 | 0.960 | 0.51 | 0.58 | 0.69 |
| 0.1 | 41.39 | 0.994 | 32.07 | 0.952 | 0.51 | 0.57 | 0.64 |
| Methods | Container vs. Carrier | Reconstructed vs. Secret | Against Steganalysis (AUC) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR (dB) | MSSIM | APE (R,G,B) | PSNR (dB) | MSSIM | APE (R,G,B) | SRM | MaxSRM | Ye-Net | |
| Baluja-Net [34] | 36.49 | 0.95 | 0.48, 0.49, 0.43 | 30.56 | 0.90 | 4.79, 4,37, 4.53 | 0.63 | 0.72 | 0.79 |
| ISN [35] | 39.28 | 0.977 | N/A | 40.42 | 0.985 | N/A | 0.59 | 0.65 | 0.73 |
| Proposed Resen-Hi-Net | 40.13 | 0.983 | 0.45, 0.46, 0.44 | 34.25 | 0.951 | 3.95, 4.34, 4.46 | 0.51 | 0.58 | 0.69 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, X.; Lai, Z.; Zhou, N.; Wu, J. Steganography with High Reconstruction Robustness: Hiding of Encrypted Secret Images. Mathematics 2022, 10, 2934. https://doi.org/10.3390/math10162934
Zhu X, Lai Z, Zhou N, Wu J. Steganography with High Reconstruction Robustness: Hiding of Encrypted Secret Images. Mathematics. 2022; 10(16):2934. https://doi.org/10.3390/math10162934
Chicago/Turabian StyleZhu, Xishun, Zhengliang Lai, Nanrun Zhou, and Jianhua Wu. 2022. "Steganography with High Reconstruction Robustness: Hiding of Encrypted Secret Images" Mathematics 10, no. 16: 2934. https://doi.org/10.3390/math10162934