A Collision Avoidance Method Based on Deep Reinforcement Learning


Abstract
:1. Introduction
2. Related Works
2.1. Autonomous Navigation
2.2. Deep Reinforcement Learning in Robotics
3. Collision Avoidance Approach
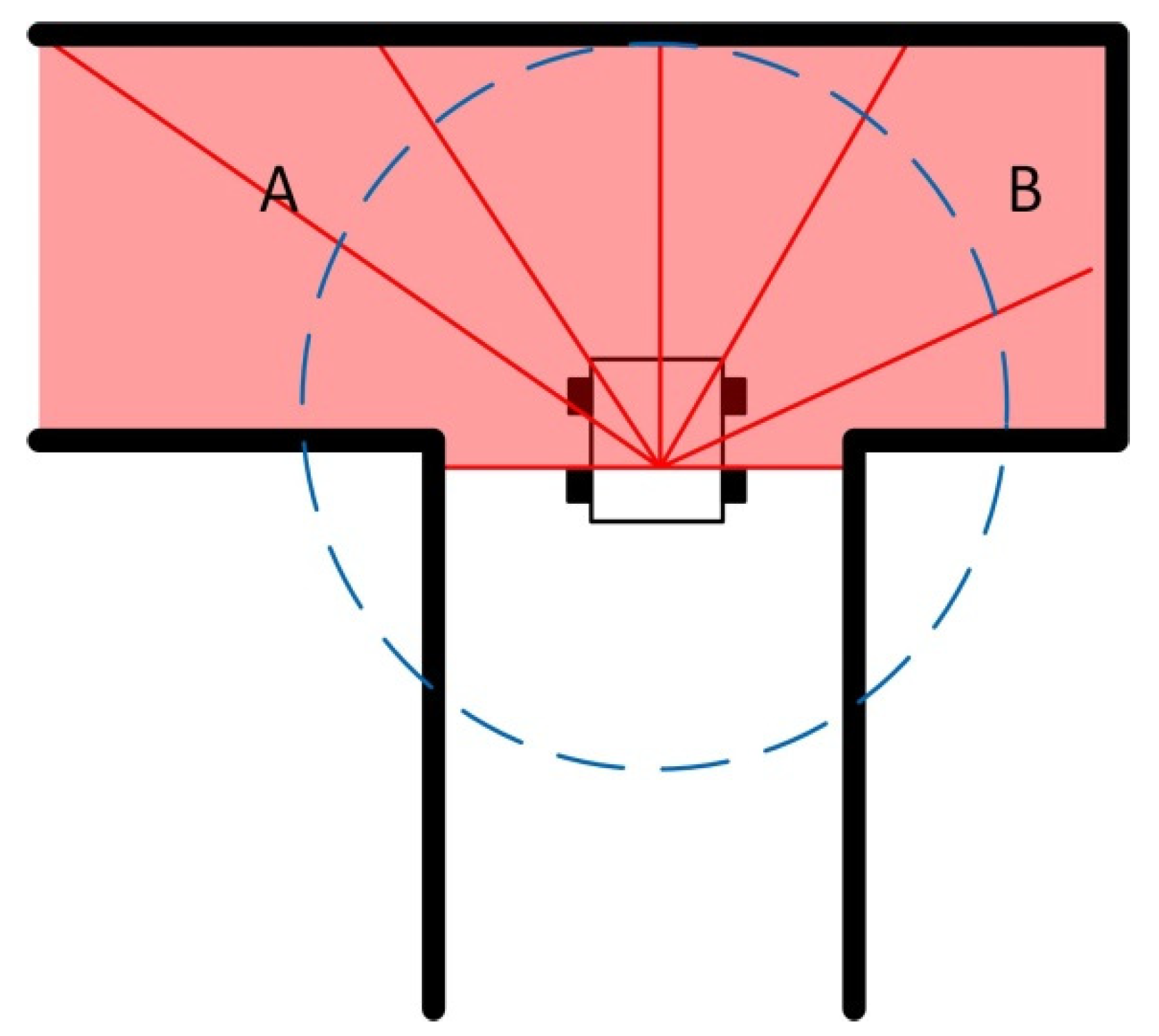
3.1. Problem Formulation
3.2. DRL Methods
3.3. Collision Avoidance with DRL
3.4. Implementation Details
| Algorithm 1. Pseudo Code of the Proposed Obstacle Avoidance Method Implemented in Gazebo Simulator. |
| 1. Initialize the Gazebo simulator; |
| Initialize the memory D and the Q-network with random weight ; |
| Initialize the target Q-network with random weights |
| 2: for episode = 1, k do |
| 3: Put the visual robot at a random position in the 3D world; |
| Get the first state |
| 4: for t = 1,T do |
| 5: With probability ε select a random action |
| 6: Otherwise, select |
| 7: Take action ; get reward and state |
| 8: Store transition in D |
| 9: Sample random mini-batch of transitions |
| 10: if = −1000 then |
| 11: |
| 12: else |
| 13: |
| 14: end if |
| 15: Calculate by performing mini-batch gradient descent on the |
| Mini-batch of loss |
| 16: Replace the target network parameters every N step |
| 17: end for |
| 18: end for |
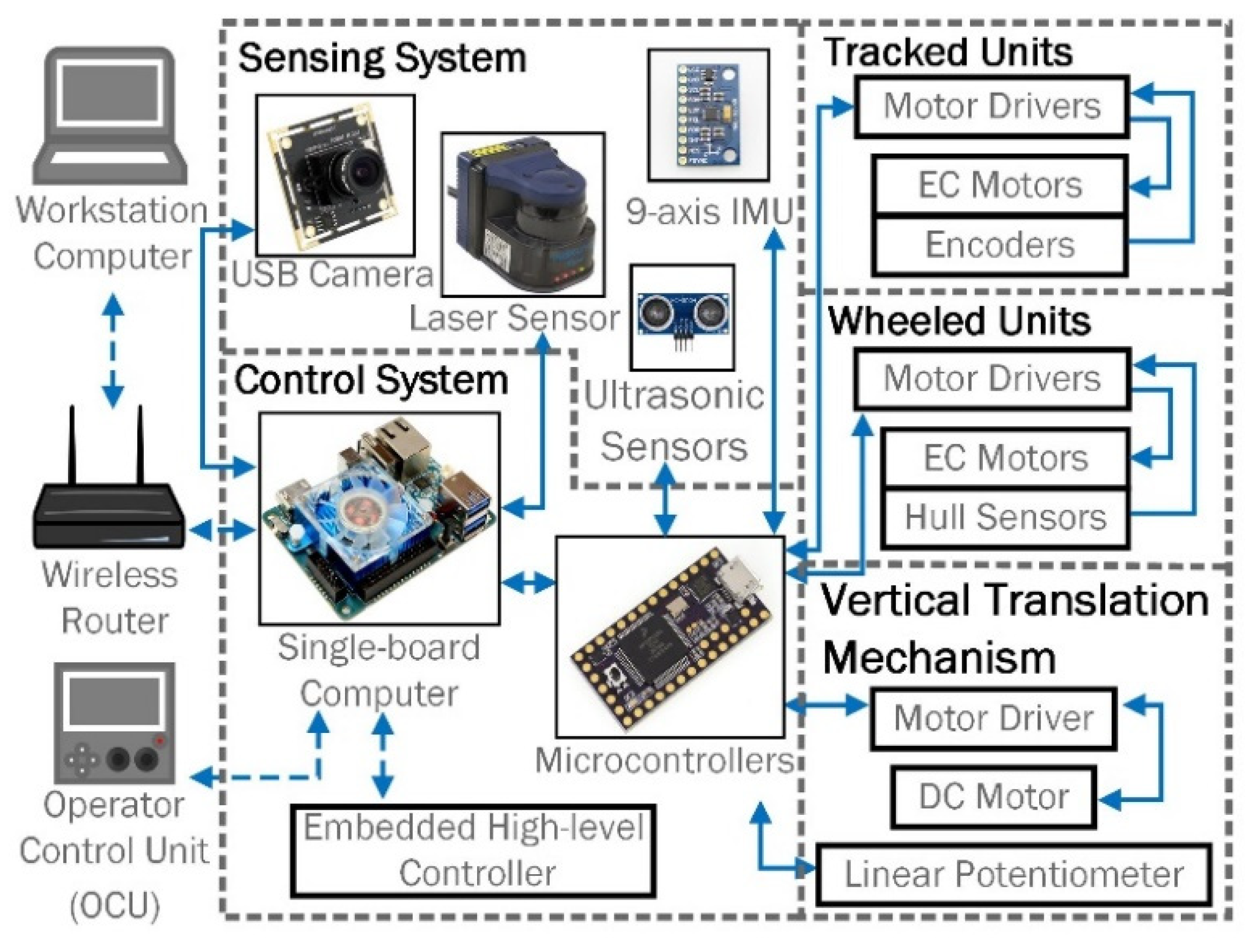
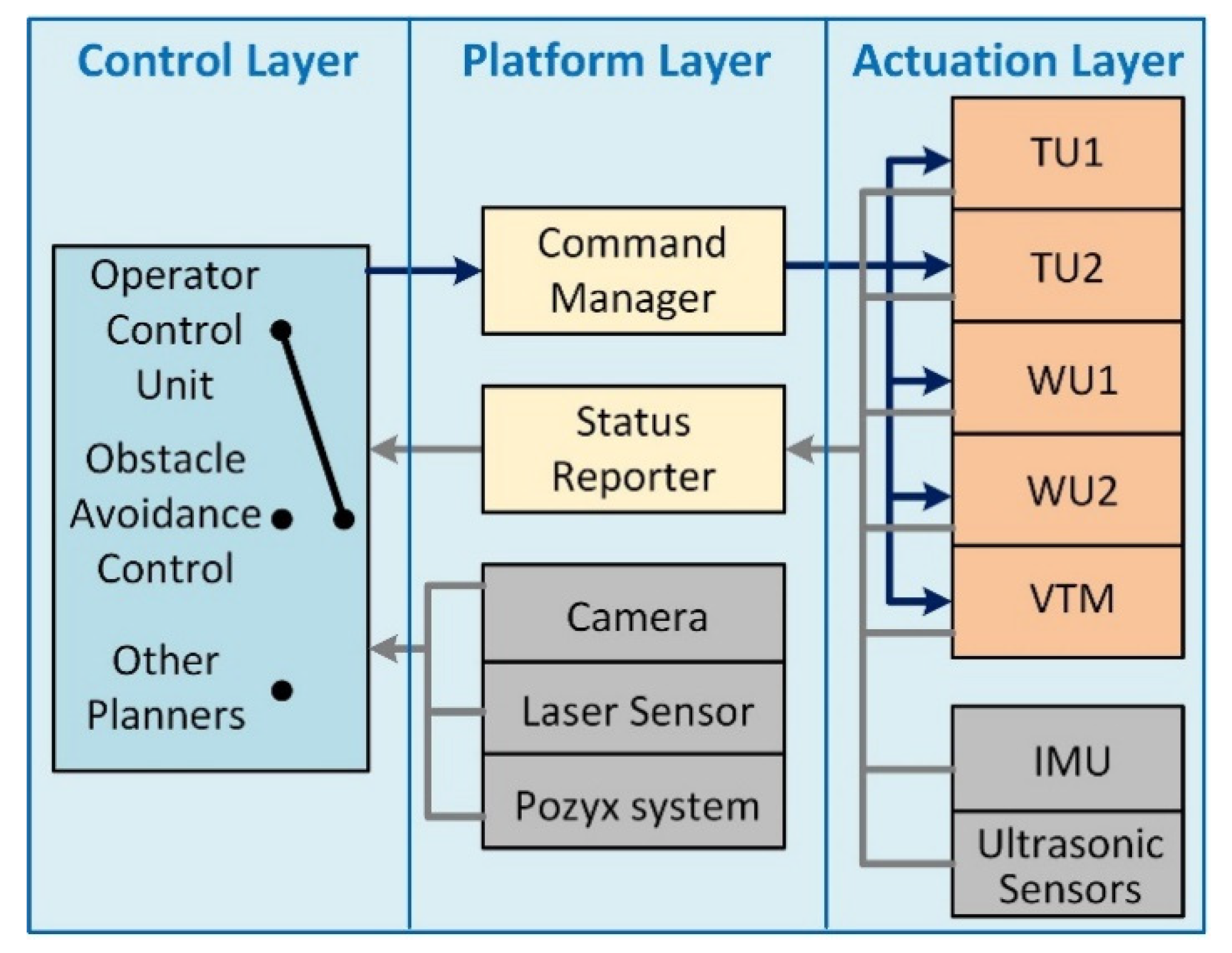
4. Robot Platform Description
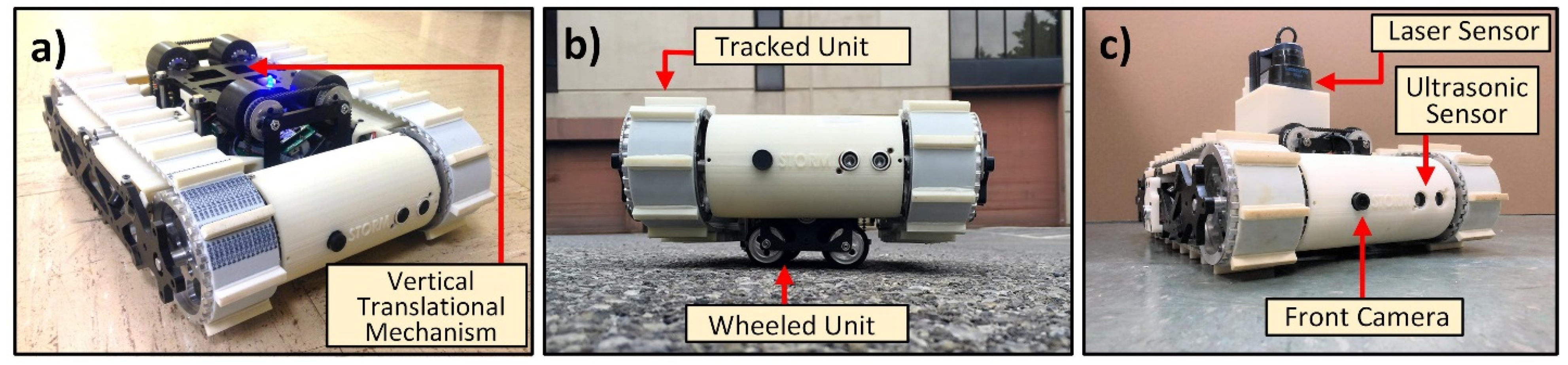
4.1. Mechanical System
4.2. Electronic System
4.3. Software System
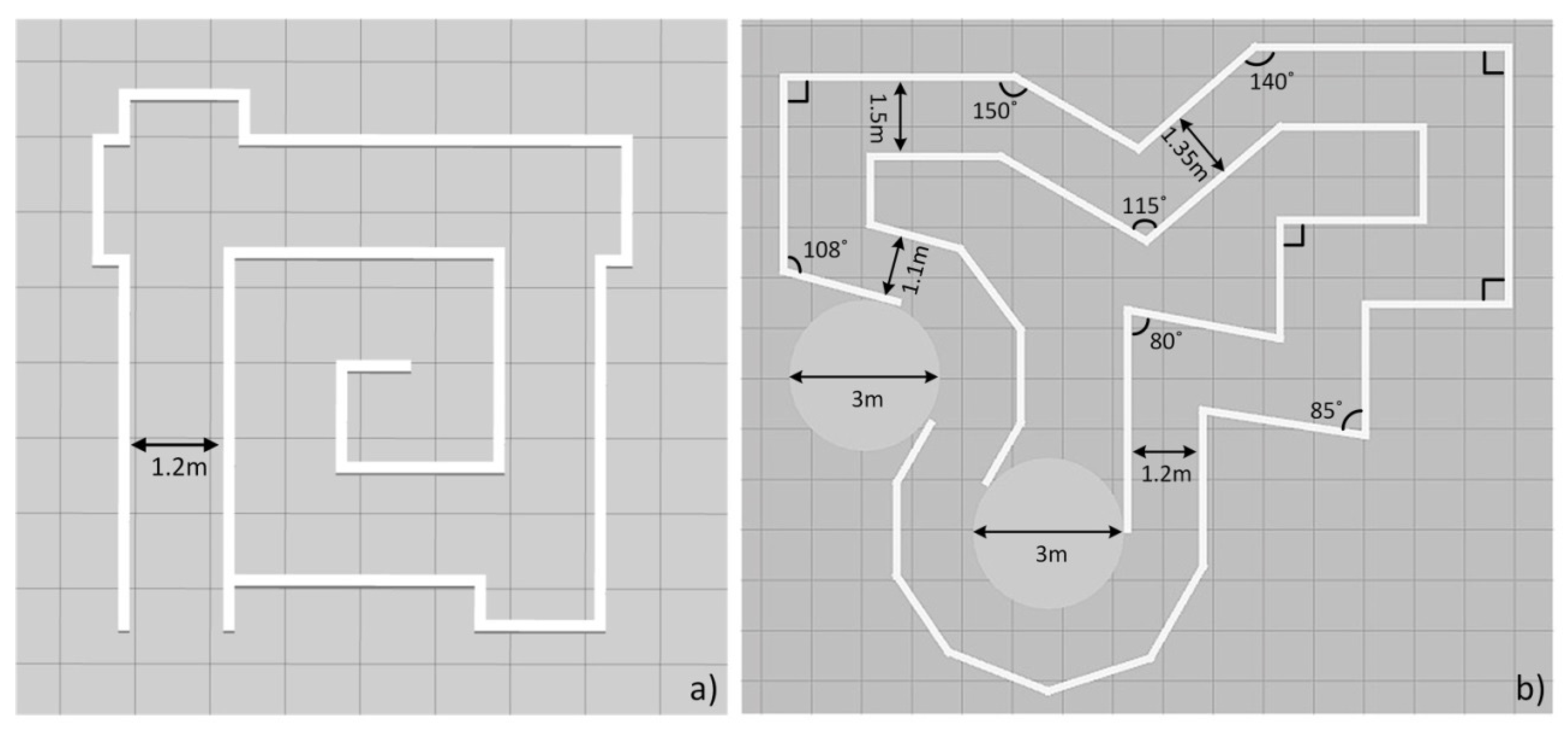
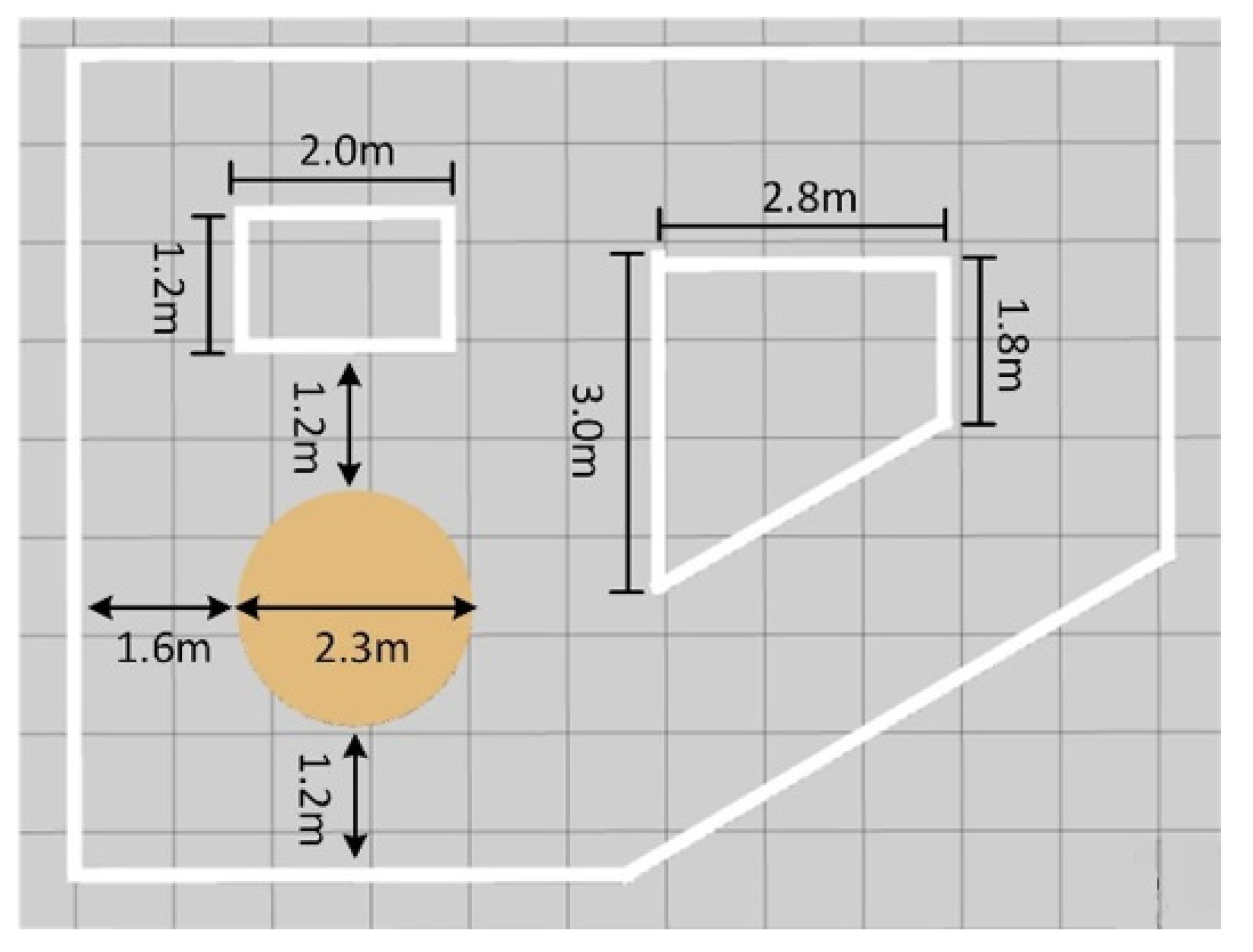
5. Simulations and Results
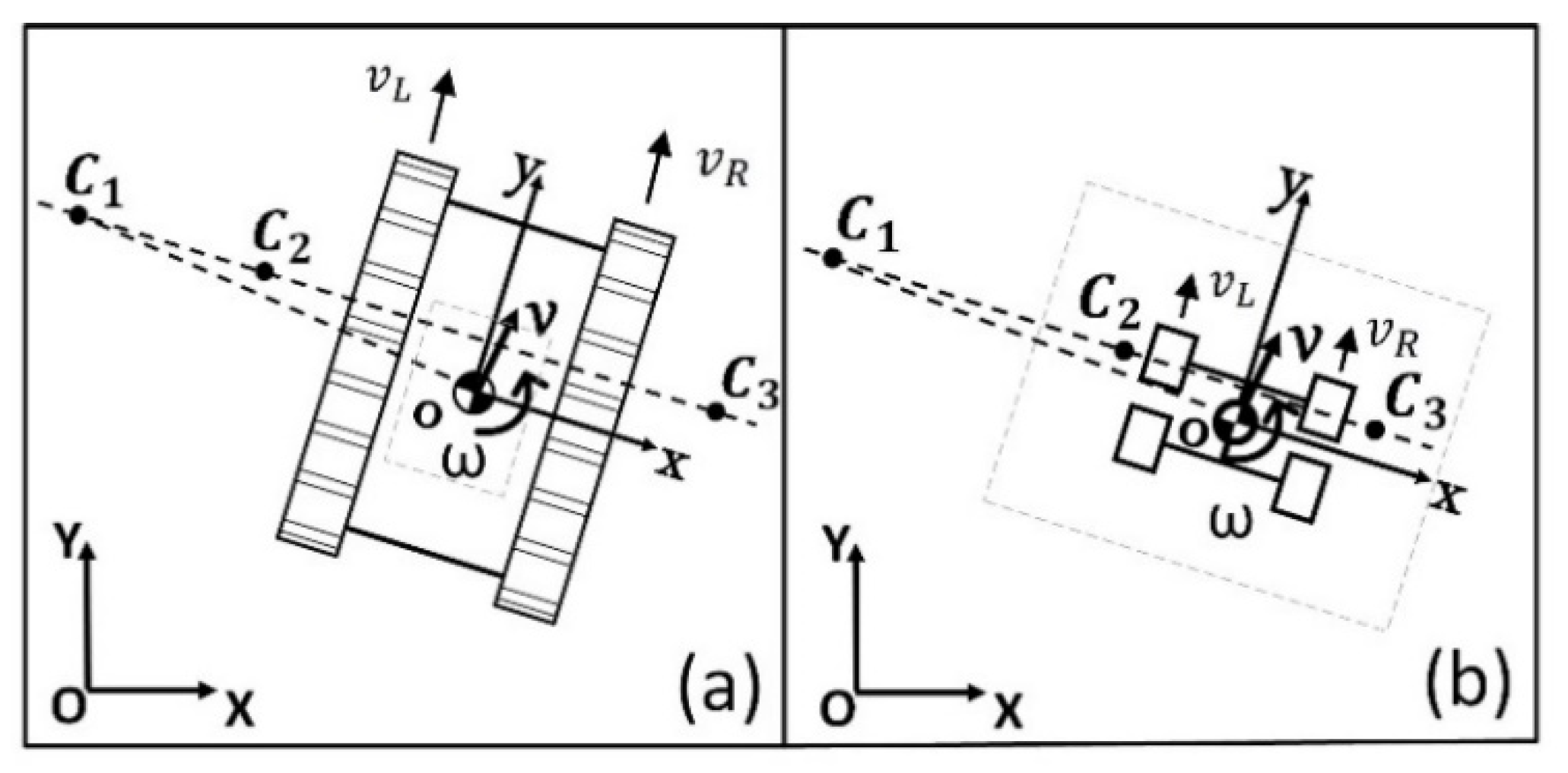
5.1. Kinematic Model of the Virtual STORM Module
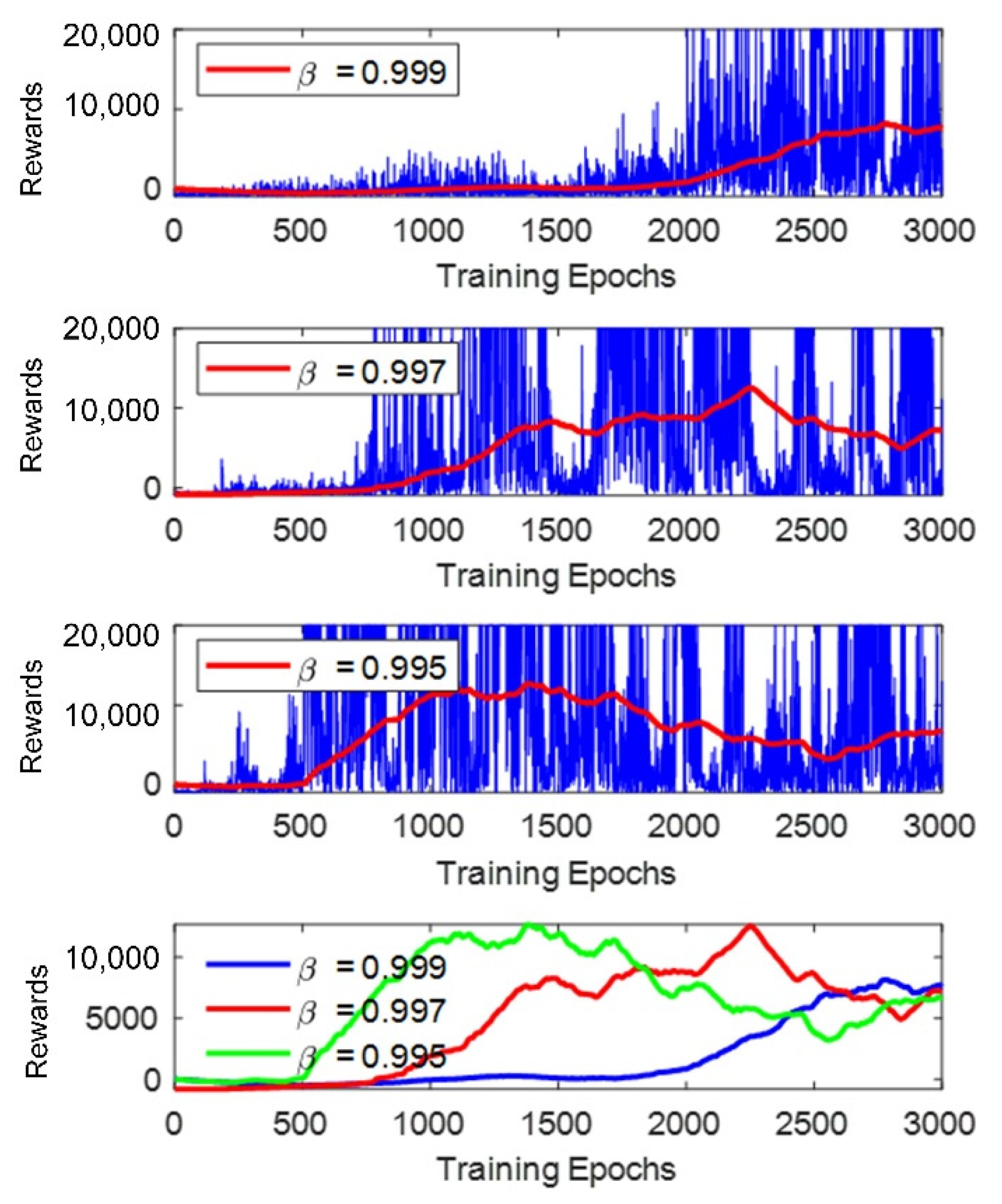
5.2. Training Parameter Selection and Analysis
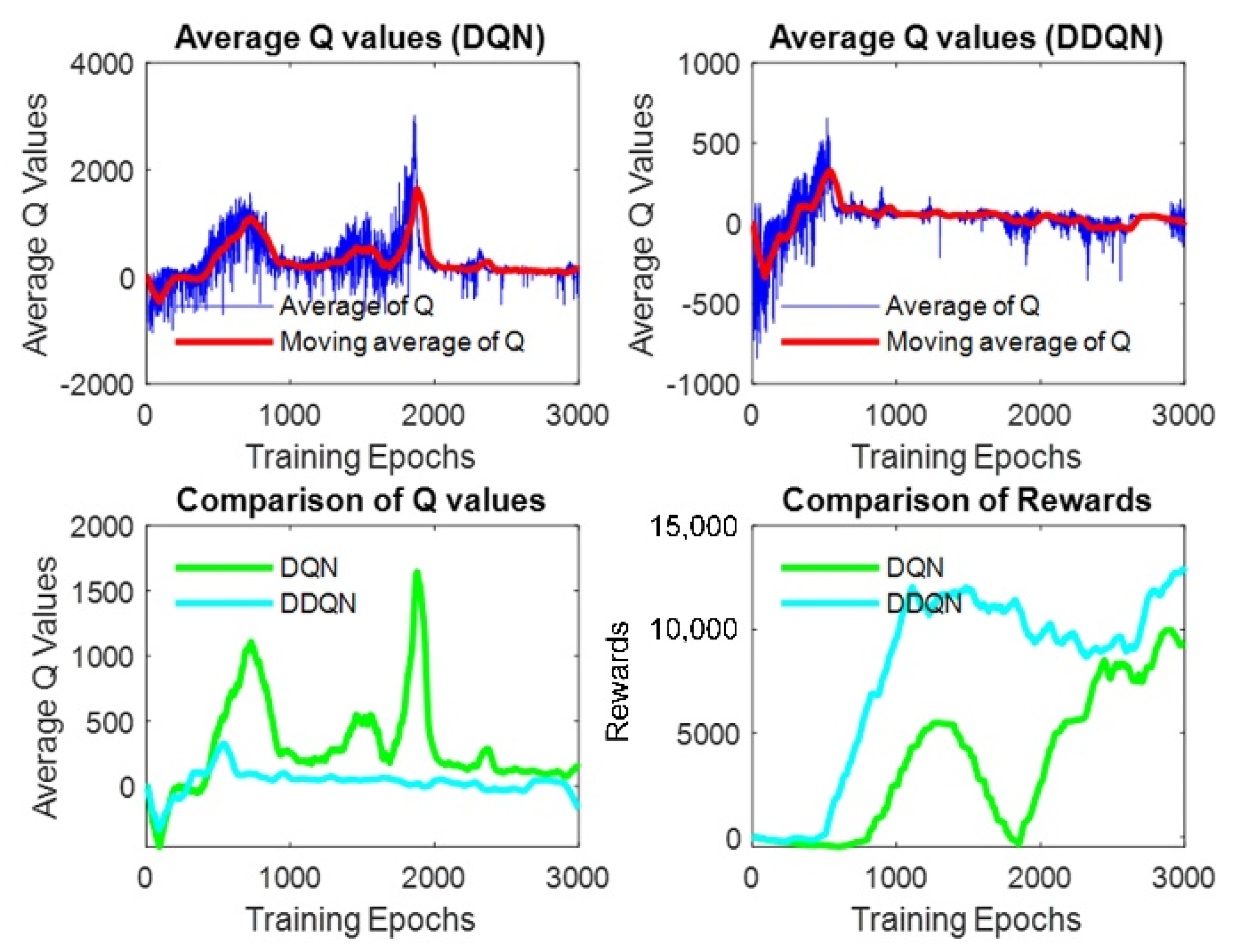
- The training process was performed three times in Map 2, as shown in Figure 9b, with the decay rate β set to 0.997, 0.998, and 0.999, respectively. Each neural network was trained for 3000 epochs for the following reasons: (a) All the three tests reach the lowest value of ε to choose a random action after 3000 epochs, for example, when β = 0.999, ε reaches 0.05 at epochs. (b) The current work did not include the improvement of the training efficiency. Training the neural network for 3000 epochs keeps the entire test within an acceptable training time, while at the same time ensuring that reasonable results can be obtained according to our previous experiences when training the neural network in [32].
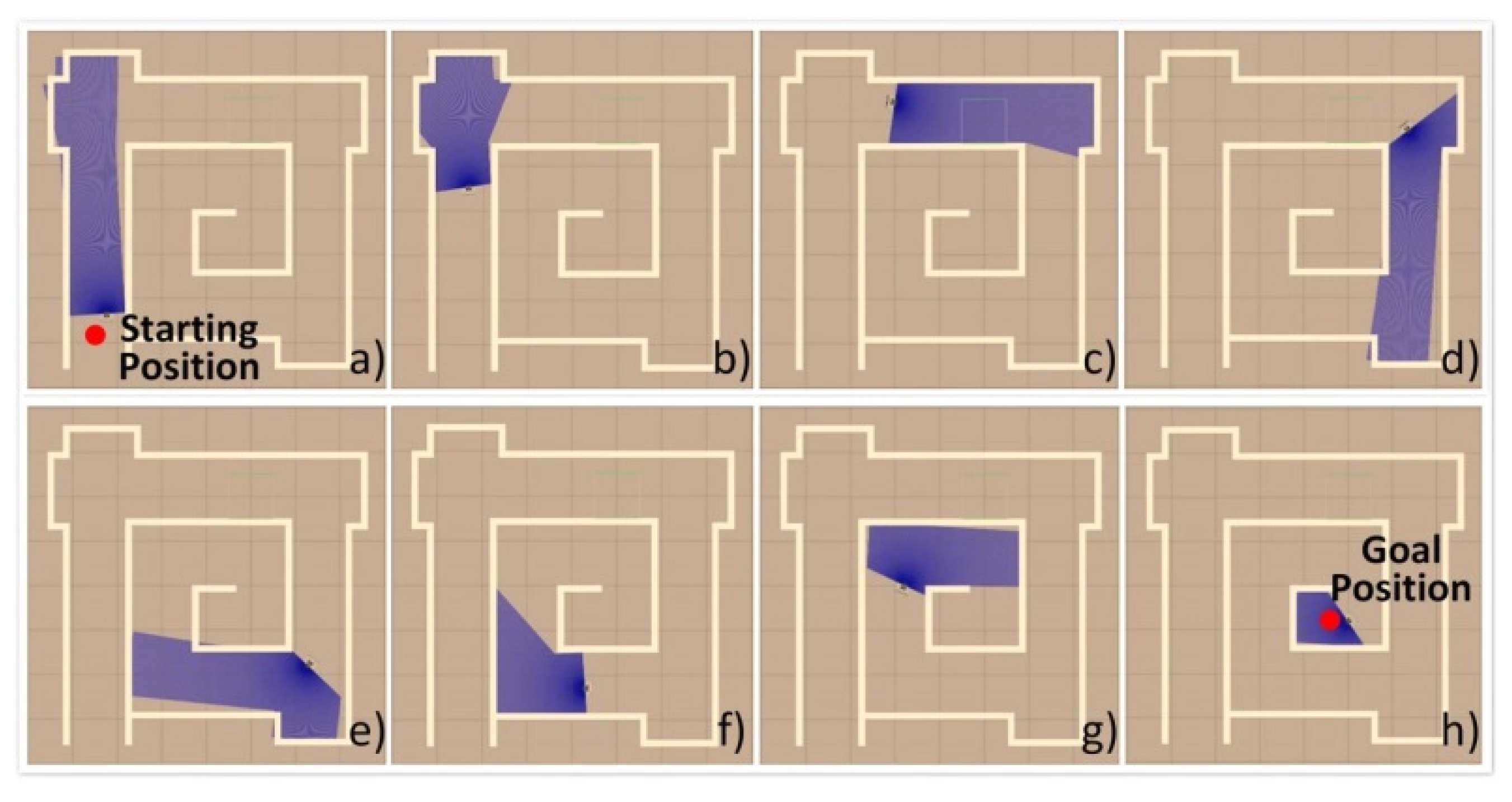
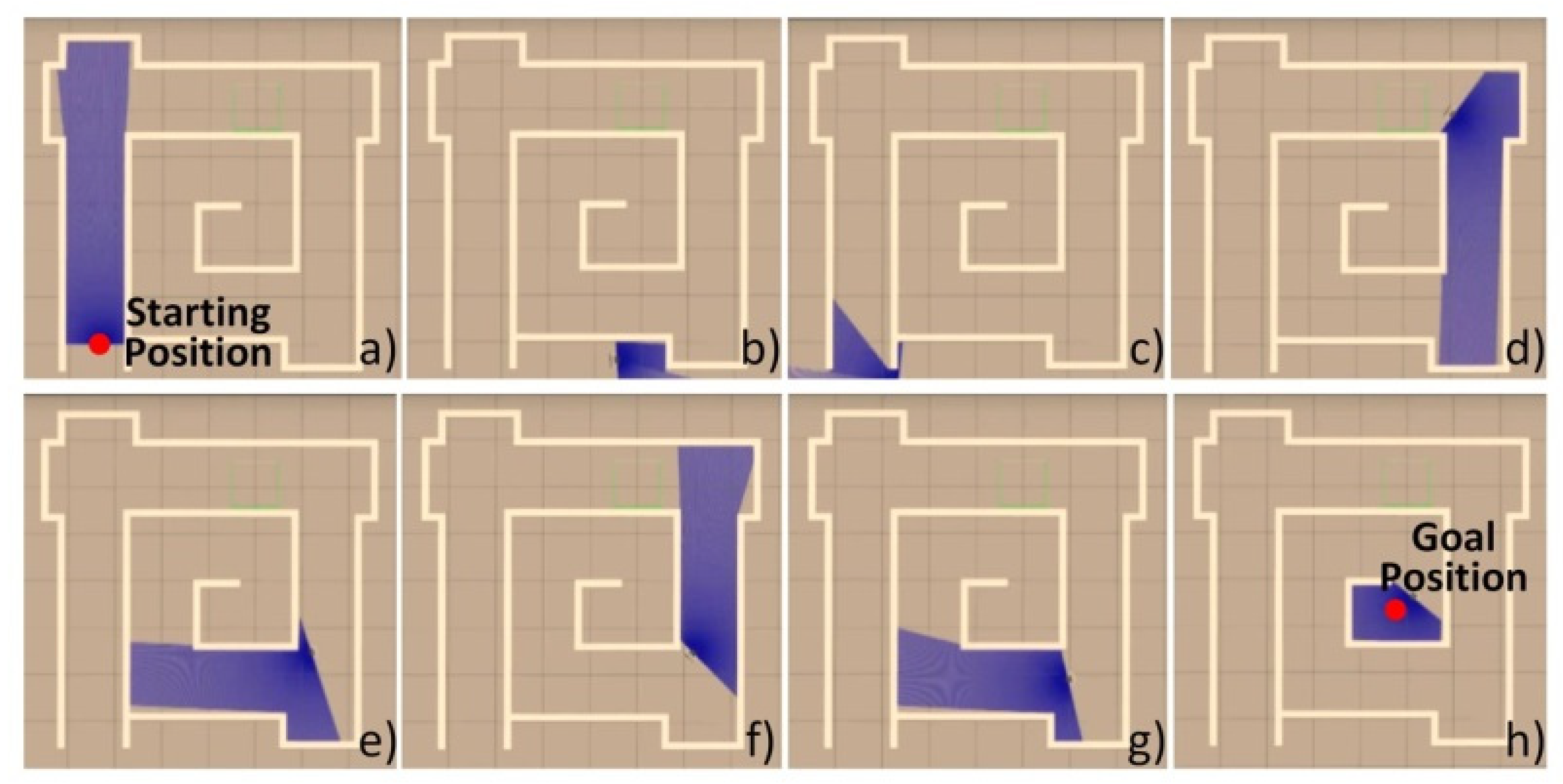
- The three neural networks were applied to the virtual STORM successively to navigate the test map with similar features in Map 2, as shown in Figure 10, for five minutes. The metric for evaluating the performance of the neural networks is chosen to be the number of collisions undergone within five minutes of simulation.
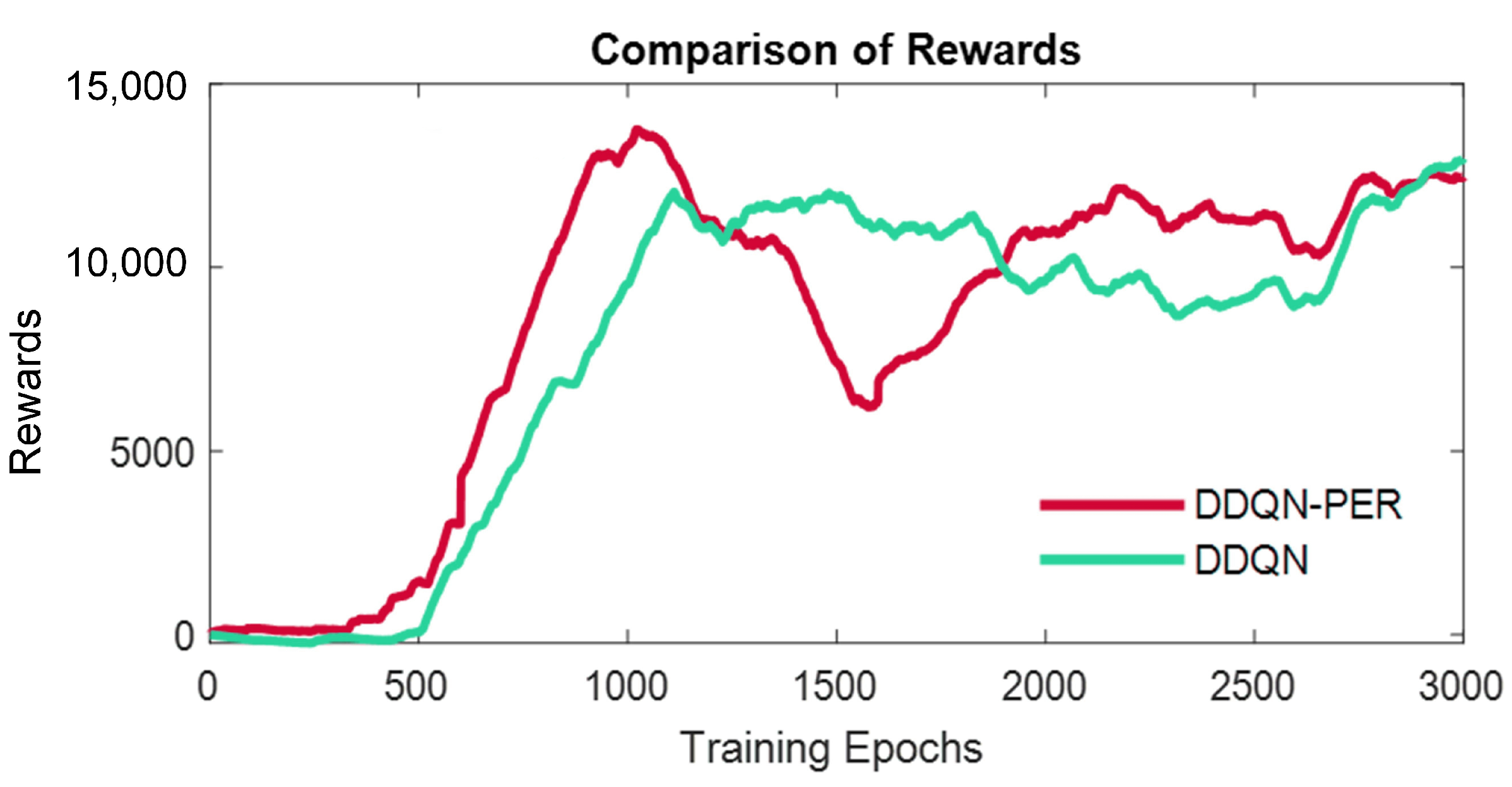
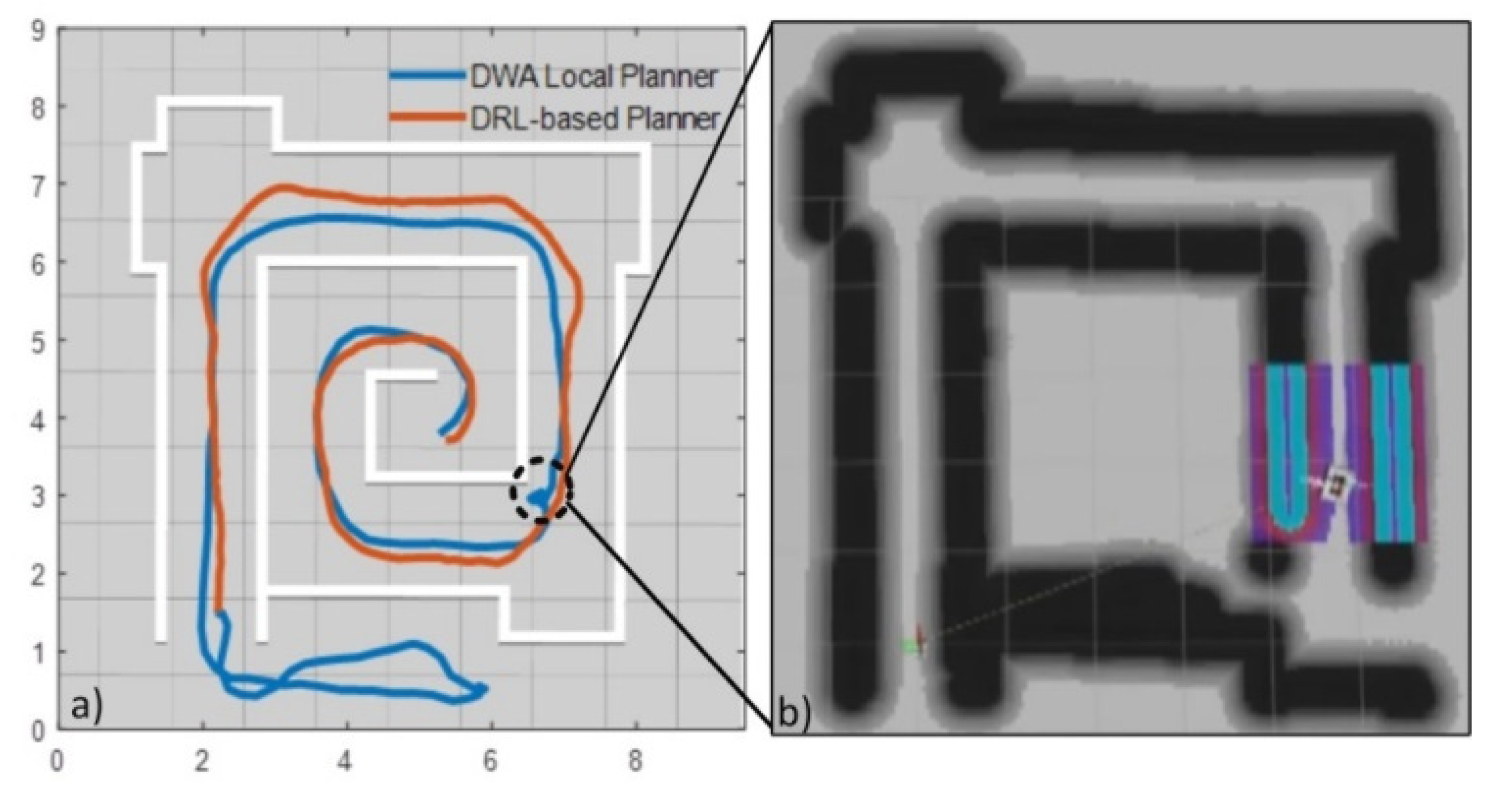
5.3. Comparison with State-of-the-Art Method
5.4. Simulation Results
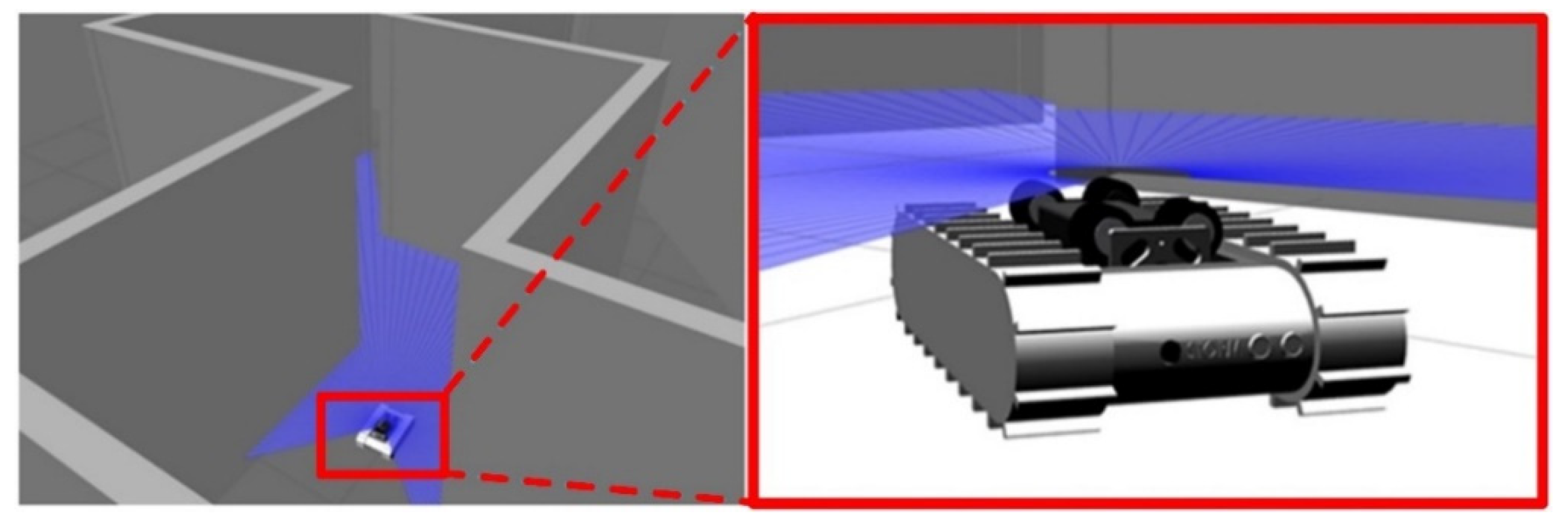
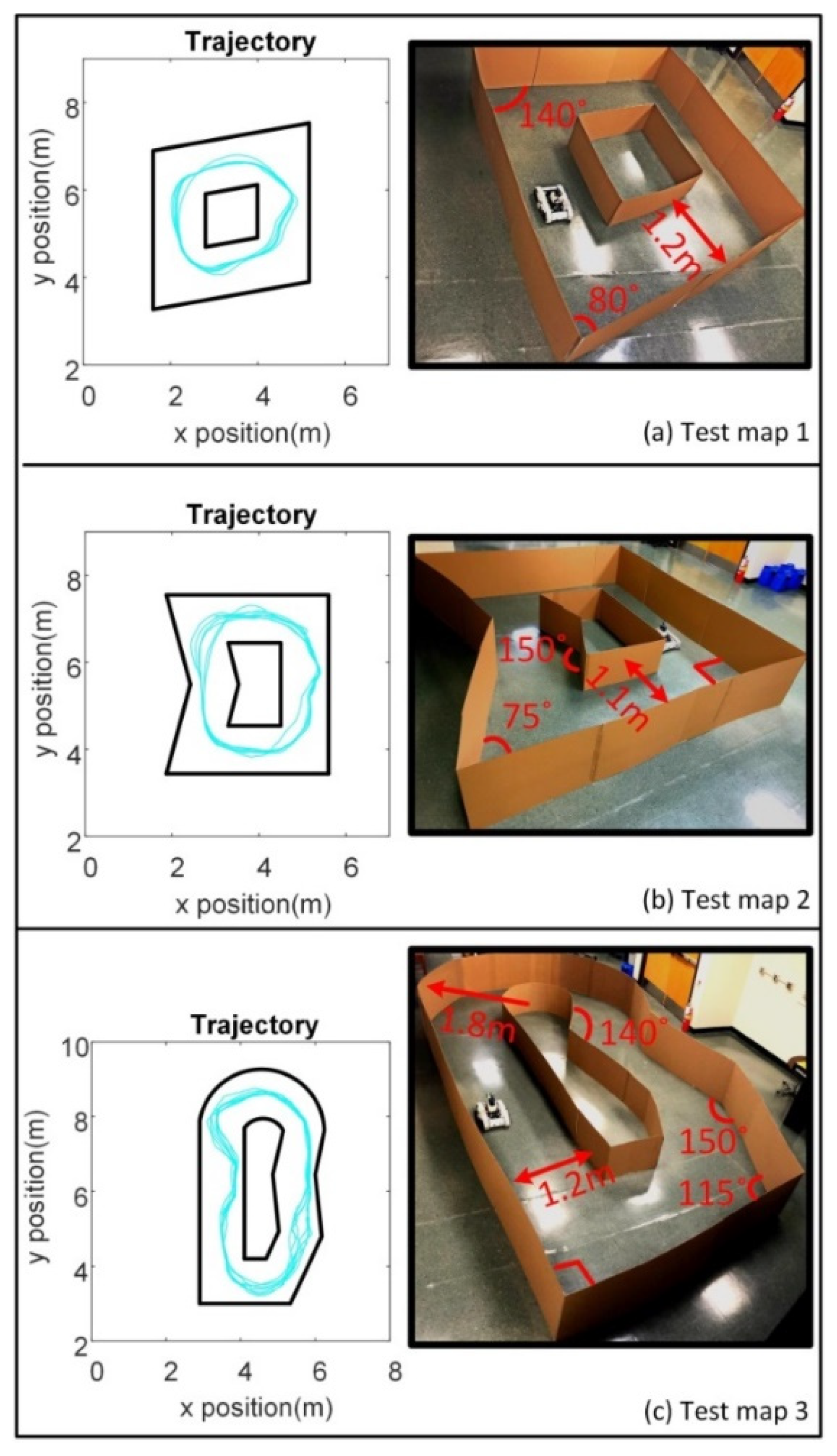
5.5. Real-World Implementation
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. Mastering chess and shogi by self-play with a general reinforcement learning algorithm. arXiv 2017, arXiv:1712.01815. [Google Scholar]
- François-Lavet, V.; Henderson, P.; Islam, R.; Bellemare, M.G.; Pineau, J. An Introduction to Deep Reinforcement Learning. Found. Trends Mach. Learn. 2018, 11, 219–354. [Google Scholar] [CrossRef] [Green Version]
- Moreira, I.; Rivas, J.; Cruz, F.; Dazeley, R.; Ayala, A.; Fernandes, B. Deep reinforcement learning with interactive feedback in a human-robot environment. Appl. Sci. 2020, 10, 5574. [Google Scholar] [CrossRef]
- Gu, S.; Holly, E.; Lillicrap, T.; Levine, S. Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 3389–3396. [Google Scholar] [CrossRef] [Green Version]
- Pirník, R.; Hruboš, M.; Nemec, D.; Mravec, T.; Božek, P. Integration of inertial sensor data into control of the mobile platform. Adv. Intell. Syst. Comput. 2017, 511, 271–282. [Google Scholar]
- Kilin, A.; Bozek, P.; Karavaev, Y.; Klekovkin, A.; Shestakov, V. Experimental investigations of a highly maneuverable mobile omniwheel robot. Int. J. Adv. Robot. Syst. 2017, 14, 1–9. [Google Scholar] [CrossRef]
- Zhu, Y.; Mottaghi, R.; Kolve, E.; Lim, J.J.; Gupta, A.; Fei-Fei, L.; Farhadi, A. Target-driven visual navigation in indoor scenes using deep reinforcement learning. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; IEEE: Piscataway, NJ, USA, 2017; Volume 1, pp. 3357–3364. [Google Scholar]
- Tai, L.; Paolo, G.; Liu, M. Virtual-to-real deep reinforcement learning: Continuous control of mobile robots for mapless navigation. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 31–36. [Google Scholar]
- Ulrich, I.; Borenstein, J. VFH*: Local obstacle avoidance with look-ahead verification. In Proceedings of the Proceedings 2000 ICRA. Millennium Conference. IEEE International Conference on Robotics and Automation. Symposia Proceedings (Cat. No.00CH37065), San Francisco, CA, USA, 24–28 April 2000; IEEE: Piscataway, NJ, USA, 2000; Volume 3, pp. 2505–2511. [Google Scholar]
- Gazebo. Available online: http://gazebosim.org/ (accessed on 12 May 2017).
- Kumar, P.; Saab, W.; Ben-Tzvi, P. Design of a Multi-Directional Hybrid-Locomotion Modular Robot With Feedforward Stability Control. In Proceedings of the Volume 5B: 41st Mechanisms and Robotics Conference, Cleveland, OH, USA, 6–9 August 2017; ASME: New York, NY, USA, 2017; p. V05BT08A010. [Google Scholar] [CrossRef] [Green Version]
- Ben-Tzvi, P.; Saab, W. A hybrid tracked-wheeled multi-directional mobile robot. J. Mech. Robot. 2019, 11, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Moubarak, P.M.; Alvarez, E.J.; Ben-Tzvi, P. Reconfiguring a modular robot into a humanoid formation: A multi-body dynamic perspective on motion scheduling for modules and their assemblies. In Proceedings of the 2013 IEEE International Conference on Automation Science and Engineering (CASE), Madison, WI, USA, 17–21 August 2013; IEEE: Piscataway, NY, USA, 2013; pp. 687–692. [Google Scholar] [CrossRef]
- Sebastian, B.; Ben-Tzvi, P. Physics Based Path Planning for Autonomous Tracked Vehicle in Challenging Terrain. J. Intell. Robot. Syst. Theory Appl. 2018, 1–16. [Google Scholar] [CrossRef]
- Sebastian, B.; Ben-Tzvi, P. Active Disturbance Rejection Control for Handling Slip in Tracked Vehicle Locomotion. J. Mech. Robot. 2018, 11, 021003. [Google Scholar] [CrossRef] [Green Version]
- Sohal, S.S.; Saab, W.; Ben-Tzvi, P. Improved Alignment Estimation for Autonomous Docking of Mobile Robots. In Proceedings of the Volume 5A: 42nd Mechanisms and Robotics Conference, Quebec City, QC, Canada, 26–29 August 2018; ASME: New York, NY, USA, 2018; p. V05AT07A072. [Google Scholar] [CrossRef]
- Hart, P.; Nilsson, N.; Raphael, B. A Formal Basis for the Heuristic Determination of Minimum Cost Paths. IEEE Trans. Syst. Sci. Cybern. 1968, 4, 100–107. [Google Scholar] [CrossRef]
- Lozano-Pérez, T.; Wesley, M.A. An Algorithm for Planning Collision-Free Paths Among Polyhedral Obstacles. Commun. ACM 1979, 22, 560–570. [Google Scholar] [CrossRef]
- Khatib, O. Real-Time Obstacle Avoidance for Manipulators and Mobile Robots. Int. J. Rob. Res. 1986, 5, 90–98. [Google Scholar] [CrossRef]
- Brock, O.; Khatib, O. High-speed navigation using the global dynamic window approach. In Proceedings of the Proceedings 1999 IEEE International Conference on Robotics and Automation (Cat. No.99CH36288C), Detroit, MI, USA, 10–15 May 1999; IEEE: Piscataway, NJ, USA, 1999; Volume 1, pp. 341–346. [Google Scholar]
- Koren, Y.; Borenstein, J. Potential field methods and their inherent limitations for mobile robot navigation. In Proceedings of the Proceedings. 1991 IEEE International Conference on Robotics and Automation, Sacramento, CA, USA, 7–12 April 1991; IEEE: Piscataway, NJ, USA, 2016; Volume 11, pp. 1398–1404. [Google Scholar]
- Borenstein, J.; Koren, Y. The vector field histogram-fast obstacle avoidance for mobile robots. IEEE Trans. Robot. Autom. 1991, 7, 278–288. [Google Scholar] [CrossRef] [Green Version]
- Faisal, M.; Hedjar, R.; Al Sulaiman, M.; Al-Mutib, K. Fuzzy logic navigation and obstacle avoidance by a mobile robot in an unknown dynamic environment. Int. J. Adv. Robot. Syst. 2013, 10, 37. [Google Scholar] [CrossRef]
- Pothal, J.K.; Parhi, D.R. Navigation of multiple mobile robots in a highly clutter terrains using adaptive neuro-fuzzy inference system. Rob. Auton. Syst. 2015, 72, 48–58. [Google Scholar] [CrossRef]
- Dijkstra, E.W. A note on two problems in connexion with graphs. Numer. Math. 1959, 1, 269–271. [Google Scholar] [CrossRef] [Green Version]
- Dechter, R.; Pearl, J. Generalized Best-First Search Strategies and the Optimality of A. J. ACM 1985, 32, 505–536. [Google Scholar] [CrossRef]
- Kavraki, L.E.; Svestka, P.; Latombe, J.-C.; Overmars, M.H. Probabilistic roadmaps for path planning in high-dimensional configuration spaces. IEEE Trans. Robot. Autom. 1996, 12, 566–580. [Google Scholar] [CrossRef] [Green Version]
- Elbanhawi, M.; Simic, M. Sampling-based robot motion planning: A review. IEEE Access 2014, 2, 56–77. [Google Scholar] [CrossRef]
- Ulrich, I.; Borenstein, J. VFH+: Reliable obstacle avoidance for fast mobile robots. Proc. IEEE Int. Conf. Robot. Autom. 1998, 2, 1572–1577. [Google Scholar]
- Haarnoja, T.; Pong, V.; Zhou, A.; Dalal, M.; Abbeel, P.; Levine, S. Composable deep reinforcement learning for robotic manipulation. arXiv 2018, arXiv:1803.06773v1. [Google Scholar]
- Wang, C.; Wang, J.; Shen, Y.; Zhang, X. Autonomous Navigation of UAVs in Large-Scale Complex Environments: A Deep Reinforcement Learning Approach. IEEE Trans. Veh. Technol. 2019, 68, 2124–2136. [Google Scholar] [CrossRef]
- Feng, S.; Ren, H.; Wang, X.; Ben-Tzvi, P. Mobile robot obstacle avoidance base on deep reinforcement learning. Proc. ASME Des. Eng. Tech. Conf. 2019, 5A-2019, 1–8. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Chapter 1 Introduction. Reinf. Learn. An Introd. 1988. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep Reinforcement Learning with Double Q-learning. Assoc. Adv. Artif. Intell. 2016, 30, 2094–2100. [Google Scholar]
- Saab, W.; Ben-Tzvi, P. A Genderless Coupling Mechanism with 6-DOF Misalignment Capability for Modular Self-Reconfigurable Robots. J. Mech. Robot. 2016, 8, 1–9. [Google Scholar] [CrossRef]
- POZYX Positioning System. Available online: https://www.pozyx.io/ (accessed on 23 February 2018).
- Mandow, A.; Martinez, J.L.; Morales, J.; Blanco, J.L.; Garcia-Cerezo, A.; Gonzalez, J. Experimental kinematics for wheeled skid-steer mobile robots. IEEE Int. Conf. Intell. Robot. Syst. 2007, 1222–1227. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Strategy | Prior Knowledge | Real-Time Capability | Comments |
|---|---|---|---|---|
| A* [17] | Search-based approach | Yes | Offline planning | Avoids expanding paths that are already expensive |
| Dijkstra’s Algorithm [25] | Explores all the possible path and take more time | |||
| Greedy Best First Search [26] | Finds out the optimal path fast but not always work | |||
| Probabilistic roadmap (PRM) [27] | Sample-based planning | Yes | Offline planning | Selects a random node from the C-space and performs multi-query |
| RRT [28] | Selects a random node from the C-space and incrementally adds new node | |||
| PF [19] | Potential field-based approach | No | Online planning | Has several drawbacks: local minima, no passage of narrow path, oscillations in narrow passages |
| VFF [21] | Overcomes the local minima problem, but the other two shortcomings still exist | |||
| VFH [9], VFH+ [29] | Overcomes the drawbacks, but problematic scenarios exist | |||
| VFH* [9] | Yes | Overcomes the problematic scenarios but relies on information from a map | ||
| FLC [23] | Fuzzy logic-based method | No | Online planning | Generates various decisions according to different sensory information |
| Proposed Approach | DRL-based approach | No | Online planning | Generates optimal decisions from a well-trained neural network. Complex scenarios can be overcome as long as the robot has sufficient experiences during training |
| Characteristic | Parameters |
|---|---|
| Outer dimensions | 410 × 305 × 120 mm3 |
| Vertical translation | 50 mm |
| Robot mass | 8.40 kg |
| TU mass | 2 × 2.81 kg |
| WU mass | 2 × 0.76 kg |
| VTU | 0.73 kg |
| Decay Rate β | Number of Collisions in 5 min |
|---|---|
| 0.999 | 0 |
| 0.997 | 1 |
| 0.995 | 2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, S.; Sebastian, B.; Ben-Tzvi, P. A Collision Avoidance Method Based on Deep Reinforcement Learning. Robotics 2021, 10, 73. https://doi.org/10.3390/robotics10020073
Feng S, Sebastian B, Ben-Tzvi P. A Collision Avoidance Method Based on Deep Reinforcement Learning. Robotics. 2021; 10(2):73. https://doi.org/10.3390/robotics10020073
Chicago/Turabian StyleFeng, Shumin, Bijo Sebastian, and Pinhas Ben-Tzvi. 2021. "A Collision Avoidance Method Based on Deep Reinforcement Learning" Robotics 10, no. 2: 73. https://doi.org/10.3390/robotics10020073