1. Introduction
In recent years, the increasing occurrence of wildfires across Europe (and all over the world) served as a warning that a better management of the forest is needed. An optimised forest management process will enable to reduce the losses during the fires events. Forest represents up to 38% of the total land surface of the European Union countries [
1], making this a very relevant societal and ecological issue.
Over the years, the scientific community has been proposing several works aiming at better forest monitoring and care by means of imagery methods. Some are to prevent and detect diseases in forest trees using Deep Learning (DL) and Unmanned Aerial Vehicle (UAV) imagery [
2,
3,
4] or satellite high-resolution imagery [
5]. The use of UAVs as a remote sensing platform is also a common way of detecting dead trees individually [
6] or in clusters [
7], as this can help prevent the occurrence of wildfires. The early detection of wildfires can help prevent their progress over forest lands, hence reducing their ecological and societal impact. Other ways of detecting forest fires are about segmentation of burned areas in UAV images [
8], flame detection [
9,
10,
11], flame segmentation [
12,
13,
14,
15] or smoke detection [
16] with DL in terrestrial and aerial images. These works can enable an early alert to firefighters about the appearance of a possible forest fire, thus increasing forest protection and, consequently, forest monitoring. From UAVs to terrestrial vehicles, the monitoring of the forest areas and forest inventory can be improved with the help of robotics with advanced intelligent perception systems.
The use of robotics in forestry has made slow progress mostly due to some inherent problems that exist in forests: variations of temperature and humidity, steep slope and harsh terrains, and the general complexity of such environment with high probability of appearing wild animals and several obstacles, such as boulders, bushes, holes and fallen trees [
17]. Nevertheless, some terrestrial [
18,
19,
20,
21] and aerial [
22,
23,
24] robotic platforms have been developed that can contribute to improve forest protection and monitoring. However, there are terrain-independent aspects that can compromise the performance of a robot in a forest such as the absence of good communication means, since Global Navigation Satellite System (GNSS) and internet connection, in general, do not work well enough in this domain [
25]. Hence, advanced perception solutions are needed to make robots capable of working under such difficult conditions.
Robotic visual perception in forestry contexts is a topic that has been developing within the scientific community and plays an important role in the way robots perceive the world. Back in 2011, a work about 3D log (a tree trunk that was cut off) recognition and respective pose estimation for log grasping operations was proposed [
26]. By means of a structured light camera, the authors were capable of extracting 3D information about the logs and, after some 3D segmentation steps and an extrinsic calibration, they reconstructed the logs and estimated their respective poses. The authors concluded that the reconstruction errors increased exponentially relatively to the distance to the logs, and that best results were obtained under 3 m. Another work where the authors proposed the 3D detection of tree trunks by means of cameras (in this case a stereo-pair) was presented in [
27]. Here, a DL-based 3D object detector was trained on point clouds of tree trunks acquired with a ZED Stereo 2 camera. The authors concluded that their 3D recognition system was capable of accurately detecting tree trunks at ranges up to 7 m. Although 3D information about the surroundings is important for robots for mapping and navigation purposes, the go-to way of handling the data provided by cameras is 2D. More recently, some works have been published about tree trunks detection in images (in 2D): some detected tree trunks in street images [
28,
29], others focused on detecting tree trunks in forest contexts [
30], while others detected stumps in harvested forest areas [
31]. In [
32], instead of only detecting logs, it was aimed at the detection and segmentation of logs for grasping operations. For that, they trained and tested several DL-based object segmentation methods, and they concluded that such perception methods and systems can be used as an assistance tool for operators or even for fully autonomous operations in the forestry domain.
Even though some advances have been made in recent years regarding robotic visual perception, more work needs to be completed in order to attain safer and smarter robotic systems to work in forests semi or fully autonomously. With this in mind, this work produced a study and a use case about forest tree trunks detection and mapping, using Edge Artificial Intelligence (AI), to support monitoring operations in forests. Edge AI approaches are important for robotics in general, since it allows running DL-based models and algorithms on specific hardware devices that can be placed on the robot itself. So, instead of running these models on self-managed servers or using a cloud service (which always account with some additional communication latency), the models can be run locally, hence improving performance, in terms of speed, of the robotics tasks that rely on them.
This work contributes to the knowledge domain with three contributions:
Public dataset of forest images fully annotated;
Benchmark between four different edge-computing hardware and 13 DL models;
Use case of tree trunks mapping using one DL model combined with an AI-enabled vision device.
This article is structured as follows:
Section 2 reviews the state-of-the-art of cutting-edge DL models that were used in this work,
Section 3 presents the dataset built in this study, shows some details about the edge-devices used to test the object detection models and specifies the training and testing conditions of the DL models.
Section 4 presents the obtained testing results in terms of tree trunks detection precision, inference time and the accuracy of tree trunks mapping.
Section 5 discusses the obtained results, and
Section 6 ends this paper presenting the main conclusions and future work.
2. Deep Learning-Based Object Detection Methods
This section presents the DL models that were used in this work to detect forest tree trunks. The DL methods that were used are the following: Single-Shot Detector (SSD) [
33] combined with MobileNet V1 [
34], MobileNet V2 [
35] and MobileNet V3 (Small and Large) [
36], three light versions of EfficientDet [
37], a tiny version of YOLOv4 [
38], two light versions of YOLOv5 (
https://doi.org/10.5281/zenodo.3908559, accessed on 26 July 2022), a tiny version of YOLOv7 [
39], a combination of Cross Stage Partial network (CSP) [
40] with YOLOR [
41], and a Vision Transformer-based detector called DETR [
42].
Single Shot Detector (SSD) [
33] is an object detector that generates a set of candidate bounding boxes with different scales and aspect ratios. At prediction time, the bounding boxes are scored considering whether an object is present within the box or not. In the affirmative case, the box is adjusted to better fit the object.
MobileNets [
34] are very light and efficient neural network models created for embedded and mobile applications. They are formed by depth-wise separable convolutions that make the model smaller and computationally lighter. In addition, two hyper-parameters were implemented which, when tweaked, allow to improve the accuracy and/or speed of the model. The second version of MobileNets (MobileNet V2) [
35] appeared in 2019 and brought some improvements regarding inference speed and model’s size comparatively with the previous version. Such improvements were enabled by the implementation of inverted residuals and linear bottlenecks. The third and last version of MobileNets (MobileNet V3) [
36] was published in late 2019, and it was designed for mobile phones applications. This was achieved by combining a hardware-aware network architecture search with a method that takes the best found architecture and fine-tunes the same until a certain speed is attained. From this work, two variations of MobileNet V3 appeared: a smaller and a larger one. In general, MobileNet V3 Small is faster and Mobilenet V3 Large is more accurate than MobileNet V1 and V2.
EfficientDets [
37] are a family of object detectors that are more efficient and less computationally expensive that prior state-of-the-art detectors. The major improvements made with these detectors are the implementation of a weighted bi-directional feature pyramid network responsible for a fast multi-scale fusion of features, and a method that uniformly scales the depth, width and resolution for all architecture compounds at the same time.
You Only Look Once (YOLO) [
43] is a single-stage object detection network that predicts and scores bounding boxes in one run from full images. YOLO divides the input image into a grid of cells, and for each cell, it predicts bounding boxes, their confidences and associated class likelihoods. YOLO proved to be a reliable real-time object detector achieving processing frequencies of 45 Hz and 155 Hz with its base and smaller models, respectively, while gathering competitive accuracy results with less than real-time detectors. The second [
44] and third [
45] versions of YOLO (YOLOv2 and YOLOv3) suffered some architecture tweaks that brought improvements for the model in terms of accuracy and speed, outperforming state-of-the-art models at that time, such as SSD. The fourth version of YOLO (YOLOv4) [
38] was published in 2020, and the major changes were about the use of new features to attempt improve YOLO. Such features include weighted residual connections, cross-stage partial connections, cross-mini-batch normalisation, self-adversarial training and mish activation. At that time, YOLOv4 was the fastest and more accurate real-time object detector, achieving twice the speed of EfficientDet while keeping a comparable accuracy. YOLOv4 also improved YOLOv3’s precision and speed by 10% and 12%, respectively.
Since YOLOv4, three new versions of YOLO series have appeared. YOLOv5 is the fifth version of YOLO and is considered to be “non-official” by the community. The authors claimed that YOLOv5 achieved better detection and speed performance than previous YOLO versions and other detectors, but they did not provide a real comparison, for instance, with YOLOv4. YOLOv6 [
46] corresponds to the YOLO version and was designed to be mainly applied to industrial applications. The more recent new version of YOLO is YOLOv7 [
39]. This seventh version is currently the best object detector, surpassing all known state-of-the-art detectors with the highest average precision of 56.8% on the MS COCO dataset [
47] and with inference times ranging from 6 up to 200 ms. The authors of [
39] contributed to this model with a bag-of-freebies approach to tackle two issues that appeared along the way: replacement of the re-parameterised module and the allocation of dynamic label assignment.
You Only Learn One Representation (YOLOR) [
41] is a network that is inspired in the way human experience is learned. In fact, in [
41], the authors presented a detector that can encode implicit knowledge (the model learns subconsciously) and explicit knowledge (the model learns from input data), similarly to the human brain that can learn in an explicit (from experience) and implicit way.
DEtection TRansformer (DETR) [
42] is an object detector that is based on a Vision Transformer (ViT) [
48]. Transformers were recently introduced to tackle Computer Vision (CV) tasks, as they were the standard architecture for natural language processing tasks. ViTs (the transformers applied in vision) attained also great results recognising images compared to the standard Convolutional Neural Networks (CNN) [
48] and at the same time needing fewer resources during training. DETR is also based on the transformer architecture, but its main goal is to detect objects in images rather than classify the images. DETR showed comparable results with other detectors, especially with large objects; regarding small objects, the authors claim that it is a challenge to train, optimise and detect these objects.
3. Materials and Methods
This section details the image acquisition process (cameras and platforms that were used to acquire the data), presents the post-processing that was made on the images (data labelling, augmentation operations and pre-train dataset splitting), shows the training environment, model configurations and conversions, and presents the trunk detection evaluation metrics used and the experiments that were performed in this work.
3.1. Image Acquisition Process
The dataset used in this work corresponds to a new version of the dataset presented in [
49], with more than 2000 new images and annotations. The images that were added were from a Robot Operating System (ROS) bag dataset presented in [
50]. The image dataset was acquired in three different regions of Portugal: Lobão (41°11′22.09″ N, 8°29′55.54″ W), Vila do Conde (41°21′14.22″ N, 8°44′30.66″ W) and Valongo (40°59′05.10″ N, 8°29′17.41″ W). In these regions, eucalyptus and pinus are the predominant tree species. In each forestry area, video footage was captured using five different cameras: FLIR M232 (
https://www.flir.eu/products/m232, accessed on 26 July 2022), ZED Stereo (
https://www.stereolabs.com/zed, accessed on 26 July 2022), Allied Mako G-125 (
https://www.alliedvision.com/en/camera-selector/detail/mako/G-125, accessed on 26 July 2022), OAK-D (
https://store.opencv.ai/products/oak-d, accessed on 26 July 2022), and GoPro Hero6 (
https://gopro.com/en/gb/update/hero6, accessed on 26 July 2022). Only GoPro was transported by hand during image recording process; the other cameras were mounted on ground robotic vehicles. OAK-D was the only camera that was placed facing sideways; the others were placed pointing towards the front.
The images were extracted from the videos using a sub-sampling methodology and were filtered according to the presence of any defects on them, such as blur or incandescence caused by the sun. The result was a total of 5325 images belonging to different cameras and spectra (visible and thermal images).
Table 1 presents some features of the images that are part of the original dataset. Compared to the previous version, this dataset has 2430 more images which were all recorded in Valongo with three of the five cameras: ZED (640 images), FLIR (940 thermal images), and OAK-D (850 images). This new dataset was made publicly available (
https://doi.org/10.5281/zenodo.7186052, accessed on 11 October 2022).
3.2. Data Labelling, Augmentation and Splitting
After acquiring images from the forestry areas, those images were labelled using Computer Vision Annotation Tool (CVAT) (
https://github.com/opencv/cvat, accessed on 26 July 2022) with the Pascal Visual Object Classes format [
51]. All images and their labels from the original dataset went through nine augmentation processes, resulting in each original image being transformed into nine new versions—the nine augmentation operations are explained in
Table 2. Dataset augmentation is an important step and must be taken because training DL models require large amounts of data in order to achieve a good performance in unseen data; missing this step could compromise the accuracy of the models. In the end of the augmentation processes, the size of the augmented dataset was about 53,250 images (
). However, images without any label (absence of trunks) were discarded. So, the final size of the augmented dataset was actually 49,608 images (3642 images were removed).
Before using the augmented dataset for DL training, the same was split into three subsets: training, validation and testing. The ratios that were used to perform this division were 70% for training, 10% for validation and 20% for testing, so 34,723 images, 4964 images and 9910 images for the train, validation and test sets, respectively. From the test set, two different subsets were considered for testing the DL models: one is made by augmented images and corresponds to 100% of the test set, the other is made by only original (non-augmented) images which comprises 10% of the test set.
3.3. Configuration, Training and Conversion of Deep Learning-Based Object Detection Models
The DL models that were chosen for the task at hand were: SSD MobileNet V1, SSD MobileNet V2, SSD MobileNet V3 Small, SSD MobileNet V3 Large, EfficientDet Lite0, EfficientDet Lite1, EfficientDet Lite2, YOLOv4 Tiny, YOLOv5 Nano, YOLOv5 Small, YOLOv7 Tiny, YOLOR-CSP and DETR-ResNet50. In terms of network architecture, YOLOv4 Tiny was the only model that suffered a minor change, regarding its activation function that originally was Leaky Rectified Linear Unit (ReLU), and we changed it to ReLU.
All models were trained using an NVIDIA GeForce 3090 Graphics Processing Unit (GPU) with 32 GygaByte (GB) of available memory and a compute capability of
floating point Operations Per Second (OPS). A transfer learning approach was taken to train the DL models, and their training parameters are defined in
Table 3. The learning rate and input resolution were kept default, the batch size was selected according to the GPU memory and the training epochs were chosen in a way that all models’ training loss curves converged with a variation of less than 5%. A relevant aspect to be mentioned is that the input resolution of DETR-ResNet50 can vary between 800 and 1333 pixels in width and height [
42]. So, the resolution (indicated with “*” in
Table 3) is in fact the maximum input resolution the model can have during training.
After training, 10 models were quantised (weights of 8-bit integer) with success and were converted to run on Coral USB Accelerator’s Tensor Processing Unit (TPU) (
https://coral.ai/products/accelerator, accessed on 26 July 2022): SSD-based models were quantised using Quantisation-Aware Training, and EfficientDet Lite models, YOLOv4 Tiny and YOLOv5 models were quantised using Post-Training Quantisation. In order for a model to be fully supported on the TPU, its operations must be supported by the TPU; otherwise, such operations will be run on the Central Processing Unit (CPU) instead on the TPU. So,
Table 4 shows the number of supported and unsupported operations and the respective ratio in percentage. It is important to mention that we had to reduce the input resolution of YOLOv5 models to a maximum of 448 × 448 pixels to enable their successful conversion for the TPU.
3.4. Tree Trunks Detection Evaluation, Tree Trunks Mapping and Research Experiments
In this section, the evaluation metrics and edge-devices that were used to perform tree trunks detection are presented. Additionally, the tree trunk mapping algorithm and the research experiments that were conducted in this work are detailed.
3.4.1. Evaluation Metrics and Devices
The models evaluation was made by running inference on the test subset (defined in
Section 3.2). Then, the detections outputted from the models were filtered using Non-Maximum Suppression (NMS) with 10% and 60% confidence thresholds and the overlapping threshold, respectively. This way, only detections with confidence above 10% were considered. The metric that was chosen to evaluate accuracy-wise the models was the F1 score, as this metric allows to maximise, at the same time, two well-known metrics in this domain: Precision (measures the detections that are objects) and Recall (measures the objects that are detected).
In addition to evaluating the models in terms of detection accuracy, they were also evaluated in terms of inference time in four different edge-devices, which are presented in
Table 5. The NVIDIA GeForce RTX 3090 GPU served as the baseline for the other devices, and the Intel Movidius Myriad X Visual Processing Unit (VPU) of OAK-D was used to deploy some models to perform real-time tree trunks mapping. The lower the inference time of the models, the more likely the models are to perform tasks in real-time.
3.4.2. Tree Trunk Mapping Algorithm
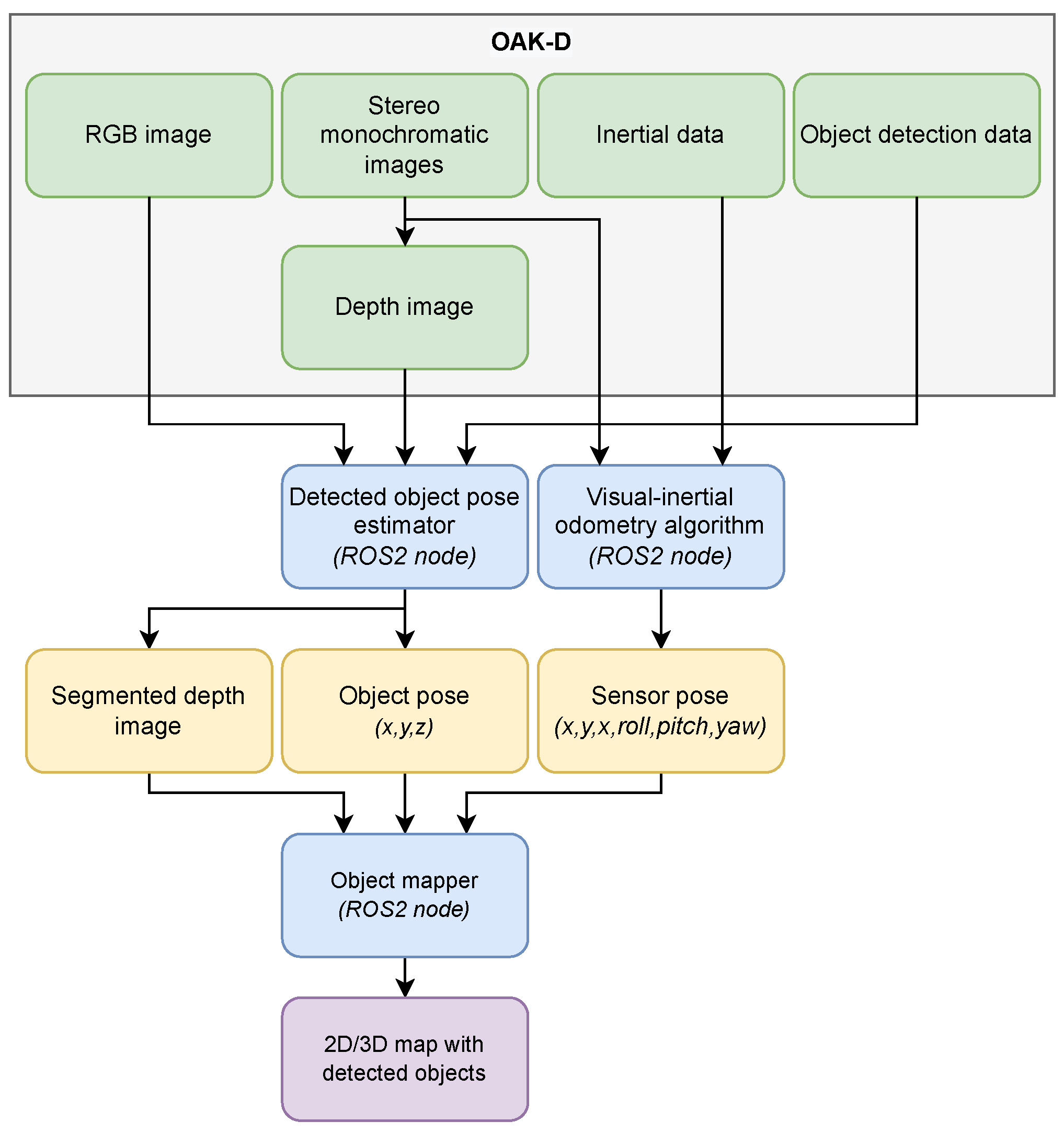
The tree trunk mapping algorithm receives data from an OAK-D perception device, which is shown in
Figure 1. This sensing device has an embedded inertial measurement device, one colour camera (at the body centre) and two monochromatic cameras that form a stereo-vision pair for depth processing. Additionally, the OAK-D has a VPU responsible for running the object detection neural network to detect the tree trunks.
The tree trunk algorithm is summarised by
Figure 2. The algorithm starts by receiving the detections made with the centred colour camera which are aligned with the depth images. This way, it is possible to know almost exactly (because depth computation by means of stereo vision has inherent errors) the distance to the detected objects. With such detections, we masked the bounding boxes on the respective depth images, and through a depth thresholding step on the centre point of each bounding box, the objects are segmented. The trunk mapping is made by means of a visual–inertial odometry method (OpenVINS [
52]) that uses the stereo images and the inertial data of OAK-D to give an estimation of the six Degrees of Freedom (DoF) relative pose of the device. The final result is a 2D/3D map with the detected tree trunks. An important aspect to be highlighted is that all raw data are processed and made available only by OAK-D.
3.4.3. Tree Trunk Detection Experiments
The experiments conducted in this work were:
Original test subset vs. augmented test subset;
Non-quantised vs. quantised weights;
Decrease of input resolutions for YOLOv5, YOLOv7, YOLOR and DETR models;
Evolution of F1 score across several confidence levels;
Inference speed in four edge-devices;
Tree trunks mapping with an OAK-D.
Experiment
#1 is about assessing the detection accuracy of the models, using the F1 score, in the original test data subset versus in the augmented test data subset. Normally, augmentation processes are only applied to the training and/or validation datasets [
53], so we have also used augmented images in the test subset to measure the impact of their utilisation for testing DL models.
Experiment
#2 is about evaluating the detection accuracy of the quantised models, using the F1 score, compared to their non-quantised variants. Normally, the non-quantised variants of the models are more precise than the quantised ones for the same task, since the weights of the former are in floating point format and, after being quantised, are turned into a less precise floating point format (for instance, from 32-bit floating point precision to 16-bit) or event into an integer format [
54].
Experiment
#3 is about decreasing the input resolution of higher resolution models, such as YOLOv5, YOLOv7, YOLOR and DETR, in order to observe the variation of detection accuracy and also to make a fair comparison among all models, since the other models have much lower input resolutions than the four aforementioned. The input resolutions selected were 320 × 320 and 448 × 448. The first one was chosen because it was very close to the input resolution of the SSD models and EfficientDet Lite0, the second was chosen because it was close to the remaining EfficientDet Lite’s and YOLOv4’s input resolution, and also for being the maximum accepted input resolution for the TPU (as mentioned in
Section 3.3).
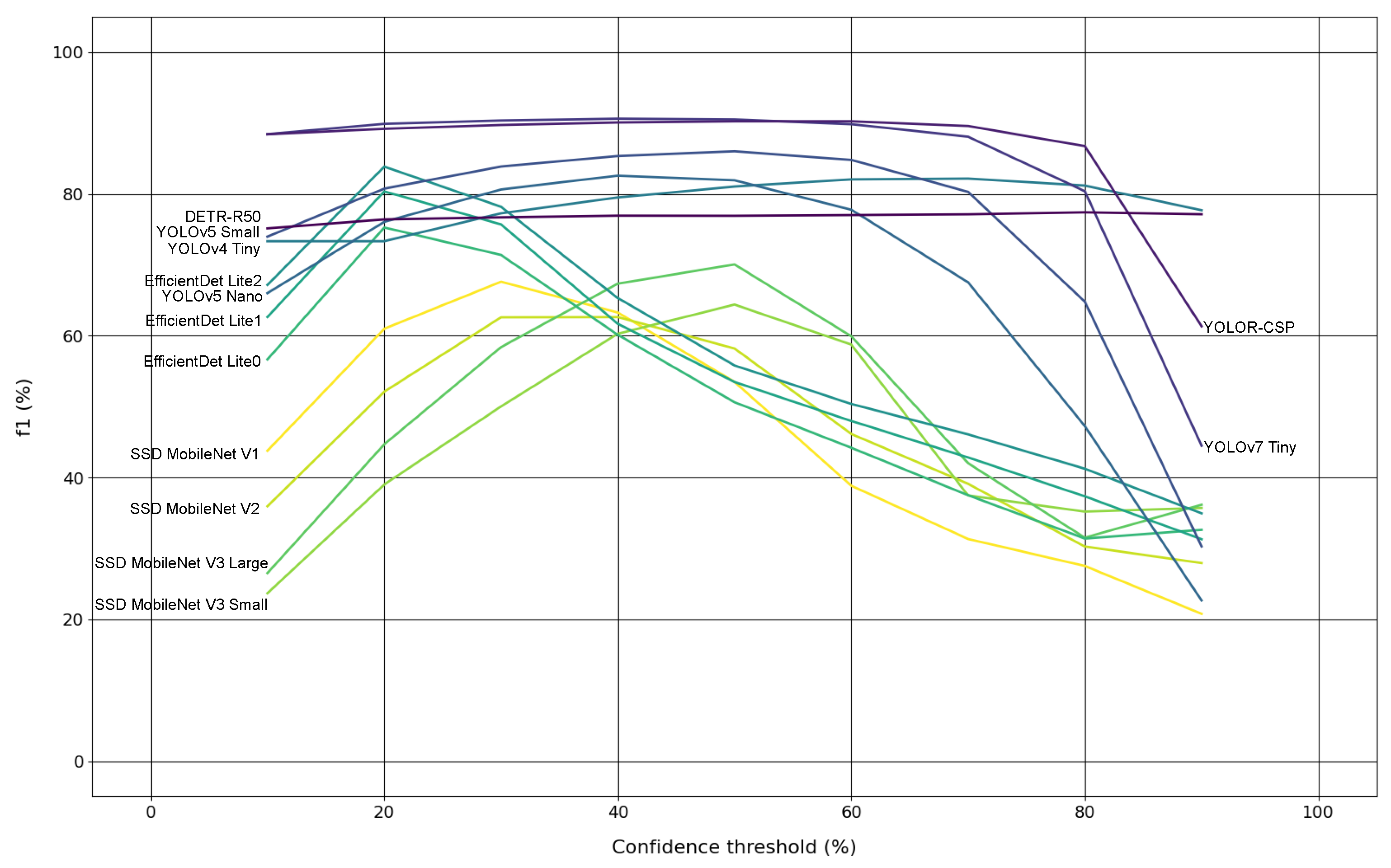
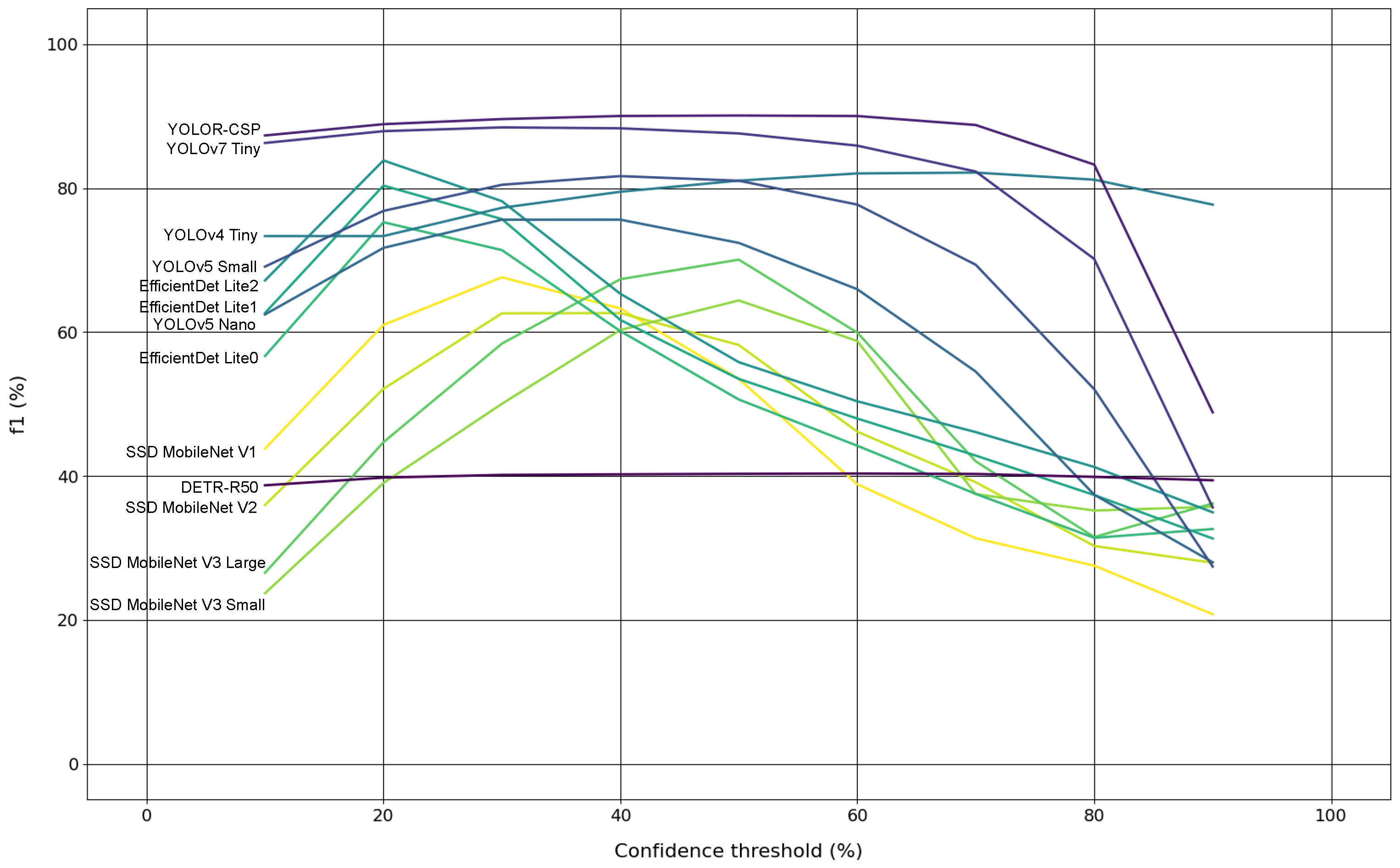
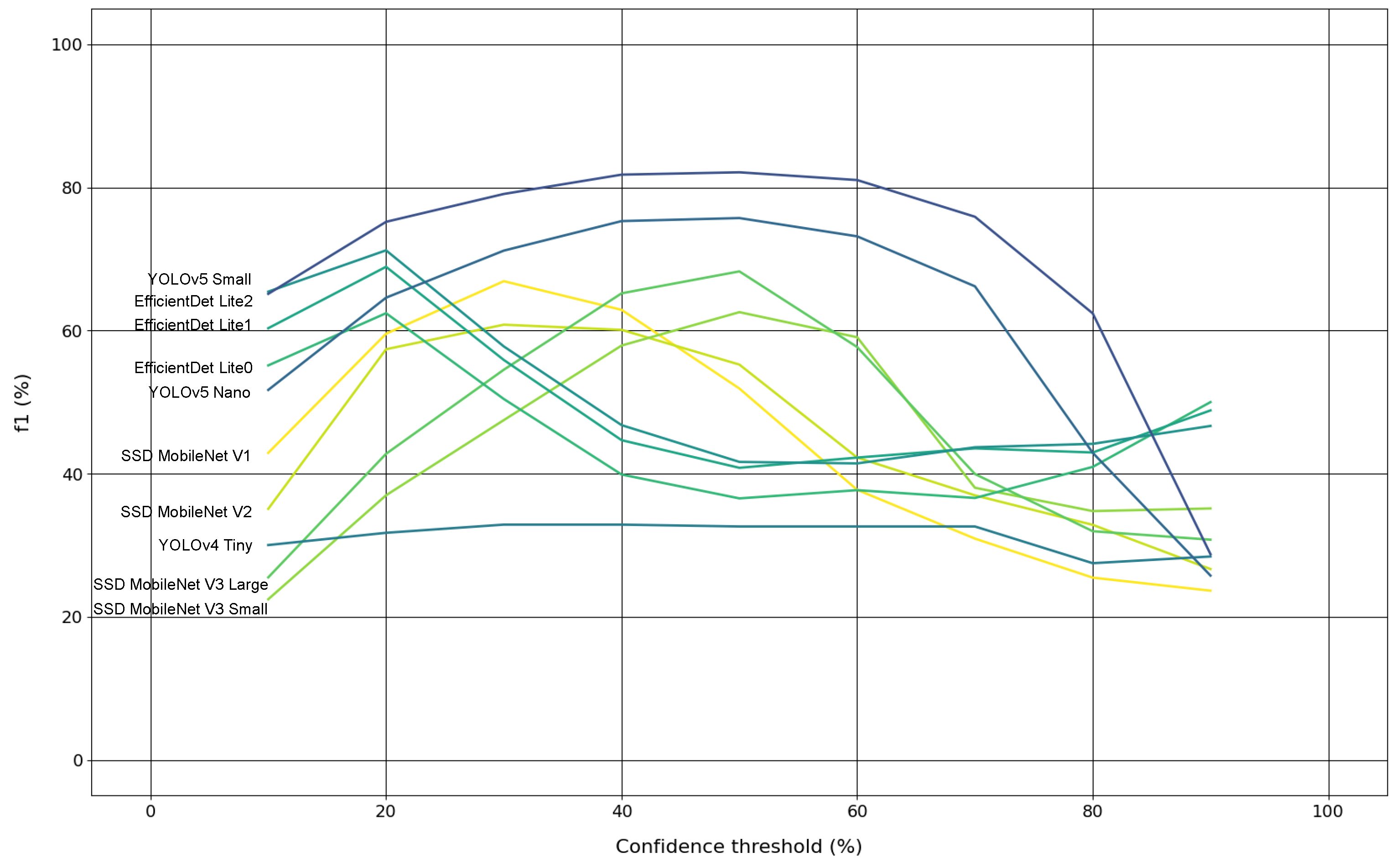
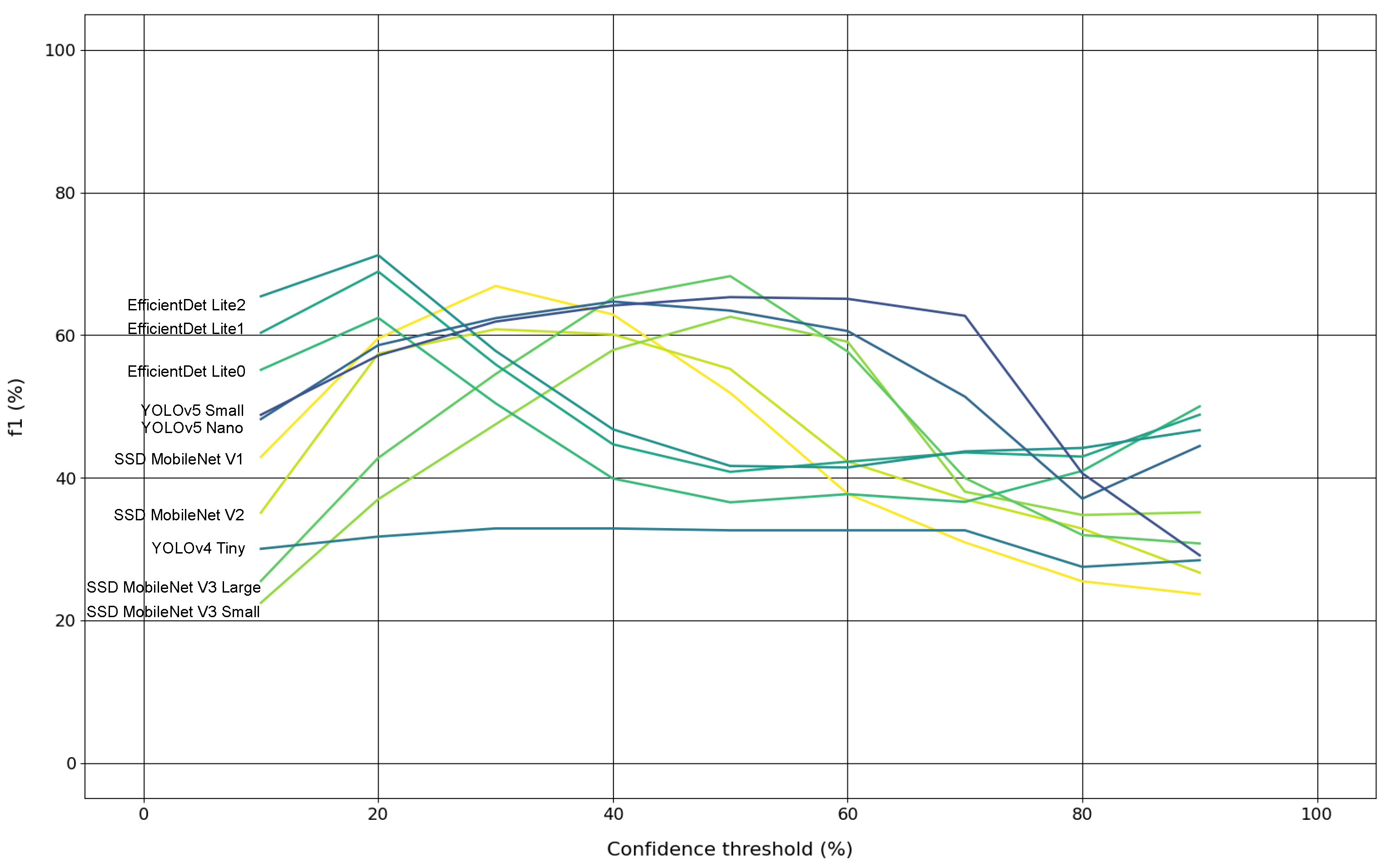
Experiment #4 is about assessing the evolution of models’ F1 scores, on the original test subset, across a confidence range from 10% to 90% with steps of 10%, producing nine confidence levels. This way, it was possible to study the most and least robust models to perform trunk detection.
Experiment
#5 is about evaluating the inference speed of the models in four different edge-devices, which are defined in
Table 5: Raspberry Pi 4B (CPU), Jetson Nano (GPU), Google Coral Accelerator (TPU), and NVIDIA GeForce RTX 3090 (GPU) that served as a baseline for inference speed assessing. For this experiment, the input resolutions considered for running YOLOv5, YOLOv7, YOLOR and DETR models on the CPU and TPU were 320 × 320 and 448 × 448, since these two are more constrained in terms of hardware and the second resolution is the maximum accepted by the TPU; hence, a fair comparison could be made with these two hardware. This experiment also allowed to study a field called Edge AI that has been gaining importance in recent years, where the AI data processing is completed at the edge rather than in the cloud. This type of approach enables the data to be processed in real-time, at high frame rates and at the location where it was collected [
55]. This approach allows one to run algorithms on that data and collect its processing results right after.
Experiment
#6 is about taking one of the 13 models, deploying it to the OAK-D edge-device (presented in the last row of
Table 5) and combining these two with a higher-level perception algorithm to map tree trunks in real-time and in a real-world context. The OAK-D was mounted on a terrestrial robotic platform as shown in
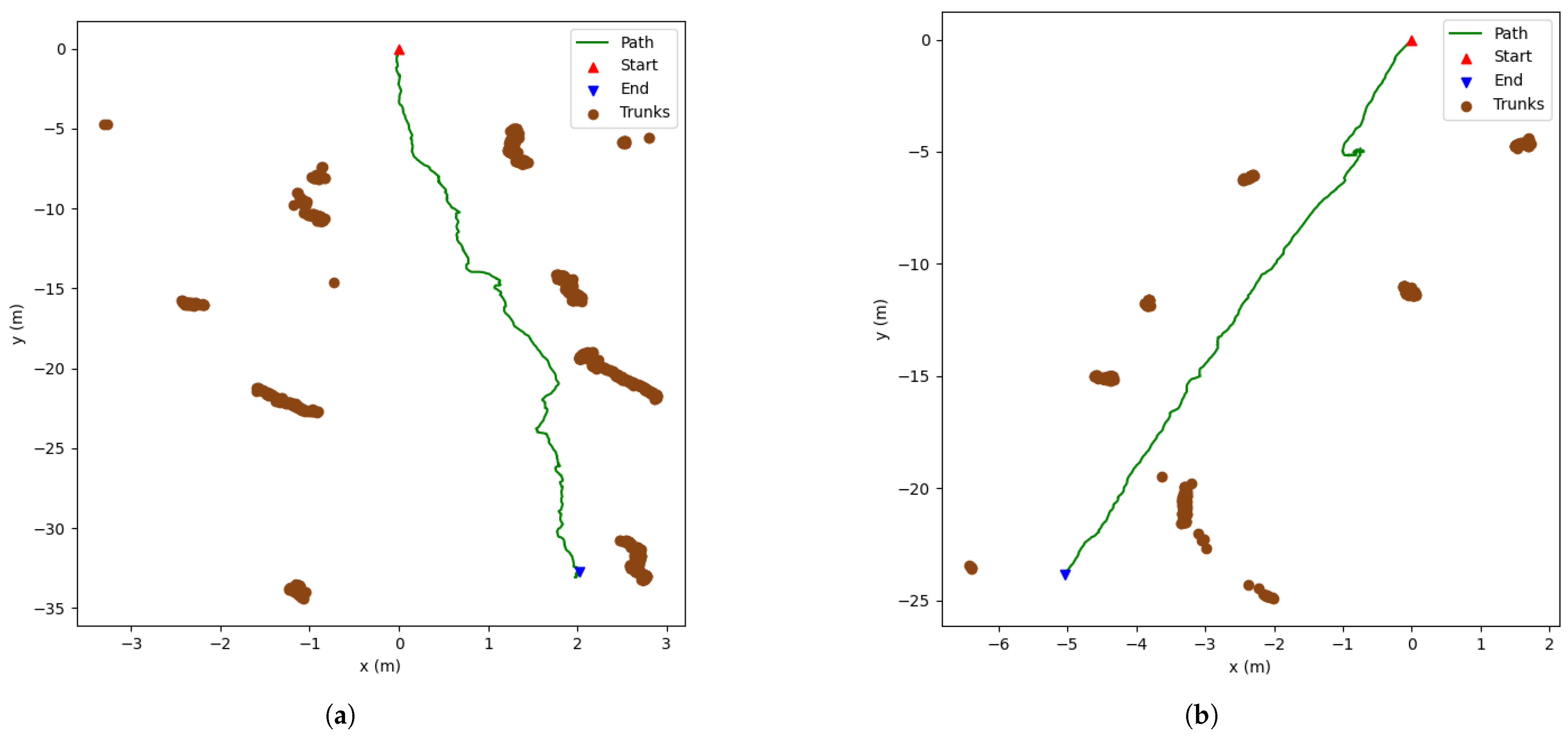
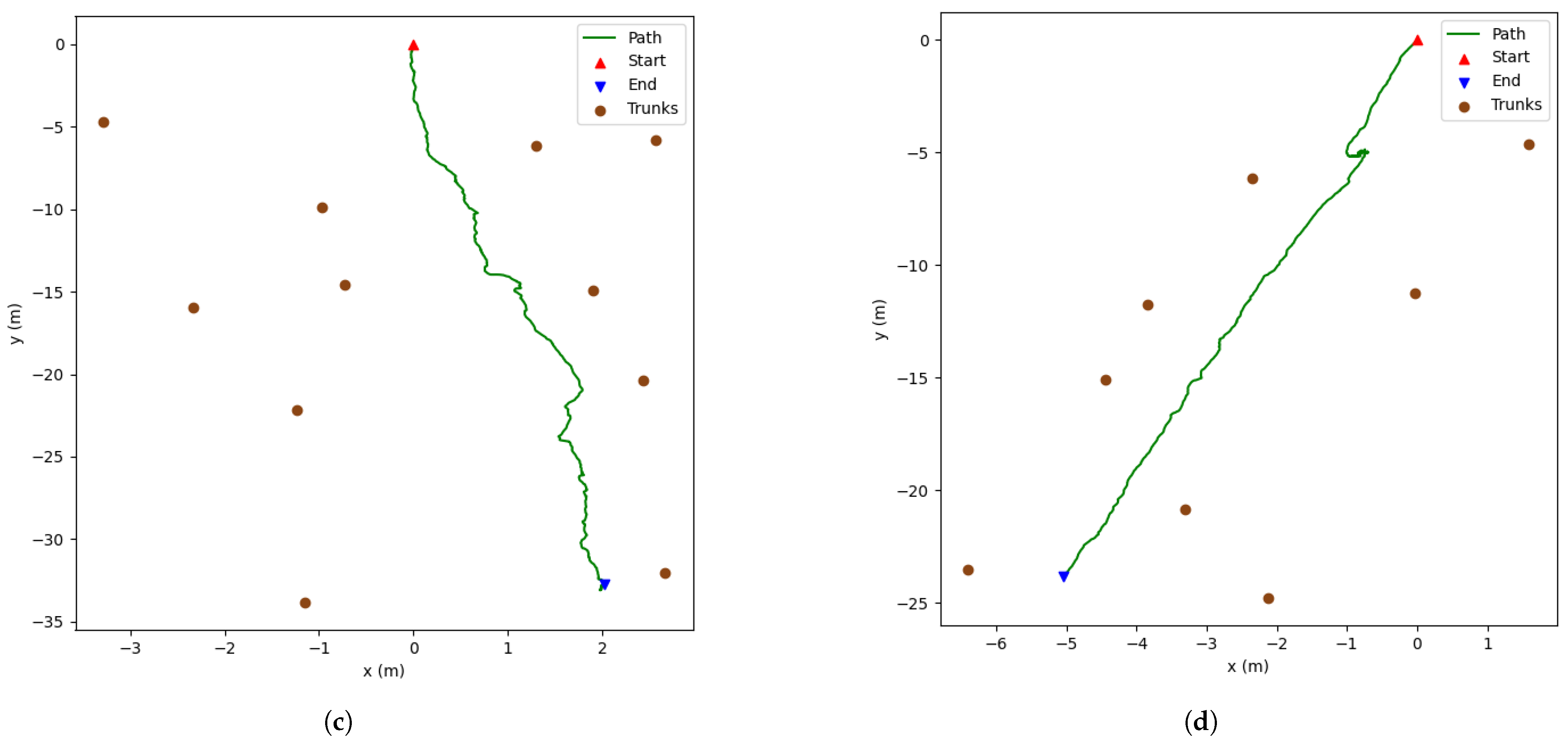
Figure 3. The robot traversed a straight line twice (round trip) in an urban area that had trees with the aim of the detecting and mapping them.
5. Discussion
This section focuses on discussing the results previously presented in
Section 4. From the experiments that were conducted, it is possible to affirm that: models evaluation with and without augmented data revealed little changes globally in detection accuracy level, with only one model (DETR) presenting an absolute difference on the F1 score metric larger than 2%; the impact of quantising the models weights, in order to produce inferences with them in low-cost hardware devices, is notorious since all quantised models have worsened their performance in terms of detection accuracy, and so it is the impact of decreasing the input resolution of some models, as they suffered a detection accuracy drop; the best two models overall, considering floating-point weights and default input resolutions, are YOLOR and YOLOv7 by this order, because they both presented similar F1 scores, but YOLOR seemed to be more robust and confident at detecting tree trunks, as can be seen in the results of the fourth experiment, more specifically in
Figure 5 and
Figure 6. The last experiment was about assessing the use of one of the models at detecting and mapping tree trunks (by means of additional algorithms); it was proven that such a task can be accomplished using only one OAK-D sensor running embedded object detection along with an object pose estimation algorithm and a sensor pose estimation algorithm.
In terms of tree trunks detection performance, this work can be compared with the one presented in [
28], as the authors assessed the detection of trees at ground level, although their images were taken from the street instead of being captured in forestry locations. Despite that, by analysing our results, it can be concluded that our models showed excellent performances, as our top two—YOLOR (640 × 640) and YOLOv7 (640 × 640)—on both the original and augmented test datasets achieved F1 scores around 90%. Considering that our models were tested on an augmented test set made of by 9910 images in forestry areas, that by itself makes the detection even more difficult due to the presence of shadows (this can be seen in
Figure 4d) and the existence of many more trees and more closer to each other than in the cities. Another important aspect to be highlighted is that even if the authors claim in [
28] that they achieved an average precision of 98% using YOLOv2 [
44] with a ResNet50 [
56], their test set only had 89 images, which is around 10 times and 100 times smaller than our original and augmented test datasets, respectively. Another work to be mentioned is the one presented in [
29]. In this work, the authors made use of a occlusion-aware R-CNN for detecting trees in street images. To assess the performance of their method, they used a metric called best miss rate, and they claimed to attain a 20.62% on that metric. In spite of their evaluation metric being different from the one we used, we strongly believe that our models achieved excellent detection results given that their test dataset is around 19 times smaller than our augmented test dataset. A similar work was produced in [
30], where the authors proposed an object detector based on YOLOv3 [
45] to detect tree trunks and telegraph/lamp posts. The authors created an original dataset composed of 812 annotated images (with 90% being trunks); then, they augmented it to obtain a 1198-image dataset, from which they picked randomly 20% of the images (198 images) to serve as the test dataset. The authors obtained the best results for an overlapping threshold of 30%, attaining an average recall rate of 90–93%, surpassing the predefined YOLOv3 architecture in best case by around 4%. Comparing to our work, besides having used a higher overlapping threshold, which makes the detection task more challenging, our augmented test dataset is much larger than theirs (around 50 times), hence proving the robustness of our models.
With respect to the tree trunk mapping, in the work proposed in [
31], the authors performed stump detection and localisation in harvested forest terrains using YOLO and a ZED2 stereo camera. In fact, their object pose estimation system is similar to ours but works at a much lower rate (6.1 Hz for detection and 5.6 Hz for localisation). In fact, they mentioned the common existence of a delay when viewing the localisation results. They did not make stump mapping over an area continuously; they simply pass discrete images to their system to detect the stumps and give their estimated localisation in those images. Another aspect to be noted is that their system relies on two separate devices: a ZED camera and a GPU-based board, called NVIDIA Jetson Xavier, in order to work properly and provide perception data in real-time. On the other hand, our system only needs one OAK-D to give inertial data, coloured and depth image data, and also object detection data, that are fed, in real-time, to higher-level algorithms. Another work that aimed at mapping trees was the one presented in [
27], where the authors also used a ZED2 stereo camera but instead of training DL algorithms to detect object in images (in 2D), they trained a 3D object detector to detect tree trunks in 3D data provided by the stereo camera. Then, they used the spatial mapping programming interface of the manufacturers of the stereo camera to map the detected trees in 3D space, and after, they applied a clustering method to extract only the trees from the 3D map.
6. Conclusions
This work aimed at researching forest tree trunks detection by means of Deep Learning models. To accomplish that, 13 DL-based object detection models were trained and tested using a new public dataset of manually annotated tree trunks composed by more than 5000 images. The models were evaluated in terms of detection accuracy and inference times in four different edge-devices. Then, one of the 13 models was picked and deployed to run inference in real-time on an OAK-D (AI-enabled sensor with an embedded VPU), and the obtained predictions were used to perform tree trunks mapping.
After the experiments conducted in this work, one can conclude that:
The use of test datasets with and without augmented data caused tiny changes in the detection accuracy level of the models, as only one model (DETR) presented an absolute difference larger than 2%;
The quantisation of models’ weights caused a performance worsening in all models;
The diminution of models’ input resolution also lowered their performances during tree trunks detection;
The two trunk detectors that achieved the best results were YOLOR and YOLOv7 achieving around 90% in F1 score, while YOLOR can be considered the best model overall at detecting tree trunks, as it showed more robustness and more confidence at this task, whereas the worst model was SSD MobileNet V2;
The fastest model overall was YOLOv4 Tiny, achieving an average inference time of 1.93 ms on NVIDIA RTX3090, while on Jetson Nano’s GPU, YOLOv5 Nano proved to be the fastest (20.21 ms); on the Raspberry Pi 4 CPU and Coral’s TPU, SSD MobileNet V3 Small (22.25 ms) and SSD MobileNet V1 (7.30 ms) were quickest, respectively;
Considering the trade-off between detection accuracy and detection speed, YOLOv7 is the best trunk detection model, achieving the highest F1 score similar to YOLOR with average inference times under 4 ms on the RTX3090 GPU;
The tree trunks mapping by means of only one sensor (OAK-D) and some higher-level estimation algorithms is possible, but it needs additional effort for filtering/matching the raw trunk detections.
This article explores several approaches to make an accelerated perception for forestry robotics. The most common approaches were compared, including processing in the vision sensor and adding dedicated hardware for processing. It is expected that the perception system presented in this work is able to improve the quality of robotic perception in a forestry environment, as the proposed strategies are most adequate to autonomous mobile robotics. As the locomotion of terrestrial robots (specially the wheeled ones) is very difficult in forests, the DL-based tree trunk detection benchmark in this work can be applied not only to terrestrial robots but also to aerial robots. However, for the latter, it is necessary for the robots to fly under the forest canopy so that the tree trunks are visible. Furthermore, the vision perception system developed in this work can be used for forest inventory purposes, such as tree counting and tree trunk diameter estimation.
Future work will include training DL models to perform the detection of different tree species and different forestry objects such as bushes, rocks and obstacles in general to increase the awareness of a robot and prevent it from getting into dangerous situations. We will aim to improve the mapping operation using embedded object detection by means of, for instance, running object tracking inside OAK-D, so instead of producing all of the object detections, only tracked objects would be outputted from the sensor. These proposals will enable further developments regarding robotic artificial vision in the forestry domain in order to achieve a more precise monitoring of the forest resources.


 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}