
A Multi-Fidelity Uncertainty Propagation Model for Multi-Dimensional Correlated Flow Field Responses
Abstract
:1. Introduction
2. Uncertainty Propagation Model Framework and Key Algorithms
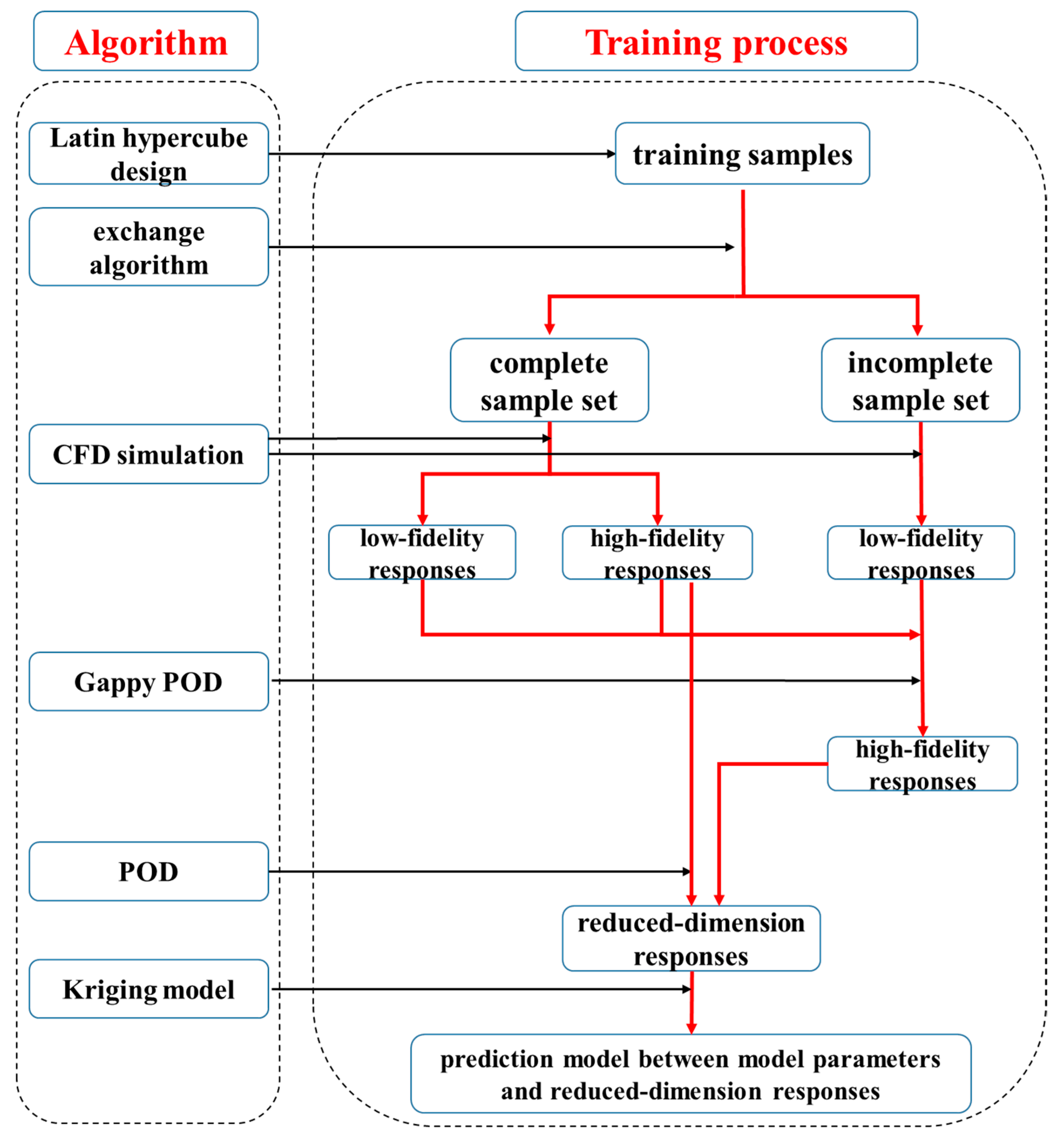
2.1. Model Training Process
- (1)
- In the input parameter space, Latin hypercube sampling is employed to generate the inputs for the ntrain training samples.
- (2)
- (3)
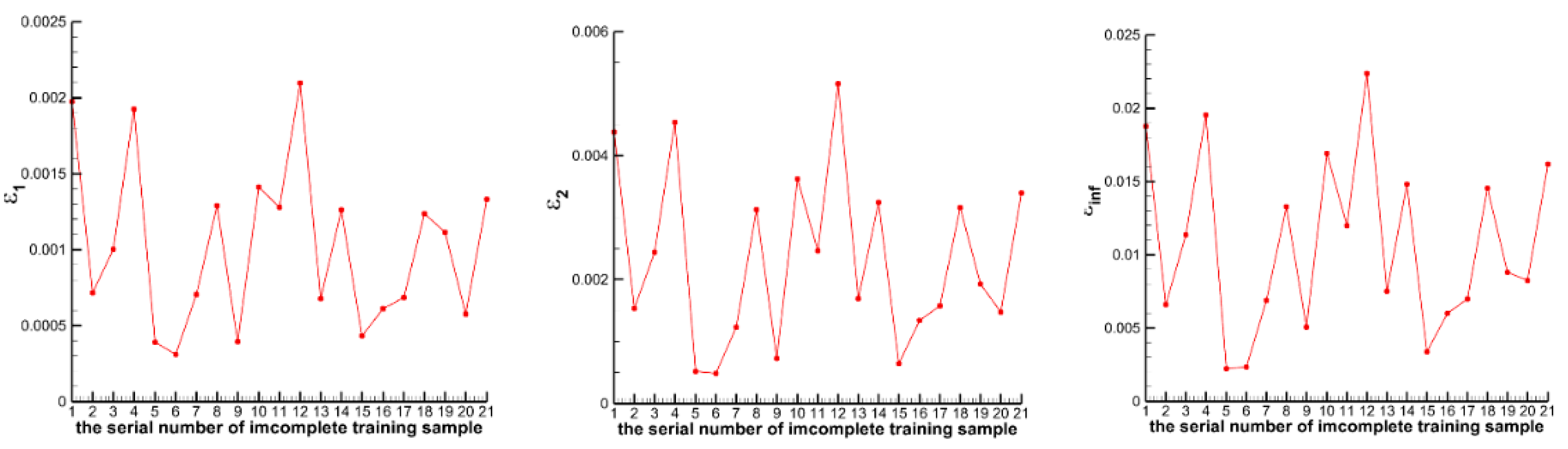
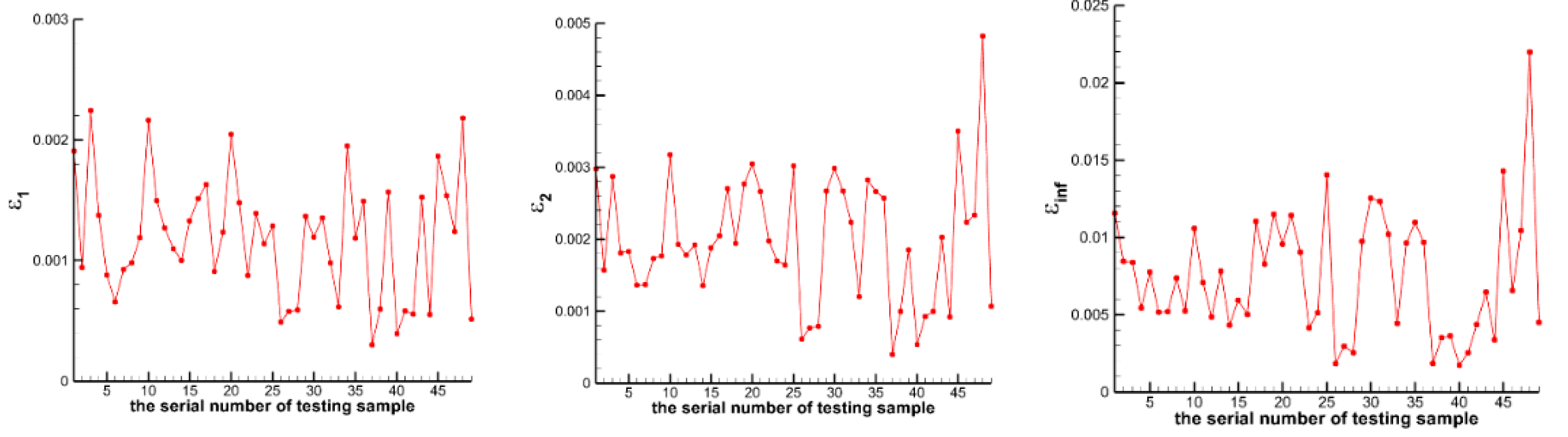
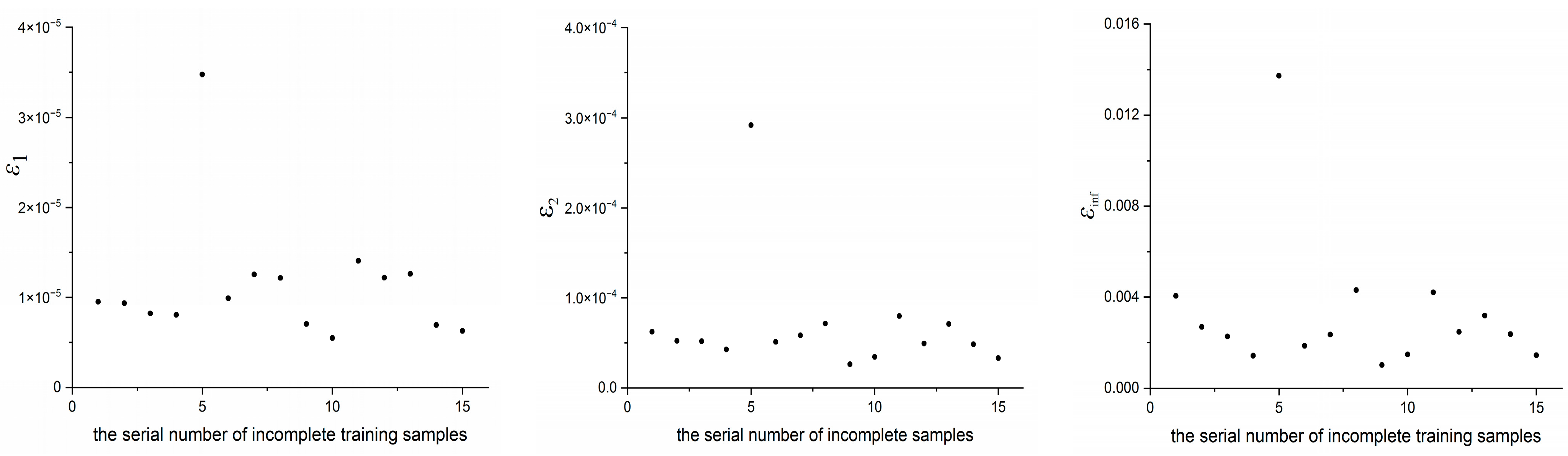
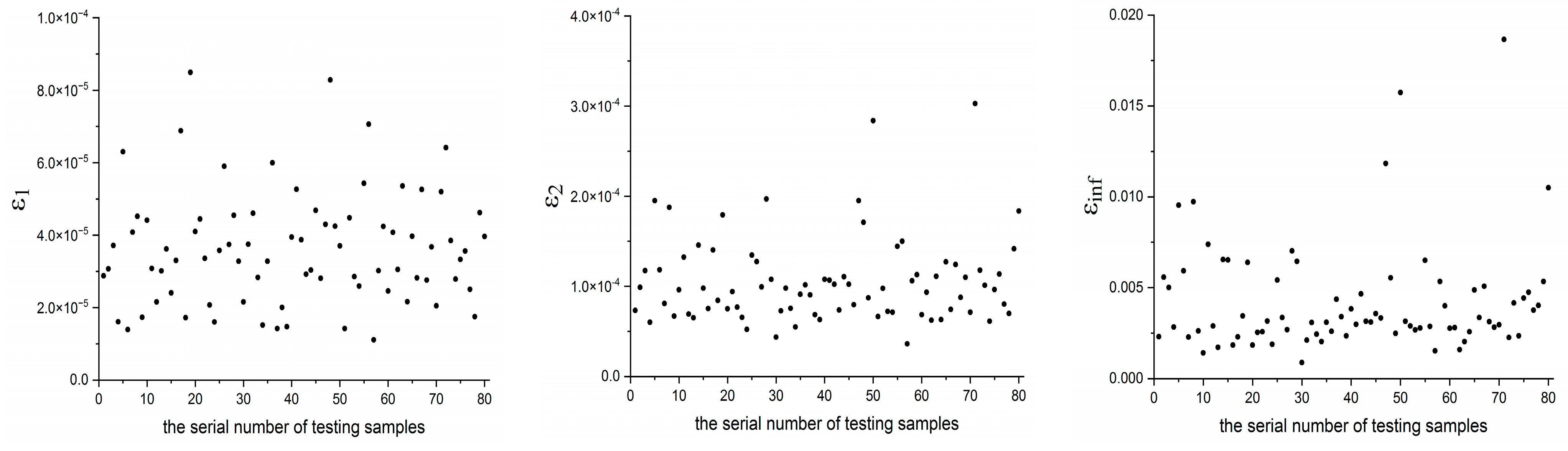
- For the M complete samples, their corresponding high- and low-fidelity outputs are obtained through CFD calculations. For the ntrain m incomplete samples, only their corresponding low-fidelity outputs are obtained through CFD calculations, while their high-fidelity outputs are considered unknown.Of course, we also obtain the high-fidelity outputs of ntrain m incomplete samples through CFD calculations. However, these data are not used for model training but only for testing the prediction ability of the Gappy POD method described below.
- (4)
- (5)
- (6)
- Based on the ntrain training samples, a Kriging model [18,19] is constructed between the input parameters and the basis function coefficients. Since the orthogonal basis functions obtained through POD are mutually orthogonal, an individual model can be constructed for each basis function coefficient. When given new input parameters, the corresponding basis function coefficients can be predicted based on the models, and the complete flow field response can be reconstructed using the bidirectional expression of POD.
2.2. Model Testing Process
2.3. Exchange Algorithm
2.4. POD
2.5. Gappy POD
2.6. Kriging Model
3. Case Description
3.1. Low-Speed Flow around an NACA0012 Airfoil
3.2. Transonic Flow around an M6 Wing
4. Results and Discussion
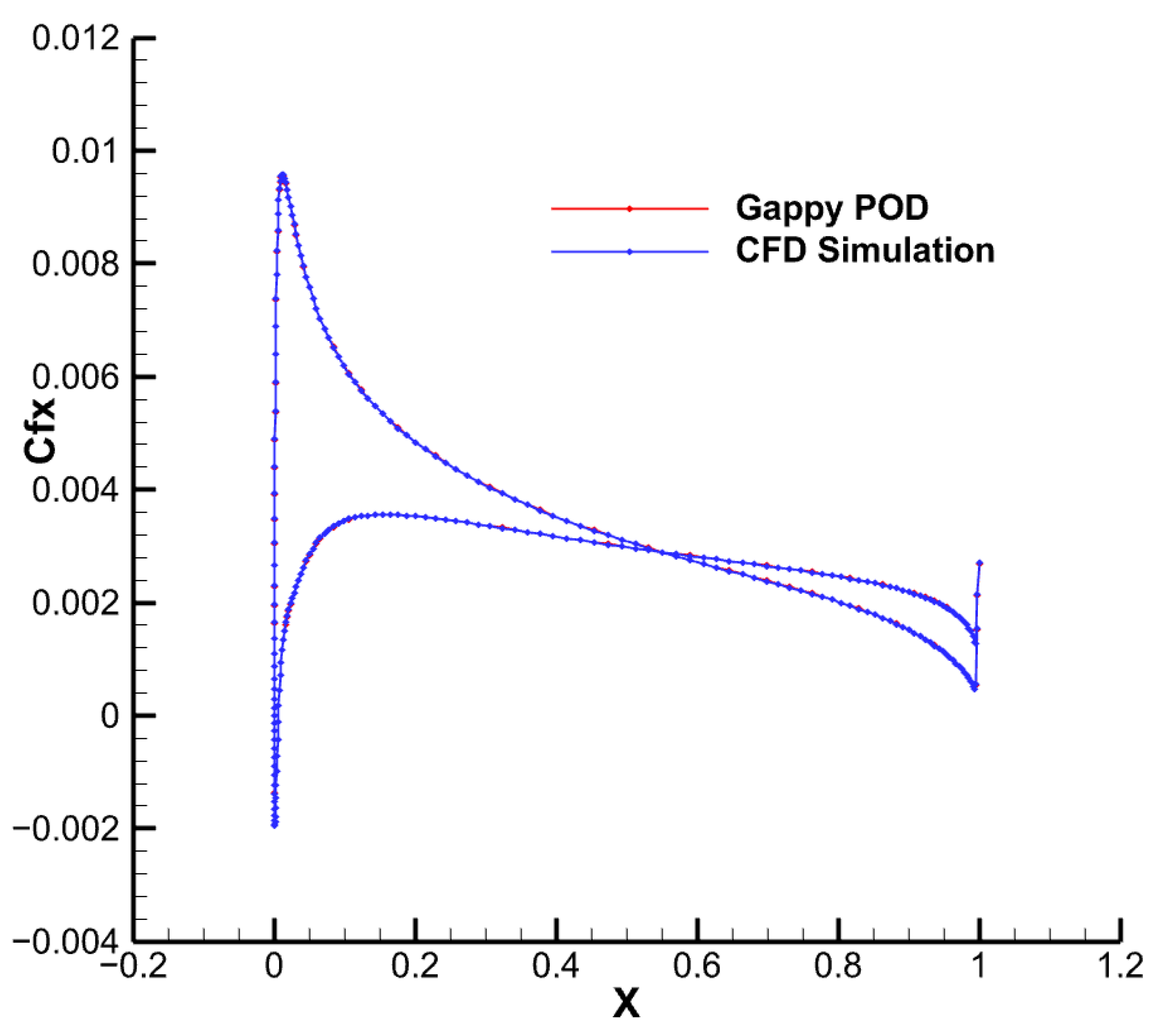
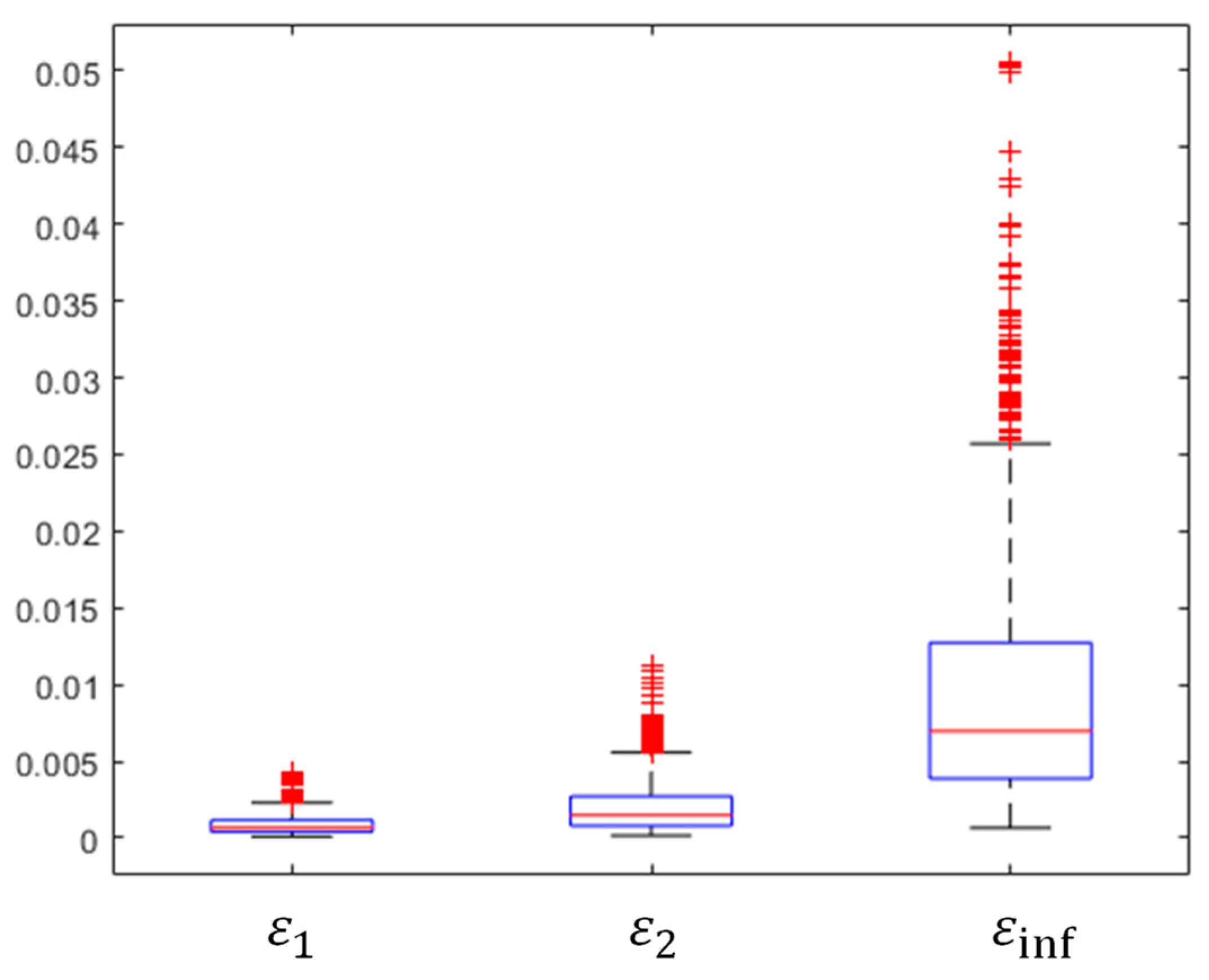
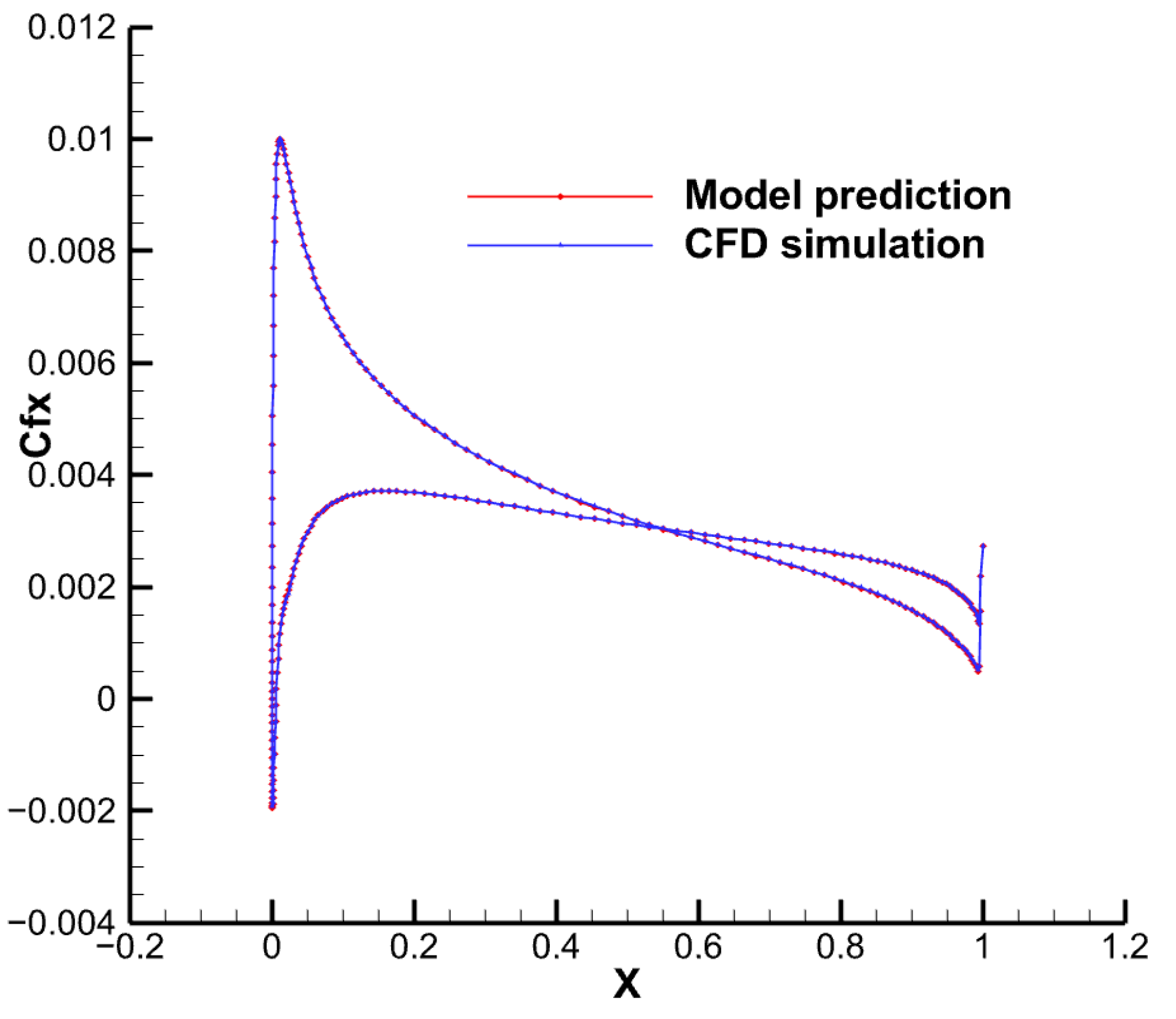
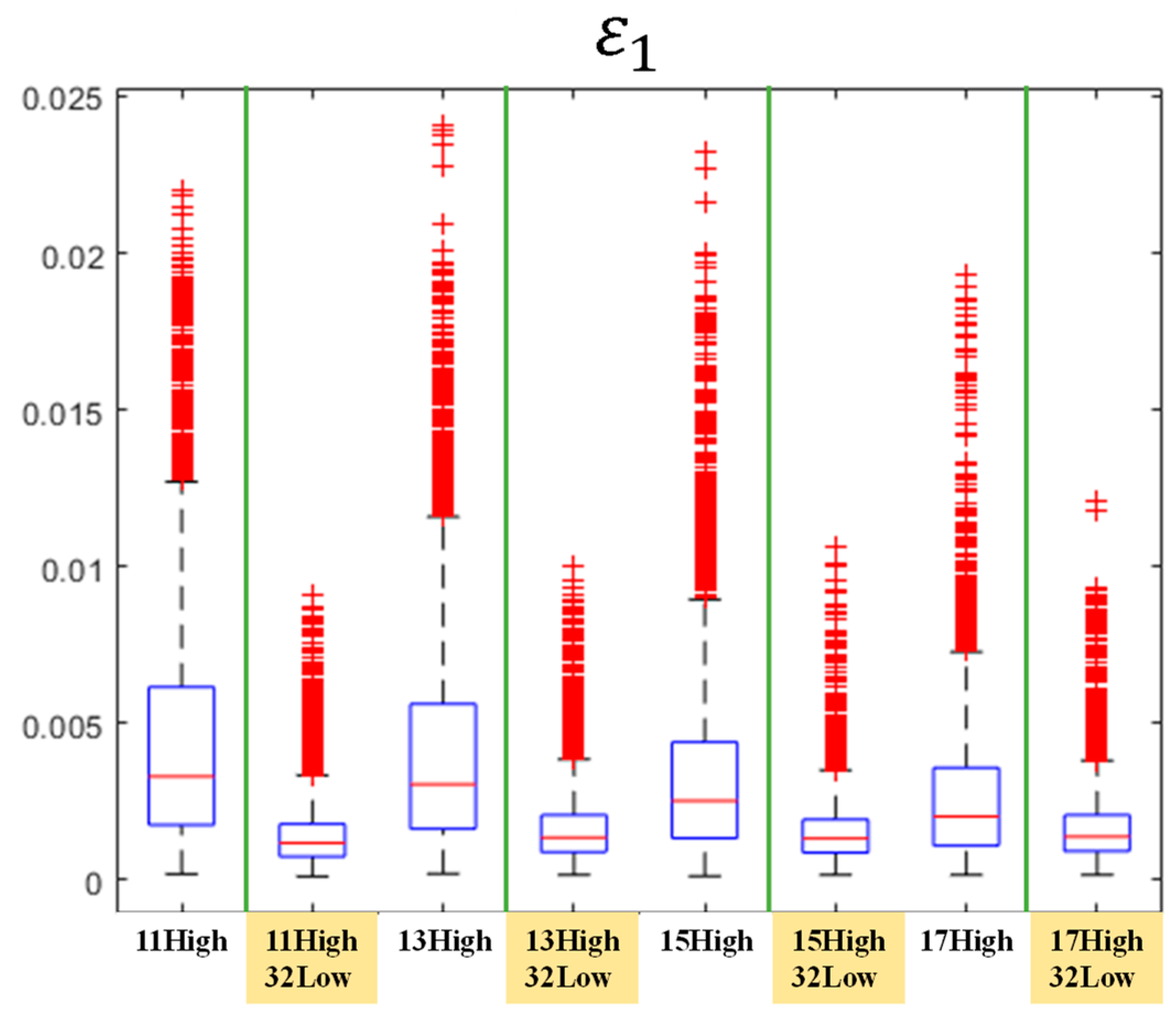
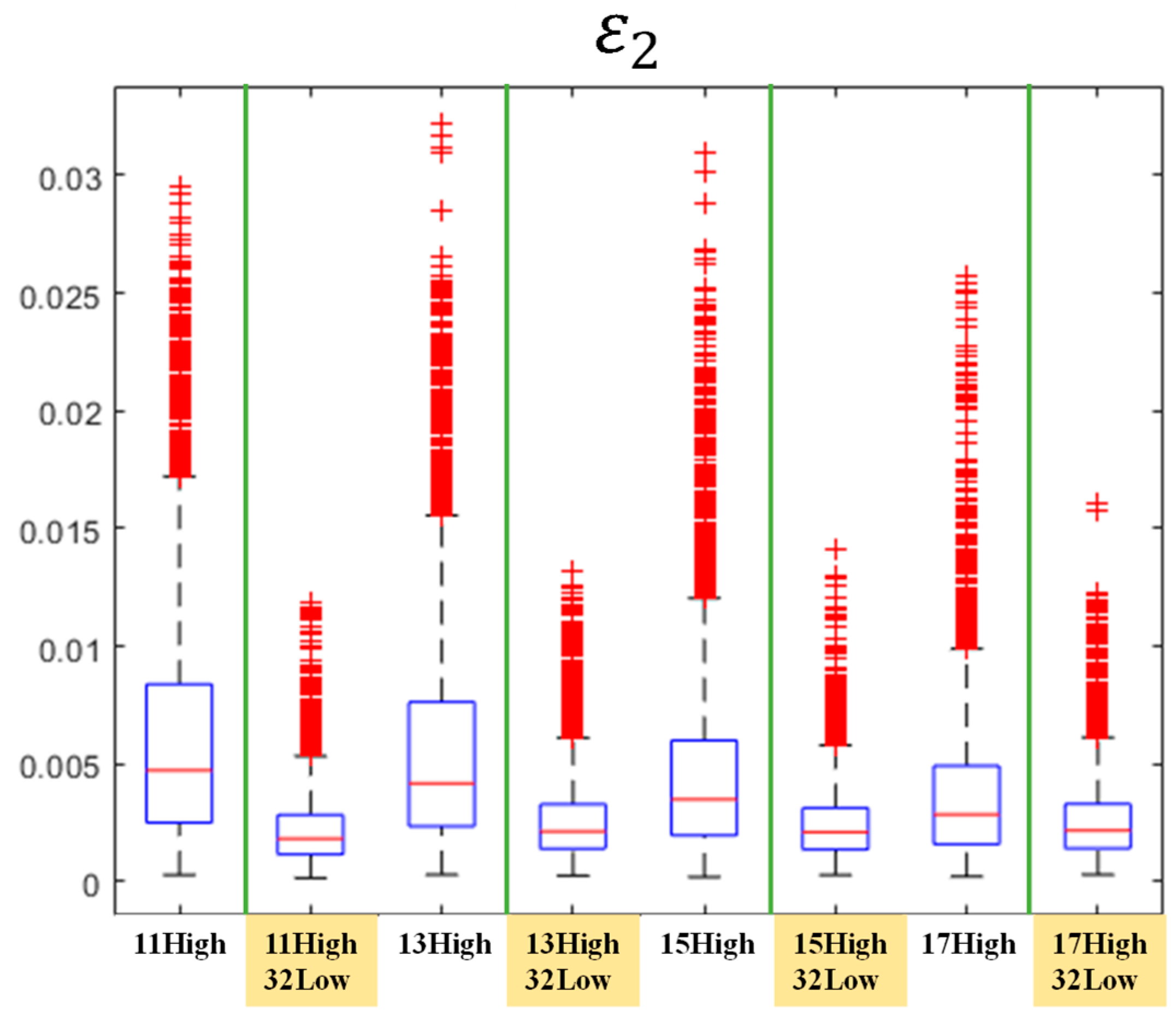
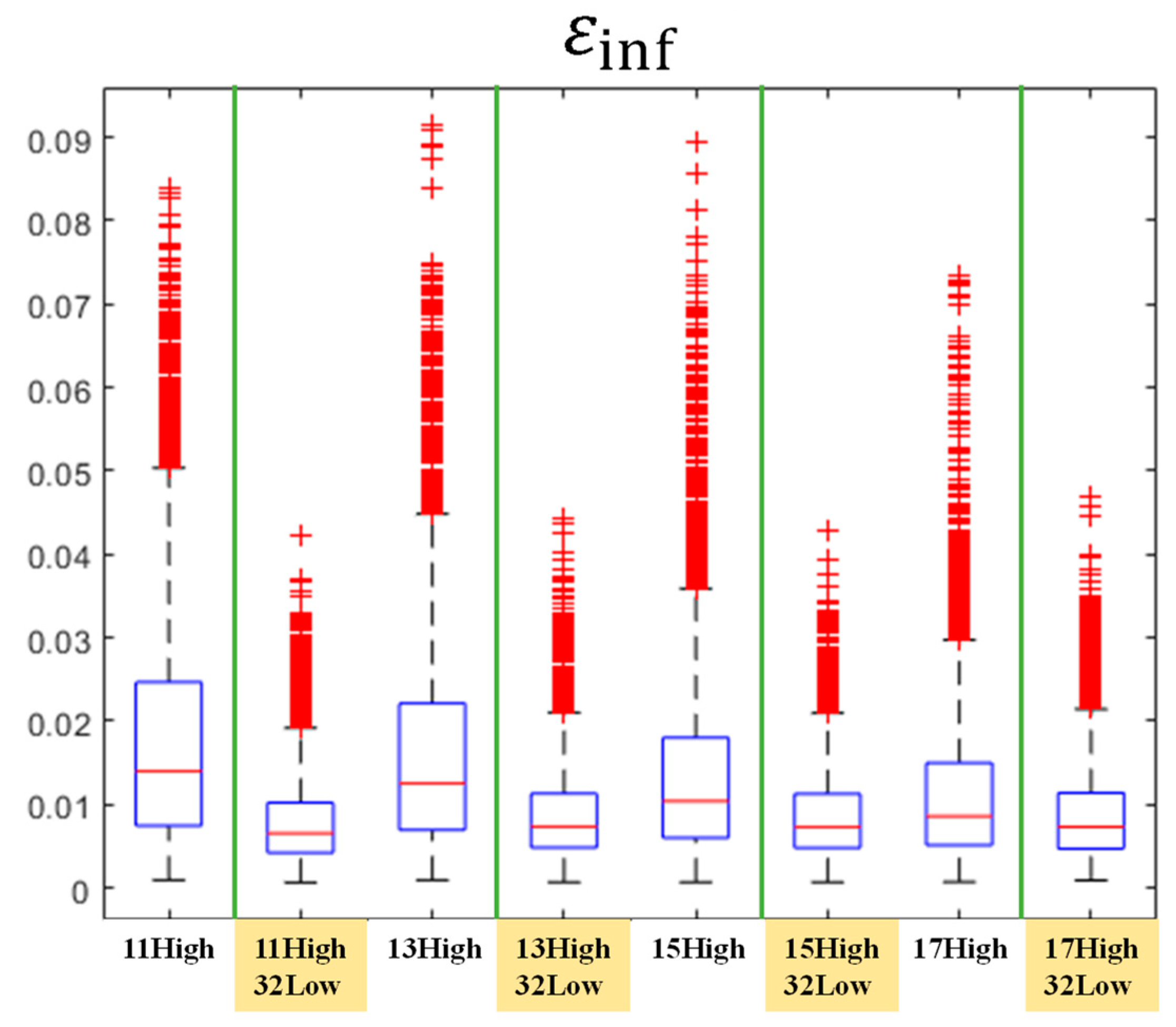
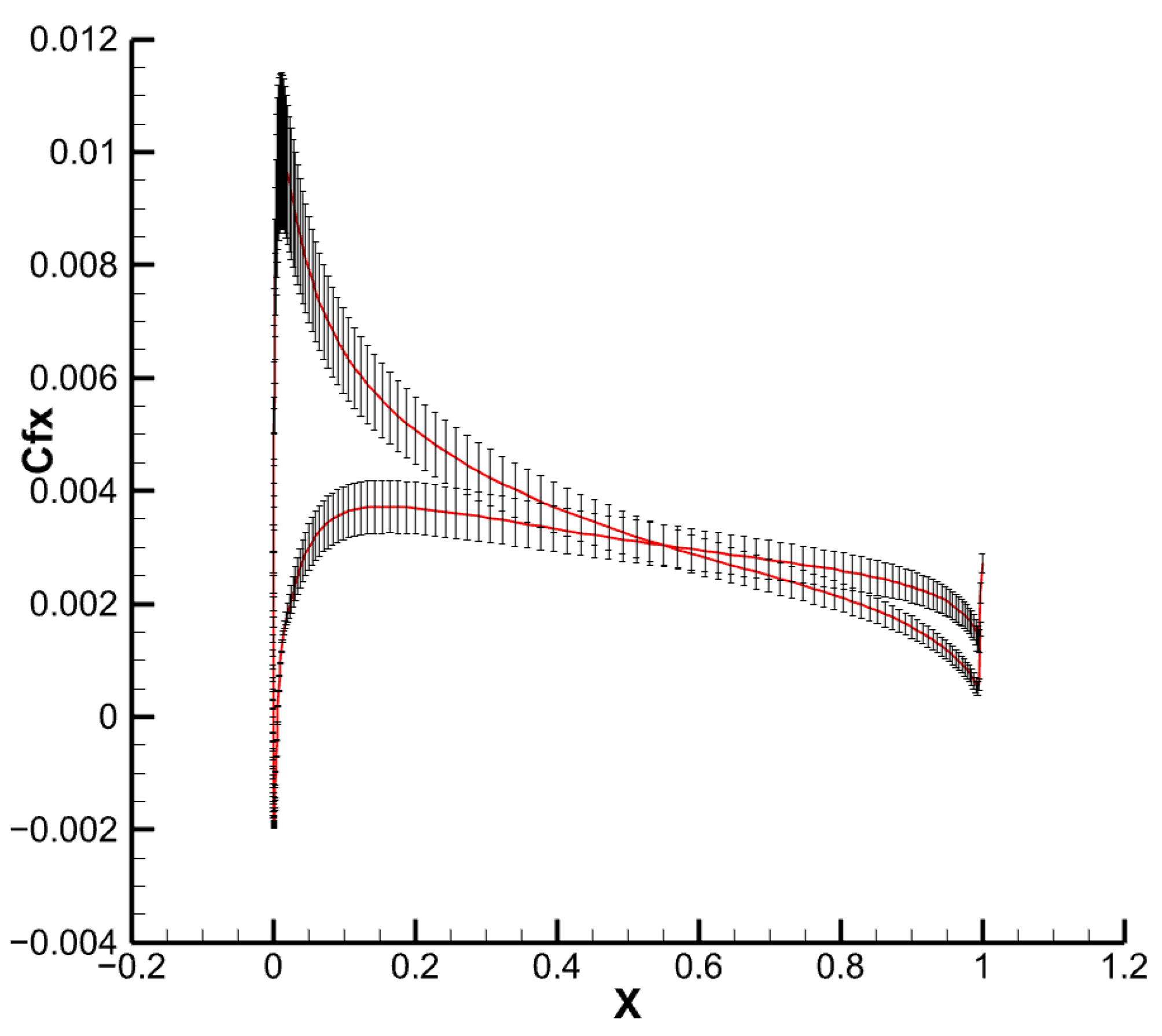
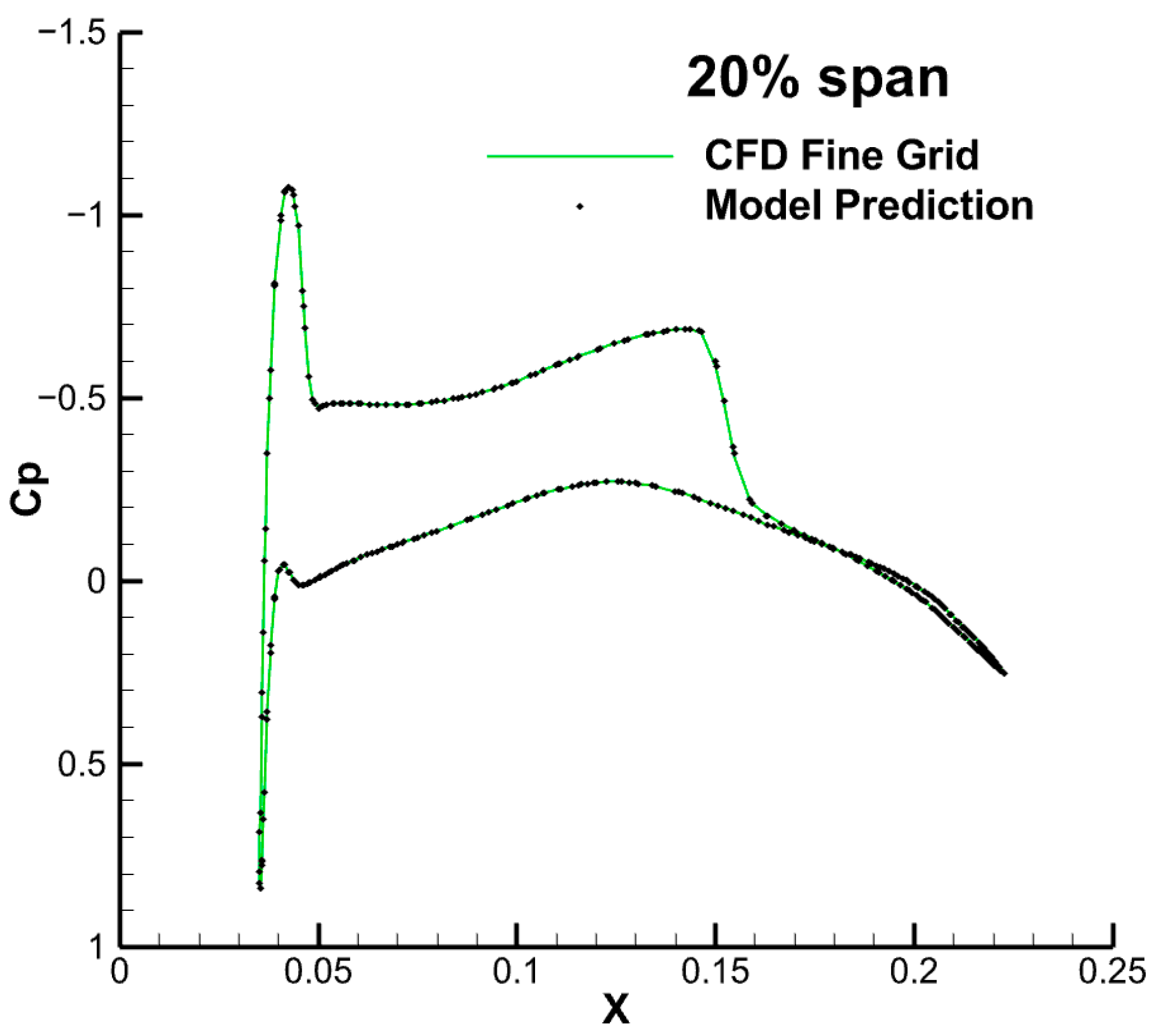
4.1. Low-Speed Flow around an NACA0012 Airfoil
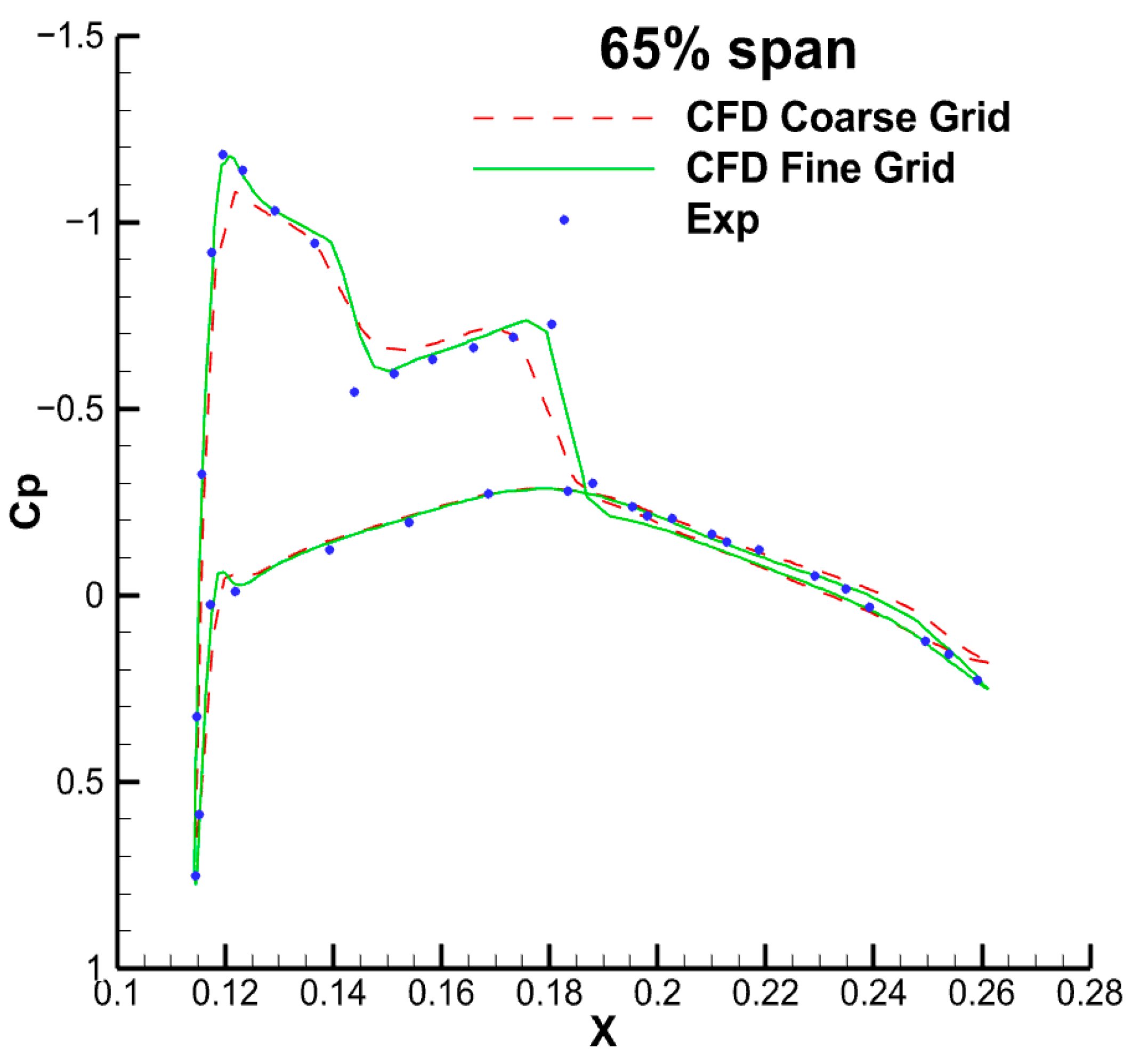
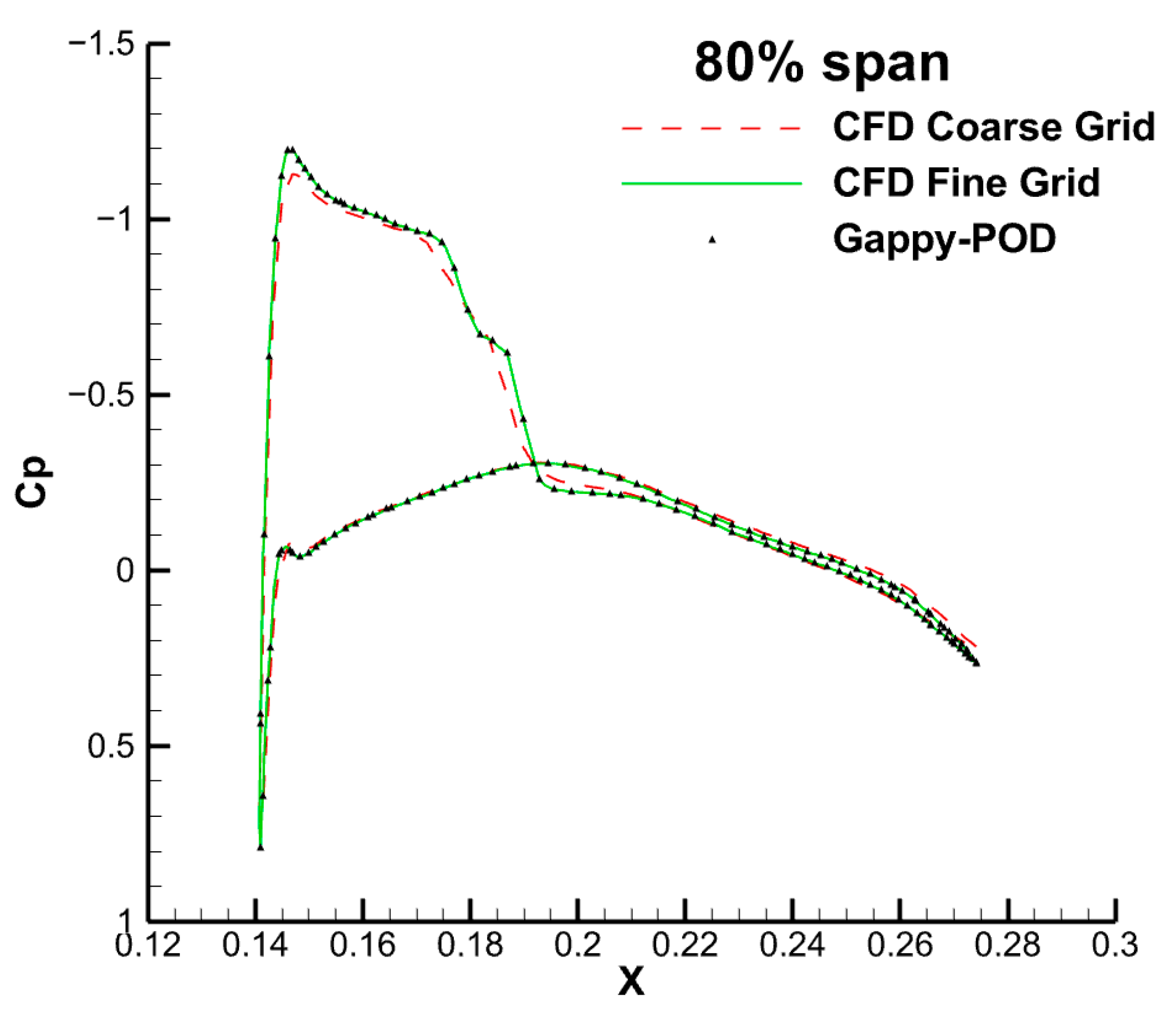
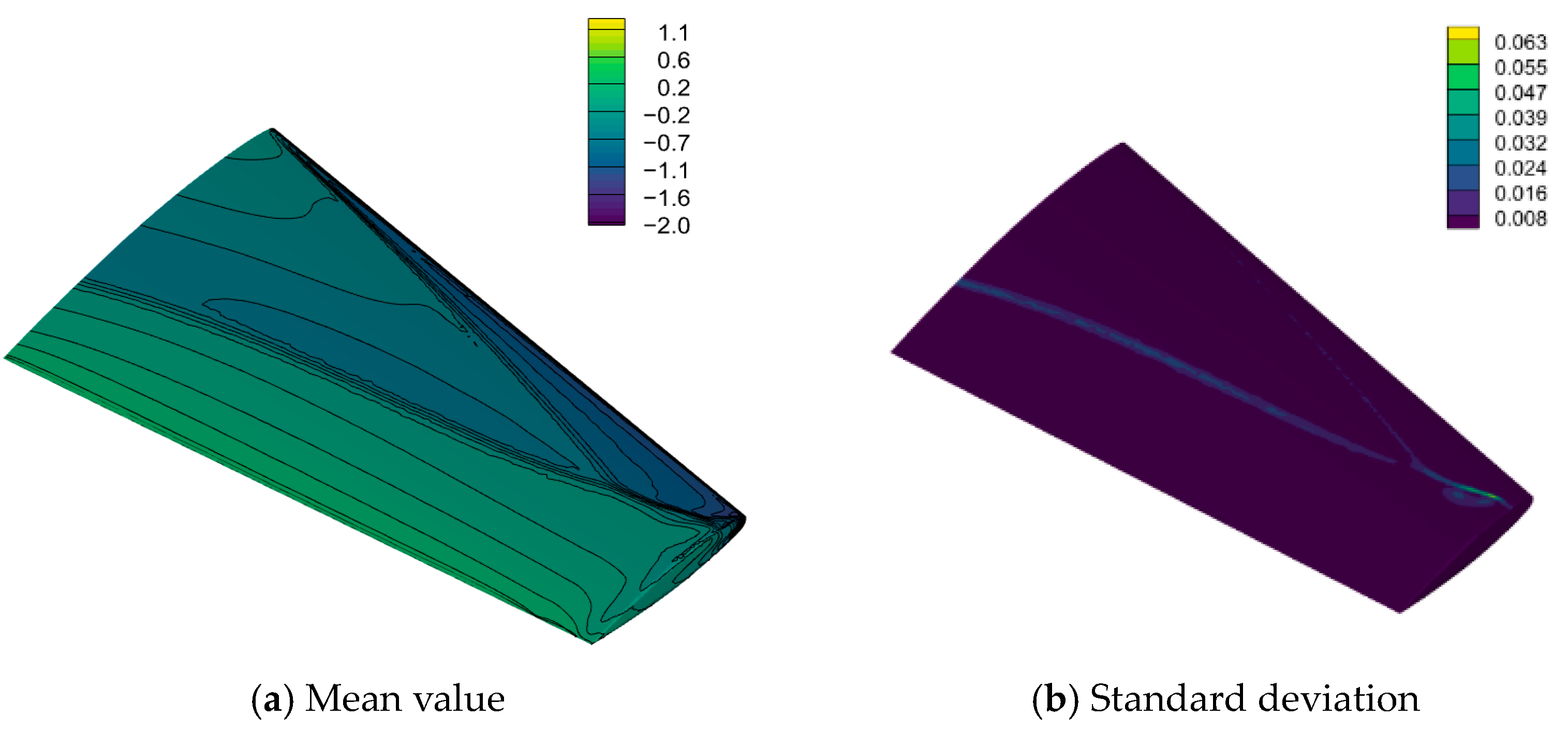
4.2. Transonic Flow around an M6 Wing
5. Conclusions
- (1)
- The Gappy POD-based method for supplementing missing data in flow fields enables the restoration of high-fidelity outputs from a limited amount of complete sample data, utilizing the low-fidelity outputs of incomplete samples. This approach effectively avoids the need for computationally expensive high-fidelity CFD calculations on a large number of samples, significantly reducing computational costs.
- (2)
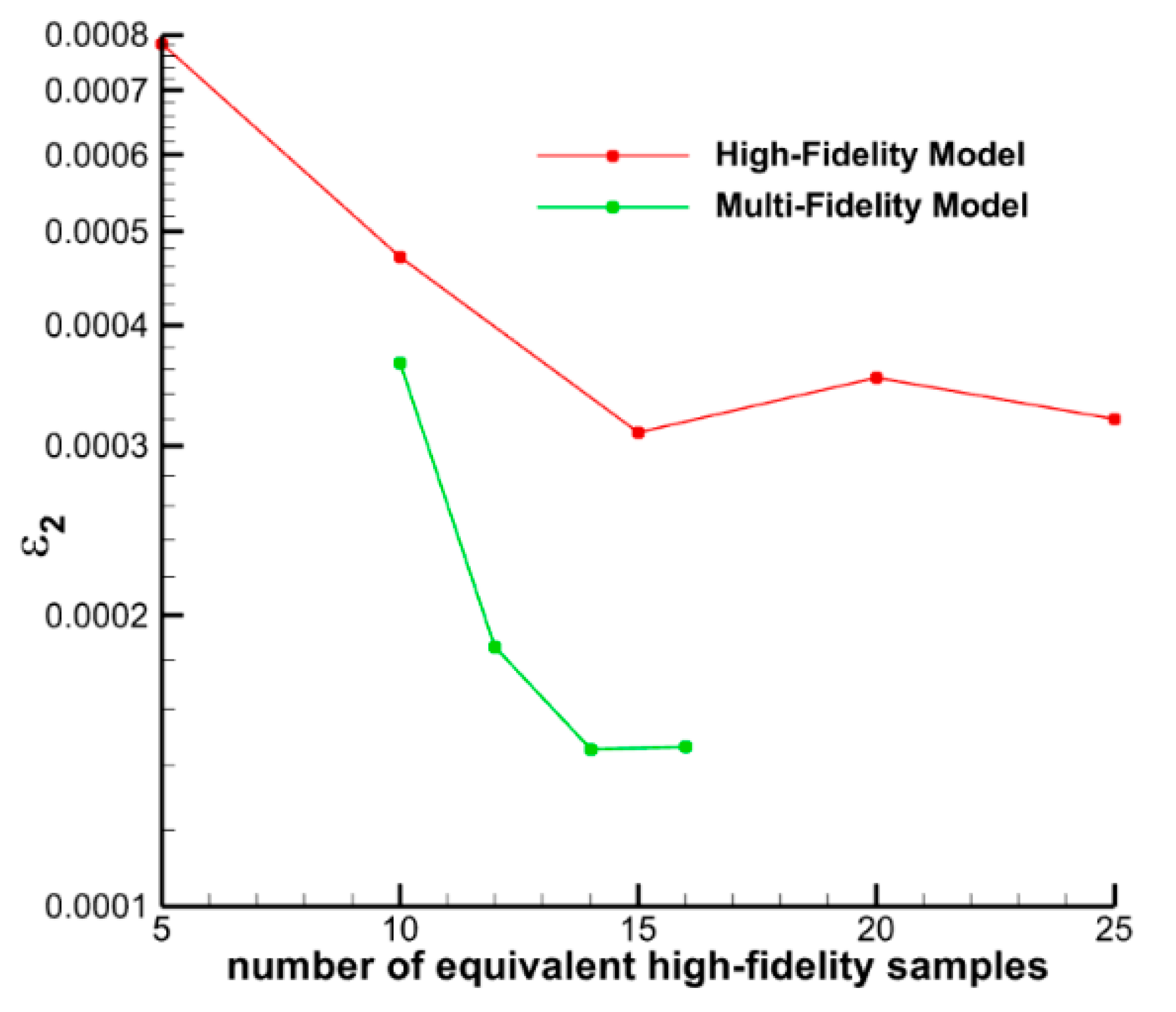
- The multi-fidelity modeling approach demonstrates a marked improvement in prediction accuracy and model stability compared to single-fidelity methods while incurring approximately the same computational cost for sample processing. This methodology offers an efficient and robust prediction model for large-scale random sampling.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mehta, U.B.; Eklund, D.R.; Romero, V.J.; Pearce, J.A.; Keim, N.S. Simulation Credibility, Advances in Verification, Validation, and Uncertainty Quantification; NASA/TP-2016-219422; NASA Ames Research Center: Moffett Field, CA, USA, 2016.
- Xiu, D.; Karniadakis, G. The Wiener-Askey Polynomial Chaos for Stochastic Differential Equations. SIAM J. Sci. Comput. 2002, 24, 619–644. [Google Scholar] [CrossRef]
- Li, M.; Wang, Z. Surrogate Model Uncertainty Quantification for Reliability-based Design Optimization. Reliab. Eng. Syst. Saf. 2019, 192, 106432. [Google Scholar] [CrossRef]
- Bhattacharyya, B. Uncertainty quantification of dynamical systems by a POD–Kriging surrogate model. J. Comput. Sci. 2022, 60, 101602. [Google Scholar] [CrossRef]
- Li, X.; Zou, Z.-J.; Wang, Z.-H.; Zou, L.; Gao, H. Surrogate model based uncertainty quantification of CFD simulations of the viscous flow around a ship advancing in shallow water. Ocean. Eng. 2021, 234, 109206. [Google Scholar]
- Tripathy, R.K.; Bilionis, I. Deep UQ: Learning deep neural network surrogate models for high dimensional uncertainty quantification. J. Comput. Phys. 2018, 375, 565–588. [Google Scholar] [CrossRef]
- Kennedy, M.C.; O’Hagan, A. Predicting the Output from a Complex Computer Code When Fast Approximations Are Available. Biometrika 2000, 87, 1–13. [Google Scholar] [CrossRef]
- Forrester, A.I.J.; Sóbester, A.; Keane, A.J. Multi-fidelity optimization via surrogate modelling. Proc. R. Soc. A 2007, 463, 3251–3269. [Google Scholar] [CrossRef]
- Zimmermann, R.; Han, Z.H. Simplified cross-correlation estimation for multifidelity surrogate cokriging models. Adv. Appl. Math. Sci. 2010, 7, 181–202. [Google Scholar]
- Meng, X.; Karniadakis, G.E. A composite neural network that learns from multi-fidelity data: Application to function approximation and inverse PDE problems. J. Comput. Phys. 2019, 401, 109020. [Google Scholar] [CrossRef]
- Motamed, M. A multi-fidelity neural network surrogate sampling method for uncertainty quantification. J. Comput. Phys. 2021, 426, 109923. [Google Scholar] [CrossRef]
- Cook, R.D.; Nachtsheim, C.J. A comparison of algorithms for constructing exact D-optimal designs. Technometrics 1980, 22, 315–324. [Google Scholar] [CrossRef]
- Morris, M.D.; Mitchell, T.J. Exploratory designs for computer experiments. J. Stat. Plan. Inference 1995, 43, 381–402. [Google Scholar] [CrossRef]
- Everson, R.; Sirovich, L. Karhunen-Loeve procedure for gappy data. J. Opt. Soc. Am. A 1995, 12, 1657–1664. [Google Scholar] [CrossRef]
- Benamara, T.; Breitkopf, P.; Lepot, I.; Sainvitu, C. Adaptive infill sampling criterion for multi-fidelity optimization based on Gappy-POD Application to the flight domain study of a transonic airfoil. Struct. Multidiscip. Optim. 2016, 54, 843–855. [Google Scholar] [CrossRef]
- Lumley, J.L. The Structure of Inhomogeneous Turbulent Flows. Commun. Pure Appl. Math. 1967, 20, 453–488. [Google Scholar] [CrossRef]
- Sirovich, L.; Kirby, M. Low-dimensional procedure for the characterization of human faces. J. Opt. Soc. Am. A 1987, 4, 519–524. [Google Scholar] [CrossRef] [PubMed]
- Krige, D.G. A statistical approach to some basic mine valuation problems on the Witwatersrand. J. Chem. Metall. Min. Eng. Soc. S. Afr. 1951, 52, 119–139. [Google Scholar]
- Sacks, J.; Welch, W.J.; Mitchell, T.J.; Wynn, H.P. Design and analysis of computer experiments. Stat. Sci. 1989, 4, 409–423. [Google Scholar] [CrossRef]
- Spalart, P.R.; Allmaras, S.R. A One-Equation Turbulence Model for Aerodynamic Flows. AIAA J. 1992, 30, 5–12. [Google Scholar] [CrossRef]
- Schaefer, J.; Cary, A.; Mani, M.; Spalart, P. Uncertainty Quantification and Sensitivity Analysis of SA Turbulence Model Coefficients in Two and Three Dimensions. In Proceedings of the 55th AIAA Aerospace Sciences Meeting, Grapevine, TX, USA, 9–13 January 2017. AIAA Paper 2017-1710. [Google Scholar]
- Stephanopoulos, K.; Witte, I.; Wray, T.J.; Agarwal, R.K. Uncertainty Quantification of Turbulence Model Coefficients in OpenFOAM and Fluent for Mildly Separated Flows. In Proceedings of the 46th AIAA Fluid Dynamics Conference, Washington, DC, USA, 13–17 June 2016. AIAA Paper 2016-4401. [Google Scholar]
- Chen, J.Q.; Wu, X.J.; Zhang, J.; Li, B.; Jia, H.Y.; Zhou, N.C. Flowstar: General Unstructured-grid CFD Software for National Numerical Wind Tunnel (NNW) Project. Acta Aeronaut. Astronaut. Sin. 2021, 42, 625739. (In Chinese) [Google Scholar]
- Diskin, B.; Thomas, J.L. Comparison of Node-Centered and Cell-Centered Unstructured Finite Volume Discretizations: Inviscid Fluxes. AIAA J. 2011, 49, 836–854. [Google Scholar] [CrossRef]
- Venkatakrishnan, V. On the Accuracy of Limiters and Convergence to Steady-State Solutions. In Proceedings of the 31st Aerospace Sciences Meeting, Reno, NV, USA, 11–14 January 1993. AIAA Paper 1993-0880. [Google Scholar]
- Gamboa, F.; Janon, A.; Klein, T.; Lagnoux, A. Sensitivity Analysis for Multidimensional and Functional Outputs. Electron. J. Stat. 2014, 8, 575–603. [Google Scholar] [CrossRef]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Minimum Value | Maximum Value | Standard Value | |
|---|---|---|---|
| cb1 | 0.12893 | 0.137 | 0.1355 |
| σ | 0.6 | 1.0 | 2/3 |
| cb2 | 0.60983 | 0.6875 | 0.622 |
| κ | 0.38 | 0.42 | 0.41 |
| cw2 | 0.055 | 0.3525 | 0.3 |
| cw3 | 1.75 | 2.5 | 2.0 |
| cv1 | 6.9 | 7.3 | 7.1 |
| ct3 | 1.0 | 2.0 | 1.2 |
| ct4 | 0.3 | 0.7 | 0.5 |
| Main Effect | Total Effect | |
|---|---|---|
| cb1 | 0.0061 | 0.0073 |
| σ | 0.1223 | 0.1270 |
| cb2 | 0.0001 | 0.0004 |
| κ | 0.7945 | 0.7991 |
| cw2 | 0.0482 | 0.0504 |
| cw3 | 0.0001 | 0.0001 |
| cv1 | 0.0200 | 0.0210 |
| ct3 | 0.0001 | 0.0008 |
| ct4 | 0.0001 | 0.0004 |
| Main Effect | Total Effect | |
|---|---|---|
| cb1 | 0.0625 | 0.0674 |
| σ | 0.2375 | 0.2550 |
| cb2 | 0.0050 | 0.0050 |
| κ | 0.6079 | 0.6184 |
| cw2 | 0.0338 | 0.0382 |
| cw3 | 0.0016 | 0.0017 |
| cv1 | 0.0340 | 0.0368 |
| ct3 | 0.0035 | 0.0040 |
| ct4 | 0.0012 | 0.0012 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Zhao, J.; Xiao, W.; Lv, L.; Zhao, W.; Wu, X. A Multi-Fidelity Uncertainty Propagation Model for Multi-Dimensional Correlated Flow Field Responses. Aerospace 2024, 11, 263. https://doi.org/10.3390/aerospace11040263
Chen J, Zhao J, Xiao W, Lv L, Zhao W, Wu X. A Multi-Fidelity Uncertainty Propagation Model for Multi-Dimensional Correlated Flow Field Responses. Aerospace. 2024; 11(4):263. https://doi.org/10.3390/aerospace11040263
Chicago/Turabian StyleChen, Jiangtao, Jiao Zhao, Wei Xiao, Luogeng Lv, Wei Zhao, and Xiaojun Wu. 2024. "A Multi-Fidelity Uncertainty Propagation Model for Multi-Dimensional Correlated Flow Field Responses" Aerospace 11, no. 4: 263. https://doi.org/10.3390/aerospace11040263