
Describing Linguistic Vagueness of Evaluative Expressions Using Fuzzy Natural Logic and Linguistic Constraints


Abstract
:1. Introduction
2. Fuzzy Natural Logic: Formal Prerequisites
- Fuzzy set. A fuzzy set A in a universe U, is a function where is a support of the standard Łukasiewicz MV-algebra . The are lattice operations (here equal to min and max), are Łukasiewicz conjunction and implication, respectively defined bywhere . The set of all fuzzy sets on U is denoted by . If A is a fuzzy set then its kernel is a set .
- Lakoff’s hypothesis of universal meaning. According to Lakoff [8], natural logic is a collection of terms and rules that comes with natural language and allows people to reason and argue in it. This idea captures the basic principle of why people understand each other. This principle is universal in all languages and makes communication among people possible.
- Evaluative linguistic expressions are those expressions of natural language used by people to characterize features of objects or their parts [1,5,12] such as length, beauty, size, complexity, economical value, kindness, among others. The most elaborated evaluative expressions in FNL simple evaluative ones. They have the general formcan be grouped to form a fundamental evaluative trichotomy consisting of two antonyms and a middle term, for example , , , etc. The triple of adjectives is taken as canonical. On the other hand, makes more or less specific the meaning of the . Usually it is represented by an intensifying adverb such as “very”, “roughly”, “approximately”, “significantly”, etc. This is a special expression representing a linguistic phenomenon called hedging. In some papers of FNL, is found as .
- Possible world. It is a specific context in which a linguistic expression is used. In the case of evaluative expressions, it is characterized by a triple . Without loss of generality, it can be defined by three real numbers where . These numbers represent an interval of reals where is marked to emphasize position of “typically medium”.
- Intension. The intension of a linguistic expression is a property denoted by a specific word or expression. It is independent on a concrete possible world (context) and does not change when the context is changed.
- Extension. The extension of a linguistic expression is the referent. It depends on the particular context and changes when the possible world changes. With the exception of few specific cases, the elements falling into an extension are delineated vaguely. In our theory, they are accompanied by degrees. For example, the expression “very long distance” has always a high degree in any context of distance (possible world). Thus, “very long distance in Europe” is “1000 km” when “driving a car”, while it is “5 km” when “walking on foot”. In such case, extensions are fuzzy sets in the intervals and .
3. Fuzzy Property Grammar
- General or universal constraints that are valid for a universal grammar (any language).
- Specific constraints that are applicable to a specific grammar.
- Prototypical constraints that definitely belong to a specific grammar, i.e., their degree of membership is 1.
- Borderline constraints that belong to a specific language with some degree only (we usually measure it by a number from [0,1]).
- -
- Linearity of precedence order between two elements: A precedes B, in symbols . Therefore, a violation is triggered when B precedes A. Example: “The () professor ()”, (). stands for satisfied constraint.
- -
- Co-occurrence between two elements: A requires B, in symbols . A violation is triggered if A occurs, but B does not. Example: “The () girl () plays football”(), but “girl () plays football”(). stands for violated constraint.
- -
- Exclusion between two elements: A and B never appear in co-occurrence in the specified construction, in symbols . That is, only A or only B occurs. Example: “He () does yoga”, (), but “He () boy () does yoga”().
- -
- Uniqueness means that neither a category nor a group of categories (constituents) can appear more than once in a given construction. For example, in a construction X, . A violation is triggered if one of these constituents is repeated in a construction. Example: “The () the () kid that who used to be my friend”(in nominal construction: ).
- -
- Dependency. An element A has a dependency on an element B, in symbols . Typical dependencies (but not exclusively) for are (subject), (modifier), (object), (specifier), (verb), (conjunction). A violation is triggered if the specified dependency does not occur. Example: “Andorra is a small () country ()”, (), but “Andorra is a small () goodly ()”, ().
- -
- Obligation. This property determines which elements are heads. It is expressed by the symbol □. This property tends to be avoided since FPGr pursues to define the relationship of part-of-speech without hierarchy or derivation, only at a local level. However, it is useful to define specific constructions to express the mandatory appearance of a category or linguistic feature.
- Linguistic Feature. Features specifies when properties are going to be applied to a category. The typical feature to be represented is a linguistic function, such as the function of subject: . Features are always written and subindexed in a linguistic category, i.e., .Example 1.A property for an English grammar such as might be inaccurate since the noun can both precede and be preceded by a verb. We can specify functions and other values for a category to provide proper linguistic information thanks to the features. Therefore, property grammars can specify that a noun as a subject precedes a verb: N. Features reinforce properties as a tool that can describe linguistic information independently of a context and more precisely represent grammatical knowledge by taking into account linguistic variation. However, features can express any type of specification from any domain. For this paper, we are interested in semantic features, which will be expressed like the following . Such characterization is useful for words that even being defined with the same category trigger different meanings, i.e., I have a snake, (snake ), John is a snake, (snake ).
- xCategory. An is a feature which specifies that a certain category is displaying a syntactic fit from another category, for example, an adjective with a syntactic fit of a noun. All the are marked with a x before a prototypical category, i.e., . For example, in Spanish, el boxeador () león () (the lion boxer), león () is performing as an adjective; therefore, el boxeador () león ().
- is a phonological constraint} is the set of constraints that can be determined in phonology.
- is the set of constraints that can be determined in morphology.
- is the set of constraints that characterize syntax.
- is the set of constraints that characterize semantic phenomena.
- is the set of constraints that occur on lexical level.
- is the set of constraints that characterize pragmatics.
- is the set of constraints that can be determined in prosody.
- The morphological domain, which defines the part-of-speech and the constraints between lexemes and morphemes. For example, in English, the lexeme of an adjective ≺ (precedes) the morpheme -ly, and the morpheme -ly⇒ (requires) an adjective as a lexeme.
- The syntactical domain, which defines the structure relations between categories in a linguistic construction or phrase. For example, in English, an adjective as a modifier of a noun is dependent () of such a noun ().
- The semantic domain, which defines the network-of-meanings of a language and its relation with the syntactical domain. This can be defined with semantic frames [34,35]. It is also responsible for explaining semantic phenomena as metaphorical meaning, metonymy, and semantic implausibility. For example, in English, object (i.e., ) ⇒ (requires) (i.e., ). A metonymy can be triggered with the follow rule: If asking for something without (i.e., “may I have some water, please?”), then is included as a feature in the frame of object, i.e., .
4. Evaluative Linguistic Expressions with Linguistic Features
4.1. Linguistic Prerrequisites
- Referent. A referent is a person or thing to which a linguistic expression refers. For example, in the sentence Paul talks to me, the referent of the word Paul is the particular person called Paul who is being spoken of, while the referent of the word me is the person uttering the sentence. In the case of the evaluative linguistic expressions, we will understand the referent as the entity which is being evaluated.The referent of the evaluation can be: (1) in the linguistic input, (2) close to the evaluative word, or (3) it can be absent in the linguistic input but present in the extra-linguistic context.Usually, in English and Spanish language, the referent will typically be the subject of the evaluative sentence () if the referent and the evaluation are in a dependency relationship with a . Otherwise, the syntactic head of the evaluative word will establish a modifier dependency with it. This syntactic head will usually be a from the evaluation. For example, in Paul runs fast, the referent of the evaluation runs fast is Paul, not the runs. Therefore, the fact that the evaluative word has a dependency of modifying a , , does not imply that it will be the referent, even though is a higher element in the syntactic hierarchy. Sometimes, a referent can be co-referential. That is, the same referent appears twice in a sentence.For example, Paul had his huge backpack with him. In such case, Paul and him refers to the same person. But, following our definition, the referent of the evaluation is not Paul, but the backpack since it is the one receiving the evaluation.When the referent is in the linguistic input, the evaluative word and the referent will have a relationship of dependence. Such as in Mark watches a bad show on TV. In this case, the referent is a show, and the evaluative word is bad. On the other hand, typically, when the evaluation and the referent are connected with a dependency through a verb, the referent will usually be the subject. For example, Cristina thinks that Claudia is smart enough to pass her degree. The evaluation is is smart enough, and the referent is Claudia. Both constructions have a relationship of dependence, and they are connected because of the verb. However, further exploring to set a frequent pattern of dependency between referent and evaluation is needed.
- Linguistic pairing stands for the task or phenomena in which linguistic features associate two linguistic elements. These can be syntactic or semantic features or both. The most interesting linguistic pairing for adding linguistic features in the evaluative linguistic expressions is the one which pairs the referent with the evaluative word.
- Markedness arises to represent the importance of the linguistic context (not extra-linguistic) for a word. A sentence is more marked than a sentence if is acceptable in less contexts than . It can be determined either by the judgments of the speakers or by extracting the number of possible context types for a sentence [36]. Therefore, a canonical constraint or property () is never context dependent. For example, (). A borderline constraint or property () is context-dependent if the degree of unacceptability triggered by its violation varies from one context to another. For example, in Spanish, canonically, determiners do not precede proper nouns, that is (). However, such constraint can be violated when what the structure is triggering the meaning of a football team, “El () Barcelona () era mejor con Messi que ahora” (“The Barcelona was better with Messi than now”). Such a feature is important to characterize and clarify both the referent and the evaluation. Following the last sentence, the evaluation of was better with Messi than now would have a biased referent if the grammar would understand that the Barcelona meant the city of Barcelona, and not the football club.In this case, the violation of the property, accepted only in few contexts, displays and characterizes a marked structure () ( means semantics), with a marked meaning (), expressed as: .Additionally, in semantics, structures are marked when they do not allow interchangeability of elements, and yet keep the same meaning. A non-marked structure would be: “Mary’s house, the nice one, is in Elm Street”. I change the elements and yet I can get almost same meaning “My sister’s home, the one when you were last time, is next to mine” (knowing that Mary is my sister, the nice one is the one when you were last time and next to mine is Elm Street)’. However, this cannot happen with idioms, or other marked structures such as “Mark is a pain in the ass” by Mark is a pain in the finger/eye/foot/chest/etc., or “it is raining cats-and-dogs” by it is raining elephants-and-giraffes, etc. Therefore, idioms tend to have marked meanings. Another example: “No shit, Sherlock”, meaning ‘judgment over a statement that was obvious’. It is implausible to exchange such construction for other elements such as: No turd, detective, or No smoke, Einstein. Moreover, FNL should not purse to characterize extra-linguistic extreme-implied (non-)evaluations that demand extreme knowledge of the context, such as the one when you were last time understanding that such a construction is a very polite way of saying I am referring to the nice one, not the ugly one.
- Semantic Coercion stands for implausibility of meaning. Coercion is a typical effect in defining and identifying metaphors, which non-literal meanings are triggered due to the implausibility of such meaning. To summarize, it is the similar effect of markedness but focused on the semantic domain.
- Compositionality is typically understood as that the summarization of meanings brings us the final meaning, i.e., “it a strong rain”, meaning: [it + is + a + strong + rain]. However, compositionality does not always work taking into account the previous example it is raining cats-and-dogs. It does not actually mean that animals are falling from the sky!. Therefore, the evaluative sentence it is raining cats-and-dogs does not fall on the logic of compositionality.
- Lexical unit, in FPGr, stands for those structures that work as a single part-of-speech, that is as a single unit, and, therefore, they only count as a one category. For example, in the chief () executive () office () of Amazon is Jeff Bezos; FPGr would parse it as the [chief executive office ()] of Amazon is Jeff Bezos, and not as the [chief () executive () office ()] of Amazon is Jeff Bezos. Therefore, the chief executive office is working as a single . In fact, that is why the tendency is to reduce it to CEO, the CEO of Amazon is Jeff Bezos. The same applies to evaluations such as it is raining cats-and-dogs, which stands for it is raining really heavily or it is pelting down, or it is bucketing down, which stands for it is raining very, very heavily. Therefore, the notion of the lexical unit serves both the evaluation and its referent.
4.2. The Concept of Evaluative Expressions
- (1)
- I love you very much.
- -
- Express affection. The verb love is the evaluative word. The referent is ‘you’.
- (2)
- Plane food is disgusting.
- -
- Express a judgment. The evaluative word is ‘disgusting’. The referent is ‘plane food’. The referent operates as either a lexicalized (‘plane food’ is ), or as a with an adjective fit which modifies the other : ‘plane’ () ‘food’ ().
- (3)
- John is not a bad person, but he can be a snake.
- -
- Express a judgment. ‘Snake’ is fitting a metaphorical meaning, ’treacherous’, and not the animal. The referents are John, and he.
- (4)
- John looked like this (showing at a tomato) when Jennifer asked him for a date.
- -
- Express a judgment. ‘this’ is a deictic work. Thus, it is empty of meaning by itself, and the context is needed to grasp the meaning that is intended to be communicated. The context reveals that it probably means John was shy. Probably is stressed since the meaning is not known for sure. Only an implication can be made by linking the linguistic input, its linguistic context, world knowledge, and communicative context.
4.3. Semantics of Evaluative Expressions
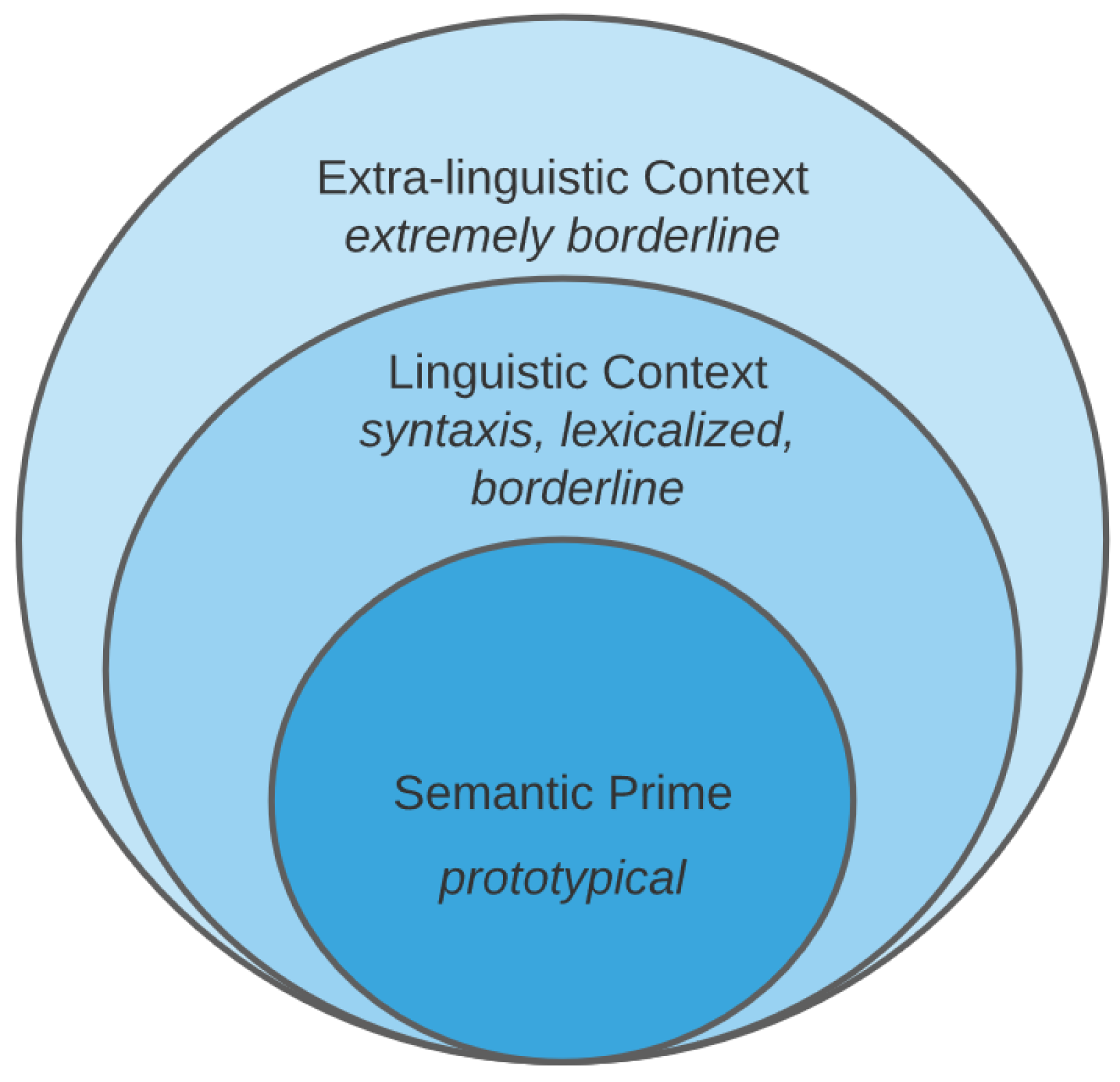
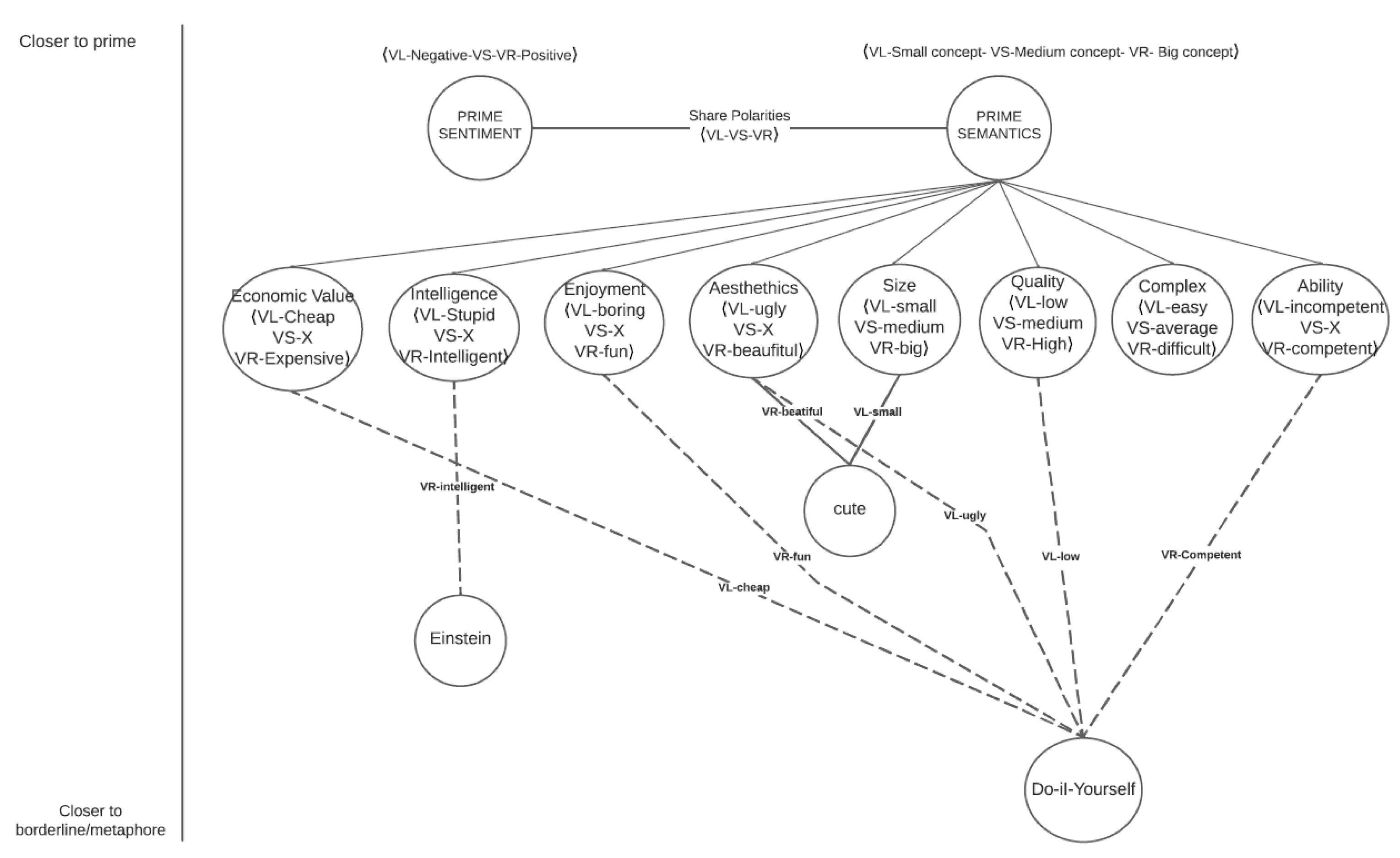
- On the first level, closer to the thought, we will find a semantic prime, always understanding semantic primes as those most abstract concepts which will define a fuzzy set. This idea is inspired in [37]. However, this author considers as semantic primes only the concepts of good-bad. While in this work, we consider primes as all those triplets that create a fundamental trichotomous expression such as [ugly-medium-beautiful], [small- medium-big], [easy-medium-complex], etc. Any prime has to be a prototypical meaning, that is, non-context dependent.
- On the second level, we would find those evaluations that are sensitive to the linguistic context. Those words that are given a specific structure trigger a non-prototypical meaning. That is the case of Example 3), in which the syntactic relation between the referent he, meaning a person, the verb ‘to be’, and the word snake, trigger a borderline meaning on the word snake due to the implausibility that a person would be an actual animal. This effect of implausibility is called semantic coercion [38,39,40,41]. However, it is clear that meaning is not a matter of probabilities in both the semantic prime, and in the linguistic context stage. The semantics of linguistic inputs related with those stages can be characterized using logic and linguistic features.
- On the third level, and further from the semantic prime, we would find those evaluations that need extra-linguistic context. Such concepts can only be understood when the communicative context is known or expresses a common knowledge shared by the interlocutors. Example 4) is a clear example of extra-linguistic meaning. Therefore, it is impossible to extract its meaning from the linguistic input’s information to us. These cases are acknowledged as being extremely borderline. We will not formalize this type of evaluative expression here.
4.4. Syntax of Evaluative Expressions
- I think this is quite right, but…
- Your paint seems a little bit odd.
- (1)
- Mark is very intelligent:.
- (2)
- Mark is an Einstein.
- (3)
- I love Mark’s intelligence very much.
- If the evaluative head is canonically and productively used as an evaluative, the evaluative head is prototypical.
- If the evaluative head is not canonically and productively used as an evaluative, but it passes a constituency test by being replaced by a prototypical evaluative head, then the evaluative head is borderline.
- The elements within the construction can be found between brackets [].
- The first element is the intensifier, defined as optional, that is why it is between parenthesis ().
- -
- It is also defined with a linguistic dependency of modifier; meaning that the intensifier will always be dependent of the evaluative head as a modifier, no matter the language or grammar.
- The second element is the evaluative head, which is mandatory. That is why it is represented with the constraint of obligation □.
- -
- Additionally, the evaluative head will bare a dependency on its referent, that is, the element which is being evaluated. Because we want to keep this formalization as the most linguistically universal possible, we do not state the dependency that the evaluative bears. That is why it is represented with . In English, the most common evaluative construction is found as the object of a copular verb (“to be”, “feel”, “seem”, “become”, etc.) and as the subject as its reference: Subject-Copular Verb-Evaluative Construction. In such a case, we would say that the evaluative head has a dependency on the subject.
- *
- It is specified that the referent experience a pairing with the evaluative head, which states if they are semantically compatible or if any coercion would be involved . A clear case of a coerced pairing can be found in the sentence “Mark is a giant”. The pairing between “Mark” and “giant”is implausible since “Mark” bares the quality of being “+ human” and “giants” does not exist, they are mythological creatures. However, the paring is possible, and a coerced meaning is interpreted. If a pairing is not present in the linguistic context, the referent would be found in the communicative context; that is, it will be extra-linguistic .
4.5. Evaluative Expressions: A Formal Characterization
- The insertion of grammar. stands for inserting an FPGr or other grammar with constraints (a universe), which will define the specific constraints of a language, as mentioned in Equation (4). This grammar will define those satisfied and violated constraints of a particular language. Therefore, FPGr will be able to characterize the degree of grammaticality of an evaluative expression with regards to a specific grammar.
- The constraints of the intensifier. The intensifier displays the same constraints as in Figure 3.
- -
- means any category X as intensifier has a dependency as a type of modifier towards any category as an evaluative head .
- The constraints of the evaluative head. The evaluative head displays some of the same constraints observed, as in Figure 3, such as:
- -
- meaning any category X as an evaluative head is mandatory □, leaving the intensifier as optional.
- -
- means any category X as an evaluative head has a non specified dependency towards a referent , which can be found in the linguistic context with linguistic pairing or in the extra linguistic context .
- -
- Additionally, the evaluative head displays semantic constraints here that are necessary to complete such a universal characterization of the constructions of an evaluative expression.
- *
- . Meaning that any category X as an evaluative head requires to be part of one of the sets of a trichotomous expression , either the left one , the one in the middle , or the right one, . And (∧), the trichotomous expression, requires to be tagged with a Linguistic Semantic Variable (). The trichotomous expression can be incorporated in any constraint-based grammar in terms of hyponym and hypernymy (being the hypernym interpreted as our semantic prime) simply by using as a constraint. Therefore, lexical items as “beautiful”, “difficult”, “pig”, and “hate”, can be defined with such constraints as:
- ·
- “beautiful”, .
- ·
- “difficult”, .
- ·
- “pig”, .
- ·
- “hate”, .
- *
- Moreover, it can be specified whether such lexical items are a prototypical or borderline evaluative expression, always with regards to the Linguistic Semantic Variable (the semantic prime). If the evaluative head is prototypical with regards to the prime, it will be defined with the semantic constraint . If the evaluative head is borderline with regards to the prime, it will be defined with the semantic constraint of . For example:
- ·
- “beautiful”, .
- ·
- “pig”, .
- -
- The last constraint is . Meaning that any category X as an evaluative head requires a sentiment to be assigned . Sentiment is characterized as a trichotomous expression of judgment , such as . As with before, the sentiment can be prototypical or borderline, since it is considered that any evaluation can be potentially used in both ways [16]. For example:
- *
- “This song is excellent”, it is interpreted as positive because the word “excellent” is prototypical positive:
- *
- “This song is excellent for deaf people”, it is used as a borderline negative because of the linguistic context:
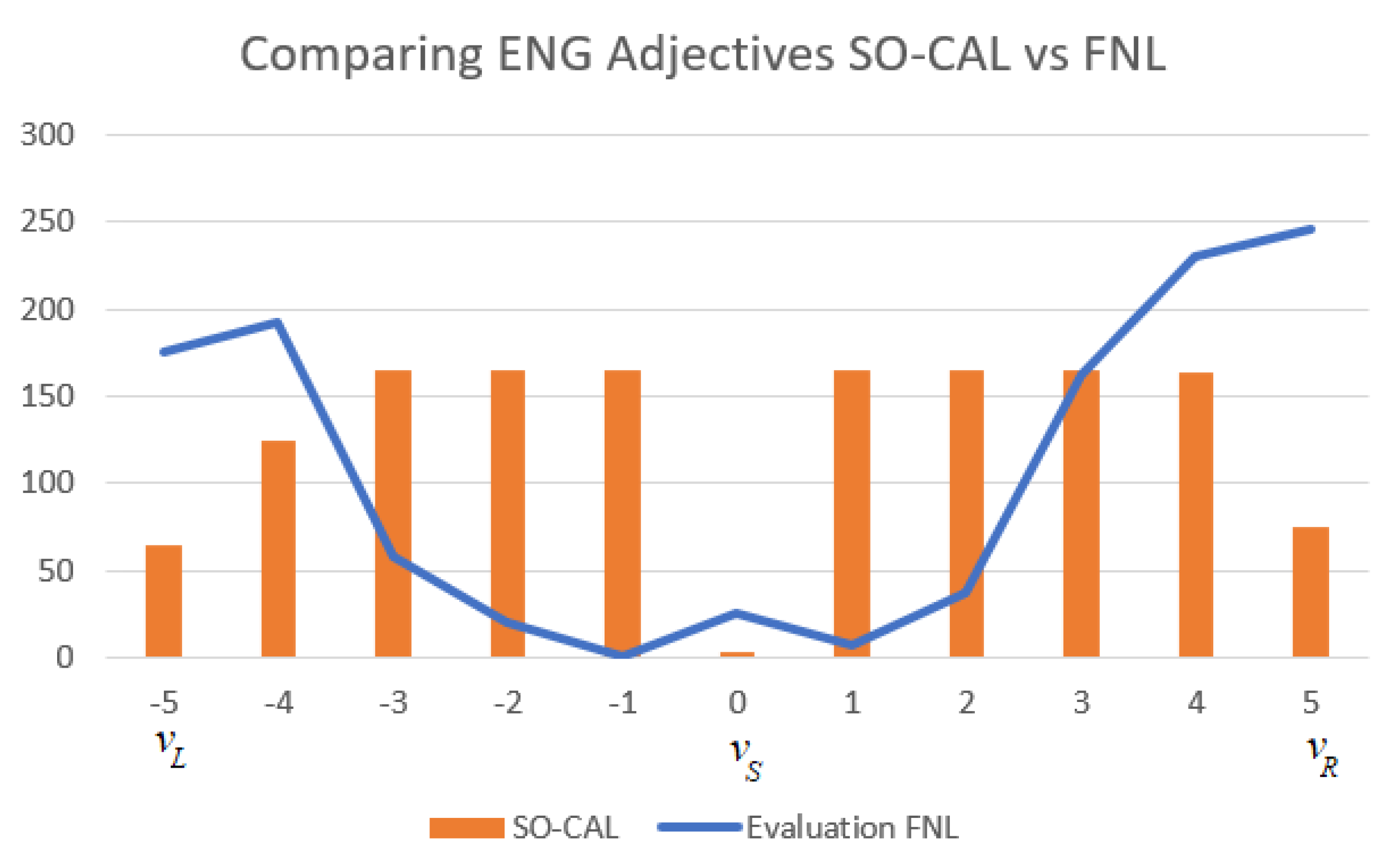
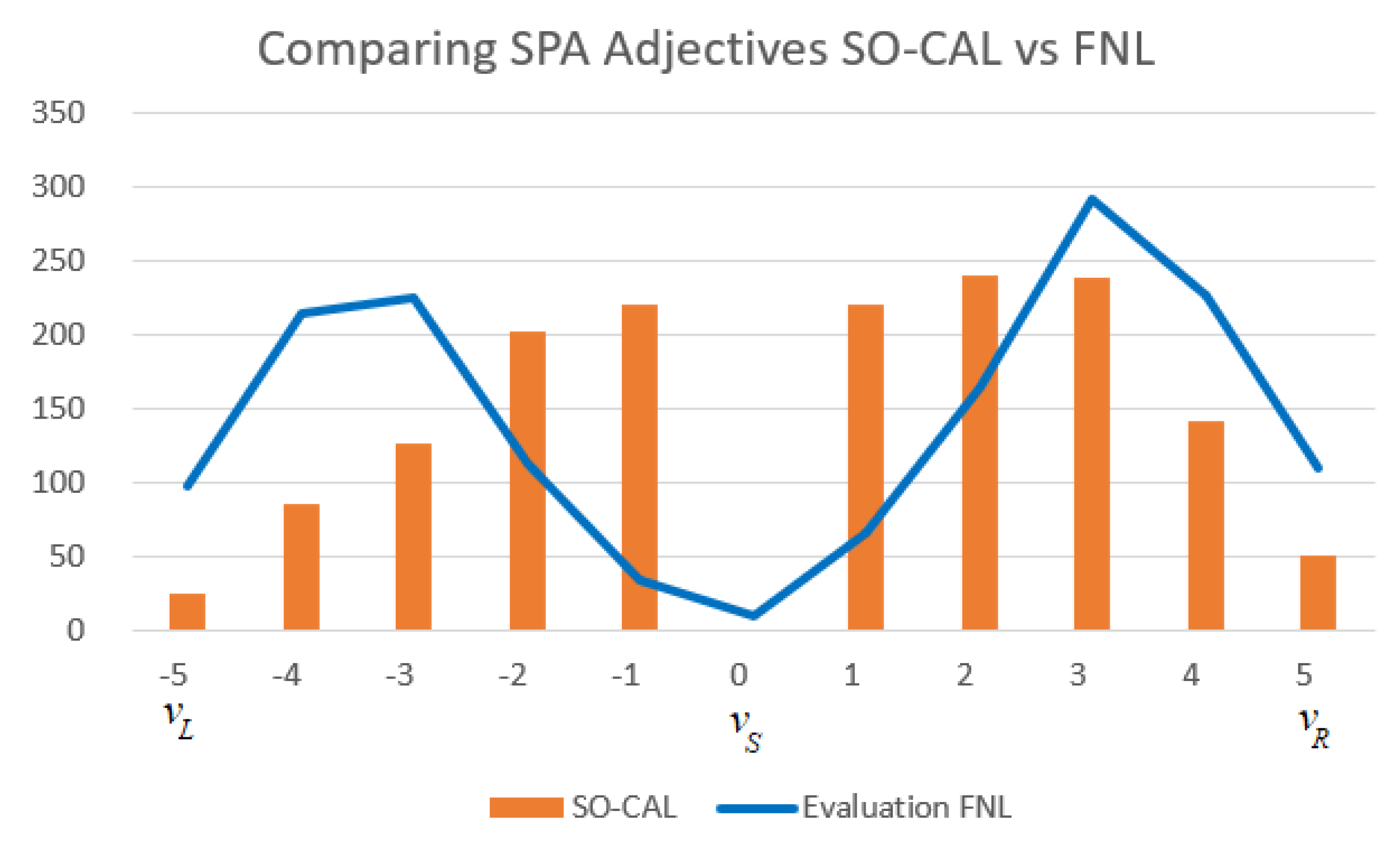
- They occur in each member of a triplet of expressions –an evaluative trichotomy–, such as small-medium-big, short-medium-tall, beautiful-average-ugly. A trichotomous expression is a characterization of a general semantic feature –a semantic prime– called a linguistic semantic value. Examples of these linguistic semantic values are height, beauty, complexity, intelligence, etc. Technically, we can refer to features of a given object.
- They have a sentiment value expressed in terms of positive, negative degree. Sentiment is computed by ordering all the trichotomous expressions as protoypically negative , protoypically medium , protoypically positive , and converting those to borderline sentiment when needed.
- FNL can characterize the interpretability of an evaluation even if it is subjective.
5. Towards a Lexicon of Evaluative Expressions
- Evaluation of the plots;
- Universality of the mid-value;
- Struggles with TE-adjective in LSV.
- (1)
- It is complex to know under which LSV tag the adjective should be classified if we do not look at the linguistic context of the word,
- (2)
- Some adjectives might be suspicious of being able to appear in more than one LSV scale. It is the case of beautiful which could be Beauty: she is beautiful, and/or Pleasing-Likability: the food taste beautiful, and/or Judgment: it is a beautiful job.
- To evaluate the model’s advantages and limitations when building a lexicon with FNL—improving the model with new linguistic properties.
- To check if it is feasible to convert adjectives from the semantics of the evaluative expression into an equivalent positive-negative value.
- To check in which cases the linguistic context is needed to classify an evaluative adjective in a LSV under a prime EH.
6. Conclusions
- Firstly, evaluative linguistic expression’s syntax, semantics, and sentiment are vague and gradient. The vagueness and gradience of its syntax and semantics are definable through the concepts of grammaticality and coercion.
- Secondly, the semantics of an evaluative linguistic expression can be associated with a semantic prime with a sentiment value. A real number cannot represent the extension of this prime most of the time. Therefore, it is necessary to consider an abstract extension representing an intensity similar to a Liker-t scale.
- Thirdly, every evaluative linguistic expression has a single lexical unit as an evaluative head. Such heads are not necessarily adjectives and have to be defined in terms of prototypical and borderline meanings.
- Lastly, syntactic structures that violate syntactic constraints detonate semantic intensions equivalent to a semantic prime. Therefore, variability does not compromise the final processing of the meaning of the construction.
- The linguistic mechanisms displayed in this paper to define evaluative expressions are mainly found in Section 3 and Section 4. Those mechanisms are mainly the linguistic constraints from FPGr (Section 3) and selected concepts of Fuzzy Natural Logic (FNL) adapted to FPGr (Section 4), which consist of using the description of the trichotomous expression as a constraint to define the semantics of an evaluative head. So, for example, some evaluative heads would have a constraint of that define its semantics, such as “big”, “tall”, “complex”, “beautiful”, and so on. In summary, the general approach to the model, its mechanisms such as the linguistic constraints, and its architecture are married to how FNL compute evaluative expressions.
- Evaluative expressions as a “component” are identified with a lexicon. Therefore, building a lexicon is fundamental for applying both FPGr and FNL to characterize evaluative expressions, mainly because an evaluative head does not have a fixed linguistic category.
- Our proposal is theoretical, including a proof-of-concept of how to build a lexicon of evaluative expressions. In the future, it is necessary to extend the tags on the evaluative expressions because it does need a lexicon to identify them, so their special fuzzy semantics can be characterized.
- Regarding whether the system prevents over-generation or not, FPGr and FNL system does not generate language, treebanks, or tree structures; they only characterize language. The generation of constraints or establishing the number of constraints for each language is up to each language’s grammar or the experts configuring such grammar. If there is a problem with the overgeneration, it is not a fault of the system or the architecture. It is a fault of how the system was applied to define a particular language.
- The grammaticality of syntax is considered, as the gradient is a fundamental part of the FPGr. However, the notion of gradient grammaticality is not as “radical” as it might seem under the architecture of FPGr. First, as observed in Section 3, the grammar is defined as a set of constraints. Thus, the set of constraints represents the knowledge of grammar. These constraints can be prototypical; therefore, they are, for sure, constraints of a specific grammar, or borderline, so they are “sometimes” constraints of specific grammar. That is, they are marked, and they appear in specific contexts that are not prototypical. Therefore, the grammar is fuzzy because it considers both prototypical and borderline constraints and weighs them. Secondly, a natural language input will have a degree of membership of a specific grammar according to the number of satisfied and violated constraints of such specific grammar. Therefore, the degree of grammaticality is defined as the degree of belongingness of an input, with regards to specific natural language grammar. For further information, see Torrens-Urrutia [19].
- FPGr and FNL do not consider extra-linguistic interpretations, since such a case would entail pragmatics. Therefore, it cannot generate from an input such as “I love your food” an output as: “I love the fact that you cooked for me, regardless of the quality of the food”. Such an interpretation is considered pragmatic due to extra-linguistic reasons, i.e., theory of politeness, context, intention, implicatures, etc. (see Figure 2). Semantics in FPGr only focuses on the essential part of the meaning, the most primitive one, that is why we defend the notion of semantic primes as a hypernym, and the system defines constraints of evaluations regarding a prime. These constraints are .
7. Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Novák, V. The Concept of Linguistic Variable Revisited. In Recent Developments in Fuzzy Logic and Fuzzy Sets; Sugeno, M., Kacprzyk, J., Shabazova, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; pp. 105–118. [Google Scholar]
- Novák, V. Fuzzy Logic in Natural Language Processing. In Proceedings of the International Conference FUZZ-IEEE, Naples, Italy, 9–12 July 2017. [Google Scholar]
- Novák, V.; Perfilieva, I.; Dvořák, A. Insight Into Fuzzy Modeling; Wiley & Sons: Hoboken, NJ, USA, 2016. [Google Scholar]
- Novák, V. What is Fuzzy Natural Logic. In Integrated Uncertainty in Knowledge Modelling and Decision Making; Huynh, V., Inuiguchi, M., Denoeux, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2015; pp. 15–18. [Google Scholar]
- Novák, V. Fuzzy Natural Logic: Towards Mathematical Logic of Human Reasoning. In Fuzzy Logic: Towards the Future; Seising, R., Trillas, E., Kacprzyk, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2015; pp. 137–165. [Google Scholar]
- Novák, V. Evaluative linguistic expressions vs. fuzzy categories? Fuzzy Sets Syst. 2015, 281, 81–87. [Google Scholar] [CrossRef]
- Novák, V. Mathematical Fuzzy Logic: From Vagueness to Commonsese Reasoning. In Retorische Wissenschaft: Rede und Argumentation in Theorie und Praxis; Kreuzbauer, G., Gratzl, N., Hielb, E., Eds.; LIT-Verlag: Wien, Austria, 2008; pp. 191–223. [Google Scholar]
- Lakoff, G. Linguistics and natural logic. Synthese 1970, 22, 151–271. [Google Scholar] [CrossRef] [Green Version]
- Novák, V.; Murinová, P.; Boffa, S. On the properties of intermediate quantifiers and the quantifier “MORE-THAN”. In Information Processing and Management of Uncertainty in Knowledge-Based Systems, Part III; Medina, J., Ojeda-Aciego, M., Verdegay, J.L., Pelta, D.A., Cabrera, I.P., Bouchon-Meunier, B., Yager, R.R., Eds.; Springer Nature: Zürich, Switzerland, 2020; pp. 159–172. [Google Scholar]
- Murinová, P.; Novák, V. The theory of intermediate quantifiers in fuzzy natural logic revisited and the model of “Many”. Fuzzy Sets Syst. 2020, 388, 56–89. [Google Scholar] [CrossRef]
- Novák, V.; Murinová, P. A formal model of the intermediate quantifiers “A few, Several, A little”. In Fuzzy Techniques: Theory and Applications; Kearfott, R., Batyrshin, I., Reformat, M., Ceberio, M., Kreinovich, V., Eds.; Springer: Cham, Switzerland, 2019; pp. 429–441. [Google Scholar]
- Nguyen, L.; Novák, V. Forecasting seasonal time series based on fuzzy techniques. Fuzzy Sets Syst. 2019, 361, 114–129. [Google Scholar] [CrossRef]
- Novák, V.; Pavliska, V.; Perfilieva, I.; Stepnicka, M. F-transform and Fuzzy Natural logic in Time Series Analysis. In Proceedings of the EUSFLAT Conference, Milano, Italy, 11–13 September 2013. [Google Scholar]
- Novák, V. Linguistic characterization of time series. Fuzzy Sets Syst. 2016, 285, 52–72. [Google Scholar] [CrossRef]
- Novák, V.; Perfilieva, I.; Dvořák, A.; Chen, G.; Wei, Q.; Yan, P. Mining pure linguistic associations from numerical data. Int. J. Approx. Reason. 2008, 48, 4–22. [Google Scholar] [CrossRef] [Green Version]
- Torrens Urrutia, A.; Jiménez-López, M.D.; Novák, V. Fuzzy Natural Logic for Sentiment Analysis: A Proposal. In Proceedings of the International Symposium on Distributed Computing and Artificial Intelligence, Salamanca, Spain, 6–8 October 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 64–73. [Google Scholar]
- Torrens Urrutia, A. Towards a fuzzy grammar for natural language grammars. In Recerca en Humanitats 2018; Publicacions URV: Reus, Spain, 2018; pp. 271–282. [Google Scholar]
- Torrens Urrutia, A. An Approach to Measuring Complexity with a Fuzzy Grammar & Degrees of Grammaticality. In Proceedings of the Workshop on Linguistic Complexity and Natural Language Processing, Santa Fe, NM, USA, 25 August 2018; pp. 59–67. [Google Scholar]
- Torrens Urrutia, A. A Formal Characterization of Fuzzy Degrees of Grammaticality for Natural Language. Ph.D. Thesis, Universitat Rovira i Virgili, Tarragona, Spain, 2019. [Google Scholar]
- Torrens Urrutia, A.; Jiménez-López, M.D.; Brosa-Rodríguez, A. A Fuzzy Approach to Language Universals for NLP. In Proceedings of the IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Virtual, 11–14 July 2021; pp. 1–6. [Google Scholar]
- Hemmatian, F.; Sohrabi, M.K. A survey on classification techniques for opinion mining and sentiment analysis. Artif. Intell. Rev. 2019, 52, 1495–1545. [Google Scholar] [CrossRef]
- Yadav, A.; Vishwakarma, D.K. Sentiment analysis using deep learning architectures: A review. Artif. Intell. Rev. 2020, 53, 4335–4385. [Google Scholar] [CrossRef]
- Taboada, M. Sentiment Analysis: An Overview from Linguistics. Annu. Rev. Linguist. 2016, 2, 325–347. [Google Scholar] [CrossRef] [Green Version]
- Baccianella, S.; Esuli, A.; Sebastiani, F. Sentiwordnet 3.0: An enhanced lexical resource for sentiment analysis and opinion mining. In Proceedings of the LREC, Valletta, Malta, 17–23 May 2010; Volume 10, pp. 2200–2204. [Google Scholar]
- Mohammad, S.; Dunne, C.; Dorr, B. Generating high-coverage semantic orientation lexicons from overtly marked words and a thesaurus. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–7 August 2009; pp. 599–608. [Google Scholar]
- Wilson, T.; Wiebe, J.; Hoffmann, P. Recognizing contextual polarity in phrase-level sentiment analysis. In Proceedings of the Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing, Vancouver, BC, Canada, 6–8 October 2005; pp. 347–354. [Google Scholar]
- Wiebe, J.; Wilson, T.; Bruce, R.; Bell, M.; Martin, M. Learning subjective language. Comput. Linguist. 2004, 30, 277–308. [Google Scholar] [CrossRef] [Green Version]
- Blache, P. Representing syntax by means of properties: A formal framework for descriptive approaches. J. Lang. Model. 2016, 4, 183–224. [Google Scholar] [CrossRef] [Green Version]
- Universal Dependency Corpora. Available online: https://universaldependencies.org/ (accessed on 1 September 2021).
- Blache, P.; Rauzy, S.; Montcheuil, G. MarsaGram: An excursion in the forests of parsing trees. In Proceedings of the 12th Language Resources and Evaluation Conference, LREC 2020, Marseille, France, 11–16 May 2020; Volume 10, p. 7. [Google Scholar]
- Manca, V.; Jiménez-López, M.D. GNS: Abstract Syntax for Natural Languages. Triangle 2012, 8, 55–79. [Google Scholar] [CrossRef]
- Fillmore, C.J. The mechanisms of “construction grammar”. In Proceedings of the Annual Meeting of the Berkeley Linguistics Society, 13–15 February 1988; Volume 14, pp. 35–55. Available online: http://journals.linguisticsociety.org/proceedings/index.php/BLS/article/viewFile/1794/1566 (accessed on 10 January 2022).
- Goldberg, A.E. Constructions at Work: The Nature of Generalization in Language; Oxford University Press on Demand: Oxford, UK, 2006. [Google Scholar]
- Fillmore, C.J.; Baker, C. A frames approach to semantic analysis. In The Oxford Handbook of Linguistic Analysis; Oxford University Press: Oxford, UK, 2010. [Google Scholar]
- Goldberg, A. Verbs, constructions and semantic frames. In Syntax, Lexical Semantics, and Event Structure; Oxford University Press: Oxford, UK, 2010; pp. 39–58. [Google Scholar]
- Müller, G. Optimality, markedness, and word order in German. Linguistics 1999, 37, 777–818. [Google Scholar] [CrossRef] [Green Version]
- Wierzbicka, A. Semantics: Primes and Universals: Primes and Universals; Oxford University Press: Oxford, UK, 1996. [Google Scholar]
- Erk, K.; Padó, S.; Padó, U. A flexible, corpus-driven model of regular and inverse selectional preferences. Comput. Linguist. 2010, 36, 723–763. [Google Scholar] [CrossRef]
- Baroni, M.; Lenci, A. Distributional memory: A general framework for corpus-based semantics. Comput. Linguist. 2010, 36, 673–721. [Google Scholar] [CrossRef]
- Greenberg, C.; Sayeed, A.; Demberg, V. Improving unsupervised vector-space thematic fit evaluation via role-filler prototype clustering. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics Human Language Technologies, Denver, CO, USA, 31 May–5 June 2015; ACL: Denver, CO, USA, 2015; pp. 21–31. [Google Scholar]
- Santus, E.; Chersoni, E.; Lenci, A.; Blache, P. Measuring thematic fit with distributional feature overlap. arXiv 2017, arXiv:1707.05967. [Google Scholar]
- Crystal, D. On keeping one’s hedges in order. Engl. Today 1988, 4, 46–47. [Google Scholar] [CrossRef]
- Layman, L. Reticence in oral history interviews. In The Oral History Reader; Routledge: London, UK, 2015; pp. 234–252. [Google Scholar]
- Islam, J.; Xiao, L.; Mercer, R.E. A lexicon-based approach for detecting hedges in informal text. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 202; pp. 3109–3113.
- Hassan, A.S.; Said, N.K.M. A pragmatic study of hedges in American political editorials. Int. J. Res. Soc. Sci. Humanit. 2020, 10. [Google Scholar] [CrossRef]
- Taboada, M.; Brooke, J.; Tofiloski, M.; Voll, K.; Stede, M. Lexicon-based methods for sentiment analysis. Comput. Linguist. 2011, 37, 267–307. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
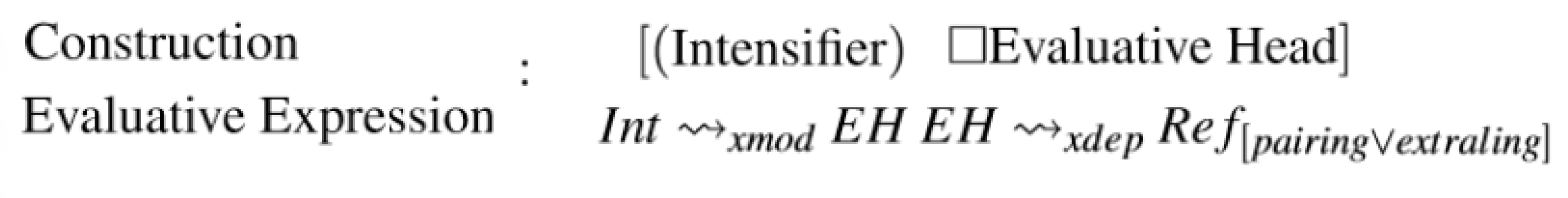{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
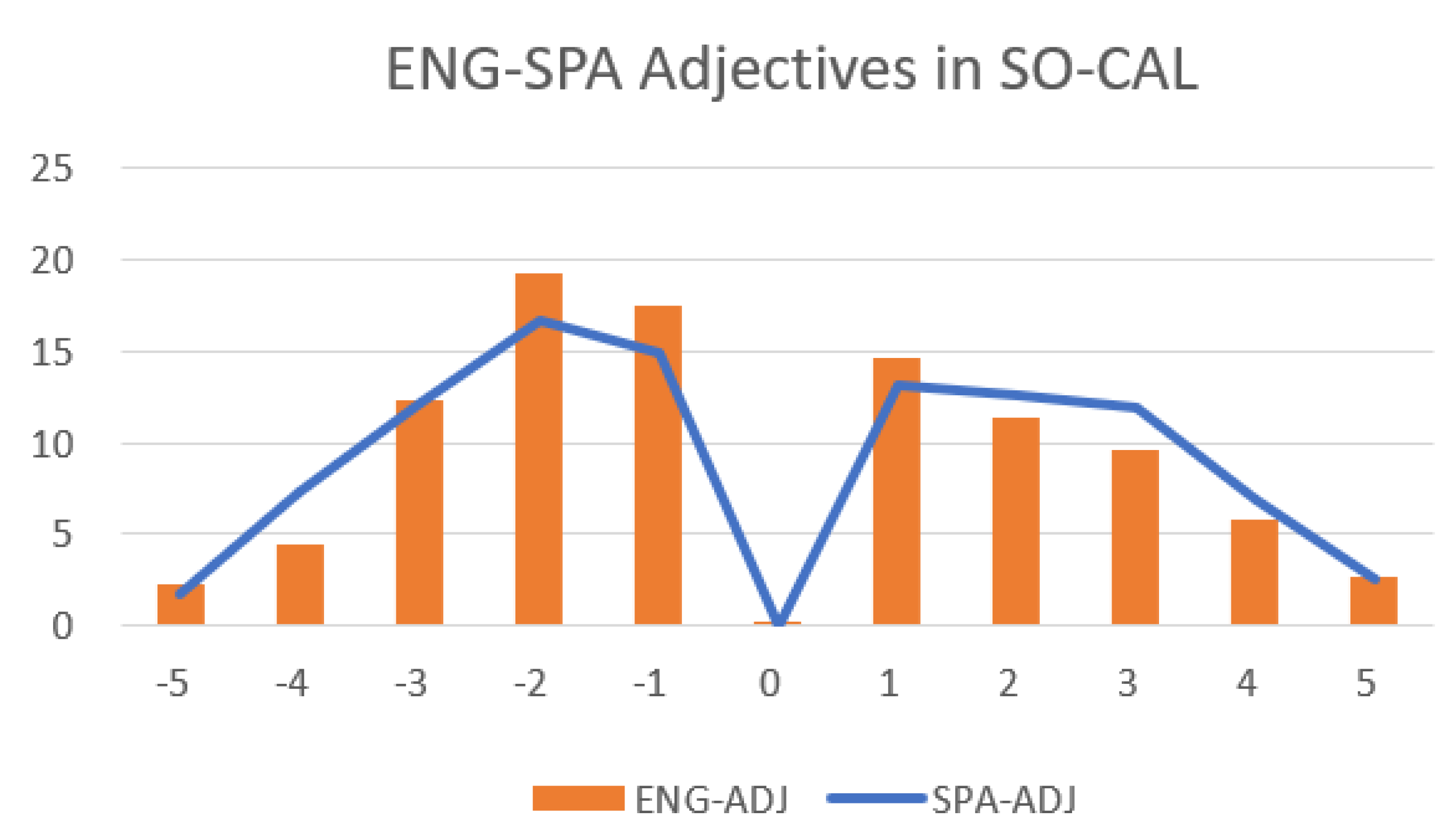
| SentiWordNet [24] Baccianella et al. (2010) | Macquire Dictionary [25] Mohammad et al. (2009) | Subjectivity Dictionary [26] Wilson et al. (2005) | SO-CAL [23] Taboada (2016) | |
|---|---|---|---|---|
| good | Positive | Positive | Positive (weak) | 3 |
| excellent | Positive | Positive | Positive (strong) | 5 |
| masterpiece | Positive | Positive | Positive (strong) | 5 |
| bad | Negative | Negative | Negative (strong) | −3 |
| terrible | Negative | Negative | Negative (strong) | −5 |
| disaster | Negative | Negative | Negative (strong) | −4 |
| FNL Tags in English and Spanish Lexicon | |||||
|---|---|---|---|---|---|
| LSV | Judgment | Esteem | Beauty | Size | Capability-Skills |
| Primes EH | 〈negative/bad-medium/normal-positive/good〉 | 〈hated-X-loved〉 | 〈ugly-X-beautiful〉 | 〈small/short-medium-big/long〉 | 〈disable-average-capable〉 |
| LSV | Complexity | Fear-Courage | Fullness | Indeterminacy | Intelligence |
| Primes EH | 〈simple-normal-complex〉 | 〈scared-X-brave〉 | 〈empty-X-full〉 | 〈blurred-X-clear〉 | 〈stupid-average-intelligent〉 |
| LSV | Generates-Interest | Pleasing-Likability | Proximity | Veridicality | Similarity-Usual |
| Primes EH | 〈boring-X-interesting〉 | 〈disgusting-X-pleasing〉 | 〈far-central-close〉 | 〈fake/false-X-real/truth〉 | 〈different-similar-usual〉 |
| LSV | Speed | Strength-Intensity | Temperature | Time-Lifetime | Worth-Value |
| Primes EH | 〈slow-medium-fast〉 | 〈weak/fragile-X-intense/strong〉 | 〈cold-X-hot〉 | 〈life/new/young/ beggining- medium/ adult-death/old/end〉 | 〈worthless-X-worthy〉 |
| LSV | Value (economical) | ||||
| Primes EH | 〈cheap-affordable-expensive〉 | ||||
| Lexical Unit: Beautiful | ||
|---|---|---|
| Beauty | ||
| Judgment, Pleasing-Likability | ||
| positive | ||
| Lexical Unit: Sick | Lexical Unit: Geek | ||||
|---|---|---|---|---|---|
| Judgment | Similarity-Usual | ||||
| Pleasing-Likability Capability-Skills | Intelligence | ||||
| negative | negative | ||||
| positive {IFF capability-skills} | positive {IFF generates-interest} | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Torrens-Urrutia, A.; Novák, V.; Jiménez-López, M.D. Describing Linguistic Vagueness of Evaluative Expressions Using Fuzzy Natural Logic and Linguistic Constraints. Mathematics 2022, 10, 2760. https://doi.org/10.3390/math10152760
Torrens-Urrutia A, Novák V, Jiménez-López MD. Describing Linguistic Vagueness of Evaluative Expressions Using Fuzzy Natural Logic and Linguistic Constraints. Mathematics. 2022; 10(15):2760. https://doi.org/10.3390/math10152760
Chicago/Turabian StyleTorrens-Urrutia, Adrià, Vilém Novák, and María Dolores Jiménez-López. 2022. "Describing Linguistic Vagueness of Evaluative Expressions Using Fuzzy Natural Logic and Linguistic Constraints" Mathematics 10, no. 15: 2760. https://doi.org/10.3390/math10152760