
Match Algorithms for Scientific Names in FlorItaly, the Portal to the Flora of Italy


Abstract
:1. Introduction
- A matcher, which compares the output of the parser with a thesaurus of names. Among matchers, some are based upon phonetic similarity (such as Soundex [16]), while others use metrics for measuring orthographic differences among strings, such as the Levenshtein distance. An interesting example is the Taxamatch algorithm [17], which combines the two approaches.
2. Materials and Methods
2.1. Data Preparation
2.2. The Algorithms
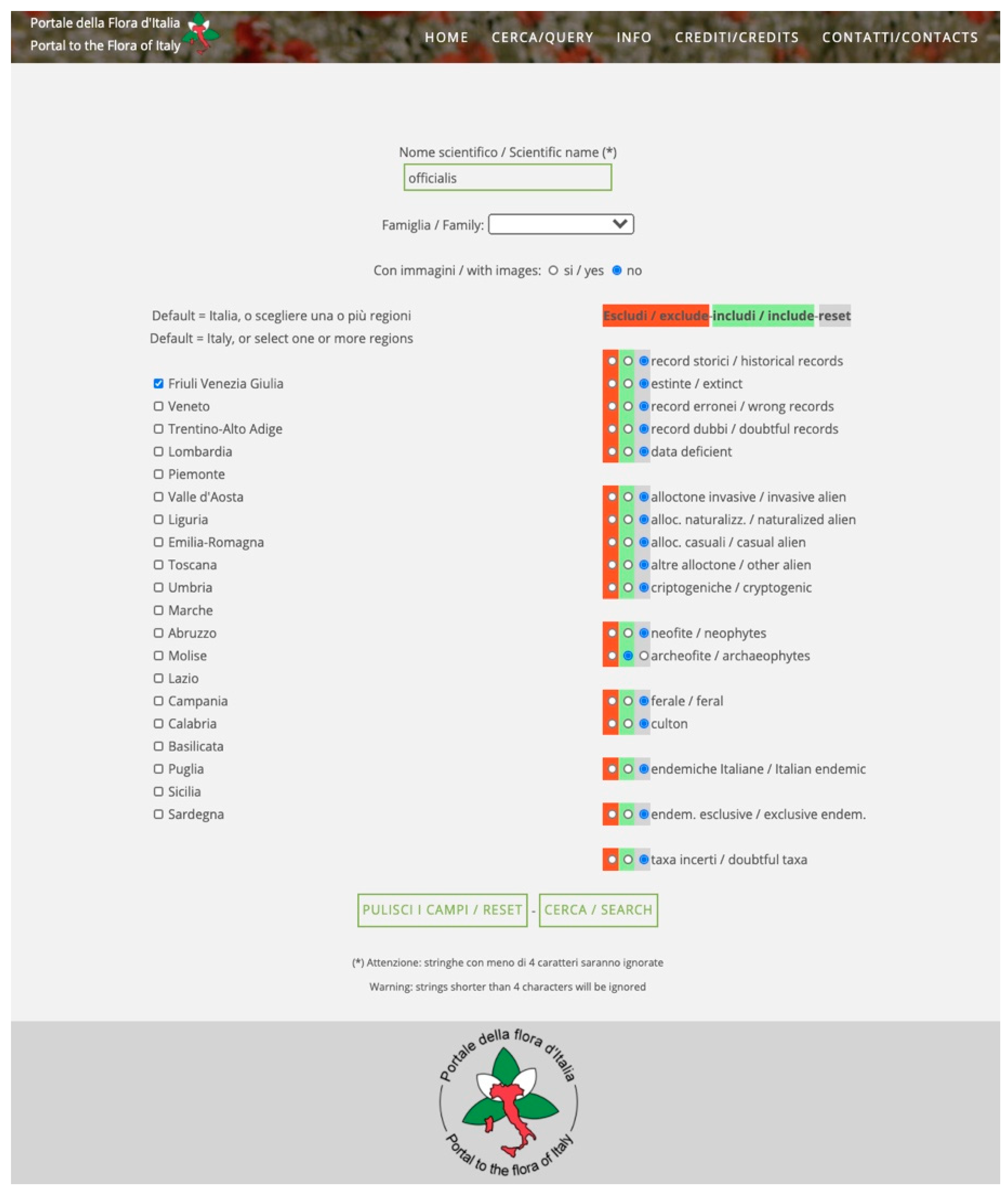
2.2.1. Input String
2.2.2. Lists of Taxa
(1) Normalization
(2) Pre-Processing
(3) Parsing
(4) Matching
(5) Algorithm Settings
3. Results
- Select the character used as a separator (comma, colon, semicolon, etc.);
- Select the terms used for infraspecific taxonomic ranks, such as subspecies, variety, and form;
- Allow the inclusion/exclusion of phonetic matches;
- Increase the tolerance of the algorithm, i.e., accepting a wider range of near matches than those allowed by the default settings. Increasing the degrees of freedom of the algorithm increases the time required for performing the query.
- Dataset A: 890 names, without authorities, and “s.” as the infraspecific identifier for subspecies;
- Dataset B: 2981 names, all written in uppercase;
- Dateset C: 304 names written following the current code of nomenclature (ICBN).
- The results are reported in Table 1.
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Linnaeus, C. Critica Botanica; Apud Conradum Wishoff: Lugduni Batavorum, The Netherlands, 1737. [Google Scholar]
- Patterson, D.; Cooper, J.; Kirk, P.; Pyle, R.; Remsen, D. Names are key to the big new biology. Trends Ecol. Evol. 2010, 25, 686–691. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nimis, P.L. A tale from Bioutopia. Nature 2001, 413, 21. [Google Scholar] [CrossRef]
- Kennedy, J.; Kukla, R.; Paterson, T.; Ludäscher, B.; Raschid, L. Scientific names are ambiguous as identifiers for biological taxa: Their context and definition are required for accurate data integration. In Data Integration in the Life Sciences, Proceedings of the Second International Workshop, San Diego, CA, USA, 20–22 July 2005; Lecture Notes in Computer Science 3615; Springer: Berlin/Heidelberg, Germany, 2005; pp. 80–95. [Google Scholar]
- Remsen, D. The use and limits of scientific names in biological informatics. ZooKeys 2016, 550, 207–223. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Clark, T.; Martin, S.; Liefeld, T. Globally distributed object identification for biological knowledgebases. Brief. Bioinform. 2004, 5, 59–70. [Google Scholar] [CrossRef]
- Martin, S.; Hohman, M.M.; Liefeld, T. The impact of Life Science Identifier on informatics data. Drug Discov. Today 2005, 10, 1566–1572. [Google Scholar] [CrossRef]
- Page, R.D.M. Biodiversity informatics: The challenge of linking data and the role of shared identifiers. Brief. Bioinform. 2008, 9, 345–354. [Google Scholar] [CrossRef]
- Boyle, B.; Hopkins, N.; Lu, Z.; Garay, J.A.R.; Mozzherin, D.; Rees, T.; Matasci, N.; Narro, M.L.; Piel, W.H.; Mckay, S.J.; et al. The taxonomic name resolution service: An online tool for automated standardization of plant names. BMC Bioinform. 2013, 14, 16. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cachuela-Palacio, M. Towards an index of all known species: The Catalogue of Life, its rationale, design and use. Integr. Zoöl. 2006, 1, 18–21. [Google Scholar] [CrossRef] [PubMed]
- Norman, K.E.A.; Chamberlain, S.; Boettiger, C. taxadb: A high-performance local taxonomic database interface. Methods Ecol. Evol. 2020, 11, 1153–1159. [Google Scholar] [CrossRef]
- Rees, T. TAXAMATCH, a “fuzzy” matching algorithm for taxon names, and potential applications in taxonomic data-bases. In Proceedings of TDWG; Biodiversity Information Standards (TDWG) and the Missouri Botanical Garden: St. Louis, MO, USA, 2008; p. 35. [Google Scholar]
- Mozzherin, D.Y.; Myltsev, A.A.; Patterson, D.J. “gnparser”: A powerful parser for scientific names based on Parsing Expression Grammar. BMC Bioinform. 2017, 18, 279. [Google Scholar] [CrossRef] [Green Version]
- GBIF Name Parser. Available online: https://www.gbif.org/tools/name-parser (accessed on 20 January 2021).
- Berghe, E.V.; Coro, G.; Bailly, N.; Fiorellato, F.; Aldemita, C.; Ellenbroek, A.; Pagano, P. Retrieving taxa names from large biodiversity data collections using a flexible matching workflow. Ecol. Inform. 2015, 28, 29–41. [Google Scholar] [CrossRef] [Green Version]
- Christen, P. A Comparison of Personal Name Matching: Techniques and Practical Issues. In Proceedings of the Sixth IEEE International Conference on Data Mining—Workshops (ICDMW’06), Hong Kong, China, 18–22 December 2006; pp. 290–294. [Google Scholar]
- Rees, T. Taxamatch, an Algorithm for Near (‘Fuzzy’) Matching of Scientific Names in Taxonomic Databases. PLoS ONE 2014, 9, e107510. [Google Scholar] [CrossRef] [Green Version]
- Martellos, S.; Bartolucci, F.; Conti, F.; Galasso, G.; Moro, A.; Pennesi, R.; Peruzzi, L.; Pittao, E.; Nimis, P.L. FlorItaly—The portal to the Flora of Italy. PhytoKeys 2020, 156, 55–71. [Google Scholar] [CrossRef]
- Bartolucci, F.; Peruzzi, L.; Galasso, G.; Albano, A.; Alessandrini, A.; Ardenghi, N.M.G.; Astuti, G.; Bacchetta, G.; Ballelli, S.; Banfi, E.; et al. An updated checklist of the vascular flora native to Italy. Plant Biosyst. Int. J. Deal. Asp. Plant Biol. 2018, 152, 179–303. [Google Scholar] [CrossRef]
- Galasso, G.; Conti, F.; Peruzzi, L.; Ardenghi, N.M.G.; Banfi, E.; Celesti-Grapow, L.; Albano, A.; Alessandrini, A.; Bacchetta, G.; Ballelli, S.; et al. An updated checklist of the vascular flora alien to Italy. Plant Biosyst. Int. J. Deal. Asp. Plant Biol. 2018, 152, 556–592. [Google Scholar] [CrossRef]
- Bartolucci, F.; Domina, G.; Ardenghi, N.M.; Banfi, E.; Bernardo, L.; Bonari, G.; Buccomino, G.; Calvia, G.; Carruggio, F.; Cavallaro, V.; et al. Notulae to the Italian native vascular flora: 5. Ital. Bot. 2018, 5, 71–81. [Google Scholar] [CrossRef]
- Galasso, G.; Domina, G.; Adorni, M.; Ardenghi, N.M.; Bonari, G.; Buono, S.; Cancellieri, L.; Chianese, G.; Ferretti, G.; Fiaschi, T.; et al. Notulae to the Italian alien vascular flora: 5. Ital. Bot. 2018, 5, 45–56. [Google Scholar] [CrossRef] [Green Version]
- Bartolucci, F.; Domina, G.; Ardenghi, N.M.; Bacchetta, G.; Bernardo, L.; Buccomino, G.; Buono, S.; Caldararo, F.; Calvia, G.; Carruggio, F.; et al. Notulae to the Italian native vascular flora: 6. Ital. Bot. 2018, 6, 45–64. [Google Scholar] [CrossRef] [Green Version]
- Galasso, G.; Domina, G.; Alessandrini, A.; Ardenghi, N.M.; Bacchetta, G.; Ballelli, S.; Bartolucci, F.; Brundu, G.; Buono, S.; Busnardo, G.; et al. Notulae to the Italian alien vascular flora: 6. Ital. Bot. 2018, 6, 65–90. [Google Scholar] [CrossRef] [Green Version]
- Bartolucci, F.; Domina, G.; Alessandrini, A.; Angiolini, C.; Ardenghi, N.M.; Bacchetta, G.; Banfi, E.; Bolpagni, R.; Bonari, G.; Bräuchler, C.; et al. Notulae to the Italian native vascular flora: 7. Ital. Bot. 2019, 7, 125–148. [Google Scholar] [CrossRef] [Green Version]
- Galasso, G.; Domina, G.; Ardenghi, N.M.; Aristarchi, C.; Bacchetta, G.; Bartolucci, F.; Bonari, G.; Bouvet, D.; Brundu, G.; Buono, S.; et al. Notulae to the Italian alien vascular flora: 7. Ital. Bot. 2019, 7, 157–182. [Google Scholar] [CrossRef] [Green Version]
- Bartolucci, F.; Domina, G.; Ardenghi, N.M.G.; Bacaro, G.; Bacchetta, G.; Ballarin, F.; Banfi, E.; Barberis, G.; Beccarisi, L.; Bernardo, L.; et al. Notulae to the Italian native vascular flora: 8. Ital. Bot. 2019, 8, 95–116. [Google Scholar] [CrossRef]
- Galasso, G.; Domina, G.; Andreatta, S.; Angiolini, C.; Ardenghi, N.M.G.; Aristarchi, C.; Arnoul, M.; Azzella, M.M.; Bacchetta, G.; Bartolucci, F.; et al. Notulae to the Italian alien vascular flora: 8. Ital. Bot. 2019, 8, 63–93. [Google Scholar] [CrossRef]
- Bartolucci, F.; Domina, G.; Andreatta, S.; Angius, R.; Ardenghi, N.M.G.; Bacchetta, G.; Ballelli, S.; Banfi, E.; Barberis, D.; Barberis, G.; et al. Notulae to the Italian native vascular flora: 9. Ital. Bot. 2020, 9, 71–86. [Google Scholar] [CrossRef]
- Galasso, G.; Domina, G.; Adorni, M.; Angiolini, C.; Apruzzese, M.; Ardenghi, N.M.G.; Assini, S.; Aversa, M.; Bacchetta, G.; Banfi, E.; et al. Notulae to the Italian alien vascular flora: 9. Ital. Bot. 2020, 9, 47–70. [Google Scholar] [CrossRef]
- Bartolucci, F.; Domina, G.; Bagella, S.; Barberis, G.; Briozzo, I.; Calbi, M.; Caria, M.C.; Cavallaro, V.; Chianese, G.; Cibei, C.; et al. Notulae to the Italian native vascular flora: 10. Ital. Bot. 2020, 10, 47–55. [Google Scholar] [CrossRef]
- Galasso, G.; Domina, G.; Azzaro, D.; Bagella, S.; Barone, G.; Bartolucci, F.; Bianco, M.; Bolzani, P.; Bonari, G.; Boscutti, F.; et al. Notulae to the Italian alien vascular flora: 10. Ital. Bot. 2020, 10, 57–71. [Google Scholar] [CrossRef]
- Sigovini, M.; Keppel, E.; Tagliapietra, D. Open Nomenclature in the biodiversity era. Methods Ecol. Evol. 2016, 7, 1217–1225. [Google Scholar] [CrossRef]
- Jansen, F.; Dengler, J. Plant names in vegetation databases—A neglected source of bias. J. Veg. Sci. 2010, 21, 1179–1186. [Google Scholar] [CrossRef]
- iPlant Modified Version of the SilverBiology PHP/MySQL Port of Taxamatch. Available online: https://github.com/iPlantCollaborativeOpenSource/TNRS (accessed on 20 January 2021).
- iPlant Taxonomic Name Resolution Service. Available online: http://tnrs.iplantcollaborative.org (accessed on 20 January 2021).
- Global Name Parser/Gnparser (v0.14.4). Available online: https://parser.globalnames.org (accessed on 20 January 2021).
- Fiori, A. Nuova Flora Analitica d’Italia; Tipografia M. Ricci: Firenze, Italy, 1923. [Google Scholar]
- Zangheri, P. Flora Italica; Cedam: Padova, Italy, 1976. [Google Scholar]
- Pignatti, S. Flora d’Italia; Edagricole: Milano, Italy, 1982. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Dataset | Total Names | Unambiguous Matches | Ambiguous Matches | No Matches |
|---|---|---|---|---|
| A | 890 | 609 (68.43%) | 271 (30.45%) | 10 (1.12%) |
| B | 2981 | 2649 (88.86%) | 296 (9.93%) | 36 (1.21%) |
| C | 304 | 293 (96.38%) | 10 (3.29%) | 1 (0.33%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Conti, M.; Nimis, P.L.; Martellos, S. Match Algorithms for Scientific Names in FlorItaly, the Portal to the Flora of Italy. Plants 2021, 10, 974. https://doi.org/10.3390/plants10050974
Conti M, Nimis PL, Martellos S. Match Algorithms for Scientific Names in FlorItaly, the Portal to the Flora of Italy. Plants. 2021; 10(5):974. https://doi.org/10.3390/plants10050974
Chicago/Turabian StyleConti, Matteo, Pier Luigi Nimis, and Stefano Martellos. 2021. "Match Algorithms for Scientific Names in FlorItaly, the Portal to the Flora of Italy" Plants 10, no. 5: 974. https://doi.org/10.3390/plants10050974