1. Introduction
The symmetric tridiagonal matrices often arise as primary data in many computational quantum physical [
1,
2], mathematical [
3,
4,
5], dynamical [
6,
7], computational quantum chemical [
8,
9], signal processing [
10], or even medical [
11] problems and hence are important. The current software reduces the generalized and the standard symmetric eigenproblems to a symmetric tridiagonal eigenproblem as a common practice [
10,
12,
13]. What is more interesting is that the opposite path is also productive. Marques [
14] computes the SVD of a bidiagonal matrix through the eigenpairs of an associated symmetric tridiagonal matrix. In this paper, we focus on symmetric eigenvalue solving.
People desire a parallel algorithm of good performance and flexibility, especially today as CPU cores and massively parallel technology have skyrocketed. We noticed that in many application scenes of eigenvalue computation, for example, in dynamics, it is often necessary to solve only the first few orders of eigenvalues of a large matrix. The desire for the largest eigenvalue is also common in practice [
15,
16,
17]. However, the current QR, MRRR (Multiple Relatively Robust Representations), DC (Divided and Conquer), and Bisection algorithms do not seem to perform sufficient parallel operations if the number of CPU cores (say, 40) is significantly larger than the number of eigenvalues (say, 1) to be solved.
The most popular algorithm at present for a symmetric eigenproblem is the QR algorithm because of its stability and computational efficiency [
18,
19,
20]. When only eigenvalues are desired, all square roots can be eliminated in the QR transformation. This was first observed by Ortega and Kaiser in 1963 [
21] and a fast, stable algorithm was developed by Pal, Walker, and Kahan (PWK) in 1969 [
22]. However, the parallelization of the QR algorithm is a problem, in this case, requiring more than a straightforward transcription of serial code to parallel code. Many researchers have made attempts, such as blocking the given matrix [
23], look-ahead strategies [
24], load-balancing schemes [
25], pipelining of iterations [
20,
26], or dimensional analysis [
27]. However, few seem adequate for the symmetric tridiagonal matrices because most of those attempts are for dense matrices. One more essential trouble is that the QR algorithm is unsuitable for computing one or several selected eigenvalues. The MRRR algorithm [
28] has a similar disadvantage as it is based on the DQDS algorithm [
29,
30] to compute the eigenvalues. In detail, both QR and DQDS algorithms use a designed shift, for example, Wilkinson’s shift, to obtain a high-order asymptotic convergence rate. As a consequence, the order of eigenvalue convergence is not manageable.
The DC algorithm [
31] is easily parallelizable and has developed well in recent years [
32,
33]. However, efficient parallel implementations are not straightforward to program, and the decision to switch from task to data parallelism depends on the characteristics of the underlying machine. Its space complexity is also an obvious shortcoming. In fact, even the “dstedc” routine corresponding to the DC algorithm in LAPACK calls “dsterf” when only eigenvalues are computed, i.e., the PWK version of the QR algorithm. The DC algorithm also does not support the computation of eigenvalues of a specific order or within a particular interval, let alone parallelization.
The Bisection method [
34] calculates eigenvalues in any order or interval with a variable precision, which is suitable and handy for the mixed precision calculation [
35]. Its embarrassingly parallel nature and high accuracy make it implemented in current software libraries for distributed memory computers. In addition, the Bisection method has a parallelizing efficiency of 1 (unless the number of computational cores is larger than the matrix dimension, which is rare) and little communication cost, which makes it highly advantageous in massively parallel computations. However, parallel Bisection can only be implemented if the number of unsolved eigenvalues is no less than the number of CPU cores. In addition, the computational efficiency of the Bisection method disconcerts.
We briefly summarize here: QR, DC, and MRRR algorithms are only available for obtaining all the eigenvalues. The Bisection method has excellent accuracy and flexibility but with limited efficiency when computing all the eigenvalues. All existing methods fail to calculate a single eigenvalue in parallel. Therefore, this paper has two goals: (1) to give a new Bisection method that can perform parallel operations with any number of threads when computing one specific eigenvalue; (2) to improve the efficiency of the Bisection method when calculating a major set of or all eigenvalues.
Section 2 presents some theorems, lemmas, corollaries, and equations. They are demonstrated for the design of Algorithms 4 and 5 and the accuracy analyses in
Section 5. The big view of our method for one specific eigenvalue is dividing the matrix for parallel computing and merging them for the final result, with an insignificant time cost in the merging process. For the Bisection method to retain its ability to compute eigenvalues of any order, our strategy is to make the underlying iteration loop parallelizable. Instead of counting Sturm sequences iteratively, Algorithm 4 (provided in
Section 3) distributes the task into the submatrices, which can be fulfilled independently. To merge these submatrices, in
Section 2, we give a special determinant Formula (
2) (with our new proof inspired by Maxwell’s reciprocity theorem), Corollary 1, and Theorem 3.
We give Algorithm 5 in
Section 4 as a modified Bisection method for all the eigenvalues. To reduce the number of iterations, the key is called a faster root-finder, which has less than
time cost of the traditional Bisection iteration process. However, it can only work when an isolating interval, i.e., an interval within only one eigenvalue, is obtained. Theorem 3 provides an excellent approach to such an interval, and the calculation is executed by dividing and merging. To accelerate convergence, we prove Theorem 4 in
Section 4 and utilize the deflation property in Algorithm 5.
In
Section 5, we analyze the accuracy and present the numerical experiments.
Section 5.2 shows the accuracy results and
Section 5.3 shows the efficiency result. In
Section 5.3, diversified computing tasks are discussed and the feasibility is analyzed. The results show that the new Divisional Bisection method can substantially improve the efficiency of the Bisection algorithm while maintaining its accuracy and flexibility.
2. Dividing the Matrix
The sequential principal minors of an ST (Symmetric Tridiagonal) matrix form a Sturm Chain, which is the key to the Bisection algorithm. We denote the ith sequential principal minor of a matrix A by , which is similar to the conventions in Matlab. The submatrix of A in rows i through j will be denoted by ; A is determinant by . We denote the characteristic polynomial by , , or if necessary.
Let
A be an
unreduced ST matrix (all ST matrices discussed in this paper are unreduced),
be its
ith eigenvalue,
be its
ith eigenvector and
be the
jth component of
. Then, we have the iterative formulae of the ST determinants from [
34] as
where
and
.
The Bisection method counts Sturm sequences by
q or
p. The number of eigenvalues that are less than
u is equal to the number of negative
q values, while the number of
is equal to the non-negative
q’s. The neighboring
and
have the following theorem from [
12].
Theorem 1 (Root Separation Theorem).
has only simple roots, which are separated strictly by the roots of , for .
From Theorem 1, we have the following corollary.
Corollary 1. The signs of and in the intervals separated by their roots can be expressed aswhere denotes the kth root of and denotes the kth root of . Proof. As
, we have
Considering that has only simple roots (Theorem 1), the result shows. □
We stress Theorem 1 and Corollary 1 here because they are not only the basis for the following Theorems 2 and 3 but also support our subsequent algorithms and analyses. When merging the submatrices, we use Corollary 1 and the signs of
values to decide the global
in Algorithm 4. The accuracy of original iterations in Algorithm 5 is analyzed through Theorem 1 and Corollary 1, which guarantee that the original results can be checked and fixed with an acceptable iteration number (this process is carried by Algorithm 7). See more details in
Section 3 and
Section 5.
Recall that our task is to count Sturm sequences in submatrices; then, it is convenient to calculate
q values and
p values from both ends of
A. A specific determinant formula shows the connection between
and
and
or
and
, which is from [
36]. Here, we present a new proof inspired by Maxwell’s reciprocity theorem.
According to Maxwell’s reciprocity theorem, the output at j caused by input at any point i in a linear system is equal to the output at i caused by equal input at j. If we consider the ST matrix A to be a dynamical system, the following lemma holds.
Lemma 1. For an invertible symmetry matrix A, if and then , where x and y are both column vectors.
Proof. It can be easily established by symmetry. □
Theorem 2 (Determinant Formula).
Let a be the diagonal of an unreduced ST matrix A and b be the sub-diagonal, we have Proof. Let:
substitute them into (
1), then we have
when uniting (
1) and (
3).
Construct a vector
z so that
where
is a nonzero scalar.
Unite (
4)–(
6); then, the result shows. □
Remark 1. (2) can also be expressed as In addition, although u should not be an eigenvalue of A in Lemma 1, (2) also holds for all valuesof A. To prove this, we need to check the existence of x and y first, as is a singular matrix. We have in (4), which means x and y are both eigenvectors. Consider the eigenvectors-from-eigenvalues formula (see [37])where denotes the minor formed from A by deleting the jth row and column of A. As A is symmetric and tridiagonal, (7) can be expressed as Let , from (8) we have Consider Theorem 1; then, it shows that the eigenvector of an ST matrix has no zero components at both ends. So, existence is guaranteed. Then, the result can be easily verified by the continuous prolongation theorem.
Remark 2. The determinant formula is introduced in [36] (page 518, Equation (5)), which gives a form of a general tridiagonal matrix, not having to be symmetric. (2) is the specific form for symmetry. Nevertheless, we insist on presenting this different proof here because some intermediate products of the derivation process consist of the basis of Theorem 4, which is one key technology to accelerate Algorithm 5. See more details in Section 4. Theorem 3 (Interlacing Property). If and do not have a common root, the roots of (i.e., the eigenvalues of ) separate the eigenvalues of A strictly; if not, the common roots are some eigenvalues of A and the others still separate strictly. In addition, Corollary 1 also holds for and .
Proof. According to [
12,
38], we have
where
denotes the
ith eigenvalue of
.
If
and
have a common root, it can be easily seen from (
2) that
; if not, we have
similarly.
So, the equal signs hold if and only if and have a common root. □
With Theorem 2 and 3, we now divide the unreduced ST matrix A into and , and we count the negative Sturm sequences of a tentative eigenvalue u independently. In , is the number of negative values () and is the negative values () in . Let ; apparently, it is equal to the number of eigenvalues of that are less than u. Thus, the sign of is . According to Theorem 3, this also means . Theorem 2 shows the connection between the sign of and the sign of . Thus, the final , which is either equal to the previous or , can be concluded with a cheap merging calculation. See more details in the next section.
3. Computing One ST Eigenvalue
We now consider more details of the Divisional Bisection method. First, we introduce Algorithm 1 for computing
,
and
in an unreduced
ST matrix
A according to [
34], and the simplified variant Algorithm 2, for the determinant only.
| Algorithm 1: Bisection Iteration |
![Mathematics 10 02782 i001]() |
| Algorithm 2: Computing ST Determinant |
![Mathematics 10 02782 i002]() |
If
as discussed in
Section 2, we have
according to (
2) and Corollary 1. Then, we have
and
when
. When
, which means (
10) cannot be calculated, we directly obtain
according to Theorem 3. Similarly, we have
if
and
are both zeros.
In the lower level, is divided into and . Independently, we calculate
- 1.
, , and in by Algorithm 1;
- 2.
, and in by Algorithm 1;
- 3.
and in by Algorithm 2.
And the same in .
By substituting these outputs into (
2), (
10) and (
11),
- 1.
, ;
- 2.
, ;
- 3.
, .
These are determined, and then, we have
finally, completing one Bisection iteration. The new Divisional Bisection iteration method is given by Algorithm 3.
| Algorithm 3: Divisional Bisection Iteration |
![Mathematics 10 02782 i003]() |
Algorithm 3 calls Algorithm 2 to compute
extra determinants of the submatrices compared to the traditional method. So, the parallel efficiency of Algorithm 3 is
, given that the cost of the merging part is negligible compared to the cost of Algorithms 1 and 2 called during computation. It should be noted that counting non-negative
q values instead is more efficient if a high-order eigenvalue is desired. By replacing the iterative process, we give the new Divisional Bisection Algorithm 4 for computing one ST eigenvalue.
| Algorithm 4: Computing One ST Eigenvalue |
![Mathematics 10 02782 i004]() |
In addition, it can be predicted that a considerable number of Divisional Bisection iterations will end early, especially for the lower or higher order eigenvalues. To find the smallest eigenvalue of a matrix, for example, we can break the iteration in advance if any , which means the final number will inevitably exceed 1 according to Theorem 3. This strategy can save substantial time in the early computation and more if a larger p is available.
4. Computing All ST Eigenvalues
The Bisection algorithm has many practical advantages but earns the disrepute of being slow when computing all ST eigenvalues. A significant contributor is the excessive number of iterations. The Bisection algorithm permits an eigenvalue to be computed with 53 iterations in IEEE double-precision arithmetic. When an eigenvalue is isolated in an interval, we have some faster root-finders such as Laguerre’s method [
12,
39], the Zeroin scheme [
40,
41] and the fzero scheme [
42] (‘fzero’ function in Matlab). These competitors can finish the work in less than 10 iterations but seem to stumble when eigenvalues cluster. Another trouble is that so much more has to be completed in the inner loop [
39,
43] to obtain isolating intervals, costing embarrassingly more time.
Our strategy is to obtain isolating intervals by the eigenvalues of . These eigenvalues can be obtained by QR or a Bisection algorithm on each submatrix. The clustering eigenvalues, which can be challenging problems otherwise, accelerate the calculation in our method according to Theorem 3. The submatrix under continuing division (if necessary) has no eigenvalues clustered eventually. Then, we can compute all the eigenvalues by dividing and merging. For convenience, we choose the ‘fzero’ function in Matlab as the root-finder, which requires an average of 7.5 iterations per root. Our numerical experience supports this conclusion.
It has been found in [
31,
38] that the deflation properties and techniques of the DC algorithm allow it to converge quickly when the eigenvalues of submatrices cluster or the eigenvectors have zero ends in finite precision arithmetic. These deflation cases are quite common in ST matrices and should be utilized in the Divisional Bisection algorithm. Let
be the expected precision and
be the eigenvalues of
, which can be divided into
and
. From [
38] we have
where
and are the eigendecomposition of and ;
is the last row of ;
is the first row of ;
the diagonals of and are arranged in ascending order.
Now, consider how deflation occurs during the calculation and how our algorithm can perceive it. In (
12), the close eigenvalues of
and
can be easily detected, since we do the calculation by dividing and merging. However, the connection between zero ends of
or
and the intermediate results of Bisection iterations are not easily accessible. Therefore, we give Theorem 4, especially Theorem 4b, to show the deflation properties and to suggest an approach to detecting. First, we introduce the following Lemma 2 as an auxiliary for our proof of Theorem 4.
Lemma 2. Let and be real symmetric matrices with eigenvalues and , respectively. Then Theorem 4 (Deflation Properties).
If where and are arithmetic approximations of and , then or is an arithmetic approximation of ;
Let u be an arithmetic approximation to which is one of the ’s and . If
- (1)
;
- (2)
,
where , then u is an arithmetic approximate eigenvalue of A, and the similar holds in .
Proof. It can be easily seen from Theorem 3.
Without loss of generality, we assume is an isolated eigenvalue of because if not, we can turn to Theorem 4a.
From (
3) and (
4), it shows
is the last component on the diagonal of
. Then, we have
where
is the
jth eigenvector of
.
As
is the determinant of
,
should be close to zero when
. However, in IEEE double precision arithmetic, this is not true if
is also small when compared to
. (
13) can be expressed as
where apparently (recall that
)
Given that
u is the previous computation result, we have
. When
, (
14) and (
15) can be united as
In addition, we have
similarly when
.
The condition of Theorem 4b shows
according to (
17). By taking a review of (
12) and Lemma 2, the proof is completed. □
Theorem 4 is satisfying because values of and values of happen to be accompanying products of Algorithm 2, which can be utilized as the basic iteration of the ‘fzero’ scheme. The condition of Theorem 4b is sufficient but not necessary, as there are many other possibilities that make , even when . A trivial plan is to calculate and check once one is solved and the accompanying is suspiciously small. Although this idea already saves a large number of unnecessary computations compared to the DC algorithm, we are still concerned that it is too expensive to call the Inverse Iteration algorithm here.
Our scheme is to mark those suspicious small
values by a rough discriminant, for example
, then to substitute the corresponding
values into Algorithm 1 to check if deflation is available. We have found in our numerical experiments that it is difficult to cover all the deflation situations by this method, even if we set the discriminant quite loosely. Even filtrating directly by
, as in the DC algorithm, would still leave some out. We applied these methods to 20 randomly generated
matrices for computation, where
and
are both
matrices. The averages were calculated and are shown in
Table 1. We collected the hit rate of the DC algorithm by checking how many
values, which had negligible corresponding
values, were really close to
values. In
Table 1, the plan 1 refers to “rough discriminant + Inverse Iteration algorithm”, the plan 2 refer to “rough discriminant + Algorithm 1”, and the hit rates of them were collected similarly. It can be seen that the hit rate and accuracy of our method are acceptable or at least no worse than the DC algorithm. The errors in
Table 1 refer to the difference between
values selected during deflations and
values obtained by the Bisection method. The data were collected on an Intel Core i5-4590 3.3 GHz CPU and 16 GB RAM machine. All codes were written in Matlab2017b and executed in IEEE double precision. The machine precision is
.
We give the Divisional Bisection method for all eigenvalues by Algorithm 5 and the following subroutine Algorithm 6.
| Algorithm 5: Computing all ST Eigenvalues |
![Mathematics 10 02782 i005]() |
| Algorithm 6: Fzero by Determinant |
Input: a, , n, V, Output: x, - 2
call Algorithm 2 ⇐a, , n - 3
call ‘fzero’ function in Matlab ⇐ Algorithm 2, V, - 4
then get x - 5
save of the last iteration.
|
5. Accuracy Analysis and Numerical Results
5.1. Accuracy Analysis
After the eigenvalues of the original submatrices are calculated by the QR Algorithm, as shown by line 3 in Algorithm 5, it is not safe to take
as a
if one
, because the QR algorithm is not always as accurate as the Bisection method or fzero scheme. So, in practice, we do an extra check for the selected
values by Theorem 4a when checking deflation from results of the QR Algorithm. Suppose
m sub-eigenvalues (denoted by
) cluster in the interval
where
; the process is shown as Algorithm 7.
| Algorithm 7: Recheck the Results of QR |
![Mathematics 10 02782 i006]() |
In Algorithm 7,
is a pessimistic estimation of QR algorithm error, which means it decuples that of the Bisection error. The data in
Table 2, which are present in a later paragraph, supports our point. Line 2 in Algorithm 7 costs 2 Bisection iterations for
values and line 10 costs 3 to 4 per
compared to about 7.5 iterations per
in Algorithm 6 and 53 iterations per
in the Bisection algorithm.
When arithmetic approximations
are treated as the boundaries of isolating intervals in the next level, they do not affect the accuracy because if the number of
’s in an interval is not one, Algorithm 6 fails. The troublesome number could be 0 or 2, but it is certainly not bigger than 3. When there are 4 or more
’s in an interval, it means there are clustering
’s of the previous results which can be perceived during the deflation check. For example, if 4
’s lie in
as
we have
where
is the previous computation error. (
18) shows that
and
both lie in
, which could not happen because we do the deflation check previously.
We regard this as a beneficial situation. It can be seen in (
18) that the troublesome number arises only when
(or
), contrary to Theorem 3. As the accurate
and
, we have
and then can speed up the calculation. Finally, the accuracy of Theorem 5 is as good as the Bisection algorithm.
We checked the accuracy of Algorithm 5 by computing the eigenvalues of a
Toeplitz ST matrix, which has all 2’s on its diagonal and all
’s on its sub-diagonal. The results of each method were then compared with the exact value, i.e.,
, and are shown in
Table 2. In addition, all eigenvalues of 20 randomly generated matrices were calculated for testing the efficiency on serial machines, and we show the average results of 20 in
Table 3. We set
in Algorithm 5 for the serial execution.
Table 2 demonstrates that our method substantially improves the speed of the Bisection method without losing accuracy. In addition,
Table 3 confirms that Algorithm 5 is
as its iteration based on Algorithm 2. In the following subsections, we illustrate more test results of several different types of matrices. All results in
Section 5 were collected on an Intel Core i5-4590 3.3-GHz CPU and 16-GB RAM machine, except for the last figure, which will be introduced in
Section 5.4 specifically. All codes were written in Matlab2017b and executed in IEEE double precision. The machine precision is
.
5.2. Matrices Introduction and Accuracy Test
In the following subsections, we present a numerical comparison among the Divisional Bisection algorithm and four other algorithms for solving the ST eigenvalue problem:
- 1.
Bisection, by calling subroutine ‘dstebz’ from LAPACK in Matlab;
- 2.
MRRR, by calling subroutine ‘dstegr’ from LAPACK in Matlab;
- 3.
QR, by calling subroutine ‘dsteqr’ from LAPACK in Matlab;
- 4.
PWK version of QR (which would be denoted by QR-pwk in the figures), by calling subroutine ‘dsterf’ from LAPACK in Matlab.
We use the following sets of test matrices:
- 1.
Matrix A:
i.e., the Toeplitz matrix [1,2,1] to test the accuracy and efficiency, which has
;
- 2.
Matrix T1:
to test the accuracy and efficiency, which has
. Matrix T1 is from [
45], as well as the following Matrix T2 and T3;
- 3.
Matrix T2 [
45]:
to test the accuracy and efficiency, which has
;
- 4.
Matrix T3 [
45]:
to test the accuracy and efficiency, which has
;
- 5.
Matrix W [
12,
46], which has the
ith diagonal component equal to
(
n is odd) and all off-diagonal components equal to 1, to test the efficiency only as its exact eigenvalues are not accessible;
- 6.
Random Matrix with both diagonal and off-diagonal elements being uniformly distributed random numbers in [−1,1] to test the efficiency only as its exact eigenvalues are not accessible.
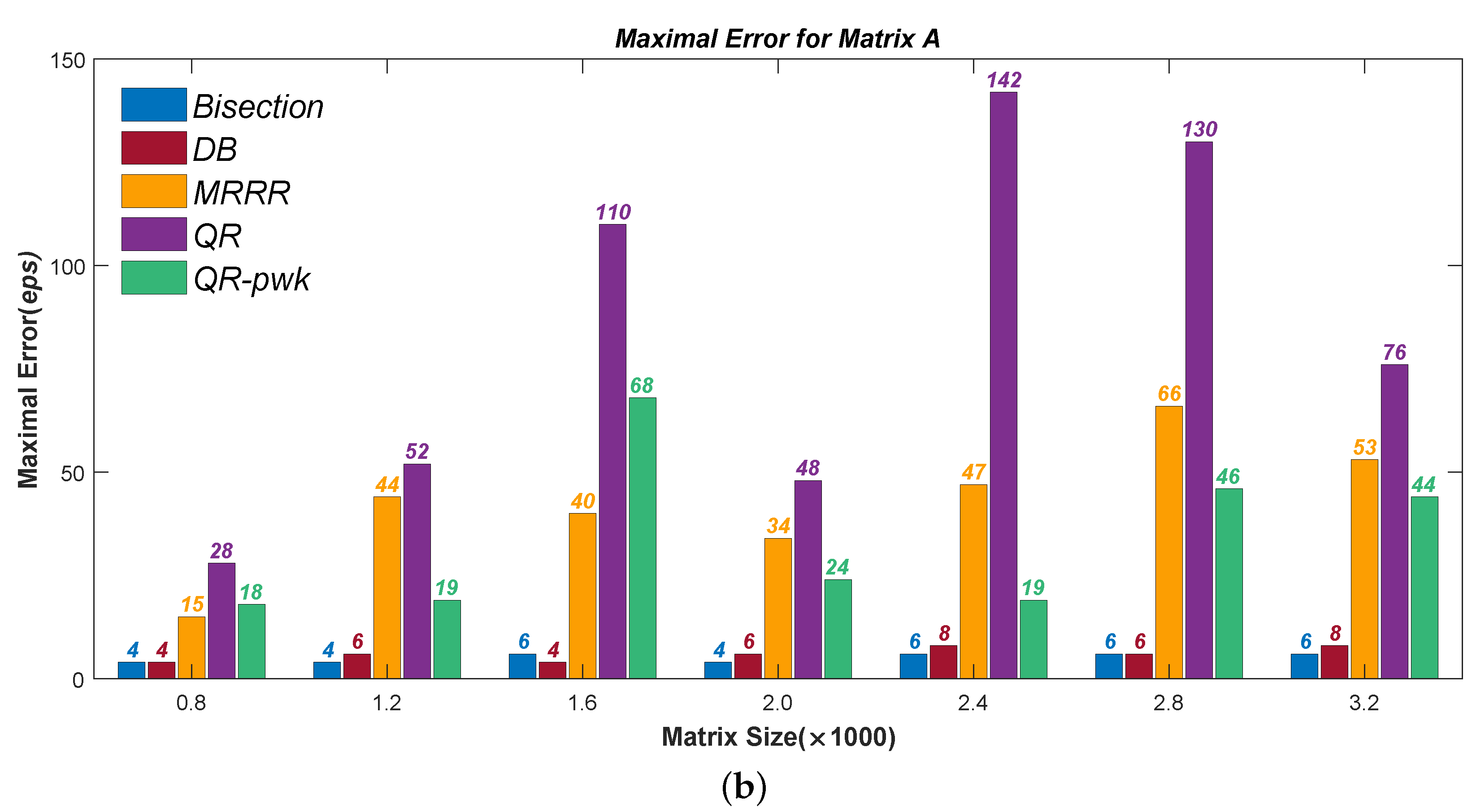
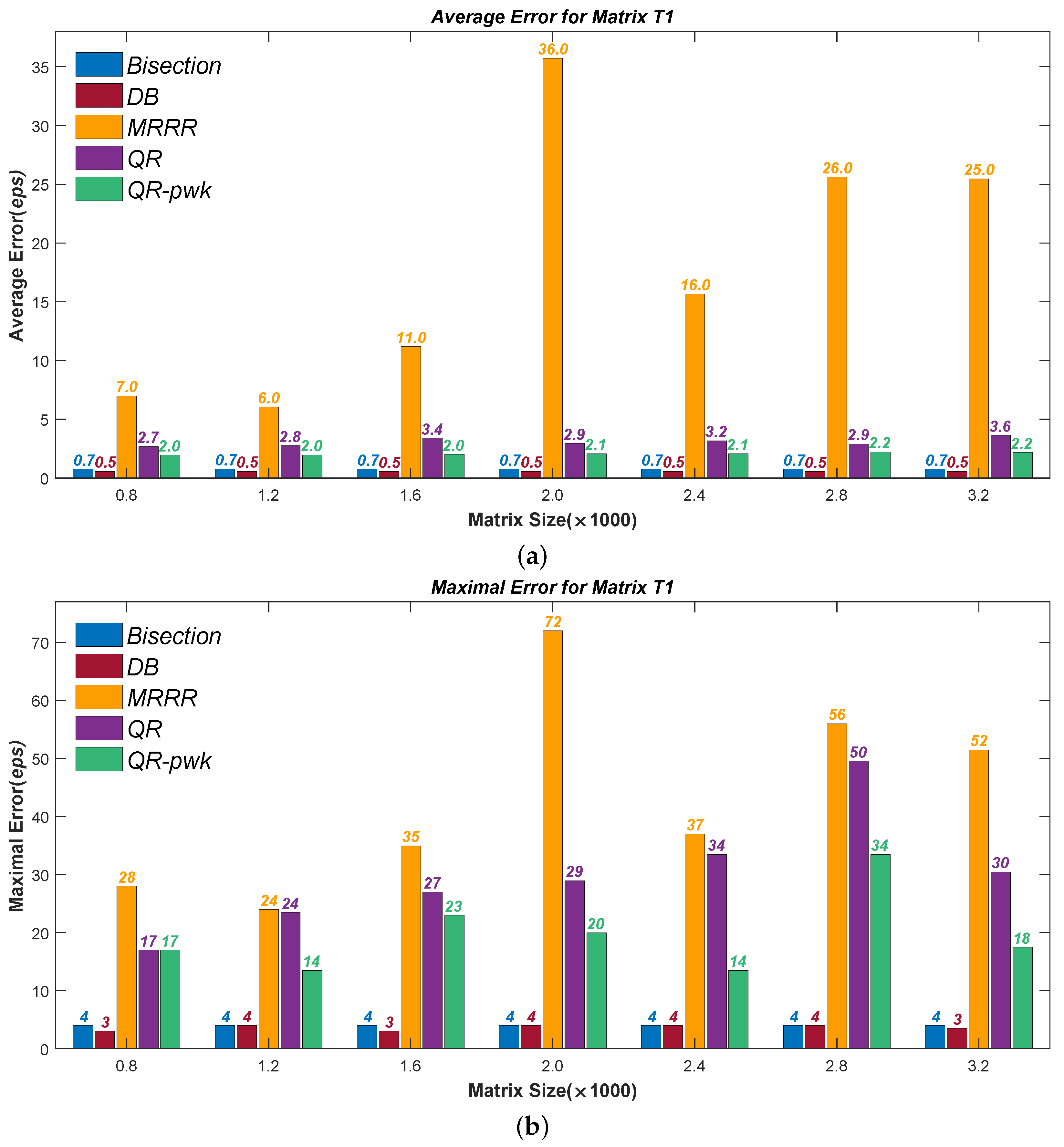
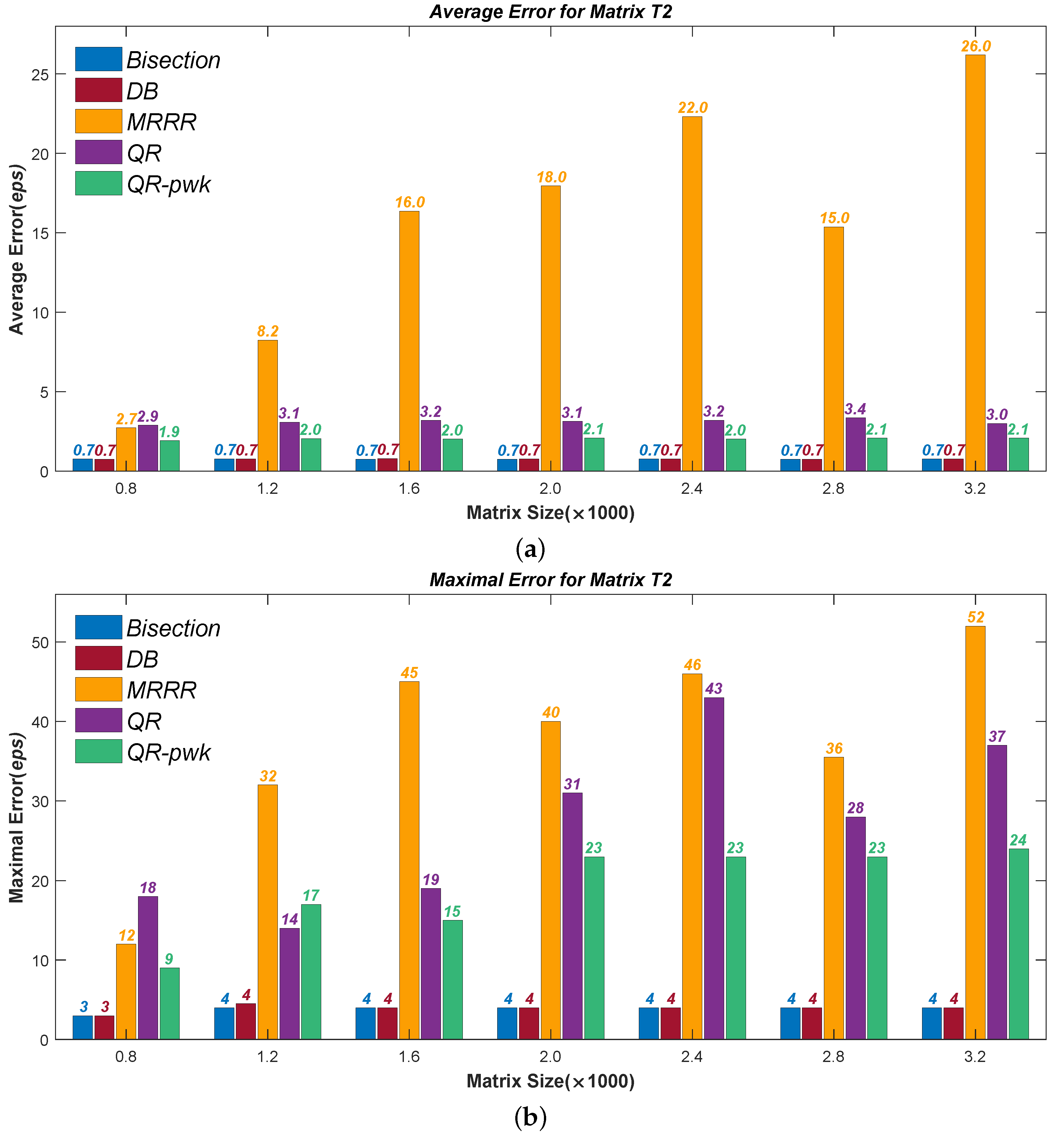
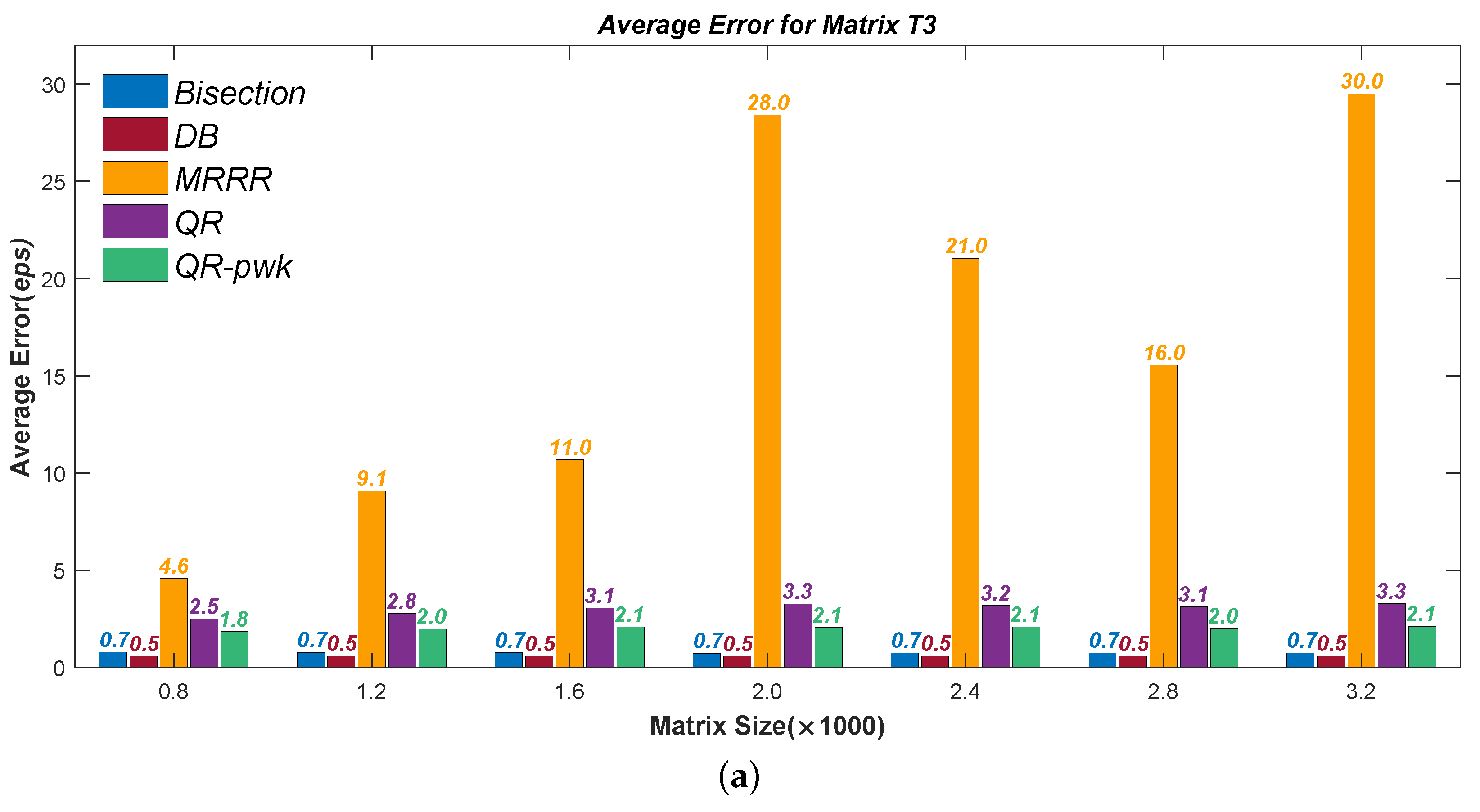
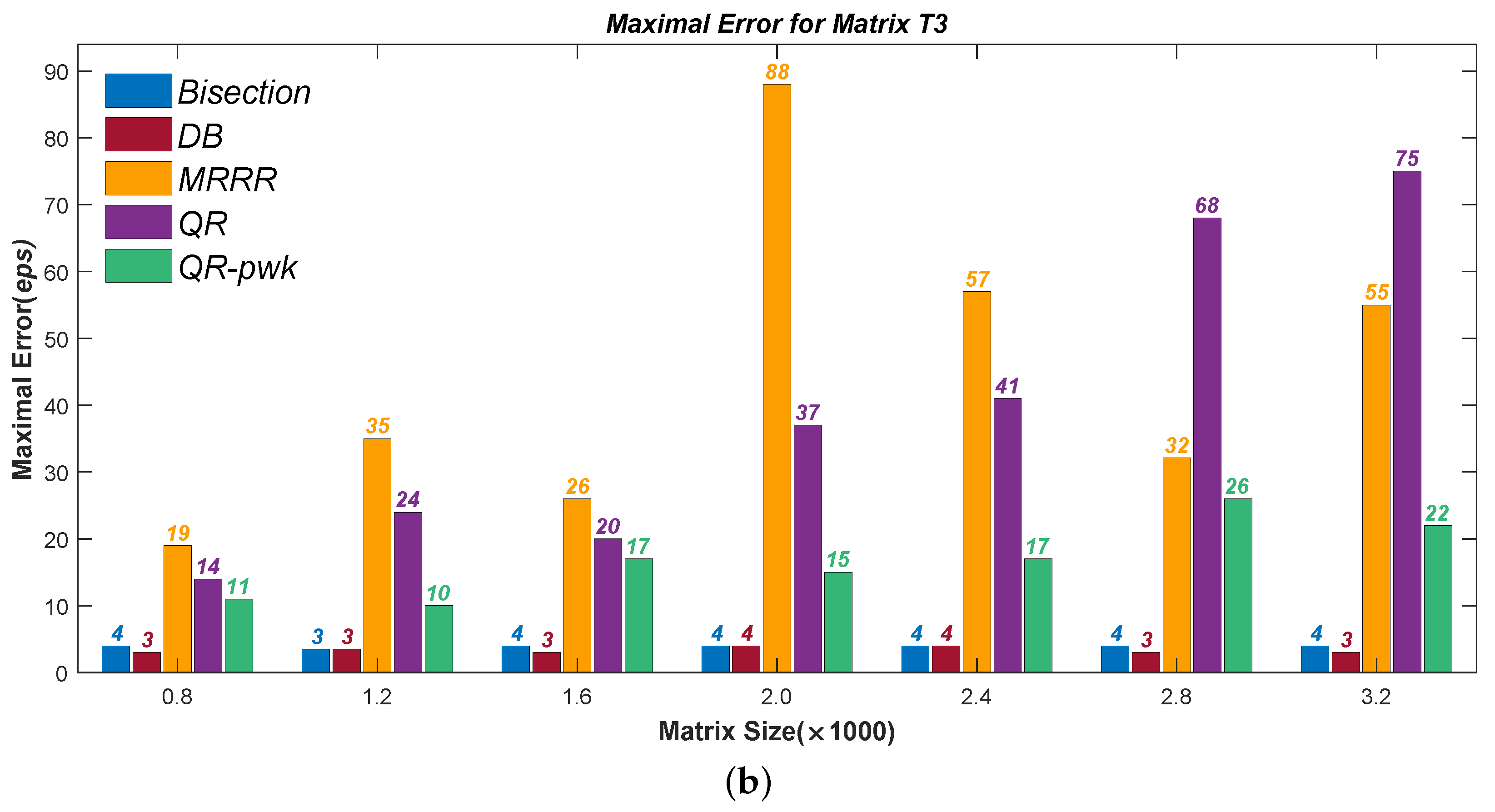
Figure 1,
Figure 2,
Figure 3 and
Figure 4 present the test results of accuracy, where the Average Errors denote the means of errors of all the calculated eigenvalues and the Maximal Errors denote the maximum. Seven different sizes are used, from
to
. All errors have been divided by the machine precision
for clarity. It can be seen that the new Divisional Bisection algorithm has the best accuracy as well as the Bisection method, considerably higher than the others.
5.3. Efficiency Test for Computing all the Eigenvalues
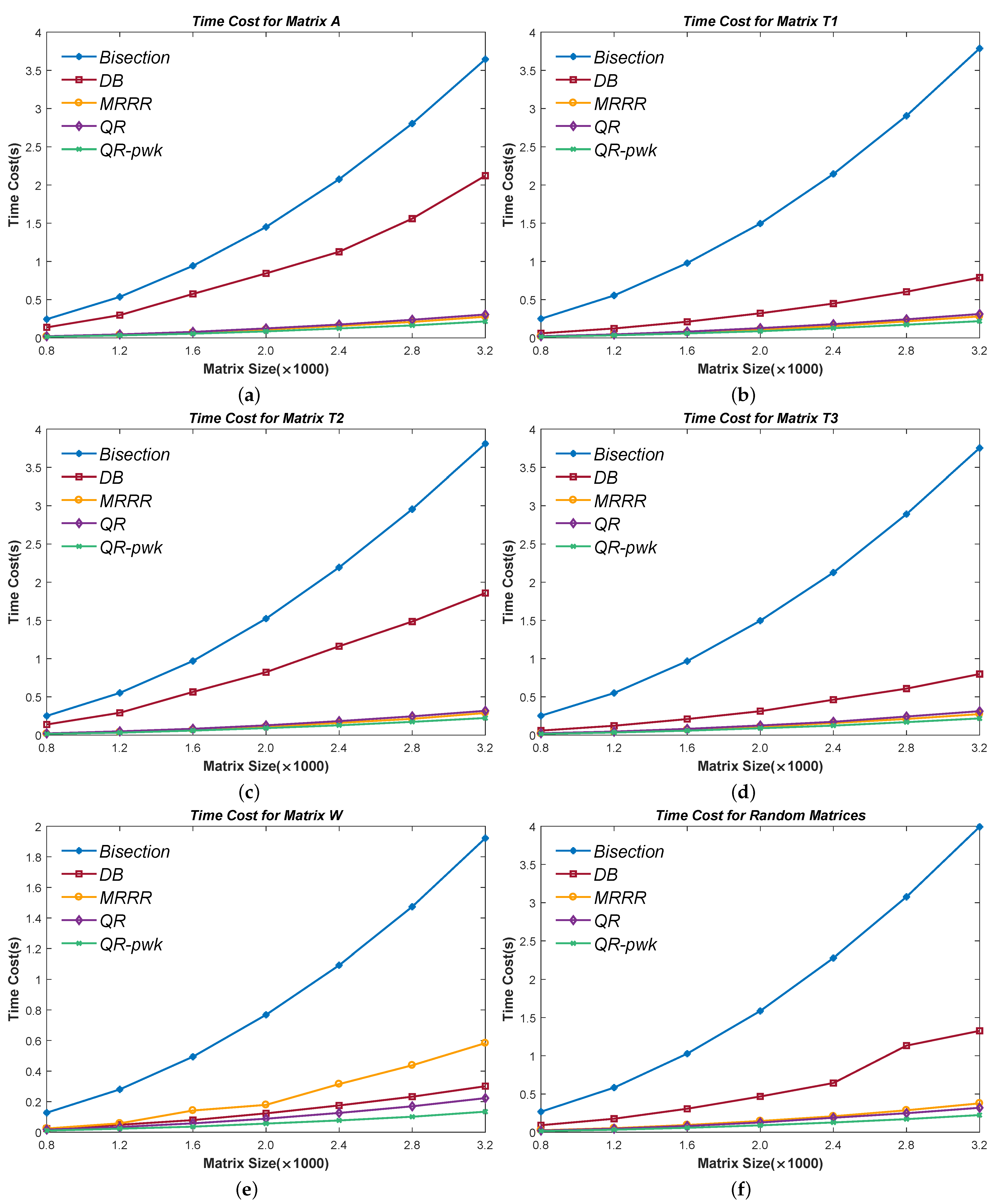
Figure 5 presents the test results of time cost. Seven different sizes are used, from
to
. Note that the results of the Random Matrix of each size are the mean data of 20 tests. Therefore, we use the plural form in the figures.
When the eigenvalues clutter, as in Matrix W, the Divisional Bisection method improves the Bisection method by about . Such a good result can also be in Matrix T1 and Matrix T3. However, the improvement is less than in Matrix A and Matrix T2. The reason is their submatrices have close eigenvalues to the global one but are not equal in finite precision arithmetic. For example, the sub-eigenvalues give an interval for Algorithm 6 and have an upper or lower bound that has a distance between less than . The ‘fzero’ scheme uses the linear interpolation to accelerate convergence; such a bound produces poor slopes during the linear interpolation process. As a consequence, more iterations are needed to guarantee convergence, which finally results in the efficiency loss of the Divisional Bisection method. Recall that Algorithm 7 is for checking similar situations. However, a distance of could not be detected, because it does not meet the conditions of Theorem 4.
Nevertheless, we are not pessimistic about the Divisional Bisection method. First, it still improves more than in such cases and performs well for Random Matrices. Secondly, the ‘fzero’ scheme is not a prerequisite or non-replaceable in our method, which could be modified or substituted by a more powerful competitor in future follow-up studies.
5.4. Efficiency Test for Computing a Part of the Eigenvalues
All along, the Bisection method undertakes the task of computing a part of eigenvalues, especially when the size of the matrix is large. When Algorithm 5 obtains all the sub-eigenvalues, as shown in lines 2–11 in Algorithm 5, it is an easy task to calculate any parts of ’s. For example, if eigenvalues in a certain interval are wanted, we can drop the sub-eigenvalues which are outside and substitute , in Algorithm 5 line 2 and line 15, with the upper and lower bounds of the given interval. If th∼th eigenvalues are wanted, we need to drop the sub-eigenvalues that are of the order lower than or higher than . When and are the substitutions of , the problem can be solved.
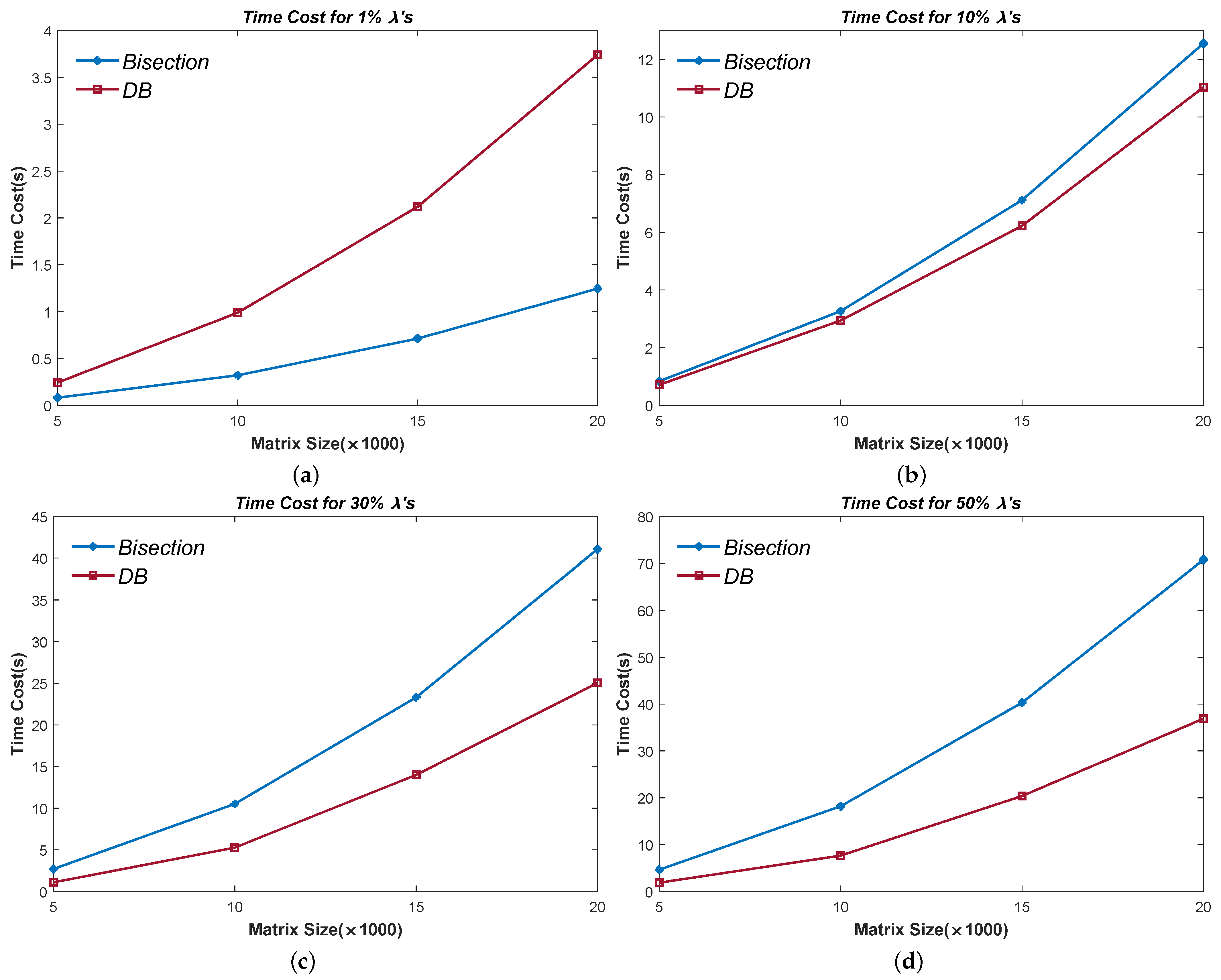
Figure 6 shows the time cost in Random Matrices of four relatively large size, i.e.,
, 10,000 × 10,000, 15,000 × 15,000, and 20,000 × 20,000. We calculated
,
,
, and
’s of each size. Note the results are mean data of 40 tests, 20 for computing
’s in a certain interval and 20 for computing
’s in a certain order. Given that there is no evident difference between the test results of calculating
’s in an interval or order, we mixed them for averaging.
The results show that the Divisional Bisection method is not suitable for computing a small group of eigenvalues, despite the matrix being relatively large. We consider as an applicable threshold. Although we can replace the QR method with the Bisection method in Algorithm 5 line 3, which could avoid the calculation of all the sub-eigenvalues, the result seems even worse. As the matrix size increases, the efficiency disadvantage of the Bisection method becomes increasingly severe, which could ignore only a quite small number of wanted , for example, . In this case, the ‘fzero’ loops (line 12 to line 24 in Algorithm 5) become a heavy burden to the Divisional Bisection method. Therefore, we insist on using the PWK version of the QR method in Algorithm 5.
We now consider the situation of calculating one
in parallel. The problem also arises when the number of wanted
is less than the number of CPU cores or not divisible by it. Algorithm 4 solves the problem and makes it available for computing with any number of CPU cores. Of course, the need to compute an eigenvalue in parallel must occur in a very large matrix. Therefore, we use three Random Matrices with sizes of
,
, and
for the test of parallel efficiency. The results, presented in
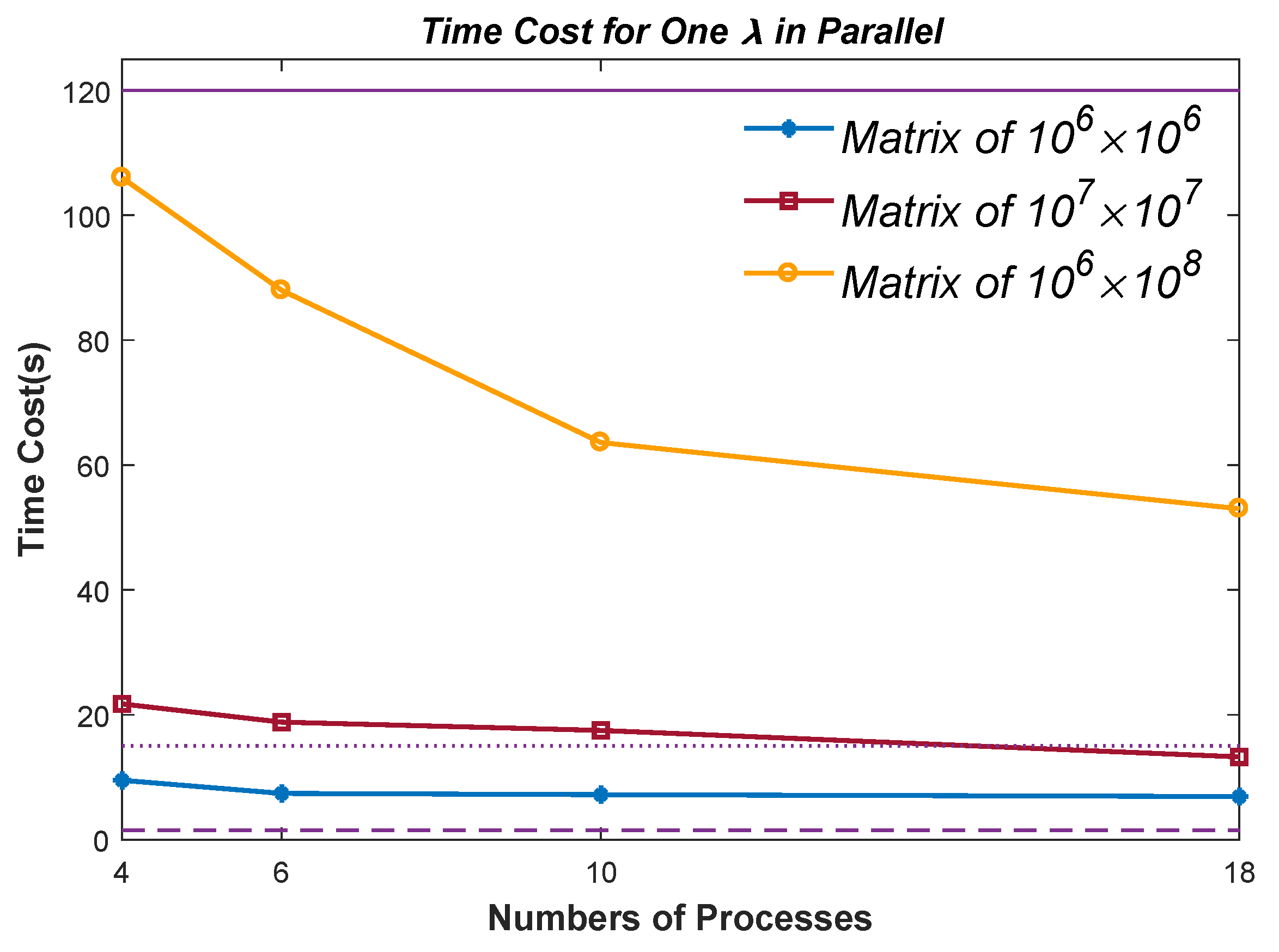
Figure 7, were collected on an Intel Xeon(R) Core E5-2687 3.1-GHz CPU and 256-GB RAM machine, which has 20 CPU cores. Note that the results are mean data of 20 tests.
The three purple horizontal lines in
Figure 7 denote the time cost of the serial Bisection algorithm. Specifically, the top one denotes the time cost for
Random Matrices, the middle
, and the bottom
. The parallel efficiency is unsatisfactory, especially for the
and
Random Matrices, which are even worse than the serial Bisection algorithm. The reason is that Matlab is not available for multi-threaded computation. Instead, we run the codes in multi-processes. The task of copying inputs and distributing them to the processes takes up the vast majority of the time. The script time consumption analysis tool in Matlab confirms our point, which shows at least
time was consumed during copying and distributing. Therefore, we would focus on the version written in C or Fortran of the Divisional Bisection algorithm in future follow-up studies. Nevertheless,
Figure 7 verifies the feasibility of Algorithm 4, which to our knowledge is the only algorithm that works in parallel for computing any one ST eigenvalue. This paper also focuses on the serial version.



















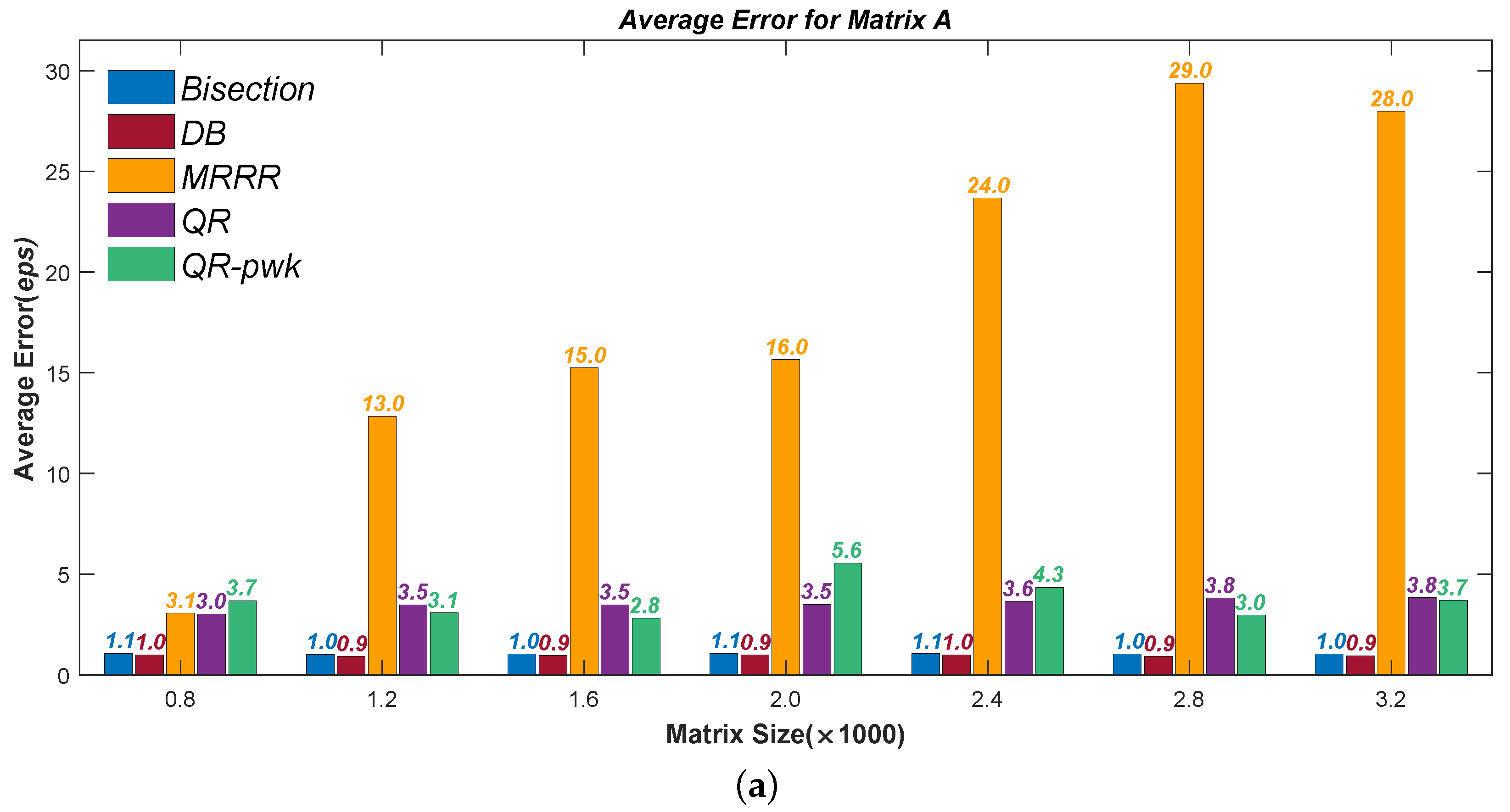{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}