

Causal Vector Autoregression Enhanced with Covariance and Order Selection
 , , , and
, , , and
Abstract
:1. Introduction
2. Materials and Methods
- Reduced form VAR model: for given integer , it iswhere is white noise, it is uncorrelated with , it has zero expectation and covariance matrix (not necessarily diagonal, but positive definite), and the matrices satisfy the stability conditions (see Deistler and Scherrer (2019)). (Sometimes, is isolated on the left-hand side.) is called innovation, i.e., the error term of the (added value to the) best one-step ahead linear prediction of with its past, which (in the case of a VAR(p) model) can be carried out with the p-lag long past .Here, the ordering of the components of does not matter: if it is changed (with some permutation of ), then clearly the rows of the matrices s and, furthermore, the rows and columns of are permuted accordingly.
- Structural form SVAR model: for given integer , it iswhere the white noise term is uncorrelated with , and it has zero expectation with uncorrelated components, i.e., with positive definite, diagonal covariance matrix . is a upper triangular matrix with 1s along its main diagonal, whereas are matrices; see also Lütkepohl (2005). The components of are called structural shocks, and they are mutually uncorrelated and assigned to the individual variables.Here, the ordering of the components of does matter: if it is changed (with some permutation of ), then the matrices , and cannot be obtained in a simple way; they profoundly change under the given permutation.
- Causal CVAR unrestricted model: it also obeys Equation (2), but here the ordering of the components follows a causal ordering, given e.g., by an expert’s knowledge. This is a recursive ordering along a “complete” DAG, where the permutation (labeling) of the graph nodes (assigned to the components of ) is such that can be caused by whenever , which means a directed edge. Here, the causal effects are meant contemporaneously, and reflected by the upper triangular structure of the matrix .It is important that, in any ordering of the jointly Gaussian variables, a Bayesian network (in other words, a Gaussian directed graphical model) can be constructed, in which every node (variable) is regressed linearly with the variables corresponding to higher label nodes. The partial regression coefficients behave like path coefficients, also used in SEM. If the DAG is complete, then there are no zero constraints imposed on the partial regression coefficients. Here, building the DAG just aims at finding a sensible ordering of the variables.
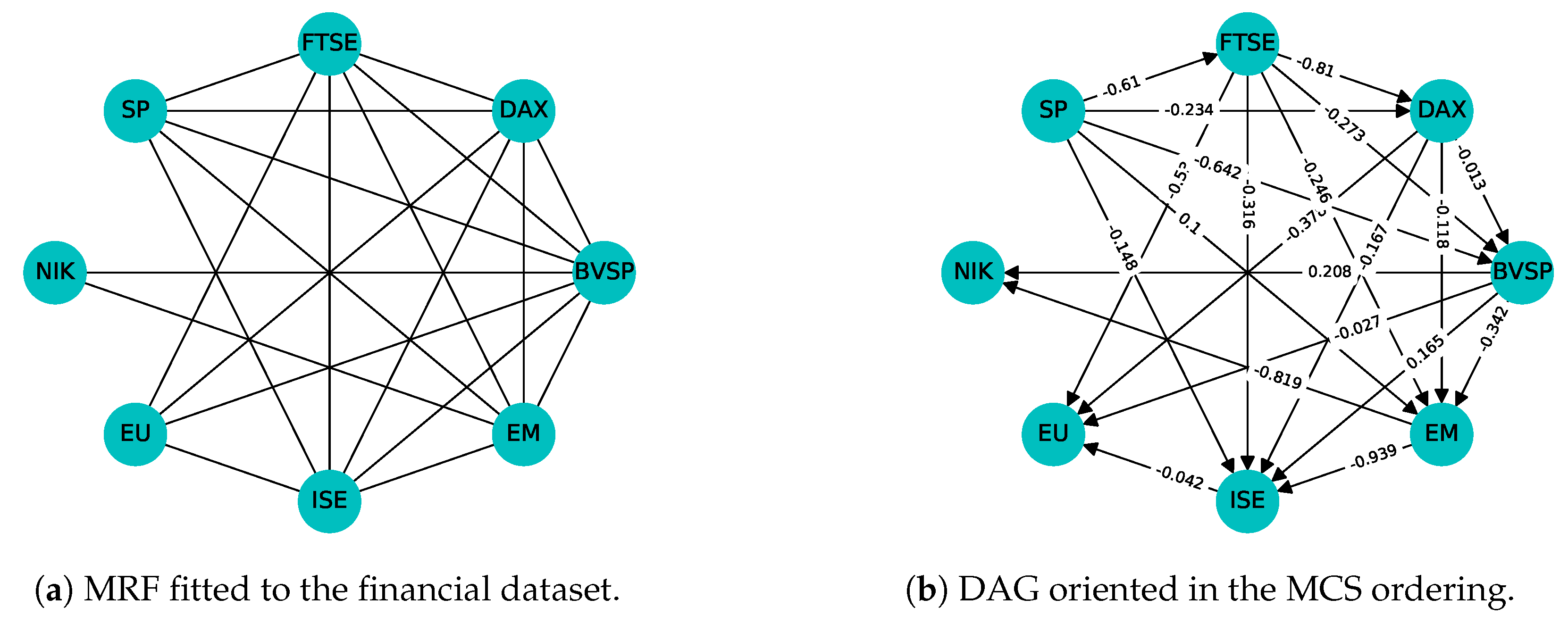
- Causal CVAR restricted model: here, an incomplete DAG is built, based on partial correlations.First, we build an undirected graph: do not connect i and j if the partial correlation coefficients of and , eliminating the effect of the other variables is 0 (theoretically), or less than a threshold (practically). Such an undirected graphical model is called Markov random field (MRF). It is known (see Rao (1973) and Lauritzen (2004)) that partial correlations can be calculated from the concentration matrix (inverse of the covariance matrix). However, here the upper left block of the inverse of the large block matrix, containing the first p autocovariance matrices, is used. If this undirected graph is triangulated, then in a convenient (so-called perfect) ordering of the nodes, the zeros of the adjacency matrix form an RZP. We can find such a (not necessarily unique) ordering of the nodes with the maximal cardinality search (MCS) algorithm, together with cliques and separators of a so-called junction tree (JT); see Lauritzen (2004), Koller and Friedman (2009), and Bolla et al. (2019). In this ordering (labeling) of the nodes, a DAG can also be constructed, which is Markov equivalent to the undirected one (it has no so-called sink V configuration); for further details, see Section 3.2.Having an RZP in the CVAR restricted model, we use the incomplete DAG for estimation. With the covariance selection method of Dempster (1972), the starting concentration matrix is re-estimated by imposing zero constraints for its entries in the RZP positions (symmetrically). By the theory (see, e.g., Bolla et al. (2019)), this will result in zero entries of in the no directed edge positions.
3. Results
3.1. The Unrestricted Causal VAR(p) Model
- Upper left block: ;
- Upper right block: ;
- Lower left block: ;
- Lower right block: ,
3.2. The Restricted Causal VAR(p) Model
- G is triangulated (with other words, chordal), i.e., every cycle in G of a length of at least four has a chord.
- G has a perfect numbering of its nodes such that, in this labeling, is a complete subgraph, where is the set of neighbors of i, for . It is also called single node elimination ordering (see Wainwright (2015)), and obtainable with the maximal cardinality search (MCS) algorithm of Tarjan and Yannakakis (1984); see also Koller and Friedman (2009).
- G has the following running intersection property: we can number the cliques of it to form a so-called perfect sequence where each combination of the subgraphs induced by and is a decomposition , i.e., the necessarily complete subgraph is a separator. More precisely, is a node cutset between the disjoint node subsets and . This sequence of cliques is also called a junction tree (JT).Here, any clique is the disjoint union of (called residual), the nodes of which are not contained in any , and of (called separator) with the following property: there is an such thatThis (not necessarily unique) is called parent clique of . Here, and . Furthermore, if such an ordering is possible, a version may be found in which any prescribed set is the first one. Note that the junction tree is indeed a tree with nodes and one less edge that are the separators .
- There is a labeling of the nodes such that the adjacency matrix contains a reducible zero pattern (RZP). It means that there is an index set which is reducible in the sense that, for each and , we have or or both.Indeed, this convenient labeling is a perfect numbering of the nodes.
- The following Markov chain property also holds: .Therefore, if we have a perfect sequence of the cliques with separators , then, for any state configuration , we have the following factorized form of the density:
4. Applications with Order Selection
4.1. Financial Data
4.2. IMR (Infant Mortality Rate) Longitudinal Data
- Case 1: .
- Case 2: .
5. Discussion
6. Conclusions and Further Perspectives
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| VAR | Vector AutoRegression |
| SVAR | Structural Vector AutoRegression |
| CVAR | Causal Vector AutoRegression |
| SEM | Structural Equation Modeling |
| DAG | Directed Acyclic Graph |
| JT | Junction Tree |
| MCS | Maximal Cardinality Search |
| IPS | Iterative Proportional Scaling |
| RZP | Reducible Zero Pattern |
| MRF | Markov Random Field |
| AIC | Akaike Information Criterion |
| AICC | Akaike Information Criterion Corrected |
| BIC | Bayesian Information Criterion |
| HQ | Hannan and Quinn’s criterion |
| MLE | Maximum Likelihood Estimate |
| PLS | Partial Least Squares regression |
| RMSE | Root Mean Square Error |
| IMR | Infant Mortality Rate |
| LDL | variant of the Cholesky decomposition for a symmetric, positive semidefinite matrixas (lower triangular) (diagonal) |
Appendix A. Proofs of the Main Theorems
Appendix A.1. Proof of Theorem 1
Appendix A.2. Algorithm for the Block LDL Decomposition of Appendix A.1
- Outer cycle (column-wise). For : (with the reservation that );
- Inner cycle (row-wise). For :and(with the reservation that, in the case, the summand is zero), where for is vector in the bottom left block of .
Appendix A.3. Proof of Theorem 2
Appendix A.4. Algorithm for the Block LDL Decomposition of Appendix A.3
- Outer cycle (column-wise). For : (with the reservation that );
- Inner cycle (row-wise). For :and(with the reservation that, in the case, the summand is zero), where for are vectors in the bottom left block of .
Appendix B. Pseudocodes
| Algorithm A1: Constructing an undirected graph and a causal ordering of variables |
Input :, data matrix p, order of the CVAR model , threshold for the partial correlation statistical test Output: undirected graph G and its perfect ordering
|
| Algorithm A2: Constructing an unrestricted CVAR model |
Input :: data matrix or the existing from Algorithm A1 p: order of the CVAR model , causal ordering of the d observed variables. Output: parameter matrices
|
| Algorithm A3: Constructing a restricted CVAR model |
Input :: data matrix p: order of the CVAR model G, (undirected) chordal graph for observed variables , causal ordering of observed variables. Output: parameter matrices
|
| 1 | Please see the main text for suggestions on graphs that are not triangulated when moralization and running the IPS algorithm is needed. The default threshold is usually set according to a significance level (e.g., ) for the partial correlation test. This can be changed based on the sample size and the effect size. |
References
- Abdelkhalek, Fatma, and Marianna Bolla. 2020. Application of Structural Equation Modeling to Infant Mortality Rate in Egypt. In Demography of Population Health, Aging and Health Expenditures. Edited by Christos H. Skiadas and Charilaos Skiadas. Cham: Springer, pp. 89–99. [Google Scholar]
- Akbilgic, Oguz, Hamparsum Bozdogan, and M. Erdal Balaban. 2014. A Novel Hybrid RBF Neural Networks Model as a Forecaster. Statistics and Computing 24: 365–75. [Google Scholar] [CrossRef]
- Bazinas, Vassilios, and Bent Nielsen. 2022. Causal Transmission in Reduced-Form Models. Econometrics 10: 14. [Google Scholar] [CrossRef]
- Bolla, Marianna, Fatma Abdelkhalek, and Máté Baranyi. 2019. Graphical models, regression graphs, and recursive linear regression in a unified way. Acta Scientiarum Mathematicarum (Szeged) 85: 9–57. [Google Scholar] [CrossRef]
- Bolla, Marianna, and Tamás Szabados. 2021. Multidimensional Stationary Time Series: Dimension Reduction and Prediction. New York: CRC Press, Taylor and Francis Group. [Google Scholar]
- Box, George EP, Gwilym M. Jenkins, Gregory C. Reinsel, and Greta M. Ljung. 2015. Time series Analysis: Forecasting and Control. New York: Wiley. [Google Scholar]
- Brillinger, David R. 1996. Remarks concerning graphical models for time series and point processes. Revista de Econometria 16: 1–23. [Google Scholar] [CrossRef] [Green Version]
- Brockwell, Peter J., and Richard A. Davis. 1991. Time Series: Theory and Methods. Berlin/Heidelberg: Springer. [Google Scholar]
- Deistler, Manfred, and Wolfgang Scherrer. 2019. Vector Autoregressive Moving Average Models. In Handbook of Statistics. Berlin/Heidelberg: Springer, vol. 41. [Google Scholar]
- Deistler, Manfred, and Wolfgang Scherrer. 2022. Time Series Models. Cham: Springer Nature. [Google Scholar]
- Dempster, Arthur P. 1972. Covariance selection. Biometrics 28: 157–75. [Google Scholar] [CrossRef]
- Eichler, Michael. 2006. Graphical modelling of dynamic relationships in multivariate time series. In Handbook of Time Series Analysis. Edited by Schelter Björn, Winterhalder Matthias and Timmer Jens. Berlin/Heidelberg: Wiley-VCH Berlin. [Google Scholar]
- Eichler, Michael. 2012. Graphical modelling of multivariate time series. Probability Theory Related Fields 153: 233–68. [Google Scholar] [CrossRef] [Green Version]
- Geweke, John. 1984. Inference and causality in economic time series models. In Handbook of Econometrics. Amsterdam: Elsevier, vol. 2. [Google Scholar]
- Golub, Gene H., and Charles F. Van Loan. 2012. Matrix Computations. Baltimore: JHU Press. [Google Scholar]
- Granger, Clive W. J. 1969. Investigating causal relations by econometric models and cross-spectral methods. Econometrica 37: 424–38. [Google Scholar] [CrossRef]
- Haavelmo, Trygve. 1943. The statistical implications of a system of simultaneous equations. Econometrica 11: 1–12. [Google Scholar] [CrossRef]
- Hagberg, Aric, Pieter Swart, and Daniel S Chult. 2008. Exploring network structure, dynamics, and function using NetworkX. Paper presented at the 7th Python in Science Conference (SciPy2008), Pasadena, CA, USA, August 19–24; Edited by Varoquaux Gäel, Vaught Travis and Millman Jarrod. Los Alamos: Los Alamos National Lab (LANL), pp. 11–15. [Google Scholar]
- Jöreskog, Karl G. 1977. Structural equation models in the social sciences. Specification, estimation and testing. In Applications of Statistics. Edited by Pathak R. Krishnaiah. Amsterdam: North-Holland Publishing Co., pp. 265–87. [Google Scholar]
- Keating, John W. 1996. Structural information is recursive VAR orderings. Journal of Econometric Dynamics and Control 20: 1557–80. [Google Scholar] [CrossRef]
- Kiiveri, Harri, Terry P. Speed, and John B. Carlin. 1984. Recursive causal models. Journal of the Australian Mathematical Society 36: 30–52. [Google Scholar] [CrossRef] [Green Version]
- Kilian, Lutz, and Helmut Lütkepohl. 2017. Structural Vector Autoregressive Analysis. Cambridge: Cambridge University Press. [Google Scholar]
- Koller, Daphne, and Nir Friedman. 2009. Probabilistic Graphical Models. Principles and Techniques. Cambridge: MIT Press. [Google Scholar]
- Lauritzen, Steffen L. 2004. Graphical Models. Oxford Statistical Science Series; Oxford: Clarendon Press, Oxford University Press, reprint with corr. edition. [Google Scholar]
- Lütkepohl, Helmut. 2005. New Introduction to Multiple Time Series Analysis. Berlin/Heidelberg: Springer. [Google Scholar]
- Nocedal, Jorge, and Stephen J. Wright. 1999. Numerical Optimization. Berlin/Heidelberg: Springer. [Google Scholar]
- Rao, Calyampudi Radhakrishna. 1973. Linear Statistical Inference and its Applications. New York: Wiley. [Google Scholar]
- Rózsa, Pál. 1991. Linear Algebra and Its Applications. Budapest: Műszaki Kiadó. (In Hungarian) [Google Scholar]
- Sims, Christopher A. 1980. Macroeconomics and reality. Econometrica 48: 1–48. [Google Scholar] [CrossRef] [Green Version]
- Tarjan, Robert E., and Mihalis Yannakakis. 1984. Simple Linear-Time Algorithms to Test Chordality of Graphs, Test Acyclicity of Hypergraphs, and Selectively Reduce Acyclic Hypergraphs. SIAM Journal on Computing 13: 566–79. [Google Scholar] [CrossRef]
- Wainwright, Martin J., and Michael I. Jordan. 2008. Graphical models, exponential families, and variational inference. Foundations and Trends in Machine Learning 1: 1–305. [Google Scholar] [CrossRef] [Green Version]
- Wainwright, Martin J. 2015. Graphical Models and Message-Passing Algorithms: Some Introductory Lectures. In Mathematical Foundations of Complex Networked Information Systems. Lecture Notes in Mathematics 2141. Edited by Fagnani Fabio, Sophie M. Fosson and Ravazzi Chiara. Cham: Springer. [Google Scholar]
- Wermuth, Nanny. 1980. Recursive equations, covariance selection, and path analysis. Journal of the American Statistical Association 75: 963–72. [Google Scholar] [CrossRef]
- Wiener, Norbert. 1956. The theory of prediction. In Modern Mathematics for Engineers. Edited by E. F. Beckenback. New York: McGraw–Hill. [Google Scholar]
- Wold, Herman O. A. 1960. A generalization of causal chain models. Econometrica 28: 444–63. [Google Scholar] [CrossRef]
- Wold, Herman O. A. 1985. Partial least squares. In Encyclopedia of Statistical Sciences. Edited by Samuel Kotz, Norman L. Johnson and C. R. Read. New York: Wiley. [Google Scholar]
- Wright, Sewall. 1934. The method of path coefficients. The Annals of Mathematical Statistics 5: 161–215. [Google Scholar] [CrossRef]



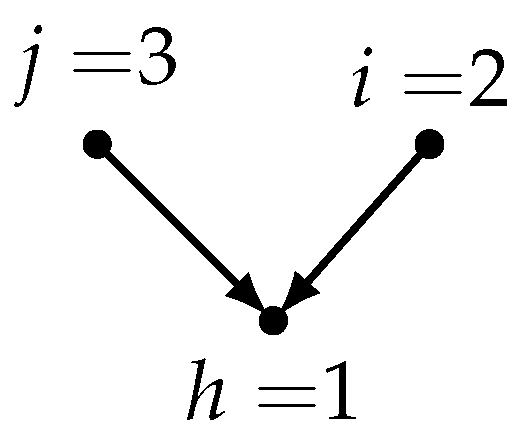{kind=link}
{kind=link}
| NIK | EU | ISE | EM | BVSP | DAX | FTSE | SP | |
|---|---|---|---|---|---|---|---|---|
| NIK | 0.016 * | 0.035 * | 0.522 | −0.260 | −0.019 * | −0.076 | 0.024 * | |
| EU | 0.016 * | 0.217 | 0.034 * | 0.067 | 0.687 | 0.747 | 0.018 * | |
| ISE | 0.035 * | 0.217 | 0.358 | −0.157 | −0.077 | −0.059 | 0.034 * | |
| EM | 0.522 | 0.034 * | 0.358 | 0.546 | 0.048 | 0.086 | −0.184 | |
| BVSP | −0.260 | 0.067 | −0.157 | 0.546 | −0.093 | −0.045 | 0.533 | |
| DAX | −0.019 * | 0.687 | −0.077 | 0.048 | −0.093 | −0.203 | 0.191 | |
| FTSE | −0.076 | 0.747 | −0.059 | 0.086 | −0.045 | −0.203 | 0.057 | |
| SP | 0.024 * | 0.018 * | 0.034 * | −0.184 | 0.533 | 0.191 | 0.057 |
| NIK | EU | ISE | EM | BVSP | DAX | FTSE | SP | |
|---|---|---|---|---|---|---|---|---|
| NIK | 1 | 0.0264 | 0.0042 | −0.8902 | 0.2030 | 0.0170 | 0.0781 | −0.0336 |
| EU | 0 | 1 | −0.0418 | −0.0146 | −0.0239 | −0.3746 | −0.5255 | −0.0033 |
| ISE | 0 | 0 | 1 | −0.9518 | 0.1613 | −0.1658 | −0.3129 | −0.1413 |
| EM | 0 | 0 | 0 | 1 | −0.3507 | −0.1182 | −0.2464 | 0.1077 |
| BVSP | 0 | 0 | 0 | 0 | 1 | −0.0129 | −0.2782 | −0.6375 |
| DAX | 0 | 0 | 0 | 0 | 0 | 1 | −0.8102 | −0.2336 |
| FTSE | 0 | 0 | 0 | 0 | 0 | 0 | 1 | −0.6100 |
| SP | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| NIK | EU | ISE | EM | BVSP | DAX | FTSE | SP | |
|---|---|---|---|---|---|---|---|---|
| NIK | 0.1845 | −0.1685 | −0.0874 | 0.0852 | 0.0635 | 0.0205 | −0.1236 | −0.2798 |
| EU | −0.0131 | 0.1219 | −0.0044 | 0.0291 | −0.0124 | −0.0393 | −0.0979 | 0.0011 |
| ISE | 0.0677 | 0.2811 | −0.0657 | 0.2473 | −0.2940 | −0.0543 | 0.0098 | −0.1442 |
| EM | −0.0016 | −0.0569 | −0.0159 | 0.1076 | −0.0917 | −0.0945 | 0.0875 | −0.1071 |
| BVSP | −0.0140 | 0.0704 | 0.0142 | −0.1046 | 0.1397 | −0.1497 | 0.1188 | −0.0812 |
| DAX | −0.0034 | 0.2021 | −0.0342 | −0.0044 | −0.0352 | −0.0476 | −0.0670 | −0.0673 |
| FTSE | 0.0293 | −0.0168 | −0.0109 | 0.0420 | −0.1129 | 0.2141 | 0.0805 | −0.2641 |
| SP | 0.0417 | 0.2603 | −0.0261 | 0.0112 | −0.0026 | −0.0709 | −0.2850 | 0.1240 |
| NIK | EU | ISE | EM | BVSP | DAX | FTSE | SP | |
|---|---|---|---|---|---|---|---|---|
| NIK | 1 | −0.0114 | 0.0103 | −0.8822 | 0.1995 | 0.0233 | 0.0856 | −0.0214 |
| EU | 0 | 1 | −0.0426 | −0.0110 | −0.0240 | −0.3745 | −0.5137 | −0.0128 |
| ISE | 0 | 0 | 1 | −0.9788 | 0.1701 | −0.1669 | −0.3139 | −0.1361 |
| EM | 0 | 0 | 0 | 1 | −0.3450 | −0.1154 | −0.2375 | 0.0922 |
| BVSP | 0 | 0 | 0 | 0 | 1 | −0.0047 | −0.2655 | −0.6601 |
| DAX | 0 | 0 | 0 | 0 | 0 | 1 | −0.8120 | −0.2339 |
| FTSE | 0 | 0 | 0 | 0 | 0 | 0 | 1 | −0.6320 |
| SP | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| NIK | EU | ISE | EM | BVSP | DAX | FTSE | SP | |
|---|---|---|---|---|---|---|---|---|
| NIK | 0.2063 | −0.1826 | −0.1106 | 0.1063 | 0.0731 | 0.0187 | −0.1502 | −0.2580 |
| EU | −0.0037 | 0.1364 | −0.0010 | 0.0232 | −0.0150 | −0.0371 | −0.0996 | −0.0107 |
| ISE | 0.0409 | 0.2476 | −0.0771 | 0.2274 | −0.2772 | −0.0447 | 0.0331 | −0.1284 |
| EM | 0.0489 | −0.0200 | −0.0030 | 0.1360 | −0.1150 | −0.0996 | 0.0468 | −0.1162 |
| BVSP | −0.0066 | 0.0931 | 0.0261 | −0.1091 | 0.1312 | −0.1573 | 0.1161 | −0.0935 |
| DAX | −0.0123 | 0.2146 | −0.0319 | 0.0073 | −0.0406 | −0.0536 | −0.0727 | −0.0694 |
| FTSE | 0.0852 | 0.0019 | 0.0275 | 0.0145 | −0.1117 | 0.2377 | 0.1035 | −0.3427 |
| SP | 0.0530 | 0.2759 | −0.0565 | −0.0033 | 0.0024 | −0.0945 | −0.3106 | 0.1789 |
| NIK | EU | ISE | EM | BVSP | DAX | FTSE | SP | |
|---|---|---|---|---|---|---|---|---|
| NIK | −0.0402 | −0.1695 | −0.0410 | 0.0156 | 0.0998 | −0.0406 | 0.1367 | −0.0091 |
| EU | 0.0017 | 0.0771 | −0.0065 | 0.0054 | 0.0037 | 0.0192 | −0.0762 | −0.0394 |
| ISE | −0.0142 | −0.1725 | −0.0276 | −0.0088 | 0.0389 | 0.1167 | 0.0826 | 0.0357 |
| EM | −0.0054 | 0.0650 | −0.0322 | 0.1155 | −0.0695 | −0.0959 | −0.0162 | −0.0270 |
| BVSP | −0.0423 | 0.0332 | −0.0449 | 0.2878 | −0.0717 | −0.0221 | −0.0381 | −0.0120 |
| DAX | −0.0372 | 0.0177 | 0.0130 | 0.0658 | −0.0360 | −0.0108 | −0.0202 | 0.0059 |
| FTSE | 0.0491 | 0.3107 | −0.0820 | 0.0693 | 0.0299 | 0.0153 | −0.0840 | −0.3038 |
| SP | 0.0447 | −0.0628 | 0.0804 | −0.1824 | 0.0785 | 0.0133 | −0.1775 | 0.1284 |
| NIK | EU | ISE | EM | BVSP | DAX | FTSE | SP | |
|---|---|---|---|---|---|---|---|---|
| NIK | 1 | 0 | 0 | −0.8193 | 0.2080 | 0 | 0 | 0 |
| EU | 0 | 1 | −0.0421 | 0 | −0.0269 | −0.3782 | −0.5297 | 0 |
| ISE | 0 | 0 | 1 | −0.9386 | 0.1653 | −0.1675 | −0.3161 | −0.1477 |
| EM | 0 | 0 | 0 | 1 | −0.3419 | −0.1184 | −0.2464 | 0.0997 |
| BVSP | 0 | 0 | 0 | 0 | 1 | −0.0130 | −0.2729 | −0.6423 |
| DAX | 0 | 0 | 0 | 0 | 0 | 1 | −0.8102 | −0.2336 |
| FTSE | 0 | 0 | 0 | 0 | 0 | 0 | 1 | −0.6104 |
| SP | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| NIK | EU | ISE | EM | BVSP | DAX | FTSE | SP | |
|---|---|---|---|---|---|---|---|---|
| NIK | 0.1811 | −0.1797 | −0.0856 | 0.0842 | 0.0739 | −0.0058 | −0.1146 | −0.2662 |
| EU | −0.0131 | 0.1213 | −0.0046 | 0.0304 | −0.0130 | −0.0415 | −0.0969 | 0.0002 |
| ISE | 0.0676 | 0.2814 | −0.0658 | 0.2483 | −0.2941 | −0.0567 | 0.0120 | −0.1472 |
| EM | −0.0016 | −0.0567 | −0.0158 | 0.1067 | −0.0908 | −0.0951 | 0.0890 | −0.1085 |
| BVSP | −0.0139 | 0.0704 | 0.0142 | −0.1041 | 0.1391 | −0.1488 | 0.1195 | −0.0828 |
| DAX | −0.0034 | 0.2019 | −0.0342 | −0.0046 | −0.0353 | −0.0474 | −0.0669 | −0.0672 |
| FTSE | 0.0292 | −0.0171 | −0.0109 | 0.0419 | −0.1130 | 0.2142 | 0.0807 | −0.2642 |
| SP | 0.0417 | 0.2608 | −0.0261 | 0.0115 | −0.0026 | −0.0713 | −0.2853 | 0.1239 |
| NIK | EU | ISE | EM | BVSP | DAX | FTSE | SP | |
|---|---|---|---|---|---|---|---|---|
| NIK | 1 | 0 | 0 | −0.8191 | 0.2076 | 0 | 0 | 0 |
| EU | 0 | 1 | −0.0423 | 0 | −0.0293 | −0.3811 | −0.5192 | 0 |
| ISE | 0 | 0 | 1 | −0.9662 | 0.1790 | −0.1713 | −0.3112 | −0.1470 |
| EM | 0 | 0 | 0 | 1 | −0.3361 | −0.1153 | −0.2372 | 0.0835 |
| BVSP | 0 | 0 | 0 | 0 | 1 | −0.0069 | −0.2544 | −0.6664 |
| DAX | 0 | 0 | 0 | 0 | 0 | 1 | −0.8128 | −0.2336 |
| FTSE | 0 | 0 | 0 | 0 | 0 | 0 | 1 | −0.6319 |
| SP | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| NIK | EU | ISE | EM | BVSP | DAX | FTSE | SP | |
|---|---|---|---|---|---|---|---|---|
| NIK | 0.2009 | −0.1869 | −0.1098 | 0.1089 | 0.0824 | −0.0079 | −0.1493 | −0.2428 |
| EU | −0.0038 | 0.1387 | −0.0013 | 0.0260 | −0.0153 | −0.0410 | −0.1027 | −0.0086 |
| ISE | 0.0353 | 0.2865 | −0.0750 | 0.2479 | −0.2741 | −0.0639 | 0.0101 | −0.1418 |
| EM | 0.0494 | −0.0218 | −0.0027 | 0.1338 | −0.1144 | −0.0990 | 0.0500 | −0.1177 |
| BVSP | −0.0107 | 0.1202 | 0.0276 | −0.0947 | 0.1327 | −0.1674 | 0.0987 | −0.1030 |
| DAX | −0.0110 | 0.2072 | −0.0322 | 0.0034 | −0.0412 | −0.0503 | −0.0677 | −0.0675 |
| FTSE | 0.0824 | 0.0176 | 0.0281 | 0.0224 | −0.1104 | 0.2309 | 0.0928 | −0.3463 |
| SP | 0.0506 | 0.2898 | −0.0560 | 0.0040 | 0.0037 | −0.1010 | −0.3199 | 0.1760 |
| NIK | EU | ISE | EM | BVSP | DAX | FTSE | SP | |
|---|---|---|---|---|---|---|---|---|
| NIK | −0.0455 | −0.1847 | −0.0391 | 0.0264 | 0.0906 | −0.0486 | 0.1427 | 0.0089 |
| EU | 0.0017 | 0.0755 | −0.0058 | 0.0047 | 0.0033 | 0.0179 | −0.0765 | −0.0370 |
| ISE | −0.0161 | −0.1634 | −0.0290 | −0.0021 | 0.0352 | 0.1113 | 0.0821 | 0.0313 |
| EM | −0.0056 | 0.0659 | −0.0330 | 0.1189 | −0.0701 | −0.0959 | −0.0167 | −0.0283 |
| BVSP | −0.0430 | 0.0415 | −0.0456 | 0.2906 | −0.0729 | −0.0258 | −0.0389 | −0.0168 |
| DAX | −0.0369 | 0.0163 | 0.0130 | 0.0656 | −0.0356 | −0.0100 | −0.0203 | 0.0064 |
| FTSE | 0.0485 | 0.3142 | −0.0820 | 0.0716 | 0.0290 | 0.0128 | −0.0845 | −0.3054 |
| SP | 0.0442 | −0.0606 | 0.0805 | −0.1825 | 0.0778 | 0.0117 | −0.1773 | 0.1281 |
| p | AIC | AICC | BIC | HQ |
|---|---|---|---|---|
| 1 | −76.81 | −33,222.68 | −76.07 | −76.52 |
| 2 | −76.85 | −33,173.98 | −75.60 | −76.36 |
| 3 | −76.84 | −33,095.75 | −75.08 | −76.15 |
| 4 | −76.83 | −33,011.98 | −74.55 | −75.94 |
| 5 | −76.77 | −32,893.23 | −73.97 | −75.67 |
| 6 | −76.69 | −32,766.33 | −73.37 | −75.39 |
| 7 | −76.58 | −32,612.38 | −72.74 | −75.08 |
| 8 | −76.48 | −32,457.38 | −72.11 | −74.77 |
| 9 | −76.41 | −32,316.33 | −71.52 | −74.49 |
| p | AIC | AICC | BIC | HQ |
|---|---|---|---|---|
| 1 | −76.87 | −33,239.11 | −76.19 | −76.60 |
| 2 | −76.91 | −33,190.27 | −75.71 | −76.44 |
| 3 | −76.93 | −33,129.67 | −75.22 | −76.26 |
| 4 | −77.00 | −33084.90 | −74.77 | −76.13 |
| 5 | −76.94 | −32,969.37 | −74.19 | −75.86 |
| 6 | −76.92 | −32,869.31 | −73.65 | −75.64 |
| 7 | −76.81 | −32,718.36 | −73.02 | −75.33 |
| 8 | −76.80 | −32,612.63 | −72.49 | −75.11 |
| 9 | −76.78 | −32,495.56 | −71.94 | −74.88 |
| IMR | MMR | HepB | OPExp | HExp | GDP | |
|---|---|---|---|---|---|---|
| IMR | 1.0 | −1.1259 | −0.0161 | 0.0003 | 0.0176 | −0.1348 |
| MMR | 0.0 | 1.0000 | 0.3594 | 0.0492 | −0.0684 | 0.7135 |
| HepB | 0.0 | 0.0000 | 1.0000 | −0.1626 | 0.2510 | −0.8196 |
| OPExp | 0.0 | 0.0000 | 0.0000 | 1.0000 | −0.6876 | −0.4229 |
| HExp | 0.0 | 0.0000 | 0.0000 | 0.0000 | 1.0000 | 0.6749 |
| GDP | 0.0 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 1.0000 |
| IMR-1 | MMR-1 | HepB-1 | OPExp-1 | HExp-1 | GDP-1 | |
|---|---|---|---|---|---|---|
| IMR | 0.2986 | −0.3589 | −0.0076 | 0.0042 | −0.0115 | −0.0639 |
| MMR | −0.0149 | −0.7469 | −0.2358 | 0.0540 | 0.0193 | −0.5577 |
| HepB | 13.0541 | −15.7658 | −1.1915 | −0.3506 | 0.2170 | −1.7902 |
| OPExp | 7.1616 | −8.0906 | −0.2994 | −0.1038 | −0.0215 | −0.7720 |
| HExp | 1.6861 | −2.9922 | −0.4650 | −0.1566 | −0.0681 | −1.0913 |
| GDP | −11.0674 | 13.2182 | 0.3254 | 0.3204 | −0.3099 | 1.2129 |
| IMR | MMR | HepB | GDP | OPExp | HExp | |
|---|---|---|---|---|---|---|
| IMR | 1.0 | 0.0736 | 0.0052 | 0.0111 | 0.0 | 0.0040 |
| MMR | 0.0 | 1.0000 | 0.0237 | 0.1180 | 0.0 | −0.0116 |
| HepB | 0.0 | 0.0000 | 1.0000 | −0.3418 | 0.0 | 0.0236 |
| GDP | 0.0 | 0.0000 | 0.0000 | 1.0000 | 0.0 | −0.0035 |
| OPExp | 0.0 | 0.0000 | 0.0000 | 0.0000 | 1.0 | −0.7854 |
| HExp | 0.0 | 0.0000 | 0.0000 | 0.0000 | 0.0 | 1.0000 |
| IMR-1 | MMR-1 | HepB-1 | GDP-1 | OPExp-1 | HExp-1 | |
|---|---|---|---|---|---|---|
| IMR | −0.9198 | −0.0592 | −0.0021 | 0.0053 | −0.0013 | −0.0049 |
| MMR | −1.0175 | 0.2511 | −0.0002 | 0.0607 | −0.0047 | 0.0039 |
| HepB | 3.6850 | -4.4606 | −0.9058 | −0.4230 | −0.0811 | −0.0950 |
| GDP | 0.5849 | −0.4453 | 0.0640 | −0.8573 | 0.0896 | 0.1086 |
| OPExp | 3.6432 | −3.7486 | −0.1413 | −0.4380 | 0.0273 | −0.0926 |
| HExp | 1.9561 | −3.4687 | −0.5221 | −0.6302 | −0.2298 | −0.1171 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bolla, M.; Ye, D.; Wang, H.; Ma, R.; Frappier, V.; Thompson, W.; Donner, C.; Baranyi, M.; Abdelkhalek, F. Causal Vector Autoregression Enhanced with Covariance and Order Selection. Econometrics 2023, 11, 7. https://doi.org/10.3390/econometrics11010007
Bolla M, Ye D, Wang H, Ma R, Frappier V, Thompson W, Donner C, Baranyi M, Abdelkhalek F. Causal Vector Autoregression Enhanced with Covariance and Order Selection. Econometrics. 2023; 11(1):7. https://doi.org/10.3390/econometrics11010007
Chicago/Turabian StyleBolla, Marianna, Dongze Ye, Haoyu Wang, Renyuan Ma, Valentin Frappier, William Thompson, Catherine Donner, Máté Baranyi, and Fatma Abdelkhalek. 2023. "Causal Vector Autoregression Enhanced with Covariance and Order Selection" Econometrics 11, no. 1: 7. https://doi.org/10.3390/econometrics11010007