Appendix B.1. Tests of GARCH Equations
The test for slow moving baseline volatility has a statistic whose distribution is sensitive to the high frequency, GARCH, volatility. For this reason, one cannot use the asymptotic distribution, rather the distribution must be generated via simulation. Further,
Silvennoinen and Teräsvirta (
2016) showed that the size of the test was distorted if the GARCH parameterisation deviates from the true one. For this reason, a few alternative approaches to estimate the GARCH parameters, and especially the persistence, have been investigated. It should be noted that estimating GARCH without taking the nonstationarity into account will yield overestimated persistence, thereby, impacting the null distribution of the test statistic and thus rendering the test outcomes unreliable. These estimates are given in
Table A1.
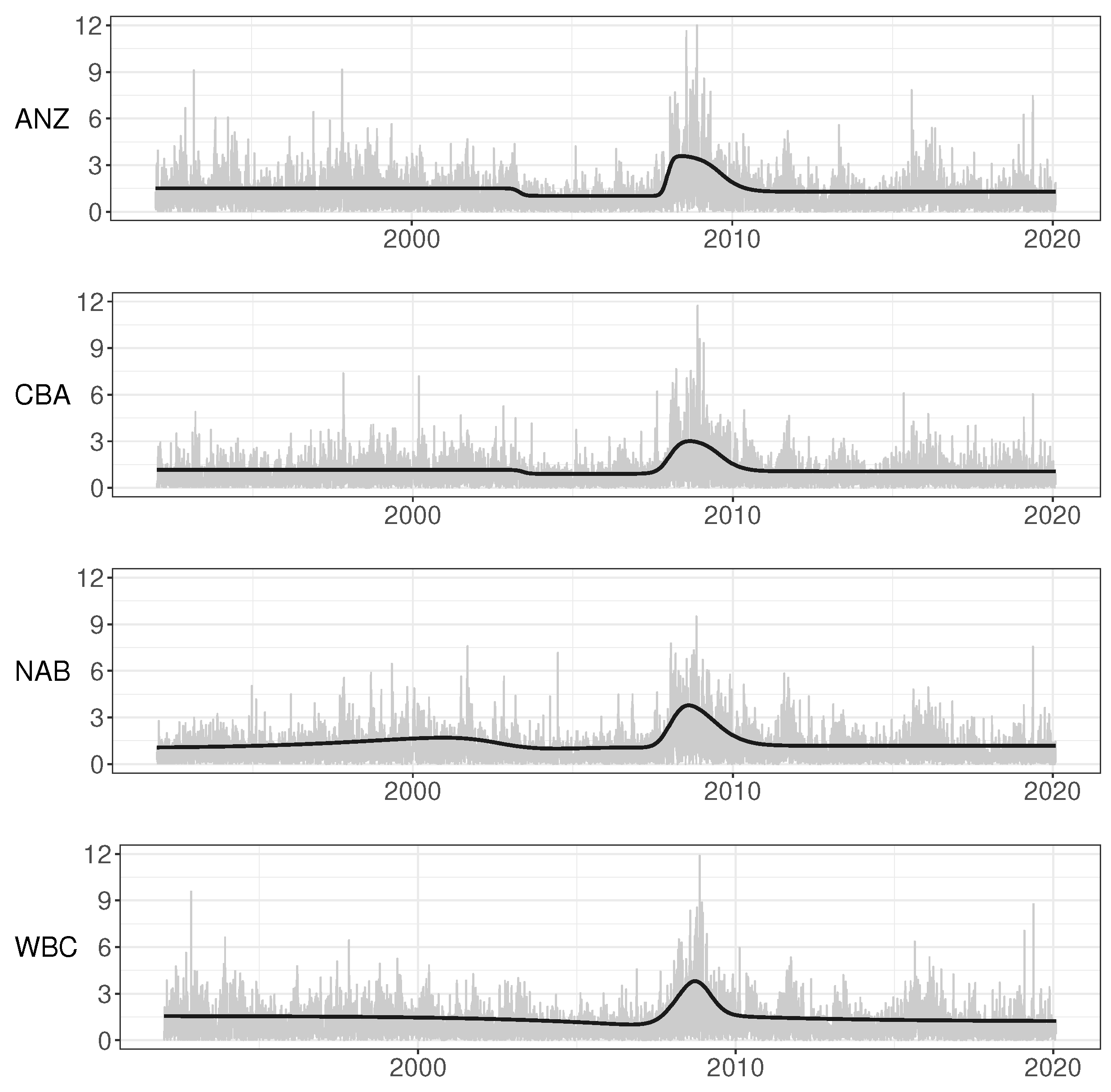
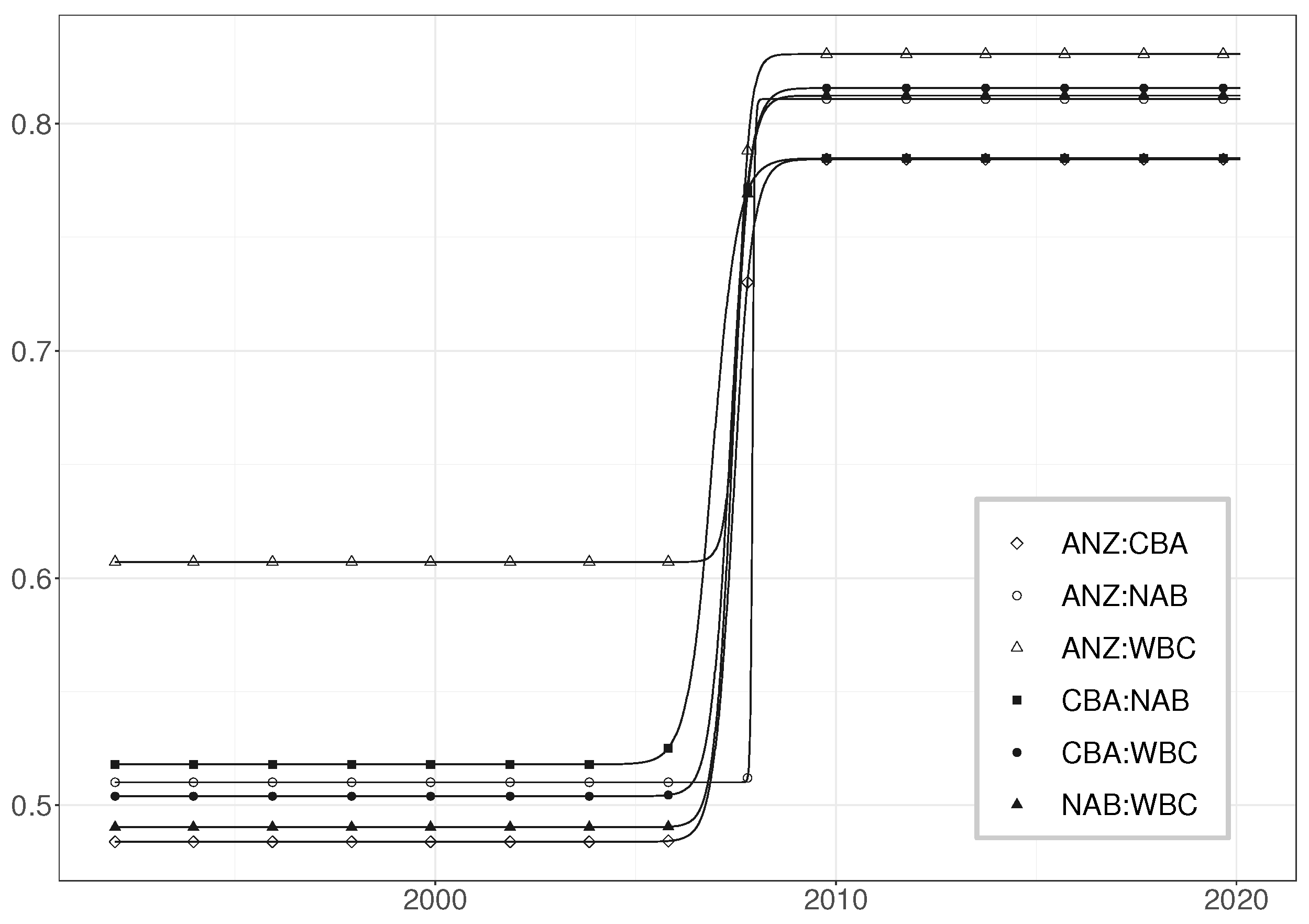
The baseline volatility may be very different in different series. Therefore, one should not ignore visual inspection of the returns nor rely on general rules of thumb. If there are sufficiently long sections of data where the general level of volatility remains constant, it is advisable to estimate the GARCH parameters over such subsample. In the present case, there are a couple of relatively constant volatility sections—for example, one from November 2003 until October 2007.
The parameter estimates for that calm subperiod are in
Table A1. Comparison with the estimates from the entire period GARCH model makes it clear that the neglected nonstationarity has biased the estimates, resulting in high persistence and kurtosis. As the data set has a sufficiently long span of GARCH-type clustering without (visually) significant movement in the general baseline level, relevant estimates are obtained by using that subsample only.
Another approach consists of estimating the GARCH equation over a rolling window such that the intercept is time-varying, targeting the unconditional volatility over each window, while the other parameters are assumed to be constant over the entire sample period and estimated in the usual way. The choice of the window length should consider the general recommendations regarding the sample size when attempting GARCH estimation. Too long a window will be impacted by the slowly changing baseline volatility level, whereas too short a window will yield very uncertain GARCH estimates.
To investigate the properties of this approach, we ran a simulation experiment with a few different baseline volatilities. The window widths varied from 250 to 1000 observations.
Figure A1,
Figure A2 and
Figure A3 depict the distributions of the GARCH estimates and the derived persistence and kurtosis measures, as explained in
He and Teräsvirta (
1999), for a selection of baseline volatilities and window widths. Based on these experiments, we concluded that a window width of 400 observations yields sufficiently robust results for our application.
The resulting GARCH estimates are reported in
Table A1, and they are quite similar to the ones obtained for the aforementioned calm period. This can be interpreted as support for the rolling window method, particularly in situations where visual inspection of data does not reveal a sufficiently long period of constant unconditional volatility.
Overall, it is clear that using simply the GARCH estimates from the entire sample to calibrate the null distribution of the test statistic for the specification of the deterministic component of the volatility is not recommended. For comparison,
Table A1 also reports the GARCH estimates from a TV-GARCH model where the TV specification has been completed. The estimated persistence is higher than the ones obtained from the calm period or rolling window variance targeting method, however, as discussed in
Silvennoinen and Teräsvirta (
2016), underestimation of persistence has a less severe impact on the performance of the TV specification test than does overestimation.
Table A1.
Specification stage for the deterministic component in volatilities of each of the four banks. and are the initial estimates used for calibrating the test statistic distribution. The rolling window method allows the GARCH intercept to adjust to target the unconditional variance in a window of size 400. The ‘calm period’ selects the continuous period from November 2003 to October 2007, which has very little visible variation in the baseline volatility. For comparison, the GARCH estimates from the entire sample period are reported along with the final estimates from the TV-GARCH model.
Table A1.
Specification stage for the deterministic component in volatilities of each of the four banks. and are the initial estimates used for calibrating the test statistic distribution. The rolling window method allows the GARCH intercept to adjust to target the unconditional variance in a window of size 400. The ‘calm period’ selects the continuous period from November 2003 to October 2007, which has very little visible variation in the baseline volatility. For comparison, the GARCH estimates from the entire sample period are reported along with the final estimates from the TV-GARCH model.
| | | | | Persistence | Kurtosis |
|---|
| Rolling window 400 | ANZ | 0.090 | 0.836 | 0.926 | 3.38 |
| CBA | 0.087 | 0.850 | 0.937 | 3.43 |
| NAB | 0.095 | 0.817 | 0.912 | 3.36 |
| WBC | 0.085 | 0.858 | 0.943 | 3.45 |
| Calm period | ANZ | 0.073 | 0.852 | 0.925 | 3.24 |
| CBA | 0.081 | 0.842 | 0.923 | 3.29 |
| NAB | 0.066 | 0.829 | 0.896 | 3.14 |
| WBC | 0.091 | 0.806 | 0.897 | 3.28 |
| Entire period GARCH only | ANZ | 0.065 | 0.927 | 0.992 | 6.40 |
| CBA | 0.089 | 0.890 | 0.979 | 4.83 |
| NAB | 0.104 | 0.867 | 0.971 | 4.85 |
| WBC | 0.075 | 0.911 | 0.986 | 5.08 |
| Entire period TV-GARCH | ANZ | 0.078 | 0.880 | 0.957 | 3.50 |
| CBA | 0.091 | 0.860 | 0.950 | 3.61 |
| NAB | 0.107 | 0.825 | 0.931 | 3.62 |
| WBC | 0.084 | 0.878 | 0.962 | 3.70 |
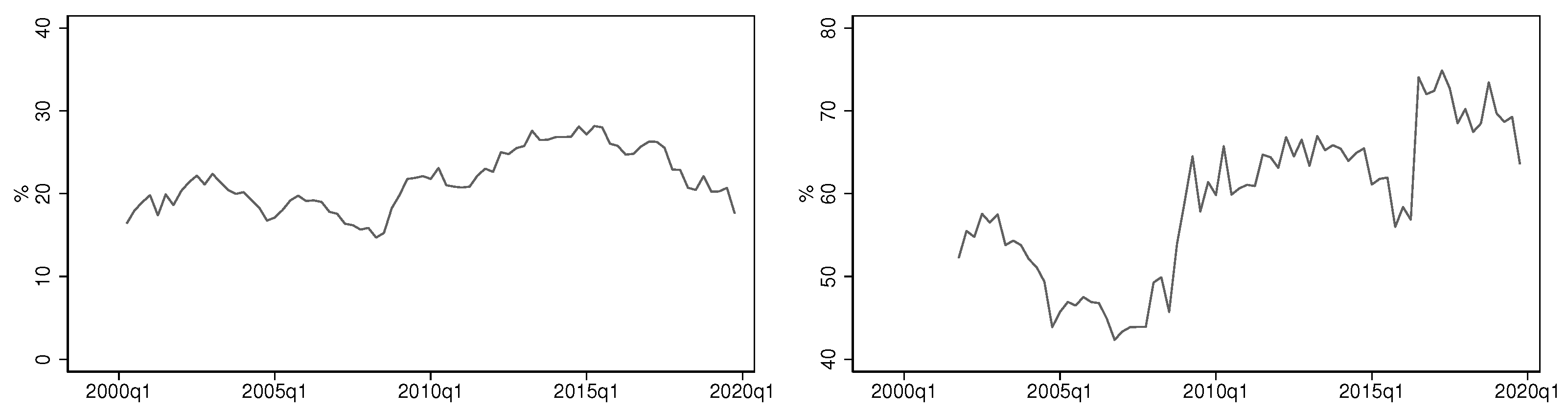
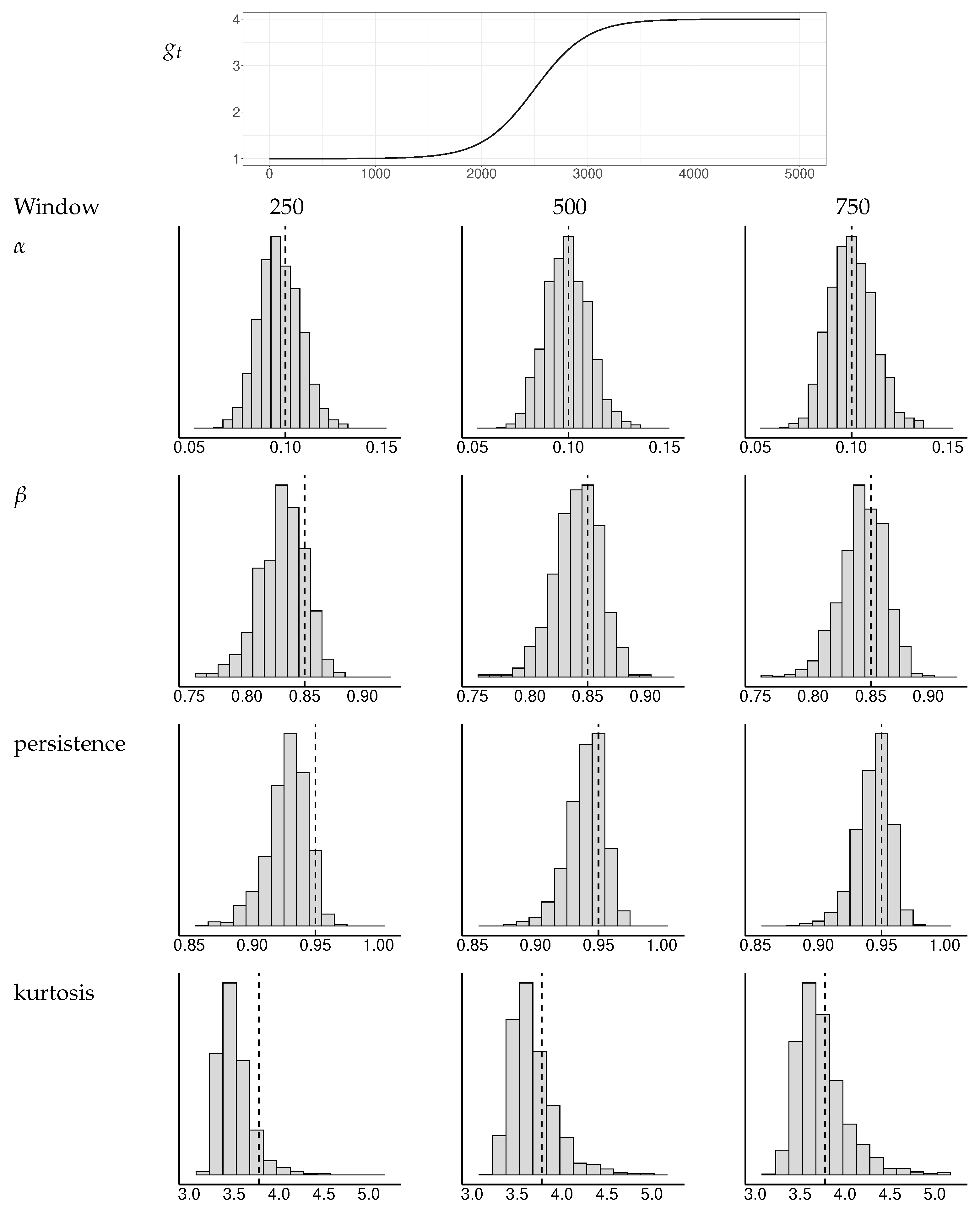
Figure A1.
Simulated distributions of GARCH estimates and implied persistence and kurtosis measures for a selection of window widths. The baseline has a single transition. The dotted vertical lines indicate the true values of the parameters , , persistence, and kurtosis.
Figure A1.
Simulated distributions of GARCH estimates and implied persistence and kurtosis measures for a selection of window widths. The baseline has a single transition. The dotted vertical lines indicate the true values of the parameters , , persistence, and kurtosis.
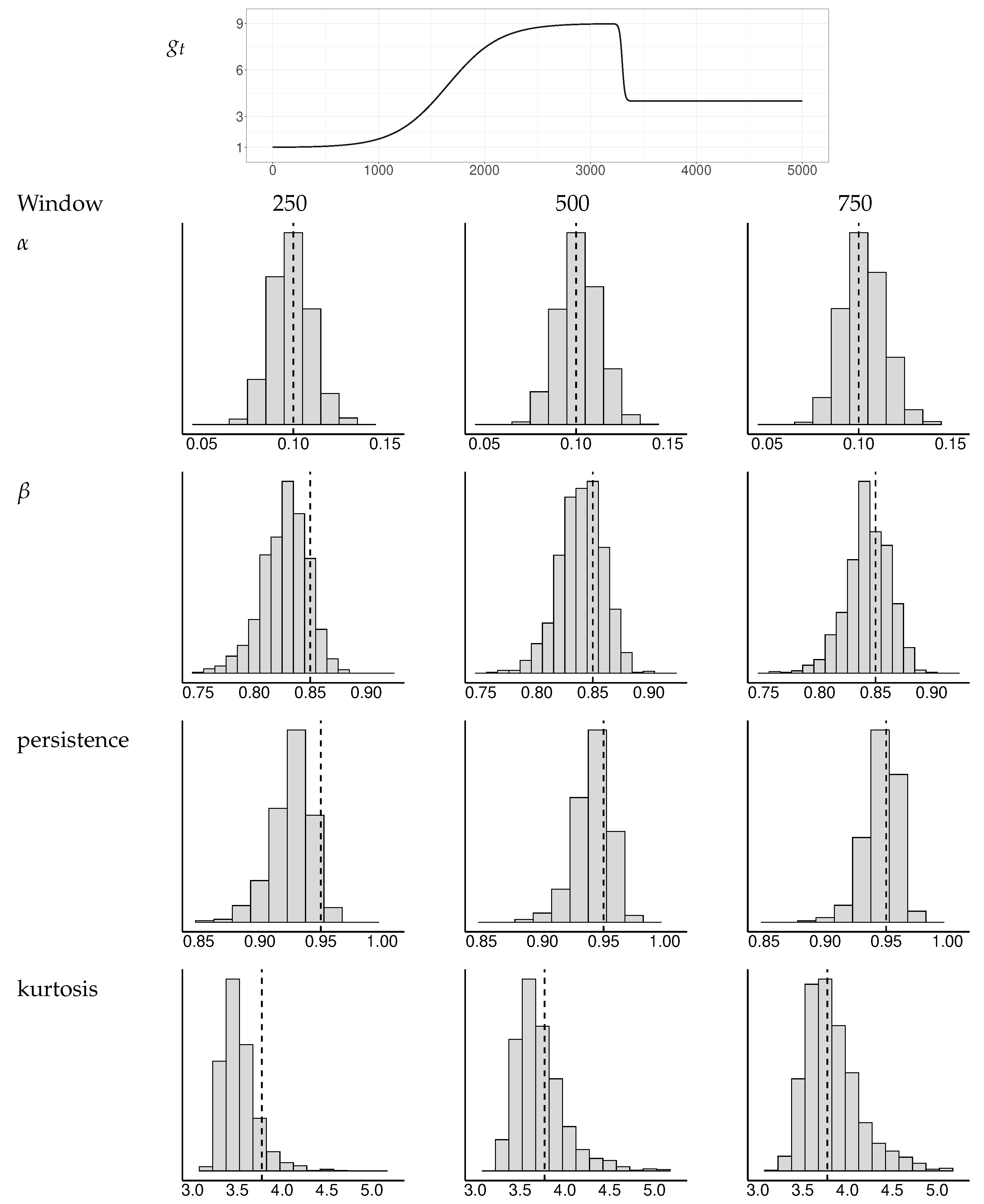
Figure A2.
Simulated distributions of GARCH estimates and implied persistence and kurtosis measures for a selection of window widths. The baseline has an asymmetric double transition. The dotted vertical lines indicate the true values of the parameters , , persistence, and kurtosis.
Figure A2.
Simulated distributions of GARCH estimates and implied persistence and kurtosis measures for a selection of window widths. The baseline has an asymmetric double transition. The dotted vertical lines indicate the true values of the parameters , , persistence, and kurtosis.
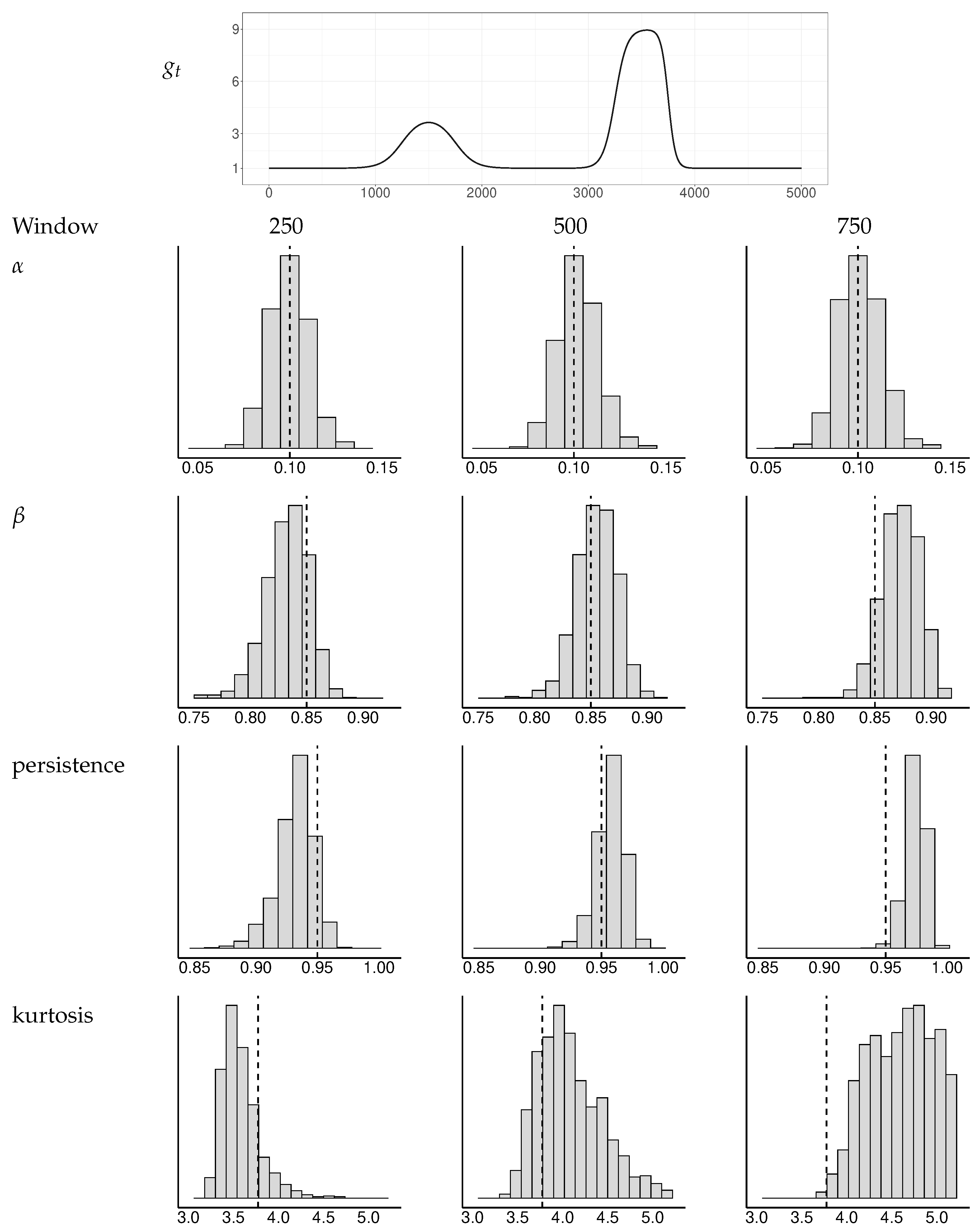
Figure A3.
Simulated distributions of GARCH estimates and implied persistence and kurtosis measures for a selection of window widths. The baseline has two double transitions. The dotted vertical lines indicate the true values of the parameters , , persistence, and kurtosis.
Figure A3.
Simulated distributions of GARCH estimates and implied persistence and kurtosis measures for a selection of window widths. The baseline has two double transitions. The dotted vertical lines indicate the true values of the parameters , , persistence, and kurtosis.
Appendix B.2. Evaluation Tests of GARCH Equations
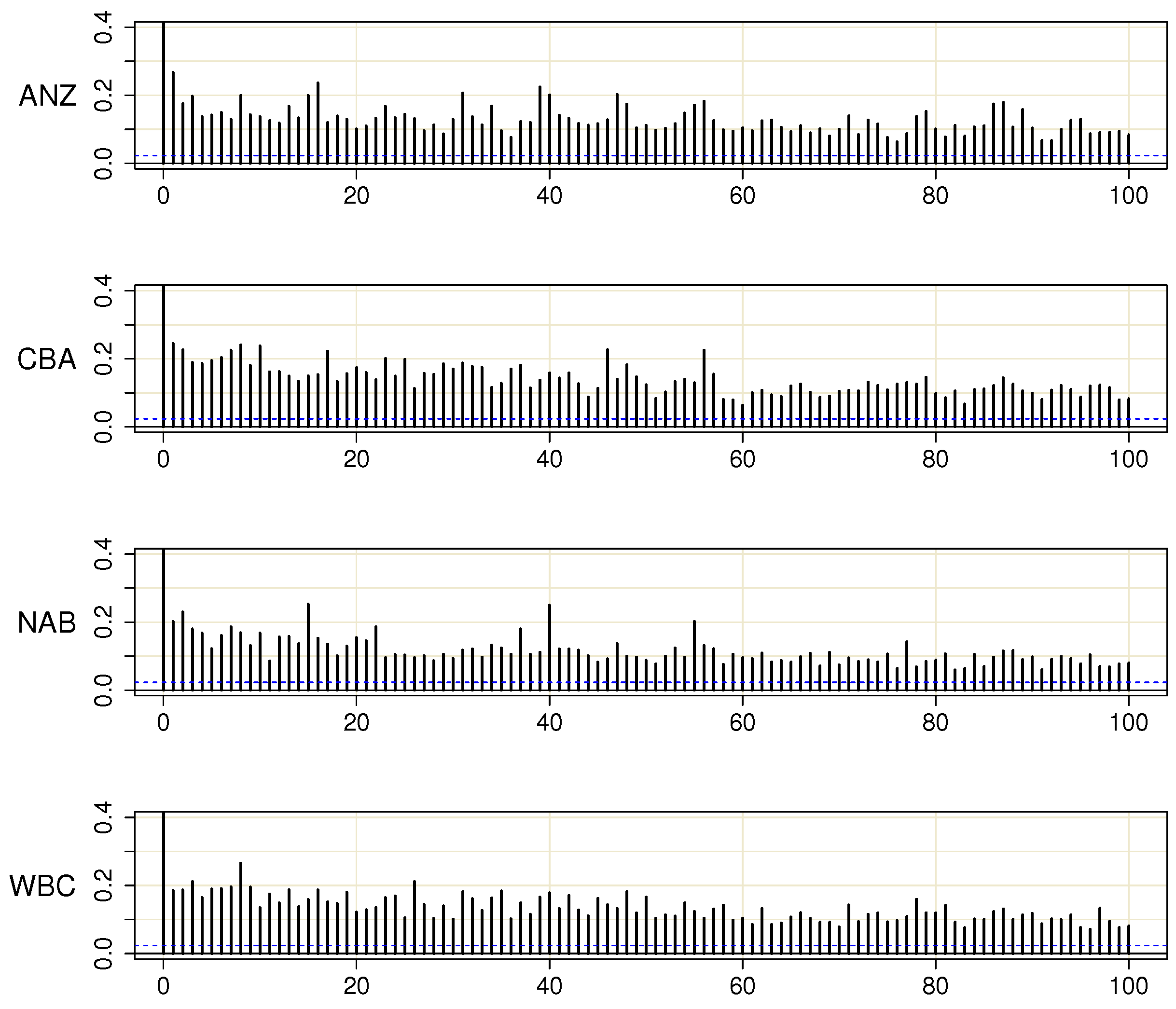
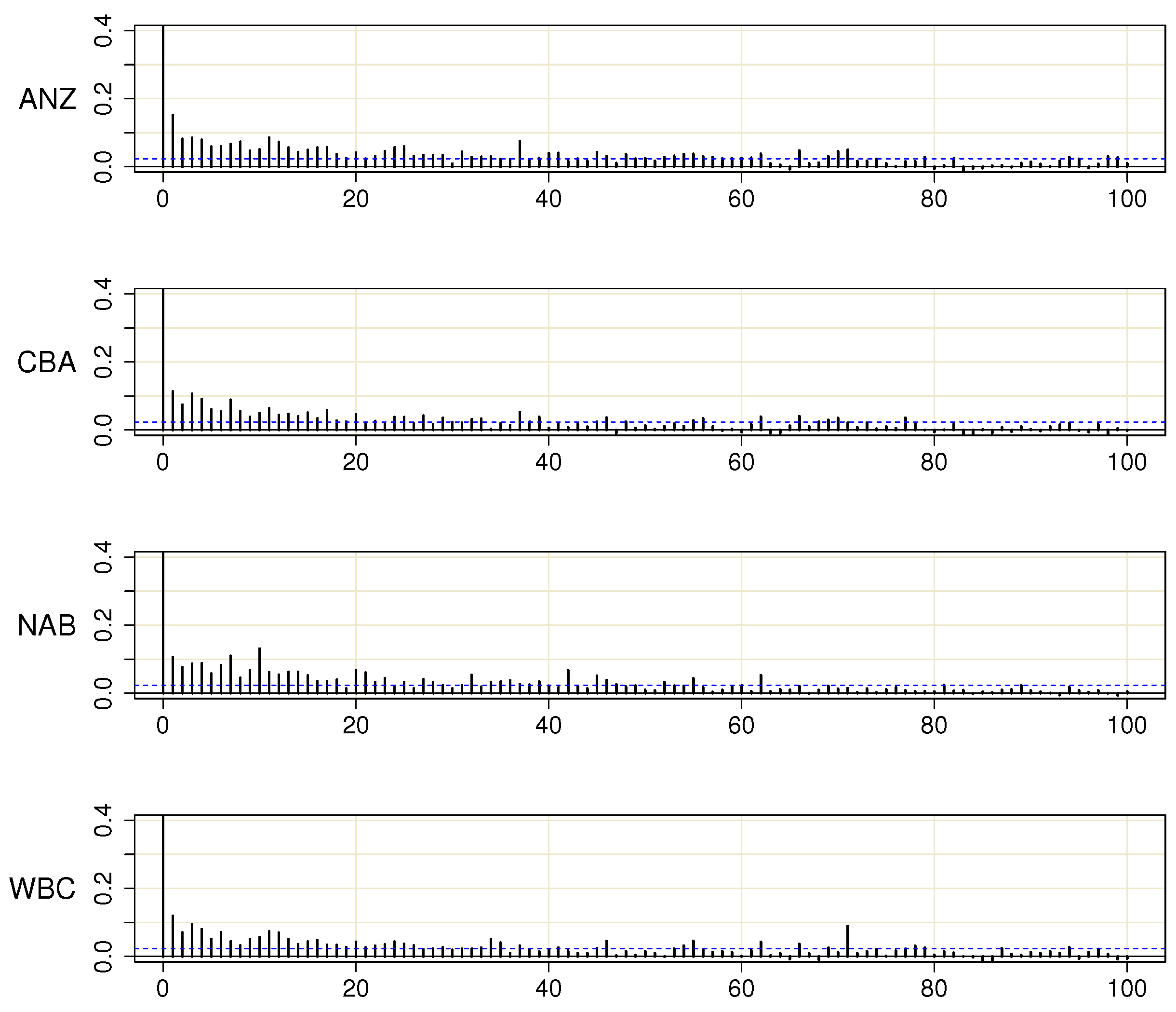
The fact that the evaluation tests discussed in
Appendix A.2 are applied to the pre-filtered data
is known to potentially alter the distribution of the test statistic. In this section, we present simulation results that show that the size of the tests remains practically unchanged, rendering the tests applicable in the proposed way.
The simulation uses 2000 observations on a bivariate TVGARCH model parametrised as , . These are coupled with a CCC model with , and then with an STCC model parametrised as , , . The noise terms are iid standard normal. Two estimation procedures were used, a two-step and a multi-step one.
- First step
The individual TVGARCH models are estimated, assuming the series are uncorrelated.
- Second step
Estimate the correlation model conditional on the volatility model estimates from the previous step. Then, estimate the TVGARCH models conditional on the correlation estimates.
The misspecification tests are then calculated using the TVGARCH estimates from the second step, and the data is pre-filtered with the correlation estimates from the second step. The multi-step continues repeating the procedure of the second step until no further improvements are achieved.
Table A2.
Size simulation for the three types of misspecification tests in
Amado and Teräsvirta (
2017). 2000 replications.
,
. MS1:
additively misspecified, alternative linearised with a first-order term only; MS2-a: GARCH(1,1) vs. GARCH(1,2); MS2-b: GARCH(1,1) vs. GARCH(2,1); MS3: test for remaining ARCH, lag 1.
Table A2.
Size simulation for the three types of misspecification tests in
Amado and Teräsvirta (
2017). 2000 replications.
,
. MS1:
additively misspecified, alternative linearised with a first-order term only; MS2-a: GARCH(1,1) vs. GARCH(1,2); MS2-b: GARCH(1,1) vs. GARCH(2,1); MS3: test for remaining ARCH, lag 1.
| | | Standard | Robust |
|---|
| | | 10% | 5% | 1% | 10% | 5% | 1% |
|---|
| CCC two-step | MS1 | 0.146 | 0.085 | 0.020 | 0.132 | 0.074 | 0.016 |
| | MS2-a | 0.122 | 0.064 | 0.012 | 0.101 | 0.048 | 0.013 |
| | MS2-b | 0.143 | 0.080 | 0.017 | 0.108 | 0.051 | 0.008 |
| | MS3 | 0.125 | 0.061 | 0.010 | 0.104 | 0.054 | 0.010 |
| STCC two-step | MS1 | 0.134 | 0.074 | 0.023 | 0.121 | 0.055 | 0.015 |
| | MS2-a | 0.123 | 0.059 | 0.015 | 0.101 | 0.045 | 0.013 |
| | MS2-b | 0.122 | 0.062 | 0.019 | 0.087 | 0.044 | 0.010 |
| | MS3 | 0.115 | 0.058 | 0.015 | 0.100 | 0.050 | 0.011 |
| CCC multi-step | MS1 | 0.145 | 0.083 | 0.022 | 0.133 | 0.073 | 0.014 |
| | MS2-a | 0.116 | 0.062 | 0.015 | 0.097 | 0.052 | 0.009 |
| | MS2-b | 0.133 | 0.069 | 0.018 | 0.100 | 0.046 | 0.010 |
| | MS3 | 0.120 | 0.062 | 0.016 | 0.107 | 0.060 | 0.014 |
| STCC multi-step | MS1 | 0.147 | 0.084 | 0.023 | 0.135 | 0.068 | 0.012 |
| | MS2-a | 0.130 | 0.059 | 0.011 | 0.103 | 0.046 | 0.006 |
| | MS2-b | 0.120 | 0.067 | 0.016 | 0.090 | 0.039 | 0.005 |
| | MS3 | 0.112 | 0.055 | 0.012 | 0.104 | 0.047 | 0.009 |
From
Table A2, it is evident that the standard form of the tests is slightly oversized. The robust version of the tests, on the other hand, seems to behave well, and there is no need for any adjustments of the test statistics or their distributions. Therefore, the procedure of removing the correlations between the series prior to applying the evaluation tests can be recommended.
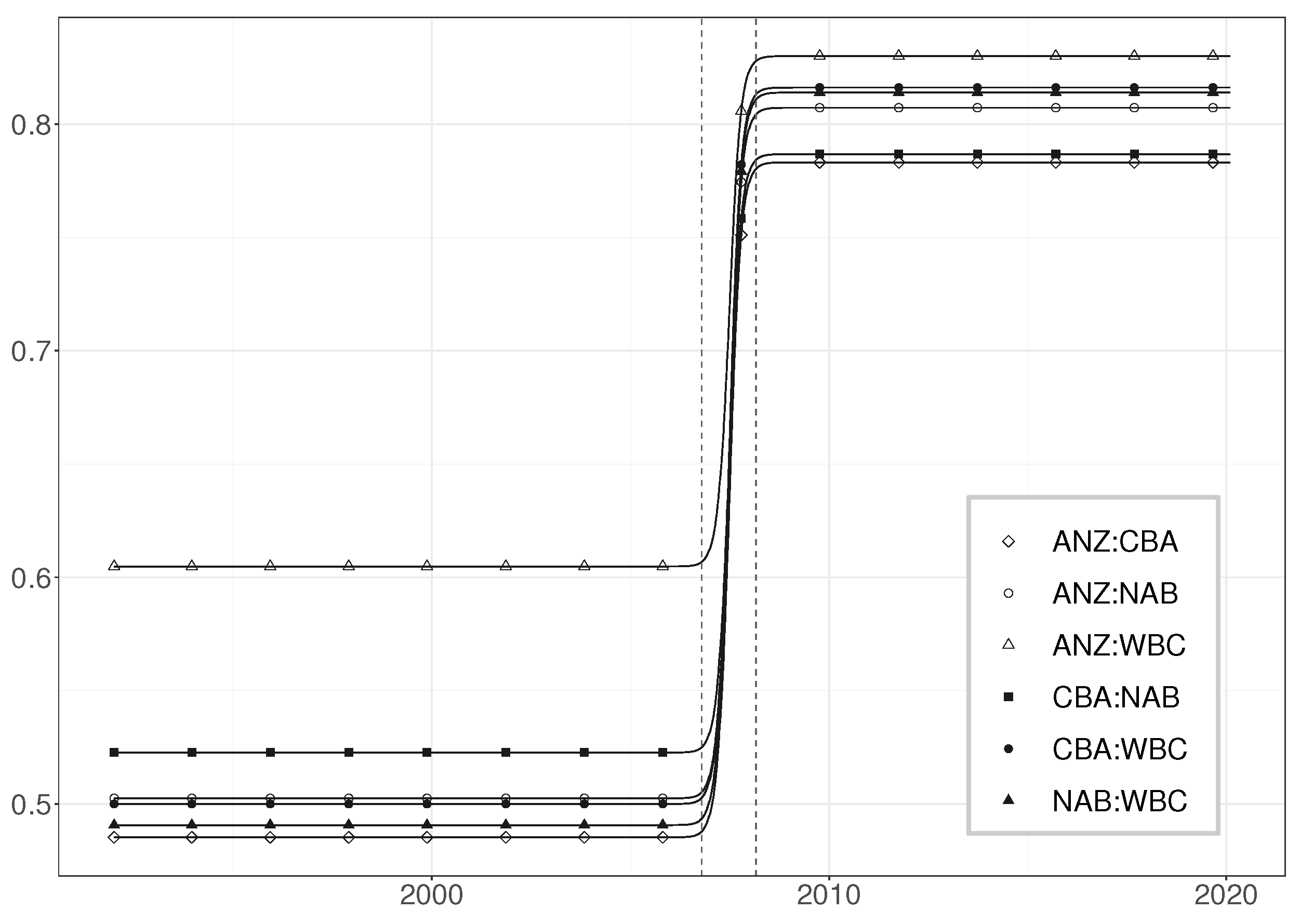
Appendix B.3. Tests of Correlations
The simulation experiment investigates the size of the test in an environment where the multivariate model is correctly specified. The number of data series considered in the system is . The length varies from for the bivariate systems, which is relevant for time series systems in macro applications, up to , which, in turn, is considered to be a fairly small sample size for high frequency returns data. The length of the time series places a constraint on the dimension of the model—that is, the parametric alternative is only feasible if the number of parameters remains comfortably below the amount of available data points. We simulated the test by both assuming that and that there is conditional heteroskedasticity in the model: .
When
we found that the results were fairly independent of the structure of the correlations. We used both equicorrelation and Toeplitz matrices in our simulations, and the results remained the same.
Table A3 contains the results of a simulation in which
, and the
correlation matrix
is an equicorrelated one with weak (
) and moderately strong (
) correlation. The table also reports the results from using a Toeplitz correlation matrix such that
with
representing moderate to weak correlation and
representing strong to moderate correlation. It is seen that the empirical size of the test is rather close to the nominal one already when
and
. The size holds up across the various correlation patterns.
Table A3.
Size-study: Test of constant correlations. Data are generated as an MTV-CCC with an equicorrelation coefficient of 0.33 (CEC33) and 0.67 (CEC67) and a Toeplitz structure with a correlation coefficient of 0.5 (CTC50) and 0.9 (CTC90). Tests are based on the first-order polynomial approximation. A total of 5000 replications.
Table A3.
Size-study: Test of constant correlations. Data are generated as an MTV-CCC with an equicorrelation coefficient of 0.33 (CEC33) and 0.67 (CEC67) and a Toeplitz structure with a correlation coefficient of 0.5 (CTC50) and 0.9 (CTC90). Tests are based on the first-order polynomial approximation. A total of 5000 replications.
| | | CEC33 | CEC67 | CTC50 | CTC90 |
|---|
| N | T | 1% | 5% | 10% | 1% | 5% | 10% | 1% | 5% | 10% | 1% | 5% | 10% |
|---|
| 2 | 25 | 0.023 | 0.076 | 0.132 | 0.022 | 0.069 | 0.128 | 0.024 | 0.074 | 0.130 | 0.022 | 0.070 | 0.126 |
| | 50 | 0.015 | 0.063 | 0.116 | 0.016 | 0.064 | 0.115 | 0.016 | 0.064 | 0.115 | 0.015 | 0.062 | 0.109 |
| | 100 | 0.011 | 0.056 | 0.104 | 0.010 | 0.054 | 0.102 | 0.011 | 0.056 | 0.103 | 0.010 | 0.051 | 0.101 |
| | 250 | 0.012 | 0.055 | 0.108 | 0.010 | 0.054 | 0.107 | 0.011 | 0.055 | 0.106 | 0.009 | 0.053 | 0.108 |
| | 500 | 0.010 | 0.051 | 0.097 | 0.009 | 0.049 | 0.097 | 0.010 | 0.050 | 0.096 | 0.009 | 0.050 | 0.094 |
| | 1000 | 0.010 | 0.048 | 0.099 | 0.010 | 0.048 | 0.095 | 0.010 | 0.046 | 0.097 | 0.010 | 0.049 | 0.092 |
| 5 | 100 | 0.011 | 0.054 | 0.112 | 0.011 | 0.053 | 0.110 | 0.011 | 0.056 | 0.112 | 0.011 | 0.053 | 0.111 |
| | 250 | 0.014 | 0.054 | 0.099 | 0.012 | 0.051 | 0.099 | 0.013 | 0.053 | 0.100 | 0.012 | 0.051 | 0.101 |
| | 500 | 0.010 | 0.050 | 0.104 | 0.010 | 0.053 | 0.106 | 0.009 | 0.052 | 0.101 | 0.010 | 0.054 | 0.105 |
| | 1000 | 0.010 | 0.056 | 0.102 | 0.010 | 0.052 | 0.103 | 0.009 | 0.053 | 0.100 | 0.008 | 0.053 | 0.103 |
| 10 | 250 | 0.013 | 0.055 | 0.112 | 0.013 | 0.057 | 0.112 | 0.013 | 0.057 | 0.110 | 0.012 | 0.054 | 0.115 |
| | 500 | 0.009 | 0.049 | 0.101 | 0.010 | 0.049 | 0.104 | 0.008 | 0.053 | 0.103 | 0.010 | 0.050 | 0.103 |
| | 1000 | 0.011 | 0.052 | 0.102 | 0.011 | 0.054 | 0.105 | 0.011 | 0.053 | 0.099 | 0.012 | 0.056 | 0.103 |
| 20 | 1000 | 0.012 | 0.056 | 0.106 | 0.012 | 0.057 | 0.106 | 0.013 | 0.056 | 0.103 | 0.012 | 0.056 | 0.107 |
We next turn to the case
.
Table A4 and
Table A5 contain results of size simulations where the sensitivity of the test is examined against combinations for the GARCH persistence and kurtosis as well as a selection of strengths of correlations (the equicorrelated and Toepliz ones described above). The test is generally well-sized.
Table A4.
Size-study: Test of constant correlations. Data are generated as an MTV-GARCH-CEC with persistence of 0.95 and 0.97, kurtosis of 4 and 6, and an equicorrelation coefficient of 0.33 and 0.67. Tests are based on the first-order polynomial approximation. A total of 2500 replications.
Table A4.
Size-study: Test of constant correlations. Data are generated as an MTV-GARCH-CEC with persistence of 0.95 and 0.97, kurtosis of 4 and 6, and an equicorrelation coefficient of 0.33 and 0.67. Tests are based on the first-order polynomial approximation. A total of 2500 replications.
| | | | CEC33 | CEC67 |
|---|
| | | | kurtosis = 4 | kurtosis = 6 | kurtosis = 4 | kurtosis = 6 |
|---|
| Persistence | N | T | 1% | 5% | 10% | 1% | 5% | 10% | 1% | 5% | 10% | 1% | 5% | 10% |
|---|
| 0.95 | 2 | 500 | 0.012 | 0.056 | 0.108 | 0.016 | 0.056 | 0.106 | 0.016 | 0.070 | 0.122 | 0.016 | 0.092 | 0.122 |
| | 2 | 1000 | 0.009 | 0.044 | 0.103 | 0.009 | 0.042 | 0.097 | 0.011 | 0.045 | 0.093 | 0.009 | 0.044 | 0.097 |
| | 2 | 2000 | 0.008 | 0.042 | 0.094 | 0.007 | 0.042 | 0.090 | 0.010 | 0.052 | 0.099 | 0.009 | 0.046 | 0.092 |
| | 5 | 500 | 0.006 | 0.062 | 0.118 | 0.006 | 0.070 | 0.114 | 0.018 | 0.076 | 0.140 | 0.018 | 0.082 | 0.146 |
| | 5 | 1000 | 0.016 | 0.060 | 0.119 | 0.016 | 0.061 | 0.112 | 0.016 | 0.059 | 0.115 | 0.018 | 0.060 | 0.112 |
| | 5 | 2000 | 0.010 | 0.058 | 0.108 | 0.008 | 0.051 | 0.102 | 0.016 | 0.060 | 0.116 | 0.010 | 0.052 | 0.098 |
| | 10 | 500 | 0.016 | 0.058 | 0.118 | 0.020 | 0.064 | 0.114 | 0.020 | 0.068 | 0.116 | 0.024 | 0.080 | 0.128 |
| | 10 | 1000 | 0.018 | 0.053 | 0.104 | 0.015 | 0.051 | 0.101 | 0.014 | 0.061 | 0.111 | 0.017 | 0.063 | 0.110 |
| | 10 | 2000 | 0.014 | 0.072 | 0.126 | 0.012 | 0.060 | 0.112 | 0.018 | 0.082 | 0.142 | 0.013 | 0.062 | 0.118 |
| 0.97 | 2 | 500 | 0.010 | 0.056 | 0.114 | 0.012 | 0.054 | 0.118 | 0.020 | 0.072 | 0.114 | 0.014 | 0.068 | 0.120 |
| | 2 | 1000 | 0.011 | 0.043 | 0.102 | 0.011 | 0.044 | 0.103 | 0.012 | 0.047 | 0.107 | 0.013 | 0.048 | 0.103 |
| | 2 | 2000 | 0.009 | 0.046 | 0.094 | 0.007 | 0.042 | 0.089 | 0.010 | 0.056 | 0.108 | 0.012 | 0.050 | 0.093 |
| | 5 | 500 | 0.004 | 0.066 | 0.124 | 0.012 | 0.056 | 0.104 | 0.012 | 0.088 | 0.152 | 0.018 | 0.086 | 0.164 |
| | 5 | 1000 | 0.015 | 0.063 | 0.113 | 0.014 | 0.067 | 0.114 | 0.018 | 0.063 | 0.121 | 0.019 | 0.060 | 0.125 |
| | 5 | 2000 | 0.010 | 0.060 | 0.110 | 0.008 | 0.050 | 0.100 | 0.015 | 0.060 | 0.118 | 0.012 | 0.050 | 0.101 |
| | 10 | 500 | 0.012 | 0.062 | 0.108 | 0.016 | 0.070 | 0.112 | 0.016 | 0.072 | 0.112 | 0.022 | 0.086 | 0.148 |
| | 10 | 1000 | 0.016 | 0.053 | 0.100 | 0.015 | 0.056 | 0.107 | 0.015 | 0.063 | 0.113 | 0.018 | 0.057 | 0.110 |
| | 10 | 2000 | 0.015 | 0.074 | 0.132 | 0.014 | 0.058 | 0.108 | 0.016 | 0.088 | 0.142 | 0.010 | 0.063 | 0.112 |
Table A5.
Size-study: Test of constant correlations. Data are generated as an MTV-GARCH-CTC with persistence of 0.95 and 0.97, kurtosis of 4 and 6, and a correlation matrix with a Toeplitz structure with a correlation coefficient of 0.5 and 0.9. Tests are based on the first-order polynomial approximation. A total of 2500 replications.
Table A5.
Size-study: Test of constant correlations. Data are generated as an MTV-GARCH-CTC with persistence of 0.95 and 0.97, kurtosis of 4 and 6, and a correlation matrix with a Toeplitz structure with a correlation coefficient of 0.5 and 0.9. Tests are based on the first-order polynomial approximation. A total of 2500 replications.
| | | | CTC50 | CTC90 |
|---|
| | | | kurtosis = 4 | kurtosis = 6 | kurtosis = 4 | kurtosis = 6 |
|---|
| Persistence | N | T | 1% | 5% | 10% | 1% | 5% | 10% | 1% | 5% | 10% | 1% | 5% | 10% |
|---|
| 0.95 | 2 | 500 | 0.010 | 0.064 | 0.102 | 0.010 | 0.070 | 0.106 | 0.018 | 0.094 | 0.136 | 0.026 | 0.088 | 0.146 |
| | 2 | 1000 | 0.009 | 0.041 | 0.097 | 0.011 | 0.042 | 0.103 | 0.014 | 0.053 | 0.096 | 0.020 | 0.062 | 0.104 |
| | 2 | 2000 | 0.008 | 0.044 | 0.096 | 0.009 | 0.044 | 0.090 | 0.017 | 0.066 | 0.120 | 0.014 | 0.048 | 0.098 |
| | 5 | 500 | 0.006 | 0.062 | 0.118 | 0.010 | 0.058 | 0.114 | 0.020 | 0.120 | 0.212 | 0.050 | 0.134 | 0.210 |
| | 5 | 1000 | 0.014 | 0.060 | 0.112 | 0.018 | 0.064 | 0.113 | 0.027 | 0.076 | 0.134 | 0.034 | 0.093 | 0.144 |
| | 5 | 2000 | 0.011 | 0.057 | 0.110 | 0.008 | 0.052 | 0.105 | 0.020 | 0.075 | 0.142 | 0.018 | 0.058 | 0.110 |
| | 10 | 500 | 0.012 | 0.070 | 0.120 | 0.016 | 0.080 | 0.128 | 0.040 | 0.114 | 0.172 | 0.078 | 0.150 | 0.230 |
| | 10 | 1000 | 0.012 | 0.049 | 0.100 | 0.013 | 0.051 | 0.102 | 0.019 | 0.078 | 0.127 | 0.032 | 0.089 | 0.147 |
| | 10 | 2000 | 0.019 | 0.072 | 0.127 | 0.014 | 0.059 | 0.111 | 0.033 | 0.110 | 0.178 | 0.018 | 0.077 | 0.140 |
| 0.97 | 2 | 500 | 0.014 | 0.066 | 0.114 | 0.018 | 0.068 | 0.116 | 0.016 | 0.082 | 0.134 | 0.030 | 0.104 | 0.164 |
| | 2 | 1000 | 0.009 | 0.044 | 0.101 | 0.008 | 0.042 | 0.099 | 0.016 | 0.051 | 0.112 | 0.022 | 0.063 | 0.119 |
| | 2 | 2000 | 0.010 | 0.050 | 0.102 | 0.009 | 0.044 | 0.092 | 0.024 | 0.070 | 0.120 | 0.015 | 0.052 | 0.100 |
| | 5 | 500 | 0.014 | 0.056 | 0.128 | 0.008 | 0.074 | 0.130 | 0.024 | 0.134 | 0.208 | 0.052 | 0.160 | 0.256 |
| | 5 | 1000 | 0.013 | 0.059 | 0.112 | 0.016 | 0.066 | 0.123 | 0.022 | 0.082 | 0.157 | 0.037 | 0.102 | 0.164 |
| | 5 | 2000 | 0.014 | 0.062 | 0.112 | 0.010 | 0.052 | 0.101 | 0.028 | 0.086 | 0.145 | 0.020 | 0.066 | 0.116 |
| | 10 | 500 | 0.018 | 0.080 | 0.128 | 0.022 | 0.088 | 0.130 | 0.040 | 0.114 | 0.172 | 0.100 | 0.188 | 0.278 |
| | 10 | 1000 | 0.012 | 0.054 | 0.105 | 0.013 | 0.054 | 0.107 | 0.019 | 0.078 | 0.127 | 0.030 | 0.104 | 0.181 |
| | 10 | 2000 | 0.016 | 0.072 | 0.132 | 0.016 | 0.062 | 0.110 | 0.033 | 0.110 | 0.178 | 0.026 | 0.089 | 0.150 |
However, an interesting aspect is that there is slight oversizing when kurtosis decreases (which means shifting the relative weight from to in the GARCH equation, while keeping the persistence constant). A change in persistence does not seem to affect the size of the test. As the dimension of the system increases, the test does not perform equally well. Increasing the sample size does not seem to be able to counteract this (the simulations use ).
In yet another simulation (results not reported here), we considered the effects of misspecifying the conditional heteroskedasticity on the correlation test. More specifically, when but conditional heteroskedasticity is ignored, the test is, as may be expected, heavily oversized. The obvious conclusion is that the constancy of correlations can only be tested after specifying and estimating both and .



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











