
Probing the Metabolic Landscape of Plant Vascular Bundles by Infrared Fingerprint Analysis, Imaging and Mass Spectrometry


Abstract
:1. Introduction
2. Materials and Methods
2.1. Plant Cultivation
2.2. Sample Preparation and LC-MS Analysis
2.3. FTIR Spectroscopy
2.4. FTIR Imaging and Sample Preparation
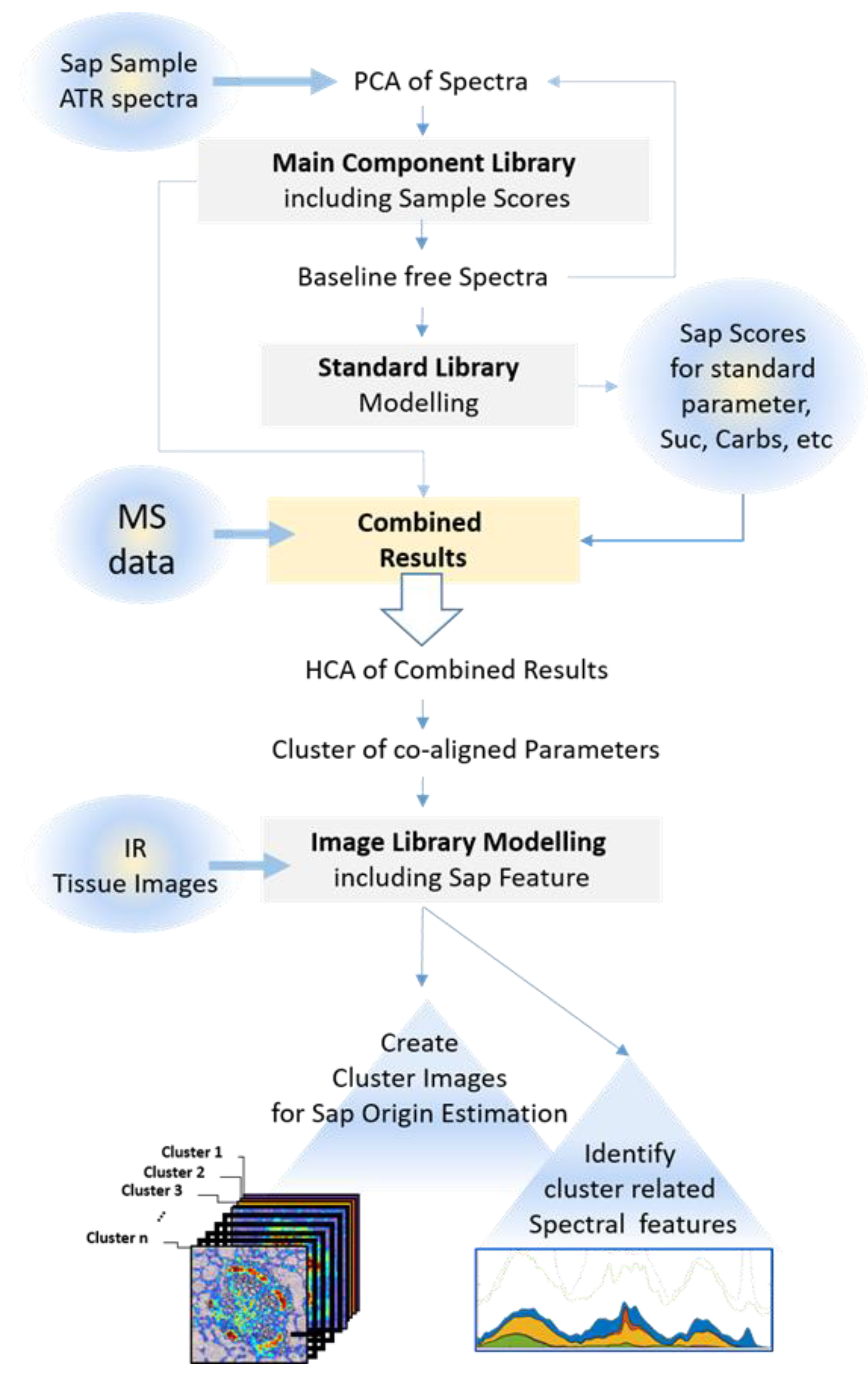
2.5. Data Processing
3. Results and Discussion
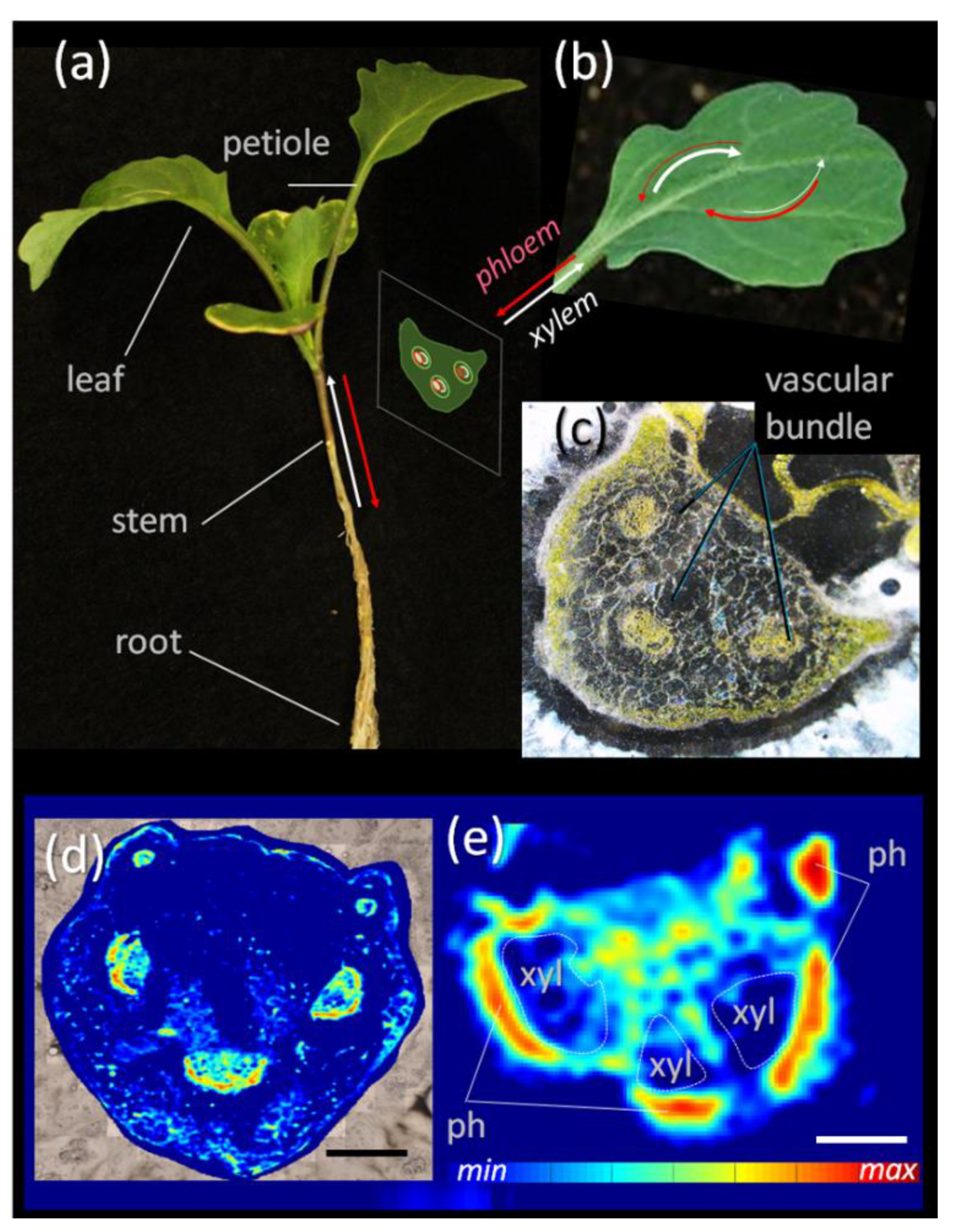
3.1. Sucrose Mapping of Vascular Bundles
3.2. Experimental Design and Workflow of the Novel Procedure
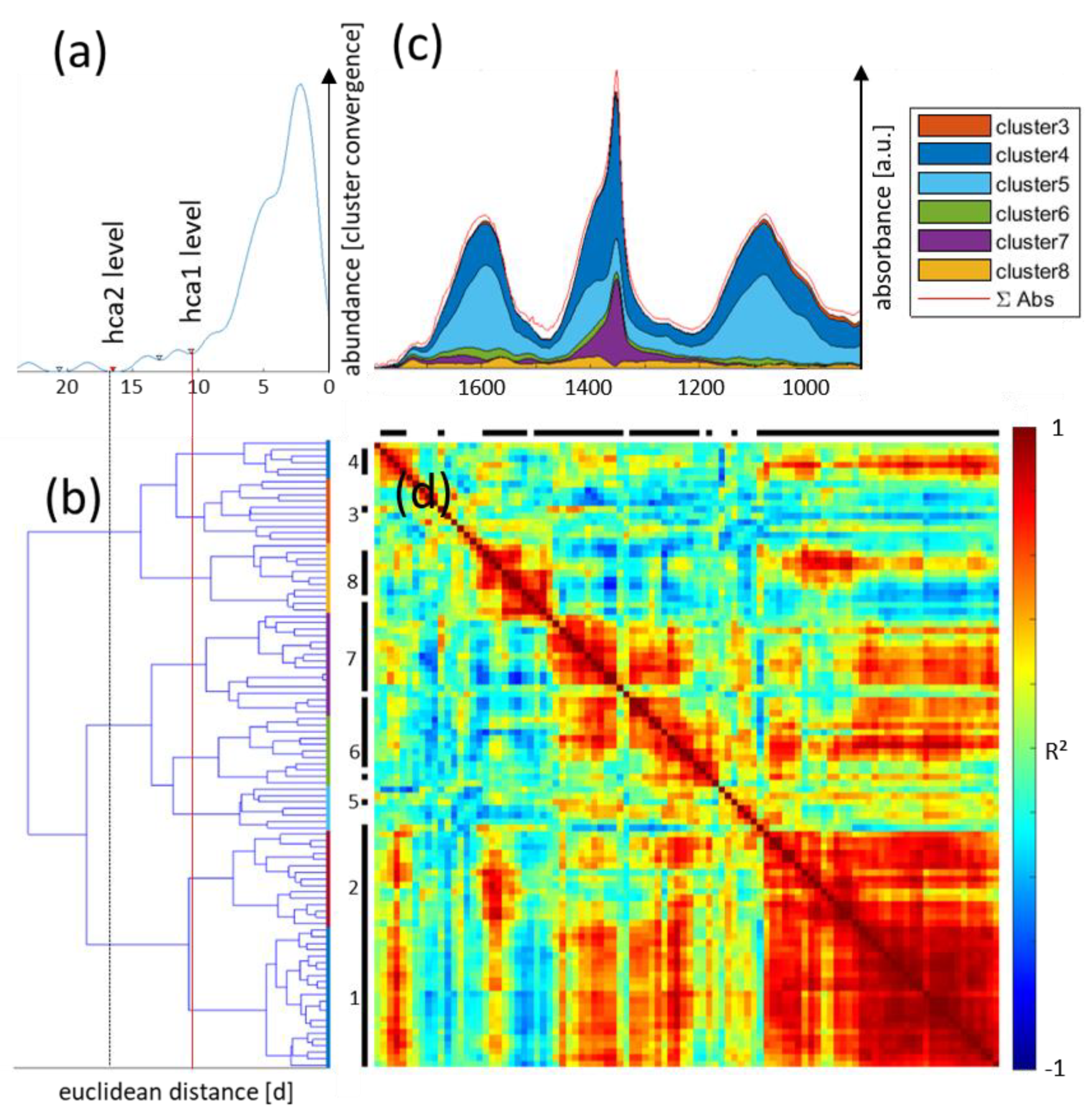
3.3. Sap IR Band Assignment
3.4. Sap MS Components
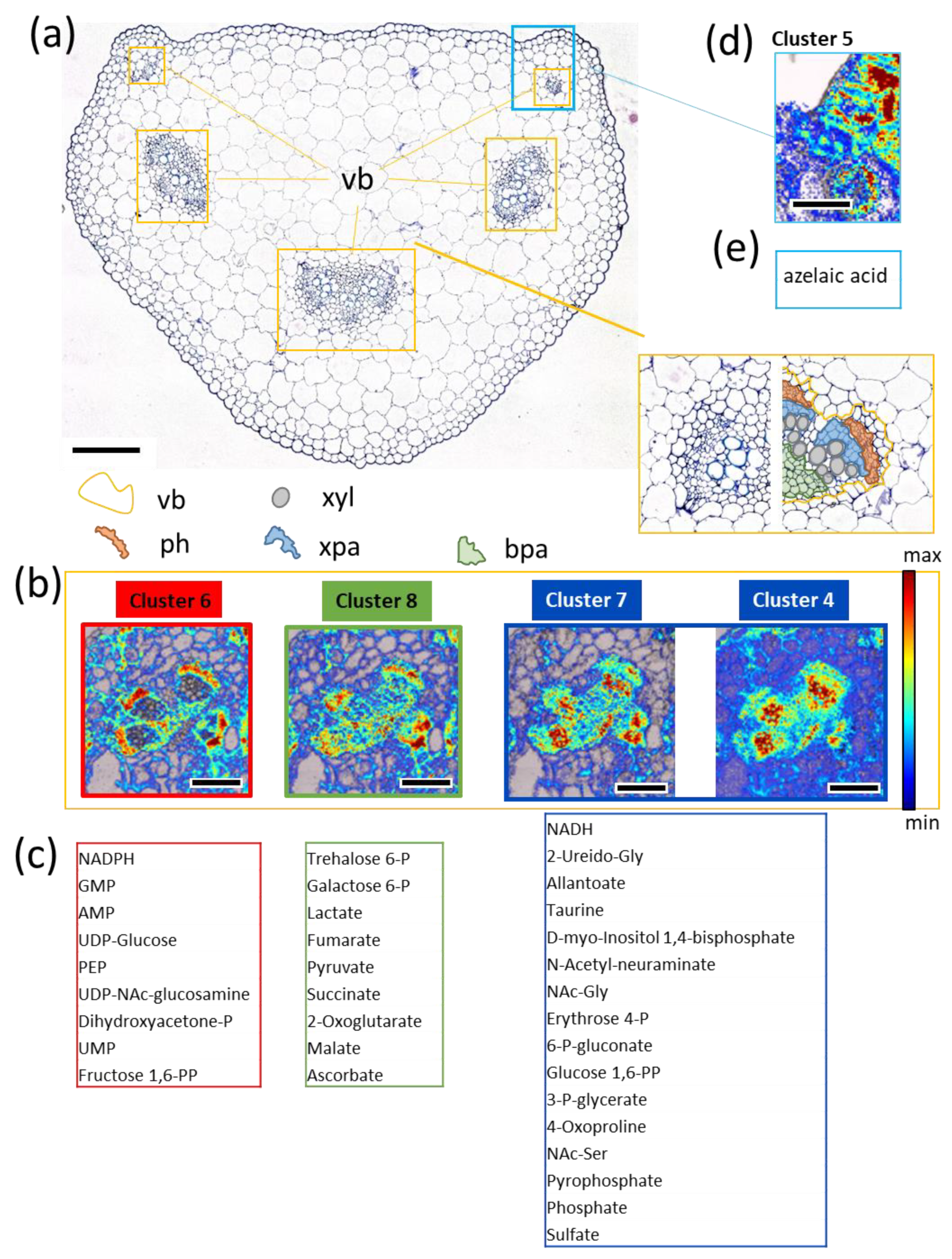
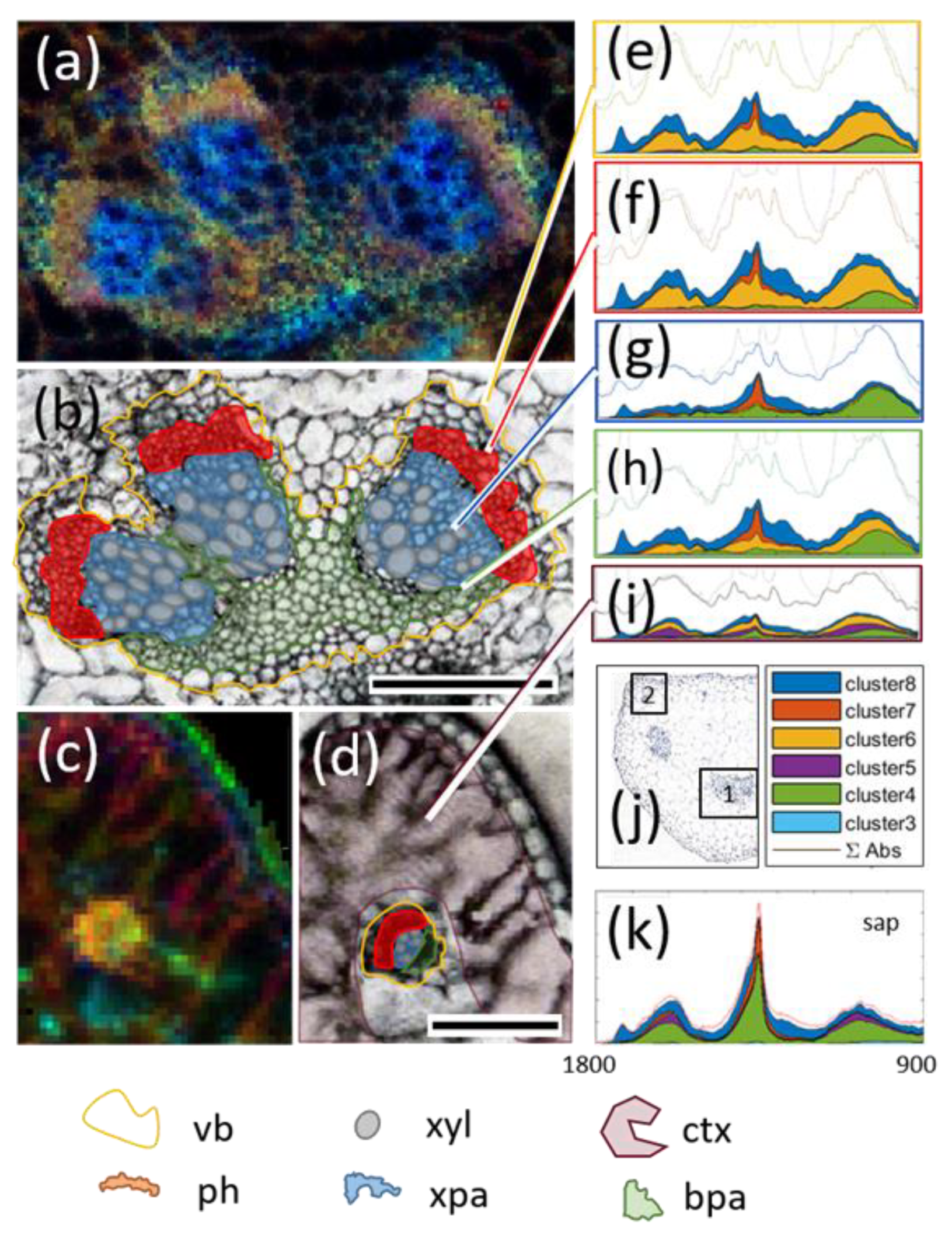
3.5. FTIR Imaging of Metabolic Clusters
3.6. Potential Biological Relevance of Chemometric Analysis and Metabolic Clusters in Vasculature
3.7. Multicluster Imaging Reflects the Functional Arrangement of Vascular Bundles
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Balan, V.; Mihai, C.T.; Cojocaru, F.D.; Uritu, C.M.; Dodi, G.; Botezat, D.; Gardikiotis, I. Vibrational spectroscopy fingerprinting in medicine: From molecular to clinical PRACTICE. Materials 2019, 12, 2884. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lovergne, L.; Ghosh, D.; Schuck, R.; Polyzos, A.A.; Chen, A.D.; Martin, M.C.; Barnard, E.S.; Brown, J.B.; McMurray, C.T. An infrared spectral biomarker accurately predicts neurodegenerative disease class in the absence of overt symptoms. Sci. Rep. 2021, 11, 15598. [Google Scholar] [CrossRef]
- Yang, S.; Li, C.; Mei, Y.; Liu, W.; Liu, R.; Chen, W.; Han, D.; Xu, K. Determination of the geographical origin of coffee beans using terahertz spectroscopy combined with machine learning methods. Front. Nutr. 2021, 8, 680627. [Google Scholar] [CrossRef]
- Krivoshein, P.K.; Dmitry, S.; Volkova, O.; Rogova, B.; Proskurnin, M.A. FTIR photoacoustic spectroscopy for identification and assessment of soil components: Chernozems and their size fractions. Photoacoustics 2020, 18, 1001623. [Google Scholar] [CrossRef] [PubMed]
- Munz, E.; Rolletschek, H.; Oeltze-Jafra, S.; Fuchs, J.; Guendel, A.; Neuberger, T.; Ortleb, S.; Jakob, P.M.; Borisjuk, L. A functional imaging study of germinating oilseed rapeseed. New Phytol. 2017, 216, 1181–1190. [Google Scholar] [CrossRef] [Green Version]
- Guendel, A.; Rolletschek, H.; Wagner, S.; Muszynska, A.; Borisjuk, L. Micro imaging displays the sucrose landscape within and along its allocation pathways. Plant Physiol. 2018, 178, 1448–1460. [Google Scholar] [CrossRef] [Green Version]
- Walerowski, P.; Gündel, A.; Yahaya, N.; Truman, W.; Sobczak, M.; Olszak, M.; Rolfe, S.A.; Borisjuk, L.; Malinowski, R. Clubroot disease stimulates early steps of phloem differentiation and recruits SWEET sucrose transporters within developing galls. Plant Cell 2018, 30, 3058–3073. [Google Scholar] [CrossRef] [Green Version]
- Holbrook, N.M.; Zwieniecki, M.A. (Eds.) Vascular Transport in Plants; Elsevier Academic Press: Amsterdam, The Netherlands, 2005; 564p. [Google Scholar]
- Windt, C.W.; Vergeldt, F.J.; De Jager, P.A.; Van As, H. MRI of long-distance water transport: A comparison of the phloem and xylem flow characteristics and dynamics in poplar, castor bean, tomato and tobacco. Plant Cell Environ. 2006, 29, 1715–1729. [Google Scholar] [CrossRef]
- Lucas, W.J.; Groover, A.; Lichtenberger, R.; Furuta, K.; Yadav, S.R.; Helariutta, Y.; He, X.Q.; Fukuda, H.; Kang, J.; Brady, S.M.; et al. The plant vascular system: Evolution, development and functions. J. Integr. Plant Biol. 2013, 55, 294–388. [Google Scholar] [CrossRef]
- King, R.W.; Zeevaart, J.A. Enhancement of phloem exudation from cut petioles by chelating-agents. Plant Physiol. 1974, 53, 96–103. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Giavalisco, P.; Kapitza, K.; Kolasa, A.; Buhtz, A.; Kehr, J. Towards the proteome of Brassica napus phloem sap. Proteomics 2006, 6, 896–909. [Google Scholar] [CrossRef]
- Tetyuk, O.; Benning, U.; Hoffmann-Benning, S. Collection and analysis of Arabidopsis phloem exudates using the EDTA-facilitated method. J. Vis. Exp. 2013, 80, 51111. [Google Scholar] [CrossRef] [Green Version]
- Fisher, D.B.; Wu, Y.; Ku, M.S.B. Turnover of soluble-proteins in the wheat sieve tube. Plant Physiol. 1992, 100, 1433–1441. [Google Scholar] [CrossRef] [Green Version]
- Pahlow, S.; Ostendorp, A.; Krüßel, L.; Kehr, J. Phloem sap sampling from Brassica napus for 3D-PAGE of protein and ribonucleoprotein complexes. J. Vis. Exp. 2018, 131, e57097. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Van Bel, A.J.E. The phloem, a miracle of ingenuity. Plant Cell Environ. 2003, 26, 125–149. [Google Scholar] [CrossRef]
- Thompson, M.V. Phloem: The long and the short of it. Trends Plant Sci. 2006, 11, 26–32. [Google Scholar] [CrossRef]
- Boughton, B.A.; Thinagaran, D.; Sarabia, D.; Bacic, A.; Roessner, U. Mass spectrometry imaging for plant biology: A review. Phytochem. Rev. 2016, 15, 445–488. [Google Scholar] [CrossRef] [Green Version]
- Radchuk, V.; Tran, V.; Hilo, A.; Muszynska, A.; Gündel, A.; Wagner, S.; Fuchs, J.; Hensel, G.; Ortleb, S.; Munz, E.; et al. Grain filling in cereals relies on developmentally controlled programmed cell death. Commun. Biol. 2021, 4, 428. [Google Scholar] [CrossRef] [PubMed]
- Trevasian, J.; Angelov, P.P.; Carmichael, P.L.; Martin, F.L. IRootLab: A free and open-source MATLAB toolbox for vibrational biospectroscopy data analysis. Bioinformatics 2013, 29, 1095–1097. [Google Scholar] [CrossRef]
- Baker, M.J.; Trevisan, J.; Bassan, P.; Bhargava, R.; Butler, H.J.; Dorling, K.M.; Fielden, P.R.; Fogarty, S.W.; Fullwood, N.J.; Heys, K.A.; et al. Using Fourier transform IR spectroscopy to analyze biological materials. Nat. Protoc. 2014, 9, 1771–1791. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lohaus, G.; Moellers, C. Phloem transport of amino acids in two Brassica napus L. genotypes and one B. carinata genotype in relation to their seed protein content. Planta 2000, 211, 833–840. [Google Scholar] [CrossRef] [PubMed]
- Garg, V.; Kühn, C. What determines the composition of the phloem sap? Is there any selectivity filter for macromolecules entering the phloem sieve elements? Plant Physiol. Biochem. 2020, 151, 284–291. [Google Scholar] [CrossRef]
- Van Bel, A.J. Interaction between sieve element and companion cell and the consequences for photoassimilate distribution. Two structural hardware frames with associated physiological software packages in dicotyledons? J. Exp. Bot. 1996, 47, 1129–1140. [Google Scholar] [CrossRef] [PubMed]
- Figueroa, C.M.; Lunn, J.E.; Iglesias, A.A. Nucleotide-sugar metabolism in plants: The legacy of Luis F. Leloir. J. Exp. Bot. 2021, 72, 4053–4067. [Google Scholar] [CrossRef]
- Hoch, G. Cell wall hemicelluloses as mobile carbon stores in non-reproductive plant tissues. Funct. Ecol. 2007, 21, 823–834. [Google Scholar] [CrossRef]
- Kubacka-Zebalska, M.; Kacperska, A. Low temperature-induced modifications of cell wall content and polysaccharide com-posi-tion in leaves of winter oilseed rape (Brassica napus L. var. oleifera L.). Plant Sci. 1999, 148, 56–67. [Google Scholar] [CrossRef]
- Lough, T.J.; Lucas, W.J. Integrative plant biology: Role of phloem long-distance macromolecular trafficking. Annu. Rev. Plant Biol. 2006, 57, 203–232. [Google Scholar] [CrossRef] [Green Version]
- Rabe, J.H.; Sammour, D.A.; Schulz, S.; Munteanu, B.; Ott, M.; Ochs, K.; Hohenberger, P.; Marx, A.; Platten, M.; Opitz, C.A.; et al. Fourier transform infrared microscopy enables guidance of automated mass spectrometry imaging to predefined tissue orphologies. Sci. Rep. 2018, 8, 313. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image Cluster 1 | Image Cluster 2 | Image Cluster 3 | Image Cluster 4 | ||||
|---|---|---|---|---|---|---|---|
| RGB Channel in Multi Component Images | |||||||
| blue | green | red | |||||
| sap cluster id | [abs/abs] | sap cluster id | [abs/ abs] | sap cluster id | [abs/abs] | sap cluster id | [abs/abs] |
| cluster 4 cluster 7 | 0.0768 0.0185 | cluster 8 | 0.1068 | cluster 3 cluster 5 | 0.0019 0.0115 | cluster 6 | 0.1093 |
| correlated IR library features | |||||||
| Total Protein Protein Type 1 | 0.0149 0.0082 | 2nd Metab. | 0.0802 | Cell wall | 0.0291 | Carb Soluble sugar Hexoses Bound water Amino acids 2nd Metab. | 0.0873 0.0479 0.0285 0.0532 0.0756 0.0401 |
| IC-MS sap features correlated with sap IR freatures | |||||||
| NADH 2-Ureido-Gly Allantoate Taurine D-myo-Inositol 1,4-bisphosphate N-acetyl-neuraminate NAc-Gly Erythrose 4-P 6-P-gluconate Glucose 1,6-PP 3-P-glycerate 4-Oxoproline NAc-Ser Pyrophosphate Phosphate Sulphate | Trehalose 6-P Galactose 6-P Lactate Fumerate Pyruvate Succinate 2-Oxoglutarate Malate Ascorbate | Allantoin Oxaloacetate Mevalonic acid-5P Isocitrate Azelaic acid | NADPH AMP GMP UMP UDP-Glucose UDP-NAc-glucosamine PEP Dihydroxyacetone-P Fructose 1,6-PP | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guendel, A.; Hilo, A.; Rolletschek, H.; Borisjuk, L. Probing the Metabolic Landscape of Plant Vascular Bundles by Infrared Fingerprint Analysis, Imaging and Mass Spectrometry. Biomolecules 2021, 11, 1717. https://doi.org/10.3390/biom11111717
Guendel A, Hilo A, Rolletschek H, Borisjuk L. Probing the Metabolic Landscape of Plant Vascular Bundles by Infrared Fingerprint Analysis, Imaging and Mass Spectrometry. Biomolecules. 2021; 11(11):1717. https://doi.org/10.3390/biom11111717
Chicago/Turabian StyleGuendel, André, Alexander Hilo, Hardy Rolletschek, and Ljudmilla Borisjuk. 2021. "Probing the Metabolic Landscape of Plant Vascular Bundles by Infrared Fingerprint Analysis, Imaging and Mass Spectrometry" Biomolecules 11, no. 11: 1717. https://doi.org/10.3390/biom11111717