1. Introduction
The financial sector faces a significant challenge in the form of financial fraud, encompassing various forms of criminal deception aimed at securing financial gains, including activities like telecommunication fraud and credit card skimming. The proliferation of electronic payment technology has propelled online transactions into the mainstream, thereby amplifying the occurrence of fraudulent schemes. The prevalence of these fraudulent transactions has led to substantial losses for financial institutions. However, the large daily transactions pose a challenge for humans in manually identifying fraud. Recently, deep learning techniques have been explored and have shown promising results in detecting financial fraud
Alarfaj et al. (
2022);
Fang et al. (
2021);
Kim et al. (
2019). Unfortunately, most real-world financial fraud datasets suffer from a severe class imbalance issue, where the fraud data’s proportion is significantly lower than that of nonfraud. In binary classification, class imbalance often leads to biased predictions favoring the majority class
Johnson and Khoshgoftaar (
2019). Consequently, the classifier’s performance on the minority class is compromised, especially when encountering dissimilar frauds. Overcoming this problem poses a significant challenge, as classifiers are expected to achieve high precision and recall in fraudulent class.
To address this problem, several oversampling methods have been employed to generate minority samples. Synthetic Minority Oversampling TEchnique (SMOTE) interpolates between the existing minority data to synthesize minority samples
Chawla et al. (
2002). Generative Adversarial Networks (GANs) comprise a discriminator that aims to differentiate between real and generated samples and a generator that strives to deceive the discriminator by synthesizing realistic samples
Goodfellow et al. (
2014). GANs have shown superior results compared with SMOTE
Fiore et al. (
2019). However, SMOTE may cause overgeneralization issues. GAN, primarily designed for image generation, is not ideal for handling the class imbalance problem. To overcome these limitations, SMOTified-GAN employs SMOTE-generated samples instead of random noises as input to the GAN
Sharma et al. (
2022).
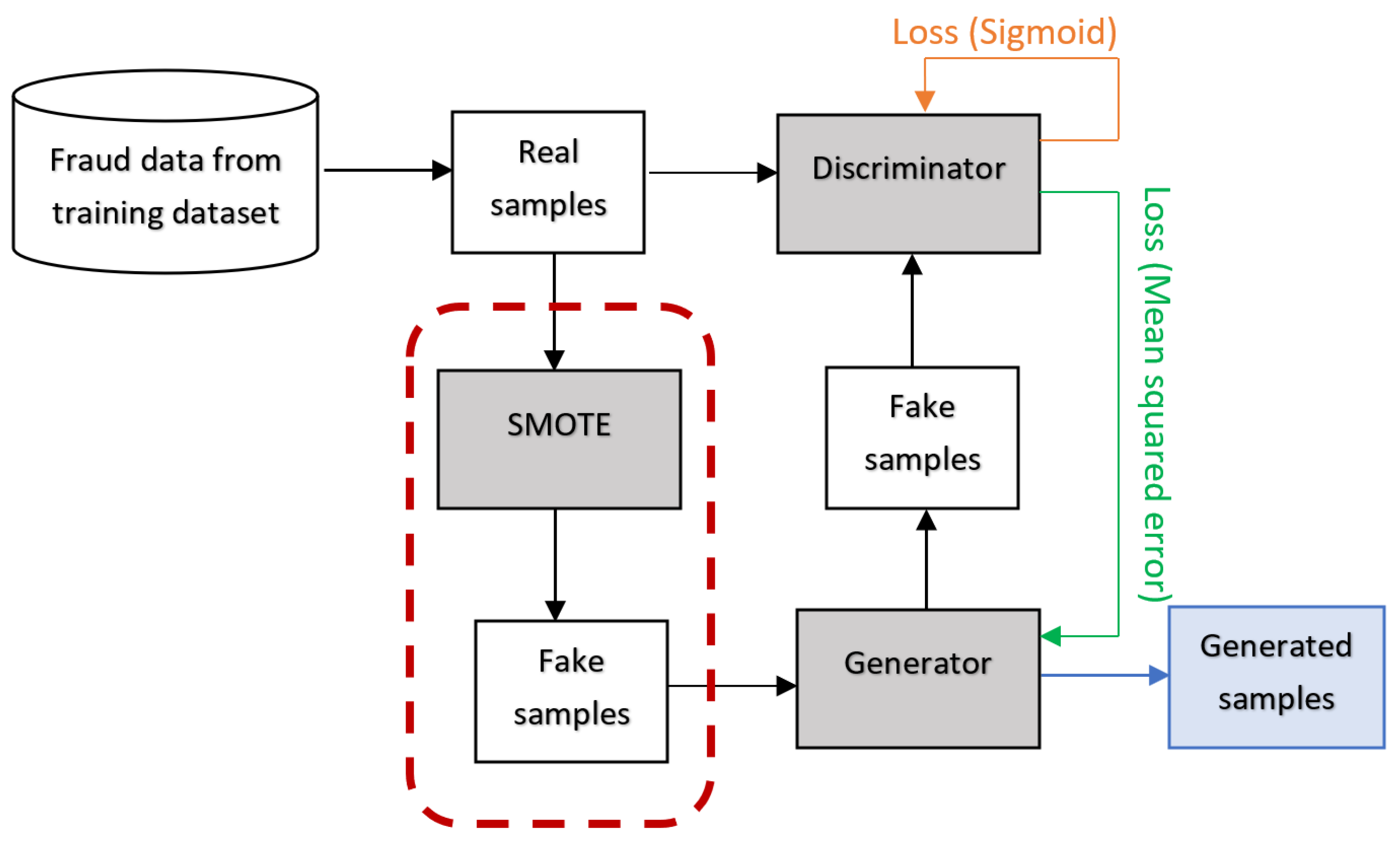
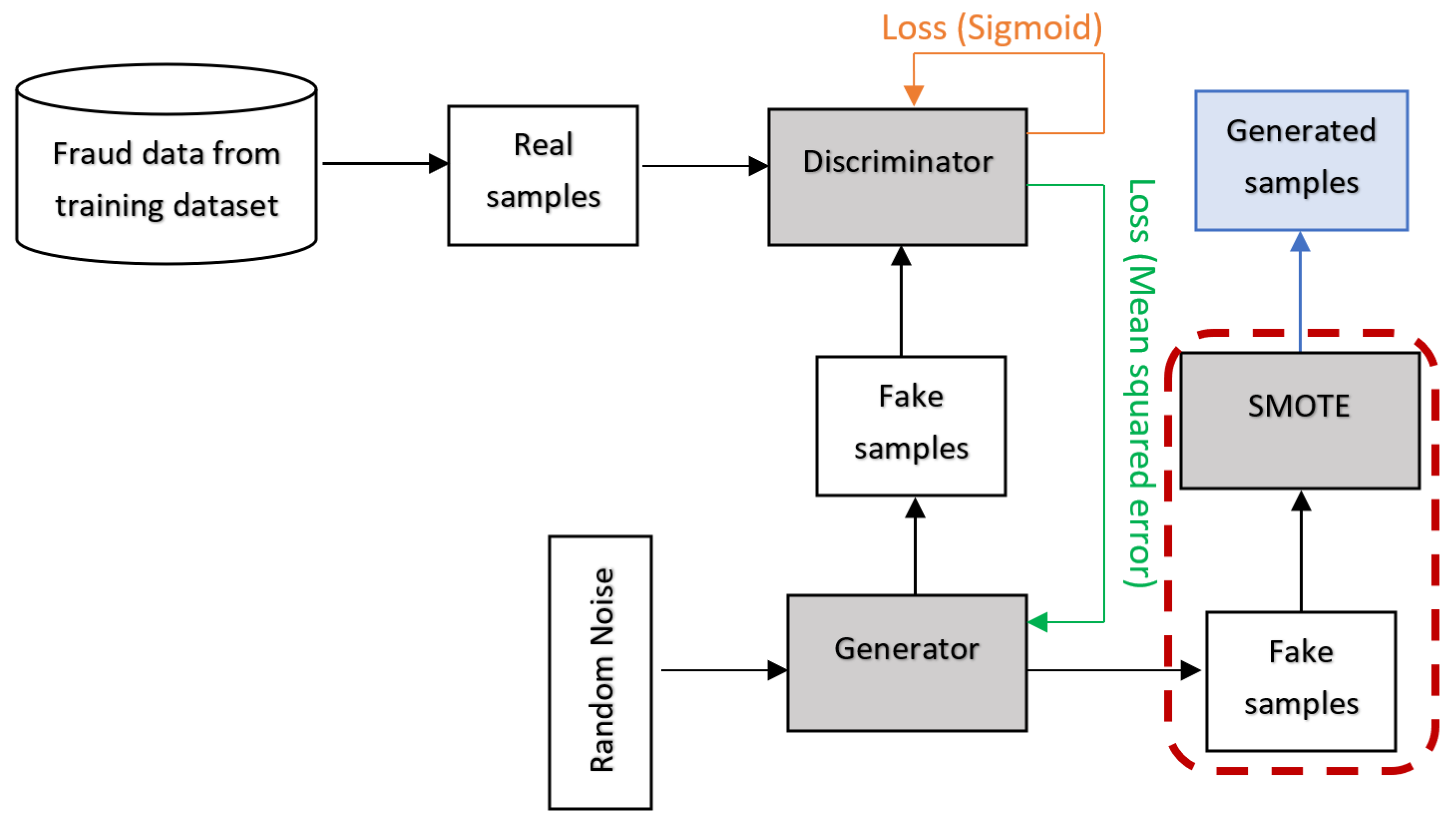
In addition to the aforementioned data generation techniques, other hybrids of SMOTE and GAN are worth exploring. This study presents the following contributions:
Introducing two data generation techniques, SMOTE+GAN and GANified-SMOTE, designed to effectively address the class imbalance issue in finance fraud detection.
Conducting a comprehensive comparison between the proposed oversampling methods and existing data generation techniques, utilizing precision, recall, and F1-score as key performance metrics.
Evaluating the performance of the data generation techniques across various neural network architectures, including a Feed-forward Neural Network (FNN), Convolutional Neural Network (CNN), and the proposed hybrid FNN+CNN.
Analyzing the impact of training classifiers on different proportions of the generated minority samples.
2. Related Work
The task of detecting financial fraud can be approached as a binary classification challenge, where classifiers examine the patterns within fraudulent and legitimate transactions to classify new transactions accurately. Consequently, it is crucial to possess an ample and diverse dataset to enable classifiers to grasp the inherent patterns of both transaction categories. Addressing the issue of inadequate fraudulent samples in the training dataset, various methodologies have been introduced to create artificial fraud instances and supplement the original data. These techniques include SMOTE, GAN, and SMOTified-GAN.
SMOTE
Chawla et al. (
2002) has been widely applied to imbalanced training datasets. More than 85 SMOTE variations were proposed by 2018, including SMOTE+TomekLinks, SMOTE+ENN, Borderline-SMOTE, and Adaptive Synthetic
Fernández et al. (
2018). Recent studies proposed Radius-SMOTE
Pradipta et al. (
2021), which prevents overlap among generated samples, and Reduced-Noise SMOTE
Arafa et al. (
2022), which removes noise after oversampling. In financial fraud detection, SMOTE and its variations have been widely utilized to resample highly imbalanced datasets before training models such as AdaBoost
Ileberi et al. (
2021) and FNN
Fang et al. (
2021). Besides the finance domain, SMOTE and its variations have found extensive application in other fields dealing with highly imbalanced datasets. In bio-informatics, SMOTE has been used to discriminate Golgi proteins
Tahir et al. (
2020) and predict binding hot spots in protein–RNA interactions
Zhou et al. (
2022). In medical diagnosis, SMOTE and its variations have been employed for diagnosing cervical cancer
Abdoh et al. (
2018) and prostate cancer
Abraham and Nair (
2018). SMOTE has also been used to predict diabetes
Mirza et al. (
2018) and heart failure patients’ survival
Ishaq et al. (
2021).
GANs
Goodfellow et al. (
2014) and their variations have more recently been employed for generating minority samples to tackle the class imbalance problem.
Douzas and Bacao (
2018) utilized a conditional GAN (cGAN) which can recover the distribution of training data to generate minority samples. To address the mode collapse issue, Balancing GAN was proposed to generate more diverse and higher-quality minority images
Mariani et al. (
2018). However, in this technique, the generator and discriminator cannot simultaneously reach their optimal states, leading to the development of IDA-GAN
Yang and Zhou (
2021). In financial fraud detection, GAN has been employed to generate fraud samples for imbalanced datasets before training classifiers, such as AdaBoost-Decision Tree
Mo et al. (
2019) and FNN
Fiore et al. (
2019). These studies have reported that the GAN achieves higher AUC, accuracy, and precision compared with SMOTE. Interestingly,
Fiore et al. (
2019) found that the best performance was achieved when twice as many GAN-generated fraud samples as the original fraud data were added to the training dataset. In other finance-related domains, GANs have been utilized to address class imbalance in money laundering detection in gambling
Charitou et al. (
2021). GANs and their variations have also been used extensively for high-dimensional imbalanced datasets, such as images
Mariani et al. (
2018);
Scott and Plested (
2019) and biomedical data
Zhang et al. (
2018). Recent studies have successfully applied GANs and their variations to generate minority samples in bio-informatics
Lan et al. (
2020).
Despite the notable accomplishments of SMOTE and GAN, these methods have certain limitations. SMOTE may introduce noise that leads to overgeneralization
Bunkhumpornpat et al. (
2009). While GANs can generate more “realistic” data, they may not be ideal for handling imbalanced data, as it was originally designed for generating images using random noise. Additionally, there may be insufficient real minority data available for training the GAN
Mariani et al. (
2018). To address these limitations,
Sharma et al. (
2022) proposed SMOTifed-GAN, which employs SMOTE-generated samples as input for GAN instead of random numbers, resulting in improved performance compared with SMOTE and GAN.
In early studies, financial fraud detection systems predominantly depended on rule-based methodologies, wherein human expertise in fraud was translated into rules to anticipate fraudulent activities
Zhu et al. (
2021). However, the evolving behaviors of fraudsters and the increasing size of transaction datasets have posed challenges in identifying fraud-related rules manually. As a result, research has shifted towards machine learning methods, such as naive Bayes, logistic regression, support vector machine, random forest, and decision tree (
Ileberi et al. 2021;
Ye et al. 2019;
Zhu et al. 2021), which can “learn” fraud and nonfraud patterns from given datasets. Nonetheless, machine learning techniques require extensive data preprocessing before training the classifier
Alarfaj et al. (
2022);
Kim et al. (
2019);
Zhu et al. (
2021).
In recent years, deep learning has gained popularity in financial fraud detection due to its superior performance compared with traditional machine learning approaches
Alarfaj et al. (
2022);
Fang et al. (
2021);
Jurgovsky et al. (
2018);
Kim et al. (
2019). Some studies have approached financial fraud detection as a sequence classification problem, considering the temporal sequence of transactions as a crucial factor. Sequential models, such as Gated Recurrent Units
Branco et al. (
2020), Long Short-Term Memory (LSTM)
Jurgovsky et al. (
2018), and Time-aware Attention-based Interactive LSTM
Xie et al. (
2022), have been proposed. However, since most available financial fraud datasets lack time-sequence information, sequential models may not be suitable in such cases. Due to the vector format of finance fraud datasets without time-sequence information, FNNs are considered a suitable choice
Fang et al. (
2021);
Fiore et al. (
2019);
Kim et al. (
2019). Initially designed for image processing and classification, CNNs have also been found effective in financial fraud detection
Alarfaj et al. (
2022);
Chen and Lai (
2021);
Zhang et al. (
2018). Their 1D convolution layers can extract patterns within smaller segments of a transaction vector.
Building on
Fiore et al. (
2019)’s findings, this study aimed to assess the performance of a model using varying amounts of minority samples in the training dataset. To achieve this, the study explores the use of SMOTE, GAN, SMOTified-GAN, and other variants of hybrid SMOTE and GAN. Consequently, a combination of SMOTE- and GAN-generated minority samples, along with GANified-SMOTE, was proposed to fulfill the research aims. Finally, FNN, CNN, and FNN+CNN models were employed to ensure a fair evaluation of the performances of different data generation techniques.
5. Conclusions
The present study introduces SMOTE+GAN and GANified-SMOTE techniques as innovative solutions to counteract class imbalance, thereby offering financial institutions an effective tool for reducing losses due to fraudulent activities. Additionally, the integration of FNN and CNN in predicting transaction categories is proposed. The effectiveness of the newly proposed data generation methods was assessed against existing techniques using an FNN, CNN, and FNN+CNN as classifiers. The outcomes highlight the potency of GANified-SMOTE, particularly when coupled with the proposed FNN+CNN classifier, in augmenting the F1-score for fraudulent data. This high F1-score indicates the method’s capacity to identify a substantial portion of fraudulent transactions with reduced misclassification of legitimate transactions. Notably, GANified-SMOTE and SMOTified-GAN consistently exhibit commendable performance across varying quantities of generated minority samples. Furthermore, the research underscores the significant impact of the classifier’s hyperparameter settings on classification performance, irrespective of the employed data generation methods.
In light of this experiment utilizing an online-acquired dataset, it is crucial to recognize that the study’s findings may not perfectly simulate real-world scenarios marked by ever-evolving fraudulent behaviors. Future endeavors should validate the efficacy of the proposed methods within actual financial institutions. Moreover, while the experiment employs a labeled dataset with presumed accurate class labels, real-world datasets often pose the challenge of being unlabeled and necessitating comprehensive preprocessing. To tackle class labeling issues, future investigations could explore the potential of unsupervised learning in data generation. Furthermore, to firmly establish the effectiveness of the proposed methods, this study acknowledges that comparisons with existing research were limited. Factors like classifier selection may have influenced observed improvements. Therefore, to enhance generalizability, future research should involve additional classifiers and ablation studies. These efforts would serve to validate the performance of the data generation methods in diverse scenarios.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}