
Testing the Triggering Hypothesis: Effect of Cognate Status on Code-Switching and Disfluencies

Abstract
:1. Introduction
- 1.
- Do cognates trigger code-switches?
- 2.
- Do cognates trigger disfluencies?
- 3.
- Do cognate effects vary by language of the task?
2. Materials and Methods
2.1. Participants
2.2. Stimuli
2.3. Procedure
2.4. Coding
2.5. Analysis
3. Results
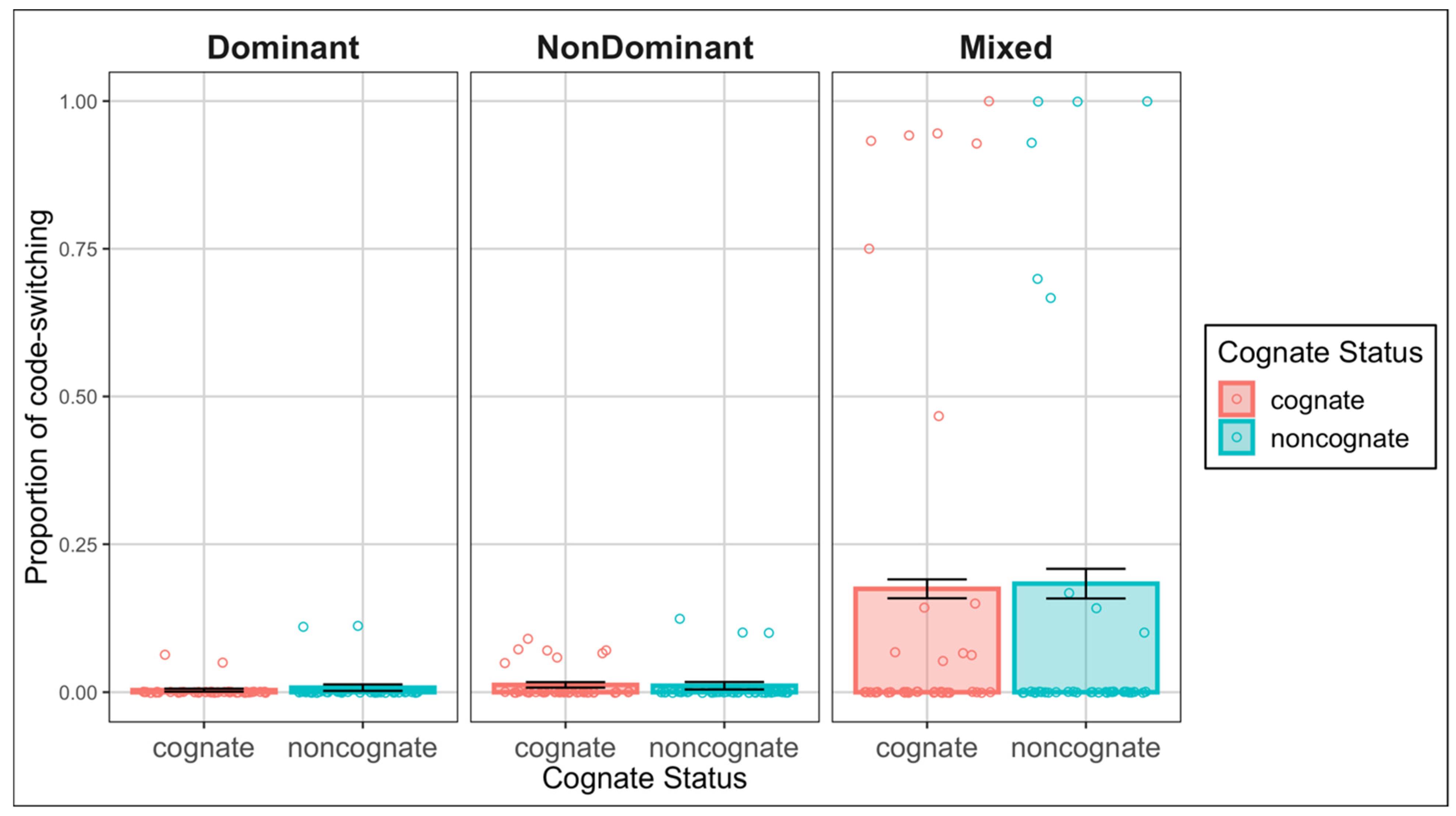
3.1. Code-Switching
3.2. Disfluencies
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Acheson, Daniel J., Lesya Y. Ganushchak, Ingrid K. Christoffels, and Peter Hagoort. 2012. Conflict monitoring in speech production: Physiological evidence from bilingual picture naming. Brain and Language 123: 131–36. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Audacity Team. 2019. Audacity(R): Free Audio Editor and Recorder [Computer Application]. Version 2.3.3. Available online: https://audacityteam.org/ (accessed on 22 November 2019).
- Bates, Douglas, Martin Mächler, Ben Bolker, and Steve Walker. 2015. Fitting Linear Mixed-Effects Models Using lme4. Journal of Statistical Software 67: 1–48. [Google Scholar] [CrossRef]
- Bates, Elizabeth, Simona D’Amico, Thomas Jacobsen, Anna Székely, Elena Andonova, Antonella Devescovi, Dan Herron, Ching Ching Lu, Thomas Pechmann, Csaba Pléh, and et al. 2003. Timed picture naming in seven languages. Psychonomic Bulletin & Review 10: 344–80. [Google Scholar]
- Beatty-Martínez, Anne L., Christian A. Navarro-Torres, and Paola E. Dussias. 2020. Codeswitching: A bilingual toolkit for opportunistic speech planning. Frontiers in Psychology 11: 1699. [Google Scholar] [CrossRef]
- Bernolet, Sarah, Simona Collina, and Robert J. Hartsuiker. 2016. The persistence of syntactic priming revisited. Journal of Memory and Language 91: 99–116. [Google Scholar] [CrossRef]
- Broersma, Mirjam. 2009. Triggered codeswitching between cognate languages. Bilingualism: Language and Cognition 12: 447–62. [Google Scholar] [CrossRef] [Green Version]
- Broersma, Mirjam, and Kees De Bot. 2006. Triggered codeswitching: A corpus-based evaluation of the original triggering hypothesis and a new alternative. Bilingualism: Language and Cognition 9: 1–13. [Google Scholar] [CrossRef] [Green Version]
- Broersma, Mirjam, Diana Carter, and Daniel J. Acheson. 2016. Cognate costs in bilingual speech production: Evidence from language switching. Frontiers in Psychology 7: 1461. [Google Scholar] [CrossRef] [Green Version]
- Broersma, Mirjam, Diana Carter, Kevin Donnelly, and Agnieszka Konopka. 2020. Triggered codeswitching: Lexical processing and conversational dynamics. Bilingualism: Language and Cognition 23: 295–308. [Google Scholar] [CrossRef] [Green Version]
- Bultena, Sybrine, Ton Dijkstra, and Janet G. van Hell. 2015a. Switch cost modulations in bilingual sentence processing: Evidence from shadowing. Language, Cognition and Neuroscience 30: 586–605. [Google Scholar] [CrossRef]
- Bultena, Sybrine, Ton Dijkstra, and Janet G. van Hell. 2015b. Language switch costs in sentence comprehension depend on language dominance: Evidence from self-paced reading. Bilingualism: Language and Cognition 18: 453–69. [Google Scholar] [CrossRef]
- Clyne, Michael. 2000. Constraints on code-switching: How universal are they. In The Bilingualism Reader. London: Routledge, pp. 257–80. [Google Scholar]
- Clyne, Michael. 1980. Triggering and language processing. Canadian Journal of Psychology/Revue Canadienne de Psychologie 34: 400. [Google Scholar] [CrossRef]
- Costa, Albert, Alfonso Caramazza, and Nuria Sebastian-Galles. 2000. The cognate facilitation effect: Implications for models of lexical access. Journal of Experimental Psychology: Learning, Memory, and Cognition 26: 1283. [Google Scholar] [CrossRef]
- Costa, Albert, and Mikel Santesteban. 2004. Lexical access in bilingual speech production: Evidence from language switching in highly proficient bilinguals and L2 learners. Journal of memory and Language 50: 491–511. [Google Scholar] [CrossRef]
- Costa, Albert, Mikel Santesteban, and Iva Ivanova. 2006. How do highly proficient bilinguals control their lexicalization process? Inhibitory and language-specific selection mechanisms are both functional. Journal of Experimental Psychology: Learning, Memory, and Cognition 32: 1057. [Google Scholar] [CrossRef] [Green Version]
- de Bruin, Angela, Arthur G. Samuel, and Jon Andoni Duñabeitia. 2018. Voluntary language switching: When and why do bilinguals switch between their languages? Journal of Memory and Language 103: 28–43. [Google Scholar] [CrossRef]
- Derwing, Tracey M., Murray J. Munro, Ronald I. Thomson, and Marian J. Rossiter. 2009. The relationship between L1 fluency and L2 fluency development. Studies in Second Language Acquisition 31: 533–57. [Google Scholar] [CrossRef]
- Dijkstra, Ton, Koji Miwa, Bianca Brummelhuis, Maya Sappelli, and Harald Baayen. 2010. How cross-language similarity and task demands affect cognate recognition. Journal of Memory and Language 62: 284–301. [Google Scholar] [CrossRef]
- Dunn, Lloyd M., and Douglas M. Dunn. 2007. PPVT-4: Peabody Picture Vocabulary Test. Minneapolis: Pearson Assessments. [Google Scholar]
- Dunn, Lloyd M., Delia E. Lugo, Eligio R. Padilla, and Leota M. Dunn. 1986. TVIP: Test de Vocabulario en Imagenes Peabody: Adaptacion Hispanoamericana = Peabody Picture Vocabulary Test [Revised]: Hispanic-American Adaptation. Circle Pines: American Guidance Service. [Google Scholar]
- Fox, John, and Sanford Weisberg. 2019. An R Companion to Applied Regression, 3rd ed. Thousand Oaks: Sage. [Google Scholar]
- Fricke, Melinda, and Gerrit Jan Kootstra. 2016. Primed codeswitching in spontaneous bilingual dialogue. Journal of Memory and Language 91: 181–201. [Google Scholar] [CrossRef]
- Fricke, Melinda, Judith F. Kroll, and Paola E. Dussias. 2016. Phonetic variation in bilingual speech: A lens for studying the production–comprehension link. Journal of Memory and Language 89: 110–37. [Google Scholar] [CrossRef] [Green Version]
- Gollan, Tamar H., Daniel Kleinman, and Christina E. Wierenga. 2014. What’s easier: Doing what you want, or being told what to do? Cued versus voluntary language and task switching. Journal of Experimental Psychology: General 143: 2167. [Google Scholar] [CrossRef]
- Green, David W. 2018. Language control and code-switching. Languages 3: 8. [Google Scholar] [CrossRef] [Green Version]
- Green, David W., and Li Wei. 2014. A control process model of code-switching. Language, Cognition and Neuroscience 29: 499–511. [Google Scholar] [CrossRef]
- Hartig, Florian. 2021. DHARMa: Residual Diagnostics for Hierarchical (Multi-Level/Mixed) Regression Models. R Package Version 0.4.1. Available online: http://florianhartig.github.io/DHARMa/ (accessed on 27 September 2022).
- Hatzidaki, Anna, Holly P. Branigan, and Martin J. Pickering. 2011. Co-activation of syntax in bilingual language production. Cognitive Psychology 62: 123–50. [Google Scholar] [CrossRef]
- Hlavac, Jim. 2011. Hesitation and monitoring phenomena in bilingual speech: A consequence of code-switching or a strategy to facilitate its incorporation? Journal of Pragmatics 43: 3793–806. [Google Scholar] [CrossRef]
- Hoshino, Noriko, and Judith F. Kroll. 2008. Cognate effects in picture naming: Does cross-language activation survive a change of script? Cognition 106: 501–11. [Google Scholar] [CrossRef]
- Jevtović, Mina, Jon Andoni Duñabeitia, and Angela de Bruin. 2020. How do bilinguals switch between languages in different interactional contexts? A comparison between voluntary and mandatory language switching. Bilingualism: Language and Cognition 23: 401–13. [Google Scholar]
- Kaufman, Alan, and Nadeen Kaufman. 2004. Kaufman Brief Intelligence Test, 2nd ed. London: Pearson, Inc. [Google Scholar]
- Kootstra, Gerrit Jan, Janet G. Van Hell, and Ton Dijkstra. 2012. Priming of code-switches in sentences: The role of lexical repetition, cognates, and language proficiency. Bilingualism: Language and Cognition 15: 797–819. [Google Scholar] [CrossRef] [Green Version]
- Kootstra, Gerrit Jan, Ton Dijkstra, and Janet G. van Hell. 2020. Interactive alignment and lexical triggering of code-switching in bilingual dialogue. Frontiers in Psychology 11: 1747. [Google Scholar] [CrossRef]
- Kroll, Judith F., Paola E. Dussias, Kinsey Bice, and Lauren Perrotti. 2015. Bilingualism, mind, and brain. Annual Review of Linguistics 1: 377–94. [Google Scholar] [CrossRef] [Green Version]
- Kroll, Judith F., Susan C. Bobb, and Zofia Wodniecka. 2006. Language selectivity is the exception, not the rule: Arguments against a fixed locus of language selection in bilingual speech. Bilingualism: Language and Cognition 9: 119–35. [Google Scholar] [CrossRef]
- Lenth, Russell V. 2021. Emmeans: Estimated Marginal Means, Aka Least-Squares Means (R Package Version 1.5.4) [Computer Software]. The Comprehensive R Archive Network. Available online: https://CRAN.R-project.org/package=emmeans (accessed on 27 September 2022).
- Li, Chuchu, and Tamar H. Gollan. 2018. Cognates facilitate switches and then confusion: Contrasting effects of cascade versus feedback on language selection. Journal of Experimental Psychology: Learning, Memory, and Cognition 44: 974. [Google Scholar] [CrossRef] [PubMed]
- Li, Chuchu, and Tamar H. Gollan. 2021. What cognates reveal about default language selection in bilingual sentence production. Journal of Memory and Language 118: 104214. [Google Scholar] [CrossRef]
- Lijewska, Agnieszka. 2020. Cognate processing effects in bilingual lexical access. In Bilingual Lexical Ambiguity Resolution. Cambridge: Cambridge University Press, pp. 71–95. [Google Scholar]
- Loy, Adam, and Heike Hofmann. 2014. HLMdiag: A Suite of Diagnostics for Hierarchical Linear Models in R. Journal of Statistical Software 56: 1–28. [Google Scholar] [CrossRef] [Green Version]
- MacWhinney, Brian. 2014. The CHILDES Project: Tools for Analyzing Talk, 3rd ed. New York: Psychology Press. [Google Scholar]
- Marian, Viorica, and Michael Spivey. 2003a. Competing activation in bilingual language processing: Within-and between-language competition. Bilingualism: Language and Cognition 6: 97–115. [Google Scholar] [CrossRef]
- Marian, Viorica, and Michael Spivey. 2003b. Bilingual and monolingual processing of competing lexical items. Applied Psycholinguistics 24: 173–93. [Google Scholar] [CrossRef] [Green Version]
- Marian, Viorica, Henrike K. Blumenfeld, and Margarita Kaushanskaya. 2007. The Language Experience and Proficiency Questionnaire (LEAP-Q): Assessing language profiles in bilinguals and multilinguals. Journal of Speech, Language, and Hearing Research 50: 940–67. [Google Scholar] [CrossRef] [Green Version]
- Moon, Jihye, and Nan Jiang. 2012. Non-selective lexical access in different-script bilinguals. Bilingualism: Language and Cognition 15: 173–80. [Google Scholar] [CrossRef]
- Poplack, Shana. 1980. Sometimes I’ll start a sentence in Spanish y termino en español: Toward a typology of code-switching. Linguistics 18: 581–618. [Google Scholar] [CrossRef] [Green Version]
- R Core Team. 2020. R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing. Available online: https://www.R-project.org/ (accessed on 27 September 2022).
- Sarkar, Deepayan. 2008. Lattice: Multivariate Data Visualization with R. New York: Springer. [Google Scholar]
- Sarkis, Justin T., and Jessica L. Montag. 2021. The effect of lexical accessibility on Spanish-English intra-sentential codeswitching. Memory & Cognition 49: 163–80. [Google Scholar]
- Shin, Jeong Ah. 2008. Structural Priming in Bilingual Language Processing and Second Language Learning. Ph.D. dissertation, University of Illinois at Urbana-Champaign, Champaign, IL, USA. (Publication No. 3347510). ProQuest Dissertations Publishing. [Google Scholar]
- Singmann, Henrik, Ben Bolker, Jake Westfall, Frederik Aust, Mattan S. Ben-Shachar, Søren Højsgaard, John Fox, Michael A. Lawrence, Ulf Mertens, Jonathon Love, and et al. 2021. afex: Analysis of Factorial Experiments (R Package Version 0.28-1) [Computer Software]. The Comprehensive R Archive Network. Available online: https://CRAN.R-project.org/package=afex (accessed on 27 September 2022).
- Snodgrass, Joan G., and Mary Vanderwart. 1980. A standardized set of 260 pictures: Norms for name agreement, image agreement, familiarity, and visual complexity. Journal of Experimental Psychology: Human Learning and Memory 6: 174. [Google Scholar] [CrossRef]
- Van Assche, Eva, Wouter Duyck, Robert J. Hartsuiker, and Kevin Diependaele. 2009. Does bilingualism change native-language reading? Cognate effects in a sentence context. Psychological Science 20: 923–27. [Google Scholar] [CrossRef] [PubMed]
- Van Hell, Janet G., and Darren Tanner. 2012. Second language proficiency and cross-language lexical activation. Language Learning 62: 148–71. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Spanish Dominant | English Dominant | All Participants | |
|---|---|---|---|
| N | 12 (4 males) | 28 (11 males) | 40 (15 males) |
| Age | 32.28 (4.81) | 21.77 (3.33) | 24.92 (6.16) |
| English receptive vocabulary a | 90.33 (19.22) | 114.59 (9.92) | 107.13 (17.40) |
| Spanish receptive vocabulary b | 92% (5%) | 82% (6%) | 85% (7%) |
| Nonverbal intelligence c | 100.25 (13.71) | 103.82 (16.61) | 102.8 (15.7) |
| English self-rated speaking d | 7.50 (1.51) | 9.68 (0.48) | 9.03 (1.35) |
| English self-rated understanding d | 7.33 (1.87) | 9.71 (0.46) | 9.00 (1.54) |
| Spanish self-rated speaking d | 9.08 (1.00) | 7.89 (1.29) | 8.25 (1.32) |
| Spanish self-rated understanding d | 9.25 (0.87) | 8.07 (1.36) | 8.43 (1.34) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Neveu, A.; McDonald, M.; Kaushanskaya, M. Testing the Triggering Hypothesis: Effect of Cognate Status on Code-Switching and Disfluencies. Languages 2022, 7, 264. https://doi.org/10.3390/languages7040264
Neveu A, McDonald M, Kaushanskaya M. Testing the Triggering Hypothesis: Effect of Cognate Status on Code-Switching and Disfluencies. Languages. 2022; 7(4):264. https://doi.org/10.3390/languages7040264
Chicago/Turabian StyleNeveu, Anne, Margarethe McDonald, and Margarita Kaushanskaya. 2022. "Testing the Triggering Hypothesis: Effect of Cognate Status on Code-Switching and Disfluencies" Languages 7, no. 4: 264. https://doi.org/10.3390/languages7040264