
A Comparison of Cartographic and Toponymic Databases in a Multilingual Environment: A Methodology for Detecting Redundancies Using ETL and GIS Tools

Abstract
:1. Introduction
2. Related Work
2.1. On Place Names, Cartography, and GIS
2.2. On Gazetteer Synchronization
2.3. On Cadastral Information and Cadastral Place Names
2.4. On Multilingualism
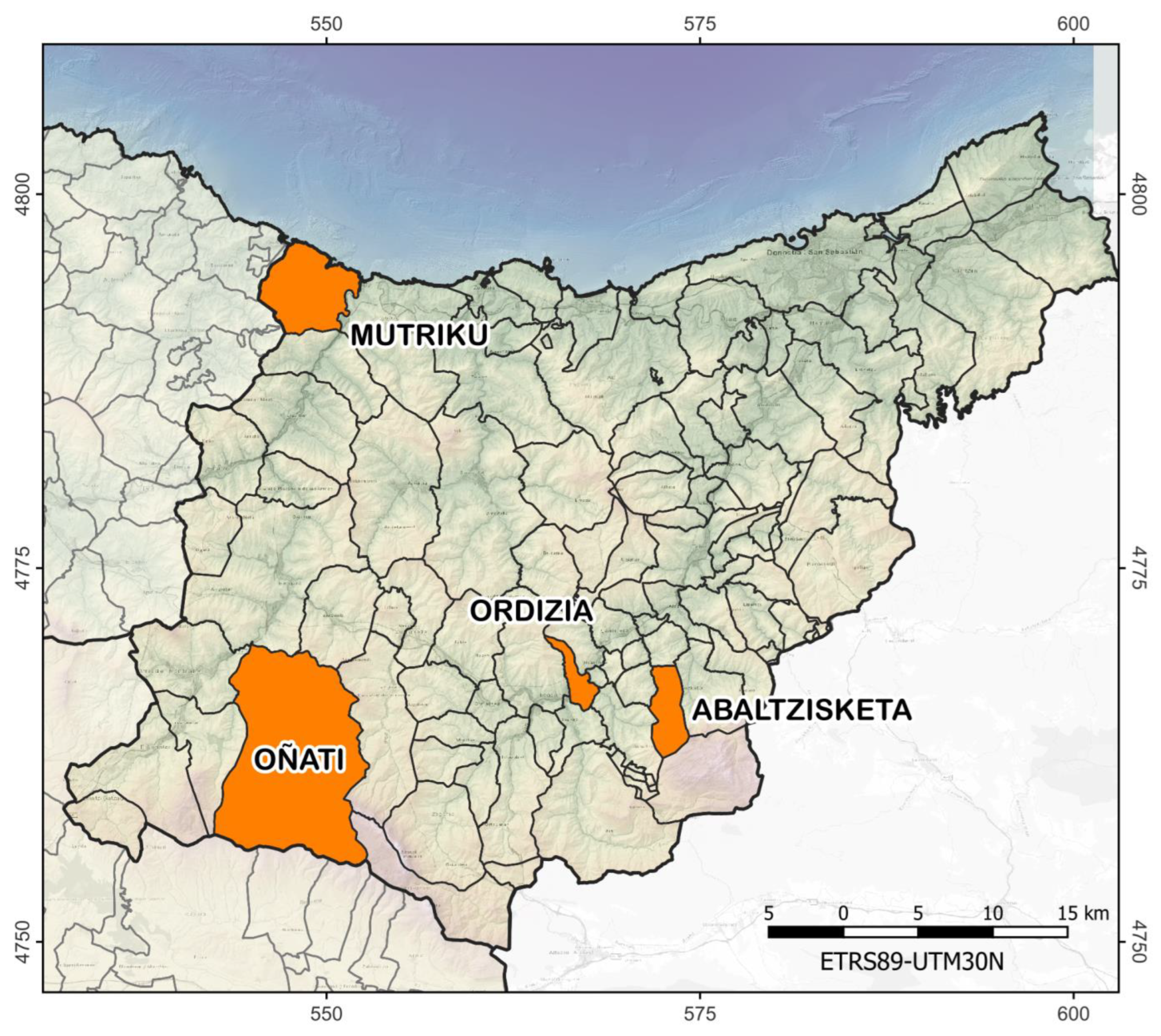
3. Study Area
4. Materials and Methods
4.1. Toponymic Geodata
4.1.1. Provincial Council. (Gipuzkoa)
4.1.2. Autonomous Community (Basque Country)
4.1.3. National Level (Spain)
4.2. Software Utilized
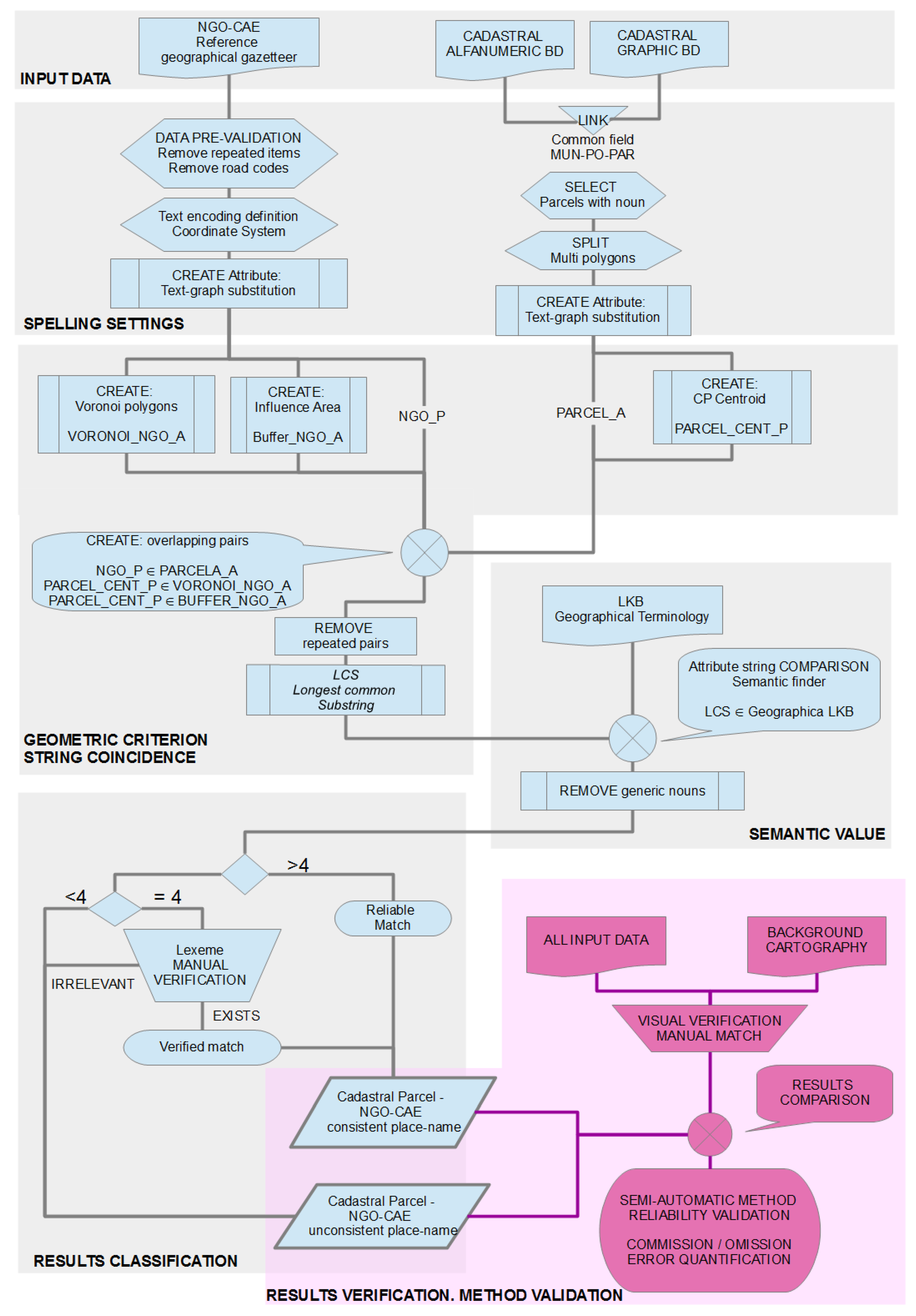
4.3. Processing Overview
4.3.1. Input Data
4.3.2. Spelling Settings
4.3.3. Comparison Premises
Geometric Criterion
String Coincidence
Semantic Value
4.3.4. Result Classifications
4.4. Results Verification (Method Validation)
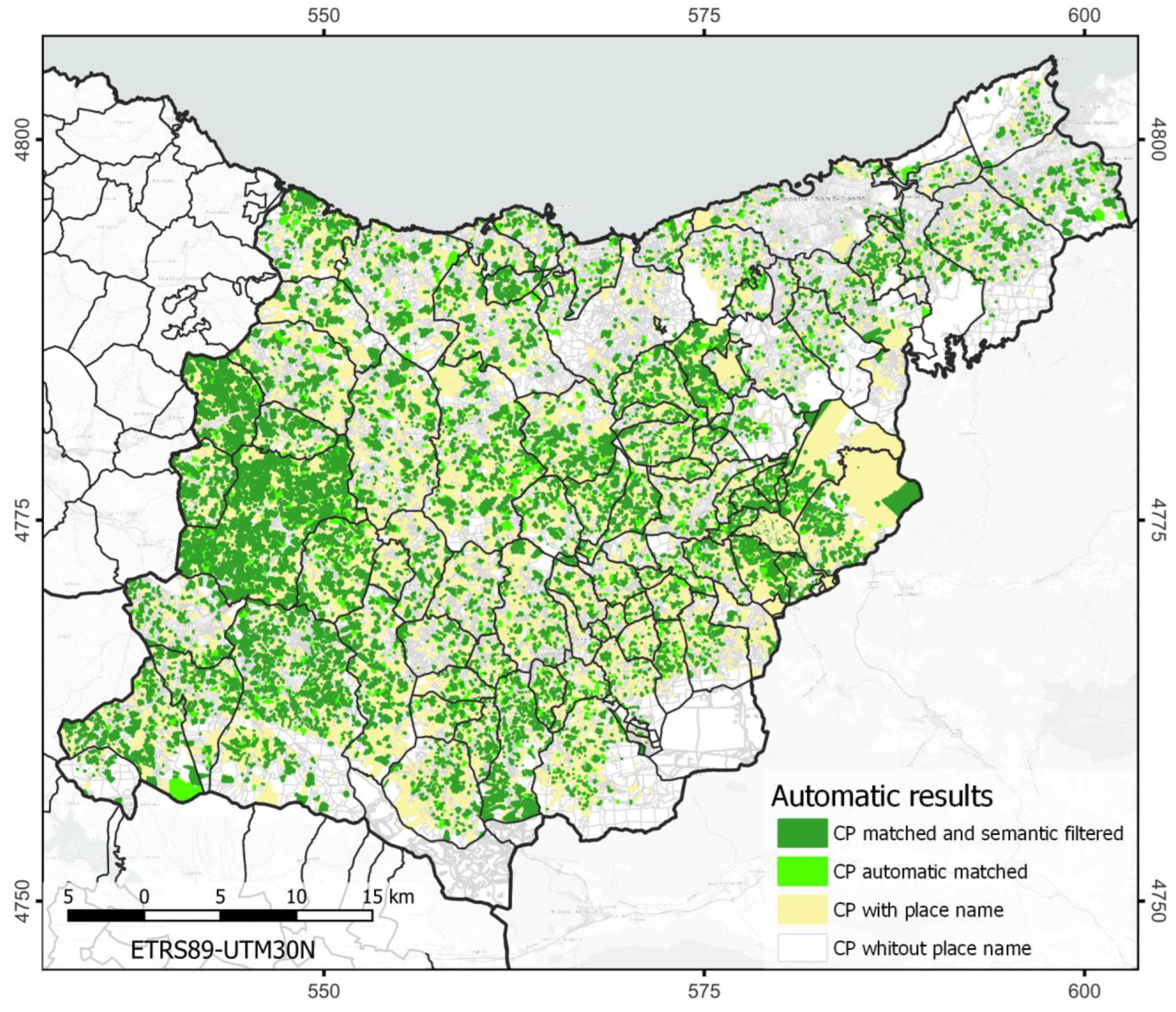
5. Results
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
References
- Quesada-García, S. A cartography of al-Andalus’ landscape: Mapping settlements of Muslim agricultural colonization in Europe applying GIS techniques. J. Hist. Geogr. 2022, 77, 65–84. [Google Scholar] [CrossRef]
- Rosselló i Verger, V.M. Cartography, landscape and territory. Catalan Soc. Sci. Rev. 2012, 1, 46–57. [Google Scholar] [CrossRef]
- Zamorshchikova, L.; Gadal, S.; Filippova, V.; Samsonova, M. Landscape Toponymic Maps: Interdisciplinary Approach (Example of Sakha Republic, Russia). In Proceedings of the International Multidisciplinary Scientific Conference SGEM2016, Albena, Bulgaria, 30 June–6 July 2016; pp. 311–316. [Google Scholar]
- Arroyo Illera, F. Toponymy as a intangible cultural legacy. Boletín Real Soc. Geogr. 2019, 153, 33–60. [Google Scholar]
- Mollo, N.M. Determinación geográfica de los sitios de interés histórico y arqueológico mediante la utilización de técnicas cartográficas. Teor. Práct. Arqueol. Hist. Latinoam. 2022, 3, 21–48. [Google Scholar] [CrossRef]
- Ingelmo Casado, R. Localización y tratamiento de información histórica a través de la toponimia menor: Utilidad del catastro de la riqueza rústica (Localization and treatment of historical information through the minor toponymy: Utility of the cadastre of rustic wealth). In Tecnologías de la Información Geográfica: La Información Geográfica al Servicio de los Ciudadanos (Geographic Information Technologies: Geographic Information at the Service of Citizens); Ojeda, J., Piya, M.F., Vallejo, I., Eds.; Secretariado de Publicaciones de la Universidad de Sevilla: Sevilla, Spain, 2010; pp. 199–213. ISBN 978-84-472-1294-1. [Google Scholar]
- Mácha, P.; Obrusník, U.; Jordan, P.; Sancho Reinoso, A. The Challenges of Studying Place-Name Politics in Multilingual Areas. In Place-Name Politics in Multilingual Areas; Springer International Publishing: Cham, Switzerland, 2021; pp. 45–69. [Google Scholar]
- González García, E.M. El catastro: Fuente de información del territorio (The cadastre: Source of territorial information). In Proceedings of the X Coloquio de Historia Canario—Americano. Coloquio 10. Tomo 2; Cabildo Insular de Gran Canaria, Ed.; ULPGC: Las Palmas de Gran Canaria, Spain, 1992; pp. 160–175. [Google Scholar]
- European Parliament and Council of the European Union. Directive 2007/2/EC of the European Parliament and of the Council of 14 March 2007 Establishing an Infraestructure for Spatial Information in the European Community (INSPIRE), L108; Official Journal of the European Union: Brussels, Belgium, 2007. [Google Scholar]
- Gobierno de España. Ley 14/2010, de 5 de Julio, sobre las Infraestructuras y los Servicios de Información Geográfica en España (LISIGE) (Law 14/2010, of July 5, 2010, on Geographic Information Infrastructures and Services in Spain); Government of Spain: Madrid, Spain, 2010. [Google Scholar]
- Liu, Z.; Cheng, L. Review of GIS Technology and Its Applications in Different Areas. IOP Conf. Ser. Mater. Sci. Eng. 2020, 735, 012066. [Google Scholar] [CrossRef]
- Mesquitela, J.; Elvas, L.B.; Ferreira, J.C.; Nunes, L. Data Analytics Process over Road Accidents Data—A Case Study of Lisbon City. ISPRS Int. J. Geo-Inf. 2022, 11, 143. [Google Scholar] [CrossRef]
- Páez, O.; Vilches-Blázquez, L.M. Bringing Federated Semantic Queries to the GIS-Based Scenario. ISPRS Int. J. Geo-Inf. 2022, 11, 86. [Google Scholar] [CrossRef]
- Drešček, U.; Kosmatin Fras, M.; Tekavec, J.; Lisec, A. Spatial ETL for 3D Building Modelling Based on Unmanned Aerial Vehicle Data in Semi-Urban Areas. Remote Sens. 2020, 12, 1972. [Google Scholar] [CrossRef]
- García-Balboa, J.; Ureña-Cámara, M.; Ariza-López, F.; Garrido-Borrego, M.T.; Torrecillas-Lozano, C. Análisis comparativo entre la base de datos de toponimia 1:10,000 (BTA10) y la toponimia contenida en la base de datos catastral (Comparative analysis between the toponymy database 1:10,000 (BTA10) and the toponymy contained in the cadastral database). In Proceedings of the I Congreso Internacional sobre Catastro Unificado Multipropósito (CICUM), Jaén, Spain, 16–18 June 2010; Alcázar-Molina, M.G., Ariza-López, F.J., García-Balboa, J.L., Mata-de-Castro, E., Ruiz-Capiscol, S., Ureña-Cámara, M.A., Eds.; Universidad de Jaén: Jaén, Spain, 2010; pp. 271–277. [Google Scholar]
- Garrido, M.; Torrecillas, C. Gestión toponímica vinculada a la cartografía en Andalucía (España) (Toponymic management linked to cartography in Andalusia (Spain)). Rev. Bras. Geogr. 2022, 67, 120. [Google Scholar]
- Vázquez Hoehne, A.; Rodríguez de Castro, A.; Luján Díaz, A.; Montilla Lillo, M.; Castaño Suárez, A. Propuesta metodológica para la elaboración del Nomenclator Geográfico Básico de España a apartir de la autocorrección de la Base Cartográfica Numérica con la información de las comunidades autómomas (Methodological proposal for the elaboration of the Basic Geographic Nomenclator of Spain from the autocorrection of the Numerical Cartographic Base with the information of the autonomous communities). In Proceedings of the Els noms en la vida quotidiana. Actes del XXIV Congrés Internacional d’ICOS sobre Ciències Onomàstiques. Annex. Secció 11; Onomástica; Biblioteca Técnica de Política Lingüística: Barcelona, Spain, 2011. [Google Scholar]
- Köhnlein, B. The morphological structure of complex place names: The case of Dutch. J. Comp. Ger. Linguist. 2015, 18, 183–212. [Google Scholar] [CrossRef] [Green Version]
- Rodríguez Pérez, C.; Castañón Álvarez, J.C. Modos de representación cartográfica de las unidades de paisaje: Revisión y propuestas (Modes of cartographic representation of landscape units: Review and proposals). Ería 2016, 99, 15–40. [Google Scholar] [CrossRef] [Green Version]
- Garrido Villén, N. Propuesta de Normalización Cartográfica para el Desarrollo Territorial. Ph.D. Thesis, Universitat Politècnica de València, Valencia, Spain, 2008. [Google Scholar]
- Mango, J.; Claramunt, C.; Ngondo, J.; Zhang, D.; Xu, D.; Colak, E.; Li, X. Multipurpose temporal GIS model for cadastral data management. Int. J. Geogr. Inf. Sci. 2022, 36, 1205–1230. [Google Scholar] [CrossRef]
- Frajer, J.; Fiedor, D. Discovering extinct water bodies in the landscape of Central Europe using toponymic GIS. Morav. Geogr. Rep. 2018, 26, 121–134. [Google Scholar] [CrossRef] [Green Version]
- Gordova, Y.; Herzen, O.; Herzen, A.; Kostovska, S. Usage of cartographic methods in place-name study (history of the problem and actual research). InterCarto. InterGIS 2021, 27, 520–536. [Google Scholar] [CrossRef]
- Rodríguez de Castro, A.; Vázquez Hoehne, A. Decoding of Place Names as Geographical Information Tools. Mitt. Osterr. Geogr. Ges. 2019, 158, 263–288. [Google Scholar] [CrossRef]
- Giraut, F.; Houssay-Holzschuch, M. Place Naming as Dispositif: Toward a Theoretical Framework. Geopolitics 2016, 21, 1–21. [Google Scholar] [CrossRef]
- Bijak, U. Space and Landscape in Polish Toponymy. J. Linguist. Cas. 2021, 72, 194–207. [Google Scholar] [CrossRef]
- Atik, M.; Kanabakan, A.; Ortaçeşme, V.; Yildirim, E. Tracing landscape characters through place names in rural Mediterranean. CATENA 2022, 210, 105912. [Google Scholar] [CrossRef]
- Felecan, O. Romanian Oikonyms and Hodonyms Mirroring the Great Union of 1918. Mitt. Osterr. Geogr. Ges. 2021, 1, 495–517. [Google Scholar] [CrossRef]
- Membrado-Tena, J.C. El papel de la Geografía en el análisis del contenido semántico de los topónimos. El caso de Alicante. An. Geogr. Univ. Complut. 2018, 38, 35–60. [Google Scholar] [CrossRef] [Green Version]
- Liao, Y.-P.; Lin, F.-T. Place Name Ambiguities in Urban Planning Domain Ontology. In Proceedings of the 7th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management, Lisbon, Portugal, 12–14 November 2015; SCITEPRESS—Science and and Technology Publications: Setúbal, Portugal, 2015; pp. 429–434. [Google Scholar]
- Membrado-Tena, J.C.; Fansa, G. Toponimia, paisaje y ciencia. El caso de los nombres de municipio de la Plana de Castelló (País Valenciano). Cuad. Geográficos 2020, 59, 28–52. [Google Scholar] [CrossRef]
- Maus, G. Landscapes of memory: A practice theory approach to geographies of memory. Geogr. Helv. 2015, 70, 215–223. [Google Scholar] [CrossRef] [Green Version]
- Mulrennan, M.E. Do Landscapes Listen? Wemindji Eeyou Knowledge, Adaptation and Agency in the Context of Coastal Landscape Change. In Landscapes and Landforms of Eastern Canada; Springer: Cham, Switzerland, 2020; pp. 543–556. [Google Scholar]
- De Felice, P.; La Greca, F.; Siniscalchi, S. The place names of the Aragonese maps. Interpretative hypotheses, landscape readings and methodological proposals. Int. J. Cartogr. 2022, 8, 3–17. [Google Scholar] [CrossRef]
- Bahgat, K.; Runfola, D. Toponym-assisted map georeferencing: Evaluating the use of toponyms for the digitization of map collections. PLoS ONE 2021, 16, e0260039. [Google Scholar] [CrossRef] [PubMed]
- Rowland, A.; Folmer, E.; Beek, W. Towards Self-Service GIS—Combining the Best of the Semantic Web and Web GIS. ISPRS Int. J. Geo-Inf. 2020, 9, 753. [Google Scholar] [CrossRef]
- Wang, L. Research on the design of large data storage structure of database based on Data Mining. In Proceedings of the 2021 3rd International Conference on Artificial Intelligence and Advanced Manufacture, Manchester, UK, 23–25 October 2021; ACM: New York, NY, USA, 2021; pp. 3001–3004. [Google Scholar]
- Nys, G.-A.; Dubois, C.; Goffin, C.; Hallot, P.; Kasprzyk, J.-P.; Treffer, M.; Billen, R. Geodata quality assessment and operationalisation of the INSPIRE directive: Feedback. Bull. Soc. Géogr. Liège 2022, 78, 179–188. [Google Scholar] [CrossRef]
- Conedera, M.; Vassere, S.; Neff, C.; Meurer, M.; Krebs, P. Using toponymy to reconstruct past land use: A case study of ‘brüsáda’ (burn) in southern Switzerland. J. Hist. Geogr. 2007, 33, 729–748. [Google Scholar] [CrossRef]
- Pijet-Migoń, E.; Migoń, P. Geoheritage and Cultural Heritage—A Review of Recurrent and Interlinked Themes. Geosciences 2022, 12, 98. [Google Scholar] [CrossRef]
- Blaschke, T.; Merschdorf, H.; Cabrera-Barona, P.; Gao, S.; Papadakis, E.; Kovacs-Györi, A. Place versus Space: From Points, Lines and Polygons in GIS to Place-Based Representations Reflecting Language and Culture. ISPRS Int. J. Geo-Inf. 2018, 7, 452. [Google Scholar] [CrossRef] [Green Version]
- Serikova, S.; Baishukurova, G. Digital technologies in the toponymy study. SHS Web Conf. 2022, 141, 04001. [Google Scholar] [CrossRef]
- Hernández, F.; Rosales, J.; Rodrigo, J. Búsquedas inteligentes de toponimia (Intelligent toponymy searches). In Proceedings of the V Jornadas Técnicas de la IDE de España, JIDEE 2008, Santa Cruz de Tenerife, Spain, 5–7 November 2008. [Google Scholar]
- Gordón-Peral, M. Toponimia de España. Estado Actual y Perspectivas de la Investigación (Toponymy of Spain. Current Status and Research Perspectives); Gordón-Peral, M.D., Ed.; Walter de Gruyter: Berlin, Germany, 2010; Volume 24, ISBN 978-3-11-023348-3. [Google Scholar]
- Grossner, K.; Grunewald, S.; Mostern, R. Bringing places from the distant past to the present: A report on the World Historical Gazetteer. Int. J. Digit. Libr. 2022, Volume, Page. [Google Scholar] [CrossRef]
- Garrido Borrego, M.T.; Torrecillas, C.; Benabad, I.G.; Cardenas, L.R.; Nicolás, C.T. Standardization of geospatial data of water sources and springs collected in the Andalusian Gazetteer (Spain). Rev. Cart. 2021, 103, 99–121. [Google Scholar] [CrossRef]
- Gelernter, J.; Ganesh, G.; Krishnakumar, H.; Zhang, W. Automatic gazetteer enrichment with user-geocoded data. In Proceedings of the Second ACM SIGSPATIAL International Workshop on Crowdsourced and Volunteered Geographic Information, Orlando, LA, USA, 5 November 2013; ACM: New York, NY, USA, 2013; pp. 87–94. [Google Scholar]
- Acheson, E.; Volpi, M.; Purves, R.S. Machine learning for cross-gazetteer matching of natural features. Int. J. Geogr. Inf. Sci. 2020, 34, 708–734. [Google Scholar] [CrossRef]
- Hearn, K.P. Mapping the past: Using ethnography and local spatial knowledge to characterize the Duero River borderlands landscape. J. Rural Stud. 2021, 82, 37–53. [Google Scholar] [CrossRef]
- Hagemans, E.; Unger, E.-M.; Soffers, P.; Wortel, T.; Lemmen, C. The new, LADM inspired, data model of the Dutch cadastral map. Land Use Policy 2022, 117, 106074. [Google Scholar] [CrossRef]
- Das, S.N.; Sreenivasan, G.; Srinivasa Rao, S.; Joshi, A.K.; Varghese, A.O.; Prakasa Rao, D.S.; Chandrasekar, K.; Jha, C.S. Geospatial Technologies for Development of Cadastral Information System and its Applications for Developmental Planning and e-Governance. In Geospatial Technologies for Resources Planning and Management; Springer: Cham, Switzerland, 2022; pp. 485–538. [Google Scholar]
- Vilches-Blázquez, L.M.; Saavedra, J. A graph-based representation of knowledge for managing land administration data from distributed agencies—A case study of Colombia. Geo-Spat. Inf. Sci. 2022, 25, 259–277. [Google Scholar] [CrossRef]
- Atazadeh, B.; Olfat, H.; Rajabifard, A.; Kalantari, M.; Shojaei, D.; Marjani, A.M. Linking Land Administration Domain Model and BIM environment for 3D digital cadastre in multi-storey buildings. Land Use Policy 2021, 104, 105367. [Google Scholar] [CrossRef]
- Gobierno de España. Ley 13/2015, de 24 de Junio, de Reforma de la Ley Hipotecaria (Law 13/2015, of June 24, 2015, on the Reform of the Mortgage Law); Government of Spain: Madrid, Spain, 2015. [Google Scholar]
- Velilla-Torres, J.M.; Mora-Navarro, G.; Femenia-Ribera, C.; Martínez-Llario, J.C. The georreferenced alternative graphic representation in the Cadastre-Land Registry coordination in Spain. Implementation study of the ISO-19152 (LADM) at the international level. In Proceedings of the 1st Congress in Geomatics Engineering—CIGeo, Valencia, Spain, 5–6 July 2017; Universitat Politècnica València: Valencia, Spain, 2017; pp. 69–76. [Google Scholar]
- Krigsholm, P.; Riekkinen, K.; Ståhle, P. The Changing Uses of Cadastral Information: A User-Driven Case Study. Land 2018, 7, 83. [Google Scholar] [CrossRef] [Green Version]
- Atazadeh, B.; Halalkhor Mirkalaei, L.; Olfat, H.; Rajabifard, A.; Shojaei, D. Integration of cadastral survey data into building information models. Geo-Spat. Inf. Sci. 2021, 24, 387–402. [Google Scholar] [CrossRef]
- Femenia-Ribera, C.; Mora-Navarro, G.; Pérez, L.J.S. Evaluating the use of old cadastral maps. Land Use Policy 2022, 114, 105984. [Google Scholar] [CrossRef]
- Duque, J.I.G. El Catastro de Rústica de Guipúzcoa/Gipuzkoa. Foresta 2012, 55, 180–185. [Google Scholar]
- Gordón-Peral, M. Las fuentes de documentación toponímica: El catastro del Marqués de la Ensenada y su interés lingüístico (The sources of toponymic documentation: The cadastre of the Marqués de la Ensenada and its linguistic interest). In Indagaciones Sobre la Lengua: Estudios de Filología y Lingüística Españolas en Memoria de Emilio Alarcos; University of Seville: Seville, Spain, 2001; pp. 437–454. ISBN 84-472-0682-3. [Google Scholar]
- Houssay-Holzschuch, M.; Giraut, F. Politics of Place Naming Naming the World; Wiley & Sons: Hoboken, NJ, USA, 2022. [Google Scholar]
- Sanz Elorza, M.; González Bernardo, F. Toponimia de origen vegetal en la provincia de Segovia a partir de los datos del Catastro de Rústica (Toponymy of vegetal origin in the province of Segovia based on the data of the Rural Cadastre). Lazaroa 2006, 27, 103–125. [Google Scholar]
- Ingelmo Casado, R. Georreferenciación de documentación histórica mediante la toponimia de los catastros (Georeferencing of historical documentation using the toponymy of land registry records). Int. Rev. Geogr. Inf. Sci. Technol. Geofocus 2012, 12, 243–267. [Google Scholar]
- Skorup, D. Models of utility cadastre in Bosnia and Herzegovina. AGG+ J. Archit. Civ. Eng. Geod. Other Relat. Sci. Fields 2020, 8, 77–88. [Google Scholar] [CrossRef]
- Sánchez Ondoño, I.; Cebrián Abellán, F.; Garcia-Gonzalez, J.A. The Cadastre as a Source for the Analysis of Urbanization Dynamics. Applications in Urban Areas of Medium-Sized Inland Spanish Cities. Land 2021, 10, 374. [Google Scholar] [CrossRef]
- Pearn, J. Surveyors, toponymy and heritage. Queensl. Hist. J. 2022, 25, 175–188. [Google Scholar]
- Cienciała, A.; Sobolewska-Mikulska, K.; Sobura, S. Credibility of the cadastral data on land use and the methodology for their verification and update. Land Use Policy 2021, 102, 105204. [Google Scholar] [CrossRef]
- Gobierno de Aragón (Spain). Nomenclátor Geográfico de Aragón; Government of Aragon: Zaragoza, Spain, 2019. [Google Scholar]
- Real Academia Galega. Xunta de Galicia (Spain) Toponimia de Galicia. Available online: https://toponimia.xunta.gal/es/toponimia (accessed on 4 February 2023).
- Fons, M.; Gomilla, X. Sobre la situación de la toponimia oficial en las Illes Balears: El Nomenclátor de Toponimia de Menorca y el futuro Nomenclátor Geográfico de las Illes Balears (On the situation of the official toponymy in the Balearic Islands: The Gazetteer of Toponymy of Menorca and the future Geographic Gazetteer of the Balearic Islands). Mapping 2019, 28, 48–56. [Google Scholar]
- Zubiaur-Carreño, F. Toponimia de San Martín de Unx según los amojonamientos de villa en el siglo XVI (Toponymy of San Martín de Unx according to the sixteenth-century town demarcations). Cuad. Etnol. Etnogr. Navar. 1978, 29, 255–272. [Google Scholar]
- Etxebarria, M. Principios y Fundamentos de Sociolingüística (Principles and Fundamentals of Sociolinguistics); UPV/EHU, Ed.; University of the Basque Country: Leioa, Spain, 2000; Volume 488. [Google Scholar]
- Benito del Valle Eskauriaza, A. Linguistic Trends of Basque Youth. Minorization and Visibilization in the Spanish and European Context. Cuad. Eur. Deusto 2022, 4, 107–135. [Google Scholar] [CrossRef]
- Jordan, P.; Mácha, P.; Balode, M.; Krtička, L.; Obrusník, U.; Pilch, P.; Sancho Reinoso, A. Place-Name Politics in Multilingual Areas; Springer International Publishing: Cham, Switzerland, 2021; ISBN 978-3-030-69487-6. [Google Scholar]
- Ruiz Vieytez, E.J. The Future of European Minority Languages: A Normative Analysis. Cuad. Eur. Deusto 2022, 4, 37–67. [Google Scholar] [CrossRef]
- Sanchez, J.M. Bilingüismo, disglosia, contacto de lenguas (Bilingualism, dysglossia, language contact). In Anuario del Seminario de Filología Vasca “Julio de Urquijo”; UPV/EHU University of the Basque Country: Bilbao, Spain, 1974; Volume 8, pp. 3–79. [Google Scholar]
- Brinkmann, L.M.; Duarte, J.; Melo-Pfeifer, S. Promoting Plurilingualism Through Linguistic Landscapes: A Multi-Method and Multisite Study in Germany and the Netherlands. TESL Can. J. 2022, 38, 88–112. [Google Scholar] [CrossRef]
- Marten, H.F.; Van Mensel, L.; Gorter, D. Studying Minority Languages in the Linguistic Landscape. In Minority Languages in the Linguistic Landscape; Palgrave Macmillan UK: London, UK, 2012; pp. 1–15. [Google Scholar]
- Hallett, R.W.; Quiñones, F.M. The linguistic landscape of an Urban Hispanic-Serving Institution in the United States. Soc. Semiot. 2021, 7, 1–15. [Google Scholar] [CrossRef]
- Rugkhapan, N.T. Between Toponymy and Cartography: An Evolving Geography of Heritage in George Town, Malaysia. In New Directions in Linguistic Geography; Springer Nature Singapore: Singapore, 2022; pp. 327–354. [Google Scholar]
- De Viñaspre, R.G. Euskara batuaren sorrera eta ibilbidea: Euskara batua eta toponimia (The creation and trajectory of the united Basque: The united Basque and toponymy). In Arantzazutik Mundu Zabalera: 1968–2018 = La Normativización del Euskera: 1968–2018 = La Standardisation de la Langue Basque: 1918–2018 = Standardization of the Basque Language: 1968–2018; Iberoamericana Vervuert: Madrid, Spain, 2022; pp. 241–252. [Google Scholar]
- Salaberri, P. Arauketa eta ikerketa, elkarren adiskide beharrak (Regulation and research, mutual needs). In Euskal Onomastika Aplikatua XXI. Mendean; Iberoamericana Editorial Vervuert: Madrid, Spain, 2020; Volume 39, pp. 155–168. [Google Scholar]
- JGG Juntas Generales de Gipuzkoa. Available online: https://www.bngipuzkoa.eus/ (accessed on 27 November 2022).
- Álvarez Pastor, M.; Ubillos Pernaut, J.; Muniategiandikoetxea Markiegi, J.; Valenciano Tamayo, T.; García Odiaga, I. Los límites fronterizos como aglutinadores de actividad en el territorio La frontera del Bidasoa (Border limits as agglutinators of activity in the territory The Bidasoa Border). In Proceedings of the Actas de los Seminarios de Apoyo a la Investigación hibridación y Transculturalidad en los modos de Habitación Contemporánea; Tapia Martín, C., Varona Gandulfo, M., Eds.; University of Seville: Seville, Spain, 2009; pp. 417–424. [Google Scholar]
- Lozano Valencia, M.A.; Lozano Valencia, P.J. Service mancommunities: An example of territorial vertebration in Guipuzcoa. A description of domestic waste in the territory. Bol. Asoc. Geógr. Esp. 2008, 48, 417–420. [Google Scholar]
- Dávila-Cabanillas, N. The rural enviroment in the territorial planning of the CAPV. Lurralde 2022, 45, 1–32. [Google Scholar]
- Membrado-Tena, J.C. Place names as indicators of extinct landscapes. The case of Castelló de la Plana. Cuad. Geogr. 2022, 108, 461–480. [Google Scholar]
- Cortes Generales (Spain). Constitución Española; Cortes Generales (General Courts): Madrid, Spain, 1978. [Google Scholar]
- Gobierno Vasco (Spain). V Mapa Sociolingüistico, 2011, 1st ed.; Servicio de Publicaciones del Gobierno Vasco: Vitoria-Gasteiz, Spain, 2014. [Google Scholar]
- Trapero, M. Para una Teoría Lingüística de la Toponimia Estudios de Toponimia Canaria; ULPGC. Servicio de Publicaciones y Difusión Científica: Las Palmas de Gran Canaria, Spain, 1995; Volume 3. [Google Scholar]
- Gobierno-Vasco-España. Decreto 179/2019, de 19 de Noviembre, sobre Normalización del uso Institucional y Administrativo de las Lenguas Oficiales en las Instituciones Locales de Euskadi (Decree 179/2019, of November 19, on the Standardization of the Institutional and Administrative Use of the Official Languages in the Local Institutions of the Basque Country); Basque Government: Vitoria-Gasteiz, Spain, 2019. [Google Scholar]
- Council-of-Europe. European Charter for Regional or Minority Languages (ETS No. 148); Council-of-Europe: Strasbourg, France, 1992. [Google Scholar]
- Jefatura-del-Estado-España. Instrumento de Ratificación de la Carta Europea de las Lenguas Regionales o Minoritarias, Hecha en Estrasburgo el 5 de Noviembre de 1992 (Instrument of Ratification of the European Charter for Regional or Minority Languages, Done at Strasbourg on November 5, 1992); Head of State-Spain: Madrid, Spain, 2001. [Google Scholar]
- Departamento de Cultura y Política Lingüística Nomenclator Geográfico Oficial de la CAE. Available online: https://www.euskadi.eus/toponima-onomastica-cav/web01-a2corpus/es/ (accessed on 28 July 2022).
- Gobierno de España. Real Decreto 1545/2007, de 23 de Noviembre, por el que se Regula el Sistema Cartográfico Nacional (Royal Decree 1545/2007, of November 23, 2007, which regulates the National Cartographic System); Government of Spain: Madrid, Spain, 2007. [Google Scholar]
- Figurska, M.; Dawidowicz, A.; Zysk, E. Voronoi Diagrams for Senior-Friendly Cities. Int. J. Environ. Res. Public Health 2022, 19, 7447. [Google Scholar] [CrossRef]
- LaForce, T.; Ebeida, M.; Jordan, S.; Miller, T.A.; Stauffer, P.H.; Park, H.; Leone, R.; Hammond, G. Voronoi Meshing to Accurately Capture Geological Structure in Subsurface Simulations. Math. Geosci. 2022, 55, 129–161. [Google Scholar] [CrossRef]
- Qi, Y.; Wang, R.; He, B.; Lu, F.; Xu, Y. Compact and Efficient Topological Mapping for Large-Scale Environment with Pruned Voronoi Diagram. Drones 2022, 6, 183. [Google Scholar] [CrossRef]
- Dalvi, N.; Olteanu, M.; Raghavan, M.; Bohannon, P. Deduplicating a places database. In Proceedings of the 23rd international conference on World wide web—WWW ’14, Seoul, Republic of Korea, 7–11 April 2014; ACM Press: New York, NY, USA, 2014; pp. 409–418. [Google Scholar]
- Instituto Geográfico Nacional. MTN25. Normas de Edición 1:25000 (1:25000 Edition Standards); Instituto Geográfico Nacional: Madrid, Spain, 2014. [Google Scholar]
- Black, P.E. “Longest Common Substring” in Dictionary of Algorithms and Data Structures. Available online: https://www.nist.gov/dads/HTML/longestCommonSubstring.html (accessed on 27 September 2022).
- Kaufman, A.R.; Klevs, A. Adaptive Fuzzy String Matching: How to Merge Datasets with Only One (Messy) Identifying Field. Polit. Anal. 2022, 30, 590–596. [Google Scholar] [CrossRef]
- Pociello, E.; Agirre, E.; Aldezabal, I. Methodology and construction of the Basque WordNet. Lang. Resour. Eval. 2011, 45, 121–142. [Google Scholar] [CrossRef]
- Azcárate Luxán, M.; Alcázar González, A.; García Cancela, X.; Gorrotxategi Nieto, M.; Vives Pérez i Piquer, A. Toponymic Guidelines for Map and Other Editors for International Use (Spain); Azcárate Luxán, M., Ed.; Centro Nacional de Información Geográfica: Madrid, Spain, 2012. [Google Scholar]
- Ugarte Garrido, J. II Congreso geoEuskadi (2nd geoEuskadi Congress). In Proceedings of the Toponimia eta EAEko Izendegi Geografiko Ofiziala; Departamento de Planificación Territorial, Vivienda y Transportes: Bilbao, Spain, 2021. [Google Scholar]
- Blandón Andrade, J.C. Applications of natural language processing. In Entre Ciencia e Ingeniería; Universidad Católica de Pereira: Pereira, Colombia, 2022; Volume 16, pp. 7–8. [Google Scholar]
- Rakhilina, E.; Ryzhova, D.; Badryzlova, Y. Lexical typology and semantic maps: Perspectives and challenges. Z. Sprachwiss. 2022, 41, 231–262. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Administrative Unit | Cadastral Parcels (CP) | CP with a Name | % CP with a Name | NGO-CAE |
|---|---|---|---|---|
| Abaltzisketa (001) | 1050 | 508 | 48.4 | 160 |
| Mutriku (056) | 1415 | 556 | 39.3 | 396 |
| Ordizia (079) | 426 | 111 | 26.1 | 70 |
| Oñati (059) | 7235 | 2661 | 36.8 | 1331 |
| GIPUZKOA | 115,282 | 45,326 | 39.3 | 25,108 |
| Administrative Unit | 6C+ Long LCS | 5C Long LCS | 4C Long LCS | 3C Long LCS | 2C Long LCS |
|---|---|---|---|---|---|
| Abaltzisketa (001) | 221 | 113 | 664 | 1696 | 5359 |
| Mutriku (056) | 111 | 338 | 314 | 1278 | 6361 |
| Ordizia (079) | 108 | 63 | 92 | 291 | 2254 |
| Oñati (059) | 1122 | 512 | 2103 | 6250 | 29,510 |
| GIPUZKOA | 18,171 | 8455 | 32,879 | 99,277 | 450,736 |
| Administrative Unit | 5C+ Match | 5C+ Match Parcels | Significant 5C+ Match Supervised | Significant 5C+ Match Parcels | 5C+ Match and Semantic Filter (SF) | 5C+ Match and SF Parcels |
|---|---|---|---|---|---|---|
| Abaltzisketa (001) | 334 | 157 | 294 | 130 | 286 | 118 |
| Mutriku (056) | 449 | 256 | 373 | 210 | 343 | 214 |
| Ordizia (079) | 25 | 20 | 23 | 20 | 23 | 20 |
| Oñati (059) | 1689 | 1125 | 1424 | 1035 | 1424 | 972 |
| GIPUZKOA | 27,679 | 17,306 | 22,617 | 14,691 |
| Administrative Unit | 4C Match (without 5C+ Parcels) | 4C Match Parcels | Significant 4C Match Supervised | Significant 4C Match Parcels | 4C Match and Semantic Filter (SF) | 4C Match and SF Parcels |
|---|---|---|---|---|---|---|
| Abaltzisketa (001) | 664 | 172 | 64 | 23 | 47 | 38 |
| Mutriku (056) | 223 | 90 | 46 | 22 | 72 | 44 |
| Ordizia (079) | 29 | 10 | 7 | 1 | 14 | 4 |
| Oñati (059) | 150 | 50 | 28 | 10 | 40 | 19 |
| GIPUZKOA | 18,092 | 7128 | 7210 | 3488 |
| Administrative Unit | CP with a Name | Total Manual Significant Match CP | Total Auto + Semantic CP Selection | Omission Occurrence CP | Commission Occurrence CP |
|---|---|---|---|---|---|
| Abaltzisketa (001) | 508 | 180 | 156 | 18 | 3 |
| Mutriku (056) | 556 | 346 | 258 | 25 | 23 |
| Ordizia (079) | 111 | 21 | 24 | 0 | 0 |
| Oñati (059) | 2661 | 1045 | 993 | 176 | 39 |
| % Total (from Total CP with manual significant match) | 13.8% | 4.1% | |||
| % Total (from Total CP with a name) | 5.7% | 1.7% | |||
| Administrative Unit | CP with a Name | Total Manual Significant Match CP | Total Auto + Semantic CP Selection | Auto + Semantic % from Significant Match CP | Auto + Semantic % from Significant with a Name |
|---|---|---|---|---|---|
| Abaltzisketa (001) | 508 | 180 | 156 | 86.6% | 30.7% |
| Mutriku (056) | 556 | 346 | 258 | 74.5% | 46.4% |
| Ordizia (079) | 111 | 21 | 24 | 114.3% | 21.6% |
| Oñati (059) | 2661 | 1045 | 993 | 96.0% | 37.3% |
| Sample average | 89.9% | 37.7% | |||
| GIPUZKOA | 45,326 | 18,179 | 40.1% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mitxelena-Hoyos, O.; Amaro-Mellado, J.-L. A Comparison of Cartographic and Toponymic Databases in a Multilingual Environment: A Methodology for Detecting Redundancies Using ETL and GIS Tools. ISPRS Int. J. Geo-Inf. 2023, 12, 70. https://doi.org/10.3390/ijgi12020070
Mitxelena-Hoyos O, Amaro-Mellado J-L. A Comparison of Cartographic and Toponymic Databases in a Multilingual Environment: A Methodology for Detecting Redundancies Using ETL and GIS Tools. ISPRS International Journal of Geo-Information. 2023; 12(2):70. https://doi.org/10.3390/ijgi12020070
Chicago/Turabian StyleMitxelena-Hoyos, Oihana, and José-Lázaro Amaro-Mellado. 2023. "A Comparison of Cartographic and Toponymic Databases in a Multilingual Environment: A Methodology for Detecting Redundancies Using ETL and GIS Tools" ISPRS International Journal of Geo-Information 12, no. 2: 70. https://doi.org/10.3390/ijgi12020070