1. Introduction
With the development of science and technology competing with the gradual improvement of urban construction levels, image recognition is increasingly being applied to urban informatization and digital construction. Among the recognition methods, the YOLOX detection framework is particularly famous. It is widely used in urban object detection [
1], pedestrian detection [
2], and other environments due to its advantage of fast response and high precision.
Modern cities are divided into regions and assigned sanitation workers for garbage cleaning using a grid management method [
3] to improve the efficiency of urban management and sanitation. Workers only need to conduct regular inspections and cleanings of the place they are responsible for to ensure basic hygiene everywhere in the city. However, the regionalization management level is still insufficient. The fixed personnel allocation method cannot adjust the number of people according to the dynamic change in the amount of garbage in each area. There is a situation where the garbage accumulates in some areas, but there are insufficient sanitation workers there. However, sanitation workers in other places have few things to do. Relying on regular inspections by sanitation workers cannot keep up with the real-time changes in the amount of garbage. If the sanitation workers do not clean in time, accumulation of garbage will happen. Over time, garbage accumulation has become a hidden danger of flood disasters. The work of dealing with urban floods has remained a tricky problem for a long time.
With the help of target detection technology and the support of the urban public surveillance system, real-time monitoring is prevailing in the maintenance of various areas, roads, and sewer manholes. The monitoring capability of an urban flood control system highly depends on the in-time identification of a garbage’s type and quantity and the collection of data. An efficient urban flood control system can help sanitation workers check and clean up the underlying danger areas such as sewer manhole covers. Committed to the goals of improving the city’s ability to prevent floods and waterlogging while reducing the work intensity of sanitation workers, a method based on the YOLOX detection framework was designed to reflect the garbage accumulation in the flood control area. The working mechanisms of analyzing the monitoring images and identifying the type and quantity of garbage on the manhole cover have improved the efficiency and ability of urban sanitation cleaning, flood controlling, and waterlogging prevention. If the garbage is occluded by other garbage during detection, it causes inaccurate counting and missed detection. A well-designed detection scheme is sufficient to solve such problems. To further improve the detection accuracy, reduce the missed detection rate, and give early warning signals more precisely, our team proposed a new detection method, Soft-YOLOX, to solve the problems above.
2. Related Work
Garbage counting is a basic application scenario in target detection [
4], and many machine learning methods have been proposed in this field to solve target detection and counting problems. Traditional machine learning cases include multi-vehicle counting algorithms based on the Haar feature principle [
5], SVM based on HOG [
6] and LBP [
7] features, and others. These traditional machine learning target detection algorithms mainly rely on manual feature extraction. First, the features are extracted from the image, then a classifier is built to classify, and finally, the wanted target is obtained. However, most of these traditional target detection algorithms do not have high accuracy and good generalization ability.
With the continuous development of artificial intelligence, deep learning technology in image recognition [
8] has been relatively mature [
9]. For example, great achievements have been made in the fields of face recognition [
10], medical image recognition [
11], remote sensing image classification [
12], ImageNet classification and recognition, traffic recognition, and character recognition. Deep learning can extract image features and achieve the function of image classification [
13] and recognition after a large-scale training. Therefore, deep learning is a very effective and universal technology in the field of target detection. Currently, target detection algorithms using deep learning methods are mainly divided into three categories, and the difference is whether there is a region proposal in the algorithm. The first category is multi-stage algorithms, such as R-CNN [
14] and SPPNet [
15]. The second is two-stage algorithms such as Fast R-CNN [
16], Faster R-CNN [
17], Mask R-CNN [
18], and Light-Head R-CNN [
19]. The third is single-stage algorithms, including YOLOV1 [
20], YOLOV2 [
21], YOLOV3 [
22], SSD [
23], Retina U-Net [
24], CenterNet [
25], FSAF [
26], FCOS [
27], YOLOV4 [
28], and YOLOX [
29]. The detection performance of the multi-stage algorithm and the two-stage algorithm is outstanding, but the detection rate in practical applications is not as good as that of the single-stage algorithm. Although the single-stage algorithm has a fast recognition speed, the accuracy rate is not high, and there are still cases of missed detection when the target to be detected is occluded. Therefore, our goal is to improve the YOLOX model and devise a solution that can address the above problems.
In traditional YOLOX, non-maximum suppression (NMS) sets the score of adjacent detection frames (the number of adjacent detection frames containing similar targets is greater than or equal to 2) to 0, resulting in the final output missing some of the target objects. This mechanism leads to missed detection that reduces detection accuracy [
30]. The Soft-NMS algorithm attenuates the scores of the above types of adjacent detection frames, rather than directly reducing their scores to 0. As long as the final score of the adjacent detection frame is greater than a certain threshold, the final output detection frame meets the expected result. The improved YOLOX is called Soft-YOLOX (using Soft-NMS instead of NMS in YOLOX). After Soft-NMS processing, the mAP value of YOLOX was 91.89%, which is 2.17% higher than that of the Original-NMS method. In the real-time detection case, the FPS reached 15.46. To further ensure the effectiveness of the improvement, we also used Soft-YOLOX to compare with other target detection algorithms, such as YOLOV4, Fast R-CNN, SSD, YOLOV5, etc. It can be seen from the mAP value in the comparison that Soft-YOLOX has greater detection performance and a lower missed detection rate. We make the following contributions:
We reveal why the traditional YOLOX model easily misses the target when the target is occluded, resulting in missed detection;
By improving YOLOX, we propose a new detection scheme (Soft-YOLOX). Experiments on the datasets show that the improved Soft-YOLOX can detect objects more accurately;
We compare Soft-YOLOX with other previous object detection algorithms, showing that Soft-YOLOX has better performance and is more favorable for deployment in real applications.
3. Methods
3.1. YOLOX and NMS Algorithms
The most significant thing in the YOLOX target detection algorithm is the YOLOX-CSPDarknet53 network structure.
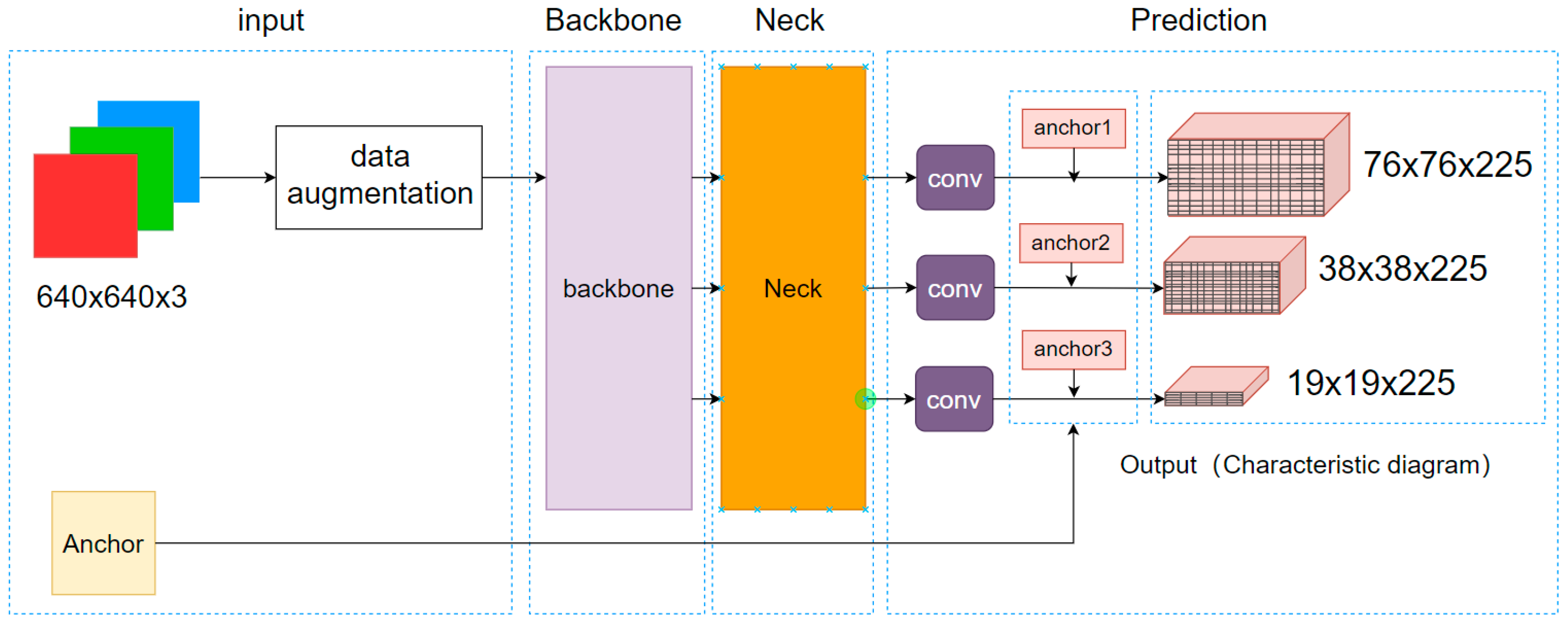
Figure 1 shows the network structure of YOLOX-CSPDarknet53. We split the YOLOX-CSPDarknet53 network structure into four parts: input, backbone network, neck, and prediction.
Input: YOLOX adopts two data enhancement methods, Mosaic [
31] and Mixup [
32]. In the realization process of this system, we only used the Mosaic data enhancement. Mosaic achieves data enhancement by using four images to be randomly scaled, cropped, and spliced, further improving the detection effect of small targets;
Backbone network: YOLOX uses the CSPDarknet53 network, which has 53 layers in total of convolutional networks. The last of these is a fully connected layer. What is used in the CSPDarknet53 is the residual network, Residual, which consists of two parts. One is mainly a 1 × 1 and 3 × 3 convolution, and another is the non-processed residual side part;
Neck: In the neck is a construction of the FPN feature pyramid for enhanced feature extraction. The FPN can fuse feature layers of different shapes, which can help improve the performance of the model and the detection ability of small targets;
Prediction:
The decoupled head is used in YOLOX. Compared with the previous target detection algorithm of the YOLO series, the decoupling head of YOLOX consists of two parts which are implemented separately and integrated at the final prediction;
The anchor-free detector does not use a priori box;
The SimOTA strategy, which can dynamically match positive samples to objects of different sizes, is adopted.
The original YOLOX model uses NMS to filter out the detection frames with the highest scores in a certain area belonging to the same category. However, only considering the detection frame and its IOU (Intersection over Union) in the calculation process, the elimination mechanism of NMS is very rigid, which easily leads to missed detection.
Figure 2 shows the missed detection of a target object.
As can be seen from
Figure 2, the sample is wrong. There are three leaves and a box on the drain cover. After NMS processing, there are cases of missed detection, such as the one leaf that is not detected in the figure. Obviously, the predicted results are not in line with the reality and cannot meet our expectation.
The critical step of accurate counting is meant to detect the targets successfully. When the target objects are blocked by each other, it is easy to cause missed detection. Therefore, we used Soft-NMS instead of the NMS method in the original YOLOX model as an improvement to solve this problem.
3.2. Principle of Soft-NMS Algorithm
First of all, from a mathematical point of view, the following principles explain the mechanism of NMS removing redundant frames:
The is the score of the current detection frame. After multiple tests on the dataset of this experiment, we found that the best threshold for IOU is 0.5.
During the experiment, we further found that when the detection frame with a higher IOU is adjacent to the detection frame with the highest score in all current detection frames, NMS reduces the score of this frame to 0, and then deletes it from the candidate frame set. Like the case in
Figure 2, it is likely to cause missed detection. Soft-NMS can solve this problem very well, and its mechanism for removing redundant frames is as follows:
It means that when Soft-NMS encounters a detection frame with a high IOU adjacent to the detection frame with the highest score, it does not directly set the score of the frame to 0. Compared with NMS, Soft-NMS adopts a penalty mechanism, which assigns the multiplication of the score of the current detection frame and the weight function as a penalty score and assigns it to the current detection frame. We used the Gaussian function as the weight function (θ is the parameter of the weight function; after many times of debugging, we defined the value of theta and set it to 0.1 according to the reference [
30]):
The larger the overlapped area of the detection frame with the highest score, the smaller the score this detection frame obtains. Lastly, only those detection frames with scores greater than or equal to 0.5 were left in the frame set, which is the candidate. Thus, Soft-NMS can remove redundant detection frames to reduce the rate of missed detection with effect. The flow chart that describes the Soft-NMS method is shown in
Figure 3.
The main idea of the Soft-NMS is as follows. At first, find all detection frames with a confidence higher than a threshold set manually from an image (no target object in the detection frame if below). Then, process the detection frames belonging to the same class. Finally, put all these detection frames into an established set S.
Sort all the detection frames in the set S according to their scores from high to low. The higher the score is, the higher the probability that the detection frame belongs to the category. Then, select the detection frame F with the highest score from the ordered set S;
Traverse each detection frame in set S, and then calculate the IOU of each detection frame and F. The Soft-NMS uses the weight function to calculate the weighted score of the current detection frame, and further assigns the weighted score to the currently traversed detection frame. The larger the overlapped area between the detection frame and F, the more serious the score attenuation. Finally, save F into the truth_box;
Go back to step 1 until the set S is empty. Finally, in truth_box, select detection frames with a score greater than or equal to 0.5 as the output of the target object.
After using the Soft-NMS method to process
Figure 2, the detection result can be seen in
Figure 4.
As can be seen from
Figure 4, the correct sample was obtained. There are three leaves and a box on the drain cover. After Soft-NMS processing, the missed detection in
Figure 2 disappeared. All objects in the image can be detected correctly. Obviously, the predicted results are in accordance with the reality and can meet our expectations.
3.3. System Framework
Figure 5 shows the application hierarchy of the system built on the problems studied in this paper.
Data layer: The area of sewer manhole covers is photographed and collected by road surveillance cameras. The camera is responsible for collecting image data, storing the image data in the system, and transmitting the image to the model in real time;
Processing layer: The recognition layer is the image processing layer of the system. It identifies manhole covers and garbage on them by the trained network model and returns the identification results to the system;
Application layer: The system makes real-time statistics and analysis according to the identification results of the model. Apart from this, the system also displays the results. If the amount of the garbage on the cover reaches the threshold, the system sends a corresponding early warning signal to the relevant staff.
4. Experimental Datasets and Evaluation Metrics
The datasets in this paper came from a research group that used a camera to simulate a road surveillance camera in a specific road scene, acquiring the situation of garbage near the sewer manhole covers at different periods and under various weather conditions at a roughly fixed angle. The advantage of doing this is that the trained model can make predictions for different scenarios and has better adaptability. Each video obtained ranged from more than ten seconds to several minutes, and the resolution of all videos was 1365 × 1024. Lastly, videos were split into frames, which were divided into two parts. Both parts contain the above datasets from different periods and under various circumstances. One of the parts was used as training sets and validating sets for training and validation of convolutional networks. The other part was used as a test for the trained model.
The annotation of the dataset was in the Pascal VOC format, and the size of each image was 1365 × 1024. For the YOLOX model, the input image was 640 × 640, thus all images could be preprocessed. There were 1800 images in the processed dataset with different types of garbage, drainage covers, and road information under different periods, weather, and road sections. To strengthen the effectiveness of the data in training, the research team also framed the data at different frame rates to reduce the workload of labeling and improve the learning efficiency of the model. Finally, we divided the dataset into the training set, verification set, and test set in the ratio of 7:2:1.
In the model evaluating the works of this paper, we had Precision, Recall, and mAP values as the evaluation indexes to evaluate the model [
33]. The calculation of Precision and Recall values are expressed by Formula (4) and Formula (5), respectively.
In the above two equations, TP means the prediction result is correctly classified as a positive sample, FP means the result is incorrectly classified as a positive sample, and FN means the result is incorrectly classified as a negative sample.
The dataset used in the evaluation includes the environment of daytime and rainy days, but excludes nighttime. In
Figure 6, the mAP values processed by NMS and Soft-NMS can be seen.
AP refers to the combination of Precision and Recall; Precision shows the prediction ability of the hit target passing the threshold in all prediction results, whereas Recall shows the ability to cover the real target in the test set. By combining the two, we can better evaluate our model. The mAP is the average of the average accuracy of each category, that is, the average AP of each category. The higher the mAP, the better the prediction ability of the model.
5. Results
5.1. Principle of Soft-NMS Algorithm
For YOLOX and Soft-YOLOX, the same prediction parameters and datasets were used to verify the effectiveness of the improvement we made. The difference is that YOLOX uses NMS, whereas Soft-YOLOX uses Soft-NMS. In the verification process, the detection effect and performance of the model are reflected by the evaluation metrics.
The mAP value of the YOLOX model processed by NMS is 89.72%, Precision is 91.54%, and Recall is 89.53%. The prediction results of the Soft-YOLOX model processed by Soft-NMS are improved, in which the mAP value is 91.89%, Precision is 92.93%, and Recall is 88.42%. The comparison results between the YOLOX model before and after improvement are shown in
Table 1.
Since Recall and Precision cannot comprehensively evaluate the effect of the algorithm, the mAP index was selected for analysis. As can be seen from the results in
Table 1, the mAP value and Precision value are higher than those of the original model, whereas Recall is lower. Soft-NMS removes redundant detection frames through the penalty mechanism of the weight function, thus reducing the missed detection rate. We found that the improvement of Soft-NMS was effective from the results.
5.2. Comparison with State-of-the-Art Methods
The experiments included the following comparison methods: Fast R-CNN [
16], target detection algorithm based on YOLOV4 (abbreviated as YOLOV4 [
34]), SSD [
23], and target detection algorithm based on YOLOV5 (abbreviated as YOLOV5 [
35]). All methods used the same evaluation index. It is not difficult to see that the Soft-YOLOX model improved performance compared with other algorithms. The detection results of each method on our dataset are shown in
Table 2.
5.3. Actual Application of the System
The left side of
Figure 7 shows that the system can detect the specific types and quantities of garbage in a complex garbage environment, which is convenient and allows for the system to further send early warning signals. The right side of
Figure 7 shows the real-time prediction results of the system on rainy days, in which the graphics card model used for reasoning was the RTX 1060 Ti, and the FPS (frames per second) was 15.46. The above results effectively demonstrate the feasibility of the project, and support our team in carrying out further research and development.
Currently, there are many cases about embedded deployment in YOLO series of algorithms, such as Fast YOLO [
36], Efficient YOLO [
37], YOLO nano [
38], and so on. The YOLOX algorithm in this paper can be implemented by exporting the ONNX model for embedded deployment, or by pruning and quantization to build the lightweight model of YOLO to, finally, achieve embedded deployment.
6. Conclusions
Compared with other target detection models, the new detection model and counting method of Soft-YOLOX proposed in this paper has better detection performance and robustness, and a lower missed detection rate. Garbage can be identified and counted accurately in the case of occlusion, which effectively avoids the phenomenon of missed detection.
With the help of public surveillance cameras on urban roads, the system collects real-time images of sanitary conditions in the areas with urban sewer manhole covers. After identifying, analyzing, and processing data by the Soft-YOLOX model, the client is shown the returned results. With future development of urban public facilities, the number of urban surveillance cameras and the area covered by cameras will continue to increase. A large amount of available image data can improve the accuracy of the model and the availability of the system. The enhancement of identification accuracy and processing capacity will also effectively help urban sanitation construction and improve urban sanitation levels [
39].
This paper proposed a new detection model called Soft-YOLOX based on YOLOX. By using Soft-NMS, the number of garbage can be accurately counted and the performance close to the actual application requirements obtained. The original YOLOX model is based on the NMS algorithm to remove redundant detection frames, whereas the YOLOX model proposed in this paper penalizes the score of detection frames based on the Soft-NMS algorithm. After comparative analysis, Soft-YOLOX had higher accuracy and lower missed detection in garbage detection applications. The mAP value of Soft-YOLOX was 91.89%, which is 2.17% higher than the YOLOX model. Therefore, Soft-YOLOX is more suitable for accumulated garbage quantity detection.
Author Contributions
Conceptualization, Z.Z. and J.L.; data curation, Y.L. and J.L.; validation, J.L., Y.L. and C.Y.; formal analysis, J.L., C.Y., Y.L., H.Z., Y.C. and Z.Z; funding acquisition, Z.Z. and J.L.; investigation, J.L.; supervision, Z.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by [the Young Innovative Talents Project of colleges and universities in Guangdong Province] grant number [2021KQNCX092]; [Doctoral program of Huizhou University] grant number [2020JB028]; [Outstanding Youth Cultivation Project of Huizhou University] grant number [HZU202009]; [Innovation Training Program for Chinese College Students] grant number [S202110577044]; [Special Funds for the Cultivation of Guangdong College Students’ Scientific and Technological Innovation. (“Climbing Program” Special Funds)] grant number [No. pdjh2022b0494].
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The dataset used in this paper is made by our team members, and some parts of the dataset can be found at the following link: [
https://github.com/Hzurang/Dataset]. (accessed on 1 July 2022).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Jin, H.; Wu, Y.; Xu, G.; Wu, Z. Research on an Urban Low-Altitude Target Detection Method Based on Image Classification. Electronics 2022, 11, 657. [Google Scholar] [CrossRef]
- Li, F.; Li, X.; Liu, Q.; Li, Z. Occlusion Handling and Multi-scale Pedestrian Detection Based on Deep Learning: A Review. IEEE Access 2022, 10, 19937–19957. [Google Scholar] [CrossRef]
- Chen, Y.; Zhou, H.; Zhang, H.; Du, G.; Zhou, J. Urban flood risk warning under rapid urbanization. Environ. Res. 2015, 139, 3–10. [Google Scholar] [CrossRef] [PubMed]
- Mikami, K.; Chen, Y.; Nakazawa, J. Deepcounter: Using deep learning to count garbage bags. In Proceedings of the 2018 IEEE 24th International Conference on Embedded and Real-Time Computing Systems and Applications (RTCSA), Hokkaido, Japan, 28–31 August 2018; pp. 1–10. [Google Scholar]
- Wei, Y.; Tian, Q.; Guo, J.; Huang, W.; Cao, J. Multi-vehicle detection algorithm through combining Harr and HOG features. Math. Comput. Simul. 2019, 155, 130–145. [Google Scholar] [CrossRef]
- Tan, G.X.; Sun, C.M.; Wang, J.H. Design of video vehicle detection system based on HOG features and SVM. J. Guangxi Univ. Sci. Technol. 2021, 32, 19–23. [Google Scholar]
- Zhai, J.; Zhou, X.; Wang, C. A moving target detection algorithm based on combination of GMM and LBP texture pattern. In Proceedings of the 2016 IEEE Chinese Guidance, Navigation and Control Conference (CGNCC), Nanjing, China, 12–14 August 2016; pp. 1057–1060. [Google Scholar]
- Pak, M.; Kim, S. A review of deep learning in image recognition. In Proceedings of the 2017 4th International Conference on Computer Applications and Information Processing Technology (CAIPT), Bali, Indonesia, 8–10 August 2017; pp. 1–3. [Google Scholar]
- Gou, J.; Yuan, X.; Du, L.; Xia, S.; Yi, Z. Hierarchical Graph Augmented Deep Collaborative Dictionary Learning for Classification. In Proceedings of the IEEE Transactions on Intelligent Transportation Systems, Macau, China, 8–12 October 2022. [Google Scholar]
- Li, L.; Mu, X.; Li, S.; Peng, H. A review of face recognition technology. IEEE Access 2020, 8, 139110–139120. [Google Scholar] [CrossRef]
- Shen, D.; Wu, G.; Suk, H.I. Deep learning in medical image analysis. Annu. Rev. Biomed. Eng. 2017, 19, 221–248. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, L.; Xia, G.-S.; Wu, T.; Lin, L.; Tai, X.-C. Deep learning for remote sensing image understanding. J. Sens. 2016, 2016, 7954154. [Google Scholar] [CrossRef]
- Gou, J.; Sun, L.; Du, L.; Ma, H.; Xiong, T.; Ou, W.; Zhan, Y. A representation coefficient-based k-nearest centroid neighbor classifier. Expert Syst. Appl. 2022, 194, 116529. [Google Scholar] [CrossRef]
- Chen, C.; Liu, M.Y.; Tuzel, O. R-CNN for Small Object Detection. Asian Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 214–230. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, J.; Liang, X.; Shen, S.; Xu, T.; Feng, J.; Yan, S. Scale-aware fast R-CNN for pedestrian detection. IEEE Trans. Multimed. 2017, 20, 985–996. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Li, Z.; Peng, C.; Yu, G. Light-head r-cnn: In defense of two-stage object detector. arXiv 2017, arXiv:1711.07264. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D. Ssd: Single Shot Multibox Detector. European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Jaeger, P.F.; Kohl, S.A.A.; Bickelhaupt, S.; Isensee, F.; Kuder, T.A.; Schlemmer, H.-P.; Maier-Hein, K.H. Retina U-Net: Embarrassingly simple exploitation of segmentation supervision for medical object detection. In Proceedings of the Machine Learning for Health Workshop, PMLR, Vancouver, BC, Canada, 13 December 2019; pp. 171–183. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Zhu, C.; He, Y.; Savvides, M. Feature selective anchor-free module for single-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 840–849. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS—Improving object detection with one line of code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]
- Zeng, G.; Yu, W.; Wang, R. Research on Mosaic Image Data Enhancement for Overlapping Ship Targets. arXiv 2021, arXiv:2105.05090. [Google Scholar]
- Fu, Y.; Wang, H.; Xu, K. Mixup based privacy preserving mixed collaboration learning. In Proceedings of the 2019 IEEE International Conference on Service-Oriented System Engineering (SOSE), San Francisco, CA, USA, 4–9 April 2019; pp. 275–2755. [Google Scholar]
- Zhang, M.; Wang, C.; Yang, J. Research on Engineering Vehicle Target Detection in Aerial Photography Environment based on YOLOX. In Proceedings of the 2021 14th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 11–12 December 2021; pp. 254–256. [Google Scholar]
- Zhang, Z.; Xia, S.; Cai, Y. A Soft-YoloV4 for High-Performance Head Detection and Counting. Mathematics 2021, 9, 3096. [Google Scholar] [CrossRef]
- Zhou, F.; Zhao, H.; Nie, Z. Safety helmet detection based on YOLOv5. In Proceedings of the 2021 IEEE International Conference on Power Electronics, Computer Applications (ICPECA), Shenyang, China, 22–24 January 2021; pp. 6–11. [Google Scholar]
- Shaifee, M.J.; Chywl, B.; Li, F.; Wong, A. Fast YOLO: A fast you only look once system for real-time embedded object detection in video. arXiv 2017, arXiv:1709.05943. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, J.; Zhao, Z. Efficient yolo: A lightweight model for embedded deep learning object detection. In Proceedings of the 2020 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Wong, A.; Famuori, M.; Shafiee, M.J. Yolo nano: A highly compact you only look once convolutional neural network for object detection. In Proceedings of the 2019 Fifth Workshop on Energy Efficient Machine Learning and Cognitive Computing-NeurIPS Edition (EMC2-NIPS), Vancouver, BC, Canada, 13 December 2019; pp. 22–25. [Google Scholar]
- Wang, Y.; Zhang, X. Autonomous garbage detection for intelligent urban management. MATEC Web of Conferences. EDP Sci. 2018, 232, 01056. [Google Scholar]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}