
Can L2 Pronunciation Be Evaluated without Reference to a Native Model? Pillai Scores for the Intrinsic Evaluation of L2 Vowels

Abstract
:1. Introduction
1.1. Evaluating L2 Pronunciation
1.2. Reasons and Methods for the Intrinsic Evaluation of L2 Pronunciation
1.3. Aim of This Contribution
2. Materials and Methods
2.1. EnglishL2 Data
2.2. FrenchL2 Data
2.3. Selection of Vowel Contrasts
2.4. Data Preparation, Extraction, and Analysis
2.5. Native Ratings
3. Results
3.1. Intrinsic Evaluation of EnglishL2 Vowels with Pillai Scores
3.2. Intrinsic Evaluation of FrenchL2 Vowels with Pillai Scores
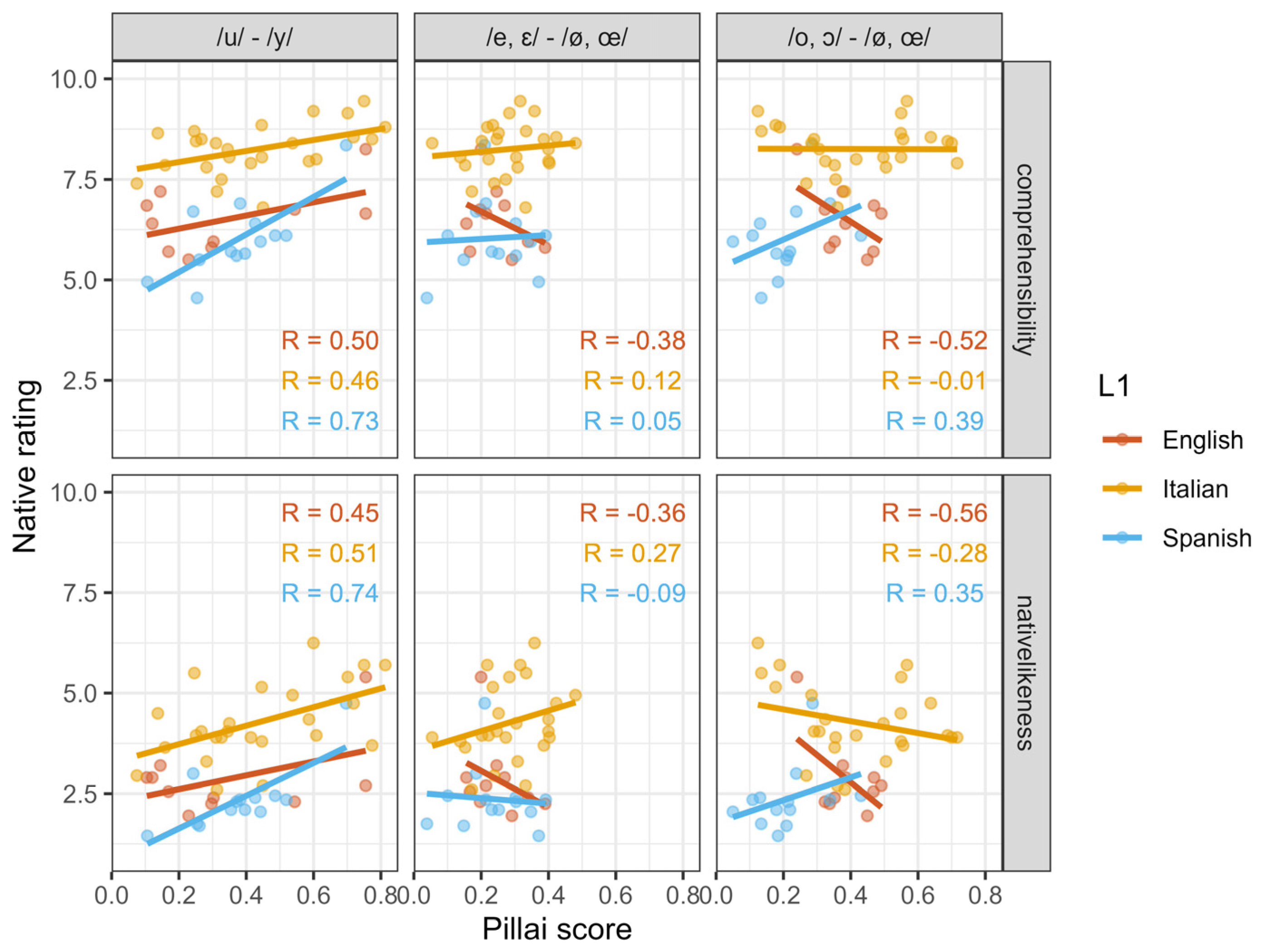
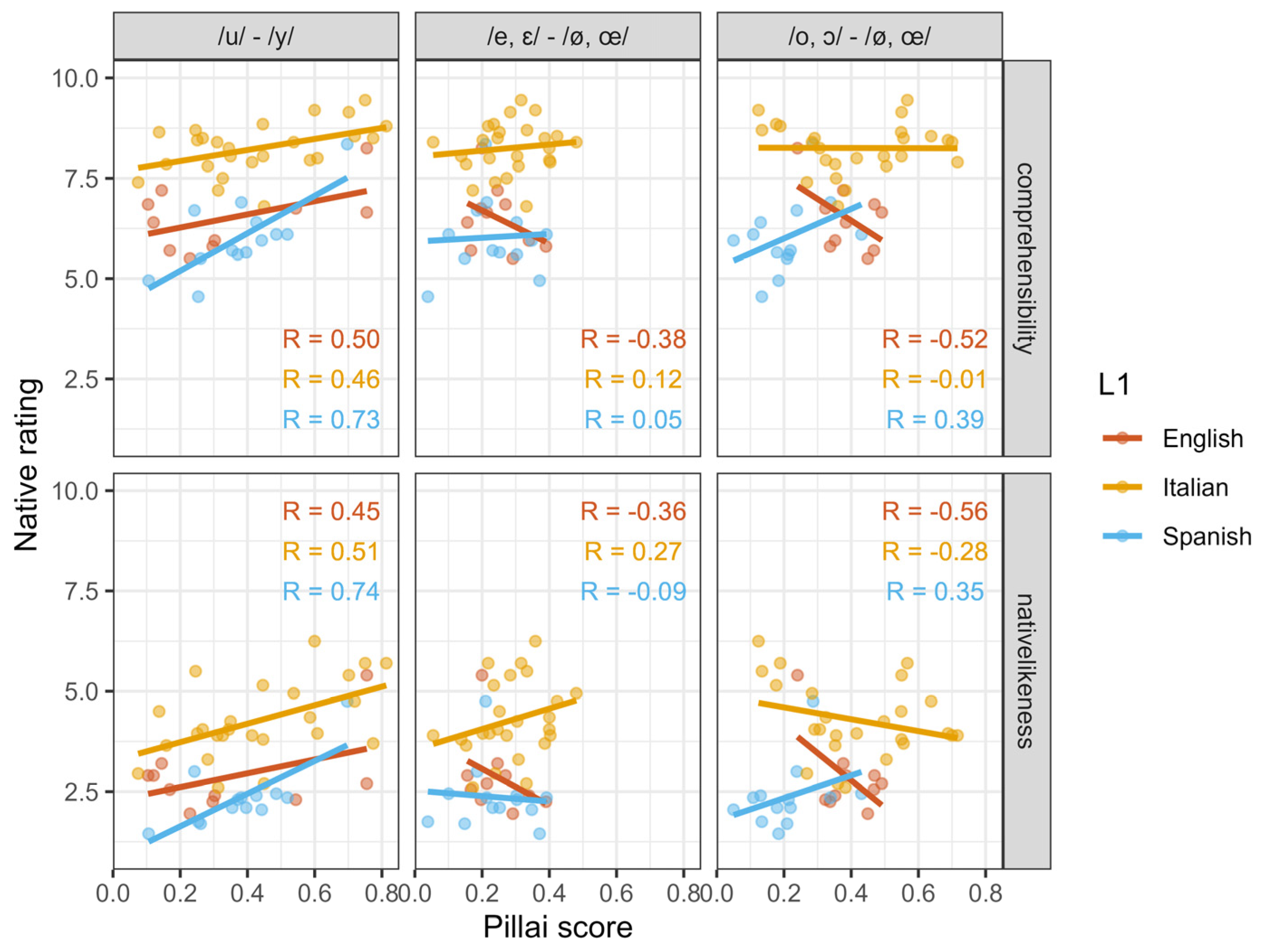
3.3. Extrinsic Evaluation of FrenchL2 Vowels with Pillai Scores
4. Discussion
4.1. Considerations on the Intrinsic Evaluation of L2 Vowels
4.2. Intrinsic vs. Extrinsic Evaluation of L2 Vowels
4.3. Other Possible Methods for Intrinsic Evaluation
4.4. Caveats and Limitations of Intrinsic Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Baills, Florence, Fabián Santiago, Paolo Mairano, and Pilar Prieto. 2022. The Effects of Prosodic Training with Logatomes and Prosodic Gestures on L2 Spontaneous Speech. Paper presented at Speech Prosody 2022, Lisbon, Portugal, May 23–26; pp. 802–6. [Google Scholar] [CrossRef]
- Barreda, Santiago. 2015. PhonTools: Functions for Phonetics in R. R Package, Version 0.2-2.1. Available online: https://cran.r-project.org/web/packages/phonTools/citation.html (accessed on 20 November 2023).
- Bartoń, Kamil. 2023. MuMIn: Multi-Model Inference. R Package, Version 1.47.5. Available online: https://CRAN.R-project.org/package=MuMIn (accessed on 20 November 2023).
- Bates, Douglas, Martin Mächler, Ben Bolker, and Steve Walker. 2015. Fitting Linear Mixed-Effects Models Using Lme4. Journal of Statistical Software 67: 1–48. [Google Scholar] [CrossRef]
- Bent, Tessa, and Ann R. Bradlow. 2003. The Interlanguage Speech Intelligibility Benefit. The Journal of the Acoustical Society of America 114: 1600–10. [Google Scholar] [CrossRef] [PubMed]
- Best, Catherine T., and Michael D. Tyler. 2007. Nonnative and Second-Language Speech Perception: Commonalities and Complementarities. In Language Learning & Language Teaching. Edited by Ocke-Schwen Bohn and Murray J. Munro. Amsterdam: John Benjamins Publishing Company, vol. 17, pp. 13–34. [Google Scholar] [CrossRef]
- Boersma, Paul, and David Weenink. 2023. Praat: Doing Phonetics by Computer [Computer Program] (Version 6). Available online: http://www.praat.org/ (accessed on 20 November 2023).
- Cebrian, Juli. 2006. Experience and the Use of Non-Native Duration in L2 Vowel Categorization. Journal of Phonetics 34: 372–87. [Google Scholar] [CrossRef]
- Cook, Vivian. 2016. Second Language Learning and Language Teaching, 5th ed. New York: Routledge. [Google Scholar] [CrossRef]
- Crothers, John. 1978. Typology and Universals of Vowel Systems in Phonology. Universals of Human Language 2: 95–152. [Google Scholar]
- Crowther, Dustin, Daniel Holden, and Kristen Urada. 2022. Second Language Speech Comprehensibility. Language Teaching 55: 470–89. [Google Scholar] [CrossRef]
- Cucchiarini, Catia, Helmer Strik, and Lou Boves. 2000. Quantitative Assessment of Second Language Learners’ Fluency by Means of Automatic Speech Recognition Technology. The Journal of the Acoustical Society of America 107: 989–99. [Google Scholar] [CrossRef]
- Dahmen, Silvia, Martine Grice, and Simon Roessig. 2023. Prosodic and Segmental Aspects of Pronunciation Training and Their Effects on L2. Languages 8: 74. [Google Scholar] [CrossRef]
- Darcy, Isabelle, Laurent Dekydtspotter, Rex A Sprouse, Justin Glover, Christiane Kaden, Michael McGuire, and John Hg Scott. 2012. Direct Mapping of Acoustics to Phonology: On the Lexical Encoding of Front Rounded Vowels in L1 English–L2 French Acquisition. Second Language Research 28: 5–40. [Google Scholar] [CrossRef]
- De Jonge, Keryn, Olga Maxwell, and Helen Zhao. 2022. Learning on the Field: L2 Turkish Vowel Production by L1 American English-Speaking NGOs in Turkey. Languages 7: 252. [Google Scholar] [CrossRef]
- Delais-Roussarie, Elisabeth, and Hiyon Yoo. 2010. The COREIL Corpus: A Learner Corpus Designed for Studying Phrasal Phonology and Intonation. Paper presented at 6th New Sounds, Poznan, Poland, May 1–3; pp. 100–5. [Google Scholar]
- Delais-Roussarie, Elisabeth, Tanja Kupisch, Paolo Mairano, Fabian Santiago, and Frida Splendido. 2018. ProSeg: A Comporable Corpus of Spoken L2 French. Paper presented at EuroSLA 2018, Münster, Germany, September 5–8. [Google Scholar]
- Escudero, Paola, and Daniel Williams. 2012. Native Dialect Influences Second-Language Vowel Perception: Peruvian versus Iberian Spanish Learners of Dutch. The Journal of the Acoustical Society of America 131: EL406–EL412. [Google Scholar] [CrossRef]
- Escudero, Paola, Ellen Simon, and Holger Mitterer. 2012. The Perception of English Front Vowels by North Holland and Flemish Listeners: Acoustic Similarity Predicts and Explains Cross-Linguistic and L2 Perception. Journal of Phonetics 40: 280–88. [Google Scholar] [CrossRef]
- Farrús, Mireia. 2023. Automatic Speech Recognition in L2 Learning: A Review Based on PRISMA Methodology. Languages 8: 242. [Google Scholar] [CrossRef]
- Ferragne, Emmanuel, and François Pellegrino. 2010. Formant Frequencies of Vowels in 13 Accents of the British Isles. Journal of the International Phonetic Association 40: 1–34. [Google Scholar] [CrossRef]
- Flege, James E. 1995. Second Language Speech Learning: Theory, Findings, and Problems. In Speech Perception and Linguistic Experience: Issues in Cross-Language Research. Edited by Winifred Strange. Timonium: York Press, pp. 233–77. [Google Scholar]
- Flege, James Emil, and Ocke-Schwen Bohn. 2021. The Revised Speech Learning Model (SLM-r). In Second Language Speech Learning, 1st ed. Edited by Ratree Wayland. Cambridge: Cambridge University Press, pp. 3–83. [Google Scholar] [CrossRef]
- Flege, James Emil, Ian R. A. MacKay, and Diane Meador. 1999. Native Italian Speakers’ Perception and Production of English Vowels. The Journal of the Acoustical Society of America 106: 2973–87. [Google Scholar] [CrossRef] [PubMed]
- Flege, James Emil, Ocke-Schwen Bohn, and Sunyoung Jang. 1997. Effects of Experience on Non-Native Speakers’ Production and Perception of English Vowels. Journal of Phonetics 25: 437–70. [Google Scholar] [CrossRef]
- Fullana Rivera, Natalia, and Ian R. A. MacKay. 2003. Production of English Sounds by EFL Learners: The Case of /i/and/ɪ/. Paper presented at 15th International Congress of Phonetic Sciences, Barcelona, Spain, August 3–9; pp. 1525–28. [Google Scholar]
- Gallant, Jordan. 2023. Typed Transcription as a Simultaneous Measure of Foreign-Accent Comprehensibility and Intelligibility: An Online Replication Study. Research Methods in Applied Linguistics 2: 100055. [Google Scholar] [CrossRef]
- Gendrot, Cédric, Kim Gerdes, and Martine Adda-Decker. 2016. Détection Automatique d’une Hiérarchie Prosodique Dans Un Corpus de Parole Journalistique. Langue Française 191: 123–49. [Google Scholar] [CrossRef]
- Georgiou, Georgios P. 2022. The Acquisition of /ɪ/–/Iː/ Is Challenging: Perceptual and Production Evidence from Cypriot Greek Speakers of English. Behavioral Sciences 12: 469. [Google Scholar] [CrossRef] [PubMed]
- Goldman, Jean-Philippe. 2011. Easyalign: An Automatic Phonetic Alignment Tool under Praat. Paper presented at Twelfth Annual Conference of the International Speech Communication Association (ISCA), Florence, Italy, August 27–31; pp. 3233–36. [Google Scholar] [CrossRef]
- Herment, Sophie, Anne Tortel, Brigitte Bigi, Daniel J. Hirst, and Anastassia Loukina. 2014. AixOx, a Multi-Layered Learners Corpus: Automatic Annotation. In Specialisation and Variation in Language Corpora. Edited by Francisco Javier Diaz-Pérez and Ana Díaz-Negrillo. Bern: Peter Lang, pp. 41–76. [Google Scholar]
- Herry-Bénit, Nadine, Stéphanie Lopez, Takeki Kamiyama, and Jeff Tennant. 2021. The Interphonology of Contemporary English Corpus (IPCE-IPAC). International Journal of Learner Corpus Research 7: 275–89. [Google Scholar] [CrossRef]
- Isaacs, Talia, and Pavel Trofimovich. 2012. Deconsctructing Comprehensibility: Identifying the Linguistic Influences on Listeners’ L2 Comprehensibility Ratings. Studies in Second Language Acquisition 34: 475–505. [Google Scholar] [CrossRef]
- Isaacs, Talia, and Ron I. Thomson. 2013. ‘Rater Experience, Rating Scale Length, and Judgments of L2 Pronunciation: Revisiting Research Conventions’. Language Assessment Quarterly 10: 135–59. [Google Scholar] [CrossRef]
- Jenkins, Jennifer. 2000. The Phonology of English as an International Language. Oxford: Oxford University Press. [Google Scholar]
- Jenkins, Jennifer. 2006. The Spread of EIL: A Testing Time for Testers. ELT Journal 60: 42–50. [Google Scholar] [CrossRef]
- Kabakoff, Heather, Gretchen Go, and Susannah V. Levi. 2020. Training a Non-Native Vowel Contrast with a Distributional Learning Paradigm Results in Improved Perception and Production. Journal of Phonetics 78: 100940. [Google Scholar] [CrossRef]
- Kang, Okim. 2010. Relative Salience of Suprasegmental Features on Judgments of L2 Comprehensibility and Accentedness. System 38: 301–15. [Google Scholar] [CrossRef]
- Kang, Okim, and Lucy Pickering. 2013. Acoustic and Temporal Analysis for Assessing Speaking. In The Companion to Language Assessment. Edited by Antony John Kunnan. Hoboken: John Wiley & Sons, Inc., pp. 1047–62. [Google Scholar] [CrossRef]
- Kang, Okim, Ron I. Thomson, and Meghan Moran. 2018. Empirical Approaches to Measuring the Intelligibility of Different Varieties of English in Predicting Listener Comprehension: Measuring Intelligibility in Varieties of English. Language Learning 68: 115–46. [Google Scholar] [CrossRef]
- Kartushina, Natalia, and Ulrich H. Frauenfelder. 2014. On the Effects of L2 Perception and of Individual Differences in L1 Production on L2 Pronunciation. Frontiers in Psychology 5: 1246. [Google Scholar] [CrossRef]
- Kelley, Matthew C., and Benjamin V. Tucker. 2020. A Comparison of Four Vowel Overlap Measures. The Journal of the Acoustical Society of America 147: 137–45. [Google Scholar] [CrossRef] [PubMed]
- Kisler, Thomas, Uwe Reichel, and Florian Schiel. 2017. Multilingual Processing of Speech via Web Services. Computer Speech & Language 45: 326–47. [Google Scholar] [CrossRef]
- Kuznetsova, Alexandra, Per B. Brockhoff, and Rune H. B. Christensen. 2017. LmerTest Package: Tests in Linear Mixed Effects Models. Journal of Statistical Software 82: 1–26. [Google Scholar] [CrossRef]
- Leppik, Katrin, Pärtel Lippus, and Eva Liina Asu. 2023. The Perception and Production of Estonian Vowels and Vocalic Quantity Contrasts by Spanish L1 Learners. Ampersand 11: 100147. [Google Scholar] [CrossRef]
- Liakin, Denis, Walcir Cardoso, and Natallia Liakina. 2015. Learning L2 Pronunciation with a Mobile Speech Recognizer: French/y/. Calico Journal 32: 1–25. [Google Scholar] [CrossRef]
- Lisker, Leigh, and Arthur S. Abramson. 1964. A Cross-Language Study of Voicing in Initial Stops: Acoustical Measurements. Word 20: 384–422. [Google Scholar] [CrossRef]
- Mairano, Paolo, Caroline Bouzon, Marc Capliez, and Valentina De Iacovo. 2019. ‘Acoustic Distances, Pillai Scores and LDA Classification Scores as Metrics of L2 Comprehensibility and Nativelikeness’. Paper presented at 19th International Congress of Phonetic Sciences, Melbourne, Australia, August 5–9; pp. 1104–8. Available online: https://www.icphs2023.org/programme/proceedings/ (accessed on 20 November 2023).
- Mairano, Paolo, and Fabian Santiago. 2020. What Vocabulary Size Tells Us about Pronunciation Skills: Issues in Assessing L2 Learners. Journal of French Language Studies 30: 141–60. [Google Scholar] [CrossRef]
- Mairano, Paolo, Leonardo Contreras Roa, Marc Capliez, and Caroline Bouzon. 2021. ‘The /s/ ~ /z/ Voice Contrast in L1 French, L1 Spanish and L1 Italian Learners of L2 English’. Language, Interaction and Acquisition 12: 210–50. [Google Scholar] [CrossRef]
- Marinescu, Irina. 2013. Native Dialect Effects in Non-Native Production: Cuban and Peninsular Learners of English. Canadian Journal of Linguistics/Revue Canadienne de Linguistique 58: 415–41. [Google Scholar] [CrossRef]
- Méli, Adrien, and Nicolas Ballier. 2019. Analyse de La Production de Voyelles Anglaises Par Des Apprenants Francophones, l’acquisition Du Contraste /ɪ/–/Iː/ à La Lumière Des k-NN. Anglophonia 27: 1–16. [Google Scholar] [CrossRef]
- Melnik-Leroy, Gerda Ana, Rory Turnbull, and Sharon Peperkamp. 2022. On the Relationship between Perception and Production of L2 Sounds: Evidence from Anglophones’ Processing of the French /u/–/y/ Contrast. Second Language Research 38: 581–605. [Google Scholar] [CrossRef]
- Munro, Murray J., and Tracey M. Derwing. 1999. Foreign Accent, Comprehensibility, and Intelligibility in the Speech of Second Language Learners. Language Learning 49: 285–310. [Google Scholar] [CrossRef]
- Neri, Ambra, Catia Cucchiarini, and Helmer Strik. 2008. The Effectiveness of Computer-Based Speech Corrective Feedback for Improving Segmental Quality in L2 Dutch. ReCALL 20: 225–43. [Google Scholar] [CrossRef]
- Nycz, Jennifer, and Lauren Hall-Lew. 2013. Best Practices in Measuring Vowel Merger. The Journal of the Acoustical Society of America 134: 4198. [Google Scholar] [CrossRef]
- Perry, Scott James, and Benjamin V. Tucker. 2019. L2 Production of American English Vowels in Function Words by Spanish L1 Speakers. Canadian Acoustics 47: 94–95. [Google Scholar]
- Pillot-Loiseau, Claire, and Martina Grando. 2020. Apport des comptines pour la prononciation du/y/français chez des enfants italophones: Une étude perceptive pilote. Paper presented at Actes de la 6e conférence conjointe JEP TALN RÉCITAL, Nancy, France, June 8–19; vol. 1, pp. 507–15. [Google Scholar]
- Racine, Isabelle, and Sylvain Detey. 2018. Production of French Close Rounded Vowels by Spanish Learners: A Corpus-Based Study. In Romance Phonetics and Phonology. Oxford: Oxford University Press, pp. 381–94. [Google Scholar] [CrossRef]
- Rathcke, Tamara, Jane Stuart-Smith, Bernard Torsney, and Jonathan Harrington. 2017. The Beauty in a Beast: Minimising the Effects of Diverse Recording Quality on Vowel Formant Measurements in Sociophonetic Real-Time Studies. Speech Communication 86: 24–41. [Google Scholar] [CrossRef]
- R Core Team. 2023. R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing. Available online: https://www.R-project.org/ (accessed on 20 November 2023).
- Ruellot, Viviane. 2011. Computer-Assisted Pronunciation Learning of French/u/and/y/at the Intermediate Level. Paper presented at 2nd Pronunciation in Second Language Learning and Teaching Conference, Ames, IA, USA, September 10–11; vol. 2, pp. 199–213. [Google Scholar]
- Saito, Kazuya. 2021. What Characterizes Comprehensible and Native-like Pronunciation Among English-as-a-Second-Language Speakers? Meta-Analyses of Phonological, Rater, and Instructional Factors. TESOL Quarterly 55: 866–900. [Google Scholar] [CrossRef]
- Saito, Kazuya, Pavel Trofimovich, and Talia Isaacs. 2017. Using Listener Judgments to Investigate Linguistic Influences on L2 Comprehensibility and Accentedness: A Validation and Generalization Study. Applied Linguistics 38: 439–62. [Google Scholar] [CrossRef]
- Santiago, Fabián, and Paolo Mairano. 2021. ‘La Prononciation Des Voyelles /e/, /ɛ/, /ə/, /ø/, /œ/ En FLE Chez Les Hispanophones et Le Rôle de l’orthographe’. In La Prononciation Du Français Langue Étrangère: Perspectives Linguistiques et Didactiques. Edited by Elisa Pustka. Romanistische Fremdsprachenforschung Und Unterrichtsentwicklungen. Tübingen: Narr, pp. 113–32. [Google Scholar]
- Simon, Ellen, Mathijs Debaene, and Mieke Van Herreweghe. 2015. The Effect of L1 Regional Variation on the Perception and Production of Standard L1 and L2 Vowels. Folia Linguistica 49: 521–53. [Google Scholar] [CrossRef]
- Strik, Helmer, Khiet Truong, Febe De Wet, and Catia Cucchiarini. 2009. Comparing Different Approaches for Automatic Pronunciation Error Detection. Speech Communication 51: 845–52. [Google Scholar] [CrossRef]
- Limesurvey Project Team. 2012. Limesurvey: An Open Source Survey Tool. Available online: http://www.limesurvey.org (accessed on 20 November 2023).
- Tejedor-Garcia, Cristian, David Escudero-Mancebo, Valentin Cardenoso-Payo, and Cesar Gonzalez-Ferreras. 2020. Using Challenges to Enhance a Learning Game for Pronunciation Training of English as a Second Language. IEEE Access 8: 74250–66. [Google Scholar] [CrossRef]
- Valenzuela Farias, Maria Gabriela. 2022. Developing English Vowel Contrasts: An Analysis of Spanish L1 Learners’ Speech Production over Time in the UK. Ph.D. thesis, University of York, Heslington, UK. [Google Scholar]
- Witt, Silke M. 2012. Automatic Error Detection in Pronunciation Training: Where We Are and Where We Need to Go. Paper presented at International Symposium on Automatic Detection on Errors in Pronunciation Training, Stockholm, Sweden, June 6–8; vol. 1, pp. 1–8. [Google Scholar]
- Witt, Silke M., and Steve J. Young. 2000. Phone-Level Pronunciation Scoring and Assessment for Interactive Language Learning. Speech Communication 30: 95–108. [Google Scholar] [CrossRef]
- Xi, Xiaoming. 2010. Special Issue: Automated Scoring and Feedback Systems for Language Assessment and Learning. Language Testing 27: 291–440. [Google Scholar] [CrossRef]
- Yoon, Su-Youn, Mark Hasegawa-Johnson, and Richard Sproat. 2010. Landmark-Based Automated Pronunciation Error Detection. Paper presented at Eleventh Annual Conference of the International Speech Communication Association (ISCA), Chiba, Japan, September 26–30; pp. 614–17. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| English | ||||||||
| /iː/ | /ɪ/ | /ɑː/ | /æ/ | /uː/ | /ʊ/ | /ɜː/ | /ʌ/ | |
| 1177 | 5078 | 418 | 1433 | 707 | 419 | 221 | 841 | |
| French | ||||||||
| /y/ | /u/ | /ø, œ/ | /e, ɛ/ | /o, ɔ/ | /a/ | // | // | // |
| 1721 (235) | 1271 (272) | 1107 (238) | 8739 (1818) | 2957 (485) | 6447 (1263) | 1427 (321) | 2342 (483) | 1601 (289) |
| EnglishL2 | FrenchL2 | |||
|---|---|---|---|---|
| Comprehensibility | Nativelikeness | Comprehensibility | Nativelikeness | |
| Mean | 7.2 (SD = 1.84) | 5.28 (SD = 1.69) | 7.29 (SD = 1.58) | 3.46 (SD = 2.04) |
| ICC | 0.90 (CI = 0.84, 0.94) | 0.95 (CI = 0.92, 0.97) | 0.91 (CI = 0.86, 0.94) | 0.88 (CI = 0.81, 0.92) |
| /iː/ — /ɪ/ | /ɑː/ — /æ/ | /ɜː/ — /ʌ/ | /uː/ — /ʊ/ | |
|---|---|---|---|---|
| Models predicting comprehensibility | ||||
| p value for fixed effect | <0.001 *** | 0.002 ** | 0.071 | 0.036 * |
| marginal R2 | 0.252 | 0.22 | 0.097 | 0.1 |
| Conditional R2 | 0.423 | 0.452 | 0.203 | 0.236 |
| Models predicting nativelikeness | ||||
| p value for fixed effect | 0.002 ** | 0.003 ** | 0.188 | 0.041 * |
| Marginal R2 | 0.201 | 0.185 | 0.05 | 0.086 |
| Conditional R2 | 0.458 | 0.503 | 0.248 | 0.312 |
| /y/ - /u/ | /ø, œ/ - /o, ɔ/ (EngL1) | /ø, œ/ - /e, ɛ/ (SpL1 & ItL1) | // - /e, ɛ/ | // - /a/ | // - /o, ɔ/ | |
|---|---|---|---|---|---|---|
| Models predicting comprehensibility | ||||||
| p value for fixed effect | <0.001 *** | 0.126 | 0.078 | 0.084 | 0.052 | 0.765 |
| Marginal R2 | 0.087 | / | 0.002 | 0.020 | 0.035 | <0.001 |
| Conditional R2 | 0.749 | / | 0.803 | 0.703 | 0.75 | 0.69 |
| Models predicting nativelikeness | ||||||
| p value for fixed effect | <0.001 *** | 0.092 | 0.325 | 0.027 * | 0.021 * | 0.836 |
| Marginal R2 | 0.146 | / | 0.009 | 0.05 | 0.07 | <0.001 |
| Conditional R2 | 0.624 | / | 0.668 | 0.56 | 0.649 | 0.523 |
| /y/ | /ø/ | // | // | // | |
|---|---|---|---|---|---|
| Models predicting comprehensibility | |||||
| p value for fixed effect | 0.43 | 0.224 | 0.299 | 0.307 | 0.716 |
| Marginal R2 | 0.004 | 0.01 | 0.007 | 0.007 | <0.001 |
| Conditional R2 | 0.694 | 0.704 | 0.703 | 0.695 | 0.693 |
| Models predicting nativelikeness | |||||
| p value for fixed effect | 0.184 | 0.32 | 0.358 | 0.141 | 0.954 |
| Marginal R2 | 0.018 | 0.01 | 0.009 | 0.023 | <0.001 |
| Conditional R2 | 0.542 | 0.538 | 0.54 | 0.542 | 0.523 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mairano, P.; Santiago, F.; Roa, L.C. Can L2 Pronunciation Be Evaluated without Reference to a Native Model? Pillai Scores for the Intrinsic Evaluation of L2 Vowels. Languages 2023, 8, 280. https://doi.org/10.3390/languages8040280
Mairano P, Santiago F, Roa LC. Can L2 Pronunciation Be Evaluated without Reference to a Native Model? Pillai Scores for the Intrinsic Evaluation of L2 Vowels. Languages. 2023; 8(4):280. https://doi.org/10.3390/languages8040280
Chicago/Turabian StyleMairano, Paolo, Fabián Santiago, and Leonardo Contreras Roa. 2023. "Can L2 Pronunciation Be Evaluated without Reference to a Native Model? Pillai Scores for the Intrinsic Evaluation of L2 Vowels" Languages 8, no. 4: 280. https://doi.org/10.3390/languages8040280