
Enhanced Evaluation Method of Musical Instrument Digital Interface Data based on Random Masking and Seq2Seq Model


Abstract
:1. Introduction
- (1)
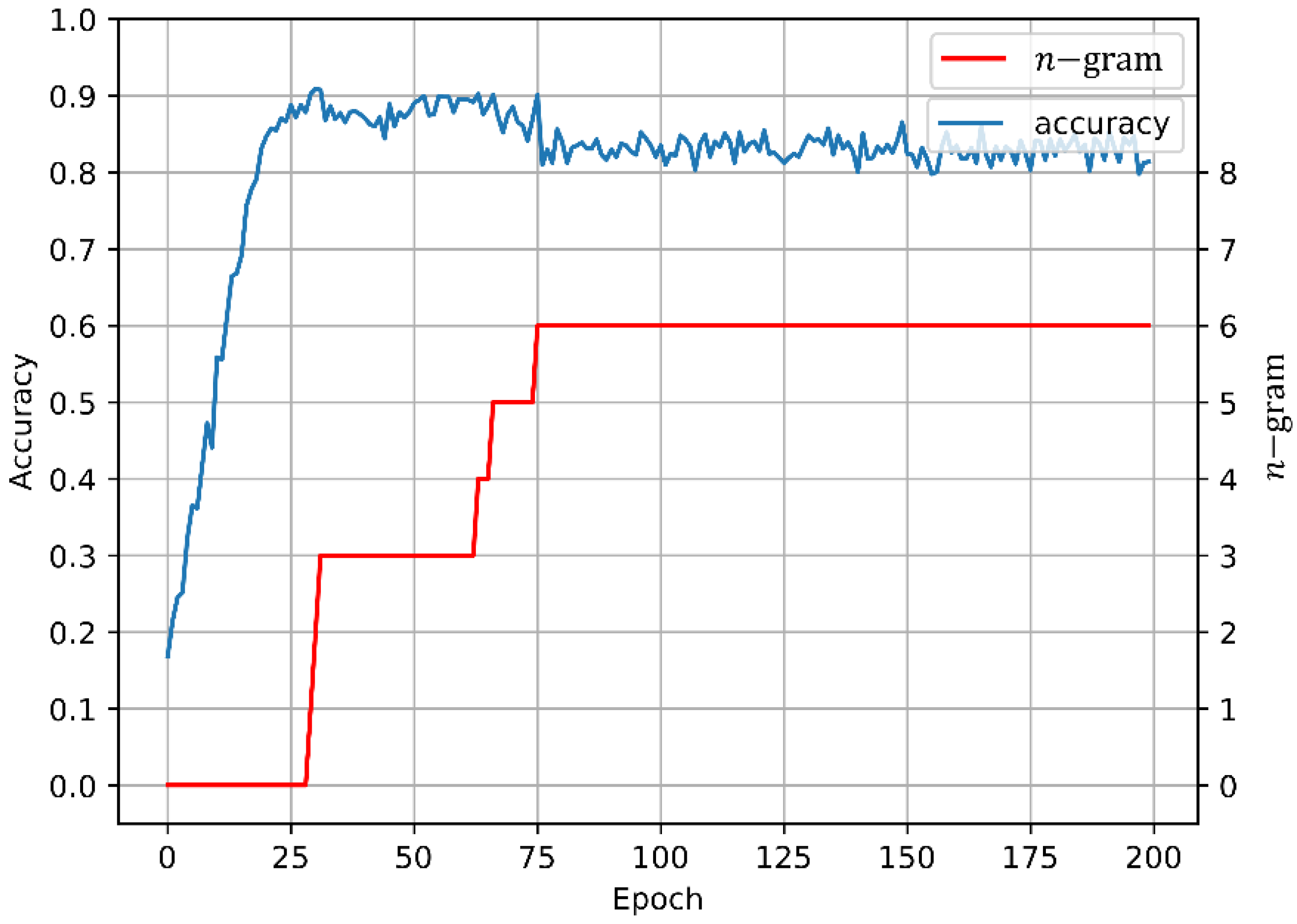
- When the accuracy of estimating the masked part of the masked sequence reaches the threshold, the coverage area of the mask is expanded, thus prompting the Seq2Seq model to estimate more unknowns with less information.
- (2)
- In the enhanced evaluation method, the Seq2Seq model and attention mechanism are used; the ability of the model to be used globally is critical.
- (3)
- The random mask processor and Seq2Seq model analyze the musical features of the MIDI data without manual setting of the general descriptive parameters. Hence, we achieve automatic evaluation of the quality of the generated MIDI data.
2. Related Works
2.1. MIDI Data Objective Evaluation Approaches
2.2. Comparison of Objective MIDI Data Evaluation Approaches
3. Enhanced Evaluation Method
3.1. Overview
3.2. Preprocessor
3.3. Seq2Seq Model Trainer
3.4. Seq2Seq Model Executer
3.5. Indices Equalizer
3.6. Score Calculator
4. Experiments
4.1. Experimental Environment
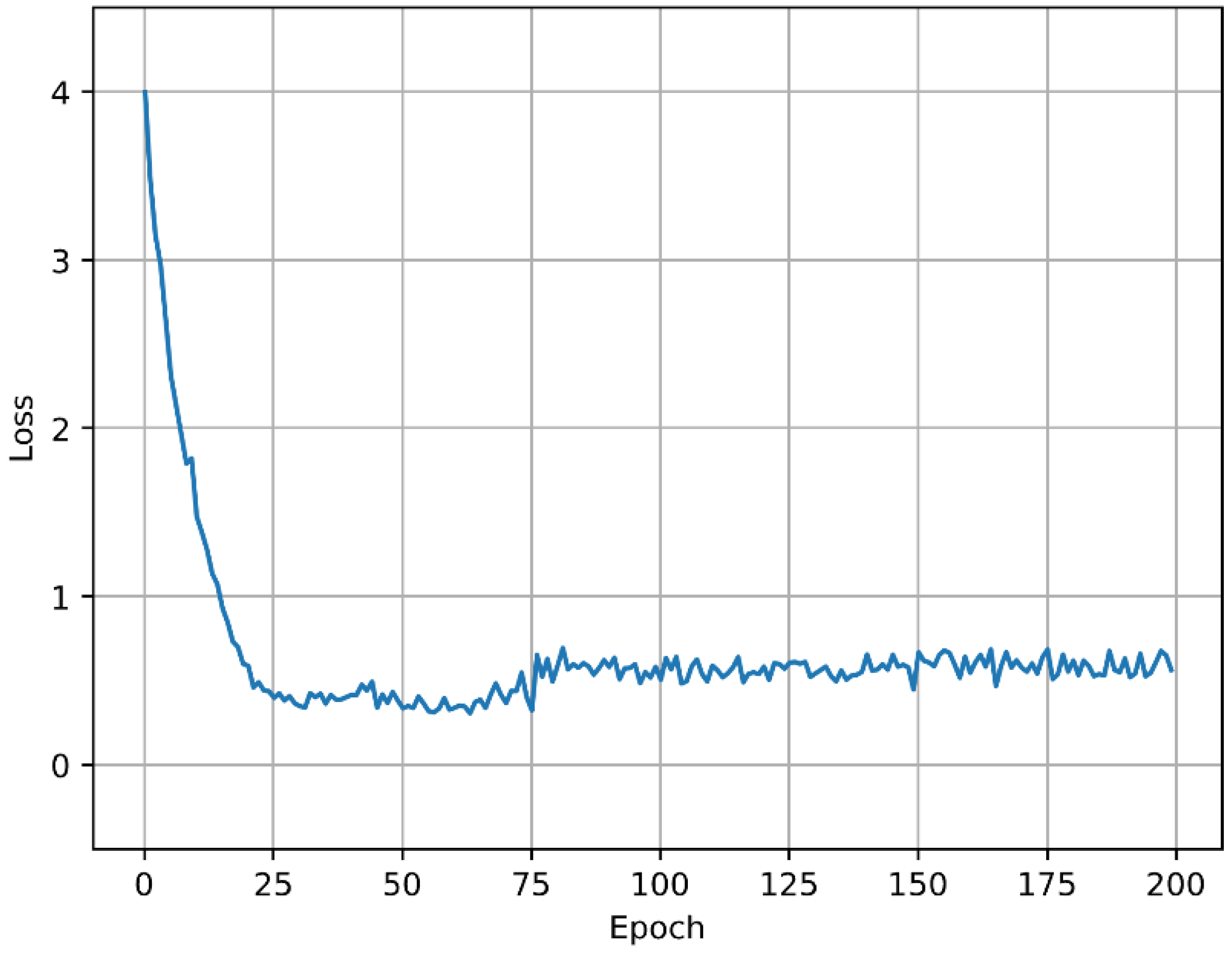
4.2. Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Schmidhuber, J. Deep Learning in Neural Networks: An Overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Louati, H.; Bechikh, S.; Louati, A.; Hung, C.C.; Said, L.B. Deep Convolutional Neural Network Architecture Design as A Bi-Level Optimization Problem. Neurocomputing 2021, 439, 44–62. [Google Scholar] [CrossRef]
- Saha, S.; Gan, Z.; Cheng, L.; Gao, J.; Kafka, O.L.; Xie, X.; Li, H.; Tajdari, M.; Kim, H.A.; Liu, W.K. Hierarchical Deep Learning Neural Network (HiDeNN): An Artificial Intelligence (AI) Framework for Computational Science and Engineering. Comput. Methods Appl. Mech. Eng. 2021, 373, 113452–113480. [Google Scholar] [CrossRef]
- Haoxiang, W.; Smys, S. Big Data Analysis and Perturbation Using Data Mining Algorithm. JSCP 2021, 3, 19–28. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhou, H.; Huang, S.; Chen, J.; Xu, J.; Li, L. Duplex Sequence-To-Sequence Learning for Reversible Machine Translation. In Proceedings of the 35th Advances in Neural Information Processing Systems (NeurIPS), Online, 6–14 December 2021; pp. 21070–21084. [Google Scholar]
- Wong, R.M.; Adesope, O.O. Meta-Analysis of Emotional Designs in Multimedia Learning: A Replication and Extension Study. Educ. Psychol. Rev. 2021, 33, 357–385. [Google Scholar] [CrossRef]
- Yu, D.; Ji, S.; Liu, J.; Wei, S. Automatic 3D Building Reconstruction from Multi-View Aerial Images with Deep Learning. ISPRS J. Photogramm. Remote Sens. 2021, 171, 155–170. [Google Scholar] [CrossRef]
- Sivaramakrishnan, N.; Subramaniyaswamy, V.; Viloria, A.; Vijayakumar, V.; Senthilselvan, N. A Deep Learning-Based Hybrid Model for Recommendation Generation and Ranking. Neural. Comput. Appl. 2021, 33, 10719–10736. [Google Scholar] [CrossRef]
- Dokuz, Y.; Tufekci, Z. Mini-Batch Sample Selection Strategies for Deep Learning Based Speech Recognition. Appl. Acoust. 2021, 171, 107573. [Google Scholar] [CrossRef]
- Choi, K.; Fazekas, G.; Sandler, M.; Cho, K. Convolutional Recurrent Neural Networks for Music Classification. In Proceedings of the 2017 IEEE 42nd International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2392–2396. [Google Scholar]
- Qiu, L.; Li, S.; Sung, Y. DBTMPE: Deep Bidirectional Transformers-Based Masked Predictive Encoder Approach for Music Genre Classification. Mathematics 2021, 9, 530–547. [Google Scholar] [CrossRef]
- Qiu, L.; Li, S.; Sung, Y. 3D-DCDAE: Unsupervised Music Latent Representations Learning Method Based on a Deep 3D Convolutional Denoising Autoencoder for Music Genre Classification. Mathematics 2021, 9, 2274–2290. [Google Scholar] [CrossRef]
- Cheng, Z.; Jialie, S.; Hoi, S.C. On Effective Personalized Music Retrieval by Exploring Online User Behaviors. In Proceedings of the 39th International Association for Computing Machinery Special Interest Group on Information Retrieval Conference on Research and Development in Information Retrieval (ACM SIGIR), Pisa, Italy, 17–21 July 2016; pp. 125–134. [Google Scholar]
- Costa, F.S.D.; Dolog, P. Collective Embedding for Neural Context-Aware Recommender Systems. In Proceedings of the 13th ACM Conference on Recommender Systems, Copenhagen, Denmark, 16–20 September 2019; pp. 201–209. [Google Scholar]
- Jiang, N.; Jin, S.; Duan, Z.; Zhang, C. RL-Duet: Online Music Accompaniment Generation Using Deep Reinforcement Learning. In Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 710–718. [Google Scholar]
- Li, S.; Jang, S.; Sung, Y. INCO-GAN: Variable-Length Music Generation Method Based on Inception Model-Based Conditional GAN. Mathematics 2021, 9, 387–403. [Google Scholar] [CrossRef]
- Ariza, C. The Interrogator as Critic: The Turing Test and the Evaluation of Generative Music Systems. Comput. Music J. 2009, 33, 48–70. [Google Scholar] [CrossRef]
- Dong, H.W.; Hsiao, W.Y.; Yang, L.C.; Yang, Y.H. MuseGan: Multi-Track Sequential Generative Adversarial Networks for Symbolic Music Generation and Accompaniment. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 34–41. [Google Scholar]
- Mogren, O. C-RNN-GAN: Continuous Recurrent Neural Networks with Adversarial Training. arXiv 2016, arXiv:1611.09904. [Google Scholar]
- Schreiber, H.; Müller, M. A Single-Step Approach to Musical Tempo Estimation Using a Convolutional Neural Network. In Proceedings of the 19th International Society for Music Information Retrieval Conference (ISMIR), Paris, France, 23–27 September 2018; pp. 98–105. [Google Scholar]
- McLeod, A.; Steedman, M. Evaluating Automatic Polyphonic Music Transcription. In Proceedings of the 19th International Society for Music Information Retrieval Conference (ISMIR), Paris, France, 23–27 September 2018; pp. 42–49. [Google Scholar]
- Friberg, A.; Schoonderwaldt, E.; Hedblad, A. Perceptual Ratings of Musical Parameters. J. Psychol. 1937, 49, 621–630. [Google Scholar]
- Asmus, E.P. Music Assessment Concepts: A Discussion of Assessment Concepts and Models for Student Assessment Introduces This Special Focus Issue. Music Eucators J. 1999, 86, 19–24. [Google Scholar] [CrossRef]
- Huang, C.Z.A.; Cooijmans, T.; Roberts, A.; Courville, A.; Eck, D. Counterpoint by Convolution. In Proceedings of the 18th International Society for Music Information Retrieval Conference (ISMIR), Suzhou, China, 23–27 October 2017; pp. 211–218. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Association for Computational Linguistics (ACL), Philadelphia, PA, USA, 6–7 July 2002; pp. 311–318. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 26th Advances in Neural Information Processing Systems (NeurIPS), Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Huang, C.Z.A.; Vaswani, A.; Uszkoreit, J.; Shazeer, N.; Simon, I.; Hawthorne, C.; Dai, A.M.; Hoffman, M.D.; Dinculescu, M.; Eck, D. Music Transformer: Generating Music with Long-Term Structure. arXiv 2018, arXiv:1809.04281. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All You Need. In Proceedings of the 31st Advances in Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pretraining of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Bittner, R.M.; Bosch, J.J. Generalized Metrics for Single-f0 Estimation Evaluation. In Proceedings of the 20th International Society for Music Information Retrieval Conference (ISMIR), Delft, The Netherlands, 4–8 November 2019; pp. 738–745. [Google Scholar]
- Briot, J.P.; Hadjeres, G.; Pachet, F. Deep Learning Techniques for Music Generation--A Survey. arXiv 2017, arXiv:1709.01620. [Google Scholar]
- Brown, P.F.; Della Pietra, V.J.; Desouza, P.V.; Lai, J.C.; Mercer, R.L. Class-Based N-Gram Models of Natural Language. CL 1992, 18, 467–480. [Google Scholar]
- Bridle, J. Training Stochastic Model Recognition Algorithms as Networks Can Lead to Maximum Mutual Information Estimation of Parameters. In Proceedings of the 4th Advances in Neural Information Processing Systems (NeurIPS), Denver, CO, USA, 26–29 November 1990; pp. 211–217. [Google Scholar]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-Level Convolutional Networks for Text Classification. arXiv 2015, arXiv:1502.01710. [Google Scholar]
- Walder, C. Modelling Symbolic Music: Beyond the Piano Roll. In Proceedings of the 8th Asian Conference on Machine Learning (ACML), Hamilton, New Zealand, 16–18 November 2016; pp. 174–189. [Google Scholar]
- Zhu, H.; Lee, K.A.; Li, H. Serialized Multi-Layer Multi-Head Attention for Neural Speaker Embedding. arXiv 2021, arXiv:2107.06493. [Google Scholar]
- Agarap, A.F. Deep Learning Using Rectified Linear Units (ReLU). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Simonetta, F.; Carnovalini, F.; Orio, N.; Rodà, A. Symbolic Music Similarity through a Graph-Based Representation. In Proceedings of the Audio Mostly on Sound in Immersion and Emotion, North Wales, UK, 12–14 September 2018; pp. 1–7. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Research Work | Metric Type | Metrics | General Descriptive Parameters | Global Consideration |
|---|---|---|---|---|
| MuseGAN [19] | Statistical | EB, UPC, QN, DP, TD | √ | √ |
| C-RNN-GAN [20] | Statistical | Polyphony, Scale Consistency, Repetitions, Tone Span | √ | √ |
| MV2H [22] | Statistical | Voice Separation, Multi-pitch Detection, Metrical Alignment, Note Value Detection, etc. | √ | √ |
| COCONET [25] | Probabilistic | Log-likelihood | ✘ | ✘ |
| BLEU [26] | Probabilistic | BLEU | ✘ | ✘ |
| The Proposed Method | Probabilistic | Seq2Seq Model and Random Mask Processor | ✘ | √ |
| Note/Mask | Index |
|---|---|
| Rest | 0 |
| C3 | 1 |
| C3# | 2 |
| D3 | 3 |
| D3# | 4 |
| E3 | 5 |
| F3 | 6 |
| F3# | 7 |
| G3 | 8 |
| … | … |
| B5 | 36 |
| Mask | −1 |
| Hyper Parameter | Value |
|---|---|
| Input dimension | 38 |
| Output dimension | 38 |
| Embedding dimension | 256 |
| Encoder block number | 3 |
| Decoder block number | 3 |
| Encoder head | 8 |
| Decoder head | 8 |
| Encoder position-wise feedforward dimension | 512 |
| Decoder position-wise feedforward dimension | 512 |
| Encoder dropout | 0.1 |
| Decoder dropout | 0.1 |
| Epoch | 200 |
| Learning rate | 0.0005 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, Z.; Li, S.; Sung, Y. Enhanced Evaluation Method of Musical Instrument Digital Interface Data based on Random Masking and Seq2Seq Model. Mathematics 2022, 10, 2747. https://doi.org/10.3390/math10152747
Jiang Z, Li S, Sung Y. Enhanced Evaluation Method of Musical Instrument Digital Interface Data based on Random Masking and Seq2Seq Model. Mathematics. 2022; 10(15):2747. https://doi.org/10.3390/math10152747
Chicago/Turabian StyleJiang, Zhe, Shuyu Li, and Yunsick Sung. 2022. "Enhanced Evaluation Method of Musical Instrument Digital Interface Data based on Random Masking and Seq2Seq Model" Mathematics 10, no. 15: 2747. https://doi.org/10.3390/math10152747