
Extraction of Hidden Authentication Factors from Possessive Information


Abstract
:1. Introduction
- The efficacy of an authentication system based on seven physiological and biological biometrics derived from commonly used personal behavioral biometrics.
- The discovery of self-classifying alphabets using individual data is made.
- The development of a security system based on several biometric measurements of an individual’s profile information that is useful for the duration of the individual’s life.
2. Different Attacks on Biometric Authentication Models
3. System Model
Adversary Model
4. Proposed System and Methodology Used
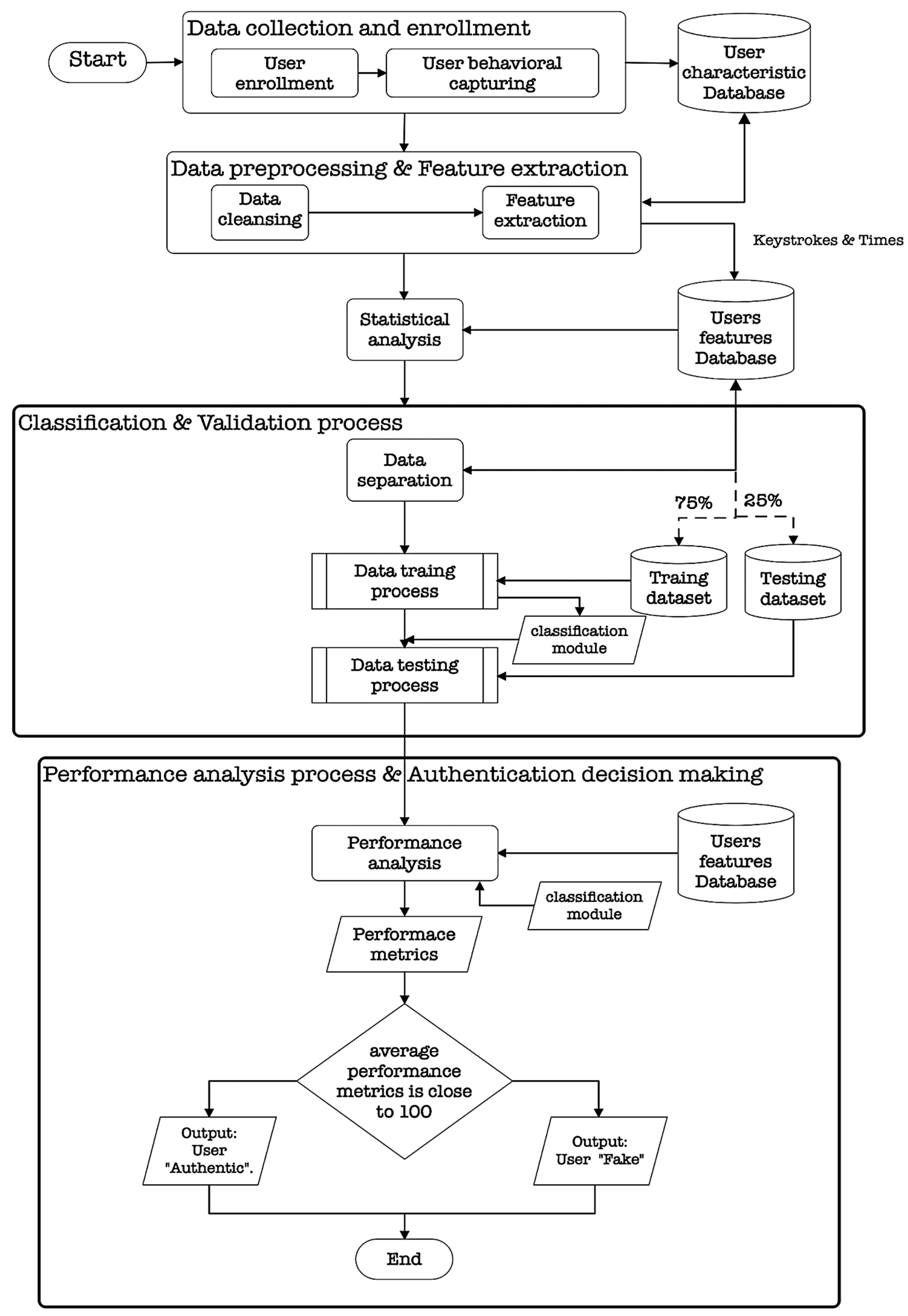
4.1. Data Collection and Enrollment Phase
4.2. User Authentication Phase
4.2.1. Data Preprocessing and Feature Extraction
- (a)
- Dwell Time: Dwell time represents the time interval between pressing and releasing a key.
- (b)
- Interval Time: Interval time measures the duration between consecutive key presses.
- (c)
- Latency Time: Latency time denotes the delay between pressing a key and the display of the corresponding character on the screen.
- (d)
- Flight Time: Flight time quantifies the duration between releasing one key and pressing the next key.
- (e)
- Up to Up Time: Up to up time captures the duration between releasing one key and releasing the subsequent key.
4.2.2. Statistical Analysis
4.2.3. Classification and Validation
5. Experimental Setup and Performance Metrics
- This experiment’s intended audience consisted of individuals who regularly use smartphones. To prevent bias in the evaluation procedure, the sample was selected at random under strict control conditions.
- To safeguard the participants’ confidential information, pseudonyms were used in lieu of their actual identities.
- The data capture process involved using mobile devices, specifically the iPhone 7, which has a touchscreen and additional sensors such as a light sensor, proximity sensor, accelerometer, barometer, and gyroscope. The choice of this device was based on its widespread use and intermediate screen size.
- A total number of 45 participants (i.e., N = 45) were considered based on Yamane’s equation [42], , which was used to calculate the required sample size . Hence, a sample size of 31 was necessary for an error of 0.1. This condition was satisfied because there were 38 volunteers for the experiment.
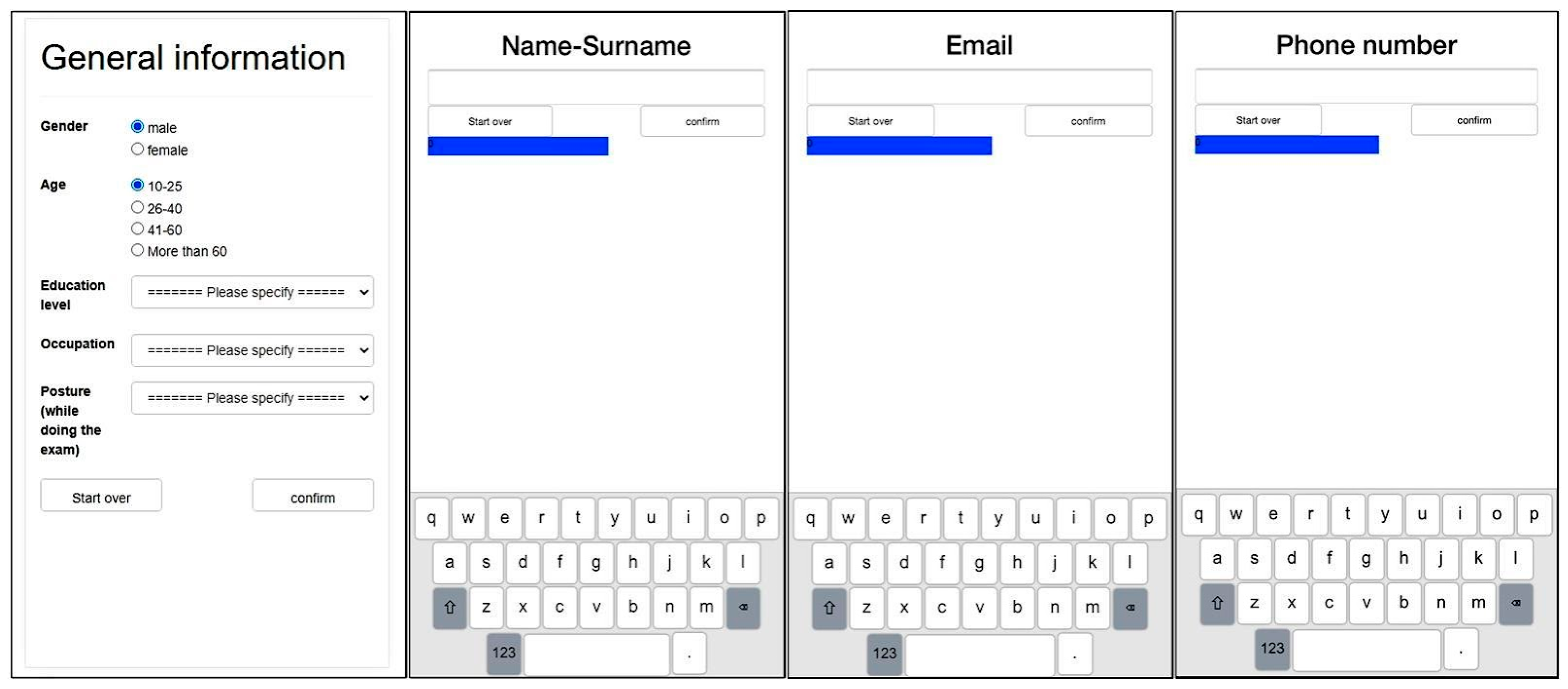
- Each participant was instructed to enter their personal information, including their name, surname, email address, and mobile phone number, using the touchscreen keyboard of the mobile device. All participants were instructed to sit while they were entering their data via the smartphone’s touchscreen, ensuring that there was no environmental variation. This data-entry process was performed ten times over the course of ten days to capture consistent typing patterns.
- The entered data, including the timing keystroke values and other features, were stored in a MySQL database. Each keystroke, along with its associated data, was recorded as a separate record in the database. The data was stored on a private cloud system, ensuring its security and accessibility for further analysis.
- Each data was picked and split into 2 datasets: these were the training set, 75%, and testing set, 25%, as depicted in Figure 6. This process is essential to evaluate the model’s generalization performance on unseen data. So, comprising 25% of the data is to provide an unbiased assessment of the model’s performance on unseen instances and evaluate its generalization capabilities. It helps validate the model’s accuracy and effectiveness beyond the specific user or data it was trained on.
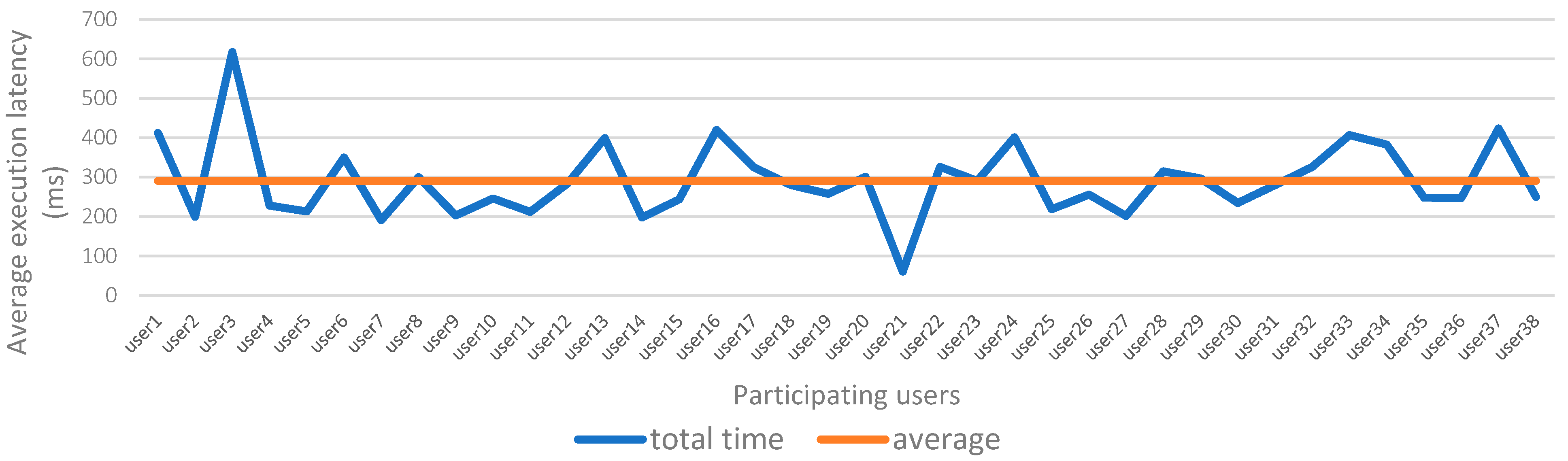
- Each user’s separate classification model was trained individually for 290.79 milliseconds on average. This means that a specific model was created and trained for each individual user based on their unique data and characteristics.The target variables used for training and validation depended on the specific classification task and the goal of the model. In the given context, the target variable would be whether the input data corresponds to the genuine user or an imposter. The model was trained to predict this target variable based on the input features such as gender, fingertip, finger pressure, dwell time, flight time, interval time, latency time, and up-to-up time.
- Accuracy: Accuracy measures the overall correctness of the authentication system in correctly identifying the genuine user and detecting potential attacks. It is calculated as the ratio of the correctly classified instances to the total number of instances. It is given as the ratio . In this, are the number of true positives, true negatives, false positives and false negatives, respectively.
- Precision: Precision measures the proportion of correctly identified genuine users among all instances classified as genuine. It provides insight into the system’s ability to minimize false positives and accurately identify the legitimate user. It is given as ratio where is the number of true positives and the number of false positives.
- The recall is, intuitively, the classifier’s capacity to identify all genuine users. The recall is given as ratio where is the number of true positives and the number of false negatives. The optimal value is 100%, while the worst value is 0%.
- Attack Detection Accuracy: This metric specifically measures the accuracy of the system in detecting and classifying attacks or imposters. It indicates how well the system can differentiate between genuine users and unauthorized individuals attempting to gain access.
- The execution time: The execution time refers to the time it takes to train the user data using the proposed authentication system.
6. Results and Evaluation
6.1. Accuracy, Precision, Recall and Execution Time Evaluation Results
6.2. Attack Detection Accuracy Evaluation Results
- Both approaches exhibited high detection accuracy at 10% malicious users, with the proposed model achieving 97.79% and the benchmark model achieving 96.24%. The proposed model performed marginally better in this scenario.
- When the percentage of malicious users reached 20%, the accuracy of both models remained relatively high. However, the proposed method achieved a detection accuracy of 95.33%, while the benchmark model achieved a detection accuracy of 95.09%.
- At 30% malicious users, the proposed model maintained a high detection accuracy of 94.86% whereas the benchmark model demonstrated a slightly reduced accuracy of 91.76%.
- Similarly, the proposed model outperformed the benchmark model at 40% and 50% malicious users, achieving detection accuracies of 94.45% and 92.48%, respectively, whereas the benchmark model achieved detection accuracies of 91.55% and 90.99%, respectively.
7. Comparative Analysis with Other Similar Related Works
7.1. Biometric Entropy-Based
7.2. Computational Cost-Based
7.3. Security Based
8. Discussions
9. Conclusions
10. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Smartphone History—The First Smartphone|SimpleTexting. Available online: https://simpletexting.com/where-have-we-come-since-the-first-smartphone/ (accessed on 8 October 2022).
- Vass, L.T. The Technological Evolution of the Smartphone. 28 April 2019. [Online]. Available online: https://papers.ssrn.com/abstract=3379257 (accessed on 8 October 2022).
- Keusch, F.; Wenz, A.; Conrad, F. Do you have your smartphone with you? Behavioral barriers for measuring everyday activities with smartphone sensors. Comput. Hum. Behav. 2022, 127, 107054. [Google Scholar] [CrossRef]
- El-Soud, M.W.A.; Gaber, T.; AlFayez, F.; Eltoukhy, M.M. Implicit authentication method for smartphone users based on rank aggregation and random forest. Alex. Eng. J. 2021, 60, 273–283. [Google Scholar] [CrossRef]
- Kokal, S.; Pryor, L.; Dave, R. Exploration of Machine Learning Classification Models Used for Behavioral Biometrics Authentication. In Proceedings of the 8th International Conference on Computer Technology Applications, Vienna, Austria, 12–14 May 2022. [Google Scholar] [CrossRef]
- Alsuhibany, S.A.; Alreshoodi, L.A.; Alsuhibany, C.A.S. Detecting human attacks on text-based CAPTCHAs using the keystroke dynamic approach. IET Inf. Secur. 2021, 15, 191–204. [Google Scholar] [CrossRef]
- Hassan, B.; Izquierdo, E.; Piatrik, T. Soft biometrics: A survey: Benchmark analysis, open challenges and recommendations. Multimed. Tools Appl. 2021, 1–44. [Google Scholar] [CrossRef]
- Anusas-Amornkul, T. Strengthening Password Authentication using Keystroke Dynamics and Smartphone Sensors. In Proceedings of the 9th International Conference on Information Communication and Management, Prague, Czech Republic, 23–26 August 2019. [Google Scholar] [CrossRef]
- Benegui, C. A Deep Learning Approach to Subject Identification Based on Walking Patterns. Procedia Comput. Sci. 2021, 192, 642–649. [Google Scholar] [CrossRef]
- Alqarni, M.A.; Chauhdary, S.H.; Malik, M.N.; Ehatisham-ul-Haq, M.; Azam, M.A. Identifying smartphone users based on how they interact with their phones. Hum.-Centric Comput. Inf. Sci. 2020, 10, 7. [Google Scholar] [CrossRef] [Green Version]
- Pang, X.; Yang, L.; Liu, M.; Ma, J. MineAuth: Mining Behavioural Habits for Continuous Authentication on a Smartphone. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2019; Volume 11547 LNCS, pp. 533–551. [Google Scholar] [CrossRef]
- Choi, M.; Lee, S.; Jo, M.; Shin, J.S. Keystroke Dynamics-Based Authentication Using Unique Keypad. Sensors 2021, 21, 2242. [Google Scholar] [CrossRef] [PubMed]
- Aizi, K.; Ouslim, M. Score level fusion in multi-biometric identification based on zones of interest. J. King Saud. Univ.-Comput. Inf. Sci. 2022, 34, 1498–1509. [Google Scholar] [CrossRef]
- Joseph, T.; Kalaiselvan, S.A.; Aswathy, S.U.; Radhakrishnan, R.; Shamna, A.R. A multimodal biometric authentication scheme based on feature fusion for improving security in cloud environment. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 6141–6149. [Google Scholar] [CrossRef]
- Acien, A.; Morales, A.; Vera-Rodriguez, R.; Fierrez, J. MultiLock: Mobile Active Authentication based on Multiple Biometric and Behavioral Patterns. In Proceedings of the MM’19: The 27th ACM International Conference on Multimedia, Nice, France, 25 October 2019. [Google Scholar] [CrossRef]
- El-Rahiem, B.A.; El-Samie, F.E.A.; Amin, M. Multimodal biometric authentication based on deep fusion of electrocardiogram (ECG) and finger vein. Multimed. Syst. 2022, 28, 1325–1337. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, P.; Hu, H. Multimodal continuous user authentication on mobile devices via interaction patterns. Wirel. Commun. Mob. Comput. 2021, 2021, 1–15. [Google Scholar] [CrossRef]
- Tse, K.W.; Hung, K. User Behavioral Biometrics Identification on Mobile Platform using Multimodal Fusion of Keystroke and Swipe Dynamics and Recurrent Neural Network. In Proceedings of the ISCAIE 2020—IEEE 10th Symposium on Computer Applications and Industrial Electronics, Penang, Malaysia, 18–19 April 2020; pp. 262–267. [Google Scholar] [CrossRef]
- Deb, D.; Ross, A.; Jain, A.K.; Prakah-Asante, K.; Prasad, K.V. Actions Speak Louder Than (Pass)words: Passive Authentication of Smartphone Users via Deep Temporal Features. In Proceedings of the 2019 International Conference on Biometrics, ICB 2019, Crete, Greece, 4–7 June 2019. [Google Scholar] [CrossRef]
- Gu, Y.; Wang, Y.; Wang, M.; Pan, Z.; Hu, Z.; Liu, Z.; Shi, F.; Dong, M. Secure User Authentication Leveraging Keystroke Dynamics via Wi-Fi Sensing. IEEE Trans. Ind. Inf. 2022, 18, 2784–2795. [Google Scholar] [CrossRef]
- Saini, B.S.; Kaur, N.; Bhatia, K.S.; Luhach, A.K. Analyzing user typing behaviour in different positions using keystroke dynamics for mobile phones. J. Discret. Math. Sci. Cryptogr. 2019, 22, 591–603. [Google Scholar] [CrossRef]
- Saini, B.S.; Singh, P.; Nayyar, A.; Kaur, N.; Bhatia, K.S.; El-Sappagh, S.; Hu, J.W. A Three-Step Authentication Model for Mobile Phone User Using Keystroke Dynamics. IEEE Access 2020, 8, 125909–125922. [Google Scholar] [CrossRef]
- Ulanoff, L. The iPhone X’s Face ID Can Be Fooled by Identical Twins|Mashable. Mashable SEA. 31 October 2017. Available online: https://mashable.com/article/putting-iphone-x-face-id-to-twin-test (accessed on 25 October 2022).
- Boyle, J. Twin Peeks: Identical Brothers Are Able to Unlock Each Other’s Phone—The Sunday Post. The Sunday Post, 26 November 2018. Available online: https://www.sundaypost.com/fp/twin-peeks-identical-brothers-able-to-unlock-each-others-phone/ (accessed on 25 October 2022).
- Chakravarti, A. Brothers Who Are Not Identical Twins Fool iPhone 12 Mini’s Face ID. India Today Group, 9 June 2021. Available online: https://www.indiatoday.in/technology/news/story/brothers-who-are-not-identical-twins-fool-iphone-12-mini-s-face-id-1812763-2021-06-09 (accessed on 25 October 2022).
- Abdulrahman, S.A.; Alhayani, B. A comprehensive survey on the biometric systems based on physiological and behavioural characteristics. Mater. Today Proc. 2021, 80, 2642–2646. [Google Scholar] [CrossRef]
- Devika, V.; Ankitha, C. Multi Account Embedded System with Enhanced Security. Int. Res. J. Eng. Technol. 2020. Online. Available online: www.irjet.net (accessed on 16 July 2023).
- Ali, G.; Dida, M.A.; Sam, A.E. Two-Factor Authentication Scheme for Mobile Money: A Review of Threat Models and Countermeasures. Future Internet 2020, 12, 160. [Google Scholar] [CrossRef]
- Cadd, S.; Islam, M.; Manson, P.; Bleay, S. Fingerprint composition and aging: A literature review. Sci. Justice 2015, 55, 219–238. [Google Scholar] [CrossRef]
- Technology, S.E. Can Fingerprints Change over Time?—Smart Eye Technology. 19 October 2020. Available online: https://getsmarteye.com/age-limit-do-fingerprints-change-overtime/ (accessed on 16 July 2023).
- Huang, Z.; Zhang, J.; Shan, H.; Key, S. When Age-Invariant Face Recognition Meets Face Age Synthesis: A Multi-Task Learning Framework. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 7917–7932. Available online: https://github (accessed on 16 July 2023). [CrossRef]
- Murad, M. Iris Patterns: One of the Most Stable Biometrics—Iris ID. Iris ID, 24 March 2021. Available online: https://www.irisid.com/iris-patterns-one-of-the-most-stable-biometrics/ (accessed on 16 July 2023).
- Javed, L.; Yakubu, B.M.; Waleed, M.; Khaliq, Z.; Suleiman, A.B.; Mato, N.G. BHC-IoT: A Survey on Healthcare IoT Security Issues and Blockchain-Based Solution. Int. J. Electr. Comput. Eng. Res. 2022, 2, 1–9. [Google Scholar] [CrossRef]
- Shah, P.G.; Ayoade, J. An Empricial Study of Brute Force Attack on Wordpress Website. In Proceedings of the 5th International Conference on Smart Systems and Inventive Technology, ICSSIT 2023, Tirunelveli, India, 23–25 January 2023; pp. 659–662. [Google Scholar] [CrossRef]
- Faircloth, C.; Hartzell, G.; Callahan, N.; Bhunia, S. A Study on Brute Force Attack on T-Mobile Leading to SIM-Hijacking and Identity-Theft. In Proceedings of the 2022 IEEE World AI IoT Congress, AIIoT 2022, Seattle, WA, USA, 6–9 June 2022; pp. 501–507. [Google Scholar] [CrossRef]
- Kuznetsov, A.; Oleshko, I.; Chernov, K.; Bagmut, M.; Smirnova, T. Biometric authentication using convolutional neural networks. In Lecture Notes in Networks and Systems, 152; Springer International Publishing: Cham, Switezrland, 2021; pp. 85–98. [Google Scholar] [CrossRef]
- Velásquez, I.; Caro, A.; Rodríguez, A. Kontun: A Framework for recommendation of authentication schemes and methods. Inf. Softw. Technol. 2018, 96, 27–37. [Google Scholar] [CrossRef]
- Ellavarason, E.; Guest, R.; Deravi, F.; Sanchez-Riello, R.; Corsetti, B. Touch-dynamics based Behavioural Biometrics on Mobile Devices—A Review from a Usability and Performance Perspective. ACM Comput. Surv. 2020, 53, 1–36. [Google Scholar] [CrossRef]
- Ometov, A.; Bezzateev, S.; Mäkitalo, N.; Andreev, S.; Mikkonen, T.; Koucheryavy, Y. Multi-Factor Authentication: A Survey. Cryptography 2018, 2, 1. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Pawara, P.; Okafor, E.; Groefsema, M.; He, S.; Schomaker, L.R.B.; Wiering, M.A. One-vs-One classification for deep neural networks. Pattern Recognit. 2020, 108, 107528. [Google Scholar] [CrossRef]
- Singh, A.S.; Masuku, M.B. Sampling Techniques & Determination of Sample Size in Applied Statistics Research: An Overview. Int. J. Econ. Commer. Manag. 2014, 2, 1–22. Available online: http://ijecm.co.uk/ (accessed on 30 October 2022).
- Cui, Z.; Huang, A.; Chen, J.; Gao, S. Piezoelectric Touch Sensing-Based Keystroke Dynamic Technique for Multi-User Authentication. IEEE Sens. J. 2021, 21, 26389–26396. [Google Scholar] [CrossRef]
- Wang, D.; Gu, Q.; Huang, X.; Wang, P. Understanding Human-Chosen PINs: Characteristics, Distribution and Security. In Proceedings of the ASIA CCS’17: ACM Asia Conference on Computer and Communications Security, Abu Dhabi, United Arab Emirates, 2–6 April 2017. [Google Scholar]
- Wang, D.; Cheng, H.; Wang, P.; Huang, X.; Jian, G. Zipf’s law in passwords. IEEE Trans. Inf. Forensics Secur. 2017, 12, 2776–2791. [Google Scholar]
- Sutcu, Y.; Tabassi, E.; Sencar, H.T.; Memon, N. What is biometric information and how to measure it? In Proceedings of the 2013 IEEE International Conference on Technologies for Homeland Security (HST), Waltham, MA, USA, 12–14 November 2013; pp. 67–72. [Google Scholar]
- Krivokuca, V.; Gomez-Barrero, M.; Marcel, S.; Rathgeb, C.; Busch, C. Towards Measuring the Amount of Discriminatory Information in Finger Vein Biometric Characteristics Using a Relative Entropy Estimator. In Advances in Computer Vision and Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2020; pp. 507–525. [Google Scholar] [CrossRef] [Green Version]
- Inthavisas, K.; Lopresti, D. Secure speech biometric templates for user authentication. IET Digit. Libr. 2012, 1, 46–54. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Factor Biometrics | Performance | Device | |||
|---|---|---|---|---|---|
| Accuracy | FRR | FAR | EER | ||
| Keystroke dynamics [8] | 97.90% | --- | --- | --- | Smartphone |
| Gait detection [9] | 98.79% | --- | --- | --- | Smartphone |
| Touch gestures [10] | 74.97% | --- | --- | --- | Smartphone |
| Behavior profiling [11] | 98.5% | --- | --- | --- | Smartphone |
| Keystroke dynamics [12] | --- | --- | --- | 10.01% | Keypad on Smartphone |
| Iris and Fingerprint [13] | 95.00% | 3.89% | 1.11% | --- | Standard database |
| Fingerprint, iris, and palm print [14] | --- | 0.15% | 94.54% | --- | Collecting database |
| Touch dynamics (touch gestures and keystroking), accelerometer, gyroscope, Wi-Fi, GPS location and app usage [15] | 82.2–97.1% | --- | --- | --- | Smartphone sensor |
| ECG, finger vein [16] | --- | --- | --- | 0.12% | Database |
| Motion and hold posture, (accelerator and capture the variation model of micro hand motions and hold patterns) [17] | 97% | --- | --- | --- | --- |
| Keystroke, Swipe dynamics [18] | 94.26% | --- | --- | --- | Smartphone |
| Keystroke, GPS position, accelerometer, gyroscope, magnetometer, linear accelerometer, gravity, and rotation sensors [19] | 97.15% | --- | --- | --- | Smartphone |
| Factor Biometrics | Single Factor | Multiple Factors | Degradation Protection | Device Dependency | Personal Skill |
|---|---|---|---|---|---|
| Keystroke dynamics [8] | P | P | |||
| Gait detection [9] | P | P | |||
| Touch gestures [10] | P | P | |||
| Behavior profiling [11] | P | P | P | ||
| Keystroke dynamics (Unique keypad on smartphone) [12] | P | P | |||
| Iris and Fingerprint [13] | P | P | |||
| Fingerprint, iris, and palm print [14] | P | P | |||
| Touch dynamics [15] | P | P | |||
| ECG, finger vein [16] | P | P | |||
| Motion and hold posture [17] | P | P | |||
| Keystroke, swipe dynamics [18] | P | P | |||
| Keystroke, mobile sensors [19] | P | P |
| Article Title | Description |
|---|---|
| Kontun: A Framework for recommendation of authentication schemes and methods [37] | There are three primary guidelines that all multimedia systems must follow to security: (1) ease of use and (2) simplicity, and (3) cost-effectiveness is a priority for the platform. |
| Touch-dynamics based Behavioral Biometrics on Mobile Devices— A Review from a Usability and Performance Perspective [38] | Review touch-dynamics-based behavioral biometrics in terms of (1) usability and its impact on (2) authentication performance, including the (3) modalities of user involvement, the (4) quantity of enrollment data needed, (5) algorithmic performance accuracy, and (6) energy consumption. |
| Multi-Factor Authentication: A Survey [39] | Thorough analysis of authentication methods that combine two or more authentication processes should increase (1) user verification security. These systems intelligently combine (2) knowledge, (3) biometrics, and (4) ownership. |
| Factor Biometrics | Single | Multiple | Non-Degradation | Device Independent | Individual-Skill | Performance |
|---|---|---|---|---|---|---|
| Keystroke dynamics [8] | P | 97.00% | ||||
| Gait detection [9] | P | 98.79% | ||||
| Touch gestures [10] | P | 74.97% | ||||
| Behavior profiling [11] | P | P | P | 98.50% | ||
| Keystroke dynamics (Unique keypad on smartphone) [12] | P | 89.99% | ||||
| Iris and Fingerprint [13] | P | 95.00% | ||||
| Fingerprint, iris, and palm print [14] | P | 94.54% | ||||
| Touch dynamics [15] | P | 97.1% | ||||
| ECG, finger vein [16] | P | EER 0.12% | ||||
| Motion and hold posture [17] | P | 97.00% | ||||
| Keystroke, swipe dynamics [18] | P | 94.26% | ||||
| Keystroke, mobile sensors [19] | P | 97.15% | ||||
| Proposed method | P | P | P | P | 97.59% |
| Ref. | Authentication Factor | Number of Digits | Characters | Dataset | Entropy (Bits) |
|---|---|---|---|---|---|
| Wang D [44] | PIN | 4-digit | Numerical characters | Dodonew, CSDN, Rockyou, Yahoo (total 3.4 M) | 8.41 |
| PIN | 6-digit | Numerical characters | Dodonew, CSDN, Rockyou, Yahoo (total 6.4 M) | 13.21 | |
| Wang D [45] | Password | 6-digit and 10-digit | lowercase alphabet characters and numbers | 14 datasets (total 113.3 M) | 20–22 |
| Sutcu Y [46] | Iris | ICE (High quality set—374 iris, 10 samples each) | 8.9–10, 8.9–10 bits | ||
| Krivokuca V [47] | Finger Vein | VERA (220 fingers, two samples each) | 4.2—13.2 | ||
| UTFVP (360 fingers, four images each) | 18.9–19.5 | ||||
| Inthavisas et al. [48] | Combine password and voice | 18–30 | |||
| The proposed method | Keystroke | 10-digit PIN | 38 samples | 51.7 |
| Category | Criterion | Behavior Profiling [11] | Keystroke, Mobile Sensors [19] | Proposed Method |
|---|---|---|---|---|
| Usability | Ease of use | High (does not require explicit user interaction) | Low (requires explicit user interaction) | Low (requires explicit user interaction to type profile data) |
| Ease of learning | Medium (user may need time to adjust to the monitoring) | Low (user may need to learn to type correctly) | Low (user may need to learn to type profile data correctly) | |
| Need of using a device | High (requires a smartphone) | High (requires a smartphone) | High (requires a smartphone) | |
| Method’s reliability | High (98.3% accuracy) | High (96.47% accuracy) | High (97.59% accuracy) | |
| Security | Importance of security | High (continuously monitors user behavior) | High (passively monitors user behavior) | High (relies on personal behavioral biometrics) |
| Resistance to well-known attacks | High (relies on smartphone data) | Low (keystroke dynamics can be easily replicated) | Low (keystroke dynamics can be easily replicated) | |
| Costs | Implementation costs | Medium (may require development resources) | Medium (may require development resources) | Medium (may require development resources) |
| Costs per user | Low (minimal additional costs for users) | Low (minimal additional costs for users) | Low (minimal additional costs for users) | |
| Server compatibility | N/A (occurs on the smartphone) | N/A (occurs on the smartphone) | N/A (occurs on the smartphone) | |
| Need of acquiring licenses | Low (minimal licensing requirements) | Low (minimal licensing requirements) | Low (minimal licensing requirements) | |
| Available technologies | High (utilizes smartphone data) | High (utilizes smartphone sensors) | Low (limited to individual’s typing-skills) | |
| Others | Client’s requirements | Medium (user may need to adjust behavior) | Low (user may need to type correctly) | Low (user may need to type profile data correctly) |
| Application context | Medium (may be limited to certain types of applications) | Medium (may be limited to certain types of applications) | Low (may be limited to certain types of applications requiring profile data input) | |
| Norms and legislation | Low (minimal legal restrictions) | Low (minimal legal restrictions) | Low (minimal legal restrictions) |
| Methods | Usability Perspective | Cost Effectiveness | Performance | ||
|---|---|---|---|---|---|
| User Friendly | Cost to Implement | Extra Equipment | Consume Space | ||
| Behavior profiling [11] | P | P | P | 98.50% | |
| Keystroke, mobile sensors [19] | P | P | P | 97.15% | |
| Proposed method | P | 97.59% | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nanglae, N.; Yakubu, B.M.; Bhattarakosol, P. Extraction of Hidden Authentication Factors from Possessive Information. J. Sens. Actuator Netw. 2023, 12, 62. https://doi.org/10.3390/jsan12040062
Nanglae N, Yakubu BM, Bhattarakosol P. Extraction of Hidden Authentication Factors from Possessive Information. Journal of Sensor and Actuator Networks. 2023; 12(4):62. https://doi.org/10.3390/jsan12040062
Chicago/Turabian StyleNanglae, Nilobon, Bello Musa Yakubu, and Pattarasinee Bhattarakosol. 2023. "Extraction of Hidden Authentication Factors from Possessive Information" Journal of Sensor and Actuator Networks 12, no. 4: 62. https://doi.org/10.3390/jsan12040062