
Differentiation of Geographical Origin of White and Brown Rice Samples Using NMR Spectroscopy Coupled with Machine Learning Techniques
 , , , and
, , , and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Rice Sample Collection
2.2. Chemicals and Reagents
2.3. Pre-Preparation and Extraction of Rice
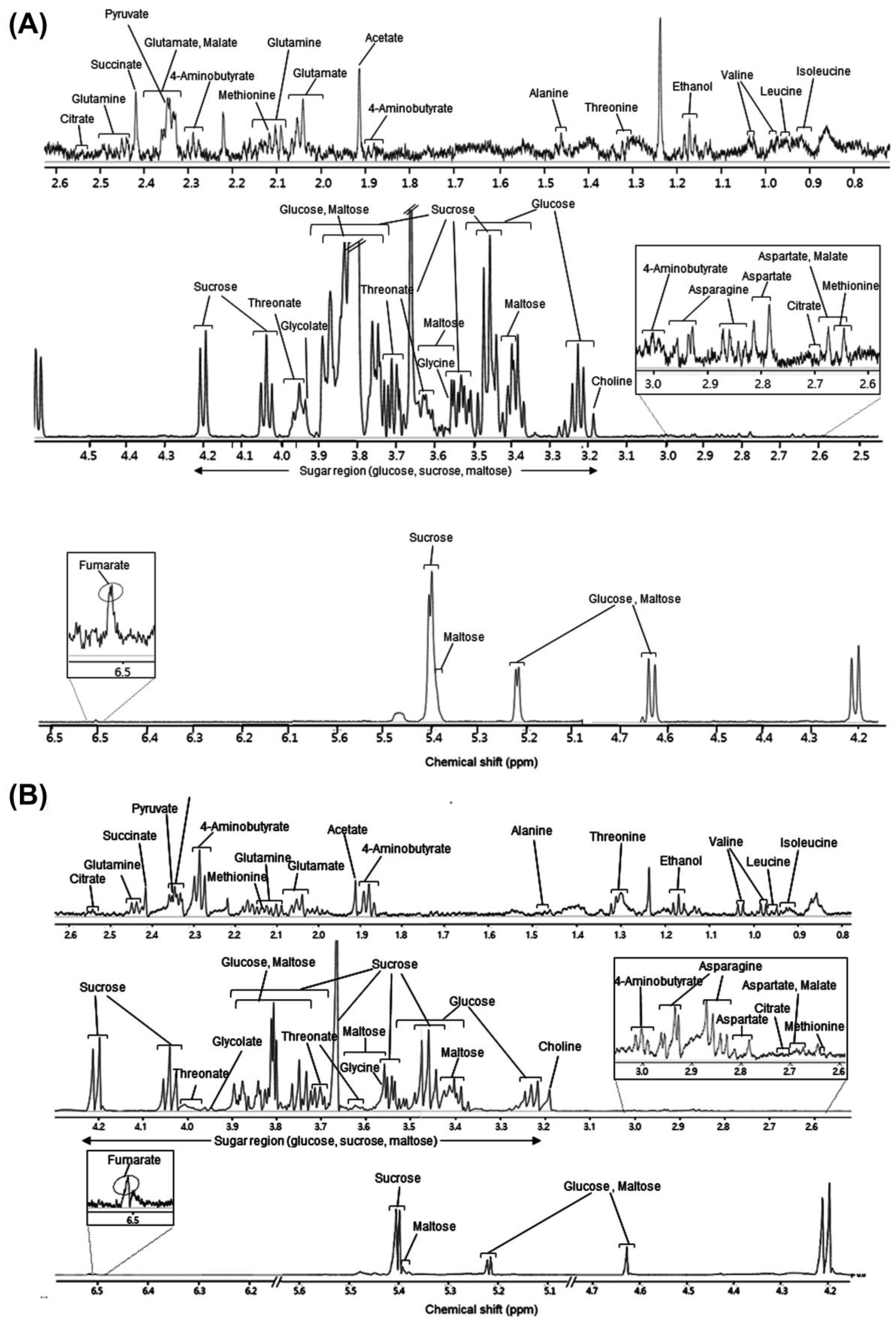
2.4. Peak NMR Spectra Assignment
2.5. NMR Data Pre-Processing and Measurement
2.6. Statistical Analysis
2.7. Development of Differentiation Models and ML Algorithms
3. Results and Discussion
3.1. Identification of Metabolites in Rice
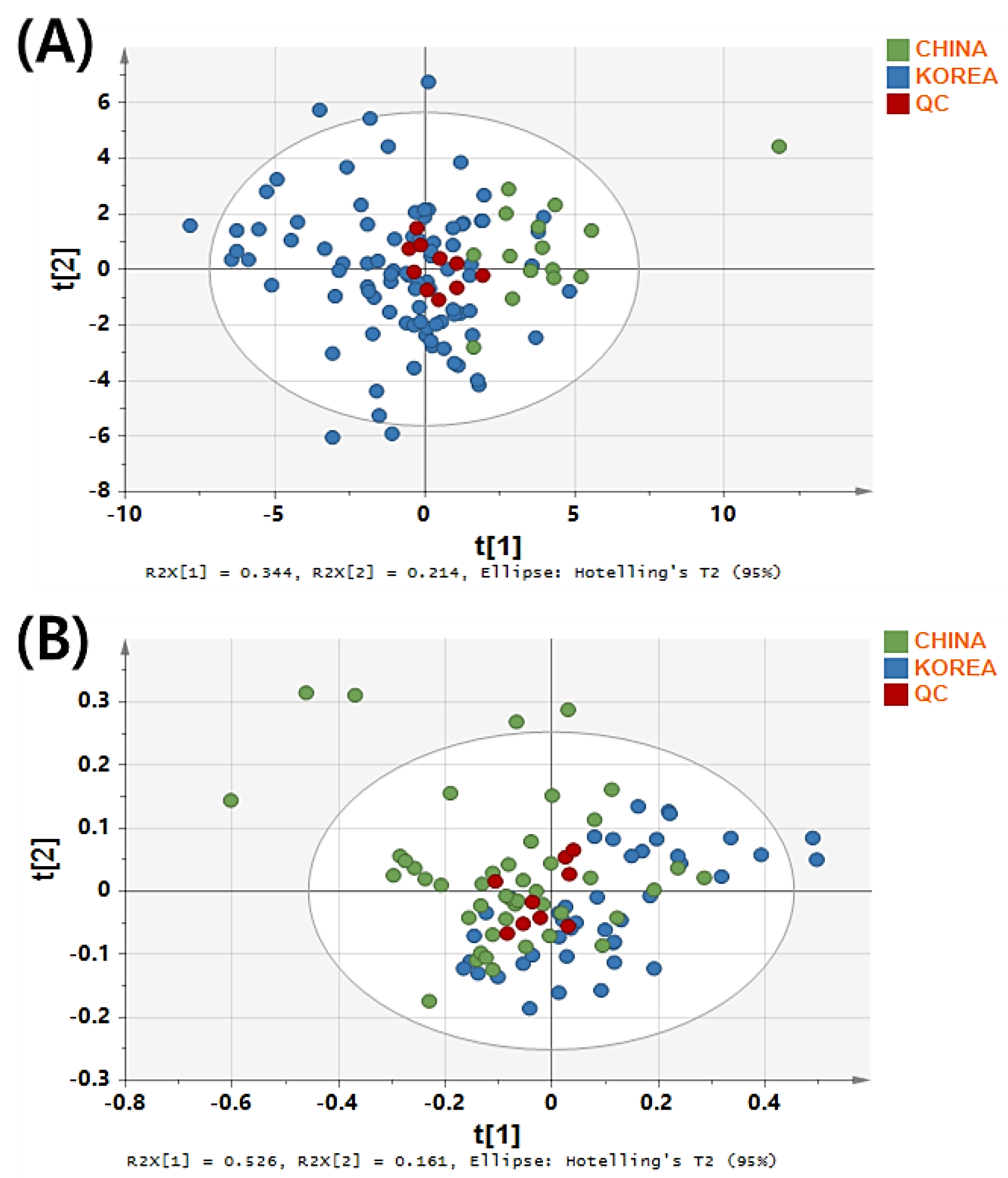
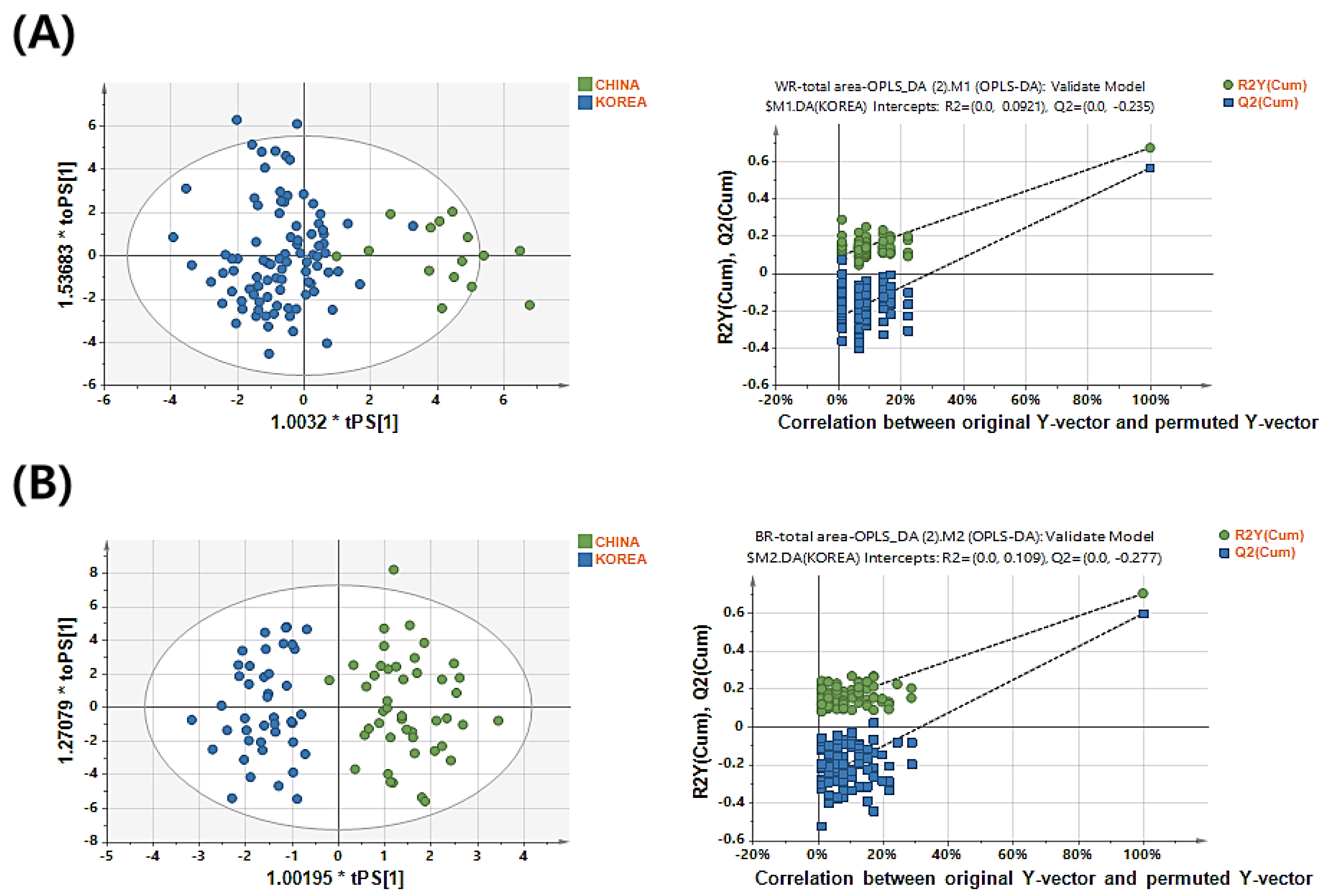
3.2. PCA Model Establishment for Predicting the Geographical Origin of Rice
3.3. Comparing ML Models for Predicting the Geographical Origin of Rice
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AUC | area under the curve |
| COSY | correlation spectroscopy |
| HMDB | Human Metabolome Database |
| HSQC | heteronuclear single quantum correlation |
| NMR | nuclear magnetic resonance |
| OPLS-DA | orthogonal partial least square–discriminant analysis |
| Par | Pareto |
| PCA | principal component analysis |
| PLS-DA | partial least square–discriminant analysis |
| RF | random forest |
| ROC | receiver operating characteristic |
| SVM | support vector machine |
| UV | unit variance |
References
- Cheajesadagul, P.; Arnaudguilhem, C.; Shiowatana, J.; Siripinyanond, A.; Szpunar, J. Discrimination of geographical origin of rice based on multi-element fingerprinting by high resolution inductively coupled plasma mass spectrometry. Food Chem. 2013, 141, 3504–3509. [Google Scholar] [CrossRef]
- Song, E.-H.; Kim, H.-J.; Jeong, J.; Chung, H.-J.; Kim, H.-Y.; Bang, E.; Hong, Y.-S. A 1H HR-MAS NMR-based metabolomic study for metabolic characterization of rice grain from various Oryza Sativa L. cultivars. J. Agric. Food Chem. 2016, 64, 3009–3016. [Google Scholar] [CrossRef] [PubMed]
- Kang, Y.; Lee, B.M.; Lee, E.M.; Kim, C.-H.; Seo, J.-A.; Choi, H.-K.; Kim, Y.-S.; Lee, D.Y. Unique metabolic profiles of Korean rice according to polishing degree, variety, and geo-environmental factors. Foods 2021, 10, 711. [Google Scholar] [CrossRef] [PubMed]
- Śliwińska-Bartel, M.; Burns, D.T.; Elliott, C. Rice fraud a global problem: A review of analytical tools to detect species, country of origin and adulterations. Trends Food Sci. Technol. 2021, 116, 36–46. [Google Scholar] [CrossRef]
- Yang, S.O.; Lee, S.W.; Kim, Y.O.; Lee, S.W.; Kim, N.H.; Choi, H.K.; Jung, J.Y.; Lee, D.H.; Shin, Y.S. Comparative analysis of metabolites in roots of Panax Ginseng obtained from different sowing methods. Korean J. Med. Crop Sci. 2014, 22, 17–22. [Google Scholar] [CrossRef] [Green Version]
- Lee, B.-J.; Zhou, Y.; Lee, J.S.; Shin, B.K.; Seo, J.A.; Lee, D.; Kim, Y.S.; Choi, H.K. Discrimination and prediction of the origin of Chinese and Korean soybeans using fourier transform infrared spectrometry (FT-IR) with multivariate statistical analysis. PLoS ONE 2018, 13, e0196315. [Google Scholar] [CrossRef]
- D’Urso, G.; Montoro, P.; Lai, C.; Piacente, S.; Sarais, G. LC-ESI/LTQOrbitrap/MS based metabolomics in analysis of Myrtus Communis leaves from Sardinia (Italy). Ind. Crops Prod. 2019, 128, 354–362. [Google Scholar] [CrossRef]
- Dunn, W.B.; Ellis, D.I. Metabolomics: Current analytical platforms and methodologies. TrAC Trends Anal. Chem. 2005, 24, 285–294. [Google Scholar] [CrossRef]
- Promchan, J.; Günther, D.; Siripinyanond, A.; Shiowatana, J. Elemental imaging and classifying rice grains by using laser ablation inductively coupled plasma mass spectrometry and linear discriminant analysis. J. Cereal Sci. 2016, 71, 198–203. [Google Scholar] [CrossRef]
- Huo, Y.; Kamal, G.M.; Wang, J.; Liu, H.; Zhang, G.; Hu, Z.; Anwar, F.; Du, H. 1H NMR-based metabolomics for discrimination of rice from different geographical origins of China. J. Cereal Sci. 2017, 76, 243–252. [Google Scholar] [CrossRef]
- Monakhova, Y.B.; Rutledge, D.N.; Roßmann, A.; Waiblinger, H.-U.; Mahler, M.; Ilse, M.; Kuballa, T.; Lachenmeier, D.W. Determination of rice type by 1H NMR spectroscopy in combination with different chemometric tools. J. Chemom. 2013, 28, 83–92. [Google Scholar] [CrossRef]
- Lim, D.K.; Mo, C.; Lee, J.H.; Long, N.P.; Dong, Z.; Li, J.; Lim, J.; Kwon, S.W. The integration of multi-platform MS-based metabolomics and multivariate analysis for the geographical origin discrimination of Oryza Sativa L. J. Food Drug Anal. 2018, 26, 769–777. [Google Scholar] [CrossRef] [Green Version]
- Kwon, Y.-K.; Bong, Y.-S.; Lee, K.-S.; Hwang, G.-S. An integrated analysis for determining the geographical origin of medicinal herbs using ICP-AES/ICP-MS and 1H NMR analysis. Food Chem. 2014, 161, 168–175. [Google Scholar] [CrossRef] [PubMed]
- Klare, J.; Rurik, M.; Rottmann, E.; Bollen, A.; Kohlbacher, O.; Fischer, M.; Hackl, T. Determination of the geographical origin of Asparagus Officinalis L. by 1H NMR spectroscopy. J. Agric. Food Chem. 2020, 68, 14353–14363. [Google Scholar] [CrossRef]
- Li, Y.; Wang, X.; Li, C.; Huang, W.; Gu, K.; Wang, Y.; Yang, B.; Li, Y. Exploration of chemical markers using a metabolomics strategy and machine learning to study the different origins of Ixeris Denticulata (Houtt.) Stebb. Food Chem. 2020, 330, 127232. [Google Scholar] [CrossRef]
- Larios, G.; Nicolodelli, G.; Ribeiro, M.; Canassa, T.; Reis, A.R.; Oliveira, S.L.; Alves, C.Z.; Marangoni, B.S.; Cena, C. Soybean seed vigor discrimination by using infrared spectroscopy and machine learning algorithms. Anal. Methods 2020, 12, 4303–4309. [Google Scholar] [CrossRef] [PubMed]
- KOSTAT. Available online: https://kostat.go.kr/portal/korea/index.action (accessed on 4 April 2022).
- KATI (Korean Association of Translators & Interpreters) in Republic of Korea. Available online: https://www.kati.net/statistics/monthlyPerformanceByProduct.do (accessed on 4 April 2022).
- Park, J. Reports of the National Assembly and Members of the National Assembly in Republic of Korea. Available online: https://nanet.go.kr/lowcontent/assamblybodo/selectAssamblyBodoDetail.do?searchSeq=99307&searchNoSeq=2019101199307 (accessed on 12 August 2022).
- Ministry of Agriculture, Food and Rural Affairs (MAFRA) in Republic of Korea. Available online: https://www.mafra.go.kr/mafra/294/subview.do?enc=Zm5jdDF8QEB8JTJGYmJzJTJGbWFmcmElMkY2OSUyRjMxODcxMyUyRmFydGNsVmlldy5kbyUzRg%3D%3D (accessed on 12 August 2022).
- Eriksson, L.; Johansson, E.; Kettaneh-Wold, N.; Wold, S. Multi-and Megavariate Data Analysis, Part 1; Umetrics Academy: Umeå, Sweden, 2006; pp. 63–101. Available online: https://www.worldcat.org/title/multi-and-megavariate-data-analysis-part-i-basic-principles-and-applications/oclc/900729892?referer=di&ht=edition (accessed on 10 April 2022).
- Mendez, K.M.; Pritchard, L.; Reinke, S.N.; Broadhurst, D.I. Toward collaborative open data science in metabolomics using jupyter notebooks and cloud computing. Metabolomics 2019, 15, 125. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pedregosa, F.; Michel, V.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Vanderplas, J.; Cournapeau, D.; Pedregosa, F.; Varoquaux, G.; et al. Scikit-learn: Machine learning in python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Uddin, S.; Khan, A.; Hossain, M.E.; Moni, M.A. Comparing different supervised machine learning algorithms for disease prediction. BMC Med. Inform. Decis. Mak. 2019, 19, 281. [Google Scholar] [CrossRef]
- Paper, D. Scikit-learn classifier tuning from complex training sets. In Hands-on Scikit-Learn for Machine Learning Applications; Apress: Berkeley, CA, USA, 2020; pp. 165–188. [Google Scholar] [CrossRef]
- Wong, T.T. Performance evaluation of classification algorithms by k-fold and leave-one-out cross validation. Pattern Recognit. 2015, 48, 2839–2846. [Google Scholar] [CrossRef]
- Cha, G.W.; Moon, H.J.; Kim, Y.C. Comparison of random forest and gradient boosting machine models for predicting demolition waste based on small datasets and categorical variables. Int. J. Environ. Res. Public Health 2021, 18, 8530. [Google Scholar] [CrossRef] [PubMed]
- Sahli, H. An introduction to machine learning. In TORUS 1-Toward an Open Resource Using Services: Cloud Computing for Environmental Data; Wiley: Hoboken, NJ, USA, 2020; pp. 61–74. [Google Scholar] [CrossRef]
- Chicco, D.; Jurman, G. The advantages of the matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef] [Green Version]
- Fiehn, O. Metabolomics—the link between genotypes and phenotypes. In Functional Genomics; Springer: Dordrecht, The Netherlands, 2002; pp. 155–171. [Google Scholar] [CrossRef]
- Tukey, H.B. Implications of allelopathy in agricultural plant science. Bot. Rev. 1969, 35, 1–16. [Google Scholar] [CrossRef]
- Marx, W.; Haunschild, R.; Bornmann, L. Global warming and tea production—The bibliometric view on a newly emerging research topic. Climate 2017, 5, 46. [Google Scholar] [CrossRef]
- Yang, L.; Wen, K.S.; Ruan, X.; Zhao, Y.X.; Wei, F.; Wang, Q. Response of plant secondary metabolites to environmental factors. Molecules 2018, 23, 762. [Google Scholar] [CrossRef] [Green Version]
- Dunn, W.B.; Wilson, I.D.; Nicholls, A.W.; Broadhurst, D. The importance of experimental design and QC samples in large-scale and MS-driven untargeted metabolomic studies of humans. Bioanalysis 2012, 4, 2249–2264. [Google Scholar] [CrossRef] [Green Version]
- Gika, H.G.; Theodoridis, G.A.; Earll, M.; Wilson, I.D. A QC approach to the determination of day-to-day reproducibility and robustness of LC–MS methods for global metabolite profiling in Metabonomics/Metabolomics. Bioanalysis 2012, 4, 2239–2247. [Google Scholar] [CrossRef]
- Craig, A.; Cloarec, O.; Holmes, E.; Nicholson, J.K.; Lindon, J.C. Scaling and normalization effects in NMR spectroscopic metabonomic data sets. Anal. Chem. 2006, 78, 2262–2267. [Google Scholar] [CrossRef]
- Zhou, Y.; Kim, S.-Y.; Lee, J.-S.; Shin, B.-K.; Seo, J.-A.; Kim, Y.-S.; Lee, D.-Y.; Choi, H.-K.; Zhou, Y.; Kim, S.-Y.; et al. Discrimination of the geographical origin of soybeans using NMR-based metabolomics. Foods 2021, 10, 435. [Google Scholar] [CrossRef]
- Li, B.; Tang, J.; Yang, Q.; Cui, X.; Li, S.; Chen, S.; Cao, Q.; Xue, W.; Chen, N.; Zhu, F. Performance evaluation and online realization of data-driven normalization methods used in LC/MS based untargeted metabolomics analysis. Sci. Rep. 2016, 6, 38881. [Google Scholar] [CrossRef] [Green Version]
- Weljie, A.M.; Newton, J.; Mercier, P.; Carlson, E.; Slupsky, C.M. Targeted pofiling: Quantitative analysis of 1H NMR metabolomics data. Anal. Chem. 2006, 78, 4430–4442. [Google Scholar] [CrossRef] [PubMed]
- Kohl, S.M.; Klein, M.S.; Hochrein, J.; Oefner, P.J.; Spang, R.; Gronwald, W. State-of-the art data normalization methods improve NMR-based metabolomic analysis. Metabolomics 2012, 8, 146–160. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- van den Berg, R.A.; Hoefsloot, H.C.J.; Westerhuis, J.A.; Smilde, A.K.; van der Werf, M.J. Centering, scaling, and transformations: Improving the biological information content of metabolomics data. BMC Genom. 2006, 7, 142. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vu, T.; Siemek, P.; Bhinderwala, F.; Xu, Y.; Powers, R. Evaluation of multivariate classification models for analyzing NMR metabolomics data. J. Proteome Res. 2019, 18, 3282–3294. [Google Scholar] [CrossRef]
- Garcés, M.A.; Orosco, L.L. EEG signal processing in brain–computer interface. In Smart Wheelchairs and Brain-Computer Interfaces Mobile Assistive Technologies; Academic Press: Cambridge, MA, USA, 2008; pp. 95–110. [Google Scholar] [CrossRef]
- Narisetty, N.N. Bayesian model selection for high-dimensional data. In Handbook of Statistics; Elsevier: Amsterdam, The Netherlands, 2020; Volume 43, pp. 207–248. [Google Scholar] [CrossRef]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 2000; ISBN 0-387-98780-0. [Google Scholar]
- Chang, Y.-W.; Lin, C.-J.; Guyon, I.; Aliferis, C.; Cooper, G.; Elisseeff, A.; Pellet, J.-P.; Spirtes, P.; Statnikov, A. Feature ranking using linear SVM. JMLR Work. Conf. Proc. 2008, 3, 53–64. [Google Scholar]
- Temko, A.; Thomas, E.; Marnane, W.; Lightbody, G.; Boylan, G. EEG-based neonatal seizure detection with support vector machines. Clin. Neurophysiol. 2011, 122, 464–473. [Google Scholar] [CrossRef] [Green Version]
- Tong, S.; Koller, D. Support vector machine active learning with applications to text classification. J. Mach. Learn. Res. 2001, 2, 45–66. [Google Scholar]
- Kotsiantis, S.B.; Zaharakis, I.D.; Pintelas, P.E. Machine Learning: A review of classification and combining techniques. Artif. Intell. Rev. 2006, 26, 159–190. [Google Scholar] [CrossRef]
- Singh, A.; Thakur, N.; Sharma, A. A review of supervised machine learning algorithms. In Proceedings of the 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 16–18 March 2016; IEEE: Piscataway, NJ, USA, 2016. Available online: https://ieeexplore.ieee.org/abstract/document/7724478 (accessed on 20 August 2022).
- Qi, Y. Random forest for bioinformatics. In Ensemble Machine Learning; Springer: Boston, MA, USA, 2012; pp. 307–323. [Google Scholar] [CrossRef] [Green Version]
- Tang, Y.; Zhang, Y.Q.; Chawla, N.V. SVMs modeling for highly imbalanced classification. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2009, 39, 281–288. [Google Scholar] [CrossRef] [Green Version]
- Hou, X.; Wang, G.; Su, G.; Wang, X.; Nie, S. Rapid identification of edible oil species using supervised support vector machine based on low-field nuclear magnetic resonance relaxation features. Food Chem. 2019, 280, 139–145. [Google Scholar] [CrossRef]
- Liu, X.; Gao, C.; Li, P. A comparative analysis of support vector machines and extreme learning machines. Neural Netw. 2012, 33, 58–66. [Google Scholar] [CrossRef] [PubMed]
- Heinemann, J. Machine learning in untargeted metabolomics experiments. In Methods in Molecular Biology; Humana Press: New York, NY, USA, 2019; Volume 1859, pp. 287–299. [Google Scholar]
- Moons, K.G.M.; Altman, D.G.; Reitsma, J.B.; Ioannidis, J.P.A.; Macaskill, P.; Steyerberg, E.W.; Vickers, A.J.; Ransohoff, D.F.; Collins, G.S. Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): Explanation and elaboration. Ann. Intern. Med. 2015, 162, W1–W73. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Garcia-Perez, I.; Posma, J.M.; Serrano-Contreras, J.I.; Boulangé, C.L.; Chan, Q.; Frost, G.; Stamler, J.; Elliott, P.; Lindon, J.C.; Holmes, E.; et al. Identifying unknown metabolites using NMR-based metabolic profiling techniques. Nat. Protoc. 2020, 15, 2538–2567. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
| No. | Compound | InChI Key | Chemical Shift | Assignment Method | |
|---|---|---|---|---|---|
| (Multiplicity ,J Value) | White Rice | Brown Rice | |||
| Amino Acids | |||||
| 1 | 4-Aminobutyrate | BTCSSZJGUNDROE-UHFFFAOYSA-N | 1.84–1.92 (m), 2.29 (t, J = 7.4), 3.00 (t, J = 7.2) | 1D | 1D, HSQC |
| 2 | Alanine | QNAYBMKLOCPYGJ-REOHCLBHSA-N | 1.47 (d, J = 7.2) | 1D | 1D |
| 3 | Asparagine | DCXYFEDJOCDNAF-REOHCLBHSA-N | 2.80–2.92 (m), 2.88–3.00 (m) | 1D | 1D |
| 4 | Aspartate | CKLJMWTZIZZHCS-REOHCLBHSA-N | 2.80 (dd, J = 17.4, 3.9) | 1D, COSY | 1D |
| 5 | Glutamate | WHUUTDBJXJRKMK-UHFFFAOYSA-N | 2.00–2.10 (m) | 1D, COSY | 1D, COSY |
| 6 | Glutamine | ZDXPYRJPNDTMRX-VKHMYHEASA-N | 2.06–2.20 (m), 2.38–2.50 (m) | 1D | 1D |
| 7 | Glycine | DHMQDGOQFOQNFH-UHFFFAOYSA-N | 3.56 (s) | 1D | 1D |
| 8 | Isoleucine | AGPKZVBTJJNPAG-WHFBIAKZSA-N | 0.92 (t, J = 7.2), 1.00 (d, J = 7.2) | 1D, HSQC | 1D, COSY, HSQC |
| 9 | Leucine | ROHFNLRQFUQHCH-YFKPBYRVSA-N | 0.95 (t, J = 6.2) | 1D | 1D, COSY |
| 10 | Methionine | FFEARJCKVFRZRR-BYPYZUCNSA-N | 2.66 (t, J = 7.8) | 1D, COSY | 1D, COSY |
| 11 | Threonine | AYFVYJQAPQTCCC-GBXIJSLDSA-N | 1.31 (d, J = 6.6) | 1D, COSY | 1D, COSY |
| 12 | Valine | KZSNJWFQEVHDMF-BYPYZUCNSA-N | 0.98 (d, J = 6.9), 1.03 (d, J = 6.6) | 1D | 1D, COSY |
| Organic acids | |||||
| 13 | Malate | BJEPYKJPYRNKOW-UHFFFAOYSA-N | 4.33 (d, J = 7.8) | 1D, COSY | 1D, COSY |
| 14 | Fumarate | VZCYOOQTPOCHFL-OWOJBTEDSA-N | 6.51 (s) | 1D | 1D |
| 15 | Succinate | KDYFGRWQOYBRFD-UHFFFAOYSA-N | 2.42 (s) | 1D | 1D |
| 16 | Acetate | QTBSBXVTEAMEQO-UHFFFAOYSA-M | 1.91 (s) | 1D | 1D |
| 17 | Glycolate | AEMRFAOFKBGASW-UHFFFAOYSA-N | 3.95 (s) | 1D | 1D |
| Sugars | |||||
| 18 | Glucose | WQZGKKKJIJFFOK-GASJEMHNSA-N | 4.63 (d, J = 7.8), 5.22 (d, J = 3.6) | 1D, HSQC | 1D, HSQC |
| 19 | Maltose | GUBGYTABKSRVRQ-PICCSMPSSA-N | 5.41 (d, J = 3.6) | 1D, COSY, HSQC | 1D, COSY, HSQC |
| 20 | Sucrose | CZMRCDWAGMRECN-UGDNZRGBSA-N | 3.46 (t, J = 9.6), 3.67 (s), 3.75 (t, J = 9.6), 4.04 (t, J = 8.6), 4.21 (d, J = 8.7), 5.39 (d, J = 3.6) | 1D, COSY, HSQC | 1D, COSY, HSQC |
| Alcohol | |||||
| 21 | Ethanol | LFQSCWFLJHTTHZ-UHFFFAOYSA-N | 1.17 (t, J = 7.2) | 1D | 1D |
| Others | |||||
| 22 | Pyruvate | LCTONWCANYUPML-UHFFFAOYSA-N | 2.36 (s) | 1D | 1D |
| 23 | Threonate | JPIJQSOTBSSVTP-STHAYSLISA-N | 4.00 (d, J = 2.4) | 1D, HSQC | 1D, HSQC |
| 24 | Choline | OEYIOHPDSNJKLS-UHFFFAOYSA-N | 3.19 (s) | 1D, HSQC | 1D, HSQC |
| Group No. | Normalization Method | Scaling Method | Component Number | R2Y | Q2Y | R2Y Intercept | Q2Y Intercept |
|---|---|---|---|---|---|---|---|
| White Rice | |||||||
| 1 | Total area | UV | 1 + 3 + 0 | 0.673 | 0.566 | 0.0731 | −0.196 |
| 2 | Par | 1 + 3 + 0 | 0.623 | 0.538 | 0.0941 | −0.244 | |
| 3 | Standardized area | UV | 1 + 1 + 0 | 0.396 | 0.233 | 0.0276 | −0.292 |
| 4 | Par | - | - | - | - | - | |
| Brown rice | |||||||
| 1 | Total area | UV | 1 + 7 + 0 | 0.844 | 0.736 | 0.172 | −0.403 |
| 2 | Par | 1 + 4 + 0 | 0.702 | 0.597 | 0.119 | −0.275 | |
| 3 | Standardized area | UV | 1 + 6 + 0 | 0.827 | 0.723 | 0.144 | −0.386 |
| 4 | Par | 1 + 7 + 0 | 0.82 | 0.702 | 0.152 | −0.399 | |
| White Rice | Parameters | Accuracy | ROC-AUC | Specificity | Precision | Recall | F1_Score | ||||||
| Methods | Train | Test | Train | Test | Train | Test | Train | Test | Train | Test | Train | Test | |
| Random forest | criterion = ‘gini’ max_depth = 4, min_samples_leaf = 2, | 0.94 | 0.92 | 0.83 | 0.78 | 0.99 | 0.98 | 0.94 | 0.92 | 0.94 | 0.92 | 0.94 | 0.92 |
| min_samples_split = 20, random state = 0 | |||||||||||||
| n_estimators = 10 | |||||||||||||
| Decision tree | criterion = ‘gini’ max_depth = 2, random state=0 | 0.99 | 0.91 | 0.95 | 0.81 | 0.99 | 0.96 | 0.99 | 0.91 | 0.99 | 0.91 | 0.99 | 0.91 |
| SVM | C = 3, gamma = 0.01, kernel = ‘linear’ | 1.00 | 0.99 | 1.00 | 0.99 | 1.00 | 0.99 | 1.00 | 0.99 | 1.00 | 0.99 | 1.00 | 0.99 |
| Logistic regression | C = 2, max_iter = 100,’ | 1.00 | 0.96 | 1.00 | 0.89 | 1.00 | 0.99 | 1.00 | 0.96 | 1.00 | 0.96 | 1.00 | 0.96 |
| random_state = 0, solver = ‘lbfgs | |||||||||||||
| KNN | n_neighbors = 2, weights = ‘distance’ | 1.00 | 0.97 | 1.00 | 0.96 | 1.00 | 0.98 | 1.00 | 0.97 | 1.00 | 0.97 | 1.00 | 1.97 |
| OPLS-DA | components = 1 + 3 + 0 | 0.96 | 0.98 | 0.98 | 0.98 | 0.99 | 0.98 | 0.95 | 0.96 | 0.89 | 0.89 | 0.92 | 0.91 |
| Brown rice | Parameters | Accuracy | ROC-AUC | Specificity | Precision | Recall | F1_score | ||||||
| Methods | Train | Test | Train | Test | Train | Test | Train | Test | Train | Test | Train | Test | |
| Random forest | criterion = ‘entropy’ max_depth = 3, min_samples_leaf = 2, | 0.99 | 0.92 | 0.98 | 0.92 | 1.00 | 0.95 | 0.99 | 0.92 | 0.99 | 0.92 | 0.99 | 0.92 |
| min_samples_split = 10, random state = 0 | |||||||||||||
| n_estimators = 20 | |||||||||||||
| Decision tree | criterion = ‘gini’ max_depth = 2, random state = 0 | 0.98 | 0.94 | 0.99 | 0.94 | 0.98 | 0.95 | 0.98 | 0.94 | 0.98 | 0.94 | 0.98 | 0.94 |
| SVM | C = 250, kernel = ‘linear’ | 1.00 | 0.96 | 1.00 | 0.96 | 1.00 | 0.96 | 1.00 | 0.95 | 1.00 | 0.95 | 1.00 | 0.95 |
| Logistic regression | C = 2, max_iter = 10,’ | 0.83 | 0.78 | 0.82 | 0.78 | 0.82 | 0.78 | 0.83 | 0.78 | 0.83 | 0.78 | 0.82 | 0.78 |
| random_state = 0, solver = ‘liblinear’ | |||||||||||||
| KNN | n_neighbors = 6, weights = ‘distance’ | 1.00 | 0.91 | 1.00 | 0.92 | 1.00 | 0.93 | 1.00 | 0.91 | 1.00 | 0.91 | 1.00 | 0.91 |
| OPLS-DA | components = 1 + 4 + 0 | 0.98 | 0.95 | 1.00 | 0.96 | 0.99 | 0.98 | 0.99 | 0.98 | 0.97 | 0.94 | 0.98 | 0.96 |
| Evaluators | White Rice (SVM) | Brown Rice (SVM) | ||||
|---|---|---|---|---|---|---|
| Developmental Model (n = 90) | Validation Model(n = 15) | Developmental Model (n = 74) | Validation Model (n = 13) | |||
| Train | Test | Train | Test | |||
| Accuracy | 1.00 | 0.97 | 1.00 | 1.00 | 0.96 | 1.00 |
| ROC-AUC | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| Specificity | 1.00 | 0.96 | 1.00 | 1.00 | 1.00 | 1.00 |
| Precision | 1.00 | 0.97 | 1.00 | 1.00 | 0.96 | 1.00 |
| Recall | 1.00 | 0.97 | 1.00 | 1.00 | 0.96 | 1.00 |
| F1_score | 1.00 | 0.97 | 1.00 | 1.00 | 0.96 | 1.00 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saeed, M.; Kim, J.-S.; Kim, S.-Y.; Ryu, J.E.; Ko, J.; Zaidi, S.F.A.; Seo, J.-A.; Kim, Y.-S.; Lee, D.Y.; Choi, H.-K. Differentiation of Geographical Origin of White and Brown Rice Samples Using NMR Spectroscopy Coupled with Machine Learning Techniques. Metabolites 2022, 12, 1012. https://doi.org/10.3390/metabo12111012
Saeed M, Kim J-S, Kim S-Y, Ryu JE, Ko J, Zaidi SFA, Seo J-A, Kim Y-S, Lee DY, Choi H-K. Differentiation of Geographical Origin of White and Brown Rice Samples Using NMR Spectroscopy Coupled with Machine Learning Techniques. Metabolites. 2022; 12(11):1012. https://doi.org/10.3390/metabo12111012
Chicago/Turabian StyleSaeed, Maham, Jung-Seop Kim, Seok-Young Kim, Ji Eun Ryu, JuHee Ko, Syed Farhan Alam Zaidi, Jeong-Ah Seo, Young-Suk Kim, Do Yup Lee, and Hyung-Kyoon Choi. 2022. "Differentiation of Geographical Origin of White and Brown Rice Samples Using NMR Spectroscopy Coupled with Machine Learning Techniques" Metabolites 12, no. 11: 1012. https://doi.org/10.3390/metabo12111012