
Extending Geodemographics Using Data Primitives: A Review and a Methodological Proposal



Abstract
:1. Introduction
2. Geodemographic Classifications
2.1. Evolution
2.2. Contemporary Classifications
2.3. Open, Closed and Hybrid Geodemographics
2.4. Bespoke Classifications
3. The Limitations of Geodemographic Classifications
3.1. Temporal Dynamics
3.2. Hard Classification
3.3. Summary
- Geodemographic classifications are temporally statistic and fail to capture the dynamic nature of many neighbourhoods;
- Classifications constructed on multiple decadal population censuses may not be sufficiently sensitive to the social processes experienced by neighbourhoods;
- The hard allocation of cluster labels masks the degree to which an individual area is a member of the class;
- When evaluated over time, clustering fails to capture any smaller signals of change or within-cluster changes.
4. Data Primitives
4.1. Defining Data Primitives
4.2. Data Primitives for Geodemographic Research
4.3. Analysing State and Change
- income inequality;
- occupation;
- unemployment;
- population density;
- population flux;
- ethnicity;
- housing affordability;
- house price;
- education;
- poor health;
- migration churn;
- business vacancy rates.
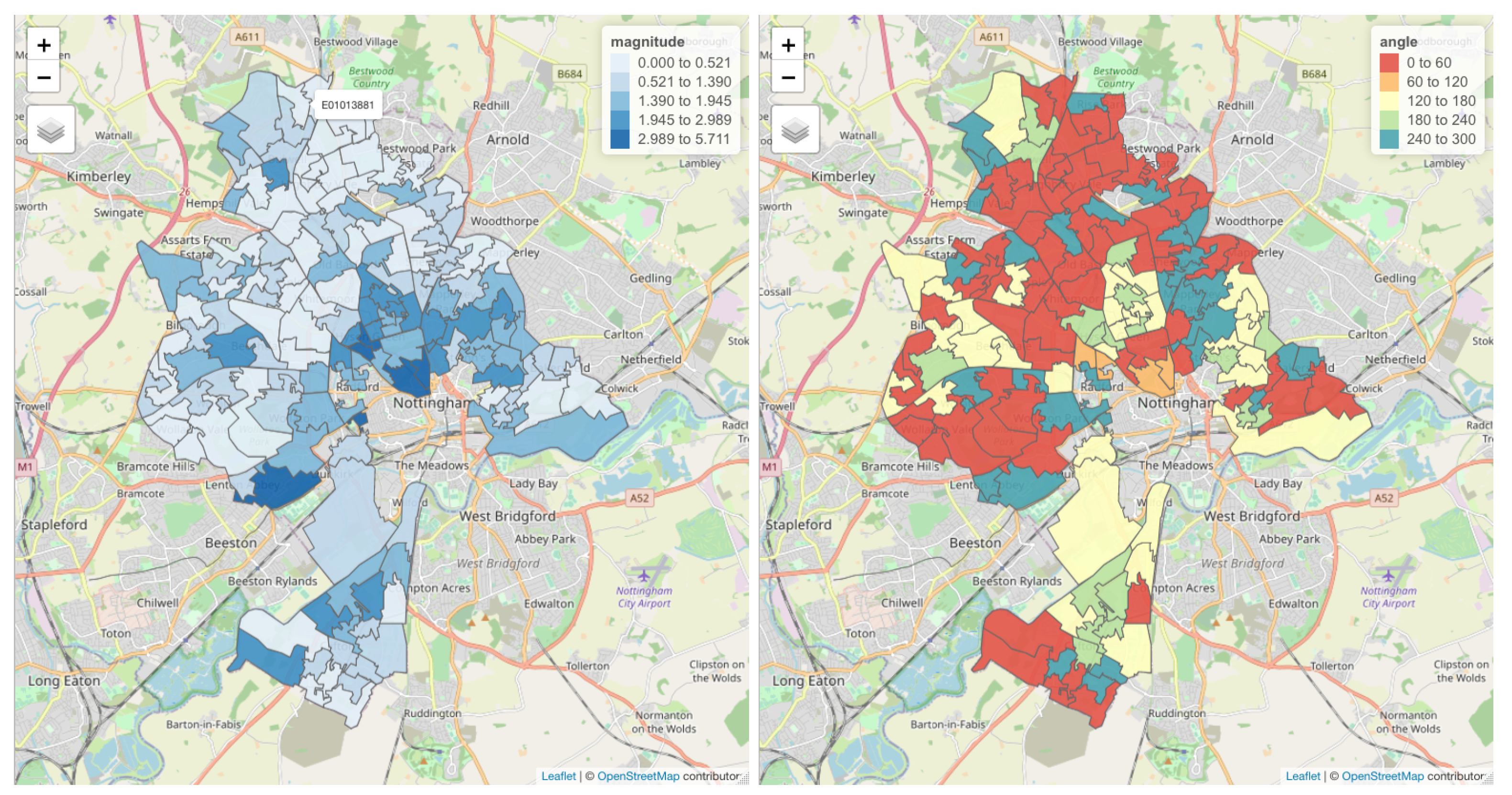
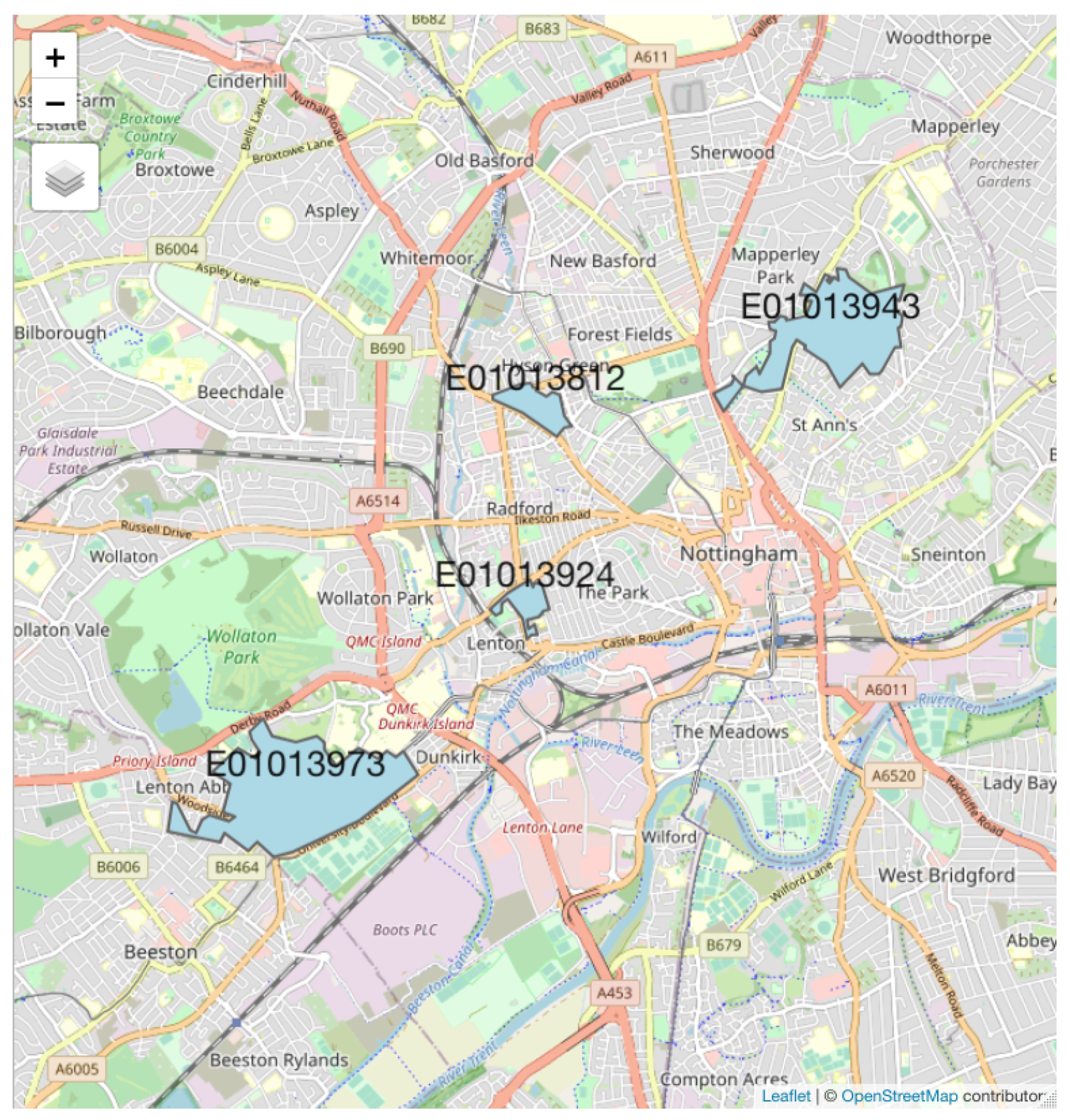
4.4. Case Study Illustration
4.5. Problems Yet to Be Solved
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, Y.; Cheng, T. Understanding public transit patterns with open geodemographics to facilitate public transport planning. Transp. Transp. Sci. 2020, 16, 76–103. [Google Scholar] [CrossRef] [Green Version]
- Harris, R.; Sleight, P.; Webber, R. Geodemographics, GIS and Neighbourhood Targeting; John Wiley & Sons: Hoboken, NJ, USA, 2005; Volume 8. [Google Scholar]
- Mitchell, V.W.; McGoldrick, P.J. The role of geodemographics in segmenting and targeting consumer markets: A Delphi study. Eur. J. Mark. 1994, 28, 54–72. [Google Scholar] [CrossRef]
- Xiang, L.; Stillwell, J.; Burns, L.; Heppenstall, A.; Norman, P. A geodemographic classification of sub-districts to identify education inequality in Central Beijing. Comput. Environ. Urban Syst. 2018, 70, 59–70. [Google Scholar] [CrossRef]
- Petersen, J.; Gibin, M.; Longley, P.; Mateos, P.; Atkinson, P.; Ashby, D. Geodemographics as a tool for targeting neighbourhoods in public health campaigns. J. Geogr. Syst. 2011, 13, 173–192. [Google Scholar] [CrossRef]
- Singleton, A.D.; Wilson, A.; O’Brien, O. Geodemographics and spatial interaction: An integrated model for higher education. J. Geogr. Syst. 2012, 14, 223–241. [Google Scholar] [CrossRef]
- Alexiou, A.; Singleton, A. Geodemographic analysis. In Geocomputation: A Practical Primer; SAGE: London, UK, 2015; pp. 137–151. [Google Scholar]
- Abbas, J.; Carlin, H.; Cunningham, A.; Dedman, D.; McVey, D. Technical Briefing 5: Geodemographic Segmentation. 2009. Available online: https://fingertips.phe.org.uk/profile/guidance (accessed on 4 April 2021).
- Webber, R.; Burrows, R. The Predictive Postcode: The Geodemographic Classification of British Society; Sage: Thousand Oaks, CA, USA, 2018. [Google Scholar]
- Singleton, A.D.; Longley, P.A. Creating open source geodemographics: Refining a national classification of census output areas for applications in higher education. Pap. Reg. Sci. 2009, 88, 643–666. [Google Scholar] [CrossRef]
- Fisher, P.; Tate, N.J. Modelling class uncertainty in the geodemographic Output Area Classification. Environ. Plan. Plan. Des. 2015, 42, 541–563. [Google Scholar] [CrossRef]
- Comber, A.J. The separation of land cover from land use using data primitives. J. Land Use Sci. 2008, 3, 215–229. [Google Scholar] [CrossRef] [Green Version]
- Wadsworth, R.; Balzter, H.; Gerard, F.; George, C.; Comber, A.; Fisher, P. An environmental assessment of land cover and land use change in Central Siberia using quantified conceptual overlaps to reconcile inconsistent data sets. J. Land Use Sci. 2008, 3, 251–264. [Google Scholar] [CrossRef] [Green Version]
- Herbert, D.; Thomas, C. Cities in Space: City as Place; Routledge: London, UK, 2013. [Google Scholar]
- Park, R.E. The city: Suggestions for the investigation of human behavior in the city environment. Am. J. Sociol. 1915, 20, 577–612. [Google Scholar] [CrossRef] [Green Version]
- Shevky, E.; Williams, M. The Social Areas of Los Angeles; University of California: Berkeley, CA, USA, 1949. [Google Scholar]
- Rees, P.H. Factorial ecology: An extended definition, survey, and critique of the field. Econ. Geogr. 1971, 47, 220–233. [Google Scholar] [CrossRef]
- Reibel, M.; Regelson, M. Neighborhood racial and ethnic change: The time dimension in segregation. Urban Geogr. 2011, 32, 360–382. [Google Scholar] [CrossRef]
- Singleton, A.D.; Spielman, S.E. The past, present, and future of geodemographic research in the United States and United Kingdom. Prof. Geogr. 2014, 66, 558–567. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Webber, R. An introduction to the national classification of wards and parishes. Plan. Res. Appl. Group Tech. Pap. 1977, 23. [Google Scholar]
- Weis, M.J. The Clustering of America; Number 306.0973 W426c; Perennial Library: New York, NY, USA, 1989. [Google Scholar]
- Birkin, M.; Clarke, G. Geodemographics. In International Encyclopaedia of Human Geography; Elsevier: Hoboken, NJ, USA, 2009. [Google Scholar]
- Longley, P. Geographical information systems: A renaissance of geodemographics for public service delivery. Prog. Hum. Geogr. 2005, 29, 57–63. [Google Scholar] [CrossRef]
- Sabater, A. Between flows and places: Using geodemographics to explore EU migration across neighbourhoods in Britain. Eur. J. Popul. 2015, 31, 207–230. [Google Scholar] [CrossRef] [Green Version]
- Moon, G.; Twigg, L.; Jones, K.; Aitken, G.; Taylor, J. The utility of geodemographic indicators in small area estimates of limiting long-term illness. Soc. Sci. Med. 2019, 227, 47–55. [Google Scholar] [CrossRef]
- Charlton, M.; Openshaw, S.; Wymer, C. Some new classifications of census enumeration districts in Britain: A poor mans ACORN. J. Econ. Soc. Meas. 1985, 13, 69–96. [Google Scholar]
- Baker, K.; Bermingham, J.; McDonald, C. The utility to market research of the classification of residential neighbourhoods. Mark. Res. Soc. J. 1997, 39, 1–12. [Google Scholar] [CrossRef]
- Howick, R. Building neighbourhood classifications-data sources and their geographic integration. In ESRC Transdisciplinary/Research Methods Seminar Series; UCL: London, UK, 2004; pp. 18–19. [Google Scholar]
- Birkin, M. Customer targeting, geodemographics and lifestyle approaches. In GIS for Business and Service Planning; Longley, P., Ed.; John Wiley: New York, NY, USA, 1995; pp. 104–149. [Google Scholar]
- Longley, P.A.; Adnan, M. Geo-temporal Twitter demographics. Int. J. Geogr. Inf. Sci. 2016, 30, 369–389. [Google Scholar] [CrossRef]
- Leventhal, B. Geodemographics for Marketers: Using Location Analysis for Research and Marketing; Kogan Page Publishers: London, UK, 2016. [Google Scholar]
- Pratt, M.D.; Longley, P.A.; Cheshire, J.; Gale, C. Open Data Sources for Domain Specific Geodemographics. GISRUK Conference. 2013. Available online: https://www.geos.ed.ac.uk/~gisteac/proceedingsonline/GISRUK2013/ (accessed on 2 June 2021).
- Singleton, A.; Pavlis, M.; Longley, P.A. The stability of geodemographic cluster assignments over an intercensal period. J. Geogr. Syst. 2016, 18, 97–123. [Google Scholar] [CrossRef] [Green Version]
- Feinberg, M. Hidden bias to responsible bias: An approach to information systems based on Haraway’s situated knowledges. Inf. Res. 2007, 12, 12–14. [Google Scholar]
- Mai, J.E. Classification in a social world: Bias and trust. J. Doc. 2010, 66, 627–642. [Google Scholar] [CrossRef] [Green Version]
- Burrows, R.; Gane, N. Geodemographics, software and class. Sociology 2006, 40, 793–812. [Google Scholar] [CrossRef]
- Vickers, D.; Rees, P. Creating the UK National Statistics 2001 output area classification. J. R. Stat. Soc. Ser. 2007, 170, 379–403. [Google Scholar] [CrossRef]
- Yazgi Walsh, B.; Brunsdon, C.; Charlton, M. Open Geodemographics: Classification of Small Areas, Ireland 2016. Appl. Spat. Anal. Policy 2021, 14, 51–79. [Google Scholar] [CrossRef]
- Gale, C.G.; Singleton, A.D.; Bates, A.G.; Longley, P.A. Creating the 2011 area classification for output areas (2011 OAC). J. Spat. Inf. Sci. 2016, 2016, 1–27. [Google Scholar] [CrossRef]
- Brunsdon, C.; Comber, A. Opening practice: Supporting reproducibility and critical spatial data science. J. Geogr. Syst. 2020, 1–20. [Google Scholar] [CrossRef]
- Brunsdon, C.; Comber, A. Big issues for big data: Challenges for critical spatial data analytics. J. Spat. Inf. Sci. 2020, 2020, 89–98. [Google Scholar]
- Singleton, A.D.; Longley, P.A. Data infrastructure requirements for new geodemographic classifications: The example of London’s workplace zones. Appl. Geogr. 2019, 109, 102038. [Google Scholar] [CrossRef]
- Webber, R.J.; Butler, T.; Phillips, T. Adoption of geodemographic and ethno-cultural taxonomies for analysing Big Data. Big Data Soc. 2015, 2, 2053951715583914. [Google Scholar] [CrossRef] [Green Version]
- Hjørland, B.; Pedersen, K.N. A substantive theory of classification for information retrieval. J. Doc. 2005, 61, 582–597. [Google Scholar] [CrossRef] [Green Version]
- Singleton, A.; Alexiou, A.; Savani, R. Mapping the geodemographics of digital inequality in Great Britain: An integration of machine learning into small area estimation. Comput. Environ. Urban Syst. 2020, 82, 101486. [Google Scholar] [CrossRef]
- Lamnisos, D.; Middleton, N.; Kyprianou, N.; Talias, M.A. Geodemographic Area Classification and association with mortality: An ecological study of small areas of Cyprus. Int. J. Environ. Res. Public Health 2019, 16, 2927. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McLachlan, G.; Norman, P. Analysing Socio-Economic Change Using a Time Comparable Geodemographic Classification: England and Wales, 1991–2011. Appl. Spat. Anal. Policy 2021, 14, 89–111. [Google Scholar] [CrossRef]
- Longley, P.A. Geodemographics and the practices of geographic information science. Int. J. Geogr. Inf. Sci. 2012, 26, 2227–2237. [Google Scholar] [CrossRef]
- Gale, C.G.; Longley, P.A. Temporal uncertainty in a small area open geodemographic classification. Trans. GIS 2013, 17, 563–588. [Google Scholar] [CrossRef] [Green Version]
- Prouse, V.; Grant, J.L.; Ramos, H.; Radice, M. Assessing Neighbourhood Change: Gentrification and suburban Decline in a Mid-Sized City; School of Planning, Dalhousie University: Halifax, NS, Canada, 2015. [Google Scholar]
- Batliwala, S. Measuring social change: Assumptions, myths and realities. Alliance 2006, 11, 12–14. [Google Scholar]
- An, L.; Tsou, M.H.; Crook, S.E.; Chun, Y.; Spitzberg, B.; Gawron, J.M.; Gupta, D.K. Space–time analysis: Concepts, quantitative methods, and future directions. Ann. Assoc. Am. Geogr. 2015, 105, 891–914. [Google Scholar] [CrossRef]
- Comber, A.; Wulder, M. Considering spatiotemporal processes in big data analysis: Insights from remote sensing of land cover and land use. Trans. GIS 2019, 23, 879–891. [Google Scholar] [CrossRef]
- Grekousis, G.; Thomas, H. Comparison of two fuzzy algorithms in geodemographic segmentation analysis: The Fuzzy C-Means and Gustafson–Kessel methods. Appl. Geogr. 2012, 34, 125–136. [Google Scholar] [CrossRef]
- Zhu, Z. Change detection using landsat time series: A review of frequencies, preprocessing, algorithms, and applications. ISPRS J. Photogramm. Remote Sens. 2017, 130, 370–384. [Google Scholar] [CrossRef]
- See, L.; Openshaw, S. Fuzzy geodemographic targeting. In Regional Science in Business; Springer: Berlin, Germany, 2001; pp. 269–281. [Google Scholar]
- Fisher, P. What is Where? Type-2 Fuzzy Sets for Geographical Information [Research Frontier]. IEEE Comput. Intell. Mag. 2007, 2, 9–14. [Google Scholar] [CrossRef]
- Adnan, M.; Longley, P.A.; Singleton, A.D.; Brunsdon, C. Towards real-time geodemographics: Clustering algorithm performance for large multidimensional spatial databases. Trans. GIS 2010, 14, 283–297. [Google Scholar] [CrossRef]
- Weiser, P.; Frank, A.U. Dynamic GIS–The final frontier. In Extended Abstract; GI-Forum: Salzburg, Austria, 2010. [Google Scholar]
- Christakos, G.; Bogaert, P.; Serre, M. Temporal GIS: Advanced Functions for Field-Based Applications; Springer Science & Business Media: Berlin, Germany, 2012. [Google Scholar]
- Ahlqvist, O. A parameterized representation of uncertain conceptual spaces. Trans. GIS 2004, 8, 493–514. [Google Scholar] [CrossRef]
- Comber, A.; Kuhn, W. Fuzzy difference and data primitives: A transparent approach for supporting different definitions of forest in the context of REDD+. Geogr. Helv. 2018, 73, 151–163. [Google Scholar] [CrossRef] [Green Version]
- Buzar, S.; Ogden, P.E.; Hall, R. Households matter: The quiet demography of urban transformation. Prog. Hum. Geogr. 2005, 29, 413–436. [Google Scholar] [CrossRef]
- Glass, R. Introduction: Aspects of Change in Centre for Urban Studies; Mac Gibbon: London, UK, 1964. [Google Scholar]
- Lees, L.; Shin, H.B.; López-Morales, E. Planetary Gentrification; John Wiley & Sons: Hoboken, NJ, USA, 2016. [Google Scholar]
- Ley, D.; Yang, Q. Global gentrifications: Uneven development and displacement; and planetary gentrification. AAG Rev. Books 2017, 5, 112–115. [Google Scholar] [CrossRef] [Green Version]
- Smith, N.; Williams, P. Alternatives to orthodoxy: Invitation to a debate. In Gentrification of the City; Routledge: London, UK, 1986; pp. 1–10. [Google Scholar]
- Glaeser, E.L.; Kim, H.; Luca, M. Nowcasting gentrification: Using yelp data to quantify neighborhood change. AEA Pap. Proc. 2018, 108, 77–82. [Google Scholar] [CrossRef] [Green Version]
- Chapple, K.; Zuk, M. Forewarned: The use of neighborhood early warning systems for gentrification and displacement. Cityscape 2016, 18, 109–130. [Google Scholar]
- Gibbons, J.; Barton, M.; Brault, E. Evaluating gentrification’s relation to neighborhood and city health. PLoS ONE 2018, 13, e0207432. [Google Scholar] [CrossRef] [Green Version]
- Lees, L.; Slater, T.; Wyly, E.K. The Gentrification Reader; Routledge: London, UK, 2010; Volume 1. [Google Scholar]
- Modai-Snir, T.; van Ham, M. Structural and exchange components in processes of neighbourhood change: A social mobility approach. Appl. Spat. Anal. Policy 2019, 12, 423–443. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Atkinson, R. Measuring gentrification and displacement in Greater London. Urban Stud. 2000, 37, 149–165. [Google Scholar] [CrossRef]
- Brummet, Q.; Reed, D. The Effects of Gentrification on the Well-Being and Opportunity of Original Resident Adults and Children 2019. FRB of Philadelphia Working Paper No. 19-30. Available online: http://dx.doi.org/10.21799/frbp.wp.2019.30 (accessed on 4 April 2021).
- Atkinson, R.; Wulff, M.; Reynolds, M.; Spinney, A. Gentrification and displacement: The household impacts of neighbourhood change. AHURI Final. Rep. 2011, 160, 1–89. [Google Scholar]
- Ilic, L.; Sawada, M.; Zarzelli, A. Deep mapping gentrification in a large Canadian city using deep learning and Google Street View. PLoS ONE 2019, 14, e0212814. [Google Scholar] [CrossRef]
- Barton, M. An exploration of the importance of the strategy used to identify gentrification. Urban Stud. 2016, 53, 92–111. [Google Scholar] [CrossRef]
- Reades, J.; De Souza, J.; Hubbard, P. Understanding urban gentrification through machine learning. Urban Stud. 2019, 56, 922–942. [Google Scholar] [CrossRef] [Green Version]
- Xu, R.; Lin, H.; Lü, Y.; Luo, Y.; Ren, Y.; Comber, A. A modified change vector approach for quantifying land cover change. Remote. Sens. 2018, 10, 1578. [Google Scholar] [CrossRef] [Green Version]
- Tewkesbury, A.P.; Comber, A.J.; Tate, N.J.; Lamb, A.; Fisher, P.F. A critical synthesis of remotely sensed optical image change detection techniques. Remote. Sens. Environ. 2015, 160, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Martin, D. 2001 Census output areas: From concept to prototype. Trends 1998, 94, 19–24. [Google Scholar]
- Leutner, B.; Horning, N.; Schwalb-Willmann, J.; Hijmans, R. RStoolbox: Tools for Remote Sensing Data Analysis. R Package Version 0.1. 2017. Available online: https://www.researchgate.net/publication/312456069_RStoolbox_Tools_for_Remote_Sensing_Data_Analysis (accessed on 4 April 2021).
- Massey, D.S.; Denton, N.A. The dimensions of residential segregation. Soc. Forces 1988, 67, 281–315. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Process | Characteristics | Data Primitives |
|---|---|---|
| Gentrification | Upward transition of neighbourhood by the influx of residents of higher income and education. | House price (increase) Education level (increase) Income inequality (increase) Migration churn (increase) Professional occupation (increase) |
| Rural flight | Rural-to-urban migration. Resulting from the industrialisation of agriculture. Exacerbated with the loss of rural services. | Low skilled occupation (decrease) Business vacancy rates (increase) |
| Urban sprawl | The unrestricted growth of urban areas with little regard for urban planning, generally on the urban fringe. Rapid expansion of the geographical extent of cities and towns. | Population density (increase) Business vacancy rates (decrease) |
| Displacement | Displacing low-income residents from gentrifying urban developments. Reduced security in tenure, employment opportunities and spending power. | Housing affordability (decrease) Low-skilled occupation (decrease) Income inequality (increase) Migration churn (increase) |
| Counter-urbanisation | Urban-to-rural migration. Can occur as a reaction to inner-city deprivation. In Europe, it involves de-concentration of one area to another that is beyond suburbanisation. | Income inequality (increase) Population density (decrease) Population flux (out) Unemployment (increase) |
| Suburbanisation | Urban-to-suburban migration. Can result in suburban sprawl, where low-density peripheral urban areas grow, as households and businesses move out of urban centres. | Population density (decrease) Population flux (out) Business vacancy rates (decrease) |
| White flight | Sudden or gradual large-scale migration of white people to more racially homogeneous suburban regions. | Ethnic minorities (increase) White ethnicity (decrease) Population density (decrease) |
| Urban decay | Downward transition of a neighbourhood, or parts of it, into disrepair by several interacting processes such as deindustrialisation and counter-urbanisation. Features increased poverty, fragmented families and low overall living standards and quality of life. | Unemployment (increase) Low-skilled occupation (decrease) Poor health (increase) Income inequality (increase) House price (decrease) |
| Deindustrialisation | The removal or reduction of industrial activity. Long-term decline in the output of manufactured goods or in employment in the manufacturing sector, shifting to the services sector. | Low skilled occupation (decrease) Unemployment (increase) |
| Municipal disinvestment | Urban planning process of abandonment, typically the poorest communities. Tends to fall along racial and class lines, perpetuating the cycle of poverty, since affluent individuals have greater social mobility. | Ethnic minorities (increase) Income inequality (increase) |
| Shrinking cities | Notable in the U.S. Dense cities experience notable population loss, often due to emigration. Cities that focus on one branch of economic growth are vulnerable. | Population density (decrease) Low-skilled occupation (decrease) Unemployment (increase) |
| Neighbourhood churn | The influx and outflux of residents such that the social character remains the same, but population turnover is high. | Population flux (in) Population flux (out) |
| International migration | The immigration of people from foreign countries. They tend to locate to the deprived inner-city where costs are lower and locate to established cultural neighbourhoods. | Population flux (in) Ethnic minorities (increase) Housing affordability (increase) |
| Acronym | Description | Source |
|---|---|---|
| POPD | Population density (people per 1 km) | Derived from census areas and population data |
| WBR | Proportion white British | From the Consumer Data Research Centre (CDRC) (see https://www.cdrc.ac.uk, accessed on 18 January 2021) |
| HAFF | Housing affordability | From the Office of National Statistics (ONS) (see https://www.ons.gov.uk, accessed on 3 November 2011) |
| HP | Average house price (in 1000 GBP) | From ONS (link above) |
| POP | Population total | From ONS (link above) |
| DLA | Proportion receiving disability living allowance | From StatXplore (see https://stat-xplore.dwp.gov.uk/, accessed on 10 April 2021) |
| CHN | Proportion of households that have changed | From the CDRC Residential Mobility Index (link above) |
| PROF | Proportion in professional occupations | From the ONS Standard Industrial Classification (link above) |
| UNEMP | Proportion unemployed | From StatXplore (as above) |
| Primitive | E01013812 | E01013924 | E01013943 | E01013973 |
|---|---|---|---|---|
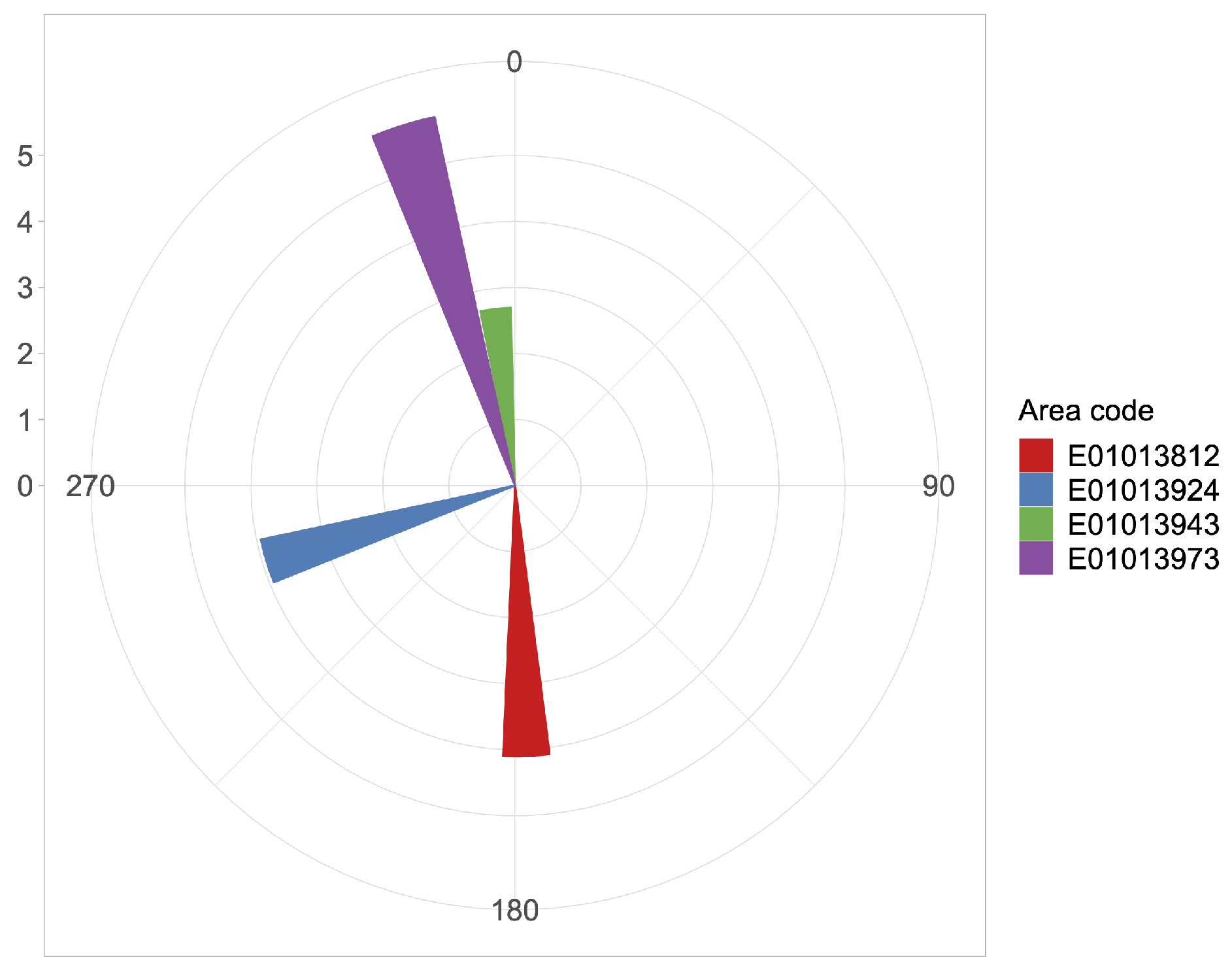
| angle | 177.58 | 253.083 | 353.713 | 342.747 |
| magnitude | 4.101 | 3.935 | 2.692 | 5.711 |
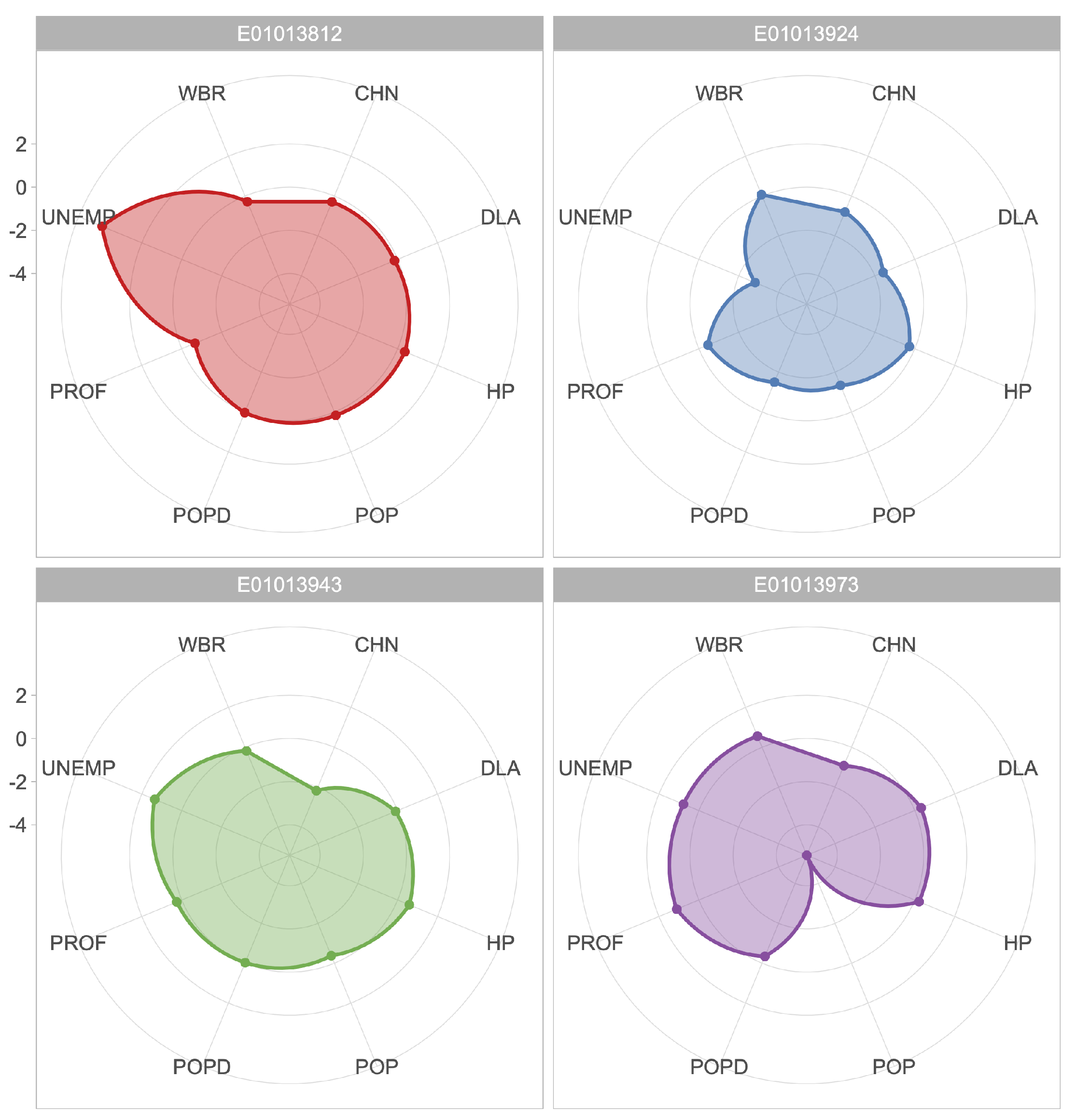
| POPD | 0.028 | −1.497 | −0.027 | −0.345 |
| PROF | −0.666 | −0.455 | 0.247 | 1.109 |
| WBR | −0.284 | 0.071 | −0.185 | 0.561 |
| HAFF | 0.294 | 0.294 | 0.294 | 0.294 |
| HP | 0.362 | −0.266 | 0.585 | 0.211 |
| POP | 0.167 | −1.335 | −0.377 | −5.411 |
| DLA | −0.159 | −1.586 | −0.105 | 0.319 |
| CHN | −0.292 | −0.797 | −2.178 | −0.924 |
| UNEMP | 3.992 | −2.819 | 1.352 | 0.766 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gray, J.; Buckner, L.; Comber, A. Extending Geodemographics Using Data Primitives: A Review and a Methodological Proposal. ISPRS Int. J. Geo-Inf. 2021, 10, 386. https://doi.org/10.3390/ijgi10060386
Gray J, Buckner L, Comber A. Extending Geodemographics Using Data Primitives: A Review and a Methodological Proposal. ISPRS International Journal of Geo-Information. 2021; 10(6):386. https://doi.org/10.3390/ijgi10060386
Chicago/Turabian StyleGray, Jennie, Lisa Buckner, and Alexis Comber. 2021. "Extending Geodemographics Using Data Primitives: A Review and a Methodological Proposal" ISPRS International Journal of Geo-Information 10, no. 6: 386. https://doi.org/10.3390/ijgi10060386