
Leveraging the Structure of DNAJA1 to Discover Novel Potential Pancreatic Cancer Therapies

Abstract
:1. Introduction
2. Material and Methods
2.1. Protein Expression and Purification
2.2. Virtual Ligand Screens
2.3. In Vitro Ligand Binding Studies
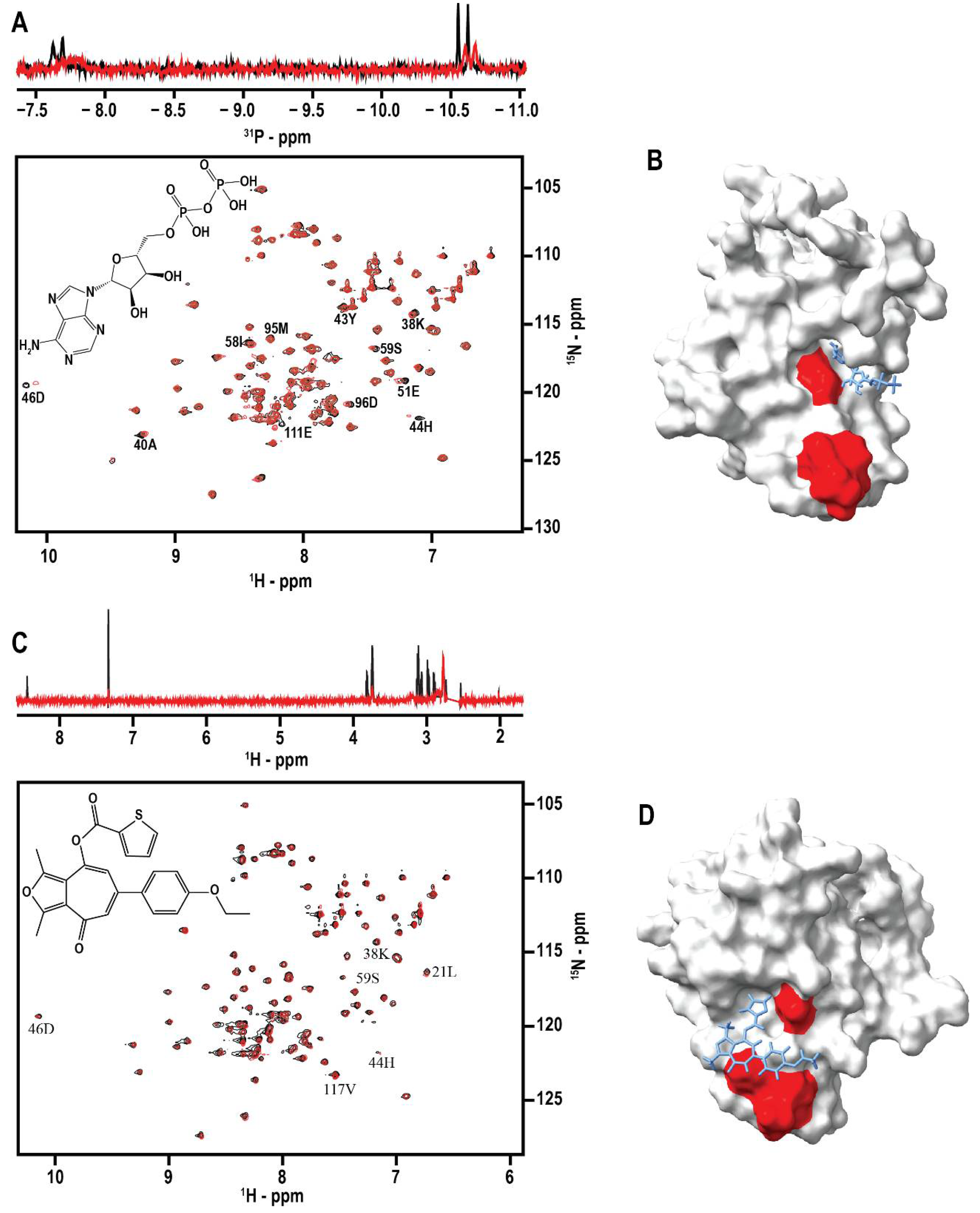
2.3.1. NMR
2.3.2. Isothermal Titration Calorimetry
2.4. DNAJA1-107 Structural Characterization
2.5. Identification of Protein Binding Partners
2.5.1. Mammalian Cell Cultures
2.5.2. Pull-Down Assay
3. Results and Discussion
3.1. DNAJA1-107 Solution Structure
3.2. DNAJA1-107 and DNAJA1-67 Structure Comparison
3.3. Virtual Ligand Affinity Screens
3.4. Identification of Ligand Binding Sites on DNAJA1-107
3.5. DNAJA1-107 Protein Binding Partners
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- American Cancer Society. Cancer Facts & Figures 2022; American Cancer Society: Atlanta, GA, USA, 2022. [Google Scholar]
- Sheikh, R.; Walsh, N.; Clynes, M.; O’Connor, R.; McDermott, R. Challenges of drug resistance in the management of pancreatic cancer. Expert Rev. Anticancer Ther. 2010, 10, 1647–1661. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Li, Y.; Ahmad, A.; Banerjee, S.; Azmi, A.S.; Kong, D.; Sarkar, F.H. Pancreatic cancer: Understanding and overcoming chemoresistance. Nat. Rev. Gastroenterol. Hepatol. 2011, 8, 27–33. [Google Scholar] [CrossRef] [PubMed]
- Stark, J.L.; Mehla, K.; Chaika, N.; Acton, T.B.; Xiao, R.; Singh, P.K.; Montelione, G.T.; Powers, R. Structure and function of human DnaJ homologue subfamily a member 1 (DNAJA1) and its relationship to pancreatic cancer. Biochemistry 2014, 53, 1360–1372. [Google Scholar] [CrossRef]
- Truman, A.W. Dealing with difficult clients via personalized chaperone inhibitors. J. Biol. Chem. 2021, 296, 100211. [Google Scholar] [CrossRef]
- Roth, H.E.; Bhinderwala, F.; Franco, R.; Zhou, Y.; Powers, R. DNAJA1 Dysregulates Metabolism Promoting an Antiapoptotic Phenotype in Pancreatic Ductal Adenocarcinoma. J. Proteome Res. 2021, 20, 3925–3939. [Google Scholar] [CrossRef]
- Kaida, A.; Yamamoto, S.; Parrales, A.; Young, E.D.; Ranjan, A.; Alalem, M.A.; Morita, K.-i.; Oikawa, Y.; Harada, H.; Ikeda, T.; et al. DNAJA1 promotes cancer metastasis through interaction with mutant p53. Oncogene 2021, 40, 5013–5025. [Google Scholar] [CrossRef]
- Bardeesy, N.; DePinho, R.A. Pancreatic cancer biology and genetics. Nat. Rev. Cancer 2002, 2, 897–909. [Google Scholar] [CrossRef]
- Qiu, X.B.; Shao, Y.M.; Miao, S.; Wang, L. The diversity of the DnaJ/Hsp40 family, the crucial partners for Hsp70 chaperones. Cell. Mol. Life Sci. CMLS 2006, 63, 2560–2570. [Google Scholar] [CrossRef]
- Hennessy, F.; Nicoll, W.S.; Zimmermann, R.; Cheetham, M.E.; Blatch, G.L. Not all J domains are created equal: Implications for the specificity of Hsp40-Hsp70 interactions. Protein Sci. 2005, 14, 1697–1709. [Google Scholar] [CrossRef]
- Wall, D.; Zylicz, M.; Georgopoulos, C. The NH2-terminal 108 amino acids of the Escherichia coli DnaJ protein stimulate the ATPase activity of DnaK and are sufficient for lambda replication. J. Biol. Chem. 1994, 269, 5446–5451. [Google Scholar] [CrossRef]
- Jiang, J.; Maes, E.G.; Taylor, A.B.; Wang, L.; Hinck, A.P.; Lafer, E.M.; Sousa, R. Structural basis of J cochaperone binding and regulation of Hsp70. Mol. Cell. 2007, 28, 422–433. [Google Scholar] [CrossRef] [PubMed]
- Mitra, A.; Shevde, L.A.; Samant, R.S. Multi-faceted role of HSP40 in cancer. Clin. Exp. Metastasis 2009, 26, 559–567. [Google Scholar] [CrossRef] [PubMed]
- Walsh, P.; Bursać, D.; Law, Y.C.; Cyr, D.; Lithgow, T. The J-protein family: Modulating protein assembly, disassembly and translocation. EMBO Rep. 2004, 5, 567–571. [Google Scholar] [CrossRef]
- Vos, M.J.; Hageman, J.; Carra, S.; Kampinga, H.H. Structural and Functional Diversities between Members of the Human HSPB, HSPH, HSPA, and DNAJ Chaperone Families. Biochemistry 2008, 47, 7001–7011. [Google Scholar] [CrossRef] [PubMed]
- Kanazawa, M.; Terada, K.; Kato, S.; Mori, M. HSDJ, a human homolog of DnaJ, is farnesylated and is involved in protein import into mitochondria. J. Biochem. 1997, 121, 890–895. [Google Scholar] [CrossRef]
- Terada, K.; Kanazawa, M.; Bukau, B.; Mori, M. The human DnaJ homolog dj2 facilitates mitochondrial protein import and luciferase refolding. J. Cell. Biol. 1997, 139, 1089–1095. [Google Scholar] [CrossRef]
- Ott, M.; Gogvadze, V.; Orrenius, S.; Zhivotovsky, B. Mitochondria, oxidative stress and cell death. Apoptosis 2007, 12, 913–922. [Google Scholar] [CrossRef]
- Paschen, S.A.; Weber, A.; Haecker, G. Mitochondrial protein import: A matter of death? Cell. Cycle 2007, 6, 2434–2439. [Google Scholar] [CrossRef]
- Petit, E.; Oliver, L.; Vallette, F.M. The mitochondrial outer membrane protein import machinery: A new player in apoptosis? Front. Biosci. Landmark Ed. 2009, 14, 3563–3570. [Google Scholar] [CrossRef]
- Llambi, F.; Green, D.R. Apoptosis and oncogenesis: Give and take in the BCL-2 family. Curr. Opin. Genet. Dev. 2011, 21, 12–20. [Google Scholar] [CrossRef] [Green Version]
- Meshalkina, D.A.; Shevtsov, M.A.; Dobrodumov, A.V.; Komarova, E.Y.; Voronkina, I.V.; Lazarev, V.F.; Margulis, B.A.; Guzhova, I.V. Knock-down of Hdj2/DNAJA1 co-chaperone results in an unexpected burst of tumorigenicity of C6 glioblastoma cells. Oncotarget 2016, 7, 22050–22063. [Google Scholar] [CrossRef] [PubMed]
- Parrales, A.; Thoenen, E.; Iwakuma, T. The interplay between mutant p53 and the mevalonate pathway. Cell. Death Differ. 2018, 25, 460–470. [Google Scholar] [CrossRef] [PubMed]
- Alexandrova, E.M.; Moll, U.M. Depleting stabilized GOF mutant p53 proteins by inhibiting molecular folding chaperones: A new promise in cancer therapy. Cell. Death Differ. 2017, 24, 3–5. [Google Scholar] [CrossRef]
- Tong, X.; Xu, D.; Mishra, R.K.; Jones, R.D.; Sun, L.; Schiltz, G.E.; Liao, J.; Yang, G.-Y. Identification of a druggable protein-protein interaction site between mutant p53 and its stabilizing chaperone DNAJA1. J. Biol. Chem. 2021, 296, 100098. [Google Scholar] [CrossRef] [PubMed]
- Xu, D.; Tong, X.; Sun, L.; Li, H.; Jones, R.D.; Liao, J.; Yang, G.-Y. Inhibition of mutant Kras and p53-driven pancreatic carcinogenesis by atorvastatin: Mainly via targeting of the farnesylated DNAJA1 in chaperoning mutant p53. Mol. Carcinog. 2019, 58, 2052–2064. [Google Scholar] [CrossRef] [PubMed]
- Yang, S.; Ren, X.; Liang, Y.; Yan, Y.; Zhou, Y.; Hu, J.; Wang, Z.; Song, F.; Wang, F.; Liao, W.; et al. KNK437 restricts the growth and metastasis of colorectal cancer via targeting DNAJA1/CDC45 axis. Oncogene 2020, 39, 249–261. [Google Scholar] [CrossRef] [PubMed]
- Parrales, A.; Ranjan, A.; Iyer, S.V.; Padhye, S.; Weir, S.J.; Roy, A.; Iwakuma, T. DNAJA1 controls the fate of misfolded mutant p53 through the mevalonate pathway. Nat. Cell. Biol. 2016, 18, 1233–1243. [Google Scholar] [CrossRef]
- Ergulen, E.; Becsi, B.; Csomos, I.; Fesus, L.; Kanchan, K. Identification of DNAJA1 as a novel interacting partner and a substrate of human transglutaminase 2. Biochem. J. 2016, 473, 3889–3901. [Google Scholar] [CrossRef]
- Jolly, C.; Morimoto, R.I. Role of the heat shock response and molecular chaperones in oncogenesis and cell death. J. Natl. Cancer Inst. 2000, 92, 1564–1572. [Google Scholar] [CrossRef]
- Mosser, D.D.; Caron, A.W.; Bourget, L.; Meriin, A.B.; Sherman, M.Y.; Morimoto, R.I.; Massie, B. The chaperone function of hsp70 is required for protection against stress-induced apoptosis. Mol. Cell. Biol. 2000, 20, 7146–7159. [Google Scholar] [CrossRef] [Green Version]
- Takayama, S.; Reed, J.C.; Homma, S. Heat-shock proteins as regulators of apoptosis. Oncogene 2003, 22, 9041–9047. [Google Scholar] [CrossRef] [PubMed]
- Ajit Tamadaddi, C.; Sahi, C. J domain independent functions of J proteins. Cell. Stress Chaperones 2016, 21, 563–570. [Google Scholar] [CrossRef] [PubMed]
- Crnogorac-Jurcevic, T.; Gangeswaran, R.; Bhakta, V.; Capurso, G.; Lattimore, S.; Akada, M.; Sunamura, M.; Prime, W.; Campbell, F.; Brentnall, T.A.; et al. Proteomic analysis of chronic pancreatitis and pancreatic adenocarcinoma. Gastroenterology 2005, 129, 1454–1463. [Google Scholar] [CrossRef] [PubMed]
- Sambrook, J.; Russell, D.W. Molecular Cloning: A Laboratory Manual; Cold Spring Harbor Laboratory Press: Cold Spring Harbor, NY, USA, 2001. [Google Scholar]
- Thomsen, R.; Christensen, M.H. MolDock: A new technique for high-accuracy molecular docking. J. Med. Chem. 2006, 49, 3315–3321. [Google Scholar] [CrossRef]
- Kelley, L.A.; Mezulis, S.; Yates, C.M.; Wass, M.N.; Sternberg, M.J.E. The Phyre2 web portal for protein modeling, prediction and analysis. Nat. Protoc. 2015, 10, 845–858. [Google Scholar] [CrossRef]
- Backman, T.W.; Cao, Y.; Girke, T. ChemMine tools: An online service for analyzing and clustering small molecules. Nucleic Acids Res. 2011, 39, W486–W491. [Google Scholar] [CrossRef]
- Worley, B.; Powers, R. Deterministic multidimensional nonuniform gap sampling. J. Magn. Reson 2015, 261, 19–26. [Google Scholar] [CrossRef]
- Ying, J.; Delaglio, F.; Torchia, D.A.; Bax, A. Sparse multidimensional iterative lineshape-enhanced (SMILE) reconstruction of both non-uniformly sampled and conventional NMR data. J. Biomol. NMR 2017, 68, 101–118. [Google Scholar] [CrossRef]
- Delaglio, F.; Grzesiek, S.; Vuister, G.W.; Zhu, G.; Pfeifer, J.; Bax, A. NMRPipe: A multidimensional spectral processing system based on UNIX pipes. J. Biomol. NMR 1995, 6, 277–293. [Google Scholar] [CrossRef]
- Maciejewski, M.W.; Schuyler, A.D.; Gryk, M.R.; Moraru, I.I.; Romero, P.R.; Ulrich, E.L.; Eghbalnia, H.R.; Livny, M.; Delaglio, F.; Hoch, J.C. NMRbox: A Resource for Biomolecular NMR Computation. Biophys. J. 2017, 112, 1529–1534. [Google Scholar] [CrossRef] [Green Version]
- Vranken, W.F.; Boucher, W.; Stevens, T.J.; Fogh, R.H.; Pajon, A.; Llinas, M.; Ulrich, E.L.; Markley, J.L.; Ionides, J.; Laue, E.D. The CCPN data model for NMR spectroscopy: Development of a software pipeline. Proteins Struct. Funct. Bioinform. 2005, 59, 687–696. [Google Scholar] [CrossRef] [PubMed]
- Shen, Y.; Vernon, R.; Baker, D.; Bax, A. De novo protein structure generation from incomplete chemical shift assignments. J. Biomol. NMR 2009, 43, 63–78. [Google Scholar] [CrossRef] [PubMed]
- Shen, Y.; Lange, O.; Delaglio, F.; Rossi, P.; Aramini, J.M.; Liu, G.; Eletsky, A.; Wu, Y.; Singarapu, K.K.; Lemak, A.; et al. Consistent blind protein structure generation from NMR chemical shift data. Proc. Natl. Acad. Sci. USA 2008, 105, 4685–4690. [Google Scholar] [CrossRef]
- Schwieters, C.D.; Kuszewski, J.J.; Tjandra, N.; Marius Clore, G. The Xplor-NIH NMR molecular structure determination package. J. Magn. Reson. 2003, 160, 65–73. [Google Scholar] [CrossRef]
- Schwieters, C.D.; Kuszewski, J.J.; Clore, G.M. Using Xplor-NIH for NMR Molecular Structure Determination. ChemInform 2006, 48, 47–62. [Google Scholar]
- Shen, Y.; Delaglio, F.; Cornilescu, G.; Bax, A. TALOS+: A hybrid method for predicting protein backbone torsion angles from NMR chemical shifts. J. Biomol. NMR 2009, 44, 213–223. [Google Scholar] [CrossRef]
- Bhattacharya, A.; Tejero, R.; Montelione, G.T. Evaluating protein structures determined by structural genomics consortia. Proteins 2007, 66, 778–795. [Google Scholar] [CrossRef]
- Pettersen, E.F.; Goddard, T.D.; Huang, C.C.; Couch, G.S.; Greenblatt, D.M.; Meng, E.C.; Ferrin, T.E. UCSF Chimera--a visualization system for exploratory research and analysis. J. Comput Chem. 2004, 25, 1605–1612. [Google Scholar] [CrossRef]
- Shevchenko, A.; Tomas, H.; Havli, J.; Olsen, J.V.; Mann, M. In-gel digestion for mass spectrometric characterization of proteins and proteomes. Nat. Protoc. 2006, 1, 2856–2860. [Google Scholar] [CrossRef]
- Consortium, T.U. UniProt: The universal protein knowledgebase in 2021. Nucleic Acids Res. 2020, 49, D480–D489. [Google Scholar] [CrossRef]
- Robinson, C.R.; Sauer, R.T. Optimizing the stability of single-chain proteins by linker length and composition mutagenesis. Proc. Natl. Acad. Sci. USA 1998, 95, 5929–5934. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Reddy Chichili, V.P.; Kumar, V.; Sivaraman, J. Linkers in the structural biology of protein-protein interactions. Protein Sci. 2013, 22, 153–167. [Google Scholar] [CrossRef] [PubMed]
- Yan, W.; Craig, E.A. The glycine-phenylalanine-rich region determines the specificity of the yeast Hsp40 Sis1. Mol. Cell. Biol. 1999, 19, 7751–7758. [Google Scholar] [CrossRef]
- George, R.A.; Heringa, J. An analysis of protein domain linkers: Their classification and role in protein folding. Protein Eng. Des. Sel. 2002, 15, 871–879. [Google Scholar] [CrossRef] [PubMed]
- Schultes, S.; de Graaf, C.; Haaksma, E.E.J.; de Esch, I.J.P.; Leurs, R.; Krämer, O. Ligand efficiency as a guide in fragment hit selection and optimization. Drug Discov. Today Technol. 2010, 7, e157–e162. [Google Scholar] [CrossRef]
- Mercier, K.A.; Shortridge, M.D.; Powers, R. A multi-step NMR screen for the identification and evaluation of chemical leads for drug discovery. Comb. Chem. High Throughput Screen. 2009, 12, 285–295. [Google Scholar] [CrossRef]
- Greene, M.K.; Maskos, K.; Landry, S.J. Role of the J-domain in the cooperation of Hsp40 with Hsp70. Proc. Natl. Acad. Sci. USA 1998, 95, 6108–6113. [Google Scholar] [CrossRef]
- Genevaux, P.; Schwager, F.; Georgopoulos, C.; Kelley, W.L. Scanning mutagenesis identifies amino acid residues essential for the in vivo activity of the Escherichia coli DnaJ (Hsp40) J-domain. Genetics 2002, 162, 1045–1053. [Google Scholar] [CrossRef]
- Kurmi, K.; Hitosugi, S.; Yu, J.; Boakye-Agyeman, F.; Wiese, E.K.; Larson, T.R.; Dai, Q.; Machida, Y.J.; Lou, Z.; Wang, L.; et al. Tyrosine Phosphorylation of Mitochondrial Creatine Kinase 1 Enhances a Druggable Tumor Energy Shuttle Pathway. Cell Metab. 2018, 28, 833–847.e8. [Google Scholar] [CrossRef]
- Ahn, B.Y.; Trinh, D.L.N.; Zajchowski, L.D.; Lee, B.; Elwi, A.N.; Kim, S.W. Tid1 is a new regulator of p53 mitochondrial translocation and apoptosis in cancer. Oncogene 2010, 29, 1155–1166. [Google Scholar] [CrossRef]
- Yang, Z.; Cheng, W.; Hong, L.; Chen, W.; Wang, Y.; Lin, S.; Han, J.; Zhou, H.; Gu, J. Adenine nucleotide (ADP/ATP) translocase 3 participates in the tumor necrosis factor induced apoptosis of MCF-7 cells. Mol. Biol. Cell 2007, 18, 4681–4689. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, G.; Zhu, J.; Yu, M.; Cai, C.; Zhou, Y.; Yu, M.; Fu, Z.; Gong, Y.; Yang, B.; Li, Y.; et al. Glutamate dehydrogenase is a novel prognostic marker and predicts metastases in colorectal cancer patients. J. Transl. Med. 2015, 13, 144. [Google Scholar] [CrossRef] [PubMed] [Green Version]




{kind=link}
{kind=link}
{kind=link}
| <SA> a | b | |
|---|---|---|
| RMSD for distance restraints (experimental) (Å) | ||
| All (1143) | 0.094 ± 0.006 | 0.078 |
| Inter-residue sequential (|i − j| = 1) (260) | 0.066 ± 0.005 | 0.069 |
| Inter-residue short-range (1 < |i − j| < 5) (274) | 0.079 ± 0.007 | 0.084 |
| Inter-residue long-range (|i − j| ≥ 5) (84) | 0.098 ± 0.005 | 0.104 |
| Intraresidue (525) | 0.108 ± 0.009 | 0.079 |
| H-bonds (23) | 0.015 ± 0.003 | 0.010 |
| RMSD for dihedral angle restraints (deg) (176) | 0.844 ± 0.117 | 1.068 |
| RMSD for 3JNHα restraints (Hz) (39) | 0.897 ± 0.047 | 0.923 |
| RMSD (covalent geometry) | ||
| Bonds (Å) | 0.007 ± 0.000 | 0.007 |
| Angles (deg) | 0.727 ± 0.019 | 0.742 |
| Impropers (deg) | 1.072 ± 0.020 | 1.060 |
| energy (kcal/mol) | ||
| Total | −3131.62 ± 104.82 | −3446.54 |
| Bonds | 38.70 ± 2.50 | 39.70 |
| Angles | 160.06 ± 9.35 | 162.09 |
| Dihedrals | 8.73 ± 2.24 | 7.43 |
| Impropers | 66.45 ± 6.32 | 68.53 |
| Van der Waals | −241.02 ± 11.94 | −216.43 |
| NOE | 108.92 ± 11.60 | 122.25 |
| 3JNHα | 30.73 ± 11.60 | 33.20 |
| PSVS Z-Score (Ordered Residues a) | |
|---|---|
| Verify3D | −2.25 |
| ProsaII (-ve) | 0.83 |
| Procheck (φ and ψ) | 0.63 |
| Procheck (all) | 0.18 |
| MolProbity clash score | −2.64 |
| Ramachandran space (all residues) | |
| Most favored regions | 90.5% |
| Additionally allowed regions | 9.5% |
| Disallowed regions | 0% |
| Compound Name | LE Score | 1D Hits a | 2D Hits b | Perturbed Residues |
|---|---|---|---|---|
| Adenosine 5′-diphosphate | −3.32 | X | X | 38K, 40A, 43Y, 44H, 46D, 51E, 58I, 59S, 95M, 96D, 111E |
| O-phospho-L-serine | −1.73 | X | X | 38K, 40A, 43Y, 44H, 46D, 51E, 58I, 59S, 77G, 80Q, 93S, 96D, 111E |
| Dihydroxyacetone phosphate | −1.53 | X | X | 38K, 44H, 46D, 51E, 96D, 111E |
| O-phospho-L-Tyrosine | 1.76 | X | X | 30E, 38K, 40A, 41L, 43Y, 44H, 46D, 50N, 52G, 58I, 59S, 77G, 93S, 103G, 111E |
| Hit2Lead ID | Compound Name | 1D Hits a | 2D Hits b | LE Score | Perturbed Residues | KD (μM) c |
|---|---|---|---|---|---|---|
| 7727968 | 6-(4-ethoxyphenyl)-1,3-dimethyl-4-oxo-4H-cyclohepta[c]furan-8-yl 2-thiophenecarboxylate | X | X | 1.76 | 117V, 21L, 38K, 44H, 46D, 59S | 10 ± 85 |
| 7912207 | N-{5-[(diethylamino)sulfonyl]-2-methoxyphenyl}-2-methoxybenzamide | X | X | 1.76 | 40A, 44H, 46D, 51E, 58I, 59S, 93S, 96D | N.D. |
| 9042610 | N-(5-chloro-2-methoxyphenyl)-2-[4-(3-methoxyphenyl)-1-piperazinyl]acetamide | X | X | −1.73 | 38K, 40A, 43Y, 44H, 46D, 51E, 58I | N.D. |
| 9080132 | N-(3-methylphenyl)-4-(5-methyl-1H-1,2,3-triazol-1-yl)benzamide | X | X | −3.32 | 38K, 40A, 44H, 46D, 51E, 58I, 93S, 96D | N.D. |
| 9101204 | 1-[(5-bromo-2-thienyl)carbonyl]-4-(4-fluorophenyl)piperazine | X | X | −3.32 | 27A, 38K, 46D, 58I, 59S, 79E, 96D, 117V | 0.1 ± 0.3 |
| UniProt ID | Gene | Protein | Localization | Matched Peptides | Sequence Coverage (%) |
|---|---|---|---|---|---|
| P12236 | SLC25A6 | ADP/ATP translocase 3 | mitochondria | 1 | 10.1 |
| P23246 | SFPQ | Splicing factor, proline- and glutamine-rich | nucleus | 22 | 30 |
| P14136 | GFAP | Glial fibrillary acidic protein | cytoplasm | 4 | 12.5 |
| P02545 | LMNA | Prelamin-A/C | nucleus | 34 | 52.7 |
| Q15233 | NONO | Non-POU domain-containing octamer-binding protein | nucleus | 11 | 20.4 |
| P00367 | GLUD1 | Glutamate dehydrogenase 1, mitochondrial | mitochondria | 18 | 28.7 |
| Q8WV22 | NSMCE1 | Non-structural maintenance of chromosomes element 1 homolog | nucleus | 6 | 12.4 |
| P12532 | CKMT1A | Creatine kinase U-type, mitochondrial | mitochondria | 9 | 22.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Roth, H.E.; De Lima Leite, A.; Palermo, N.Y.; Powers, R. Leveraging the Structure of DNAJA1 to Discover Novel Potential Pancreatic Cancer Therapies. Biomolecules 2022, 12, 1391. https://doi.org/10.3390/biom12101391
Roth HE, De Lima Leite A, Palermo NY, Powers R. Leveraging the Structure of DNAJA1 to Discover Novel Potential Pancreatic Cancer Therapies. Biomolecules. 2022; 12(10):1391. https://doi.org/10.3390/biom12101391
Chicago/Turabian StyleRoth, Heidi E., Aline De Lima Leite, Nicolas Y. Palermo, and Robert Powers. 2022. "Leveraging the Structure of DNAJA1 to Discover Novel Potential Pancreatic Cancer Therapies" Biomolecules 12, no. 10: 1391. https://doi.org/10.3390/biom12101391