
Validation of Corporate Probability of Default Models Considering Alternative Use Cases

Abstract
:1. Introduction
2. Literature Review
3. Methodology
4. Empirical Analysis
4.1. Description of Modeling Data
- CompustatTM: Standardized fundamental and market data for publicly traded companies including financial statement line items and industry classifications (Global Industry Classification Standards—“GICS” and North American Industry Classification System—“NAICS”) over multiple economic cycles from 1979 onward. These data include default types such as bankruptcy, liquidation, and rating agency’s default rating, all of which are part of the industry standard default definitions.
- Moody’s Default Risk ServiceTM (“DRS”) Rating History: An extensive database of rating migrations, default and recovery rates across geographies, regions, industries, and sectors.
- Bankruptcydata.com: A service provided by New Generation Research, Inc. (“NGR”) providing information on corporate bankruptcies.
- The Center for Research in Security PricesTM (“CRSP”) U.S. Stock Databases: This product is comprised of a database of historical daily and monthly market and corporate action data for over 32,000 active and inactive securities with primary listings on the NYSE, NYSE American, NASDAQ, NYSE Arca and Bats exchanges and include CRSP broad market indexes.
- Non-commercial and industrial (“C&I”) obligors defined by the following NAICS codes below, are not included in the population:
- Financials
- Real Estate Investment Trust (“REIT” or Real Estate Operating Company (“REOC”)
- Government
- Dealer Finance
- Not-for-Profit, including museums, zoos, hospital sites, religious organizations, charities, and education
- A similar filter is performed according to GICS (see below) classification:
- Education
- Financials
- Real Estate
- Only obligors based in the U.S. and Canada are included.
- Only obligors with maximum historical yearly Net Sales of at least USD 1B are included.
- There are exclusions for obligors with missing GICS codes, and for modeling purposes obligors are categorized into different industry segments on this basis.
- Records prior to 1Q91 are excluded, the rationale being that capital markets and accounting rules were different before the 1990s, and the macroeconomic data used in the model development are only available after 1990. As one-year change transformations are amongst those applied to the macroeconomic variables, this cutoff is advanced a year from 1990 to 1991.
- Records that are too close to a default event are not included in the development dataset, which is an industry standard approach, the rationale being that the records of an obligor in this time window do not provide information about future defaults of the obligor, but more likely the existing problems that the obligor is experiencing. Furthermore, a more effective practice is to base this on data that are 6–18 (rather than 1–12) months prior to the default date, as this typically reflects the range of timing between when statements are issued and when ratings are updated (i.e., usually it takes up to six months, depending on time to complete financials, receive them, input, and complete/finalize the ratings).
- In general, the defaulted obligors’ financial statements after the default date are not included in the modeling dataset. However, in some cases, obligors may exit a default state or “cure” (e.g., emerge from bankruptcy), in which cases, only the statements between default date and cured date are not included.
- Size: Change in Total Assets (“CTA”), Total Liabilities (“TL”)
- Leverage: Total Liabilities to Total Assets Ratio (“TLTAR”)
- Coverage Cash Use Ratio (“CUR”), Debt Service Coverage Ratio (“DSCR”)
- Efficiency: Net Accounts Receivables Days Ratio (“NARDR”)
- Liquidity: Net Quick Ratio (“NQR”), Net Working Capital to Tangible Assets Ratio (“NWCTAR”)
- Profitability: Before Tax Profit Margin (“BTPM”)
- Macroeconomic” Moody’s 500 Equity Price Index Quarterly Average Annual Change (“SP500EPIQAAC”), Consumer Confidence Index Annual Change (“CCIAC”)
- Merton Structural: Distance-to-Default (“DTD”)
4.2. Econometric Specifications and Model Validation
5. Conclusions
- alternative econometric techniques, such as various classes of machine learning models, including non-parametric alternatives;
- asset classes beyond the large corporate segment, such as small business, real estate or even retail;
- applications to stress testing of credit risk portfolios7;
- the consideration of industry specificity in model specification;
- the quantification of model risk according to the principle of relative entropy;
- different modeling methodologies, such as ratings migration or hazard rate models; and
- datasets in jurisdictions apart from the U.S., or else pooled data encompassing different countries with a consideration of geographical effects.
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
| 1 | A key limitation of this construct is that with macroeconomic variables common to all obligors, we are challenged in capturing the cross-sectional variation in the sensitivity to systematic factors across firms. This could be addressed by interaction terms between macroeconomic variables and firm specific factors or industry effects, which can be explored in future research. |
| 2 | Note that linearity does not mean that the dependent variable has a linear relationship with the explanatory variables (i.e., we can have non-linear transformations of the latter), but rather that the estimator is a linear function (or weighted average) of the dependent variable, which implies that we can obtain our estimator analytically using linear algebra operations as opposed to iterative techniques such as in the LRM. |
| 3 | All candidate explanatory variables are Winsorized at either the 10th, 5th or 1st percentile levels, at either tail of the sample distribution, in order to mitigate the influence of outliers or contamination in data, according to a customized algorithm that analyzes the gaps between these percentiles and caps/floors where these are maximal. |
| 4 | Clarifying our model selection process, we balance multiple criteria, both in terms of statistical performance and some qualitative considerations. Firstly, all models have to exhibit the stability of factor selection (where the signs on coefficient estimates are constrained to be economically intuitive) and statistical significance in k-fold cross validation sub-sample estimation. However, this is constrained by the requirement that we have only a single financial factor chosen from each category. Then, the models that meet these criteria are evaluated according to statistical performance metrics such as AIC and AUC, as well as other considerations such as rating mobility and relative factor weights. |
| 5 | The plots are omitted for the sake of brevity and are available upon request. |
| 6 | We have observed in the industry that a typical bank can have a number of applications for its PD models far into the double digits, and it would be infeasible to have completely separately developed PD models for all such applications. |
| 7 | Refer to Jacobs et al. (2015) and Jacobs (2020) for studies that address model validation and model risk quantification methodologies. These studies include supervisory applications such as comprehensive capital analysis and review (“CCAR”) and current expected credit loss (“CECL”), and further feature alternative credit risk model specifications (including machine learning model), macroeconomic scenario generation techniques, as well as the quantification and aggregation of model risk (including the principle of relative entropy). |
References
- Aguais, Scott D., Lawrence R. Forest Jr., Martin King, and Claire Lennon Marie. 2008. Designing and Implementing a Basel II Compliant PIT–TTC Ratings Framework. White Paper, Barclays Capital, August. Available online: https://mpra.ub.uni-muenchen.de/6902/1/MPRA_paper_6902.pdf (accessed on 30 March 2021).
- Altman, Edward I. 1968. Financial Ratios, Discriminant Analysis and the Prediction of Corporate Bankruptcy. Journal of Finance 23: 589–609. Available online: https://pdfs.semanticscholar.org/cab5/059bfc5bf4b70b106434e0cb665f3183fd4a.pdf (accessed on 3 June 2020). [CrossRef]
- Altman, Edward I. 2018. A Fifty-year Retrospective on Credit Risk Models, the Altman Z-Score Family of Models and their Applications to Financial Markets and Managerial Strategies. Journal of Credit Risk 14: 1–34. Available online: https://mebfaber.com/wp-content/uploads/2020/11/Altman_Z_score_models_final.pdf (accessed on 9 February 2021). [CrossRef] [Green Version]
- Altman, Edward I., and Herbert A. Rijken. 2004. How Rating Agencies Achieve Rating Stability. Journal of Banking and Finance 28: 2679–714. Available online: https://archive.nyu.edu/bitstream/2451/26557/2/FIN-04-031.pdf (accessed on 1 September 2019). [CrossRef] [Green Version]
- Altman, Edward I., and Herbert A. Rijken. 2006. A Point-in-Time Perspective on Through-the-Cycle Ratings. Financial Analyst Journal 62: 54–70. Available online: https://www.tandfonline.com/doi/abs/10.2469/faj.v62.n1.4058 (accessed on 9 May 2019).
- Altman, Edward I., and Paul Narayanan. 1997. An International Survey of Business Failure Classification Models. In Financial Markets, Institutions and Instruments. New York: New York University Salomon Center, vol. 6, Available online: https://onlinelibrary.wiley.com/doi/abs/10.1111/1468-0416.00010 (accessed on 2 August 2019).
- Amato, Jeffrey D., and Craig H. Furfine. 2004. Are Credit Ratings Procyclical. Journal of Banking and Finance 19: 2541–677. Available online: https://www.sciencedirect.com/science/article/abs/pii/S0378426604001049 (accessed on 8 February 2020). [CrossRef]
- Cesaroni, Tatiana. 2015. Procyclicality of Credit Rating Systems: How to Manage It. Journal of Economics and Business 82: 62–82. Available online: https://www.bancaditalia.it/pubblicazioni/temi-discussione/2015/2015-1034/en_tema_1034.pdf (accessed on 20 April 2020). [CrossRef] [Green Version]
- Chava, Sudhir, and Robert Jarrow. 2004. Bankruptcy Prediction with Industry Effects. Review of Finance 8: 537–69. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=287474 (accessed on 21 January 2019). [CrossRef]
- Chen, Yuo-Shivang. 2012. Classifying credit ratings for Asian banks using integrating feature selection and the cpda-based rough sets approach. Knowledge-Based Systems 26: 259–70. Available online: https://www.semanticscholar.org/paper/Classifying-credit-ratings-for-Asian-banks-using-Chen/b0aee646d5f687709851682df361f1e9b3cbd3fa (accessed on 18 November 2021). [CrossRef]
- Cheng, Simon, and J. Scott Long. 2006. Testing for IIA in the Multinomial Logit Model. Transportation Research Part B: Methodological 35: 583–600. [Google Scholar] [CrossRef]
- Cortes, Carlos, and Vladimir Vapnik. 1995. Support-vector networks. Machine Learning 20: 273–97. Available online: https://mlab.cb.k.u-tokyo.ac.jp/~moris/lecture/cb-mining/4-svm.pdf (accessed on 18 November 2021). [CrossRef]
- Duffie, Darrell, and Kenneth J. Singleton. 1999. Modeling Term Structures of Defaultable Bonds. Review of Financial Studies 12: 687–720. Available online: https://academic.oup.com/rfs/article-abstract/12/4/687/1578719?redirectedFrom=fulltext (accessed on 8 July 2021). [CrossRef] [Green Version]
- Đurović, Andrija. 2019. Macroeconomic Approach to Point in Time Probability of Default Modeling—IFRS 9 Challenges. Journal of Central Banking Theory and Practice 1: 209–23. Available online: https://www.econstor.eu/bitstream/10419/217671/1/jcbtp-2019-0010.pdf (accessed on 19 September 2020).
- Dwyer, Doug W. Lass, Ahmet E. Kogacil, and Roger M. Stein. 2004. Moody’s KMV RiskCalcTM v2.1 Model. Moody’s Analytics. Available online: https://www.moodys.com/sites/products/productattachments/riskcalc%202.1%20whitepaper.pdf (accessed on 5 September 2019).
- Fry, Tim R., and Mark N. Harris. 1996. A Monte Carlo Study of Tests for the Independence of Irrelevant Alternatives Property. Transportation Research Part B: Methodological 31: 19–32. [Google Scholar] [CrossRef] [Green Version]
- Hamilton, David T., Zhao Sun, and Ding Min. 2011. Through-the-Cycle EDF Credit Measures. White Paper, Moody’s Analytics, August. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=1921419 (accessed on 15 August 2020).
- Hausman, Jerry A., and Daniel McFadden. 1984. Specification Tests for the Multinomial Logit Model. Econometrica 52: 1219–40. Available online: https://ageconsearch.umn.edu/record/267431/files/monash-171.pdf (accessed on 9 September 2020). [CrossRef] [Green Version]
- Hodrick, Robert J., and Edward C. Prescott. 1997. Postwar U.S. Business Cycles: An Empirical Investigation. Journal of Money, Credit and Banking 29: 1–16. Available online: http://27.115.42.149/bbcswebdav/institution/%E7%BB%8F%E6%B5%8E%E5%AD%A6%E9%99%A2/teacherweb/2005000016/AdvancedMacro/Hodrick_Prescott.pdf (accessed on 29 June 2020). [CrossRef]
- Jacobs, Michael, Jr. 2020. A Holistic Model Validation Framework for Current Expected Credit Loss (CECL) Model Development and Implementation. The International Journal of Financial Studies 8: 27. Available online: http://michaeljacobsjr.com/files/Jacobs_2020_HolMdlValFrmwrkCECL-MdlDev_Impl_IFFS_vol8no27_pp1-36.pdf (accessed on 12 May 2019). [CrossRef]
- Jacobs, Michael, Jr., Ahmet K. Karagozoglu, and Frank J. Sensenbrenner. 2015. Stress Testing and Model Validation: Application of the Bayesian Approach to a Credit Risk Portfolio. The Journal of Risk Model Validation 9: 41–70. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2684227 (accessed on 28 May 2019). [CrossRef]
- Jarrow, Robert A., and Stuart M. Turnbull. 1995. Pricing Derivatives on Financial Securities Subject to Credit Risk. Journal of Finance 50: 53–85. Available online: https://www.jstor.org/stable/2329239?seq=1 (accessed on 11 February 2020).
- Jiang, Yixiao. 2021. Semiparametric Estimation of a Corporate Bond Rating Model. Econometrics 9: 23. Available online: https://doi.org/10.3390/econometrics9020023 (accessed on 24 May 2021). [CrossRef]
- Khandani, Amir E., Adlar J. Kim, and Andrew W. Lo. 2010. Consumer credit-risk models via machine-learning algorithms. Journal of Banking & Finance 34: 2767–87. Available online: https://econpapers.repec.org/article/eeejbfina/v_3a34_3ay_3a2010_3ai_3a11_3ap_3a2767-2787.htm (accessed on 18 November 2021).
- Khashman, Adnan. 2010. Neural networks for credit risk evaluation: Investigation of different neural models and learning schemes. Expert Systems with Applications 37: 6233–39. Available online: https://www.academia.edu/829842/Neural_networks_for_credit_risk_evaluation_Investigation_of_different_neural_models_and_learning_schemes (accessed on 18 November 2021). [CrossRef]
- Kiff, John, Michael Kisser, and Liliana Schumacher. 2004. Rating Through-the-Cycle: What does the Concept Imply for Rating Stability and Accuracy. Working Paper, International Monetary Fund, WP/13/64. Available online: https://www.imf.org/external/pubs/ft/wp/2013/wp1364.pdf (accessed on 18 November 2021).
- Kim, Kee S. 2005. Predicting bond ratings using publicly available information. Expert Systems with Applications 29: 75–81. Available online: https://www.sciencedirect.com/science/article/abs/pii/S0957417405000084 (accessed on 18 November 2021). [CrossRef]
- Kim, Hong Sik, and So Yong Sohn. 2010. Support vector machines for default prediction of smes based on technology credit. European Journal of Operational Research 201: 838–46. Available online: https://www.sciencedirect.com/science/article/abs/pii/S037722170900215X (accessed on 8 August 2020). [CrossRef]
- Li, Chun, and Bryan E. Shepherd. 2012. A New Residual for Ordinal Outcomes. Biometrica 99: 473–80. [Google Scholar] [CrossRef] [Green Version]
- Liu, Dungang, and Heping Zhang. 2017. Residuals and Diagnostics for Ordinal Regression Models: A Surrogate Approach. Journal of the American Statistical Association 113: 845–54. [Google Scholar] [CrossRef] [PubMed]
- Loeffler, Gunter. 2004. An Anatomy of Rating through the Cycle. Journal of Banking and Finance 28: 695–720. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=275842 (accessed on 27 September 2020). [CrossRef]
- Loeffler, Gunter. 2013. Can Rating Agencies Look Through the Cycle? Review of Quantitative Finance and Accounting 40: 623–46. Available online: https://link.springer.com/article/10.1007/s11156-012-0289-9 (accessed on 1 September 2020). [CrossRef]
- Merton, Robert C. 1974. On the Pricing of Corporate Debt: The Risk Structure of Interest Rates. Journal of Finance 29: 449–70. Available online: https://onlinelibrary.wiley.com/doi/epdf/10.1111/j.1540-6261.1974.tb03058.x (accessed on 10 October 2021).
- Mester, Loreta J. 1997. What’s the Point of Credit Scoring? Federal Reserve Bank of Philadelphia Business Review, September/October. pp. 3–16. Available online: https://fraser.stlouisfed.org/files/docs/historical/frbphi/businessreview/frbphil_rev_199709.pdf (accessed on 10 October 2020).
- Pacelli, Vincenzo, and Michele Azzollini. 2011. An artificial neural network approach for credit risk management. Journal of Intelligent Learning Systems and Applications 3: 103. Available online: https://www.researchgate.net/publication/220062573_An_Artificial_Neural_Network_Approach_for_Credit_Risk_Management (accessed on 27 March 2021). [CrossRef] [Green Version]
- Peng, Yi, Guoxun Wang, Guoxun Kou, and Yong Shi. 2011. An empirical study of classification algorithm evaluation for financial risk prediction. Applied Soft Computing 11: 2906–15. Available online: https://www.sciencedirect.com/science/article/abs/pii/S1568494610003054 (accessed on 23 January 2021). [CrossRef]
- Petrov, Alexander, and Mark Rubtsov. 2016. A Point-in-Time–Through-the-Cycle Approach to Rating Assignment and Probability of Default Calibration. Journal of Risk Model Validation 10: 83–112. Available online: https://www.risk.net/journal-of-risk-model-validation/technical-paper/2460734/a-point-in-time-through-the-cycle-approach-to-rating-assignment-and-probability-of-default-calibration (accessed on 7 July 2021).
- Repullo, Rafael, Jesus Saurina, and Carlos Trucharte. 2010. Mitigating the Procyclicality of Basel II. Economic Policy 64: 659–702. Available online: https://econpapers.repec.org/paper/bdewpaper/1028.htm (accessed on 4 April 2019). [CrossRef]
- Small, Kenneth A., and Cheng Hsiao. 1985. Multinomial Logit Specification Tests. International Economic Review 26: 619–27. Available online: https://econpapers.repec.org/article/ieriecrev/v_3a26_3ay_3a1985_3ai_3a3_3ap_3a619-27.htm (accessed on 20 August 2019). [CrossRef]
- The Bank for International Settlements—Basel Committee on Banking Supervision (BIS). 2005. Studies on the Validation of Internal Rating Systems. Working Paper 14. Basel: The Bank for International Settlements—Basel Committee on Banking Supervision, Available online: https://www.bis.org/publ/bcbs_wp14.htm (accessed on 24 August 2021).
- The Bank for International Settlements—Basel Committee on Banking Supervision (BIS). 2006. International Convergence of Capital Measurement and Capital Standards: A Revised Framework. Basel: The Bank for International Settlements—Basel Committee on Banking Supervision, Available online: https://www.bis.org/publ/bcbsca.htm (accessed on 13 May 2021).
- The Bank for International Settlements—Basel Committee on Banking Supervision (BIS). 2011. Basel III: A Global Regulatory Framework for More Resilient Banks and Banking Systems. Basel: The Bank for International Settlements—Basel Committee on Banking Supervision, Available online: https://www.bis.org/publ/bcbs189.htm (accessed on 4 April 2020).
- The Bank for International Settlements—Basel Committee on Banking Supervision (BIS). 2016. Reducing Variation in Credit Risk-Weighted Assets—Constraints on the Use of Internal Model Approaches. Consultative Document. Basel: The Bank for International Settlements—Basel Committee on Banking Supervision, Available online: http://www.bis.org/bcbs/publ/d362.htm (accessed on 11 November 2020).
- The European Banking Authority. 2016. Guidelines on PD Estimation, LGD Estimation and the Treatment of Defaulted Exposures. Consultation Paper. Paris: The European Banking Authority, Available online: https://www.eba.europa.eu/regulation-and-policy/model-validation/guidelines-on-pd-lgd-estimation-and-treatment-of-defaulted-assets (accessed on 6 July 2021).
- Topp, Rebekka, and Robert Perl. 2010. Through-the-Cycle Ratings Versus Point-in-Time Ratings and Implications of the Mapping between both Rating Types. Financial Markets, Institutions & Instruments 19: 47–61. Available online: https://onlinelibrary.wiley.com/doi/abs/10.1111/j.1468-0416.2009.00154.x (accessed on 18 March 2020).
- Vapnik, Vladimir. 2013. The Nature of Statistical Learning Theory. Berlin/Heidelberg: Springer Science & Business Media, Available online: https://link.springer.com/book/10.1007/978-1-4757-2440-0 (accessed on 6 May 2019).
- Veronezi, Pedro H. 2016. Corporate Credit Rating Prediction Using Machine Learning Techniques. Master’s thesis, Stevens Institute of Technology, Hoboken, NJ, USA. [Google Scholar]
- Xiao, Hongshan, Zhi Xiao, and Yu Wang. 2016. Ensemble classification based on supervised clustering for credit scoring. Applied Soft Computing 43: 73–86. Available online: https://www.researchgate.net/publication/297586887_Ensemble_classification_based_on_supervised_clustering_for_credit_scoring (accessed on 10 February 2021). [CrossRef]
- Yeh, Ching-Chiang, Fengyi Lin, and Chih Yu Hsu. 2012. A hybrid KMV model, random forests and rough set theory approach for credit rating. Knowledge-Based Systems 33: 166–72. Available online: https://isiarticles.com/bundles/Article/pre/pdf/48503.pdf (accessed on 11 September 2021). [CrossRef]
- Yu, Lean, Shouyang Wang, and Kin Keung Lai. 2008. Credit risk assessment with a multistage neural network ensemble learning approach. Expert Systems with Applications 34: 1434–44. Available online: https://www.researchgate.net/publication/222530702_Credit_risk_assessment_with_a_multistage_neural_network_ensemble_learning_approach (accessed on 3 January 2021). [CrossRef]


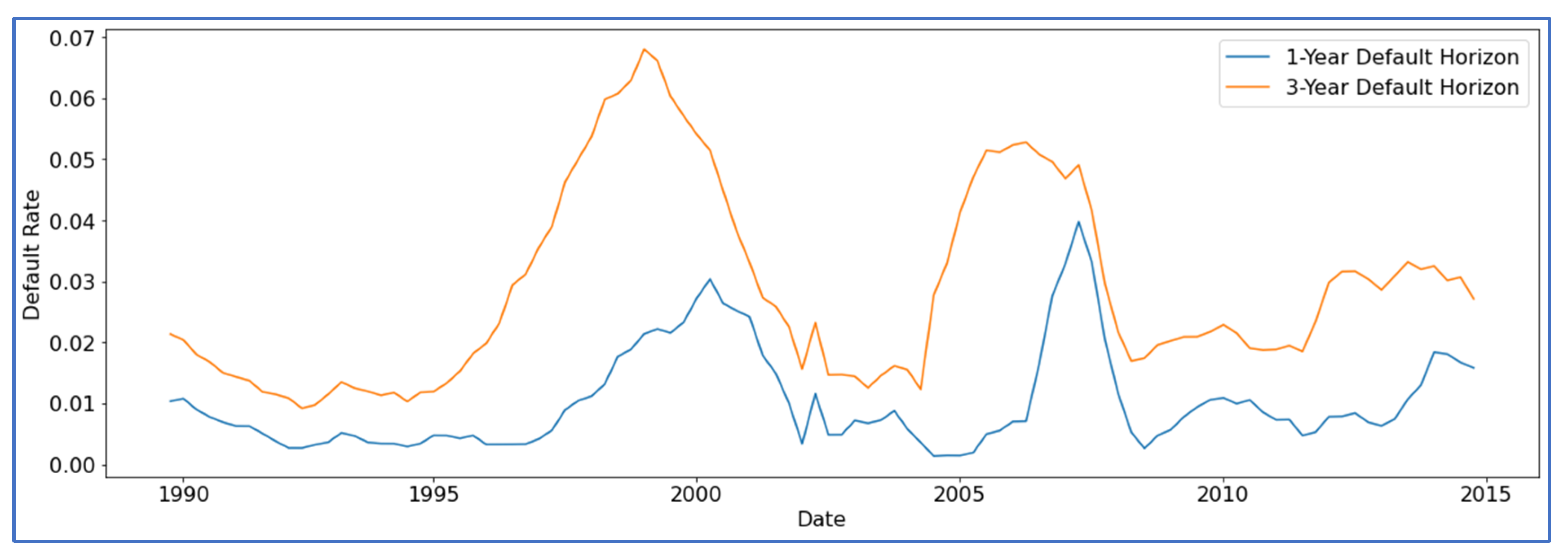{kind=link}
| GICS Industry Segment | All Moody’s Obligors | Defaulted Moody’s Obligors |
|---|---|---|
| Consumer Discretionary | 19.6% | 30.9% |
| Consumer Staples | 8.4% | 6.4% |
| Energy | 7.6% | 5.9% |
| Healthcare Equipment and Services | 2.9% | 2.9% |
| Industrials | 31.6% | 15.1% |
| Materials | 10.5% | 11.3% |
| Pharmaceuticals and Biotechnology | 2.7% | 0.2% |
| Software and IT Services | 2.5% | 1.8% |
| Technology Hardware and Communications | 4.3% | 11.3% |
| Utilities | 7.6% | 5.6% |
| NAICS Industry Segment | All Moody’s Obligors | Defaulted Moody’s Obligors |
|---|---|---|
| Agriculture, Forestry, Hunting and Fishing | 0.2% | 0.4% |
| Accommodation and Food Services | 2.3% | 2.9% |
| Waste Management % Remediation Services | 2.4% | 2.1% |
| Arts, Entertainment and Recreation | 0.7% | 1.0% |
| Construction | 1.7% | 2.5% |
| Educational Services | 0.1% | 0.2% |
| Healthcare and Social Assistance | 1.6% | 1.6% |
| Information Services | 11.5% | 12.1% |
| Management Compensation Enterprises | 0.1% | 0.1% |
| Manufacturing | 37.7% | 34.4% |
| Mining, Oil and Gas | 6.8% | 8.6% |
| Other Services (e.g., Public Administration) | 0.4% | 0.6% |
| Professional, Scientific and Technological Services | 2.3% | 2.5% |
| Real Estate, Rentals and Leasing | 0.9% | 1.6% |
| Retail Trade | 9.6% | 12.4% |
| Transportation and Warehousing | 5.4% | 7.0% |
| Utilities | 8.3% | 5.4 |
| Wholesale Trade | 7.0% | 2.7 |
| Variable | Count | Mean | Standard Deviation | Minimum | 25th Percentile | Median | 75th Percentile | Maximum |
|---|---|---|---|---|---|---|---|---|
| Default Indicator | 157,353 | 0.01 | 0.10 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 |
| Change in Total Assets | 0.14 | 0.35 | −0.40 | −0.01 | 0.06 | 0.17 | 3.21 | |
| Total Liabilities to Total Assets | 0.60 | 0.23 | 0.12 | 0.45 | 0.59 | 0.71 | 1.53 | |
| Cash Use Ratio | 1.90 | 2.84 | −22.43 | 1.41 | 2.06 | 2.65 | 19.00 | |
| Net Accounts Receivables Days | 130.25 | 101.44 | 11.26 | 68.98 | 106.74 | 159.43 | 754.09 | |
| Net Quick Ratio | 0.34 | 1.07 | −0.85 | −0.28 | 0.06 | 0.59 | 6.11 | |
| Before Tax Profit Margin | 5.94 | 21.00 | −146.67 | 1.85 | 7.09 | 12.85 | 48.70 | |
| Moody’s Equity Price Index | 1.91 | 6.09 | −27.33 | −0.19 | 2.19 | 5.68 | 12.81 | |
| Consumer Confidence Index | 2.34 | 21.58 | −60.97 | −7.02 | 4.89 | 15.35 | 73.21 |
| Variable | Count | Mean | Standard Deviation | Minimum | 25th Percentile | Median | 75th Percentile | Maximum |
|---|---|---|---|---|---|---|---|---|
| Default Indicator | 160,002 | 0.01 | 0.10 | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 |
| Change in Total Assets | 0.14 | 0.35 | −0.40 | −0.01 | 0.06 | 0.17 | 3.21 | |
| Total Liabilities to Total Assets | 0.60 | 0.23 | 0.12 | 0.45 | 0.60 | 0.71 | 1.53 | |
| Cash Use Ratio | 1.90 | 2.83 | −22.43 | 1.40 | 2.06 | 2.64 | 19.00 | |
| Net Quick Ratio | 0.34 | 1.06 | −0.85 | −0.28 | 0.06 | 0.59 | 6.11 | |
| Before Tax Profit Margin | 5.98 | 20.93 | −146.67 | 1.86 | 7.10 | 12.88 | 48.70 | |
| Moody’s Equity Price Index | 1.93 | 6.08 | −27.33 | −0.19 | 2.19 | 5.68 | 12.81 | |
| Consumer Confidence Index | 2.37 | 21.56 | −60.97 | −7.02 | 4.89 | 15.35 | 73.21 | |
| Distance-to-Default | 0.20 | 0.43 | −.1.32 | 0.02 | 0.07 | 0.18 | 5.26 |
| Variable | Count | Mean | Standard Deviation | Minimum | 25th Percentile | Median | 75th Percentile | Maximum |
|---|---|---|---|---|---|---|---|---|
| Default Indicator | 150,064 | 0.03 | 0.17 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| Total Liabilities | 3640.65 | 6741.93 | 8.86 | 422.60 | 1170.45 | 3374.12 | 41,852.00 | |
| Total Liabilities to Total Assets | 0.62 | 0.22 | 0.12 | 0.49 | 0.61 | 0.72 | 1.53 | |
| Debt Service Ratio | 16.44 | 52.82 | −25.07 | 1.74 | 4.09 | 9.80 | 409.64 | |
| Net Quick Ratio | 0.24 | 0.93 | −0.85 | −0.30 | 0.02 | 0.47 | 6.11 | |
| Before Tax Profit Margin | 5.50 | 21.08 | −146.67 | 1.57 | 6.72 | 12.40 | 48.70 |
| Variable | Count | Mean | Standard Deviation | Minimum | 25th Percentile | Median | 75th Percentile | Maximum |
|---|---|---|---|---|---|---|---|---|
| Default Indicator | 150,064 | 0.03 | 0.17 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| Total Liabilities | 3640.65 | 6741.93 | 8.86 | 422.60 | 1170.45 | 3374.12 | 41,852.00 | |
| Total Liabilities to Total Assets | 0.62 | 0.22 | 0.12 | 0.49 | 0.61 | 0.72 | 1.53 | |
| Debt Service Ratio | 16.44 | 52.82 | −25.07 | 1.74 | 4.09 | 9.80 | 409.64 | |
| Net Quick Ratio | 0.24 | 0.93 | −0.85 | −0.30 | 0.02 | 0.47 | 6.11 | |
| Before Tax Profit Margin | 5.50 | 21.08 | −146.67 | 1.57 | 6.72 | 12.40 | 48.70 | |
| Distance-to-Default | 0.20 | 0.42 | −1.32 | 0.02 | 0.07 | 0.28 | 5.26 |
| PIT 1-Year Default Horizon | TTC 3-Year Default Horizon | ||||
|---|---|---|---|---|---|
| Category | Explanatory Variables | AUC | Missing Rate | AUC | Missing Rate |
| Size | Change in Total Assets | 0.726 | 8.52% | ||
| Total Liabilities | 0.582 | 4.64% | |||
| Leverage | Total Liabilities to Total Assets Ratio | 0.843 | 4.65% | 0.783 | 4.65% |
| Coverage | Cash Use Ratio | 0.788 | 7.94% | ||
| Debt Service Coverage Ratio | 0.796 | 17.0% | |||
| Efficiency | Net Accounts Receivables Days Ratio | 0.615 | 8.17% | ||
| Liquidity | Net Quick Ratio | 0.653 | 7.71% | 0.617 | 7.17% |
| Profitability | Before Tax Profit Margin | 0.827 | 2.40% | 0.768 | 2.40% |
| Macroeconomic | Moody’s 500 Equity Price Index Quarterly Average Annual Change | 0.603 | 0.00% | ||
| Consumer Confidence Index Annual Change | 0.607 | 0.00% | |||
| Merton Structural | Distance-to-Default | 0.730 | 4.65% | 0.669 | 4.65% |
| Explanatory Variable | Parameter Estimate | p-Value | Factor Weight | AIC | AUC | HL p-Value | Mobility Index |
|---|---|---|---|---|---|---|---|
| Change in Total Assets | −0.4837 | 0.0000 | 0.0455 | 7231.00 | 0.8894 | 0.5945 | 0.7184 |
| Total Liabilities to Total Assets | 2.6170 | 0.0104 | 0.1091 | ||||
| Cash Use Ratio | −0.0428 | 0.0000 | 0.1545 | ||||
| Net Accounts Receivables Days Ratio | 0.0005 | 0.0000 | 0.2273 | ||||
| Net Quick Ratio | −0.4673 | 0.0000 | 0.0909 | ||||
| Before Tax Profit Margin | −0.0161 | 0.0000 | 0.2736 | ||||
| Moody’s Equity Index Price Index Quarterly Average | −0.0189 | 0.0000 | 0.0759 | ||||
| Consumer Confidence Index Year-on-Year Change | −0.0099 | 0.0000 | 0.0232 |
| Explanatory Variable | Parameter Estimate | p-Value | Factor Weight | AIC | AUC | HL p-Value | Mobility Index |
|---|---|---|---|---|---|---|---|
| Change in Total Assets | −0.4664 | 0.0000 | 0.0485 | 7290.00 | 0.8895 | 0.5782 | 0.7617 |
| Total Liabilities to Total Assets | 2.5385 | 0.0000 | 0.1165 | ||||
| Cash Use Ratio | −0.0428 | 0.0000 | 0.1650 | ||||
| Net Quick Ratio | −0.0169 | 0.0000 | 0.0971 | ||||
| Before Tax Profit Margin | −0.0169 | 0.0000 | 0.2913 | ||||
| Moody’s Equity Index Price Index Quarterly Average | −0.0186 | 0.0000 | 0.0801 | ||||
| Consumer Confidence Index Year-on-Year Change | −0.0100 | 0.0000 | 0.0267 | ||||
| Distance to Default | −0.1913 | 0.0052 | 0.1748 |
| Explanatory Variable | Parameter Estimate | p-Value | Factor Weight | AIC | AUC | HL p-Value | Mobility Index |
|---|---|---|---|---|---|---|---|
| Value of Total Liabilities | −6.97 × 10−6 | 0.0000 | 0.1773 | 17,751.00 | 0.8232 | 0.0039 | 0.3295 |
| Total Liabilities to Total Assets | 2.0239 | 0.0030 | 0.3133 | ||||
| Debt Service Coverage Ratio | −0.0431 | 0.0000 | 0.2332 | ||||
| Net Quick Ratio | −0.2412 | 0.0000 | 0.1372 | ||||
| Before Tax Profit Margin | −0.0129 | 0.0000 | 0.1390 |
| Explanatory Variable | Parameter Estimate | p-Value | Factor Weight | AIC | AUC | HL p-Value | Deviance/Degrees of Freedom | Pseudo R-Squared | Mobility Index |
|---|---|---|---|---|---|---|---|---|---|
| Total Liabilities to Total Assets | 2.9580 | 0.0000 | 0.3707 | 11,834.00 | 0.8226 | 0.0973 | 0.2365 | 0.1491 | 0.3539 |
| Debt Service Coverage Ratio | −0.0428 | 0.0000 | 0.2917 | ||||||
| Net Quick Ratio | −0.2403 | 0.0000 | 0.0808 | ||||||
| Before Tax Profit Margin | −0.0129 | 0.0000 | 0.0902 | ||||||
| Distance to Default | −0.1541 | 0.0000 | 0.1666 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jacobs, M., Jr. Validation of Corporate Probability of Default Models Considering Alternative Use Cases. Int. J. Financial Stud. 2021, 9, 63. https://doi.org/10.3390/ijfs9040063
Jacobs M Jr. Validation of Corporate Probability of Default Models Considering Alternative Use Cases. International Journal of Financial Studies. 2021; 9(4):63. https://doi.org/10.3390/ijfs9040063
Chicago/Turabian StyleJacobs, Michael, Jr. 2021. "Validation of Corporate Probability of Default Models Considering Alternative Use Cases" International Journal of Financial Studies 9, no. 4: 63. https://doi.org/10.3390/ijfs9040063