
In-Vehicle Speech Recognition for Voice-Driven UAV Control in a Collaborative Environment of MAV and UAV

Abstract
:1. Introduction
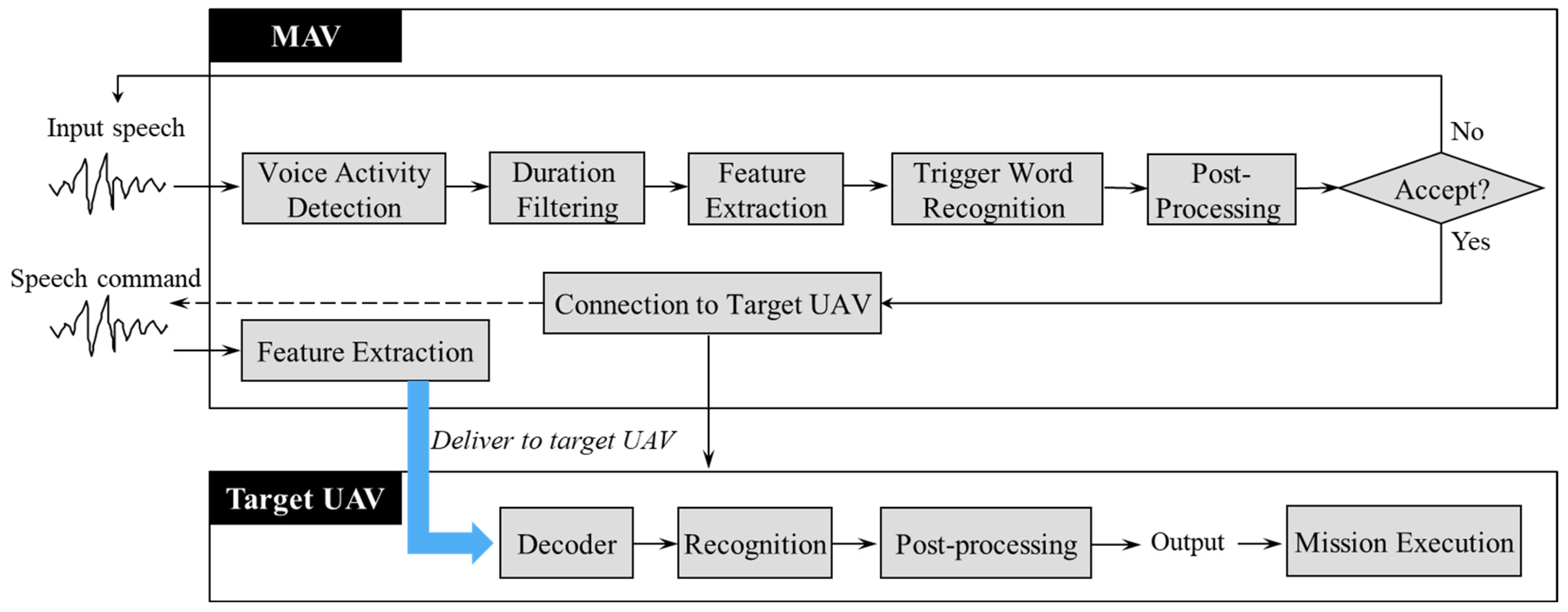
2. In-Vehicle Speech Recognition for Voice-Driven UAV Control in a Collaborative Environment of MAV and UAV
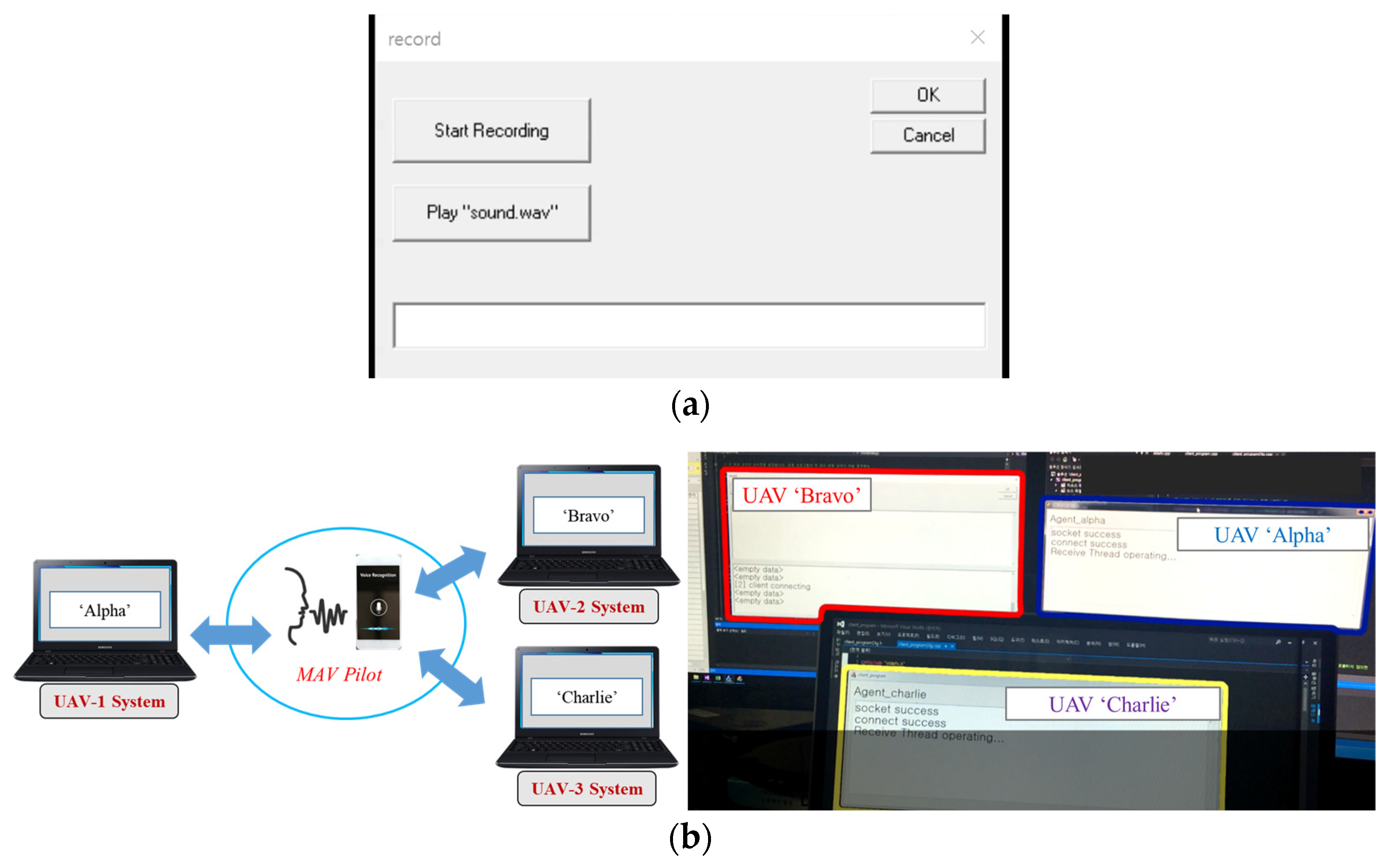
2.1. Front-End of Speech Recognition
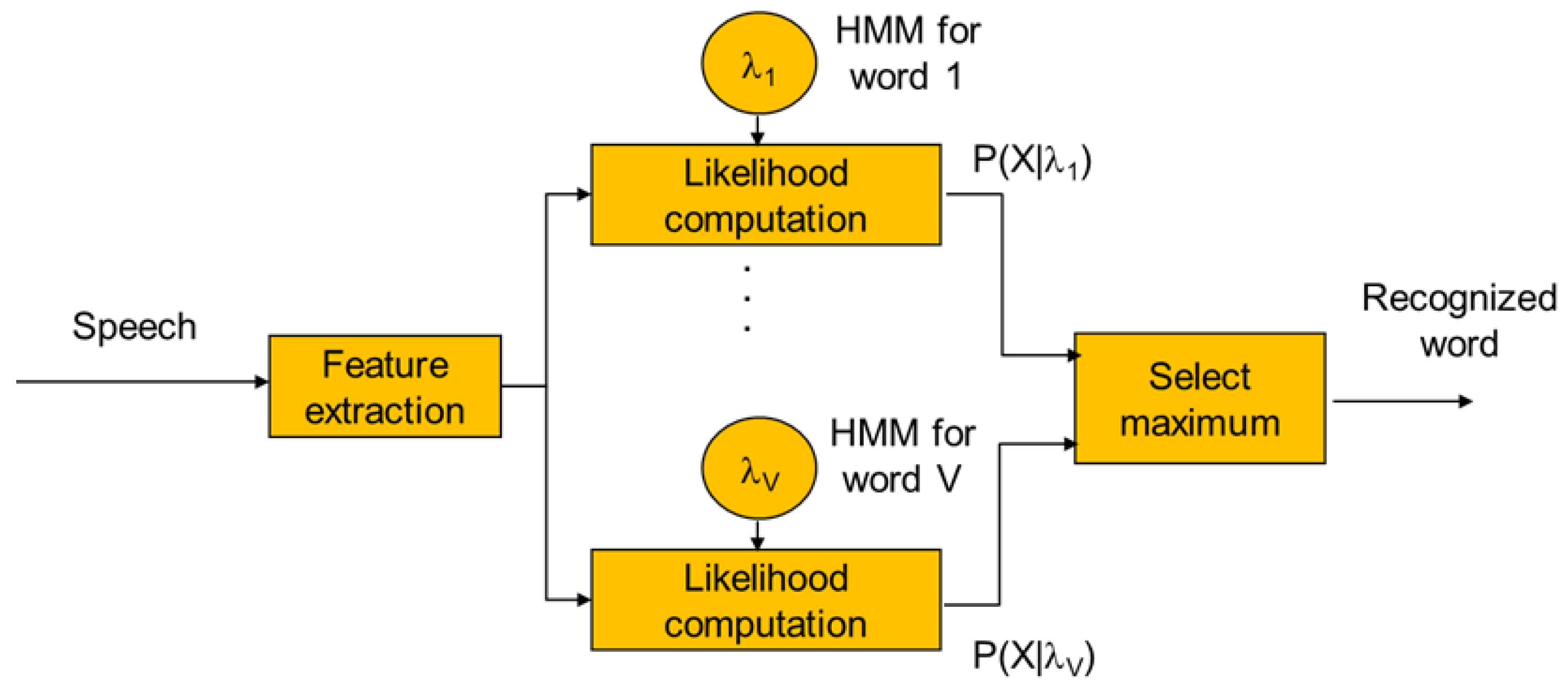
2.2. Model Construction for Speech Recognition
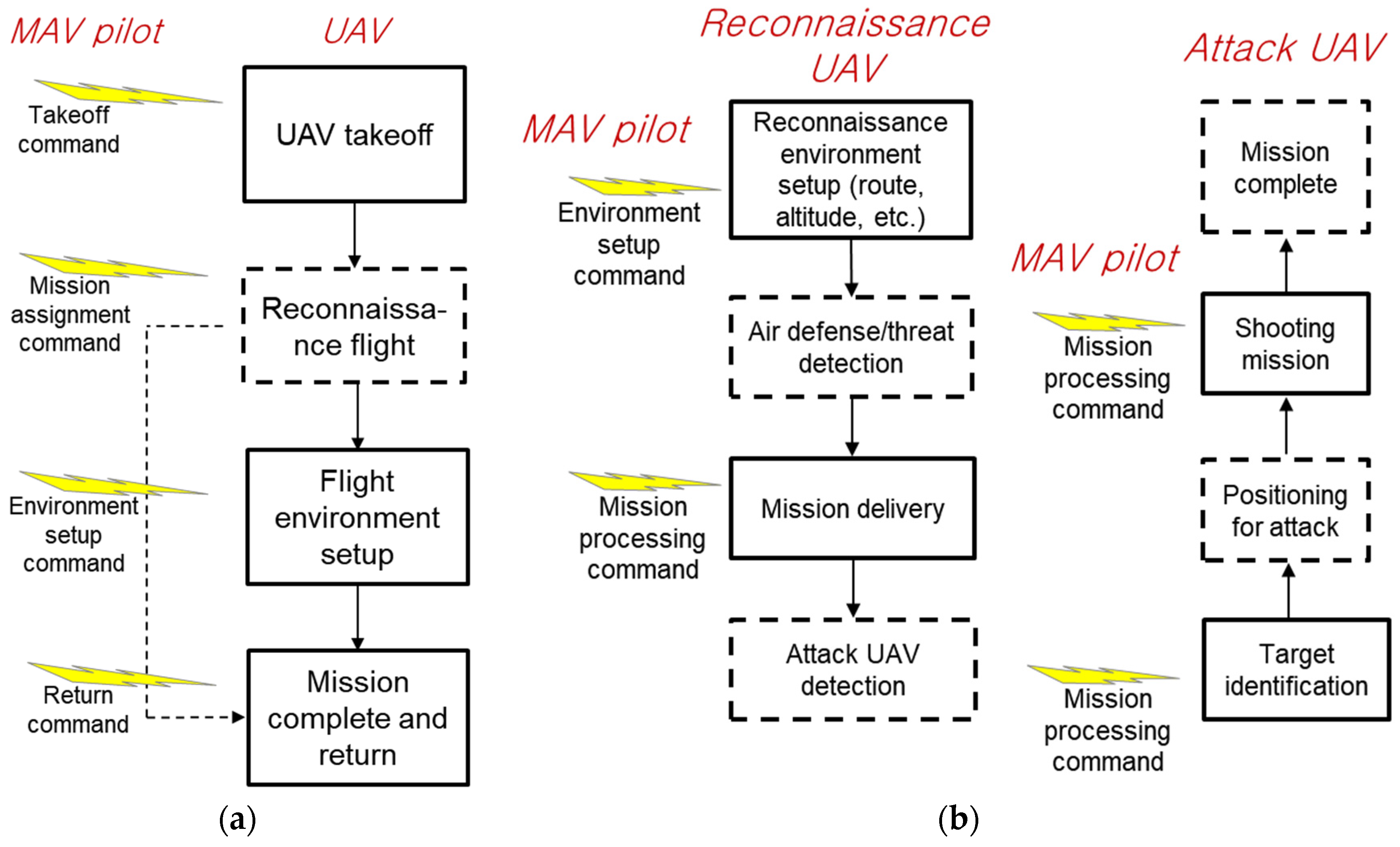
2.2.1. Definition of Voice Commands for Training Data Collection
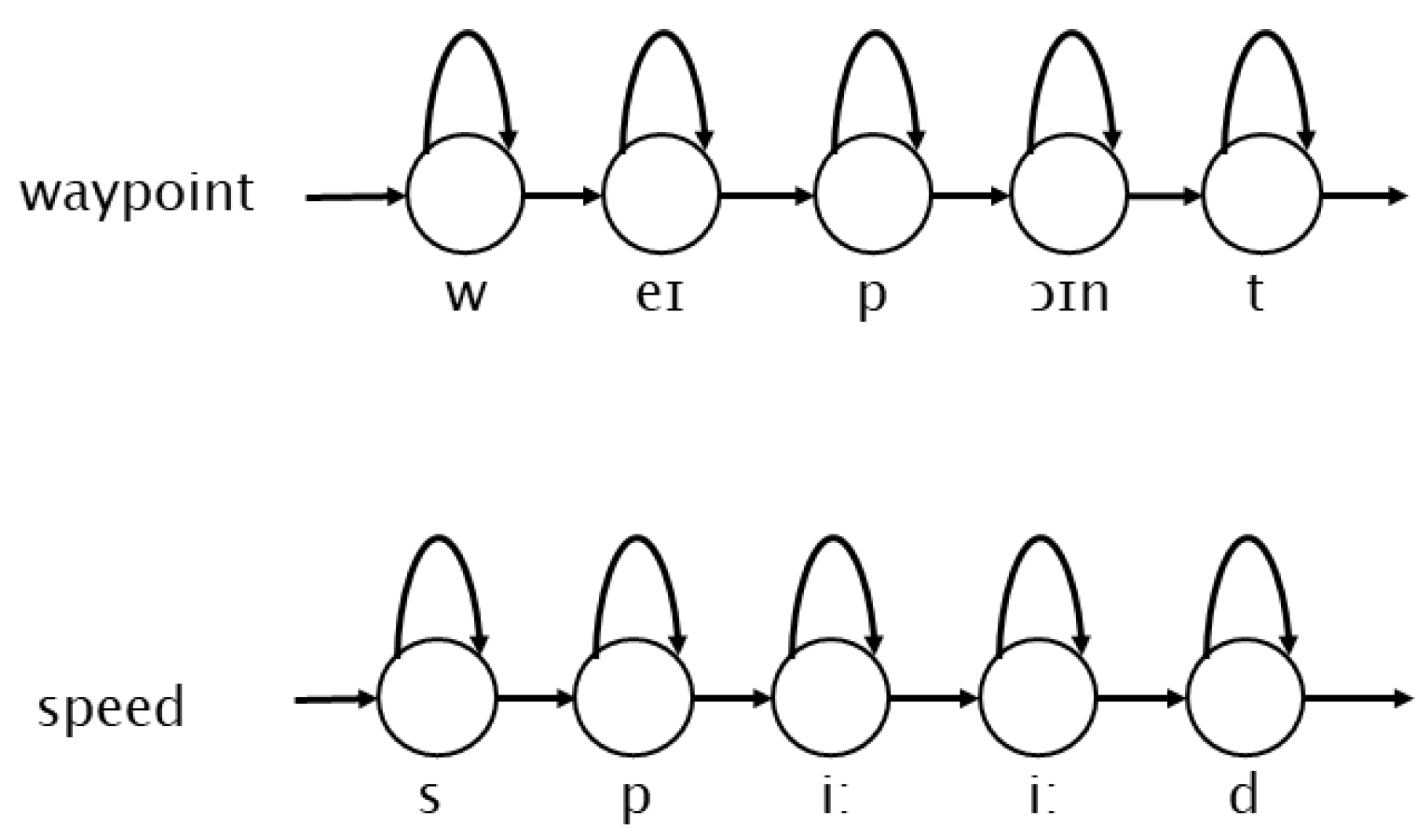
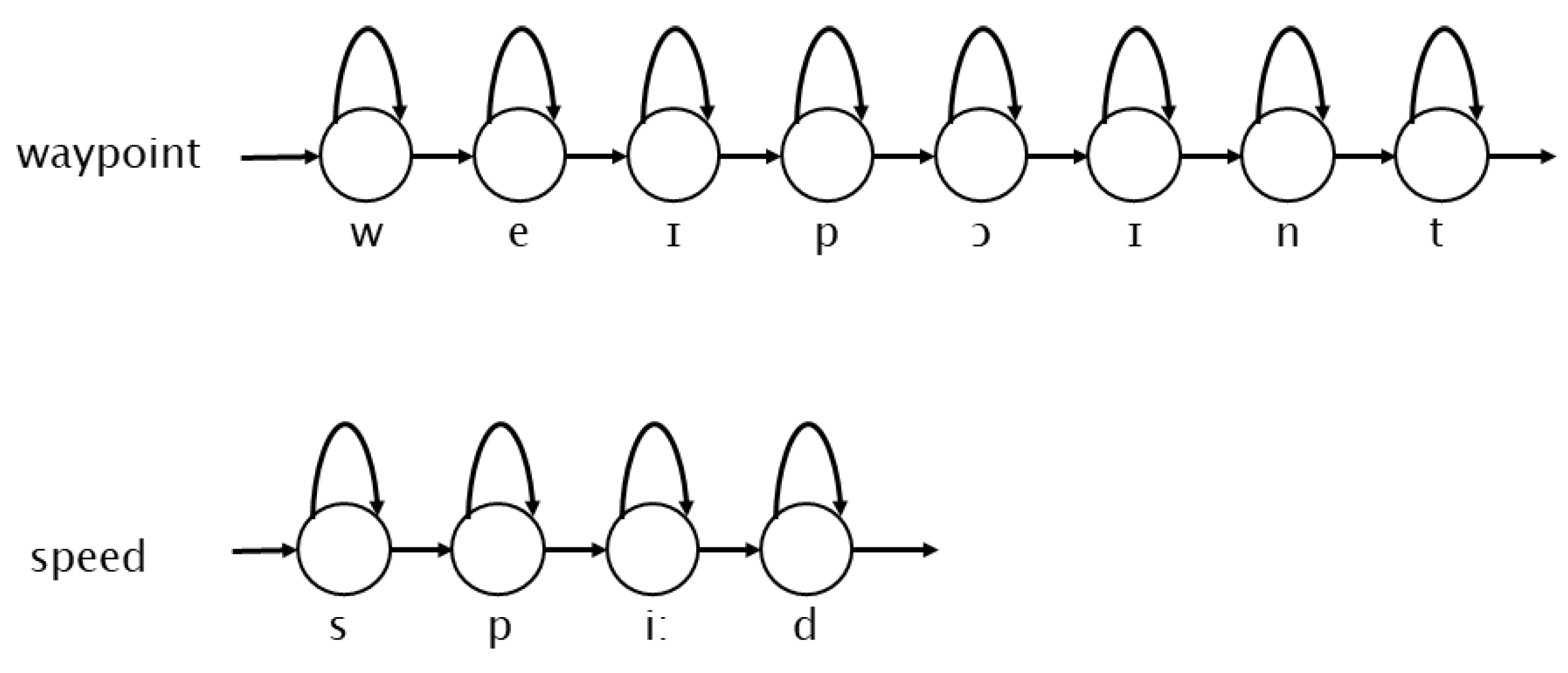
2.2.2. Acoustic Model Construction
2.3. Post-Processing with Syntax Analysis and Semantic Analysis
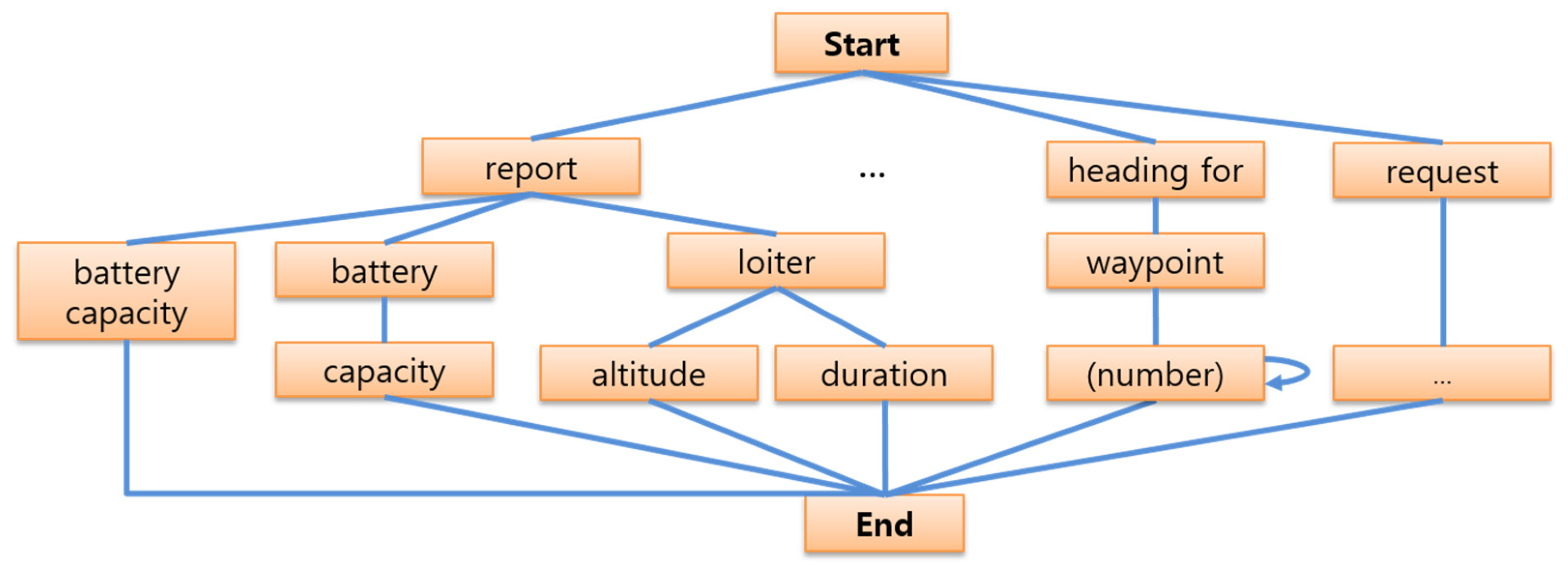
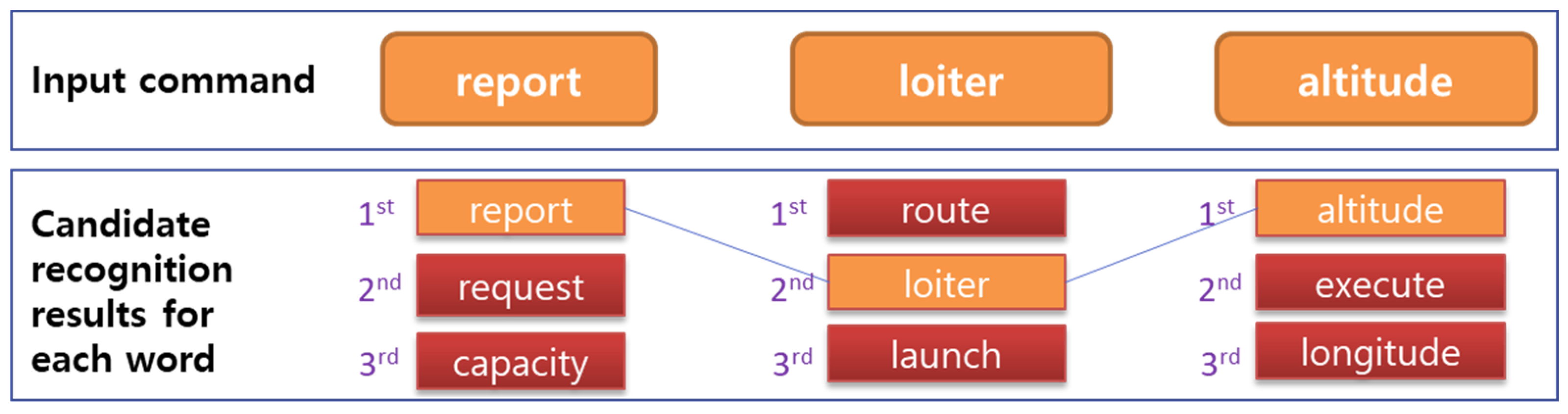
2.3.1. Syntax Analysis Based on the Grammar Network
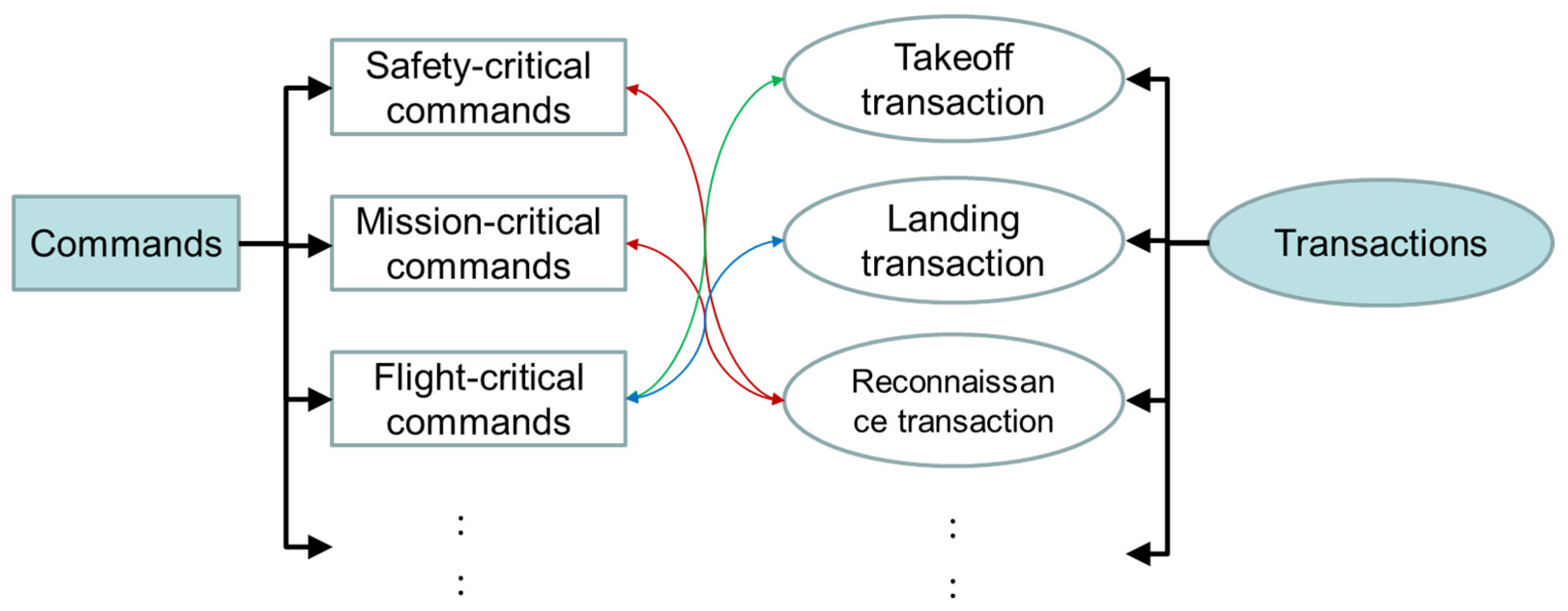
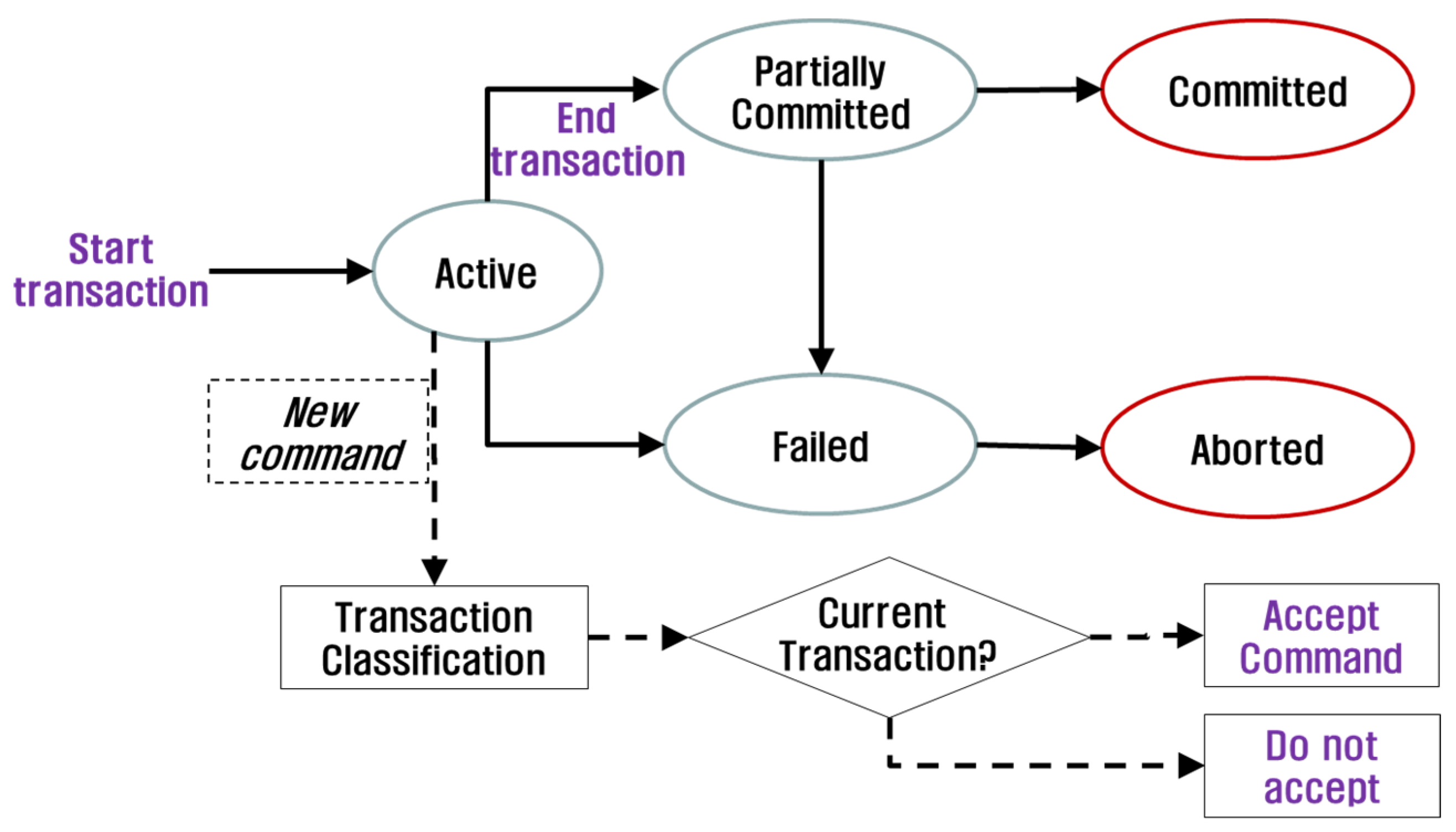
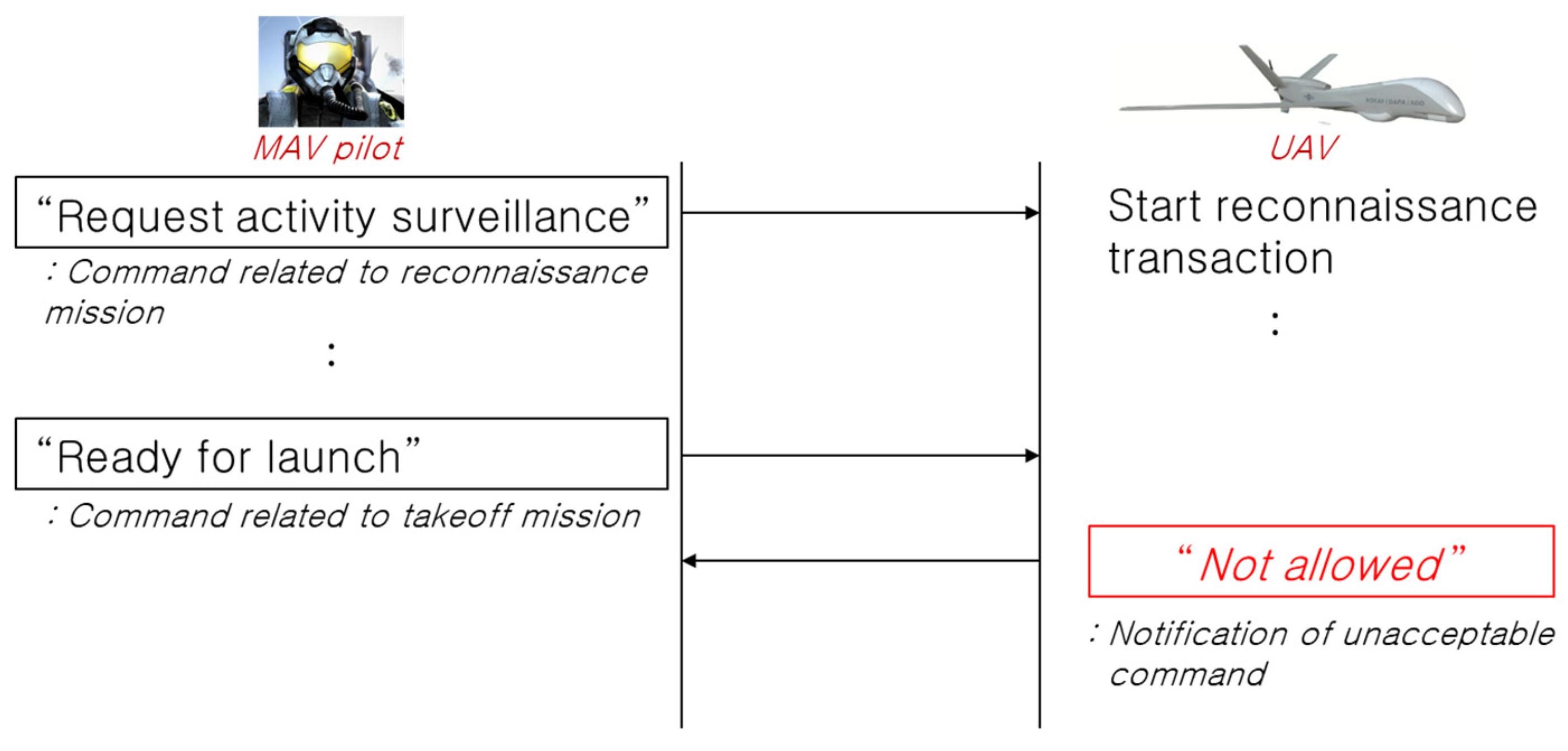
2.3.2. Semantic Analysis Based on Transaction Scheme
3. Evaluation
3.1. Validation of Speech Recognition for Mission Command Set in a Collaborative Environment of MAVs and UAVs
3.2. Verification of the Proposed Syntax Analysis Method for the Post-Processing of Mission Command Speech Recognition
3.3. Verification of the Proposed Semantic Analysis Method for the Post-Processing of Mission Command Speech Recognition
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Correction Statement
References
- Oneata, D.; Cucu, H. Kite: Automatic speech recognition for unmanned aerial vehicles. arXiv 2019, arXiv:1907.01195. [Google Scholar]
- Lavrynenko, O.Y.; Konakhovych, G.F.; Bakhtiiarov, D.I. Protected voice control system of unmanned aerial vehicle. Electr. Control Syst. 2020, 1, 92–98. [Google Scholar] [CrossRef]
- Anand, S.S.; Mathiyazaghan, R. Design and fabrication of voice controlled unmanned aerial vehicle. IAES Int. J. Robot. Autom. 2016, 5, 205–212. [Google Scholar] [CrossRef]
- Park, J.S.; Na, H.J. Front-end of vehicle-embedded speech recognition for voice-driven multi-UAVs control. Appl. Sci. 2020, 10, 6876. [Google Scholar] [CrossRef]
- Helmke, H.; Kleinert, M.; Shetty, S.; Ohneiser, O.; Ehr, H.; Arilíusson, H.; Simiganoschi, T.S.; Prasad, A.; Motlicek, P.; Veselý, K.; et al. Readback error detection by automatic speech recognition to increase ATM safety. In Proceedings of the Fourteenth USA/Europe Air Traffic Management Research and Development Seminar (ATM2021), Virtual Event, 20–23 September 2021; pp. 20–23. [Google Scholar]
- Helmke, H.; Kleinert, M.; Ahrenhold, N.; Ehr, H.; Mühlhausen, T.; Ohneiser, O.; Klamert, L.; Motlicek, P.; Prasad, A.; Zuluaga-Gomez, J.; et al. Automatic speech recognition and understanding for radar label maintenance support increases safety and reduces air traffic controllers’ workload. In Proceedings of the Fifteenth USA/Europe Air Traffic Management Research and Development Seminar (ATM2023), Savannah, GA, USA, 5–9 June 2023; pp. 1–11. [Google Scholar]
- Guo, D.; Zhang, Z.; Fan, P.; Zhang, J.; Yang, B. A context-aware language model to improve the speech recognition in air traffic control. Aerospace 2021, 8, 348. [Google Scholar] [CrossRef]
- Zhang, S.; Kong, J.; Chen, C.; Li, Y.; Liang, H. Speech GAU: A single head attention for Mandarin speech recognition for air traffic control. Aerospace 2022, 9, 395. [Google Scholar] [CrossRef]
- Lin, Y. Spoken instruction understanding in air traffic control: Challenge, technique, and application. Aerospace 2021, 8, 65. [Google Scholar] [CrossRef]
- Oneață, D.; Cucu, H. Multimodal speech recognition for unmanned aerial vehicles. Comput. Electr. Eng. 2021, 90, 106943. [Google Scholar] [CrossRef]
- Xiang, X.; Tan, Q.; Zhou, H.; Tang, D.; Lai, J. Multimodal fusion of voice and gesture data for UAV control. Drones 2022, 6, 201. [Google Scholar] [CrossRef]
- Galangque, C.M.J.; Guirnaldo, S.A. Speech recognition engine using ConvNet for the development of a voice command controller for fixed wing unmanned aerial vehicle (UAV). In Proceedings of the 12th International Conference on Information & Communication Technology and System (ICTS), Surabaya, Indonesia, 18 July 2019; pp. 93–97. [Google Scholar] [CrossRef]
- Zhou, Y.; Hou, J.; Gong, Y. Research and application of human-computer interaction technology based on voice control in ground control station of UAV. In Proceedings of the IEEE 6th International Conference on Computer and Communications (ICCC), Chengdu, China, 11–14 December 2020; pp. 1257–1262. [Google Scholar] [CrossRef]
- Contreras, R.; Ayala, A.; Cruz, F. Unmanned aerial vehicle control through domain-based automatic speech recognition. Computers 2020, 9, 75. [Google Scholar] [CrossRef]
- Trivedi, A.; Pant, N.; Shah, P.; Sonik, S.; Agrawal, S. Speech to text and text to speech recognition systems-a review. IOSR J. Comput. Eng. 2018, 20, 36–43. [Google Scholar]
- Karpagavalli, S.; Chandra, E. A review on automatic speech recognition architecture and approaches. Int. J. Signal Process. Image Process. Pattern Recognit. 2016, 9, 393–404. [Google Scholar] [CrossRef]
- Desai, N.; Dhameliya, K.; Desai, V. Feature extraction and classification techniques for speech recognition: A review. Int. J. Emerg. Technol. Adv. Eng. 2013, 3, 367–371. [Google Scholar]
- Marques, M.M. STANAG 4586—Standard interfaces of UAV control system (UCS) for NATO UAV interoperability. NATO Stand. Agency Afeite Port. 2012, 3, 1–14. [Google Scholar]
- Kim, S.; Kim, Y. Development of an MUM-T integrated simulation platform. IEEE Access. 2023, 11, 21519–21533. [Google Scholar] [CrossRef]
- Jameson, S.; Franke, J.; Szczerba, R.; Stockdale, S. Collaborative autonomy for manned/unmanned teams. In Proceedings of the Annual Forum American Helicopter Society, Grapevine, TX, USA, 1–3 June 2005; Volume 61, p. 1673. [Google Scholar]
- Alicia, T.J.; Hall, B.T.; Terman, M. Synergistic Unmanned Manned Intelligent Teaming (SUMIT). In Technical Report; U.S. Army: Madison County, NY, USA, 2020; pp. 1–92. [Google Scholar]
- Juang, B.H.; Rabiner, L.R. Hidden Markov models for speech recognition. Technometrics 1991, 33, 251–272. [Google Scholar] [CrossRef]
- Woodland, P.C.; Odell, J.J.; Valtchev, V.; Young, S.J. Large vocabulary continuous speech recognition using HTK. In Proceedings of the ICASSP’94, IEEE International Conference on Acoustics, Speech and Signal Processing, Adelaide, Australia, 19–22 April 1994; Volume 2, pp. II/125–II/128. [Google Scholar] [CrossRef]
- Mor, B.; Garhwal, S.; Kumar, A. A systematic review of hidden Markov models and their applications. Arch. Comput. Methods Eng. 2021, 28, 1429–1448. [Google Scholar] [CrossRef]
- Gales, M.; Young, S. The application of hidden Markov models in speech recognition. Found. Trends Signal Process. 2007, 1, 195–304. [Google Scholar] [CrossRef]
- Mustafa, M.K.; Allen, T.; Appiah, K. A comparative review of dynamic neural networks and hidden Markov model methods for mobile on-device speech recognition. Neural Comput. Appl. 2019, 31, 891–899. [Google Scholar] [CrossRef]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Shahin, M.A.; Ahmed, B.; McKechnie, J.; Ballard, K.J.; Gutierrez-Osuna, R. A comparison of GMM-HMM and DNN-HMM based pronunciation verification techniques for use in the assessment of childhood apraxia of speech. Interspeech 2014, 1, 1583–1587. [Google Scholar]
- Fohr, D.; Mella, O. New paradigm in speech recognition: Deep neural networks. In Proceedings of the International Conference on Information Systems and Economic Intelligence, Marrakech, Morocco, 13 April 2017. [Google Scholar]
- Këpuska, V.; Bohouta, G. Comparing speech recognition systems (Microsoft API, Google API and CMU Sphinx). Int. J. Eng. Res. Appl. 2017, 7, 20–24. [Google Scholar] [CrossRef]
- Deshmukh, A.M. Comparison of hidden Markov model and recurrent neural network in automatic speech recognition. Eur. J. Eng. Res. Sci. 2020, 5, 958–965. [Google Scholar] [CrossRef]
- Lou, H.L. Implementing the Viterbi algorithm. IEEE Signal Process. Mag. 1995, 12, 42–52. [Google Scholar] [CrossRef]
- Arora, S.J.; Singh, R.P. Automatic speech recognition: A review. Int. J. Comput. Appl. 2012, 60, 34–44. [Google Scholar] [CrossRef]
- Tur, G.; DeMori, R. Spoken Language Understanding: Systems for Extracting Semantic Information from Speech; John Wiley and Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Bernstein, P.A.; Newcomer, E. System Recovery, In Principles of Transaction Processing; Morgan Kaufmann: San Francisco, CA, USA, 2009; pp. 185–222. ISBN 9781558606234. [Google Scholar]
- Hain, T.; Woodland, P.C. Dynamic HMM selection for continuous speech recognition. In Proceedings of the 6th European Conference on Speech Communication and Technology (EUROSPEECH 1999), Budapest, Hungary, 5–9 September 1999. [Google Scholar]
- Pallett, D.S.; Fiscus, J.G.; Garofolo, J.S. DARPA resource management benchmark test results June 1990. In Proceedings of the Workshop on Speech and Natural Language, Hidden Valley, PA, USA, 24–27 June 1990. [Google Scholar]
- Povey, D.; Ghoshal, A.; Boulianne, G.; Burget, L.; Glembek, O.; Goel, N.; Hannemann, M.; Motlicek, P.; Qian, Y.; Schwarz, P.; et al. The Kaldi speech recognition toolkit. In Proceedings of the IEEE 2011 Workshop on Automatic Speech Recognition and Understanding (ASRU 2011), Waikoloa, HI, USA, 11–15 December 2011. [Google Scholar]
- Kaldi Tutorial. Available online: https://kaldi-asr.org/doc/tutorial.html (accessed on 10 January 2023).
- GitHub: Kaldi Speech Recognition Toolkit. Available online: https://github.com/kaldi-asr/kaldi (accessed on 10 January 2023).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Restrictions | Expert Advice |
|---|---|
| Structure of commands | Simple and clear commands for precise delivery (1 to 5 connected words) |
| Vocabulary size | 150 to 200 words available to pilots |
| Language | English is used for communication between military aircraft (International Telecommunications Standard) |
| DLI Message | Mission Commands |
|---|---|
| Vehicle Configuration | Check energy storage unit, read back, report energy state, report fuel state, report battery state, ready for launch, acknowledge, are you ready, take off |
| Vehicle Operating Mode | Set up control mode, request manual control, request automatic control, report control mode |
| Vehicle Steering | Set up heading point, heading for waypoint (no.), change heading point, report heading point, say heading point, set up altitude, request altitude (no.), maintain altitude, change altitude (no.), say altitude, report altitude, set up speed, reduce speed to (no.), set up loiter position, request loiter position latitude (no.) |
| Mission Transfer | Set up mission plan, clear route, change route (no.), request route (no.), clear mission, request mission (no.) |
| AV Loiter Waypoint | Set up loiter type, request loiter type circle, request loiter type racetrack, request loiter radius (no.), report loiter type, report loiter altitude, report loiter speed, request loiter speed (no.), request loiter duration (no.), report loiter duration, request loiter bearing north |
| Mission Type | Command Scenario | Mission Type | Command Scenario |
|---|---|---|---|
| Take-off | Agent Alpha Agent Bravo Agent Charlie Set up heading point Heading for waypoint 7 Set up altitude Request altitude 7000 Set up speed Request speed 250 Ready for launch Are you ready Take off Disconnection | Reconnaissance flight instructions | Agent Alpha Request approach Set up altitude Request altitude 3000 Set up area Request vertices number 1 Request area min altitude 2000 Request area max altitude 3000 Request area loop count 10 Disconnection |
| Surveillance flight instructions | Agent Bravo Request activity surveillance Request loiter type circle Request loiter radius 200 Request loiter speed 10 Disconnection Agent Charlie Request activity surveillance Request loiter type figure eight Request loiter speed 20 Disconnection | Return after completing the mission | Agent Alpha Agent Bravo Agent Charlie Clear mission Request flight Change heading point Heading for waypoint 0 Start flight termination Set up control mode Request automatic control Report arrival time Disconnection |
| Model | Measure | 2 Words | 3 Words | 4 Words | 5 or More |
|---|---|---|---|---|---|
| Fixed HMM | Rec. Rate (sent.) Word Error Rate | 100 0 | 97.4 0.87 | 95.3 1.49 | 94.2 2.15 |
| Avg. Rec. Time * | 0.03 | 0.05 | 0.06 | 0.09 | |
| Variable HMM (proposed) | Rec. Rate (sent.) Word Error Rate | 100 0 | 98.5 0.54 | 97.4 0.86 | 96.9 1.13 |
| Avg. Rec. Time * | 0.03 | 0.04 | 0.05 | 0.10 | |
| DNN | Rec. Rate (sent.) Word Error Rate | 100 0 | 98.8 0.49 | 97.6 0.80 | 97.2 1.09 |
| Avg. Rec. Time * | 2.0 | 4.5 | 6.5 | 9.0 | |
| Avg. Rec. Time ** | 0.20 | 0.38 | 0.55 | 0.85 |
| 2 Words | 3 Words | 4 Words | 5 or More | |
|---|---|---|---|---|
| Baseline | 100 | 98.5 | 97.4 | 96.9 |
| Applying syntax analysis (proposed) | 100 | 99.7 | 99.0 | 98.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, J.-S.; Geng, N. In-Vehicle Speech Recognition for Voice-Driven UAV Control in a Collaborative Environment of MAV and UAV. Aerospace 2023, 10, 841. https://doi.org/10.3390/aerospace10100841
Park J-S, Geng N. In-Vehicle Speech Recognition for Voice-Driven UAV Control in a Collaborative Environment of MAV and UAV. Aerospace. 2023; 10(10):841. https://doi.org/10.3390/aerospace10100841
Chicago/Turabian StylePark, Jeong-Sik, and Na Geng. 2023. "In-Vehicle Speech Recognition for Voice-Driven UAV Control in a Collaborative Environment of MAV and UAV" Aerospace 10, no. 10: 841. https://doi.org/10.3390/aerospace10100841