
Intrinsic Correlation with Betweenness Centrality and Distribution of Shortest Paths


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- 1.
- We propose a novel algorithm that can analyze networks hierarchically and is convenient for conducting in-depth study on betweenness centrality;
- 2.
- We discover the distribution of shortest paths has intrinsic correlation with the betweenness distribution, and experimental evidence confirms this relationship;
- 3.
- We find that the betweenness centrality indices of some nodes are 0, but these nodes are not edge nodes and characterize critical significance in real networks.
2. Related Work
2.1. Betweenness Centrality
2.2. Brandes’ Algorithm
2.3. DAWN Algorithm
3. Design of the NAHAN Algorithm
3.1. Unweighted Networks
- 1.
- The element in matrix represents the number of paths with the length k between nodes i and j in the network.
- 2.
- The element in matrix represents the number of paths with the length k that do not pass through node v when going between nodes i and j in the network.
- 3.
- The element in matrix represents the number of paths with the length k that pass through node v when going between nodes i and j in the network.
| Algorithm 1 Unweighted Networks |
| Input: |
| Output: |
|
3.2. Weighted Networks
- 1.
- Matrix represents the number of paths with the weight k between nodes i and j in the network. Matrix represents the adjacency matrix corresponding to the subnetwork formed by the edges with the weight 1 in the adjacency matrix .
- 2.
- Matrix represents the number of paths with weight k that do not pass through node v between nodes i and j in the network. Matrix represents the adjacency matrix corresponding to the subnetwork formed by the edges with a weight of 1 that do not pass through node v in the adjacency matrix .
- 3.
- Matrix represents the number of paths with the weight k that pass through node v between nodes i and j in the network. Matrix represents the adjacency matrix corresponding to the subnetwork formed by the edges with the weight 1 that pass through node v in the adjacency matrix .
- 4.
- Matrix represents the adjacency matrix corresponding to the subnetwork formed by the edges with the weight k in the adjacency matrix . If there is no edge with the weight k in the network, then is a null matrix, and we also define as a null matrix.
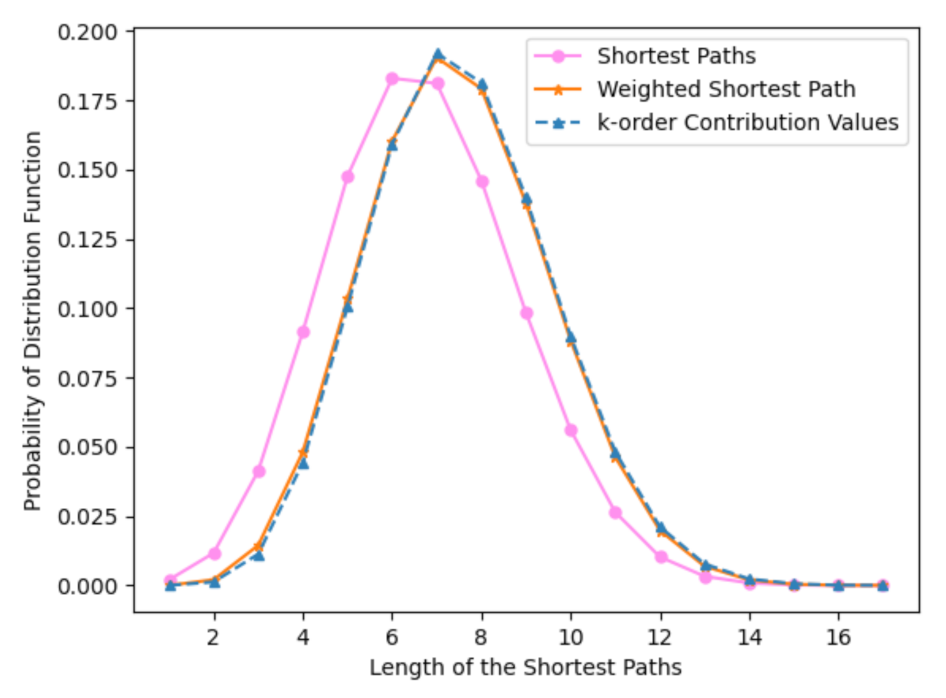
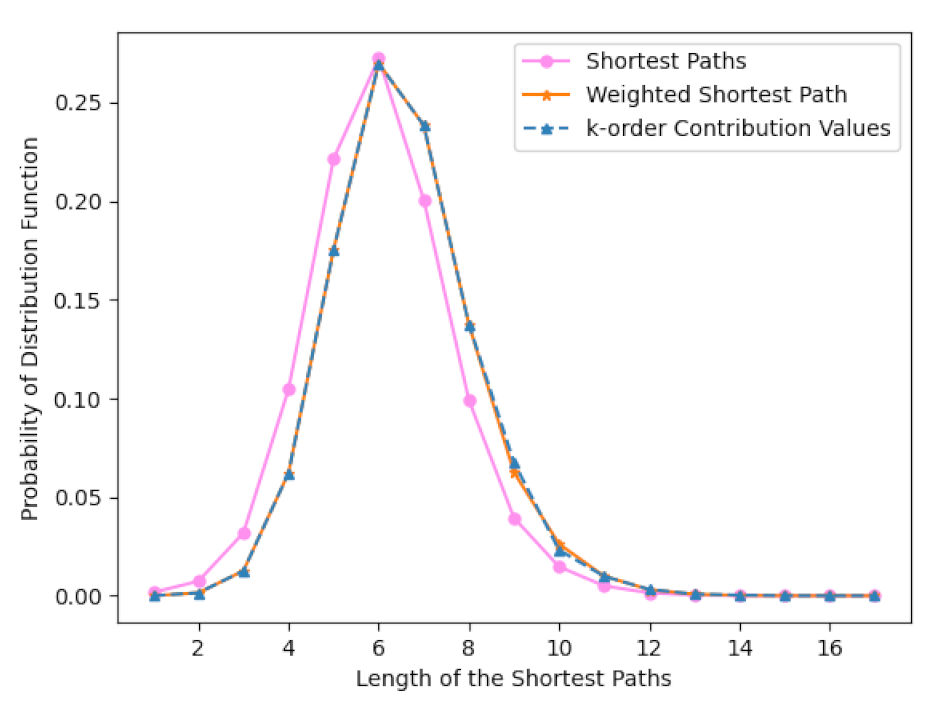
4. Distribution of Betweenness and Shortest Paths
5. Betweenness Centrality of Special Nodes
5.1. Specific Nodes in the Networks
- 1.
- We assume that there is the node 1, which forms the undirected network with the first-order neighbor nodes 2, 3 ( is shown in Figure 1);
- 2.
- There is a shortest path of length 1 between nodes 2 and 3, so the betweenness centrality index of node 1 is 0;
- 3.
- Step 2 illustrates that Theorem 1 holds in Figure 1, and we add the node 3, which is potentially connected to any of three nodes;
- When node 4 is connected to node 2 and 3, the betweenness centrality index of node 1 is 0;
- When node 4 is connected to node 1, the shortest path from node 4 to node 2 and 3 passes through node 2, and the betweenness centrality index of node 2 is not 0;
- It is necessary to add edges and nodes, which makes the betweenness centrality index of the node 1, and forms an undirected network (), which is shown in Figure 2);
- The network shown in Figure 2 is a fully connected subgraph formed by node 1 and its first-order neighbor nodes.
- 4.
5.2. Fully Connected Component
- 1.
- We assume that there is a specific connected component, which is a fully connected component and is represented by an undirected network () (shown in Figure 3);
- 2.
- Each pair of nodes in the connected component has the shortest paths of length 1, which makes the betweenness centrality indices of nodes 0;
- 3.
- 4.
- In the case of step 3, in the connected component, except for the nodes connected to the , the betweenness centrality indices of nodes is 0.
5.3. Contribution of Special Nodes
- 1.
- For the nodes for which betweenness centrality is not 0, there is at least one shortest path of length 2 passing through the node;
- 2.
- The betweenness centrality indices of the node with a second-order contribution value of 0 must be 0.
5.4. Discussion of Centrality Measures
6. Experimental Results
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| Notation | Definition |
| G | A graph |
| Set of nodes, edges and weights | |
| A node, edge and weight of edges | |
| Betweenness centrality and its normalization | |
| Adjacency matrix of unweighted graphs and weighted graphs | |
| Adjacency matrix of unweighted graphs and weighted graphs without v | |
| Adjacency matrix of unweighted graphs and weighted graphs through v | |
| Occurrence frequency of node v with the shortest paths length k | |
| K-order contribution value of node v with the shortest paths length k | |
| Constant parameter |
Appendix A. Example

Appendix B. Mathematical Foundation
References
- Li, D.; Ma, J.; Yao, C.; Chen, W.; Zhang, Z. Informatization Promotes Accurate Management and Open Sharing of National Natural Science Fund. In China’s e-Science Blue Book 2018; Springer: Singapore, 2020; pp. 219–234. [Google Scholar]
- Tizghadam, A.; Leon-Garcia, A. Betweenness centrality and resistance distance in communication networks. IEEE Netw. 2010, 24, 10–16. [Google Scholar] [CrossRef]
- Puzis, R.; Altshuler, Y.; Elovici, Y.; Bekhor, S.; Shiftan, Y.; Pentland, A. Augmented betweenness centrality for environmentally aware traffic monitoring in transportation networks. J. Intell. Transp. Syst. 2013, 17, 91–105. [Google Scholar] [CrossRef] [Green Version]
- Brandes, U. A faster algorithm for betweenness centrality. J. Math. Sociol. 2001, 25, 163–177. [Google Scholar] [CrossRef]
- Jin, S.; Huang, Z.; Chen, Y.; Chavarría-Miranda, D.; Feo, J.; Wong, P.C. A novel application of parallel betweenness centrality to power grid contingency analysis. In Proceedings of the 2010 IEEE International Symposium on Parallel and Distributed Processing (IPDPS), Atlanta, GA, USA, 19–23 April 2010; pp. 1–7. [Google Scholar]
- Mehmood, A.; Choi, G.S.; von Feigenblatt, O.F.; Park, H.W. Proving ground for social network analysis in the emerging research area “Internet of Things”(IoT). Scientometrics 2016, 109, 185–201. [Google Scholar] [CrossRef]
- Zhou, T.; Bo, W.; Wang, B. Overview of complex network research. Physics 2005, 34. [Google Scholar]
- Guo, L.; Xu, X. Complex Networks; Shanghai Science and Technology Education Press: Shanghai, China, 2010; pp. 1–15. [Google Scholar]
- Barabási, A.L. Network science. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2013, 371, 7–9. [Google Scholar] [CrossRef]
- González, H.F.; Narasimhan, S.; Johnson, G.W.; Wills, K.E.; Haas, K.F.; Konrad, P.E.; Chang, C.; Morgan, V.L.; Rubinov, M.; Englot, D.J. Role of the nucleus basalis as a key network node in temporal lobe epilepsy. Neurology 2021, 96, e1334–e1346. [Google Scholar] [CrossRef] [PubMed]
- Stoffers, D.; Altena, E.; van der Werf, Y.D.; Sanz-Arigita, E.J.; Voorn, T.A.; Astill, R.G.; Strijers, R.L.; Waterman, D.; Van Someren, E.J. The caudate: A key node in the neuronal network imbalance of insomnia? Brain 2014, 137, 610–620. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pereira, J.; Saura, S.; Jordan, F. Single-node vs. multi-node centrality in landscape graph analysis: Key habitat patches and their protection for 20 bird species in NE Spain. Methods Ecol. Evol. 2017, 8, 1458–1467. [Google Scholar] [CrossRef]
- Liu, F.; Xiao, B.; Li, H. Finding key node sets in complex networks based on improved discrete fireworks algorithm. J. Syst. Sci. Complex. 2021, 34, 1014–1027. [Google Scholar] [CrossRef]
- Ding, J.; Wen, C.; Li, G. Key node selection in minimum-cost control of complex networks. Phys. A Stat. Mech. Appl. 2017, 486, 251–261. [Google Scholar] [CrossRef]
- Li, X.; Tang, Y.; Du, Y.; Li, Y. Key Node Discovery Algorithm Based on Multiple Relationships and Multiple Features in Social Networks. Math. Probl. Eng. 2021, 2021, 1956356. [Google Scholar] [CrossRef]
- Gómez, D.; Castro, J.; Gutiérrez, I.; Espínola, R. A New Edge Betweenness Measure Using a Game Theoretical Approach: An Application to Hierarchical Community Detection. Mathematics 2021, 9, 2666. [Google Scholar] [CrossRef]
- Grobelny, B.T.; London, D.; Hill, T.C.; North, E.; Dugan, P.; Doyle, W.K. Betweenness centrality of intracranial electroencephalography networks and surgical epilepsy outcome. Clin. Neurophysiol. 2018, 129, 1804–1812. [Google Scholar] [CrossRef]
- Makarov, V.V.; Zhuravlev, M.O.; Runnova, A.E.; Protasov, P.; Maksimenko, V.A.; Frolov, N.S.; Pisarchik, A.N.; Hramov, A.E. Betweenness centrality in multiplex brain network during mental task evaluation. Phys. Rev. E 2018, 98, 062413. [Google Scholar] [CrossRef]
- Arasteh, M.; Alizadeh, S. A fast divisive community detection algorithm based on edge degree betweenness centrality. Appl. Intell. 2019, 49, 689–702. [Google Scholar] [CrossRef]
- Nigam, R.; Sharma, D.K.; Jain, S.; Srivastava, G. A local betweenness centrality based forwarding technique for social opportunistic IoT networks. Mob. Netw. Appl. 2022, 27, 547–562. [Google Scholar] [CrossRef]
- Tokito, S.; Kagawa, S.; Hanaka, T. Hypothetical extraction, betweenness centrality, and supply chain complexity. Econ. Syst. Res. 2022, 34, 111–128. [Google Scholar] [CrossRef]
- Liu, W.; Li, X.; Liu, T.; Liu, B. Approximating betweenness centrality to identify key nodes in a weighted urban complex transportation network. J. Adv. Transp. 2019, 2019, 9024745. [Google Scholar] [CrossRef]
- Xing, L.; Dong, X.; Guan, J.; Qiao, X. Betweenness centrality for similarity-weight network and its application to measuring industrial sectors’ pivotability on the global value chain. Phys. A Stat. Mech. Appl. 2019, 516, 19–36. [Google Scholar] [CrossRef]
- Madduri, K.; Ediger, D.; Jiang, K.; Bader, D.A.; Chavarria-Miranda, D. A faster parallel algorithm and efficient multithreaded implementations for evaluating betweenness centrality on massive datasets. In Proceedings of the 2009 IEEE International Symposium on Parallel & Distributed Processing, Rome, Italy, 23–29 May 2009; pp. 1–8. [Google Scholar]
- Bader, D.A.; Kintali, S.; Madduri, K.; Mihail, M. Approximating betweenness centrality. In International Workshop on Algorithms and Models for the Web-Graph; Springer: Berlin/Heidelberg, Germany, 2007; pp. 124–137. [Google Scholar]
- Furno, A.; El Faouzi, N.E.; Sharma, R.; Zimeo, E. Fast approximated betweenness centrality of directed and weighted graphs. In Complex Networks and Their Applications; Springer: Cham, Switzerland, 2018; pp. 52–65. [Google Scholar]
- Feng, Y.; Wang, H.; Lu, H. A Faster Algorithm for Betweenness Centrality Based on Adjacency Matrices. arXiv 2022, arXiv:2205.00162. [Google Scholar]
- Bavelas, A. Communication patterns in task-oriented groups. J. Acoust. Soc. Am. 1950, 22, 725–730. [Google Scholar] [CrossRef]
- Freeman, L.C. A set of measures of centrality based on betweenness. Sociometry 1977, 40, 35–41. [Google Scholar] [CrossRef]
- Freeman, L.C. Centrality in social networks conceptual clarification. Soc. Netw. 1978, 1, 215–239. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Tang, C.Y. Distributed computation of node and edge betweenness on tree graphs. In Proceedings of the 52nd IEEE Conference on Decision and Control, Firenze, Italy, 10–13 December 2013; pp. 43–48. [Google Scholar]
- Erdős, D.; Ishakian, V.; Bestavros, A.; Terzi, E. A divide-and-conquer algorithm for betweenness centrality. In Proceedings of the 2015 SIAM International Conference on Data Mining, Vancouver, BC, Canada, 30 April–2 May 2015; pp. 433–441. [Google Scholar]
- Bentert, M.; Dittmann, A.; Kellerhals, L.; Nichterlein, A.; Niedermeier, R. An Adaptive Version of Brandes’ Algorithm for Betweenness Centrality. arXiv 2018, arXiv:1802.06701. [Google Scholar] [CrossRef]
- Hagberg, A.; Swart, P.; Chult, D.S. Exploring Network Structure, Dynamics, and Function Using NetworkX; Technical Report; Los Alamos National Lab. (LANL): Los Alamos, NM USA, 2008. [Google Scholar]
- Erdős, P.; Rényi, A. On the evolution of random graphs. Publ. Math. Inst. Hung. Acad. Sci 1960, 5, 17–60. [Google Scholar]
- Barabási, A.L.; Albert, R. Emergence of scaling in random networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef] [Green Version]
- Albert, R.; Jeong, H.; Barabási, A.L. Diameter of the world-wide web. Nature 1999, 401, 130–131. [Google Scholar] [CrossRef] [Green Version]
- Faloutsos, M.; Faloutsos, P.; Faloutsos, C. On power-law relationships of the internet topology. ACM SIGCOMM Comput. Commun. Rev. 1999, 29, 251–262. [Google Scholar] [CrossRef]
- Watts, D.J.; Strogatz, S.H. Collective dynamics of ‘small-world’networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef]
- Amaral, L.A.N.; Scala, A.; Barthelemy, M.; Stanley, H.E. Classes of small-world networks. Proc. Natl. Acad. Sci. USA 2000, 97, 11149–11152. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, H.; Wang, C.; Shu, N.; Ma, C.; Yang, F. The Betweenness Identities and Their Applications. In Proceedings of the 2020 IEEE 20th International Conference on Communication Technology (ICCT), Nanning, China, 28–31 October 2020; pp. 1065–1069. [Google Scholar] [CrossRef]
- Shu, N.; Wang, H.; Wang, C.; Zhu, X.; Ma, C.; Chang, C. Global Betweenness Identities in the Networks. In Proceedings of the 2021 IEEE 21st International Conference on Communication Technology (ICCT), Tianjin, China, 13–16 October 2021; pp. 783–786. [Google Scholar] [CrossRef]
- Wang, H.; Ma, T.; Wang, C.; Shu, N.; Huang, J.; Wang, M. The Bridge and Link Betweenness in the Networks. In Proceedings of the 2020 IEEE 20th International Conference on Communication Technology (ICCT), Nanning, China, 28–31 October 2020; pp. 1097–1101. [Google Scholar] [CrossRef]
- Katzav, E.; Nitzan, M.; Ben-Avraham, D.; Krapivsky, P.; Kühn, R.; Ross, N.; Biham, O. Analytical results for the distribution of shortest path lengths in random networks. EPL (Europhys. Lett.) 2015, 111, 26006. [Google Scholar] [CrossRef] [Green Version]
- Katz, L. A new status index derived from sociometric analysis. Psychometrika 1953, 18, 39–43. [Google Scholar] [CrossRef]
- Bonacich, P. Factoring and weighting approaches to status scores and clique identification. J. Math. Sociol. 1972, 2, 113–120. [Google Scholar] [CrossRef]
- Dangalchev, C. Residual closeness in networks. Phys. A Stat. Mech. Appl. 2006, 365, 556–564. [Google Scholar] [CrossRef]
- Liao, H.; Mariani, M.S.; Medo, M.; Zhang, Y.C.; Zhou, M.Y. Ranking in evolving complex networks. Phys. Rep. 2017, 689, 1–54. [Google Scholar] [CrossRef] [Green Version]
- Brin, S.; Page, L. The anatomy of a large-scale hypertextual web search engine. Comput. Netw. ISDN Syst. 1998, 30, 107–117. [Google Scholar] [CrossRef]
- Leskovec, J.; Kleinberg, J.; Faloutsos, C. Graph evolution: Densification and shrinking diameters. ACM Trans. Knowl. Discov. Data (TKDD) 2007, 1, 2-es. [Google Scholar] [CrossRef]
- Harary, F.; Norman, R.Z.; Cartwright, D. Structural Models: An Introduction to the Theory of Directed Graphs; Wiley: New York, NY, USA, 1965; Volume 5, pp. 111–115. [Google Scholar]






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, Y.; Wang, H.; Chang, C.; Lu, H. Intrinsic Correlation with Betweenness Centrality and Distribution of Shortest Paths. Mathematics 2022, 10, 2521. https://doi.org/10.3390/math10142521
Feng Y, Wang H, Chang C, Lu H. Intrinsic Correlation with Betweenness Centrality and Distribution of Shortest Paths. Mathematics. 2022; 10(14):2521. https://doi.org/10.3390/math10142521
Chicago/Turabian StyleFeng, Yelai, Huaixi Wang, Chao Chang, and Hongyi Lu. 2022. "Intrinsic Correlation with Betweenness Centrality and Distribution of Shortest Paths" Mathematics 10, no. 14: 2521. https://doi.org/10.3390/math10142521