2.3.1. MFBP-UNet Overall Architecture
In our study, mindful of the impact of complex backgrounds and disparate lighting conditions, we developed a multi-disease segmentation network termed MFBP-UNet, which is based on the UNet architecture.The overall network architecture is shown in
Figure 6. The novelty of this network lies in its two key feature extraction modules: the MFE module and the BATok-MLP module. The MFE module fully leverages multi-scale and multi-type convolution kernels to effectively extract detailed and semantic features. To bypass traditional pooling operations, we specifically integrated a frequency attention mechanism to enhance the model’s robustness and amplify its disease feature recognition capability. In the same vein, the BATok-MLP module, while curbing model complexity, successfully incorporates a dynamic sparse attention mechanism, enabling the effective utilization of global information and the attainment of a dynamic trade-off between global and local features. In terms of optimization, we adopted a combination of cross-entropy loss and Dice loss methods. This amalgamation empowers the model to effectively recognize and pinpoint pear leaf disease spots in complex environments, especially as the Dice loss method can address class imbalance issues more competently. The specific computation formula is as follows:
where
t stands for the true labels while
y signifies the model’s predicted output.
m denotes the number of classes,
n denotes the number of pixels, and
is a hyperparameter preset to
, serving as a safeguard against zero denominator scenarios.
In this formula, and serve as weight coefficients and are respectively configured to 1 and 0.5.
Our research has elucidated that these amendments noticeably bolster the overall performance and precision of our model in comparison to UNet and other advanced networks. The primary driving force behind this enhancement is the introduction of innovative feature extraction modules and optimization strategies. These implementations ensure the model’s proficient recognition and localization capabilities under the challenges posed by complex backgrounds and diverse lighting conditions.
2.3.2. MFE Module
The convolution operation within Convolutional Neural Networks plays a critical role in local feature extraction from images, efficiently encapsulating detailed aspects of the image while preserving spatial information. Nonetheless, Convolutional Neural Networks tend to rely on pooling operations as a means to reduce computational complexity and curb overfitting. This approach, however, can compromise the model’s sensitivity to smaller targets during the dimensionality reduction process. To address this issue and ensure a more precise detection and localization of pear leaf disease within intricate environments, we devised a multiscale type module that incorporates residual connections. As opposed to conventional Convolutional Neural Networks, this module circumvents the need for pooling operations. Instead, it harnesses detail-rich and semantic features by operating at different convolution scales and levels, thereby more effectively preserving the continuity of information.
Figure 6B shows its architecture.
The operation of the Multiscale Feature Extraction (MFE) module is as follows: First, a 3 × 3 convolution layer is used to extract features from the input feature map
, producing a base feature map
. This basic feature map
is then fed into two separate branches: one uses a 3 × 3 extended convolution to extract a detail-oriented feature map
, rich in local details; the other uses a 5 × 5 convolution layer to extract a more global, semantic-oriented feature map
. The resulting feature maps
,
from these two branches are then merged along the channel dimension to produce the final feature map
.
where
denotes the operation of concatenation.
Upon this novel feature map, we implemented depthwise convolution operations with kernels of sizes
,
, and
. This particular operation significantly mitigates computational complexity and the volume of model parameters while concurrently sustaining the potent feature extraction capacity. By adopting convolution operations of diverse scales, we could extract features of varying dimensions, in turn bolstering the model’s expressivity. We then integrated the outputs across these three branches, thus furnishing a richer and more comprehensive representation encapsulating expansive disease feature information.
where
signifies a 1 × 1 convolutional layer designed for channel compression and dimensionality reduction. This operation simultaneously merges features of differing scales, leading to a reduction in the feature map’s dimensionality and an enhancement of the model’s efficiency.
symbolizes an
dilated convolution layer.
Finally, a frequency attention mechanism was incorporated to bolster the model’s focus on significant frequency features within the image. This mechanism fortifies the model’s comprehension of global information by amplifying its capacity to detect disease-related features, subsequently increasing model robustness. Concurrently, the frequency attention mechanism is effective in mitigating the effects of superfluous information and noise—such as random textures and background noise prevalent in the image—thereby elevating the precision and reliability of the model’s segmentation of pear leaf disease.
In practical applications, the initial step involves partitioning the input feature map into several groups, each subjected to a two-dimensional discrete cosine transform (2DDCT). Post-processing via a fully connected layer and function yields the ultimate weighted feature map. Subsequently, we employ a residual structure to integrate this weighted feature map with the foundational feature map, thus producing the final output feature map.
where Sigmoid signifies the activation function, FC stands for the fully connected network layer, Freq embodies the frequency domain features of the input, which is obtained through 2DDCT transformation, and n is a predetermined value denoting the subdivisions of the input feature.
Within the MFE module, we harnessed the power of a variety of convolution operations of different types and scales for feature extraction, thereby amplifying the expressive power of the features. Subsequently, we incorporated a frequency attention mechanism, which enhances the model’s focus on significant frequency features of the image by adjusting the features in the frequency domain, resulting in improved robustness and accuracy of the model. Such a design equips the module with the ability to efficiently detect and precisely locate pear leaf disease even in complex environments.
2.3.3. BATok-MLP Module
The architecture of UNet is grounded in an encoder-decoder scheme, where a succession of convolutional and deconvolutional operations are employed for progressive encoding and decoding, extracting and mapping features across diverse hierarchical levels. Lower levels primarily focus on fine-grained features (such as edges and textures), while higher levels concentrate on more abstract and global features (like objects and scenes). However, traditional convolutional approaches often lack the capacity to fully comprehend global contextual information, which may lead to the loss of fine-grained features. To address this issue, we designed a novel BATok-MLP module that incorporates a dynamic sparse attention mechanism, as shown in
Figure 6C. This module can more effectively process global contextual information, thereby minimizing the loss of fine-grained features.
The Tok-MLP [
29] module effectively captures fine-grained features by moving across the width and height of the feature map, allowing the model to focus on specific positions of the convolutional features. However, its extraction of global information is still limited, as the collection of global information primarily relies on the accumulation of local attention across various regions.
As a result, we improved the Tok-MLP module by introducing a dynamic sparse attention [
30] mechanism. This mechanism can select different parts of the input sequence for focus in each computation, allowing the model to understand information from a global perspective after multiple iterations. This dynamic attention adjustment can both capture global information and maintain sensitivity to local details.
In the BATok-MLP module, we also introduced a PatchEmbedding layer. This layer includes a 2D convolutional layer and a layer normalization operation, which can transform 2D features into 1D sequential features while preserving spatial information. This transformation allows the model to handle 2D spatial information within a 1D sequence, thus better integrating feature information and enhancing the model’s feature extraction capabilities.
The working principle of the BATok-MLP module can be divided into the following steps: First, we apply the PatchEmbedding layer to process the input feature map
, and then reshape the output one-dimensional sequence
into
to meet the requirements of subsequent operations. The specific operations are as follows:
where
represents convolutional operations,
and
denote mean and variance, respectively, corresponding to the feature dimension.
is a hyperparameter, set as
. The
operation converts two-dimensional features into one-dimensional sequential features, and
is the output one-dimensional embedded features.
Subsequently, we divide the reshaped input feature map
into multiple non-overlapping regions of size
, and each region is integrated into a feature vector. Then, we perform linear projections on each feature vector to obtain three tensors:
Q,
K, and
V.
where
,
, and
are learnable weight matrices.
Upon acquiring the tensors of queries (
Q), keys (
K), and values (
V), we calculate the attention scores among regions. Initially, we compute the mean of
Q and
K on a specific dimension (
), to obtain region-level queries and keys (
and
). Then, we perform a matrix multiplication of
and
to generate the adjacency matrix
, reflecting the correlation degree among regions. Following this, we execute a
operation, gathering indices of the
k most relevant regions from each region, denoted as
. For each region
i, we use
to collect the most relevant key-value pairs from
K and
V, denoted as
and
. Ultimately, we perform an attention operation on the collected key-value pairs to yield the output
. The corresponding mathematical expressions are as follows:
where
and
are region-level queries and keys;
denotes the adjacency matrix representing the correlation degree among regions;
is the indices of the
k most relevant regions for each region;
and
are the most relevant key-value pairs; and
is the output obtained after the attention operation on the collected key-value pairs.
After the dynamic sparse attention mechanism completes information extraction, we reshape the attention map
into
and input it into the
module. In this module, we first perform a shift operation on the width dimension, then utilize a
convolution kernel, and convert the channel number into the embedding dimension
E to achieve feature tokenization. Subsequently, these tokens are processed through a
with a hidden layer dimension of
H and further processed through a depthwise convolution layer. The corresponding mathematical expressions are as follows:
where
W denotes the width of the feature map and
represents a depthwise separable convolution.
During the processing stage after depthwise convolution, we first apply the ReLU [
31] activation function to enhance the nonlinear representation ability of the feature map
Y, obtaining the activated feature map
. Then, we perform a shift operation on the height dimension to generate
. Next, using a 3 × 3 convolution kernel and setting the channel number to the embedding dimension
E, we tokenize these shifted features for the second time, forming tokens
. These newly formed tokens
are sent to another
module for processing. This
module has an output dimension of
O and its output is denoted as
Z. Importantly, to introduce long-range dependency of features, we add a residual connection here, that is, the original tokens
are added to
Z.
Finally, layer normalization is performed on the features to ensure the stability of feature distribution among layers, which benefits model training and generalization. We denote the output of this step as
. The mathematical expressions for this series of operations are as follows:
where
represents a shift operation along the height dimension,
denotes the ReLU activation function,
stands for tokenization,
refers to MLP with specific output dimensions, and
represents layer normalization.
We inserted the BATok-MLP module at the end of the feature extraction stage of the UNet network encoder, which effectively integrates local and global information. Within the Tok-MLP module, we enhance the capture of fine-grained features by moving the width and height of the features. Additionally, we address the weakness of traditional convolutional methods in understanding global contextual information through dynamic routing sparse attention mechanism, significantly improving the model’s understanding and representation capabilities.

 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
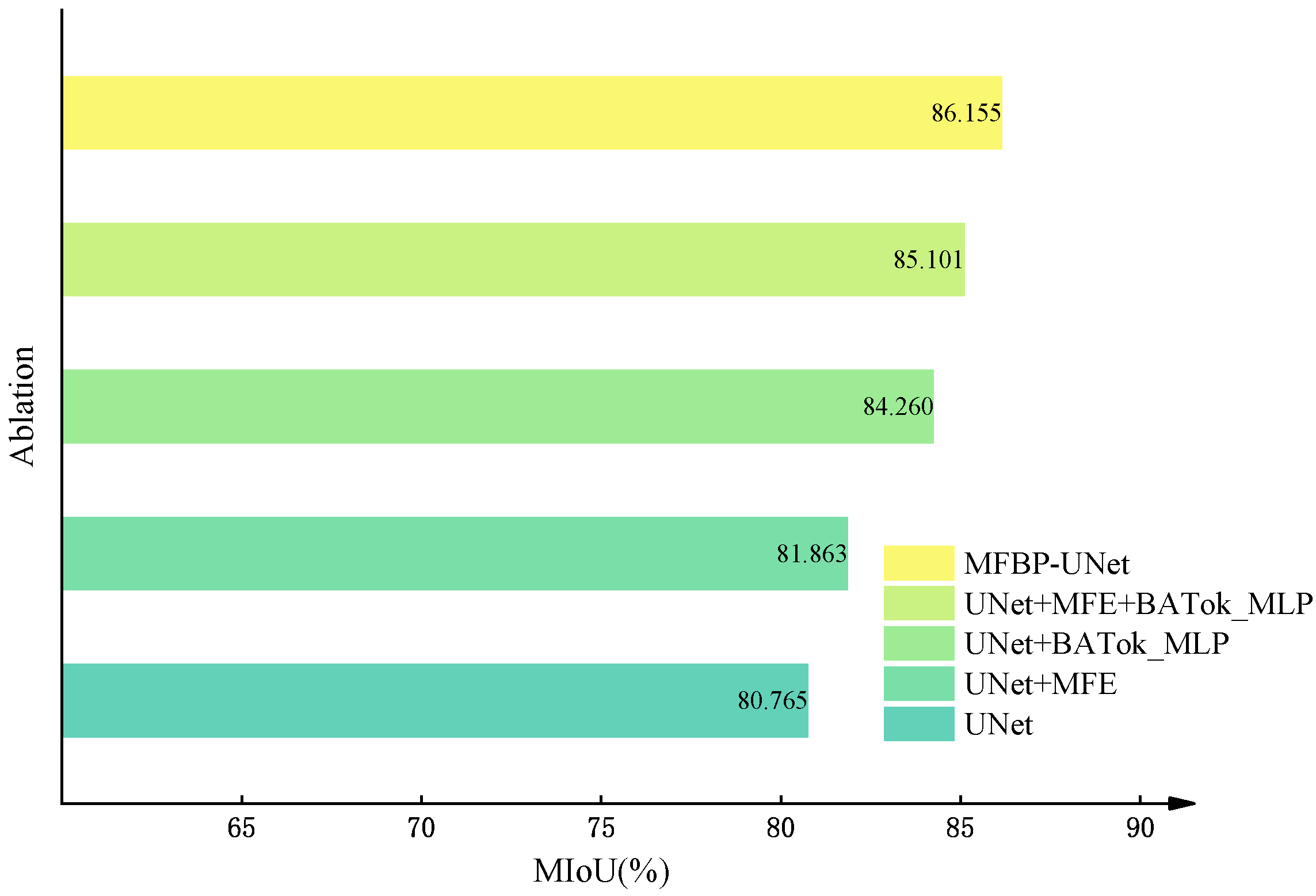{kind=link}
{kind=link}






























































