
Investigating Explanatory Factors of Machine Learning Models for Plant Classification


Abstract
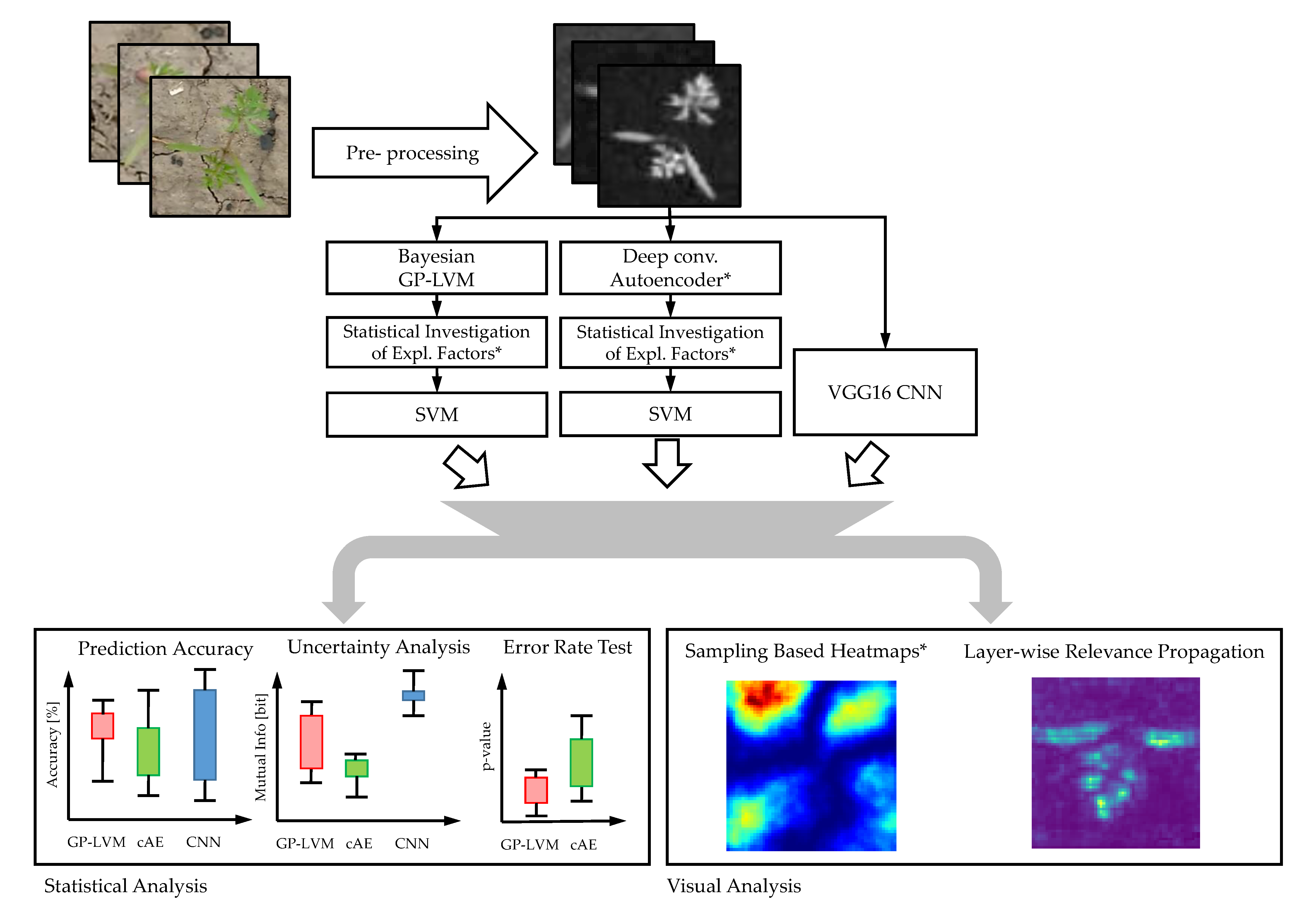
:1. Introduction
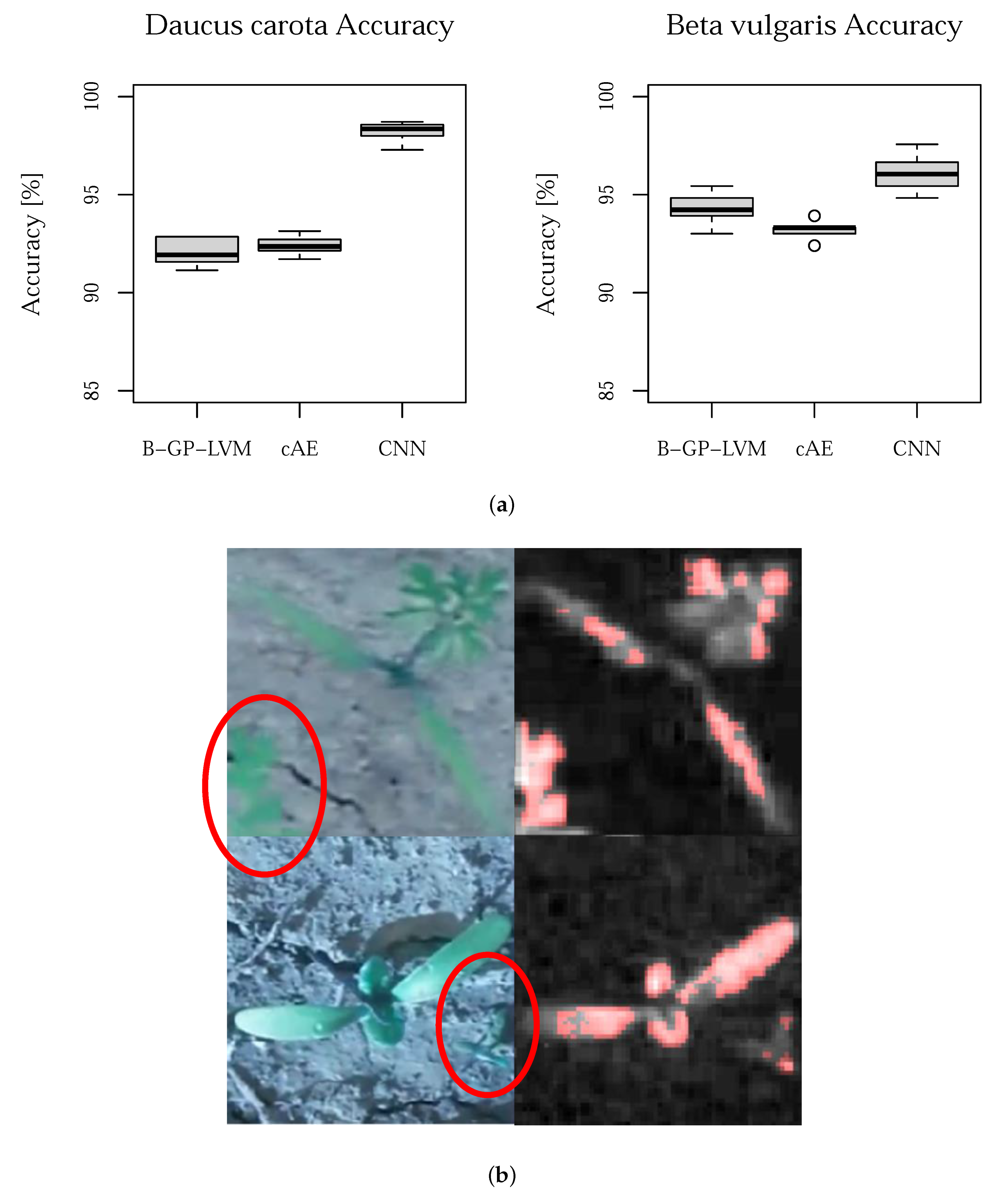
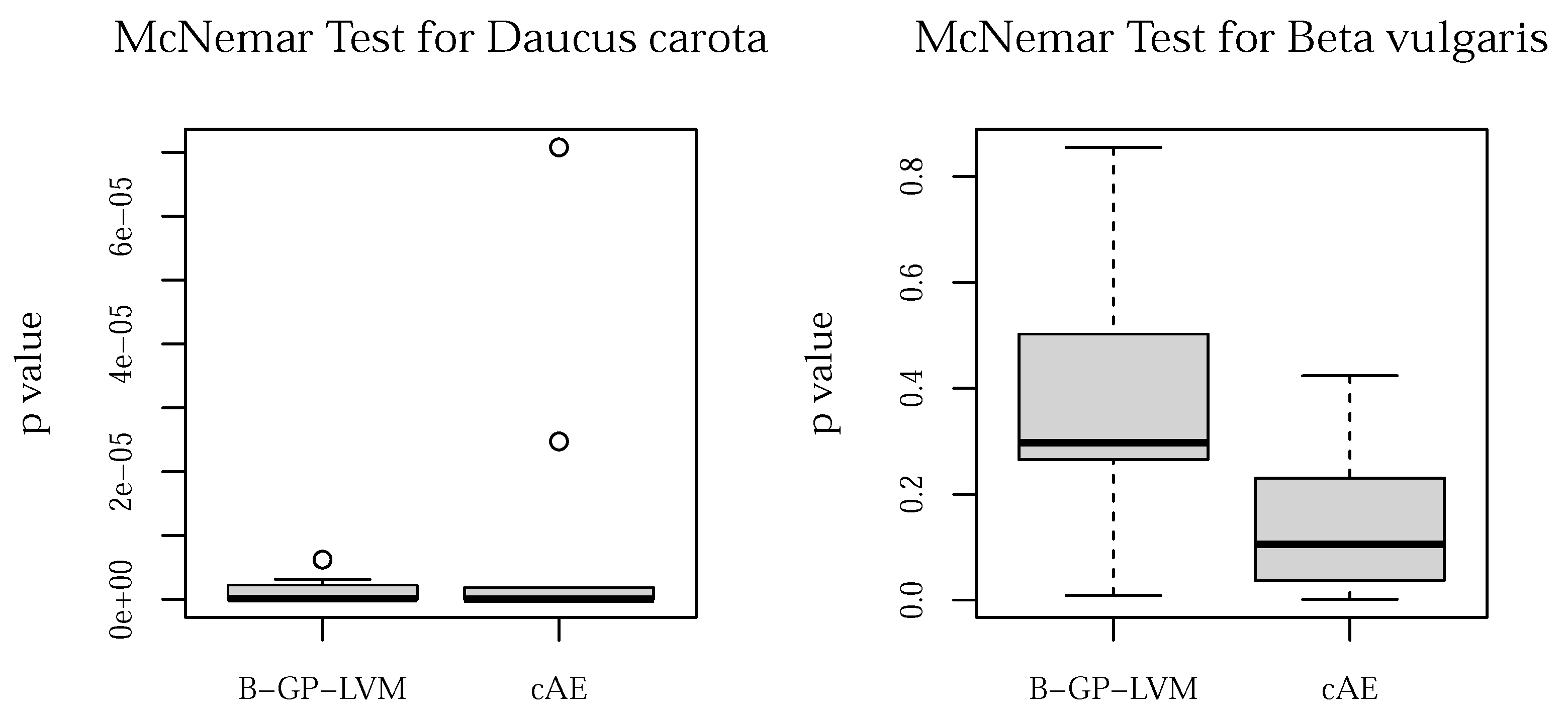
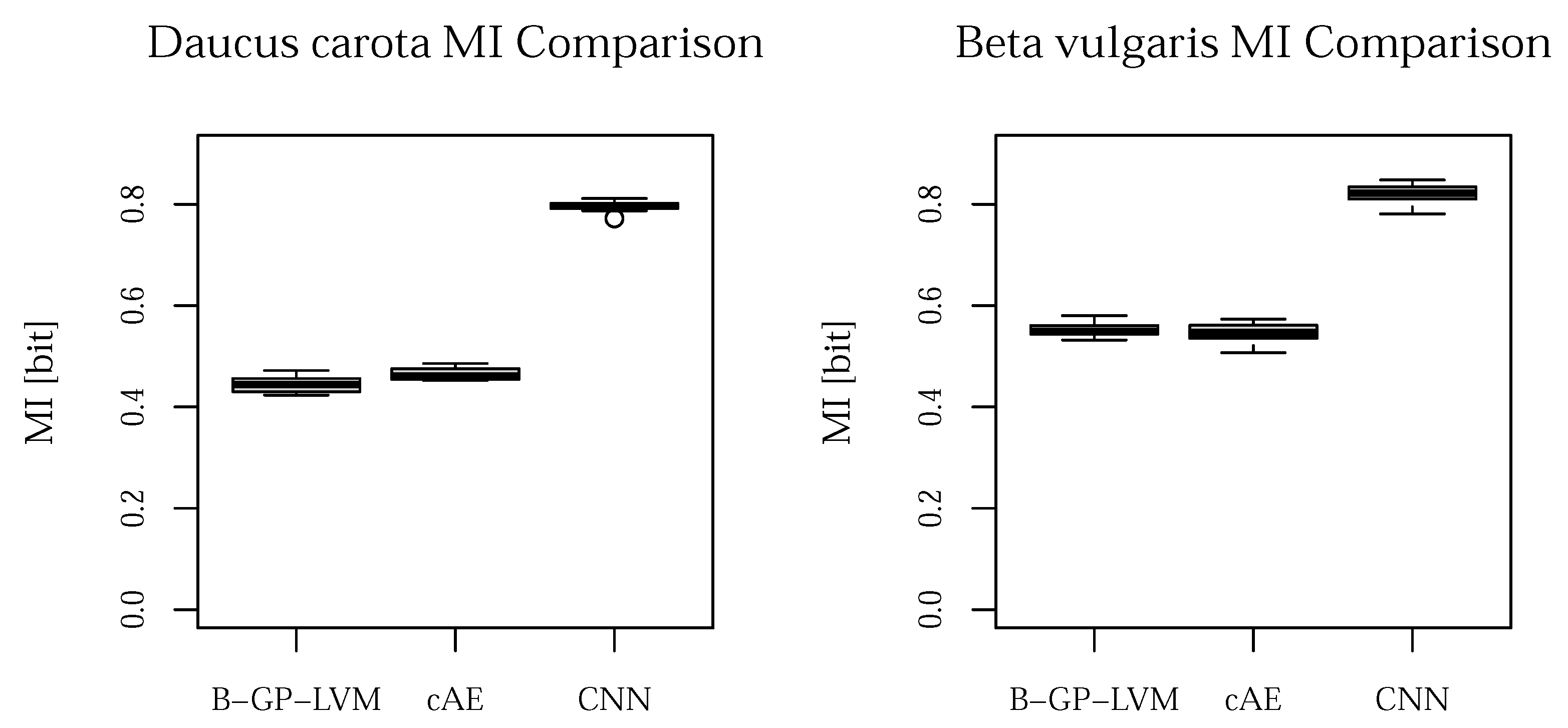
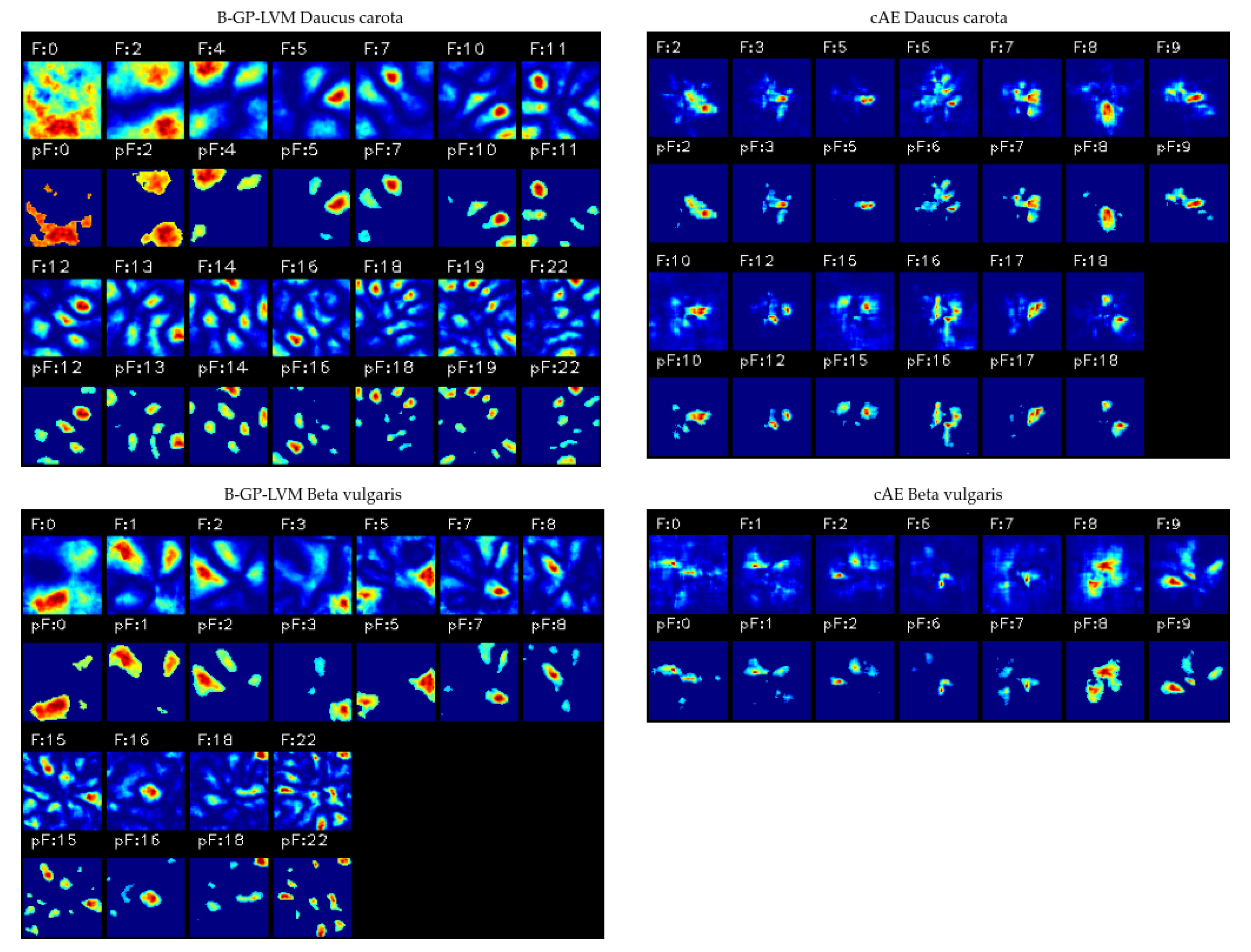
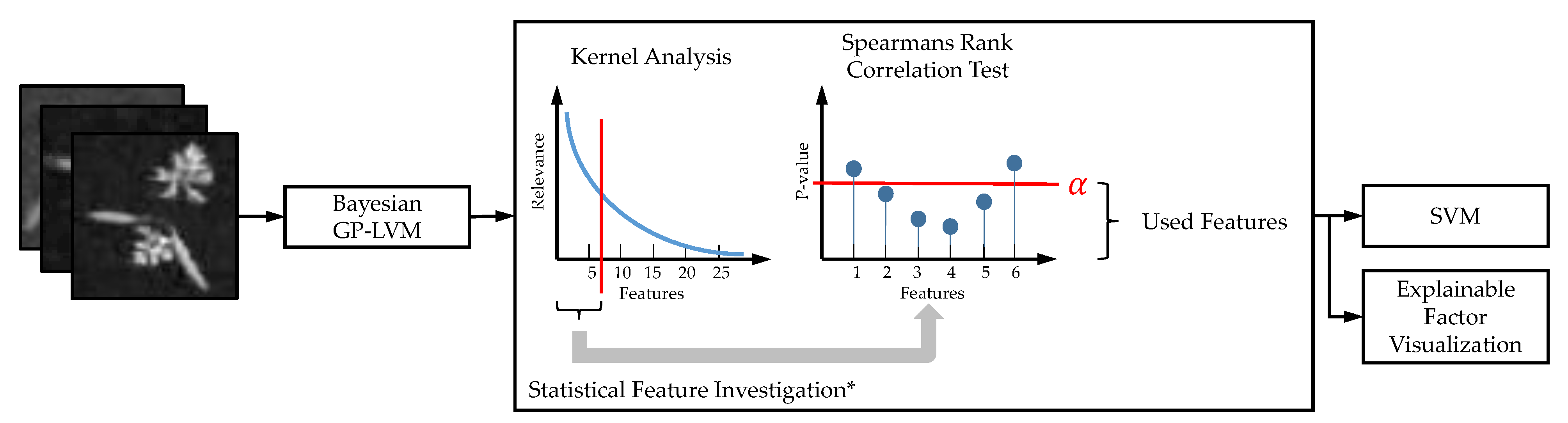
- Biological interpretation: We interpret the visual reasons for classification of the used supervised CNNs using layer-wise relevance propagation (LRP) [25,26] and for the unsupervised models the sampling based methodology introduced in [29,37]. We evaluate the significance of the pixels in the resulting saliency maps (heatmaps) using the pixel-wise significance test introduced in [29]. We refer this test as the test for saliency maps. We extend the pipeline of [29] using statistical feature analysis instead of manual selection.
- Classification accuracy: We compare the predictive accuracy using a five-fold cross-validation in 10 iterations relying on reshuffled data sets.
2. Related Work
3. Results
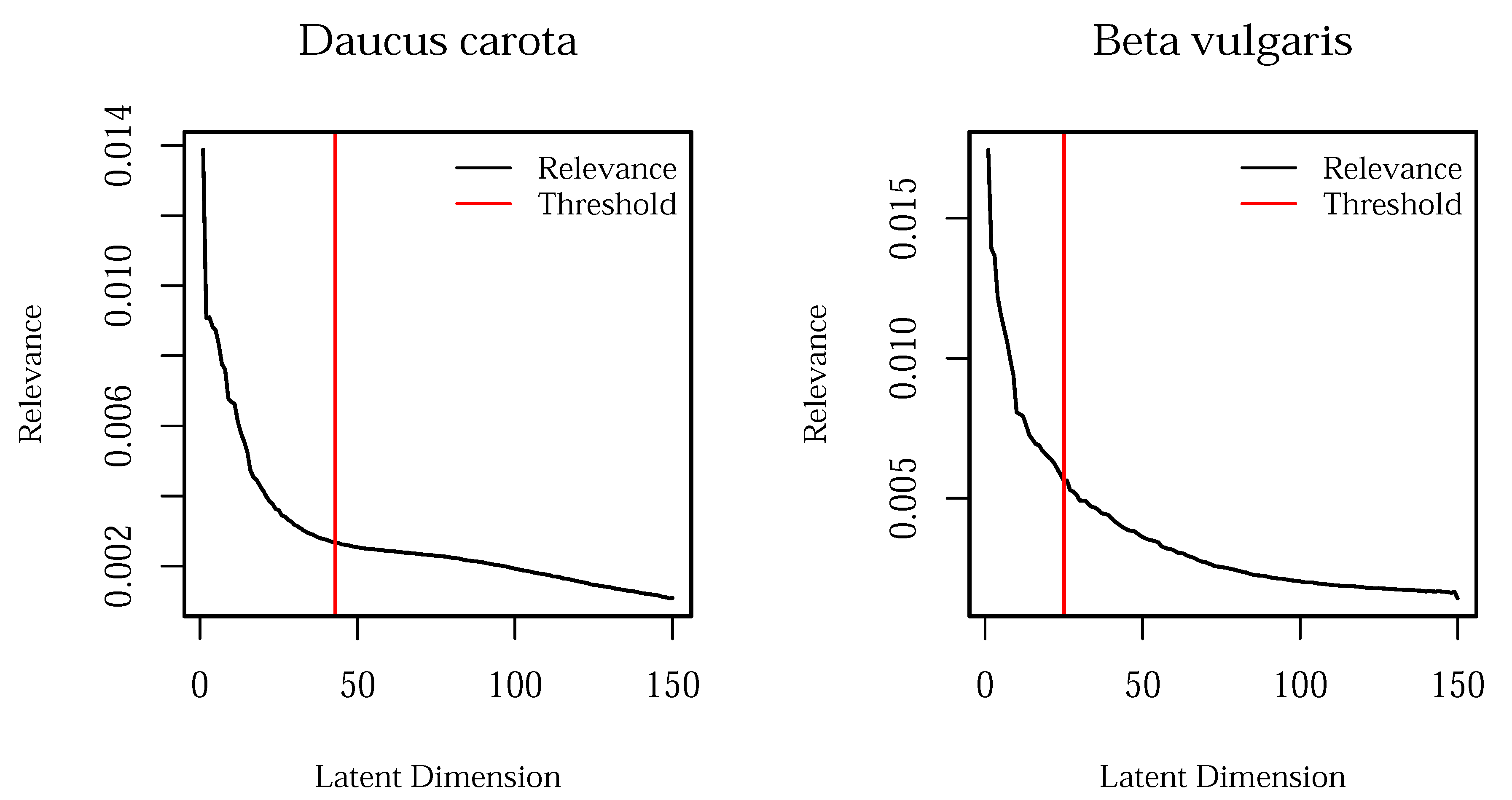
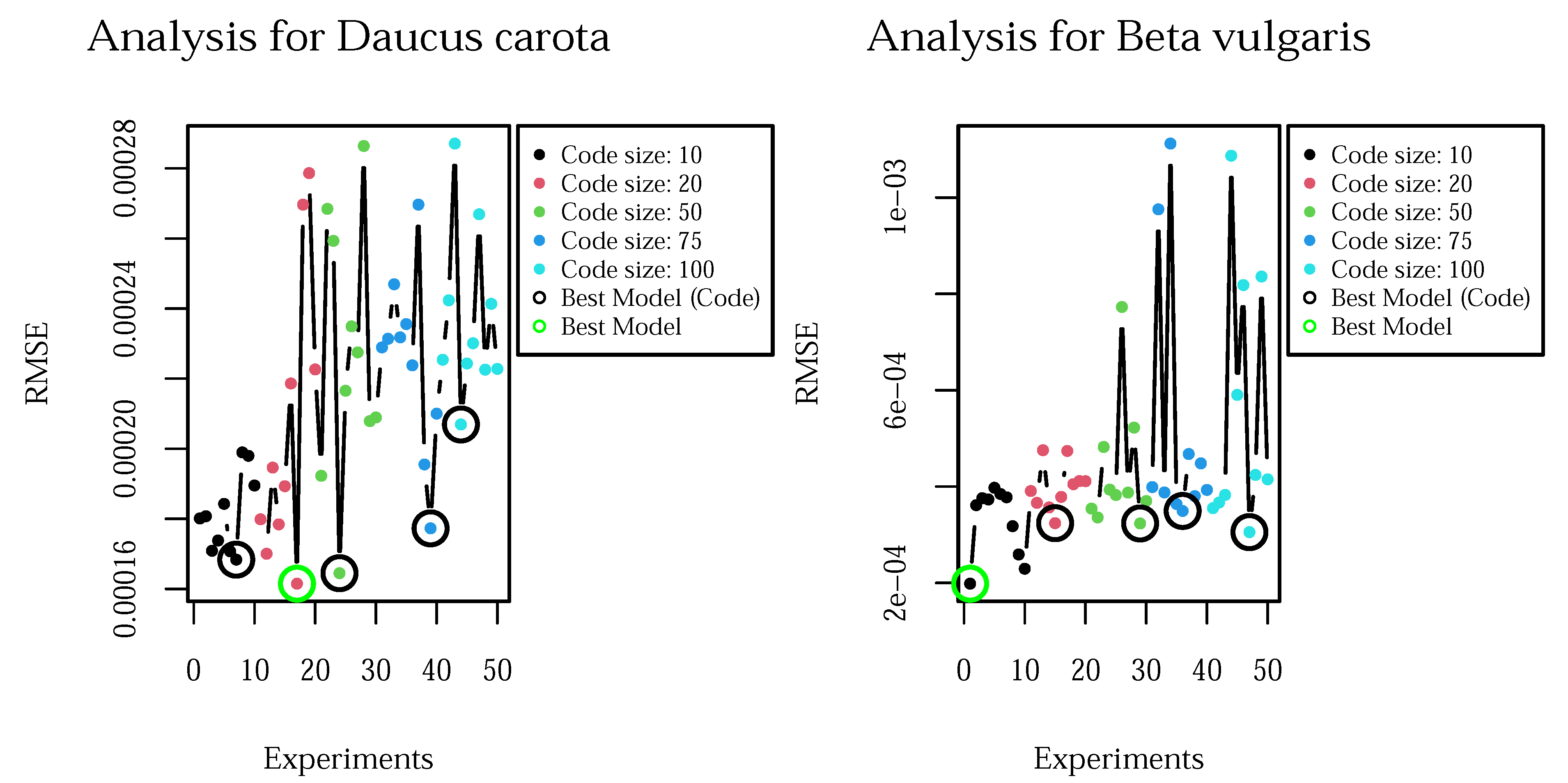
3.1. Model Selection
3.2. Model Performance
4. Discussion
5. Materials and Methods
5.1. Image Data Sets
5.2. Data Processing
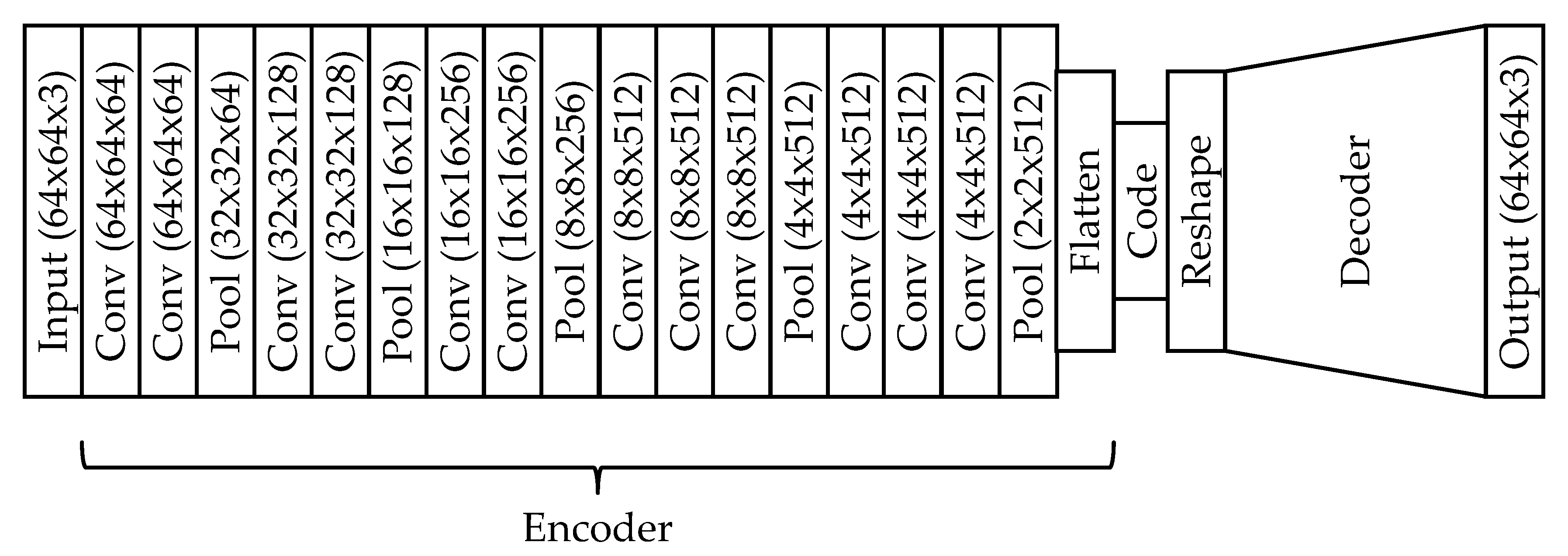
5.2.1. Convolutional Neuronal Network
5.2.2. Gaussian Process Latent Variable Model
- Initial guess of the latent space: We analyzed the image vector matrix using the principal component analysis [48]. The number of principal components explaining of variance were used as an initial guess of d, the number of latent plant features. We used sklearn’s principal component analysis implementation [56].
- Estimation of the auxiliary points: The maximum marginal log likelihood was used to find the optimal number of auxiliary points in a range of . We used the minimum number of auxiliary points above of the maximum marginal log likelihood.
- Latent dimension estimation: The number of latent dimensions was estimated using the aforementioned optimized number of auxiliary points and the maximum marginal log likelihood in a range of latent dimensions.
5.2.3. Deep Convolutional Autoencoder
5.2.4. Statistical Assessment of Saliency Maps
5.2.5. Classification of Latent Features
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| B-GP-LVM | Bayesian Gaussian process latent variable model |
| cAE | (Deep) convolutional autoencoder |
| CNN | Convolutional neuronal network |
| GP-LVM | Gaussian process latent variable model |
| LRP | Layer-wise relevance propagation |
| SVM | Support Vector machine |
References
- Integrated Digitized Biocollections. Available online: https://www.idigbio.org/ (accessed on 14 May 2020).
- Muséum National d’Histoire Naturelle. Available online: https://www.mnhn.fr/en/collections (accessed on 14 May 2020).
- Digitalis Education Solutions, Digitarium Datasets. Available online: http://www.digitaliseducation.com/products-data (accessed on 14 May 2020).
- Olsen, A.; Konovalov, D.A.; Philippa, B.; Ridd, P.; Wood, J.C.; Johns, J.; Banks, W.; Girgenti, B.; Kenny, O.; Whinney, J.; et al. DeepWeeds: A Multiclass Weed Species Image Dataset for Deep Learning. Sci. Rep. 2019, 9, 2058. [Google Scholar] [CrossRef]
- Wäldchen, J.; Rzanny, M.; Seeland, M.; Mäder, P. Automated plant species identification—Trends and future directions. PLoS Comput. Biol. 2018, 14, e1005993. [Google Scholar] [CrossRef] [Green Version]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 1–74. [Google Scholar] [CrossRef]
- Nguyen, T.T.N.; Le, T.L.; Vu, H.; Hoang, V.S. Towards an Automatic Plant Identification System without Dedicated Dataset. IJMLC 2019, 9, 26–34. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar] [CrossRef] [Green Version]
- Sun, Y.; Liu, Y.; Wang, G.; Zhang, H. Deep Learning for Plant Identification in Natural Environment. Comput. Intell. Neurosci. 2017, 2017, 7361042. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef] [Green Version]
- Fawakherji, M.; Youssef, A.; Bloisi, D.; Pretto, A.; Nardi, D. Crop and Weeds Classification for Precision Agriculture Using Context-Independent Pixel-Wise Segmentation. In Proceedings of the 2019 Third IEEE International Conference on Robotic Computing (IRC), Naples, Italy, 25–27 February 2019; pp. 146–152. [Google Scholar] [CrossRef]
- Milioto, A.; Lottes, P.; Stachniss, C. Real-Time Semantic Segmentation of Crop and Weed for Precision Agriculture Robots Leveraging Background Knowledge in CNNs. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–26 May 2018; pp. 2229–2235. [Google Scholar] [CrossRef] [Green Version]
- Afifi, A.; Alhumam, A.; Abdelwahab, A. Convolutional Neural Network for Automatic Identification of Plant Diseases with Limited Data. Plants 2021, 10, 28. [Google Scholar] [CrossRef] [PubMed]
- Hasan, R.I.; Yusuf, S.; Alzubaidi, L. Review of the State of the Art of Deep Learning for Plant Diseases: A Broad Analysis and Discussion. Plants 2020, 9, 1302. [Google Scholar] [CrossRef]
- Saleem, M.H.; Khanchi, S.; Potgieter, J.; Arif, K.M. Image-Based Plant Disease Identification by Deep Learning Meta-Architectures. Plants 2020, 9, 1451. [Google Scholar] [CrossRef]
- Boulent, J.; Foucher, S.; Théau, J.; St-Charles, P.L. Convolutional Neural Networks for the Automatic Identification of Plant Diseases. Front. Plant Sci. 2019, 10, 941. [Google Scholar] [CrossRef] [Green Version]
- Wäldchen, J.; Mäder, P. Plant Species Identification Using Computer Vision Techniques: A Systematic Literature Review. Arch. Comput. Methods Eng. 2018, 25, 507–543. [Google Scholar] [CrossRef] [Green Version]
- Nasiri, A.; Taheri-Garavand, A.; Fanourakis, D.; Zhang, Y.D.; Nikoloudakis, N. Automated Grapevine Cultivar Identification via Leaf Imaging and Deep Convolutional Neural Networks: A Proof-of-Concept Study Employing Primary Iranian Varieties. Plants 2021, 10, 1628. [Google Scholar] [CrossRef] [PubMed]
- Genaev, M.A.; Skolotneva, E.S.; Gultyaeva, E.I.; Orlova, E.A.; Bechtold, N.P.; Afonnikov, D.A. Image-Based Wheat Fungi Diseases Identification by Deep Learning. Plants 2021, 10, 1500. [Google Scholar] [CrossRef]
- Lapuschkin, S.; Wäldchen, S.; Binder, A.; Montavon, G.; Samek, W.; Müller, K.R. Unmasking Clever Hans predictors and assessing what machines really learn. Nat. Commun. 2019, 10, 1096. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bengio, Y.; Courville, A.; Vincent, P. Representation Learning: A Review and New Perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- Samek, W.; Montavon, G.; Lapuschkin, S.; Anders, C.J.; Müller, K.R. Explaining Deep Neural Networks and Beyond: A Review of Methods and Applications. Proc. IEEE 2021, 109, 247–278. [Google Scholar] [CrossRef]
- Samek, W.; Müller, K.R. Towards Explainable Artificial Intelligence. In Explainable AI: Interpreting, Explaining and Visualizing Deep Learning; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 5–22. [Google Scholar] [CrossRef] [Green Version]
- Montavon, G.; Samek, W.; Müller, K.R. Methods for interpreting and understanding deep neural networks. Digit. Signal Process. 2018, 73, 1–15. [Google Scholar] [CrossRef]
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.R.; Samek, W. On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation. PLoS ONE 2015, 10, e0130140. [Google Scholar] [CrossRef] [Green Version]
- Anders, C.J.; Weber, L.; Neumann, D.; Samek, W.; Müller, K.R.; Lapuschkin, S. Finding and removing Clever Hans: Using explanation methods to debug and improve deep models. Inf. Fusion 2022, 77, 261–295. [Google Scholar] [CrossRef]
- Marcus, G. Deep Learning: A Critical Appraisal. arXiv 2018, arXiv:1801.00631. [Google Scholar]
- Wöber, W.; Curto, M.; Tibihika, P.; Meulenbroek, P.; Alemayehu, E.; Mehnen, L.; Meimberg, H.; Sykacek, P. Identifying geographically differentiated features of Ethopian Nile tilapia (Oreochromis niloticus) morphology with machine learning. PLoS ONE 2021, 16, e0249593. [Google Scholar] [CrossRef]
- Pett, M.A. Nonparametric Statistics for Health Care Research: Statistics for Small Samples and Unusual Distributions; SAGE Publications: Newbury Park, CA, USA, 2015. [Google Scholar]
- Girshick, R.B.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv 2013, arXiv:1311.2524. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR, 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Lawrence, N.D. Probabilistic Non-linear Principal Component Analysis with Gaussian Process Latent Variable Models. J. Mach. Learn. Res. 2005, 6, 1783–1816. [Google Scholar]
- Dong, G.; Liao, G.; Liu, H.; Kuang, G. A Review of the Autoencoder and Its Variants: A Comparative Perspective from Target Recognition in Synthetic-Aperture Radar Images. IEEE Geosci. Remote Sens. Mag. 2018, 6, 44–68. [Google Scholar] [CrossRef]
- Nayak, J.; Naik, B.; Behera, D.H. A comprehensive survey on support vector machine in data mining tasks: Applications & challenges. Int. J. Database Theory Appl. 2015, 8, 169–186. [Google Scholar] [CrossRef]
- Wöber, W.; Mohamed, A.; Olaverri-Monreal, C. Classification of Streetsigns Using Gaussian Process Latent Variable Models. In Proceedings of the 2019 IEEE International Conference on Connected Vehicles and Expo, ICCVE 2019, Graz, Austria, 4–8 November 2019; pp. 1–6. [Google Scholar] [CrossRef]
- MacKay, D.J.C. Information Theory, Inference & Learning Algorithms; Cambridge University Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Titsias, M.K.; Lawrence, N.D. Bayesian Gaussian Process Latent Variable Model. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics (AISTATS), Chia Laguna Resort, Sardinia, Italy, 13–15 May 2010; pp. 844–851. [Google Scholar]
- Freund, R.J.; Wilson, W.J. Statistical Methods; Elsevier Science: Amsterdam, The Netherlands, 2003. [Google Scholar]
- Turk, M.A.; Pentland, A.P. Face recognition using eigenfaces. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Shanghai, China, 11–13 March 2011; pp. 586–591. [Google Scholar] [CrossRef]
- Samek, W.; Wiegand, T.; Müller, K.R. Explainable Artificial Intelligence: Understanding, Visualizing, and Interpreting Deep Learning Models. ITU J. ICT Discov. 2018, 1, 49–58. [Google Scholar]
- Koh, P.W.; Liang, P. Understanding Black-box Predictions via Influence Functions. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Austrialia, 6–11 August 2017; Volume 70, pp. 1885–1894. [Google Scholar]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps. arXiv 2013, arXiv:1312.6034. [Google Scholar]
- Selvaraju, R.R.; Das, A.; Vedantam, R.; Cogswell, M.; Parikh, D.; Batra, D. Grad-CAM: Why did you say that? Visual Explanations from Deep Networks via Gradient-based Localization. arXiv 2016, arXiv:1610.02391. [Google Scholar]
- Anders, C.J.; Neumann, D.; Marin, Talmaj, S.W.; Müller, K.R.; Lapuschkin, S. XAI for Analyzing and Unlearning Spurious Correlations in ImageNet. In Proceedings of the ICML’20 Workshop on Extending Explainable AI Beyond Deep Models and Classifiers (XXAI), Vienna, Austria, 17 July 2020. [Google Scholar]
- Bergstra, J.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for Hyper-Parameter Optimization. In Proceedings of the 24th International Conference on Neural Information Processing Systems, Granada, Spain, 12–15 December 2011. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer Science+Business Media: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Bradski, G. The OpenCV Library. Dr. Dobb’s J. Softw. Tools 2000, 120, 122–125. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; The MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Keras. RMSprop Class. Available online: https://keras.io/api/optimizers/rmsprop/ (accessed on 3 December 2021).
- Chollet, F. Keras. 2015. Available online: https://github.com/fchollet/keras (accessed on 3 December 2021).
- Blei, D.M.; Kucukelbir, A.; McAuliffe, J.D. Variational Inference: A Review for Statisticians. J. Am. Stat. Assoc. 2017, 112, 859–877. [Google Scholar] [CrossRef] [Green Version]
- Titsias, M. Variational Learning of Inducing Variables in Sparse Gaussian Processes. In Artificial Intelligence and Statistics; van Dyk, D., Welling, M., Eds.; PMLR: Clearwater Beach, FL, USA, 2009; Volume 5, pp. 567–574. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- GPy. GPy: A Gaussian Process Framework in Python. 2012. Available online: http://github.com/SheffieldML/GPy (accessed on 3 December 2021).
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning (Adaptive Computation and Machine Learning); The MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Savicky, P. Pspearman: Spearman’s Rank Correlation Test; R Package Version 0.3-0; R Foundation for Statistical Computing: Vienna, Austria, 2014. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021. [Google Scholar]
- Lawrence, N.D. Gaussian Process Latent Variable Models for Visualisation of High Dimensional Data. In Proceedings of the 16th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 13–18 December 2004; MIT Press: Cambridge, MA, USA, 2004; pp. 329–336. [Google Scholar]
- Yan, Y. rBayesianOptimization: Bayesian Optimization of Hyperparameters; R Package Version 1.1.0; R Foundation for Statistical Computing: Vienna, Austria, 2016. [Google Scholar]
- Meyer, D.; Dimitriadou, E.; Hornik, K.; Weingessel, A.; Leisch, F. e1071: Misc Functions of the Department of Statistics, Probability Theory Group (Formerly: E1071), TU Wien; R Package Version 1.7-7; R Foundation for Statistical Computing: Vienna, Austria, 2021. [Google Scholar]
- Damianou, A.; Lawrence, N.D. Deep Gaussian Processes. In Proceedings of the Sixteenth International Conference on Artificial Intelligence and Statistics, Scottsdale, AZ, USA, 29 April–1 May 2013; Volume 31, pp. 207–215. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Models | Explanation Strategy |
|---|---|---|
| Eigenfaces [41] | PCA | Model parameter investigation |
| LRP [21,25,26], SpRAy [27,46] | Deep CNNs | Post hoc CNN prediction analysis |
| Visualization for B-GP-LVM [29] | GP-LVM | Model investigation |
| Our contribution | GP-LVM and deep cAE | Model investigation & feature selection |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wöber, W.; Mehnen, L.; Sykacek, P.; Meimberg, H. Investigating Explanatory Factors of Machine Learning Models for Plant Classification. Plants 2021, 10, 2674. https://doi.org/10.3390/plants10122674
Wöber W, Mehnen L, Sykacek P, Meimberg H. Investigating Explanatory Factors of Machine Learning Models for Plant Classification. Plants. 2021; 10(12):2674. https://doi.org/10.3390/plants10122674
Chicago/Turabian StyleWöber, Wilfried, Lars Mehnen, Peter Sykacek, and Harald Meimberg. 2021. "Investigating Explanatory Factors of Machine Learning Models for Plant Classification" Plants 10, no. 12: 2674. https://doi.org/10.3390/plants10122674