
A High Performance Wheat Disease Detection Based on Position Information
 , , ,
, , ,
Abstract
:1. Introduction
- 1.
- To solve the problem of lack of data sets, we propose a corresponding data augmentation method.
- 2.
- Based on feature map position information, a position attention block is proposed and implemented based on PyTorch.
- 3.
- In this paper, we conducted several experiments to verify the effectiveness of the position attention block and compared it with other attention blocks.
2. Results
2.1. Experiment Results
2.2. Validation on Other Datasets
2.3. Comparison with Other Attention Blocks
3. Materials and Methods
3.1. Backgounds
3.1.1. Convolutional Neural Network (CNN)
3.1.2. Squeeze-Excitation (SE) Block
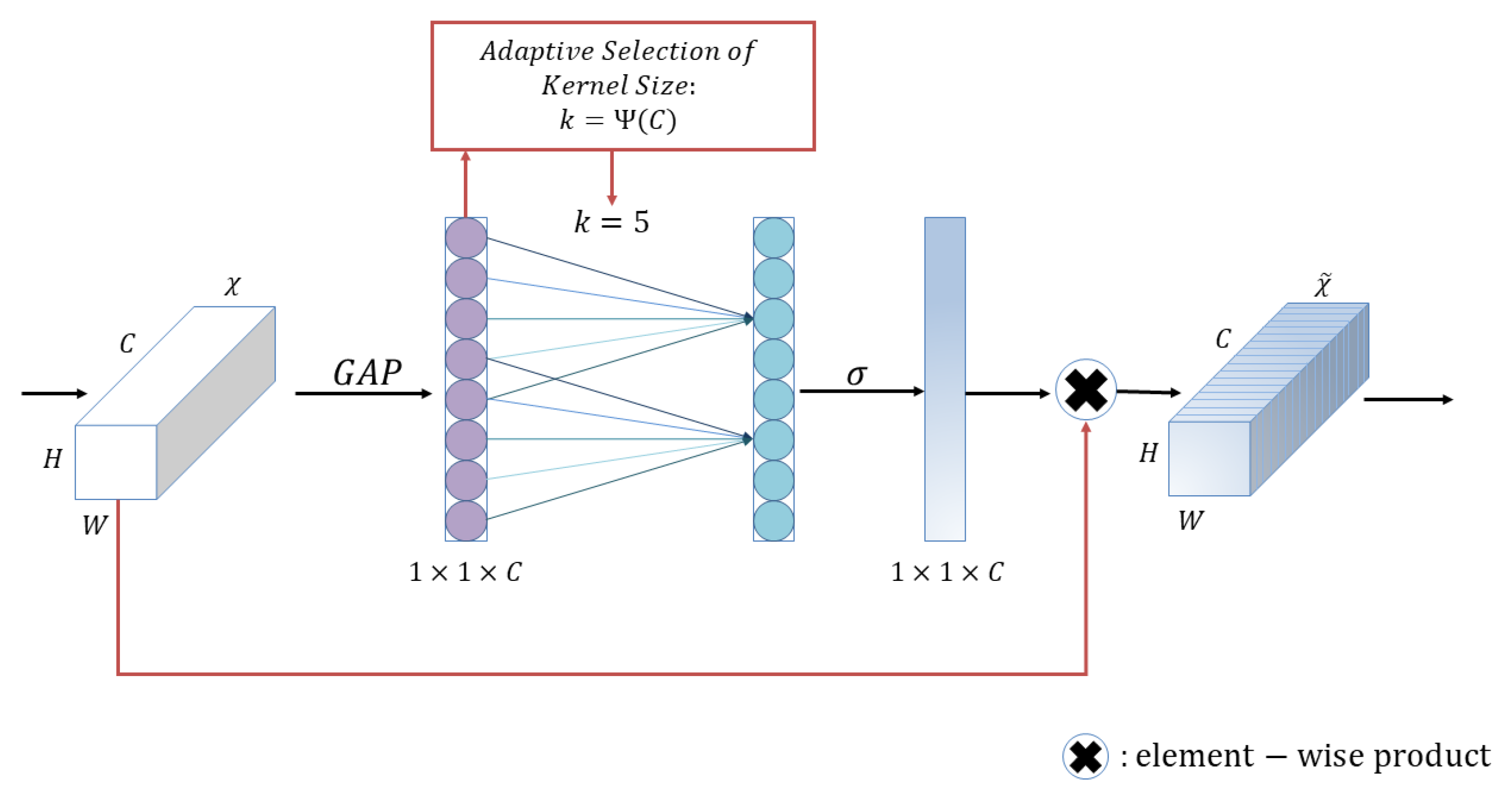
3.1.3. Efficient Channel Attention (ECA) Block
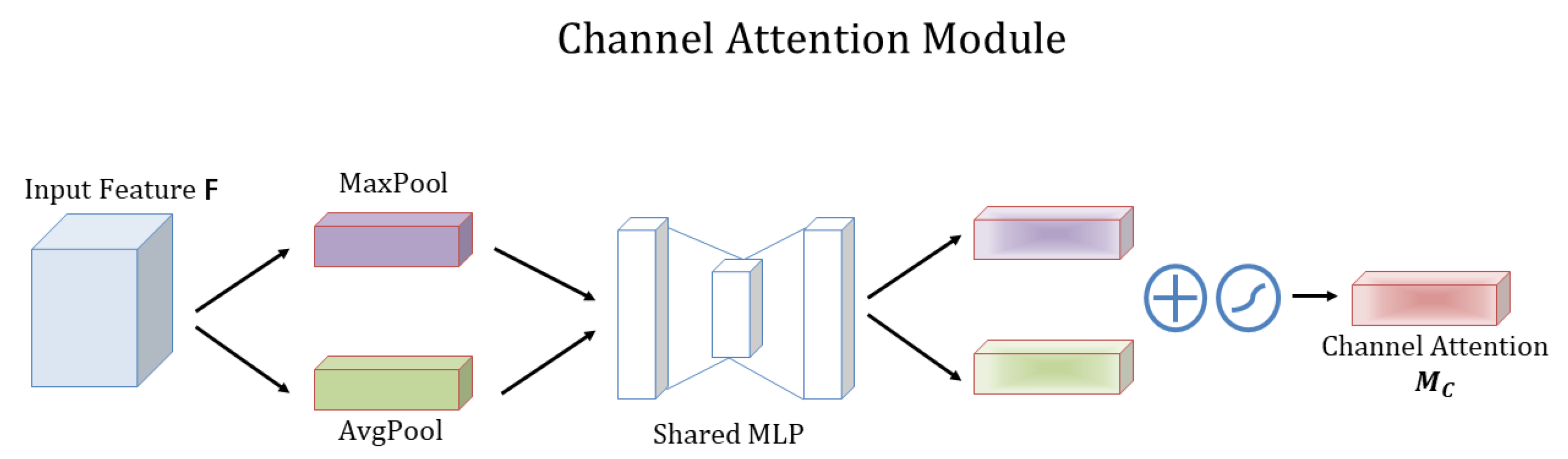
3.1.4. Convolutional Block Attention Module (CBAM)
Channel Attention Module
Spatial Attention Module
3.2. Data Collection
3.3. Data Augmentation
3.4. Proposed Method
3.4.1. Position Attention Overview
- 1.
- 2.
- It captures cross-channel information as well as position-aware information, which helps the model to more accurately locate and identify targets of interest.
- 3.
- Finally, position attention as a pre-trained model can bring significant benefits for downstream tasks on top of lightweight networks, especially those where intensive prediction exists, such as semantic segmentation, as discussed in Section 4.1.
3.4.2. Position Attention Block
3.5. Implement and Experiment
3.5.1. Implement
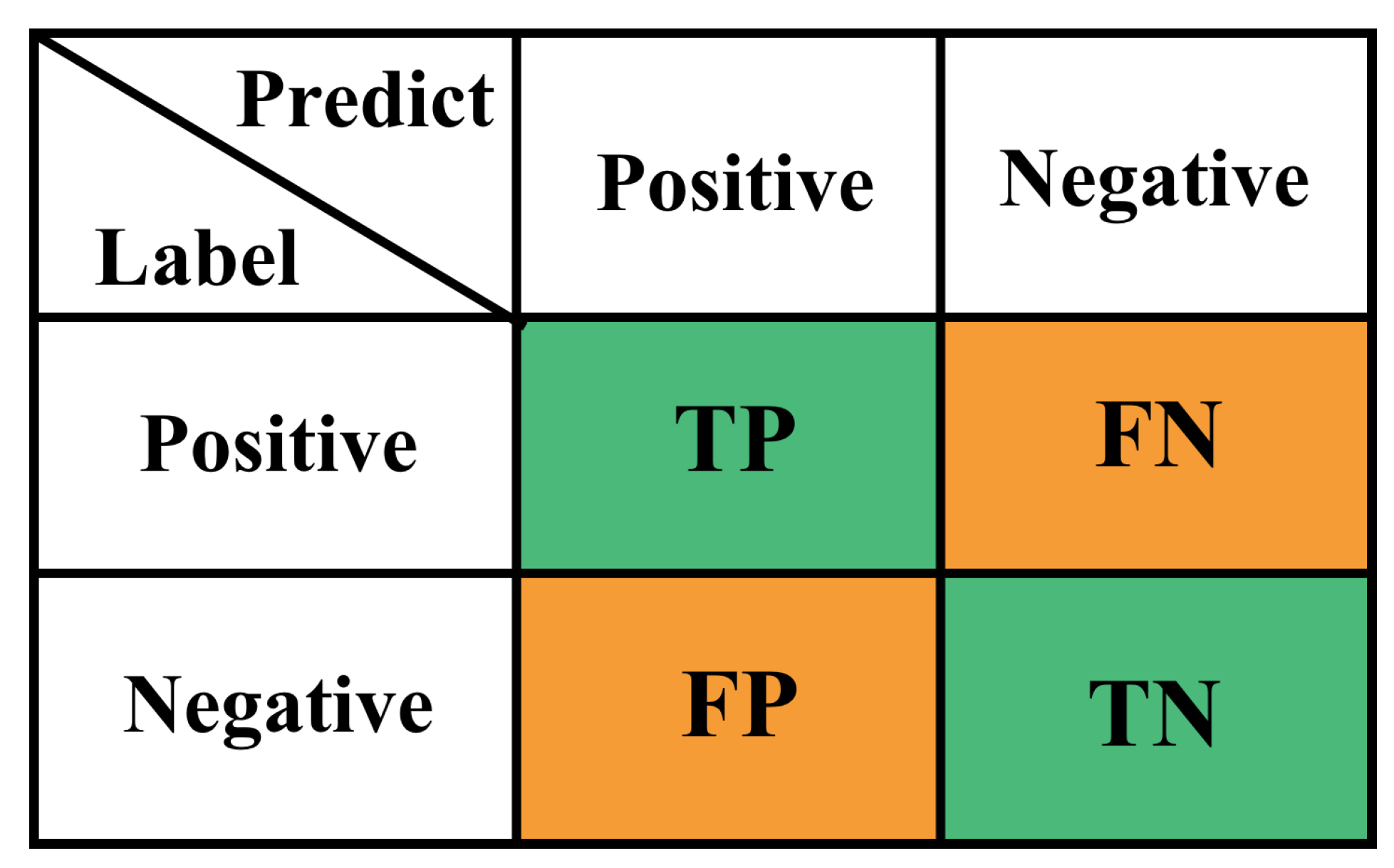
3.5.2. Experiment Metric
- 1.
- Classifies a positive case as positive, which is denoted as true positive (TP).
- 2.
- Classifies a positive case as a negative case, which is denoted as a false negative (FN).
- 3.
- Classifies a negative case as negative correctly, denoted as true negative (TN).
- 4.
- Classifies a negative case as a positive case, denoted as false positive (FP).
4. Discussion
4.1. Validation of Generality
4.2. Data Balancing
5. Conclusions
- 1.
- To solve the problem of lack of dataset, we propose a corresponding data augmentation method.
- 2.
- Based on feature map position information, a position attention block is proposed and implemented based on PyTorch.
- 3.
- In this paper, we conducted several experiments to verify the effectiveness of the position attention block and compared it with other attention blocks.
Author Contributions
Funding
Conflicts of Interest
References
- Atchison, J.; Head, L.; Gates, A. Wheat as food, wheat as industrial substance; comparative geographies of transformation and mobility. Geoforum 2010, 41, 236–246. [Google Scholar] [CrossRef]
- Mesterházy, Á.; Oláh, J.; Popp, J. Losses in the grain supply chain: Causes and solutions. Sustainability 2020, 12, 2342. [Google Scholar] [CrossRef] [Green Version]
- Nema, S.; Dixit, A. Wheat leaf detection and prevention using support vector machine. In Proceedings of the 2018 International Conference on Circuits and Systems in Digital Enterprise Technology (ICCSDET), Kottayam, India, 21–22 December 2018; pp. 1–5. [Google Scholar]
- Zhang, L.; Ji, H. Identification of wheat grain in different states based on hyperspectral imaging technology. Spectrosc. Lett. 2019, 52, 356–366. [Google Scholar] [CrossRef]
- Sakib, S.; Ahmed, N.; Kabir, A.J.; Ahmed, H. An overview of convolutional neural network: Its architecture and applications. Preprints 2018, 2018110546. [Google Scholar] [CrossRef]
- Liu, G.R. Rice color inspection based on image processing technique. In Proceedings of the 2010 International Conference on Advances in Energy Engineering, Beijing, China, 19–20 June 2010; pp. 134–137. [Google Scholar]
- Kiliçarslan, S.; Celik, M. RSigELU: A nonlinear activation function for deep neural networks. Expert Syst. Appl. 2021, 174, 114805. [Google Scholar] [CrossRef]
- Zhang, Y.; Wa, S.; Liu, Y.; Zhou, X.; Sun, P.; Ma, Q. High-Accuracy Detection of Maize Leaf Diseases CNN Based on Multi-Pathway Activation Function Module. Remote Sens. 2021, 13, 4218. [Google Scholar] [CrossRef]
- Wang, L.; Chen, A.; Zhang, Y.; Wang, X.; Zhang, Y.; Shen, Q.; Xue, Y. AK-DL: A Shallow Neural Network Model for Diagnosing Actinic Keratosis with Better Performance than Deep Neural Networks. Diagnostics 2020, 10, 217. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, X.; Wa, S.; Liu, Y.; Kang, J.; Lv, C. GenU-Net++: An Automatic Intracranial Brain Tumors Segmentation Algorithm on 3D Image Series with High Performance. Symmetry 2021, 13, 2395. [Google Scholar] [CrossRef]
- Zhang, Y.; Wa, S.; Sun, P.; Wang, Y. Pear Defect Detection Method Based on ResNet and DCGAN. Information 2021, 12, 397. [Google Scholar] [CrossRef]
- Zhang, Y.; He, S.; Wa, S.; Zong, Z.; Liu, Y. Using Generative Module and Pruning Inference for the Fast and Accurate Detection of Apple Flower in Natural Environments. Information 2021, 12, 495. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, X.; Wa, S.; Chen, S.; Ma, Q. GANsformer: A Detection Network for Aerial Images with High Performance Combining Convolutional Network and Transformer. Remote Sens. 2022, 14, 923. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, M.; Ma, X.; Wu, X.; Wang, Y. High-Precision Wheat Head Detection Model Based on One-Stage Network and GAN Model. Front. Plant Sci. 2022, 13, 787852. [Google Scholar] [CrossRef]
- Zhang, Y.; Wa, S.; Zhang, L.; Lv, C. Automatic Plant Disease Detection Based on Tranvolution Detection Network With GAN Modules Using Leaf Images. Front. Plant Sci. 2022, 13, 875693. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Wang, H.; Xu, R.; Yang, X.; Wang, Y.; Liu, Y. High-Precision Seedling Detection Model Based on Multi-Activation Layer and Depth-Separable Convolution Using Images Acquired by Drones. Drones 2022, 6, 152. [Google Scholar] [CrossRef]
- Suarez Baron, M.J.; Gomez, A.L.; Diaz, J.E.E. Supervised Learning-Based Image Classification for the Detection of Late Blight in Potato Crops. Appl. Sci. 2022, 12, 9371. [Google Scholar] [CrossRef]
- Li, Y.; Sun, S.; Zhang, C.; Yang, G.; Ye, Q. One-stage disease detection method for maize leaf based on multi-scale feature fusion. Appl. Sci. 2022, 12, 7960. [Google Scholar] [CrossRef]
- Liu, X.; Zhou, S.; Chen, S.; Yi, Z.; Pan, H.; Yao, R. Buckwheat Disease Recognition Based on Convolution Neural Network. Appl. Sci. 2022, 12, 4795. [Google Scholar] [CrossRef]
- Lingwal, S.; Bhatia, K.K.; Tomer, M.S. Image-based wheat grain classification using convolutional neural network. Multimed. Tools Appl. 2021, 80, 35441–35465. [Google Scholar] [CrossRef]
- Goyal, L.; Sharma, C.M.; Singh, A.; Singh, P.K. Leaf and spike wheat disease detection and classification using an improved deep convolutional architecture. Inform. Med. Unlocked 2021, 25, 100642. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 13–19. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Input Size | Mean Accuracy (in %) |
|---|---|---|
| AlexNet | 224 × 224 | 81.3 ± 1.7 |
| AlexNet + PA | 224 × 224 | 83.4 ± 0.7 |
| VGG | 224 × 224 | 85.6 ± 1.2 |
| VGG + PA | 224 × 224 | 86.9 ± 1.2 |
| MobileNet | 224 × 224 | 88.5 ± 2.0 |
| MobileNet + PA | 224 × 224 | 90.1 ± 1.4 |
| ResNet | 224 × 224 | 93.7 ± 0.8 |
| ResNet + PA | 224 × 224 | 96.4 ± 0.8 |
| GoogLeNet | 299 × 299 | 89.6 ± 0.9 |
| GoogLeNet + PA | 299 × 299 | 89.5 ± 0.8 |
| Model | Input Size | Pretrained Weights | mAP |
|---|---|---|---|
| MobileNet | 416 × 416 | COCO | 0.42 ± 0.08 |
| ResNet | 416 × 416 | COCO + PVD | 0.51 ± 0.03 |
| Backbone | Baseline | +SE | +CBAM | +ECA | +PA |
|---|---|---|---|---|---|
| MobileNet | 92.3 ± 1.3 | 93.5 ± 1.3 | 93.6 ± 1.3 | 93.3 ± 1.2 | 94.4 ± 1.2 |
| ResNet | 93.8 ± 0.4 | 94.7 ± 0.4 | 94.7 ± 0.4 | 94.2 ± 0.4 | 96.0 ± 0.4 |
| Class | Number |
|---|---|
| Healthy | 1489 |
| Rust | 378 |
| Blastomycosis | 296 |
| Macrophthalmia | 463 |
| Task | Model | Baseline | Ours |
|---|---|---|---|
| Object Detection | YOLOv3 | 0.84 ± 0.04 | 0.87 ± 0.04 |
| YOLOv5 | 0.87 ± 0.04 | 0.88 ± 0.03 | |
| Semantic Segmentation | MaskRCNN | 0.72 ± 0.08 | 0.73 ± 0.07 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, S.; Cheng, H.; Yang, R.; Zhou, J.; Li, Z.; Shi, B.; Lee, M.; Ma, Q. A High Performance Wheat Disease Detection Based on Position Information. Plants 2023, 12, 1191. https://doi.org/10.3390/plants12051191
Cheng S, Cheng H, Yang R, Zhou J, Li Z, Shi B, Lee M, Ma Q. A High Performance Wheat Disease Detection Based on Position Information. Plants. 2023; 12(5):1191. https://doi.org/10.3390/plants12051191
Chicago/Turabian StyleCheng, Siyu, Haolan Cheng, Ruining Yang, Junyu Zhou, Zongrui Li, Binqin Shi, Marshall Lee, and Qin Ma. 2023. "A High Performance Wheat Disease Detection Based on Position Information" Plants 12, no. 5: 1191. https://doi.org/10.3390/plants12051191