
Multi-GPU-Parallel and Tile-Based Kernel Density Estimation for Large-Scale Spatial Point Pattern Analysis


Abstract
:1. Introduction
2. Existing GPU-Parallel KDE
2.1. Overview
2.2. Limitations
3. New Extensions to GPU-Parallel KDE
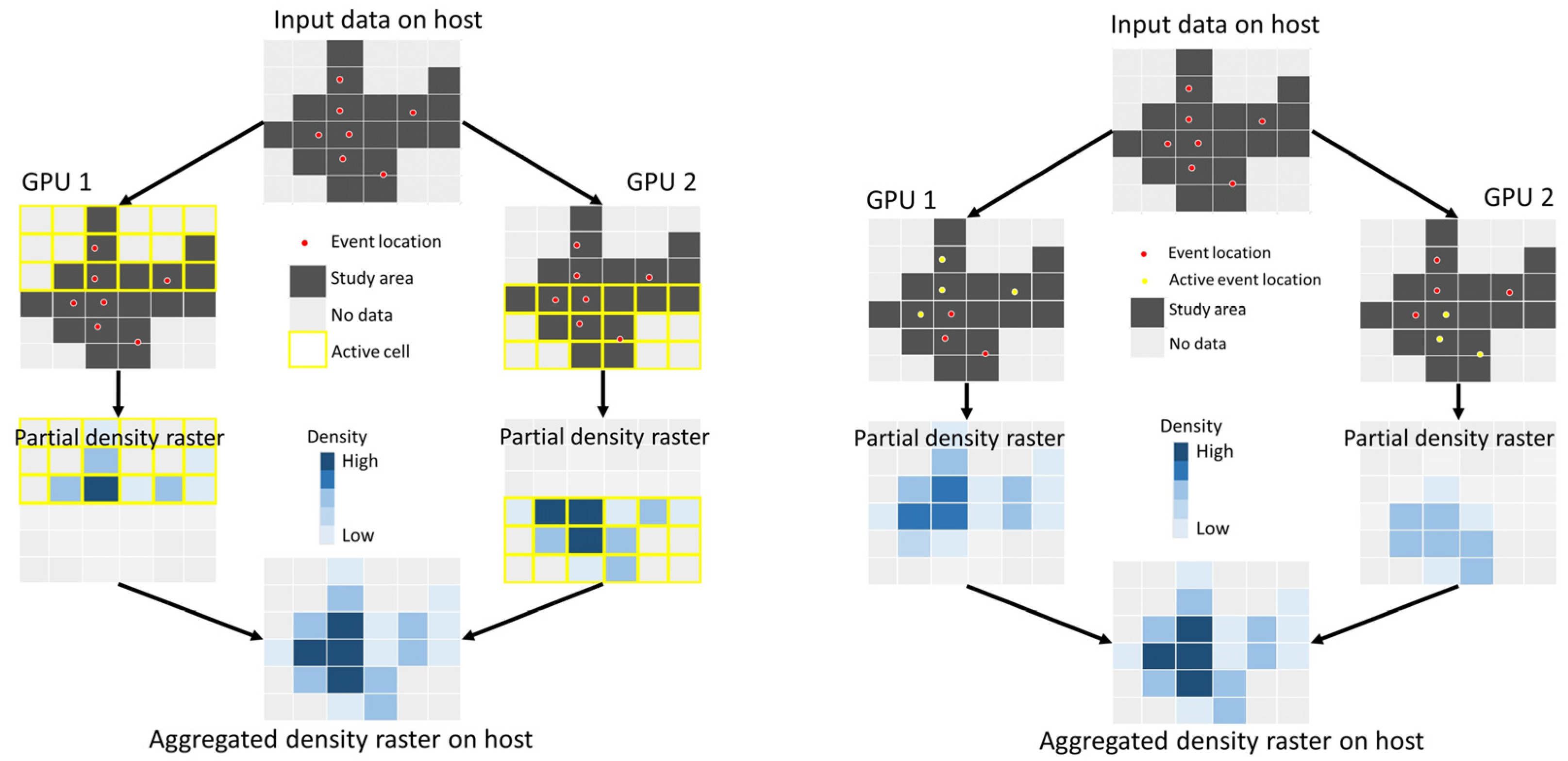
3.1. Multi-GPU Parallel Computing
3.2. Tile-Based Density Estimation
4. Performance Evaluation
4.1. Experiment Design
4.1.1. Overall Design and Metrics
4.1.2. Experiment Data
4.1.3. Computing Platforms
4.2. Experiments and Results
4.2.1. Effects of Multi-GPU Parallel Computing
4.2.1.1. Impact of the Number of Points
4.2.1.2. Impact of Density Raster Cell Size
4.2.1.3. Impact of Bandwidth Option
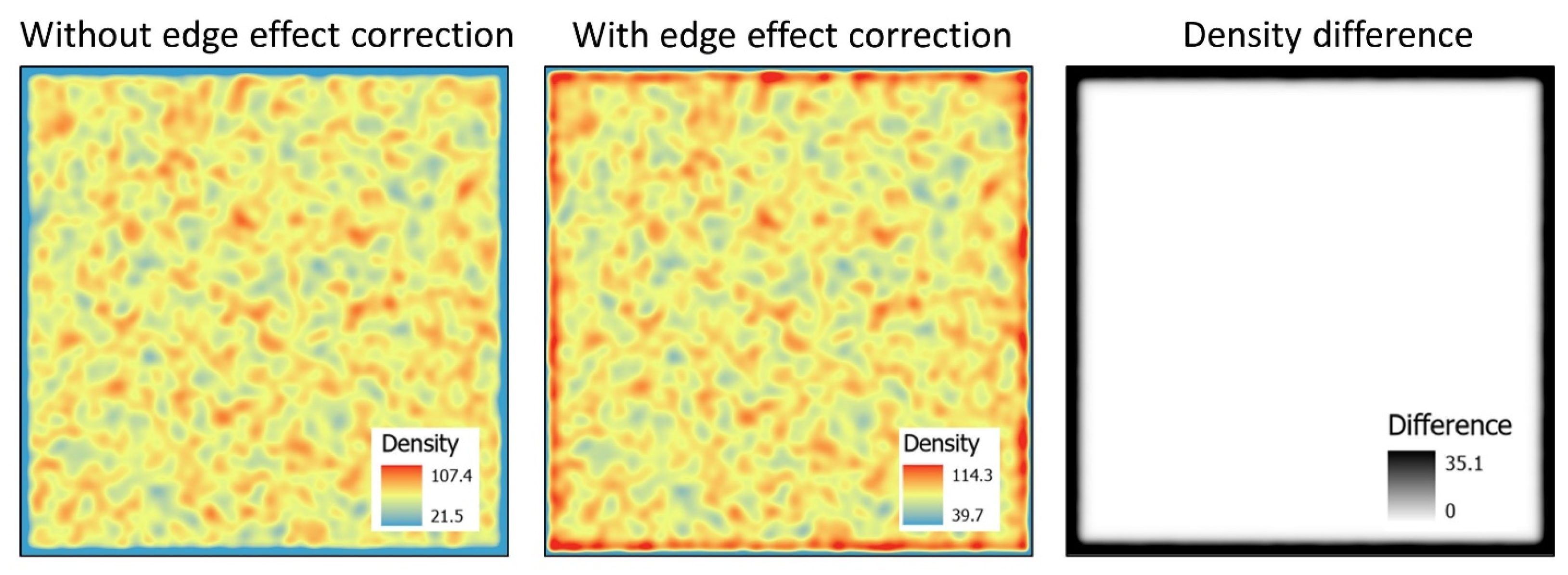
4.2.1.4. Impact of Edge Effect Correction
4.2.1.5. Impact of Computing Platforms
4.2.2. Effects of Tile-Based Density Estimation
4.2.3. Point Pattern Analysis on the eBird Dataset
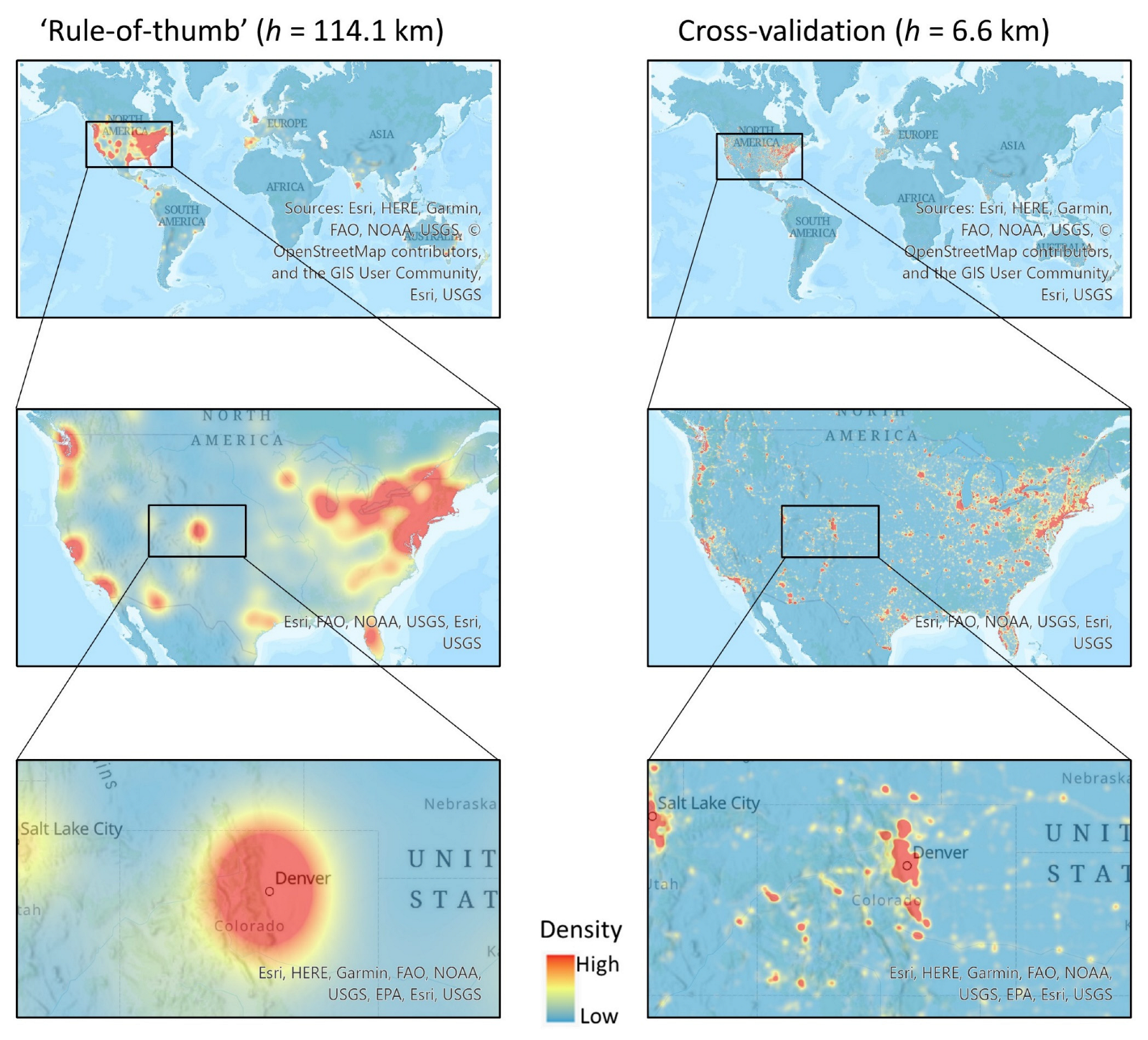
4.2.3.1. KDE with Fixed Bandwidth
4.2.3.2. KDE with Adaptive Bandwidths
5. Discussion
5.1. Cost-Benefit Analysis of the New Extensions
5.2. Recommendations on Using GPU-Parallel KDE
5.3. Point Pattern Analysis versus Heat Map Visualization
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shi, X.; Li, M.; Hunter, O.; Guetti, B.; Andrew, A.; Stommel, E.; Bradley, W.; Karagas, M. Estimation of environmental exposure: Interpolation, kernel density estimation or snapshotting. Ann. GIS 2019, 25, 1–8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xie, Z.; Yan, J. Kernel Density Estimation of traffic accidents in a network space. Comput. Environ. Urban Syst. 2008, 32, 396–406. [Google Scholar] [CrossRef] [Green Version]
- Nakaya, T.; Yano, K. Visualising crime clusters in a space-time cube: An exploratory data-analysis approach using space-time kernel density estimation and scan statistics. Trans. GIS 2010, 14, 223–239. [Google Scholar] [CrossRef]
- Yuan, K.; Chen, X.; Gui, Z.; Li, F.; Wu, H. A quad-tree-based fast and adaptive Kernel Density Estimation algorithm for heat-map generation. Int. J. Geogr. Inf. Sci. 2019, 33, 2455–2476. [Google Scholar] [CrossRef]
- Brunsdon, C. Estimating probability surfaces for geographical point data: An adaptive kernel algorithm. Comput. Geosci. 1995, 21, 877–894. [Google Scholar] [CrossRef]
- Diggle, P. A Kernel Method for Smoothing Point Process Data. J. R. Stat. Soc. Ser. C (Appl. Stat.) 1985, 34, 138–147. [Google Scholar] [CrossRef]
- van Dijk, J.; Longley, P.A. Interactive display of surnames distributions in historic and contemporary Great Britain. J. Maps 2020, 16, 68–76. [Google Scholar] [CrossRef] [Green Version]
- Okabe, A.; Satoh, T.; Sugihara, K. A kernel density estimation method for networks, its computational method and a GIS-based tool. Int. J. Geogr. Inf. Sci. 2009, 23, 7–32. [Google Scholar] [CrossRef]
- Xie, Z.; Yan, J. Detecting traffic accident clusters with network kernel density estimation and local spatial statistics: An integrated approach. J. Transp. Geogr. 2013, 31, 64–71. [Google Scholar] [CrossRef]
- Dai, D.; Taquechel, E.; Steward, J.; Strasser, S. The impact of built environment on pedestrian crashes and the identification of crash clusters on an urban university campus. West. J. Emerg. Med. 2010, 11, 294. [Google Scholar]
- Hohl, A.; Tang, W.; Casas, I.; Shi, X.; Delmelle, E. Detecting space–time patterns of disease risk under dynamic background population. J. Geogr. Syst. 2022, 24, 389–417. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.; Gong, J.; Li, S. Exploring spatiotemporal clusters based on extended kernel estimation methods. Int. J. Geogr. Inf. Sci. 2017, 31, 1154–1177. [Google Scholar]
- Delmelle, E.; Dony, C.; Casas, I.; Jia, M.; Tang, W. Visualizing the impact of space-time uncertainties on dengue fever patterns. Int. J. Geogr. Inf. Sci. 2014, 28, 1107–1127. [Google Scholar] [CrossRef]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis; Chapman and Hall: London, UK, 1986. [Google Scholar]
- Carlos, H.A.; Shi, X.; Sargent, J.; Tanski, S.; Berke, E.M. Density estimation and adaptive bandwidths: A primer for public health practitioners. Int. J. Health Geogr. 2010, 9, 39. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shi, X. Selection of bandwidth type and adjustment side in kernel density estimation over inhomogeneous backgrounds. Int. J. Geogr. Inf. Sci. 2010, 24, 643–660. [Google Scholar] [CrossRef]
- Fotheringham, A.S.; Brunsdon, C.; Charlton, M. Quantitative Geogr. Perspectives on Spatial Data Analysis; Sage: Thousand Oaks, CA, USA, 2000; ISBN 1847876412. [Google Scholar]
- Breiman, L.; Meisel, W.; Purcell, E. Variable kernel estimates of multivariate densities. Technometrics 1977, 19, 135–144. [Google Scholar] [CrossRef]
- Abramson, I.S. On bandwidth variation in kernel estimates-A square root law. Ann. Stat. 1982, 10, 1217–1223. [Google Scholar] [CrossRef]
- Zhang, G.; Zhu, A.-X.; Huang, Q. A GPU-accelerated adaptive kernel density estimation approach for efficient point pattern analysis on spatial big data. Int. J. Geogr. Inf. Sci. 2017, 31, 2068–2097. [Google Scholar] [CrossRef]
- Lee, J.-G.; Kang, M. Geospatial Big Data: Challenges and Opportunities. Big Data Res. 2015, 2, 74–81. [Google Scholar] [CrossRef]
- Zhang, G. Spatial and Temporal Patterns in Volunteer Data Contribution Activities: A Case Study of eBird. ISPRS Int. J. Geo-Inf. 2020, 9, 597. [Google Scholar] [CrossRef]
- Psyllidis, A.; Gao, S.; Hu, Y.; Kim, E.-K.; McKenzie, G.; Purves, R.; Yuan, M.; Andris, C. Points of Interest (POI): A commentary on the state of the art, challenges, and prospects for the future. Comput. Urban Sci. 2022, 2, 20. [Google Scholar] [CrossRef] [PubMed]
- Zhang, G. Detecting and visualizing observation hot-spots in massive volunteer-contributed geographic data across spatial scales using GPU-accelerated kernel density estimation. ISPRS Int. J. Geo-Inf. 2022, 11, 55. [Google Scholar] [CrossRef]
- Wu, H.; Zhang, T.; Gong, J. GeoComputation for Geospatial Big Data. Trans. GIS 2014, 18, 1–2. [Google Scholar] [CrossRef]
- Yang, C. Utilizing Cloud Computing to Address Big Geospatial Data Challenges. Comput. Environ. Urban Syst. 2017, 61, 120–128. [Google Scholar] [CrossRef] [Green Version]
- Wang, S. A CyberGIS framework for the synthesis of Cyberinfrastructure, GIS, and spatial analysis. Ann. Assoc. Am. Geogr. 2010, 100, 535–557. [Google Scholar] [CrossRef]
- Zhang, G.; Huang, Q.; Zhu, A.-X.; Keel, J. Enabling point pattern analysis on spatial big data using cloud computing: Optimizing and accelerating Ripley’s K function. Int. J. Geogr. Inf. Sci. 2016, 30, 2230–2252. [Google Scholar] [CrossRef]
- Tang, W.; Feng, W.; Jia, M. Massively parallel spatial point pattern analysis: Ripley’s K function accelerated using graphics processing units. Int. J. Geogr. Inf. Sci. 2015, 29, 412–439. [Google Scholar] [CrossRef]
- Zhang, G. PyCLKDE: A big data-enabled high-performance computational framework for species habitat suitability modeling and mapping. Trans. GIS 2022, 26, 1754–1774. [Google Scholar] [CrossRef]
- Zhang, G.; Zhu, A.-X.; Liu, J.; Guo, S.; Zhu, Y. PyCLiPSM: Harnessing heterogeneous computing resources on CPUs and GPUs for accelerated digital soil mapping. Trans. GIS 2021, 25, 1396–1418. [Google Scholar] [CrossRef]
- Luebke, D. CUDA: Scalable parallel programming for high-performance scientific computing. In Proceedings of the 2008 5th IEEE International Symposium on Biomedical Imaging: From Nano to Macro, Paris, France, 14–17 May 2008; pp. 836–838. [Google Scholar]
- Shi, X.; Ye, F. Kriging interpolation over heterogeneous computer architectures and systems. GIScience Remote Sens. 2013, 50, 196–211. [Google Scholar] [CrossRef]
- Warmerdam, F. The Geospatial Data Abstraction Library. In Open Source Approaches in Spatial Data Handling; Hall, G.B., Leahy, M.G., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 87–104. ISBN 978-3-540-74831-1. [Google Scholar]
- Qin, C.-Z.; Zhu, L.-J. GDAL/OGR and Geospatial Data IO Libraries. In The Geographic Information Science & Technology Body of Knowledge. 2020. Available online: https://gistbok.ucgis.org/bok-topics/gdalogr-and-geospatial-data-io-libraries (accessed on 30 August 2022).
- eBird. eBird Basic Dataset Metadata (v1.13). 2021. Available online: https://ebird.org/data/download/ebd (accessed on 30 August 2022).
- Sullivan, B.L.; Aycrigg, J.L.; Barry, J.H.; Bonney, R.E.; Bruns, N.; Cooper, C.B.; Damoulas, T.; Dhondt, A.A.; Dietterich, T.; Farnsworth, A.; et al. The eBird enterprise: An integrated approach to development and application of citizen science. Biol. Conserv. 2014, 169, 31–40. [Google Scholar] [CrossRef]
- Stein, A.; Detotto, C.; Belgiu, M. A spatial statistical study of the distribution of Sardinian nuraghes. Ann. GIS 2022, 28, 245–262. [Google Scholar] [CrossRef]
- Perrot, A.; Bourqui, R.; Hanusse, N.; Lalanne, F.; Auber, D. Large interactive visualization of density functions on big data infrastructure. In Proceedings of the 2015 IEEE 5th Symposium on Large Data Analysis and Visualization (lDAV), Chicago, IL, USA, 25–26 October 2015; pp. 99–106. [Google Scholar]
- Perrot, A.; Bourqui, R.; Hanusse, N.; Auber, D. HeatPipe: High throughput, low latency big data heatmap with spark streaming. In Proceedings of the 2017 21st International Conference Information Visualisation (IV), London, UK, 11–14 July 2017; pp. 66–71. [Google Scholar]
- Chan, T.N.; Cheng, R.; Yiu, M.L. QUAD: Quadratic-Bound-based Kernel Density Visualization. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, Portland, OR, USA, 14–19 June 2020; pp. 35–50. [Google Scholar]
- Chan, T.N.; Ip, P.L.; U, L.H.; Tong, W.H.; Mittal, S.; Li, Y.; Cheng, R. KDV-Explorer: A near real-time kernel density visualization system for spatial analysis. Proc. VLDB Endow. 2021, 14, 2655–2658. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Platform | CPU | GPU |
|---|---|---|
|
Precision 3620 (Basic) | Intel Core i7 CPU | NVIDIA Quadro P1000 × 2 |
| 3.6 GHz max clock speed | 1.48 GHz max clock speed | |
| 4 cores (8 logical processors) | 4 GB memory | |
| 16 GB memory | 80 GB/s peak memory bandwidth | |
|
Precision 5820 (Intermediate) | Intel Xeon CPU | NVIDIA Quadro P4000 × 2 |
| 3.7 GHz max clock speed | 1.48 GHz max clock speed | |
| 8 cores (16 logical processors) | 8 GB memory | |
| 64 GB memory | 243 GB/s peak memory bandwidth | |
|
PowerEdge T640 (Advanced) | Intel Xeon CPU | NVIDIA Tesla V100 × 1 |
| 2.7 GHz max clock speed | 1.38 GHz max clock speed | |
| 24 cores (48 logical processors) | 32 GB memory | |
| 192 GB memory | 898 GB/s peak memory bandwidth |
| # Points | # GPUs | Total | I/O | Computation | # Folds Increased | Speedup |
|---|---|---|---|---|---|---|
| 100,000 | 1 | 31.67 | 0.17 | 31.50 | 1.00 | |
| 2 | 20.10 | 0.17 | 19.92 | 1.00 | 1.58 | |
| 200,000 | 1 | 85.45 | 0.16 | 85.29 | 2.71 | |
| 2 | 45.89 | 0.17 | 45.72 | 2.29 | 1.87 | |
| 500,000 | 1 | 281.41 | 0.19 | 281.22 | 8.93 | |
| 2 | 152.29 | 0.20 | 152.09 | 7.63 | 1.85 | |
| 1,000,000 | 1 | 952.00 | 0.17 | 951.83 | 30.22 | |
| 2 | 496.35 | 0.18 | 496.16 | 24.90 | 1.92 | |
| 2,000,000 | 1 | 2237.94 | 0.15 | 2237.79 | 71.04 | |
| 2 | 1159.77 | 0.17 | 1159.60 | 58.20 | 1.93 |
| Cell Size | # GPUs | Total | I/O | Computation | # Folds Increased | Speedup |
|---|---|---|---|---|---|---|
| 0.5 | 1 | 11.30 | 0.00 | 11.29 | 1.00 | |
| 2 | 13.24 | 0.00 | 13.23 | 1.00 | 0.85 | |
| 0.2 | 1 | 13.24 | 0.01 | 13.23 | 1.17 | |
| 2 | 12.67 | 0.02 | 12.65 | 0.96 | 1.05 | |
| 0.1 | 1 | 20.69 | 0.08 | 20.62 | 1.83 | |
| 2 | 17.87 | 0.06 | 17.81 | 1.35 | 1.16 | |
| 0.05 | 1 | 47.67 | 0.15 | 47.51 | 4.21 | |
| 2 | 31.47 | 0.21 | 31.26 | 2.36 | 1.52 | |
| 0.02 | 1 | 235.49 | 1.09 | 234.41 | 20.75 | |
| 2 | 125.65 | 1.27 | 124.38 | 9.40 | 1.88 |
| Bandwidth Option | # GPUs | Total | I/O | Computation | # Folds Increased | Speedup |
|---|---|---|---|---|---|---|
|
Fixed bandwidth (‘rule-of-thumb’) | 1 | 47.67 | 0.15 | 47.51 | 1.00 | |
| 2 | 31.47 | 0.21 | 31.26 | 1.00 | 1.52 | |
|
Fixed bandwidth (cross-validation) | 1 | 155.79 | 0.16 | 155.63 | 3.28 | |
| 2 | 85.72 | 0.17 | 85.55 | 2.74 | 1.82 | |
|
Adaptive bandwidths (cross-validation) | 1 | 952.00 | 0.17 | 951.83 | 20.03 | |
| 2 | 496.35 | 0.18 | 496.16 | 15.87 | 1.92 |
| Bandwidth Option | # GPUs | Total | I/O | Computation | # Folds Increased | Speedup |
|---|---|---|---|---|---|---|
|
Fixed bandwidth (‘rule-of-thumb’) | 1 | 50.07 | 0.16 | 49.91 | 1.00 | |
| 2 | 31.16 | 0.15 | 31.01 | 1.00 | 1.61 | |
|
Fixed bandwidth (cross-validation) | 1 | 459.67 | 0.16 | 459.51 | 9.21 | |
| 2 | 242.92 | 0.17 | 242.75 | 7.83 | 1.89 | |
|
Adaptive bandwidths (cross-validation) | 1 | 17,203.41 | 0.18 | 17,203.23 | 344.70 | |
| 2 | 8941.88 | 0.19 | 8941.69 | 288.39 | 1.92 |
| Platform | # GPUs | Total | I/O | Computation | # Folds Decreased | Speedup |
|---|---|---|---|---|---|---|
| Basic | 1 | 2829.95 | 0.17 | 2829.78 | 1.00 | |
| 2 | 1473.41 | 0.17 | 1473.24 | 1.00 | 1.92 | |
| Intermediate | 1 | 952.00 | 0.17 | 951.83 | 2.97 | |
| 2 | 496.35 | 0.18 | 496.16 | 2.97 | 1.92 | |
| Advanced | 1 | 225.27 | 0.19 | 225.08 | 12.57 | n/a |
| Platform | # GPUs | # Tiles | Total | I/O | Computation |
|---|---|---|---|---|---|
| Advanced | 1 | 1 | 772.36 | 22.37 | 749.99 |
| Basic | 2 | 9 | 7370.79 | 57.54 | 7313.25 |
| Platform | Fixed Bandwidth | # GPUs | # Tiles | Total | I/O | Computation | Speedup |
|---|---|---|---|---|---|---|---|
| Intermediate | ‘Rule-of-thumb’ | 1 | 8 | 226.16 | 1.51 | 224.65 | |
| 2 | 8 | 116.79 | 1.50 | 115.29 | 1.95 | ||
| Cross-validation | 1 | 15 | 2583.30 | 1.58 | 2581.72 | ||
| 2 | 15 | 1297.52 | 1.75 | 1295.77 | 1.99 | ||
| Advanced | ‘Rule-of-thumb’ | 1 | 8 | 32.31 | 1.80 | 30.52 | |
| Cross-validation | 1 | 8 | 567.92 | 1.76 | 566.16 |
| Platform | # GPUs | # Tiles | I/O | Total | Computation |
|---|---|---|---|---|---|
| Intermediate | 2 | 32 | 12.82 | 482.13 | 469.31 |
| Advanced | 1 | 8 | 7.16 | 116.57 | 109.41 |
| Platform | # Tiles | # GPUs | Total | I/O | Computation | Speedup |
|---|---|---|---|---|---|---|
| Basic | 9 | 1 | 147.96 | 1.74 | 146.23 | |
| 9 | 2 | 78.79 | 1.88 | 76.91 | 1.90 | |
| Intermediate | 9 | 1 | 51.43 | 1.46 | 49.97 | |
| 9 | 2 | 28.47 | 1.53 | 26.94 | 1.86 | |
| Advanced | 9 | 1 | 11.14 | 1.67 | 9.47 | n/a |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, G.; Xu, J. Multi-GPU-Parallel and Tile-Based Kernel Density Estimation for Large-Scale Spatial Point Pattern Analysis. ISPRS Int. J. Geo-Inf. 2023, 12, 31. https://doi.org/10.3390/ijgi12020031
Zhang G, Xu J. Multi-GPU-Parallel and Tile-Based Kernel Density Estimation for Large-Scale Spatial Point Pattern Analysis. ISPRS International Journal of Geo-Information. 2023; 12(2):31. https://doi.org/10.3390/ijgi12020031
Chicago/Turabian StyleZhang, Guiming, and Jin Xu. 2023. "Multi-GPU-Parallel and Tile-Based Kernel Density Estimation for Large-Scale Spatial Point Pattern Analysis" ISPRS International Journal of Geo-Information 12, no. 2: 31. https://doi.org/10.3390/ijgi12020031