

ConvTEBiLSTM: A Neural Network Fusing Local and Global Trajectory Features for Field-Road Mode Classification

Abstract
:1. Introduction
2. Dataset
2.1. Dataset Description
2.2. Data Cleaning
- Removing duplicate points: The duplicate points mainly include temporal duplicate points and spatial duplicate points. When consecutive GNSS trajectory points have the same coordinates or the same timestamp, the first GNSS point is saved, and other GNSS points are removed.
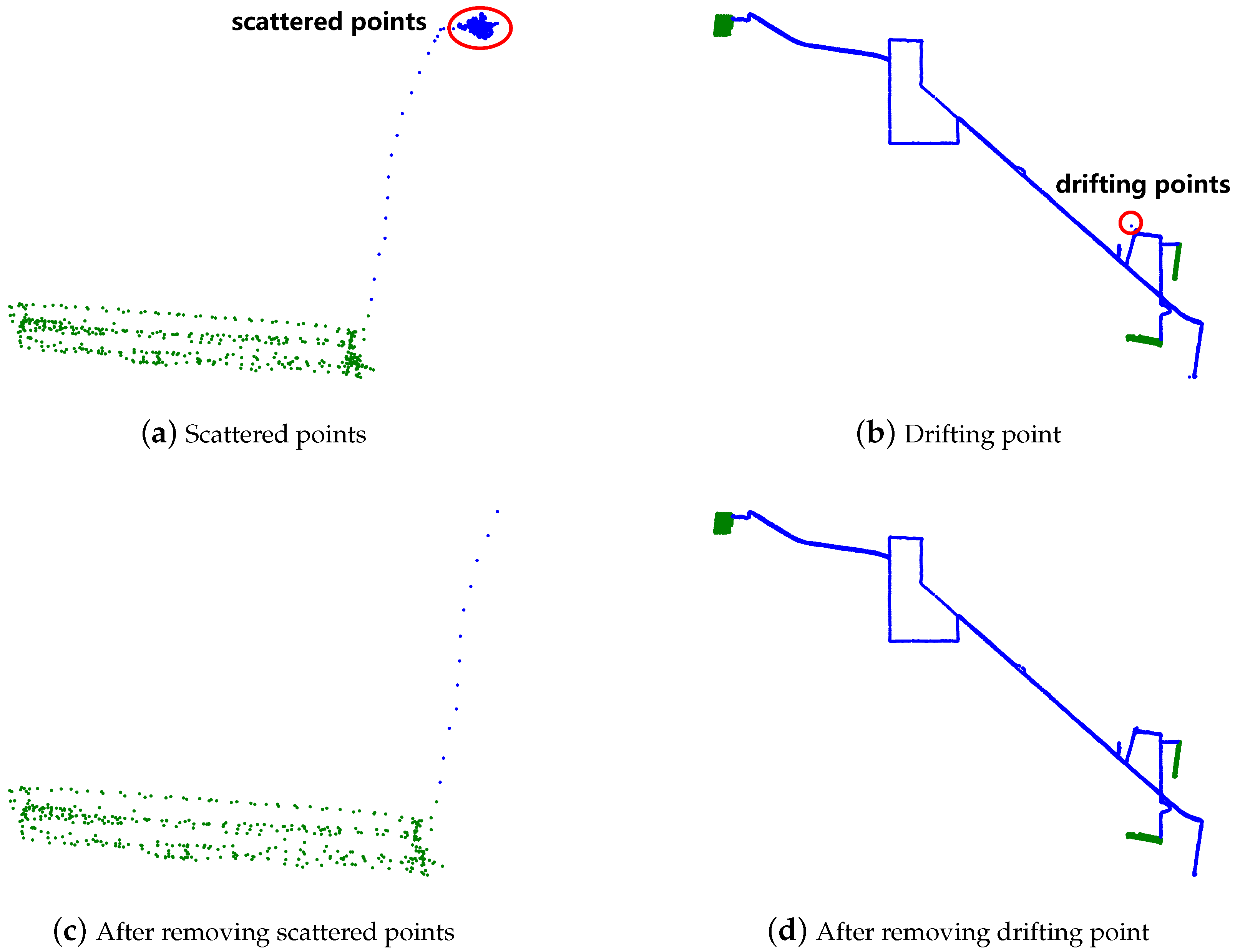
- Removing scattered points: When agricultural machinery is parked on the road or entering/exiting a garage, the GNSS receiver records many scattered road points with high density. These points are scattered within a small range around the actual position of agricultural machinery and need to be removed. Therefore, a rule-based cleaning method is proposed to effectively remove the scattered points and is formulated as follows:
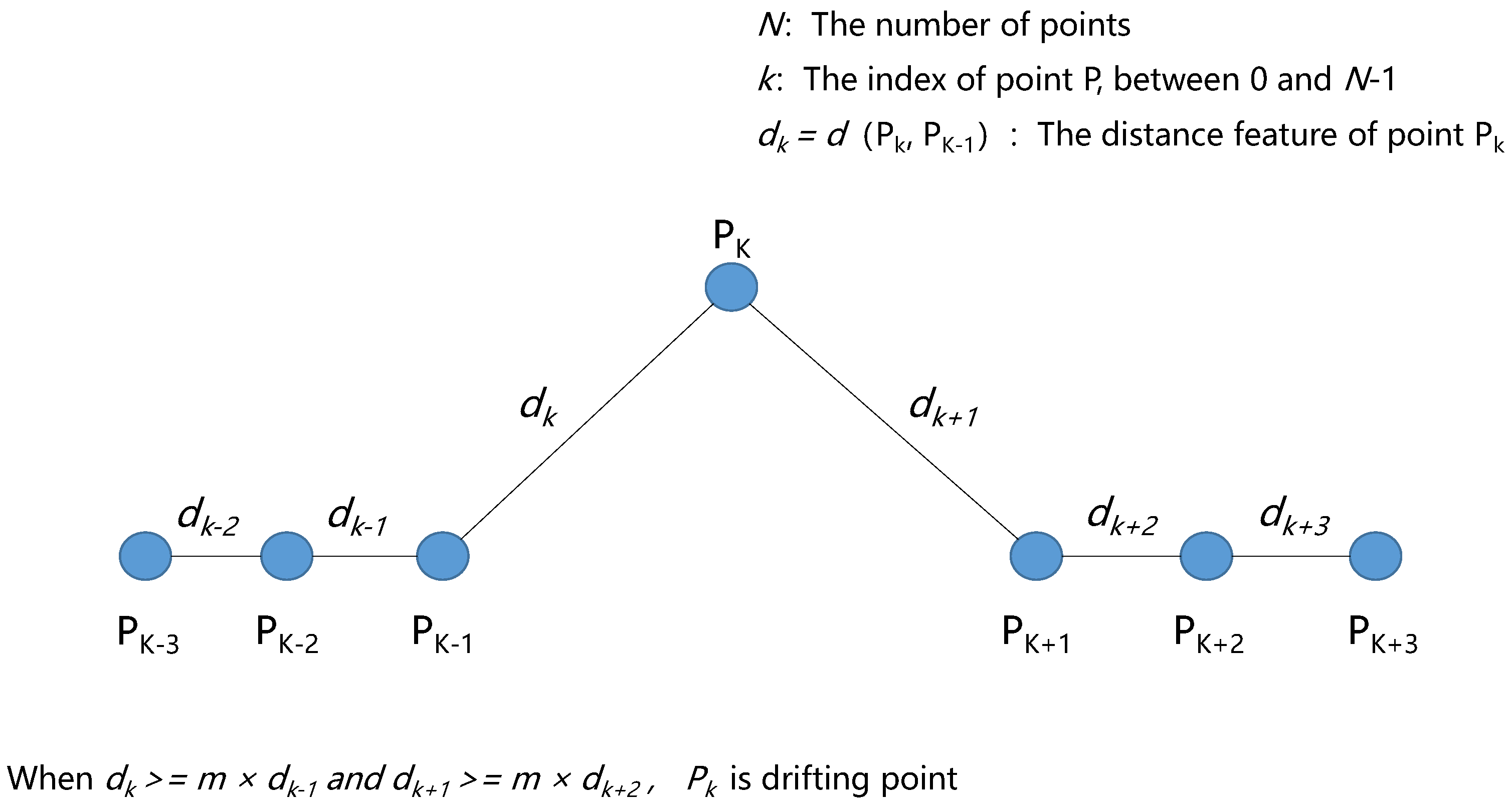
- Removing drifting points: When the distance features from a GNSS point to both its previous point and its next point are very large, the point is taken as a drifting point (see Figure 1). In this case, the drifting point is removed, its previous point becomes the ending point of the preceding trajectory segment, and its next point becomes the starting point of the subsequent trajectory segment.
3. Methodology
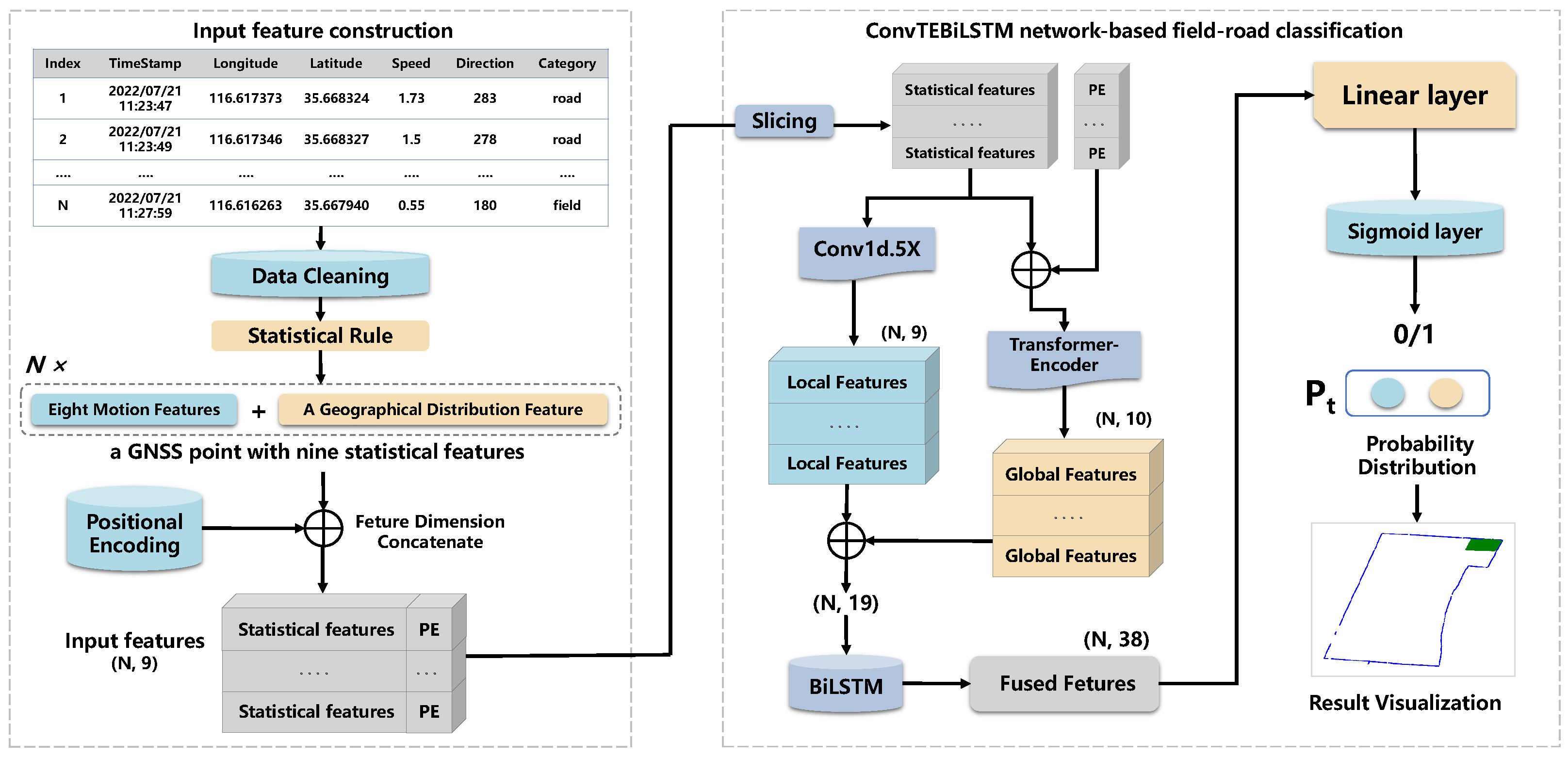
3.1. Input Feature Construction
3.1.1. Statistical Feature Extraction
| Algorithm 1 Calculate Geographical Distribution Features |
|
3.1.2. Positional Encoding
3.2. ConvTEBiLSTM Network-Based Field-Road Classification
3.2.1. Conv1d.5x for Extracting Local Trajectory Features
3.2.2. Transformer-Encoder for Extracting Global Trajectory Features
3.2.3. BiLSTM for Fusing Local and Global Trajectory Features
3.2.4. Linear Classifier for Field-Road Mode Identification
4. Experiments
4.1. Experimental Settings
4.1.1. Comparison Methods
4.1.2. Model Training Process
4.1.3. Performance Metrics
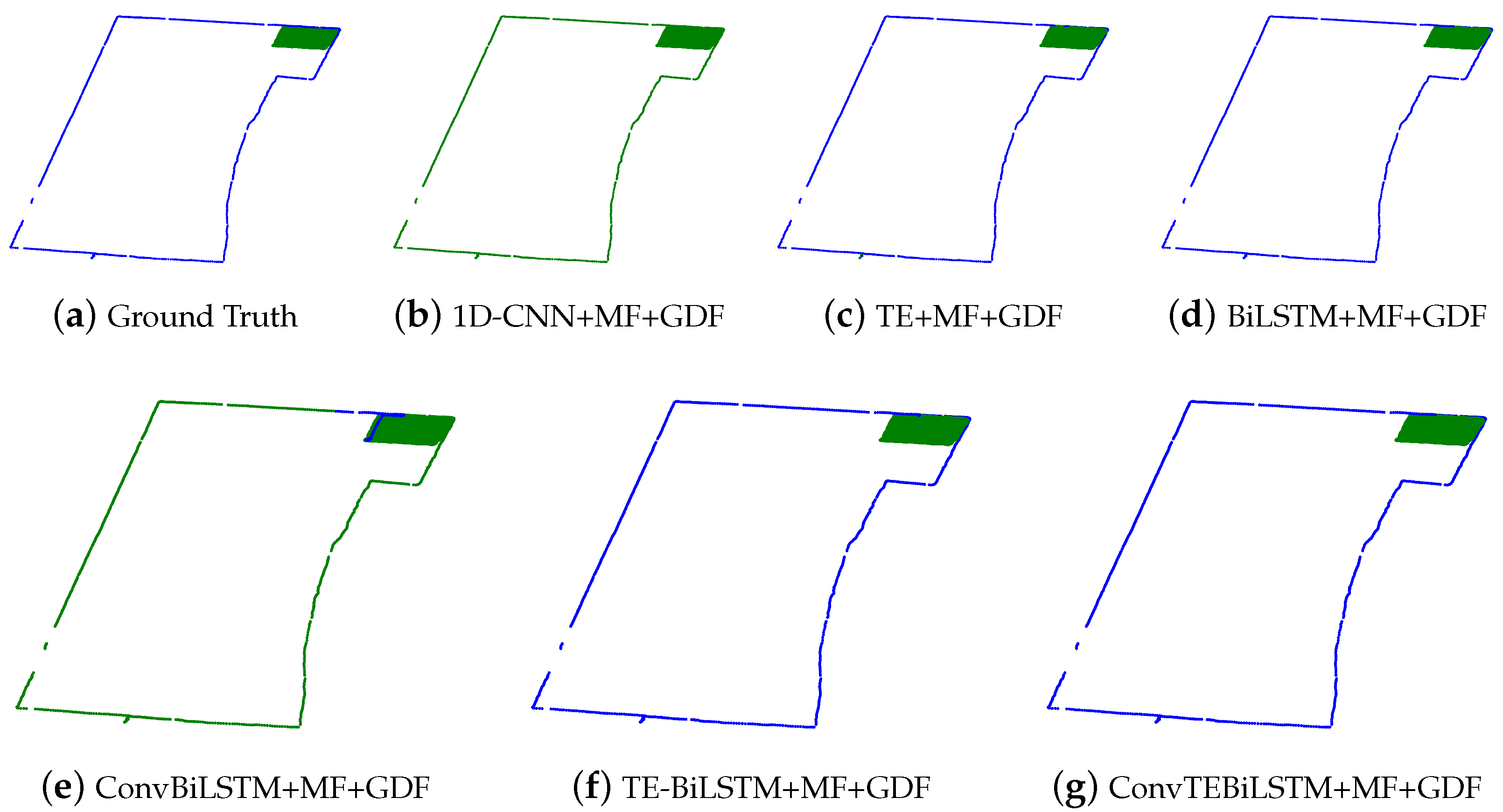
4.1.4. Model Testing
4.2. Results and Discussion
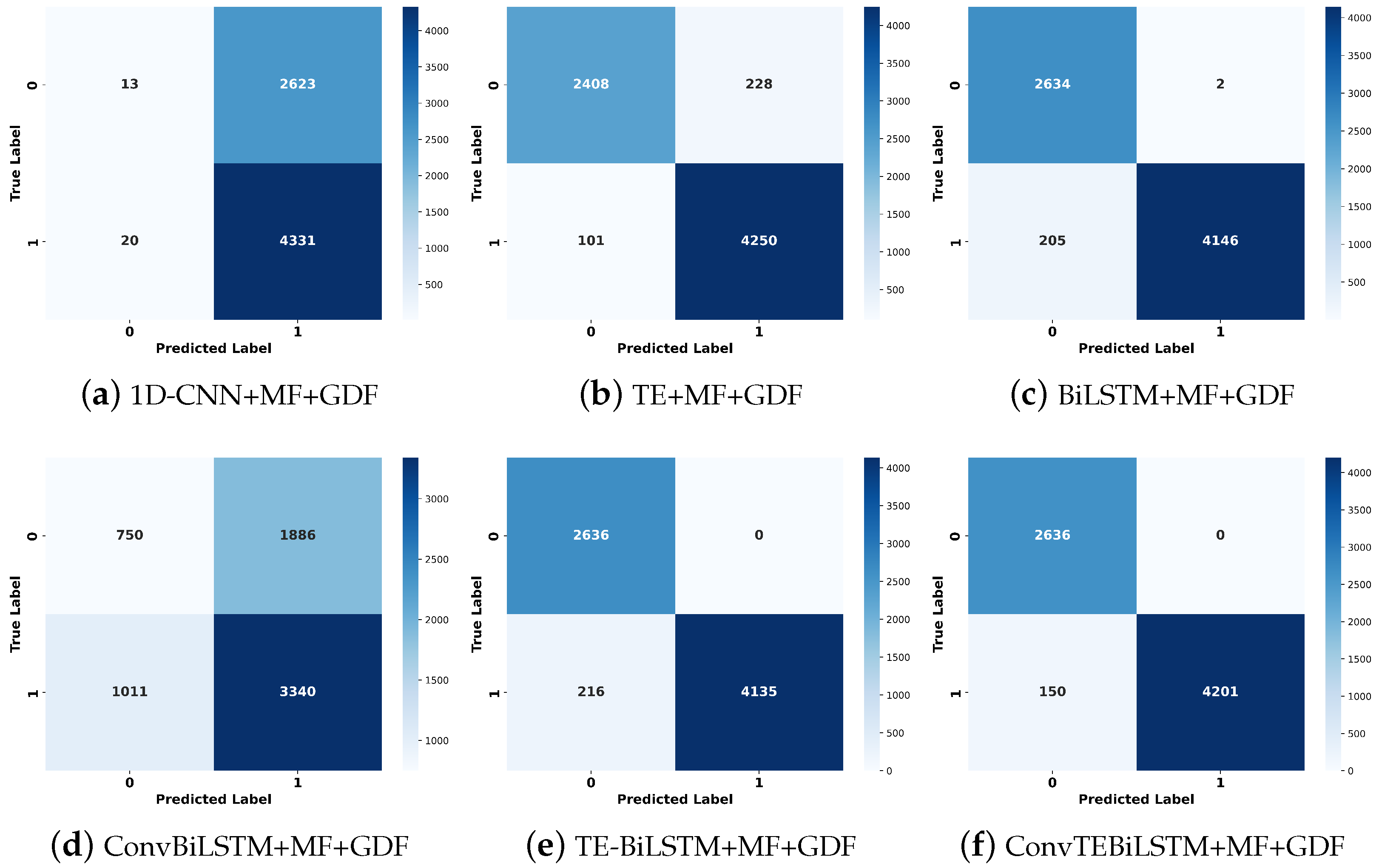
4.2.1. Method Comparisons and Analysis
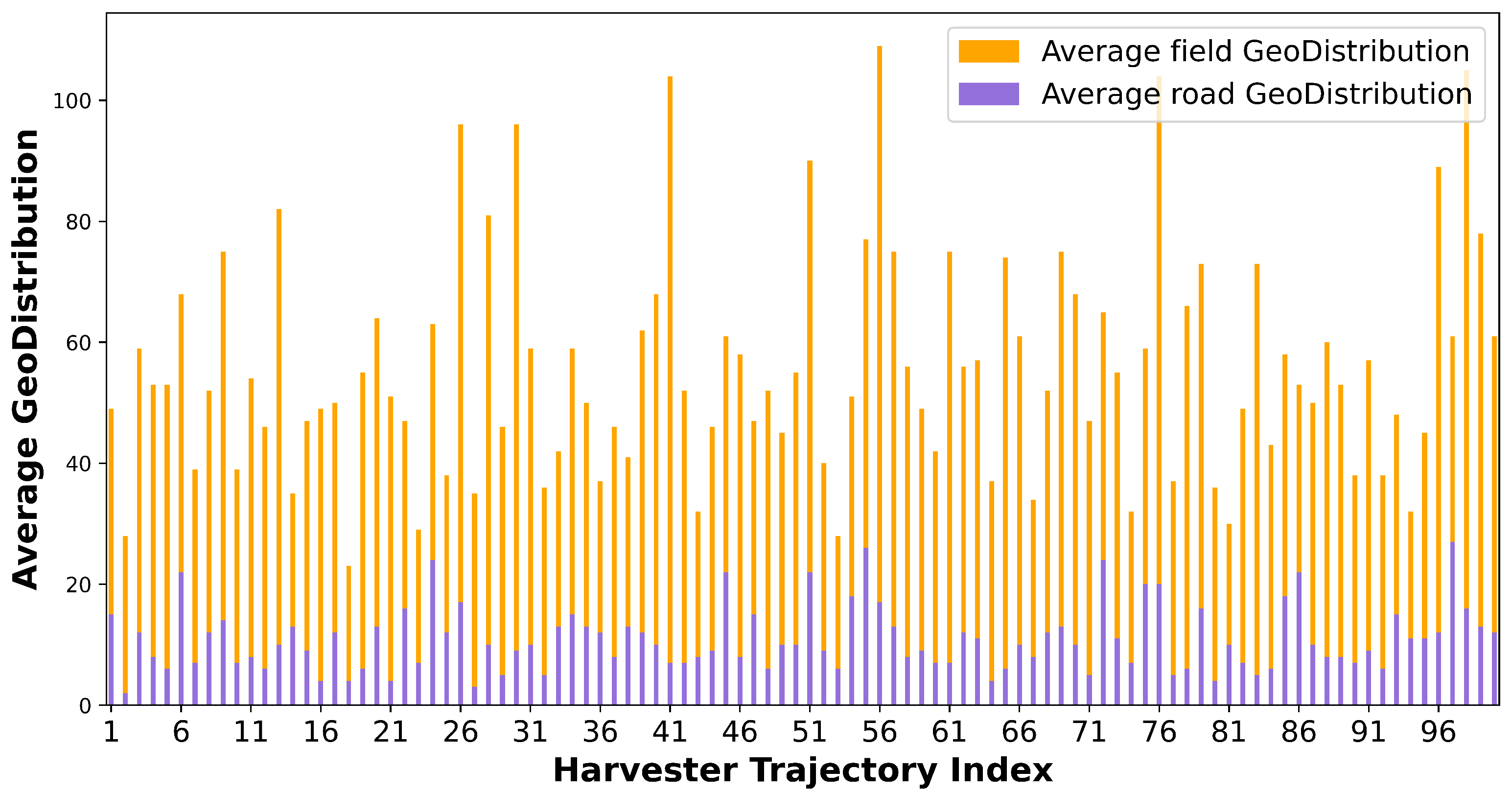
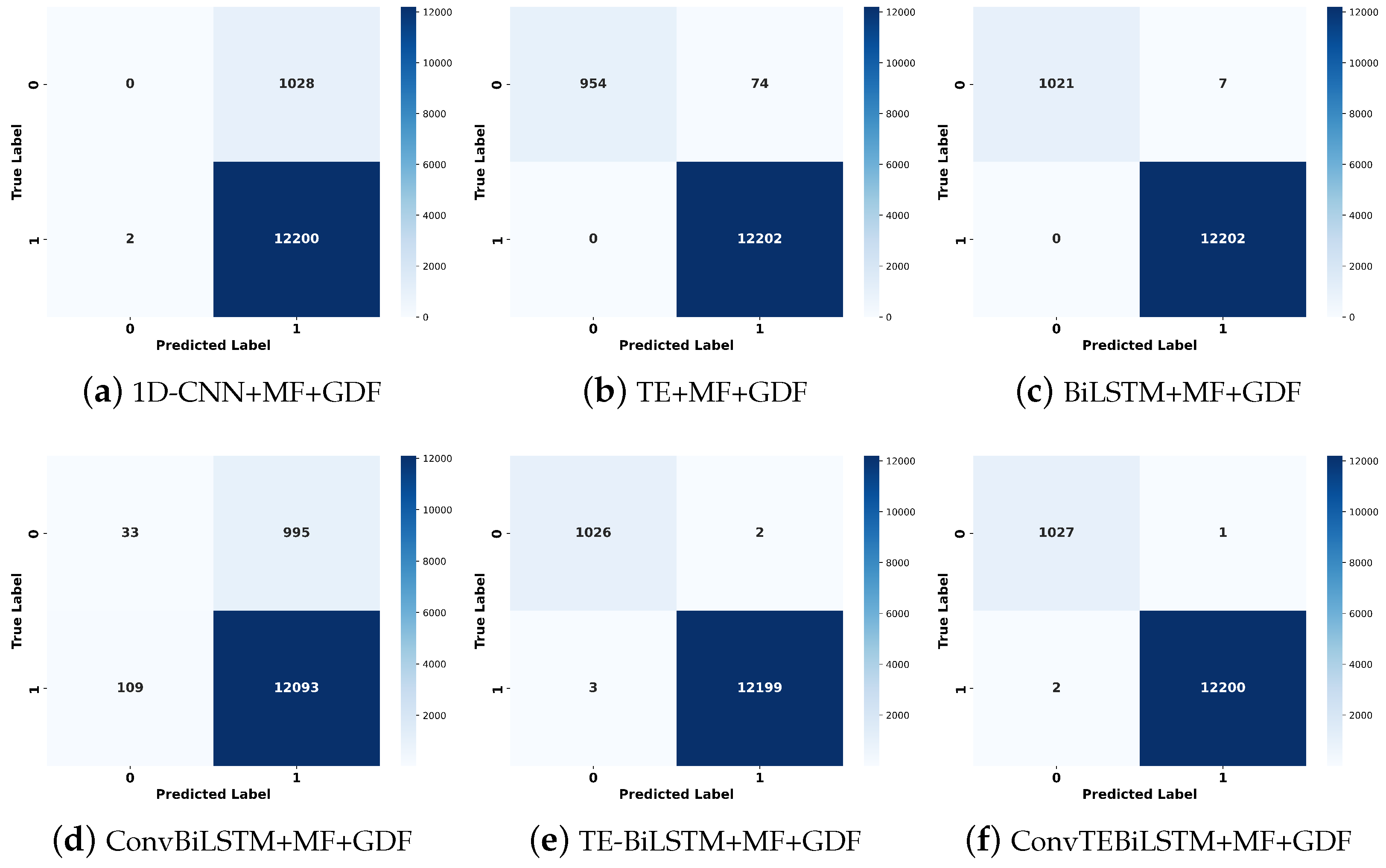
4.2.2. Effective of Geographical Distribution Feature
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Keller, T.; Lamandé, M.; Peth, S.; Berli, M.; Delenne, J.Y.; Baumgarten, W.; Rabbel, W.; Radjai, F.; Rajchenbach, J.; Selvadurai, A.; et al. An interdisciplinary approach towards improved understanding of soil deformation during compaction. Soil Tillage Res. 2013, 128, 61–80. [Google Scholar] [CrossRef]
- Damanauskas, V.; Janulevicius, A.; Pupinis, G. Influence of extra weight and tire pressure on fuel consumption at normal tractor slippage. J. Agric. Sci. 2015, 7, 55–67. [Google Scholar] [CrossRef]
- Zhang, F.Z.; Liu, R.H.; Ni, Y.D.; Wang, Y. Dynamic positioning accuracy test and analysis of Beidou satellite navigation system. GNSS World China 2018, 3, 43–48. [Google Scholar]
- Li, D.; Liu, X.; Zhou, K.; Sun, R.; Wang, C.; Zhai, W.; Wu, C. Discovering spatiotemporal characteristics of the trans-regional harvesting operation using big data of GNSS trajectories in China. Comput. Electron. Agric. 2023, 211, 108003. [Google Scholar] [CrossRef]
- Zhai, W.; Mo, G.; Xiao, Y.; Xiong, X.; Wu, C.; Zhang, X.; Xu, Z.; Pan, J. GAN-BiLSTM network for field-road classification on imbalanced GNSS recordings. Comput. Electron. Agric. 2024, 216, 108457. [Google Scholar] [CrossRef]
- Bochtis, D.D.; Sørensen, C.G.; Busato, P. Advances in agricultural machinery management: A review. Biosyst. Eng. 2014, 126, 69–81. [Google Scholar] [CrossRef]
- Sopegno, A.; Calvo, A.; Berruto, R.; Busato, P.; Bocthis, D. A web mobile application for agricultural machinery cost analysis. Comput. Electron. Agric. 2016, 130, 158–168. [Google Scholar] [CrossRef]
- Molari, G.; Mattetti, M.; Lenzini, N.; Fiorati, S. An updated methodology to analyse the idling of agricultural tractors. Biosyst. Eng. 2019, 187, 160–170. [Google Scholar] [CrossRef]
- Pagare, V.; Nandi, S.; Khare, D. Appraisal of Optimum Economic Life for Farm Tractor: A Case Study. Econ. Aff. 2019, 64, 117–124. [Google Scholar] [CrossRef]
- Li, X.; Hao, F. Research on Agricultural Machinery Behavior Recognition and Application System Based on Satellite Remote Sensing Image. Master’s Thesis, Qilu University of Technology, Jinan, China, 2023. [Google Scholar]
- Wu, C.; Li, D.; Zhang, X.; Pan, J.; Quan, L.; Yang, L.; Yang, W.; Ma, Q.; Su, C.; Zhai, W. Application note: China’s agricultural machinery operation big data system. Comput. Electron. Agric. 2023, 205, 107594. [Google Scholar] [CrossRef]
- Song, X.P.; Potapov, P.V.; Krylov, A.; King, L.; Di Bella, C.M.; Hudson, A.; Khan, A.; Adusei, B.; Stehman, S.V.; Hansen, M.C. National-scale soybean mapping and area estimation in the United States using medium resolution satellite imagery and field survey. Remote Sens. Environ. 2017, 190, 383–395. [Google Scholar] [CrossRef]
- Song, X.; Wu, F.; Lu, X.; Yang, T.; Ju, C.; Sun, C.; Liu, T. The classification of farming progress in rice–wheat rotation fields based on UAV RGB images and the regional mean model. Agriculture 2022, 12, 124. [Google Scholar] [CrossRef]
- Bereżnicka, J.; Wicki, L. Do operating subsidies increase labour productivity in Polish farms? Stud. Agric. Econ. 2021, 123. [Google Scholar]
- Xiao, Y.; Mo, G.; Xiong, X.; Pan, J.; Wu, C.; Zhai, W. DR-XGBoost: An XGBoost model for field-road segmentation based on dual feature extraction and recursive feature elimination. Int. J. Agric. Biol. Eng. 2023, 16, 169–179. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, X.; Wu, C.; Li, G. Field-road trajectory segmentation for agricultural machinery based on direction distribution. Comput. Electron. Agric. 2021, 186, 106180. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the KDD’96: Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland OR, USA, 2–4 August 1996; Volume 96, pp. 226–231. [Google Scholar]
- Poteko, J.; Eder, D.; Noack, P.O. Identifying operation modes of agricultural vehicles based on GNSS measurements. Comput. Electron. Agric. 2021, 185, 106105. [Google Scholar] [CrossRef]
- Chen, Y.; Li, G.; Zhang, X.; Jia, J.; Zhou, K.; Wu, C. Identifying field and road modes of agricultural Machinery based on GNSS Recordings: A graph convolutional neural network approach. Comput. Electron. Agric. 2022, 198, 107082. [Google Scholar] [CrossRef]
- Zitnik, M.; Agrawal, M.; Leskovec, J. Modeling polypharmacy side effects with graph convolutional networks. Bioinformatics 2018, 34, i457–i466. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Quan, L.; Zhang, X.; Zhou, K.; Wu, C. Field-road classification for GNSS recordings of agricultural machinery using pixel-level visual features. Comput. Electron. Agric. 2023, 210, 107937. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 202; Springer: Cham, Switzerland, 2022; pp. 205–218. [Google Scholar]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef] [PubMed]
- Luo, Y.; Xiao, F.; Zhao, H. Hierarchical contextualized representation for named entity recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8441–8448. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Yan, H.; Ma, X.; Pu, Z. Learning dynamic and hierarchical traffic spatiotemporal features with transformer. IEEE Trans. Intell. Transp. Syst. 2021, 23, 22386–22399. [Google Scholar] [CrossRef]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.P.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst 1912, 32, 8026. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Loshchilov, I.; Hutter, F. Fixing weight decay regularization in adam. In Proceedings of the ICLR 2018, The Sixth International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Leonard, L.C. Web-based behavioral modeling for continuous user authentication (CUA). Adv. Comput. 2017, 105, 1–44. [Google Scholar]
- Rodriguez, J.D.; Perez, A.; Lozano, J.A. Sensitivity analysis of k-fold cross validation in prediction error estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 569–575. [Google Scholar] [CrossRef]
- Stone, M. Cross-validation: A review. Stat. A J. Theor. Appl. Stat. 1978, 9, 127–139. [Google Scholar]
- Westerhuis, J.A.; Hoefsloot, H.C.; Smit, S.; Vis, D.J.; Smilde, A.K.; van Velzen, E.J.; van Duijnhoven, J.P.; van Dorsten, F.A. Assessment of PLSDA cross validation. Metabolomics 2008, 4, 81–89. [Google Scholar] [CrossRef]
- Neunhoeffer, M.; Sternberg, S. How cross-validation can go wrong and what to do about it. Polit. Anal. 2019, 27, 101–106. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Harvester |
|---|---|
| No. of GNSS trajectories | 100 |
| No. of total GNSS points | 1,152,867 |
| No. of field points | 873,424 |
| No. of road points | 279,443 |
| The ratio of “field” to “road” | 0.7576:0.2424 |
| Acquisition intervals | 2 s |
| Method | P | R | F1 | Acc | Model Size/kb | Inference Time/s |
|---|---|---|---|---|---|---|
| 1D-CNN+MF+GDF | 45.11 | 49.97 | 45.88 | 85.09 | 20.6 | 0.828824 |
| TE+MF+GDF | 91.07 | 82.55 | 85.34 | 94.29 | 112 | 0.798763 |
| ConvBiLSTM+MF+GDF | 46.91 | 50.33 | 47.80 | 84.13 | 20.7 | 0.925290 |
| TE-BiLSTM+MF+GDF | 94.01 | 91.52 | 91.79 | 96.59 | 132 | 0.968573 |
| BiLSTM+MF+GDF | 93.38 | 91.17 | 91.14 | 96.32 | 17.7 | 0.981394 |
| ConvTEBiLSTM+MF+GDF | 95.60 | 91.60 | 92.74 | 97.38 | 179 | 0.998893 |
| Method | P | R | F1 | Acc |
|---|---|---|---|---|
| BiLSTM+MF | 83.45 | 72.35 | 72.74 | 88.60 |
| BiLSTM+MF+GDF | 93.38 | 91.17 | 91.14 | 96.32 |
| ConvTEBiLSTM+MF | 51.79 | 52.23 | 49.40 | 84.41 |
| ConvTEBiLSTM+MF+GDF | 95.60 | 91.60 | 92.74 | 97.38 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bian, C.; Bai, J.; Cheng, G.; Hao, F.; Zhao, X. ConvTEBiLSTM: A Neural Network Fusing Local and Global Trajectory Features for Field-Road Mode Classification. ISPRS Int. J. Geo-Inf. 2024, 13, 90. https://doi.org/10.3390/ijgi13030090
Bian C, Bai J, Cheng G, Hao F, Zhao X. ConvTEBiLSTM: A Neural Network Fusing Local and Global Trajectory Features for Field-Road Mode Classification. ISPRS International Journal of Geo-Information. 2024; 13(3):90. https://doi.org/10.3390/ijgi13030090
Chicago/Turabian StyleBian, Cunxiang, Jinqiang Bai, Guanghe Cheng, Fengqi Hao, and Xiyuan Zhao. 2024. "ConvTEBiLSTM: A Neural Network Fusing Local and Global Trajectory Features for Field-Road Mode Classification" ISPRS International Journal of Geo-Information 13, no. 3: 90. https://doi.org/10.3390/ijgi13030090