
Comparison of the Predictive Performance of Medical Coding Diagnosis Classification Systems

Abstract
:1. Introduction
- MS-DRGs outperform the principal ICD-10-CM Dx codes for the prediction of in-patient mortality and LOS, since they incorporate information about the presence or not of (major) complications or comorbidities. This information is not incorporated into the principal ICD-10-CM.
- CCS and CCSR codes perform reasonably well compared to ICD-10-CM codes for in-patient mortality and LOS, since CCS consist of manual, expert-designed representations of medical Dx’s in a clinically meaningful way.
2. Materials and Methods
2.1. Dataset
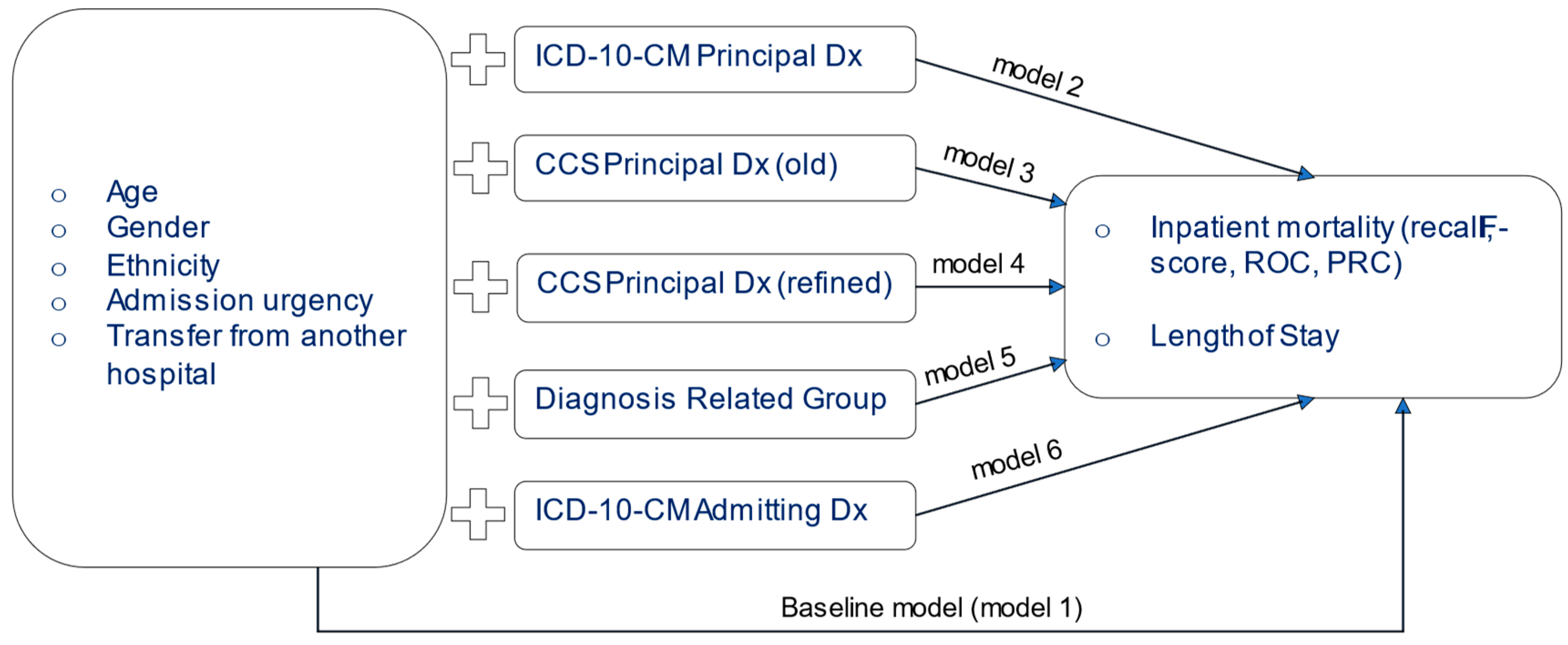
2.2. Experimental Setup
2.3. Pipeline for Data Preparation and Analysis
- Step 1: The following variables were extracted from the original dataset: ‘age group’, ‘gender’, ‘race’, ‘admission was elective (yes/no)’, ‘transfer from another hospital (yes/no)’, ‘length of stay’, ‘discharge status (alive/dead)’, ‘icd-10-dx principal Dx’, ‘icd-10-cm admitting Dx’, ‘DRG code’.
- Step 2: The ‘CCS Principal Dx (old)’ and ‘CCS Principal Dx (refined)’ to ICD-10-CM mapping dataset was acquired from the AHRQ website (https://www.hcup-us.ahrq.gov/toolssoftware/ccs/ccs.jsp (accessed on 29 June 2022)).
- Step 3: The CCS variables were merged with the first dataset to form the target file.
- Step 4: All categorical control variables were transformed to dichotomous (0/1), and the dataset was inserted into Weka.
- Step 5: A randomized sample of 50,000 cases was generated using the ReservoirSample algorithm of Weka.
- Step 6a(i): Using Naïve Bayes models were generated for the outcome ‘discharge status’ using the following parameters: batchSize = 100, numDecimals = 2
- Step 6a(ii): using 10-fold validation, each model was tested and the metrics of recall, PRC, f-score for the outcome of ‘died’ and the ROC were calculated.
- Step 7b(i) and 7b(ii): The same process was followed using the Random Forest algorithm with the following parameters: bagSize% = 100, batchSize = 100, maxDepth = n/a, numDecimals = 2, numExecuionSlots = 1, numIterations (number of trees) = 100
- Step 8: Using multiple linear regression, six models were trained for the numerical outcome of Length of Stay. Each model had the exact same predictors as shown in 6a(i). Each model was tested with 10-fold validation and the following metrics were calculated: model fit (R2), mean absolute error, root mean squared error.
3. Results
3.1. Data Description
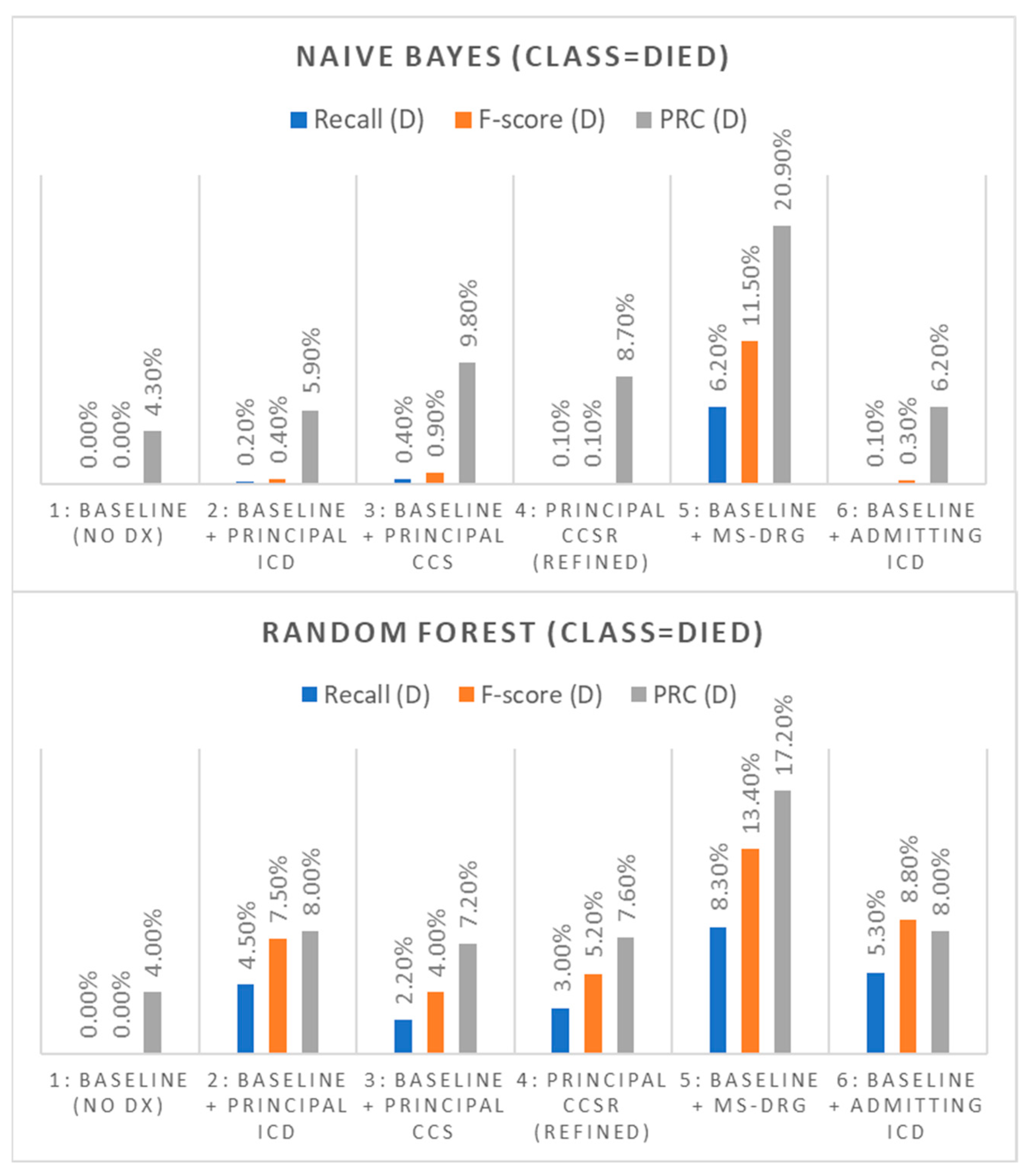
3.2. Prediction of In-Patient Mortality
3.3. Prediction of Hospital Length of Stay (LOS)
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shah, N.; Konchak, C.; Chertok, D.; Au, L.; Kozlov, A.; Ravichandran, U.; McNulty, P.; Liao, L.; Steele, K.; Kharasch, M.; et al. Clinical Analytics Prediction Engine (CAPE): Development, electronic health record integration and prospective validation of hospital mortality, 180-day mortality and 30-day readmission risk prediction models. PLoS ONE 2020, 15, e0238065. [Google Scholar] [CrossRef] [PubMed]
- Capobianco, E. Data-driven clinical decision processes: It’s time. J. Transl. Med. 2019, 17, 44. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Konchak, C.W.; Krive, J.; Au, L.; Chertok, D.; Dugad, P.; Granchalek, G.; Livschiz, E.; Mandala, R.; McElvania, E.; Park, C.; et al. From Testing to Decision-Making: A Data-Driven Analytics COVID-19 Response. Acad. Pathol. 2021, 8, 23742895211010257. [Google Scholar] [CrossRef] [PubMed]
- Englum, B.R.; Saha-Chaudhuri, P.; Shahian, D.M.; O’Brien, S.M.; Brennan, J.M.; Edwards, F.H.; Peterson, E.D. The impact of high-risk cases on hospitals’ risk-adjusted coronary artery bypass grafting mortality rankings. Ann. Thorac. Surg. 2015, 99, 856–862. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Symum, H.; Zayas-Castro, J. Identifying Children at Readmission Risk: At-Admission versus Traditional At-Discharge Readmission Prediction Model. Healthcare 2021, 9, 1334. [Google Scholar] [CrossRef] [PubMed]
- MS-DRG Classifications and Software (CMS.gov). Available online: https://www.cms.gov/Medicare/Medicare-Fee-for-Service-Payment/AcuteInpatientPPS/MS-DRG-Classifications-and-Software (accessed on 29 June 2022).
- Mishra, R.; Verma, H.; Aynala, V.B.; Arredondo, P.R.; Martin, J.; Korvink, M.; Gunn, L.H. Diagnostic Coding Intensity among a Pneumonia Inpatient Cohort Using a Risk-Adjustment Model and Claims Data: A US Population-Based Study. Diagnostics 2022, 12, 1495. [Google Scholar] [CrossRef] [PubMed]
- Clinical Classifications Software (CCS) for ICD-10-PCS. Available online: https://www.hcup-us.ahrq.gov/toolssoftware/ccs10/ccs10.jsp (accessed on 29 June 2022).
- Davies, B.J.; Allareddy, V.; Konety, B.R. Effect of postcystectomy infectious complications on cost, length of stay, and mortality. Urology 2009, 73, 598–602. [Google Scholar] [CrossRef] [PubMed]
- Goudie, A.; Dynan, L.; Brady, P.W.; Rettiganti, M. Attributable cost and length of stay for central line–associated bloodstream infections. Pediatrics 2014, 133, e1525–e1532. [Google Scholar] [CrossRef] [Green Version]
- De la Garza Ramos, R.; Goodwin, C.R.; Jain, A.; Abu-Bonsrah, N.; Fisher, C.G.; Bettegowda, C.; Sciubba, D.M. Development of a metastatic spinal tumor frailty index (MSTFI) using a nationwide database and its association with inpatient morbidity, mortality, and length of stay after spine surgery. World Neurosurg. 2016, 95, 548–555. [Google Scholar] [CrossRef] [PubMed]
- Ramkumar, P.N.; Navarro, S.M.; Frankel, W.C.; Haeberle, H.S.; Delanois, R.E.; Mont, M.A. Evidence-based thresholds for the volume and length of stay relationship in total hip arthroplasty: Outcomes and economies of scale. J. Arthroplast. 2018, 33, 2031–2037. [Google Scholar] [CrossRef] [PubMed]
- Sakai, M.; Kou, Y.F.; Shah, G.B.; Johnson, R.F. Tracheostomy demographics and outcomes among pediatric patients ages 18 years or younger—United States 2012. Laryngoscope 2019, 129, 1706–1711. [Google Scholar] [CrossRef]
- Kim, V.; Lodaya, K.; Marinaro, X.; Zhang, X.; Hayashida, D.K.; Munson, S.; D’Souza, F. PGI28 Investigating Length of Stay in Gastrointestinal Patient Surgical Clusters in the National Inpatient Sample with Machine Learning. Value Health 2021, 24, S99. [Google Scholar] [CrossRef]
- Pathak, R.; Giri, S.; Aryal, M.R.; Karmacharya, P.; Bhatt, V.R.; Martin, M.G. Mortality, length of stay, and health care costs of febrile neutropenia-related hospitalizations among patients with breast cancer in the United States. Support. Care Cancer 2015, 23, 615–617. [Google Scholar] [CrossRef]
- Cheng, S.; Essery, S.; Braithwaite, J.; Howes, M. A study using working DRGs to examine variations in length of stay. Health Inf. Manag. J. Health Inf. Manag. Assoc. Aust. 1994, 24, 7–11. [Google Scholar] [CrossRef]
- MaWhinney, S.; Brown, E.R.; Malcolm, J.; VillaNueva, C.; Groves, B.M.; Quaife, R.A.; Lindenfeld, J.; Warner, B.A.; Hammermeister, K.E.; Grover, F.L.; et al. Identification of risk factors for increased cost, charges, and length of stay for cardiac patients. Ann. Thorac. Surg. 2000, 70, 702–710. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Phillips, M.; Codde, J. Factors influencing patients’ length of stay. Aust. Health Rev. 2001, 24, 63–70. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rutledge, R.; Osler, T. The ICD-9-based illness severity score: A new model that outperforms both DRG and APR-DRG as predictors of survival and resource utilization. J. Trauma 1998, 45, 791–799. [Google Scholar] [CrossRef]
- Omachonu, V.K.; Suthummanon, S.; Akcin, M.; Asfour, S. Predicting length of stay for Medicare patients at a teaching hospital. Health Serv. Manag. Res. 2004, 17, 1–12. [Google Scholar] [CrossRef]
- Carr, C.J.; Mears, S.C.; Barnes, C.L.; Stambough, J.B. Length of stay after joint arthroplasty is less than predicted using two risk calculators. J. Arthroplast. 2021, 36, 3073–3077. [Google Scholar] [CrossRef]
- Bert, F.; Kakaa, O.; Corradi, A.; Mascaro, A.; Roggero, S.; Corsi, D.; Scarmozzino, A.; Siliquini, R. Predicting Length of Stay and Discharge Destination for Surgical Patients: A Cohort Study. Int. J. Environ. Res. Public Health 2020, 17, 9490. [Google Scholar] [CrossRef]
- Deschepper, M.; Eeckloo, K.; Vogelaers, D.; Waegeman, W. A hospital wide predictive model for unplanned readmission using hierarchical ICD data. Comput. Methods Programs Biomed. 2019, 173, 177–183. [Google Scholar] [CrossRef] [PubMed]
- Harerimana, G.; Kim, J.W.; Jang, B. A deep attention model to forecast the Length Of Stay and the in-hospital mortality right on admission from ICD codes and demographic data. J. Biomed. Inform. 2021, 118, 103778. [Google Scholar] [CrossRef]
- Karnuta, J.M.; Churchill, J.L.; Haeberle, H.S.; Nwachukwu, B.U.; Taylor, S.A.; Ricchetti, E.T.; Ramkumar, P.N. The value of artificial neural networks for predicting length of stay, discharge disposition, and inpatient costs after anatomic and reverse shoulder arthroplasty. J. Shoulder Elb. Surg. 2020, 29, 2385–2394. [Google Scholar] [CrossRef] [PubMed]
- Aubert, C.E.; Schnipper, J.L.; Roumet, M.; Marques-Vidal, P.; Stirnemann, J.; Auerbach, A.D.; Zimlichman, E.; Kripalani, S.; Vasilevskis, E.E.; Robinson, E.; et al. Best definitions of multimorbidity to identify patients with high health care resource utilization. Mayo Clin. Proc. Innov. Qual. Outcomes 2020, 4, 40–49. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Radley, D.C.; Gottlieb, D.J.; Fisher, E.S.; Tosteson, A.N. Comorbidity risk-adjustment strategies are comparable among persons with hip fracture. J. Clin. Epidemiol. 2008, 61, 580–587. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ramkumar, P.N.; Navarro, S.M.; Haeberle, H.S.; Karnuta, J.M.; Mont, M.A.; Iannotti, J.P.; Patterson, B.M.; Krebs, V.E. Development and validation of a machine learning algorithm after primary total hip arthroplasty: Applications to length of stay and payment models. J. Arthroplast. 2019, 34, 632–637. [Google Scholar] [CrossRef]
- Center for Medicare & Medicaid Services (CMS), Medicare Claims Data. Available online: https://healthdata.gov/dataset/Center-for-Medicare-Medicaid-Services-CMS-Medicare/buvm-ucbs (accessed on 29 June 2022).
- Zikos, D. Session Details: Reasoning Systems and Machine Learning. In PETRA, Proceedings of the 12th ACM International Conference on PErvasive Technologies Related to Assistive Environments, Rhodes Greece, 5–7 June 2019; Association for Computing Machinery: New York, NY, USA, 2019. [Google Scholar]
- Das, M.; Dash, R. A Comparative Study on Performance of Classification Algorithms for Breast Cancer Data Set Using WEKA Tool. In Intelligent Systems; Springer: Singapore, 2022; pp. 289–297. [Google Scholar]
- Nagwani, N.K. Stream Mining: Introduction, Tools & Techniques and Applications. Data Mining and Machine Learning Applications. Data Min. Mach. Learn. Appl. 2022, 24, 99–124. [Google Scholar]
- Bhatia, S.; Malhotra, J. Naïve Bayes Classifier for Predicting the Novel Coronavirus. In Proceedings of the 2021 Third International Conference on Intelligent Communication Technologies and Virtual Mobile Networks (ICICV), Tirunelveli, India, 4–6 February 2021; pp. 880–883. [Google Scholar]
- Bayramli, I.; Castro, V.; Barak-Corren, Y.; Madsen, E.M.; Nock, M.K.; Smoller, J.W.; Reis, B.Y. Temporally informed random forests for suicide risk prediction. J. Am. Med. Inform. Assoc. 2022, 29, 62–71. [Google Scholar] [CrossRef]
- Röösli, E.; Bozkurt, S.; Hernandez-Boussard, T. Peeking into a black box, the fairness and generalizability of a MIMIC-III benchmarking model. Sci. Data 2022, 9, 24. [Google Scholar] [CrossRef]
- Javeed, M.; Jalal, A.; Kim, K. Wearable sensors based exertion recognition using statistical features and random forest for physical healthcare monitoring. In Proceedings of the 2021 International Bhurban Conference on Applied Sciences and Technologies (IBCAST), Islamabad, Pakistan, 12–16 January 2021; pp. 512–517. [Google Scholar]
- Mohnen, S.M.; Rotteveel, A.H.; Doornbos, G.; Polder, J.J. Healthcare expenditure prediction with neighbourhood variables—A random forest model. Stat. Politics Policy 2020, 11, 111–138. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Dx Code System | Origin | Remarks | Role in the Study |
|---|---|---|---|
| Principal Dx (ICD-10-CM) | Developed by WHO and modified by the National Center of Health Statistics. Used in the US since 2015. | The principal Dx in ICD-10-CM. This is used as the ground truth of this study. | The ground truth of the present study |
| Admitting Dx (CD-10-CM) | See above | The initial Dx, which, later, during the hospital stay is replaced by the principal Dx. | Learn about the loss in predictive power due to clinical uncertainty |
| Diagnosis Related Group (MS-DRG) | Generated by the ‘Grouper’ software from the ICD-10-CM codes, after the patient is discharged. | Encapsulates information from principal and secondary Dx’s that qualify as complications or comorbidities. It has lower dimensionality than ICD-10-CM since it groups several similar ICD-10 codes under the same MS-DRG. | Learn about information loss from the lower dimensionality of MS-DRGs and compensation due to the severity information MS-DRGs incorporate |
| Clinical Classification Software (CCS) old version | Developed in the framework of the HCUP project, under the umbrella of AHRQ. | A clinical grouping of ICD-10 in ~500 categories. Despite specificity loss, since the grouping was performed with clinical relevance in mind, it is a useful Dx representation. | Amount of predictive power lost compared to the ICD-10-CM representation |
| Clinical Classification Software Refined (CCSR) | Recent refined version of CCS, developed in the framework of the HCUP project, under the umbrella of AHRQ. | The CCSR for ICD-10-CM diagnoses balances the retention of the clinical concepts included in the old CCS categories and the specificity of ICD-10-CM diagnoses by creating new clinical categories. |
|
| Feature Name | Information and Descriptive Statistics |
|---|---|
| Diagnosis Related Group Code | A total of 745 unique MS-DRG codes |
| Principal CCS code (old) | A total of 251 unique CCS codes |
| Principal CCSR code (refined CCS) | A total of 754 unique CCS code combos |
| Principal Dx code | A total of 8354 unique ICD-10-CM codes |
| Admitting Dx code | A total of 7657 unique ICD-10-CM codes |
| Age group | <65 years: 102,721 (24.54%), 65–69 years: 69,527 (16.37%), 70–74 years: 62,244 (14.87%), 75–79 years: 56,414 (13.48%), 80–84 years: 50,575 (12.08%), >84 years: 77,048 (18.41%) |
| Female patients | 231,377 (55.28%) |
| Percent non-white | 90,313 (21.58%) |
| Type of admission | Emergency: 288,409 (68.91%), Urgent: 54,390 (12.99%), Elective: 71,859 (17.17%), Other: 3871 (0.9%) |
| Transferred from another hospital | 33,417 (7.98%) |
| Discharged dead | 10,922 (2.61%) |
| Length of Stay | Mean = 5.35 days, Std. Dev. = 6.817 days |
| Recall (D) | F-score (D) | ROC | PRC (D) | |||||
|---|---|---|---|---|---|---|---|---|
| Dx Predictor(s) | NB | Random Forest | NB | Random Forest | NB | Random Forest | NB | Random Forest |
| 1: Baseline (no Dx) | 0.0% | 0.0% | n/a | 0.0% | 63.7% | 61.9% | 4.3% | 4.0% |
| 2: Baseline + Principal ICD | 0.2% | 4.5% | 0.4% | 7.5% | 71.4% | 71.4% | 5.9% | 8.0% |
| 3: Baseline + Principal CCS | 0.4% | 2.2% | 0.9% | 4.0% | 77.9% | 72.0% | 9.8% | 7.2% |
| 4: Principal CCSR (refined) | 0.1% | 3.0% | 0.1% | 5.2% | 77.5% | 72.8% | 8.7% | 7.6% |
| 5: Baseline + MS-DRG | 6.2% | 8.3% | 11.5% | 13.4% | 85.3% | 78.4% | 20.9% | 17.2% |
| 6: Baseline + Admitting ICD | 0.1% | 5.3% | 0.3% | 8.8% | 69.3% | 66.5% | 6.2% | 8.0% |
| Dx Predictor(s) | R2 | Mean abs. err. (days) | Root Mean sqr. err. | Root Relative sqr. err. |
|---|---|---|---|---|
| 1: Baseline (no Dx info) | 6.29% | 3.52 | 5.81 | 96.81% |
| 2: Baseline + Principal ICD-10 | 10.82% | 3.34 | 5.93 | 98.84% |
| 3: Baseline + Principal CCS | 15.83% | 3.22 | 5.50 | 91.75% |
| 4: Baseline + Principal CCSR (refined) | 15.92% | 3.19 | 5.51 | 91.82% |
| 5: Baseline + MS-DRG | 30.38% | 2.89 | 5.01 | 83.49% |
| 6: Baseline + Admitting ICD-10 | 12.94% | 3.33 | 5.67 | 94.60% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zikos, D.; DeLellis, N. Comparison of the Predictive Performance of Medical Coding Diagnosis Classification Systems. Technologies 2022, 10, 122. https://doi.org/10.3390/technologies10060122
Zikos D, DeLellis N. Comparison of the Predictive Performance of Medical Coding Diagnosis Classification Systems. Technologies. 2022; 10(6):122. https://doi.org/10.3390/technologies10060122
Chicago/Turabian StyleZikos, Dimitrios, and Nailya DeLellis. 2022. "Comparison of the Predictive Performance of Medical Coding Diagnosis Classification Systems" Technologies 10, no. 6: 122. https://doi.org/10.3390/technologies10060122