
Exploring the Role of Artificial Intelligence in Facilitating Assessment of Writing Performance in Second Language Learning

Abstract
:1. Introduction
- How robust are LLMs (GPT-4, GPT-3.5, iFLYTEK Open Platform, and Baidu AI Cloud) in assessing writing accuracy in general at the T-unit level and sentence level?
- How efficient are LLMs (GPT-4, GPT-3.5, iFLYTEK Open Platform, and Baidu AI Cloud) in assessing writing accuracy in general at the T-unit level and sentence level?
- What types of discrepancies exist between human rating results and AI rating results?
2. Literature Review
3. Methodology
3.1. Context
3.2. Procedures
3.2.1. GPT-3.5 and GPT-4
3.2.2. iFLYTEK and Baidu Cloud
3.3. Data Analysis
4. Results
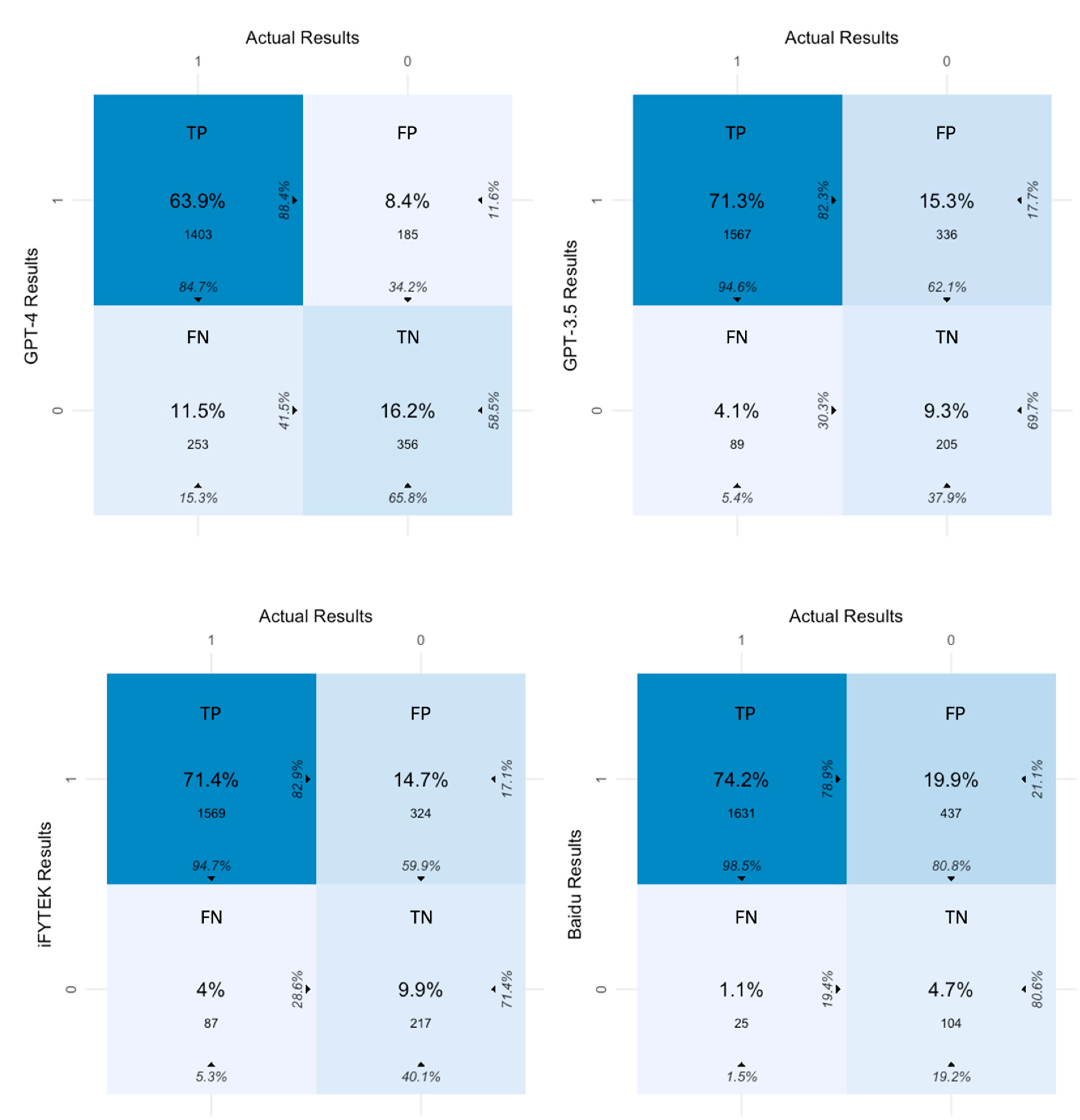
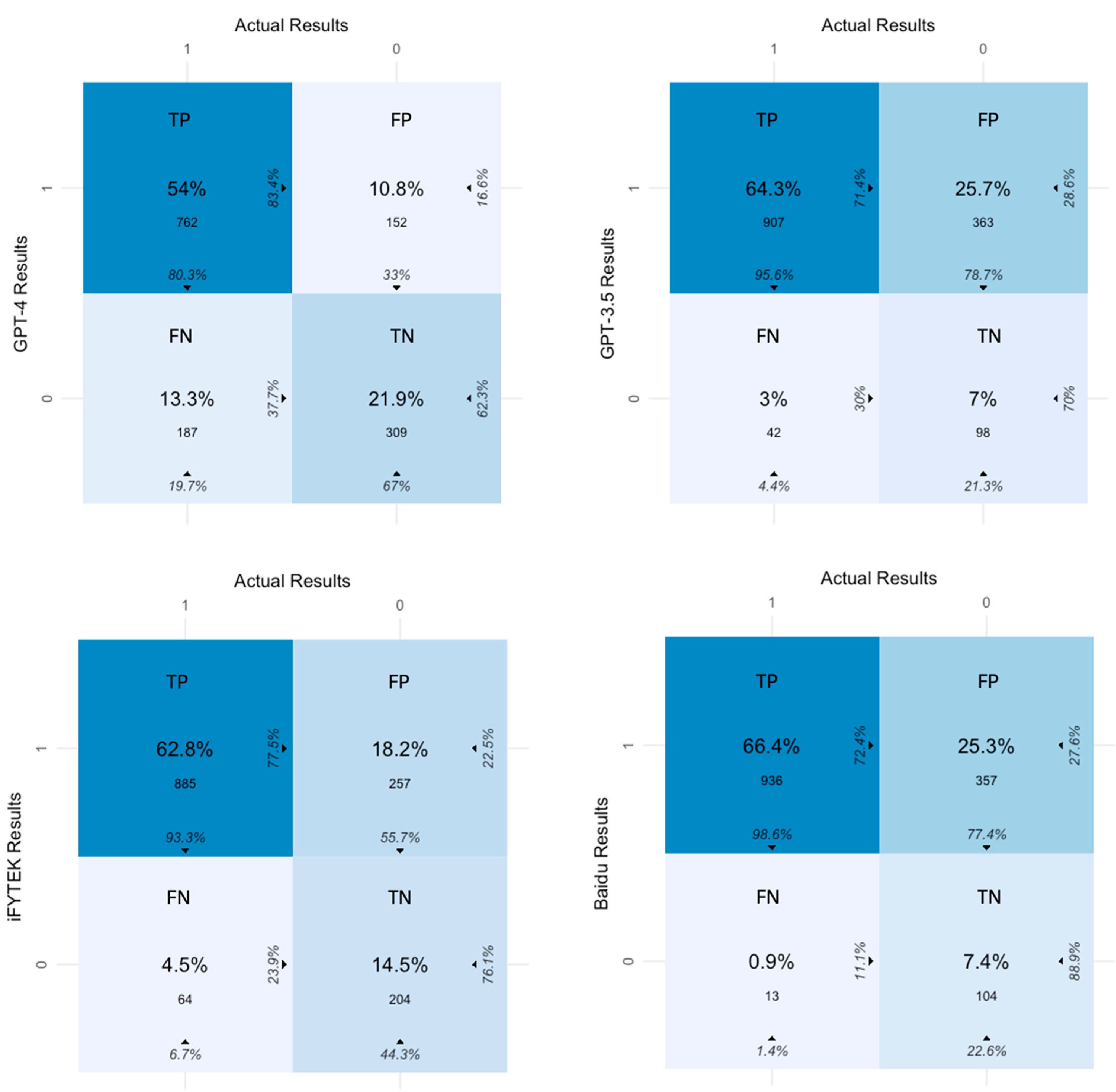
4.1. Robustness of LLMs
4.1.1. Human Assessment Results
4.1.2. LLM Assessment Results
4.2. Efficiency of LLMs
4.3. Discrepancies between Human and LLM Assessment Results
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Abd El-Haleem, Ahmed M., Mohab Mohammed Eid, Mahmoud M. Elmesalawy, and Hadeer A. Hassan Hosny. 2022. A generic ai-based technique for assessing student performance in conducting online virtual and remote controlled laboratories. IEEE Access 10: 128046–65. [Google Scholar] [CrossRef]
- Aldriye, Hussam, Asma Alkhalaf, and Muath Alkhalaf. 2019. Automated grading systems for programming assignments: A literature review. International Journal of Advanced Computer Science and Applications 10: 215–22. [Google Scholar] [CrossRef]
- Alqahtani, Abeer, and Amal Alsaif. 2019. Automatic evaluation for arabic essays: A rule-based system. Paper presented at 2019 IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), Ajman, United Arab Emirates, December 10–12; pp. 1–7. [Google Scholar] [CrossRef]
- Brown, Tom, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D. Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, and Amanda Askell. 2020. Language models are few-shot learners. Advances in Neural Information Processing Systems 33: 1877–901. [Google Scholar]
- Cho, Ji Young, and Eun-Hee Lee. 2014. Reducing confusion about grounded theory and qualitative content analysis: Similarities and differences. The Qualitative Report 19: 1–20. [Google Scholar] [CrossRef]
- Evans, Norman W., K. James Hartshorn, Troy L. Cox, and Teresa Martin De Jel. 2014. Measuring written linguistic accuracy with weighted clause ratios: A question of validity. Journal of Second Language Writing 24: 33–50. [Google Scholar] [CrossRef]
- Hoblos, Jalaa. 2020. Experimenting with latent semantic analysis and latent dirichlet allocation on automated essay grading. Paper presented at 2020 Seventh International Conference on Social Networks Analysis, Management and Security (SNAMS), Paris, France, December 14–16; pp. 1–7. [Google Scholar] [CrossRef]
- Hunt, Kellogg W. 1965. Grammatical Structures Written at Three Grade Levels. Champaign: National Council of Teachers of English, vol. 3. [Google Scholar]
- Jiang, Wenying. 2013. Measurements of development in L2 written production: The case of L2 Chinese. Applied Linguistics 34: 1–24. [Google Scholar] [CrossRef]
- Kortemeyer, Gerd. 2023. Can an AI-tool grade assignments in an introductory physics course? arXiv arXiv:2304.11221. [Google Scholar] [CrossRef]
- Liao, Jianling. 2020. Do L2 lexical and syntactic accuracy develop in parallel? Accuracy development in L2 Chinese writing. System 94: 102325. [Google Scholar] [CrossRef]
- Montero, Juan M., R. San-Segunda, Javier Macías-Guarasa, Ricardo De Cordoba, and Javier Ferreiros. 2006. Methodology for the analysis of instructors’ grading discrepancies in a laboratory course. International Journal of Engineering Education 22: 1053. [Google Scholar]
- Peng, Jinfang, Chuming Wang, and Xiaofei Lu. 2020. Effect of the linguistic complexity of the input text on alignment, writing fluency, and writing accuracy in the continuation task. Language Teaching Research 24: 364–81. [Google Scholar] [CrossRef]
- Ramalingam, V. V., A. Pandian, Prateek Chetry, and Himanshu Nigam. 2018. Automated essay grading using machine learning algorithm. Journal of Physics: Conference Series 1000: 012030. [Google Scholar] [CrossRef]
- Way, Susan, Margaret Fisher, and Sam Chenery-Morris. 2019. An evidence-based toolkit to support grading of pre-registration midwifery practice. British Journal of Midwifery 27: 251–57. [Google Scholar] [CrossRef]
- Wolfe-Quintero, Kate, Shunji Inagaki, and Hae-Young Kim. 1998. Second Language Development in Writing: Measures of Fluency, Accuracy, & Complexity. Honolulu: University of Hawaii Press. [Google Scholar]
- Zamen, John. 2020. Digital apps in formative assessment: Today’s aid in teaching and learning in higher education. EPRA International Journal of Research and Development 5: 109–14. [Google Scholar] [CrossRef]
- Zhang, Dongyu, Minghao Zhang, Ciyuan Peng, and Feng Xia. 2022. Expressing Metaphorically, Writing Creatively: Metaphor Identification for Creativity Assessment in Writing. In Presented at the Companion Proceedings of the Web Conference 2022, Lyon, France, April 25–29; pp. 1198–205. [Google Scholar]



{kind=link}
{kind=link}
| Confusion Matrix | Ground Truth | ||
|---|---|---|---|
| Actual Positive | Actual Negative | ||
| AI Results | Positive | True Positives (TP) | False Positives (FP) |
| Negative | False Negatives (FN) | True Negatives (TN) | |
| True Positives: | The outcome in which the AI correctly predicts the positive class. If the writing result was marked as correct by researchers, the AI also predicted it as correct. | ||
| False Positives: | The outcome in which the AI incorrectly predicts the positive class. The AI determined the result was true when it was false. In our context, if the writing result was marked as incorrect by researchers, the AI still predicted it as correct. | ||
| False Negatives: | The outcome in which the AI incorrectly predicts the negative class. The AI determined the result was false when it was true. In our context, if the writing result was marked as correct by researchers, the AI predicted it as incorrect. | ||
| True Negatives: | The outcome in which the AI correctly predicts the negative class. If the writing result was marked as incorrect by researchers, the AI also predicted it as incorrect. | ||
| Evaluation Metrics | ||
|---|---|---|
| Measure | Formula | Focus |
| Accuracy | (TP + TN)/(TP + FP + TN + FN) | The number of correct predictions over all predictions. Accuracy is a good measure if a balanced classifier is presented, as it is interested in all types of outputs equally. |
| Precision | TP/(TP + FP) | The degree to which the AI made correct positive predictions out of all AI positive results. It indicates how many of the positive predictions made are correct. This metric is especially useful when we want to minimize false positives. In our context of assessing accuracy, we want to see the correct results as much as possible. However, we do not want to misclassify true errors into correct ones. Missing an error has a large cost in our context. Therefore, we wish to aim to maximize precision. |
| Recall | TP/(TP + FN) | The degree to which the AI correctly identified the positive instances out of the total number of actual positives. It indicates how good the model is at picking the correct items. Recall is an important indicator when we want to minimize the chance of missing positive cases. |
| F1 | 2*Precision*Recall/(Precision + Recall) | The harmonic mean of precision and recall, working well when the classifying results are unbalanced. |
| Matched Results (TP + TN) % | Unmatched Results (FP + FN) % | Accuracy | Precision | Recall | F1 | |
|---|---|---|---|---|---|---|
| T-units | ||||||
| GPT-4 | 80.1 | 19.9 | 0.81 | 0.88 | 0.85 | 0.87 |
| GPT-3.5 | 80.6 | 19.4 | 0.81 | 0.82 | 0.95 | 0.88 |
| iFLYTEK | 81.3 | 18.7 | 0.81 | 0.83 | 0.95 | 0.88 |
| Baidu | 78.9 | 21 | 0.79 | 0.79 | 0.99 | 0.88 |
| Sentences | ||||||
| GPT-4 | 75.9 | 24.1 | 0.76 | 0.84 | 0.80 | 0.81 |
| GPT-3.5 | 71.3 | 28.7 | 0.71 | 0.71 | 0.96 | 0.82 |
| iFLYTEK | 77.3 | 22.7 | 0.77 | 0.78 | 0.93 | 0.85 |
| Baidu | 73.8 | 26.2 | 0.74 | 0.72 | 0.97 | 0.84 |
| GPT-4 | GPT-3.5 | iFLYTEK | Baidu | |
|---|---|---|---|---|
| T-unit | ||||
| Time | 6 h 31′39.6″ | 65′3″ | 27′14″ | 46′10.5″ |
| Query | 8 | 15 | 1 | 1 |
| Cost | USD 11.27 | USD 0.4 | 0 | 0 |
| Sentence | ||||
| Time | 3 h 31′51″ | 27′23.4″ | 26′54″ | 29′54.4″ |
| Query | 2 | 1 | 0 | 0 |
| Cost | USD 5.78 | USD 0.17 | 0 | 0 |
| Category | Error Types for FP Results | Notes | Error Examples | Corrected Examples |
|---|---|---|---|---|
| Word | Word choice | A word choice error occurs when a word is used incorrectly or inappropriately in a unit, causing confusion or a change in meaning. | 我吃的以后觉得胃不太舒服 (My stomach does not feel well after I had the food.) | 我吃了以后觉得胃不太舒服。(The use of 了 indicates the completion of the eating action.) |
| Error in word writing | An error in word writing can be found when the word is written in an incorrect form. Usually, the wrongly written word is similar to the correct form of the word or has a similar sound. | 去看电影和吃完饭 (Go to watch a movie and have dinner.) | 去看电影和吃晚饭 (Although the pronunciations for 完 and 晚 are the same, the tones are different.) | |
| Word form | A word form error can be found when characters are missing or the order of characters are incorrect. | 然后我坐租车到饭馆(Then, I took a taxi to the restaurant.) | 然后我坐出租车到饭馆 (The character 出 is missing.) | |
| Structure | Structure usage | A structural usage error occurs when the structure of a sentence or phrase is incorrect or inappropriate. | 这个菜做的不难 (This dish is not difficult to make.) | 这个菜做起来不难 (Using “做起来” is the correct use of the direction complement.) |
| Word order | A word order error refers to an error in the order of words or structure components. | 他的做饭很好吃 (His cooking is delicious.) | 他做的饭很好吃 (“做的饭”means the food he made.) | |
| Redundancy | A redundancy error occurs when unnecessary words duplicate the information expressed by other words or structure components in the unit. | 我在加拿大里住了十五年了 (I have been living in Canada for 15 years.) | 我在加拿大住了十五年了. (里 means in, but using this word is not necessary.) | |
| Missing components | Essential structural elements are missing. | 这是我书 (This is my book.) | 这是我的书 (的 is missing, which should be used to indicate possession.) | |
| Context | The unit is accurate on its own but is incorrect when taking the context into account. This type of error includes the error types that occur in the word and structure categories. | 我也非常喜欢吃种子 (I like eating seeds.) | 我也非常喜欢吃粽子 (I like eating glutinous rice.) |
| GPT-4 | iFLYTEK | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Total | % | n | % | Total | % | n | % | ||
| Context | Word | 21 | 11% | 16 | 9% | 32 | 10% | 26 | 8% |
| Structure | 5 | 3% | 5 | 2% | |||||
| Word | Word choice | 76 | 41% | 53 | 19% | 128 | 40% | 108 | 33% |
| Error in word writing | 14 | 8% | 12 | 4% | |||||
| Word form | 9 | 5% | 8 | 2% | |||||
| Structure | Structure usage | 88 | 48% | 19 | 10% | 164 | 50% | 40 | 12% |
| Word order | 10 | 5% | 31 | 10% | |||||
| Redundancy | 26 | 14% | 42 | 13% | |||||
| Missing components | 33 | 18% | 51 | 16% | |||||
| Total | 185 | 324 | |||||||
| Category | Definition | Student’s Response | GPT-4 Examples | iFLYTEK Examples |
|---|---|---|---|---|
| Overcorrection with correct suggestions | The original sentence is already acceptable in its current form. However, the suggestion provided may help to enhance the sentence by providing more clarity, conciseness or precision in its meaning. | 别的中国餐我也喜欢 (I also like other Chinese foods.) | 正确的表达方式应该是:“我喜欢其他所有中国菜。”或者“除了这道菜,我喜欢吃其他所有中国菜。” (The correct expression should be, “I like all other Chinese dishes” or “I like all other Chinese dishes except this one.”) | “餐”字使用错误,应使用“菜”字。(The word “餐meal” is used incorrectly; the word “菜dish” should be used.) |
| Overcorrection with incorrect suggestions | The original sentence is already acceptable in its current form. However, the suggestion provided is incorrect. | 你好李东艾 (Hello, Li Dongai.) | 这句话有一些语病。首先,在拼写上应该是“李东霖”而不是“李东艾”。其次,语序上略显不顺。正常的表达可以是:“李东霖,你好!”或者“你好,李东霖!” (First, in terms of spelling, it should be “李东霖” instead of “李东艾”. Second, the word order is slightly awkward. A more natural expression would be “李东霖,你好!” or “你好,李东霖!”.) | |
| 中国饭馆在哪儿 (Where is the Chinese restaurant?) | “哪”字使用错误,应使用“那”字。The word “where” is used incorrectly; the word “there” should be used.) | |||
| Correction of other languages | The Chinese sentences are correct, but corrections are needed for sentences in other languages. | 我喜欢你的story (I like your story.) | 这句话中的”story”没有被翻译成中文,所以显得有些不协调。可以改成:“我喜欢你的故事。” (The word “story” in this sentence is not translated into Chinese, so it seems a bit incongruous. It could be changed to “I like your story.) | |
| Need context to understand | Due to insufficient contextual information, a judgement cannot be made. | 另一个没有 (The other one did not. The context for this unit is 一个有珍珠,另一个没有:one has the boba, the other does not.) | 句子没有给出完整的意思和信息。(The sentence does not give the full meaning and information.) |
| Category | GPT-4 | iFLYTEK | ||
|---|---|---|---|---|
| Overcorrection with correct suggestions | 174 | 69% | 54 | 62% |
| Overcorrection with incorrect suggestions | 20 | 8% | 33 | 38% |
| Correction of other languages | 49 | 19% | ||
| Need context to understand | 10 | 4% | ||
| Total | 253 | 87 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, Z.; Xu, Z.; Pan, Z.; He, J.; Xie, K. Exploring the Role of Artificial Intelligence in Facilitating Assessment of Writing Performance in Second Language Learning. Languages 2023, 8, 247. https://doi.org/10.3390/languages8040247
Jiang Z, Xu Z, Pan Z, He J, Xie K. Exploring the Role of Artificial Intelligence in Facilitating Assessment of Writing Performance in Second Language Learning. Languages. 2023; 8(4):247. https://doi.org/10.3390/languages8040247
Chicago/Turabian StyleJiang, Zilu, Zexin Xu, Zilong Pan, Jingwen He, and Kui Xie. 2023. "Exploring the Role of Artificial Intelligence in Facilitating Assessment of Writing Performance in Second Language Learning" Languages 8, no. 4: 247. https://doi.org/10.3390/languages8040247