One-Dimensional Convolutional Neural Networks with Feature Selection for Highly Concise Rule Extraction from Credit Scoring Datasets with Heterogeneous Attributes


Abstract
:1. Introduction
1.1. Background
1.2. Types of Data Attributes
1.3. Heterogeneous Credit Scoring
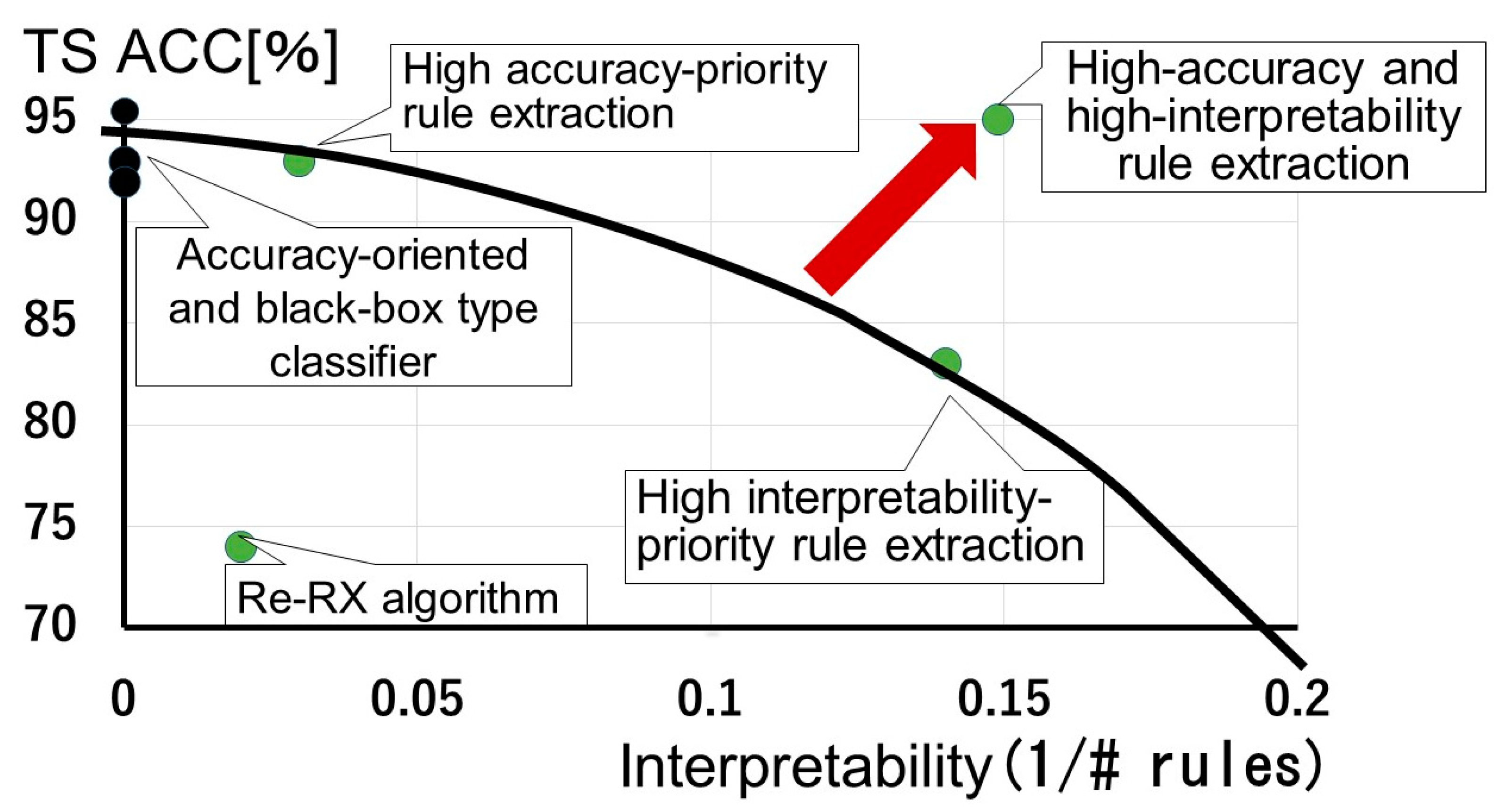
1.4. Accuracy–Interpretability Dilemma
1.5. Rule Extraction and the “Black Box” Problem
1.6. Recursive-Rule Extraction (Re-RX) and Related Algorithms
2. Motivation for This Work
Motivation for Research
3. Methods
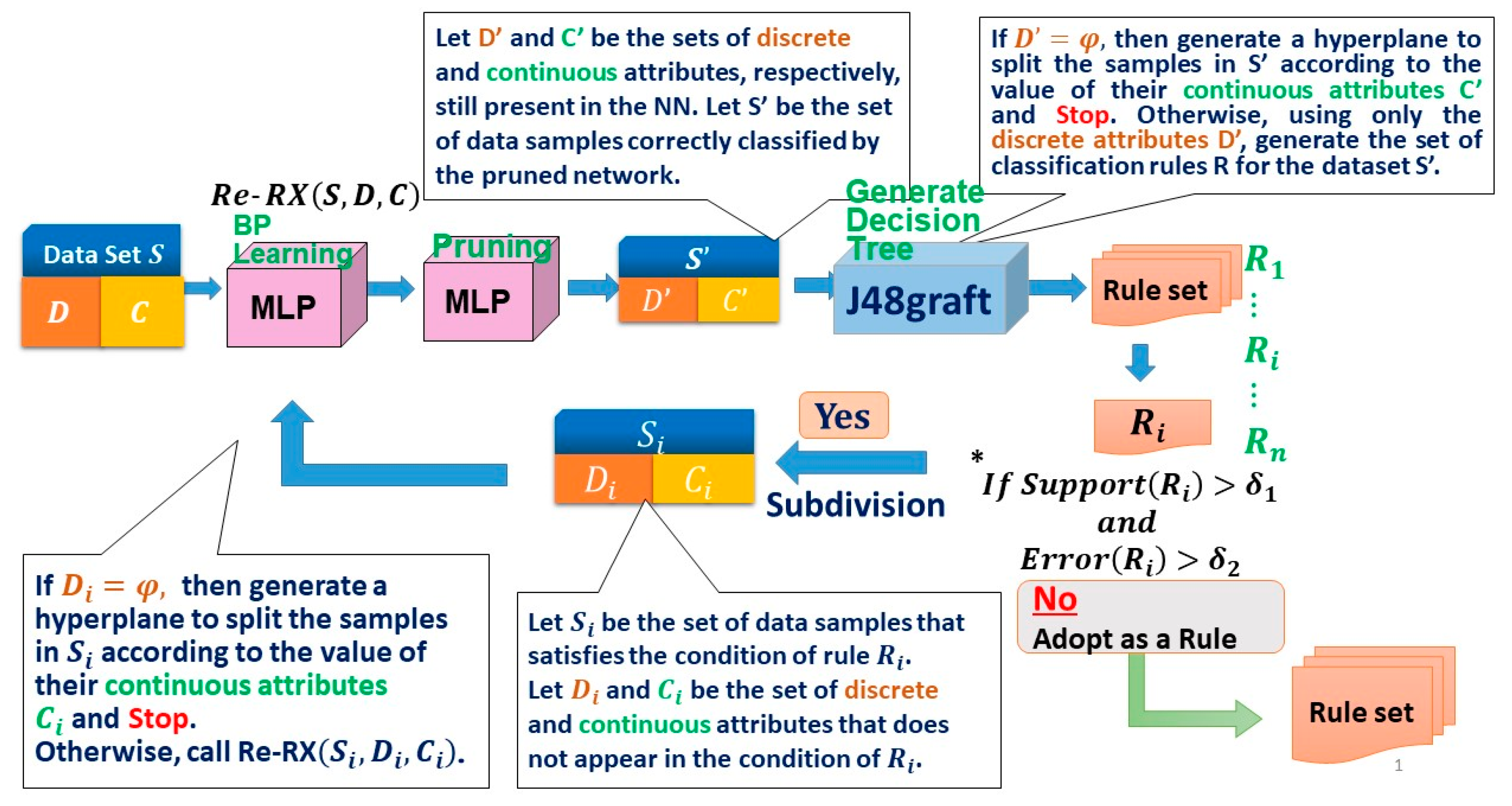
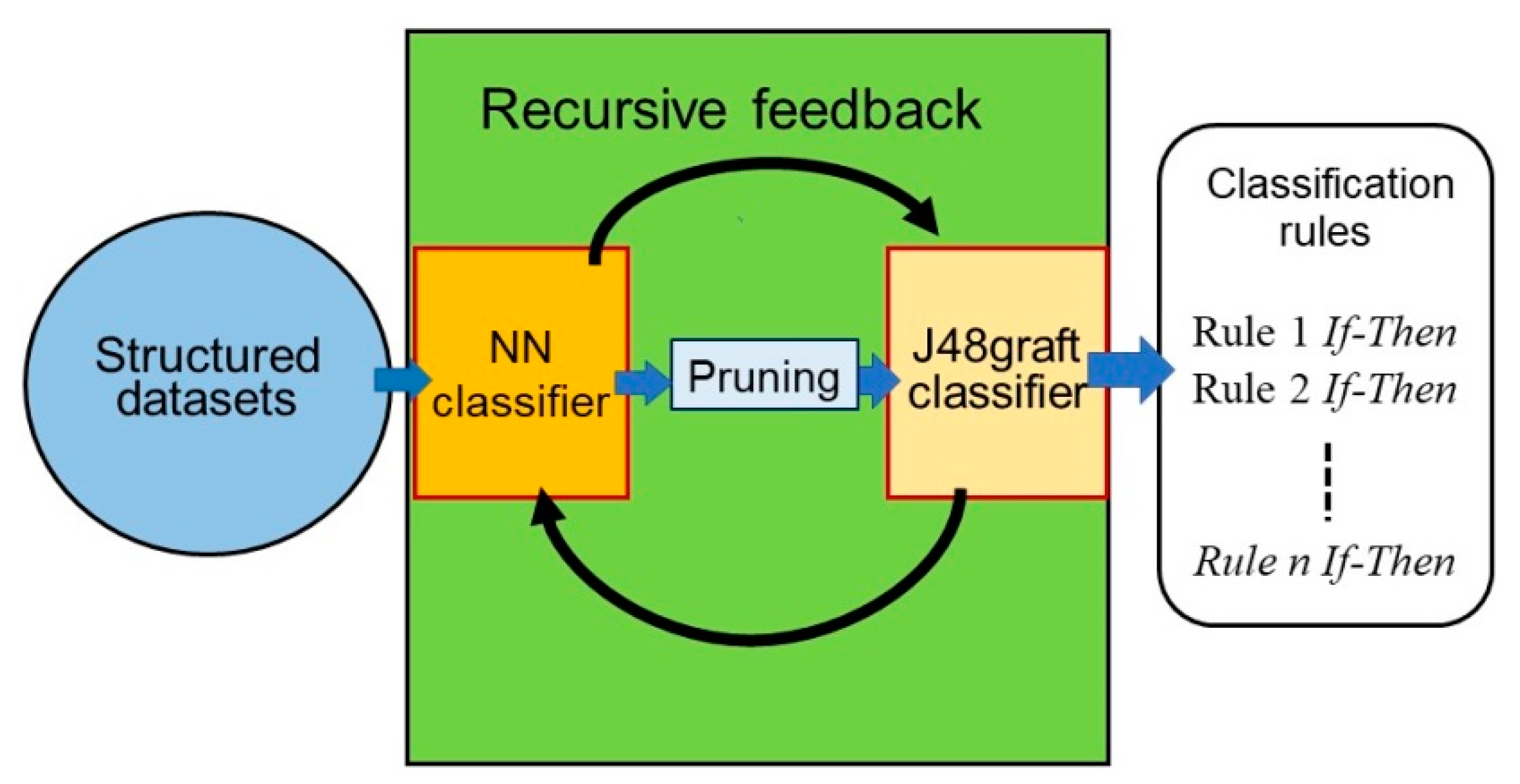
3.1. Re-RX Algorithm with J48graft
3.2. Deep Convolutional Neural Networks (DCNNs) and Inception Modules
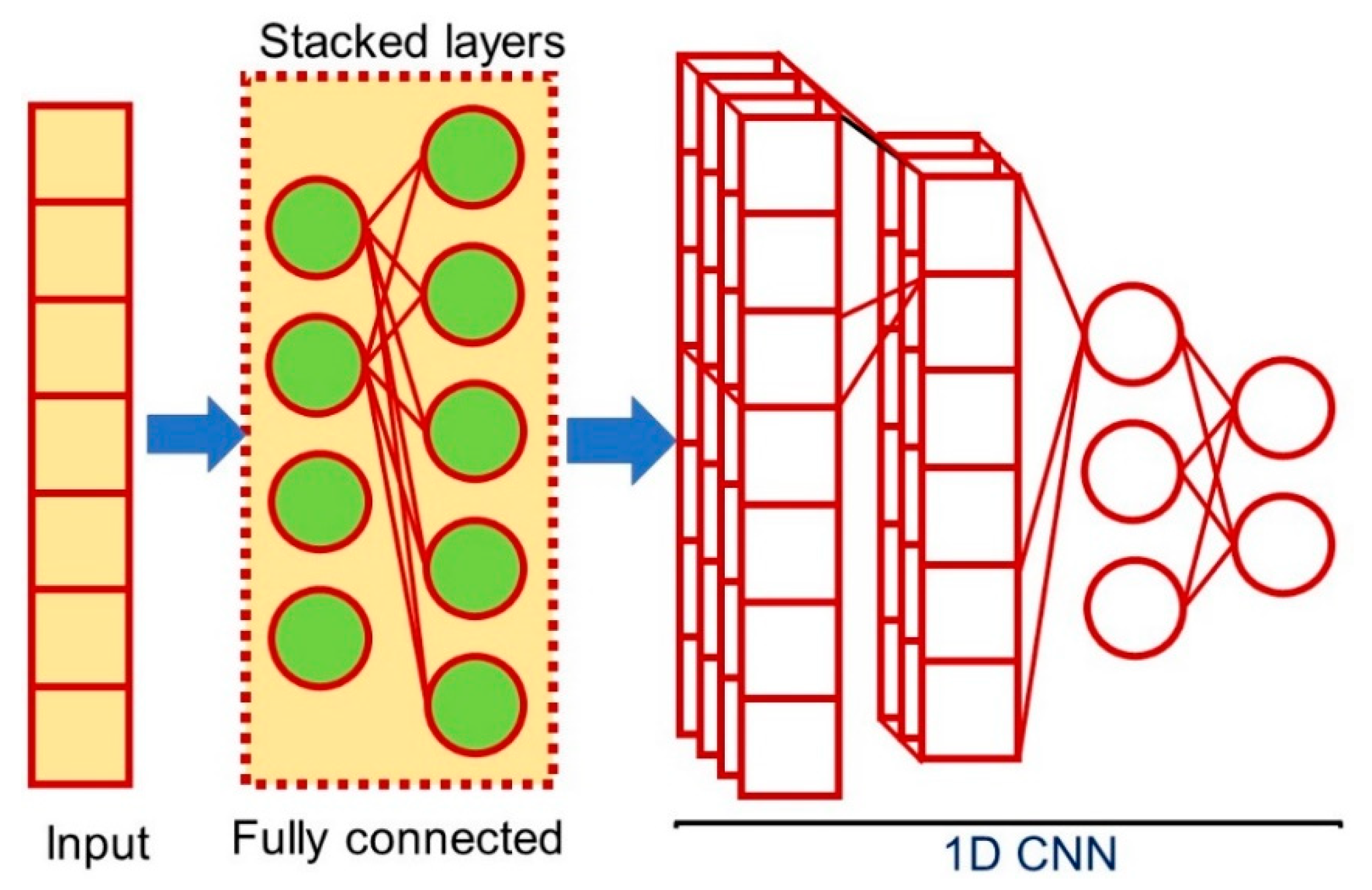
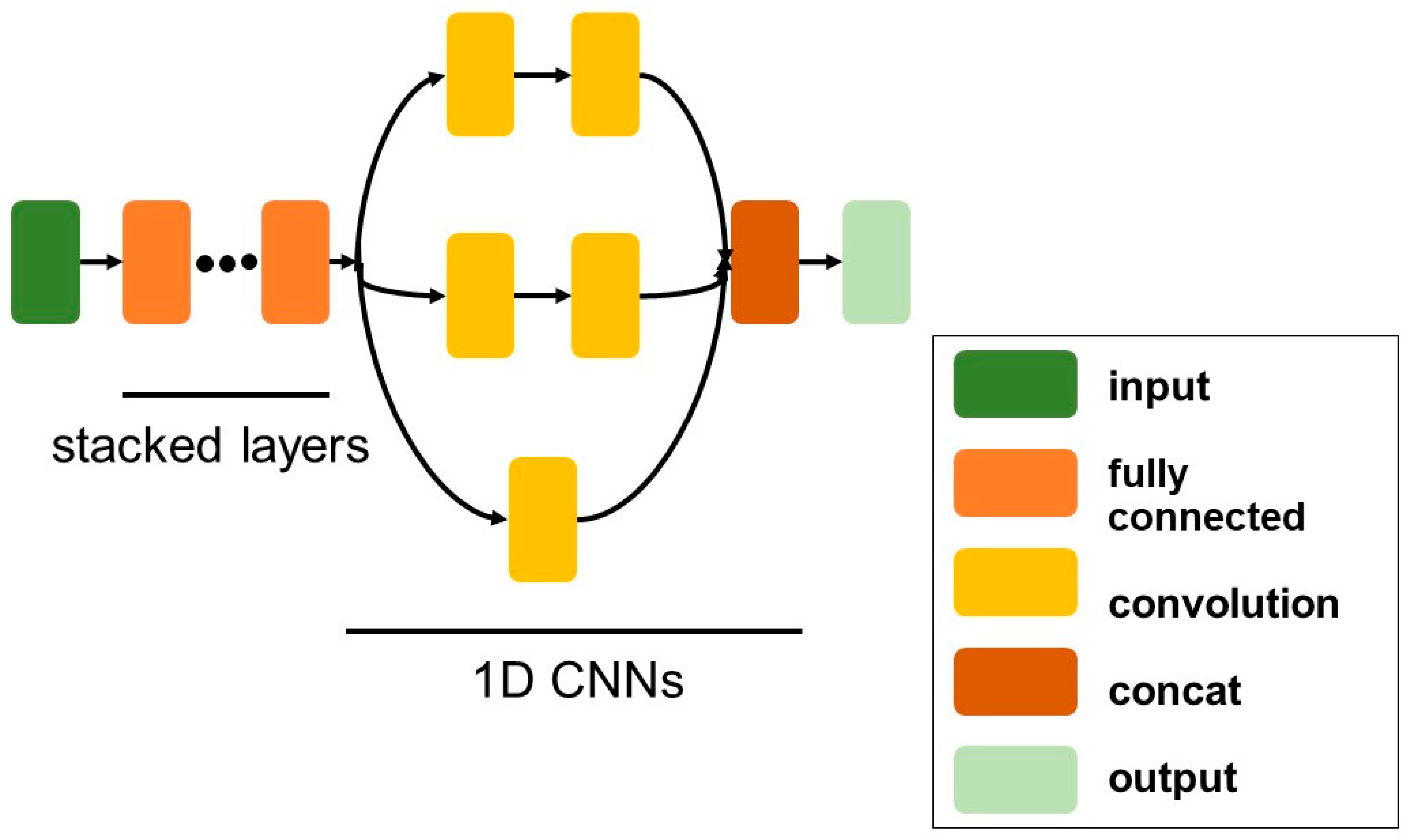
3.3. One-Dimensional Fully-Connected Layer First CNN (1D FCLF-CNN)
4. Theory
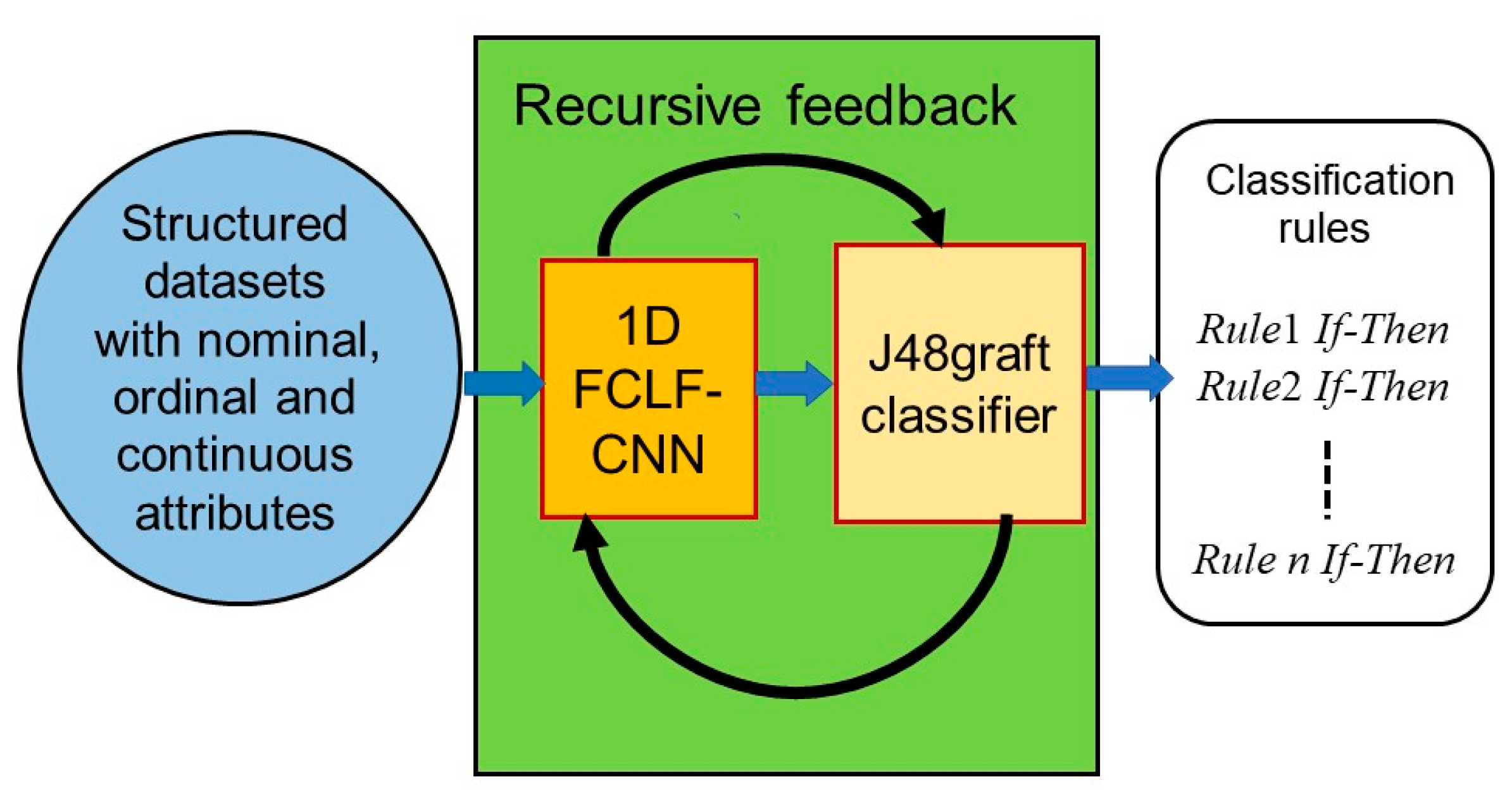
4.1. Highly Concise Rule Extraction Using a 1D FCLF-CNN with Re-RX with J48graft
4.2. Rationale Behind the Architecture for the 1D FCLF-CNN with Re-RX with J48graft
4.3. Attribute Selection by Dimension Reduction Using a 1D FCLF-CNN for Datasets with Heterogeneous Attributes
5. Experimental Procedure
6. Results
7. Discussion
7.1. Discussion
7.2. Common Issues with Re-RX with J48graft and ERENN-MHL
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
Notations
| 1/# | Reciprocal number |
| TS ACC | Test accuracy |
| # rules | Number of rules |
| 10 × 10CV | 10 runs of 10-fold cross-validation |
Abbreviations
| CNN | Convolutional neural network |
| 1D | One-dimensional |
| FCLF | Fully-connected layer first |
| Re-RX | Recursive-rule eXtraction |
| SVM | Support vector machine |
| DL | Deep learning |
| NN | Neural network |
| DNN | Deep neural network |
| AI | Artificial intelligence |
| DCNN | Deep convolutional neural network |
| BPNN | Backpropagation neural network |
| CV | Cross-validation |
| AUC-ROC | Area under the receiver operating characteristic curve |
| SMOTE | Synthetic minority over-sampling technique |
| DM | Deutsche Mark |
| SOM | Self-organization map |
| PSO | Particle swarm optimization |
| ERENN-MHL | Electric rule extraction from a neural network with a multi-hidden layer for a DNN |
References
- Pławiak, P.; Abdar, M.; Pławiak, J.; Makarenkov, V.; Acharya, U.R. DGHNL: A new deep genetic hierarchical network of learners for prediction of credit scoring. Inf. Sci. 2020, 516, 401–418. [Google Scholar] [CrossRef]
- Liberati, C.; Camillo, F.; Saporta, G. Advances in credit scoring: Combining performance and interpretation in kernel discriminant analysis. Adv. Data Anal. Classif. 2015, 11, 121–138. [Google Scholar] [CrossRef]
- Zhang, Y.; Cheung, Y.-M.; Tan, K.C. A Unified Entropy-Based Distance Metric for Ordinal-and-Nominal-Attribute Data Clustering. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 39–52. [Google Scholar] [CrossRef] [PubMed]
- Martens, D.; Baesens, B.; Van Gestel, T.; Vanthienen, J. Comprehensible credit scoring models using rule extraction from support vector machines. Eur. J. Oper. Res. 2007, 183, 1466–1476. [Google Scholar] [CrossRef]
- Abellán, J.; Mantas, C.J. Improving experimental studies about ensembles of classifiers for bankruptcy prediction and credit scoring. Expert Syst. Appl. 2014, 41, 3825–3830. [Google Scholar] [CrossRef]
- Abellán, J.; Castellano, J.G. A comparative study on base classifiers in ensemble methods for credit scoring. Expert Syst. Appl. 2017, 73, 1–10. [Google Scholar] [CrossRef]
- Tripathi, D.; Edla, D.R.; Cheruku, R. Hybrid credit scoring model using neighborhood rough set and multi-layer ensemble classification. J. Intell. Fuzzy Syst. 2018, 34, 1543–1549. [Google Scholar] [CrossRef]
- Kuppili, V.; Tripathi, D.; Edla, D.R. Credit score classification using spiking extreme learning machine. Comput. Intell. 2020, 36, 402–426. [Google Scholar] [CrossRef]
- Pławiak, P.; Abdar, M.; Acharya, U.R. Application of new deep genetic cascade ensemble of SVM classifiers to predict the Australian credit scoring. Appl. Soft Comput. 2019, 84, 105740. [Google Scholar] [CrossRef]
- Tripathi, D.; Edla, D.R.; Cheruku, R.; Kuppili, V. A novel hybrid credit scoring model based on ensemble feature selection and multilayer ensemble classification. Comput. Intell. 2019, 35, 371–394. [Google Scholar] [CrossRef]
- Sun, J.; Li, H.; Huang, Q.-H.; He, K.-Y. Predicting financial distress and corporate failure: A review from the state-of-the-art definitions, modeling, sampling, and featuring approaches. Knowl. Based Syst. 2014, 57, 41–56. [Google Scholar] [CrossRef]
- Chen, T.-C.; Cheng, C.-H. Hybrid models based on rough set classifiers for setting credit rating decision rules in the global banking industry. Knowl. Based Syst. 2013, 39, 224–239. [Google Scholar] [CrossRef]
- Florez-Lopez, R.; Ramon-Jeronimo, J.M. Enhancing accuracy and interpretability of ensemble strategies in credit risk assessment. A correlated-adjusted decision forest proposal. Expert Syst. Appl. 2015, 42, 5737–5753. [Google Scholar] [CrossRef]
- Mues, C.; Baesens, B.; Files, C.M.; Vanthienen, J. Decision diagrams in machine learning: An empirical study on real-life credit-risk data. Expert Syst. Appl. 2004, 27, 257–264. [Google Scholar] [CrossRef]
- Hsieh, N.-C.; Hung, L.-P. A data driven ensemble classifier for credit scoring analysis. Expert Syst. Appl. 2010, 37, 534–545. [Google Scholar] [CrossRef]
- Gallant, S.I. Connectionist expert systems. Commun. ACM 1988, 31, 152–169. [Google Scholar] [CrossRef]
- Saito, K.; Nakano, R. Medical Diagnosis Expert Systems Based on PDP Model. In Proceedings of the IEEE Interenational Conference Neural Network, San Diego, CA, USA, 1988, 24–27 July 1988; pp. I.255–I.262. [Google Scholar]
- Hayashi, Y.; Oishi, T. High Accuracy-priority Rule Extraction for Reconciling Accuracy and Interpretability in Credit Scoring. New Gener. Comput. 2018, 36, 393–418. [Google Scholar] [CrossRef]
- Andrews, R.; Diederich, J.; Tickle, A.B. Survey and critique of techniques for extracting rules from trained artificial neural networks. Knowl. Based Syst. 1995, 8, 373–389. [Google Scholar] [CrossRef]
- Mitra, S.; Hayashi, Y. Neuro-fuzzy rule generation: Survey in soft computing framework. IEEE Trans. Neural Netw. 2000, 11, 748–768. [Google Scholar] [CrossRef] [Green Version]
- Bologna, G. A study on rule extraction from several combined neural networks. Int. J. Neural Syst. 2001, 11, 247–255. [Google Scholar] [CrossRef]
- Setiono, R.; Baesens, B.; Mues, C. Recursive Neural Network Rule Extraction for Data with Mixed Attributes. IEEE Trans. Neural Netw. 2008, 19, 299–307. [Google Scholar] [CrossRef] [PubMed]
- Tran, S.N.; Garcez, A.S.D. Deep Logic Networks: Inserting and Extracting Knowledge from Deep Belief Networks. IEEE Trans. Neural Netw. Learn. Syst. 2016, 29, 246–258. [Google Scholar] [CrossRef]
- De Fortuny, E.J.; Martens, D. Active Learning-Based Pedagogical Rule Extraction. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 2664–2677. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hayashi, Y. The Right Direction Needed to Develop White-Box Deep Learning in Radiology, Pathology, and Ophthalmology: A Short Review. Front. Robot. AI 2019, 6, 1–8. [Google Scholar] [CrossRef]
- Hayashi, Y. New unified insights on deep learning in radiological and pathological images: Beyond quantitative performances to qualitative interpretation. Inform. Med. Unlocked 2020, 19, 100329. [Google Scholar] [CrossRef]
- Setiono, R. A Penalty-Function Approach for Pruning Feedforward Neural Networks. Neural Comput. 1997, 9, 185–204. [Google Scholar] [CrossRef]
- Quinlan, J.R. Programs for Machine Learning; Morgan Kaufman: San Mateo, CA, USA, 1993. [Google Scholar]
- Hayashi, Y.; Nakano, S. Use of a Recursive-Rule Extraction algorithm with J48graft to archive highly accurate and concise rule extraction from a large breast cancer dataset. Inform. Med. Unlocked 2015, 1, 9–16. [Google Scholar] [CrossRef] [Green Version]
- Hayashi, Y.; Nakano, S.; Fujisawa, S. Use of the recursive-rule extraction algorithm with continuous attributes to improve diagnostic accuracy in thyroid disease. Inform. Med. Unlocked 2015, 1, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Hayashi, Y. Synergy effects between grafting and subdivision in Re-RX with J48graft for the diagnosis of thyroid disease. Knowl. Based Syst. 2017, 131, 170–182. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E.; Hall, M.A. Data Mining: Practical Machine Learning Tools and Techniques; Elsevier BV: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Webb, G.I. Decision Tree Grafting from the All-Tests-But-One Partition. In Proceedings of the 16th International Joint Conference on Artificial Intelligence, San Mateo, CA, USA, 10–16 July 1999; pp. 702–707. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. lmageNet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Kim, J.-Y.; Cho, S.-B. Exploiting deep convolutional neural networks for a neural-based learning classifier system. Neurocomputing 2019, 354, 61–70. [Google Scholar] [CrossRef]
- Liu, K.; Kang, G.; Zhang, N.; Hou, B. Breast Cancer Classification Based on Fully-Connected Layer First Convolutional Neural Networks. IEEE Access 2018, 6, 23722–23732. [Google Scholar] [CrossRef]
- Chen, C.; Jiang, F.; Yang, C.; Rho, S.; Shen, W.; Liu, S.; Liu, Z. Hyperspectral classification based on spectral–spatial convolutional neural networks. Eng. Appl. Artif. Intell. 2018, 68, 165–171. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Keras. Available online: https://github.com/keras-team/keras (accessed on 30 June 2020).
- Craven, J.M.; Shavlik, J. Extracting tree-structured representations of trained networks. Adv. Neural Inf. Process. Syst. 1996, 8, 24–30. [Google Scholar]
- Chakraborty, M.; Biswas, S.K.; Purkayastha, B. Rule extraction from neural network trained using deep belief network and back propagation. Knowl. Inf. Syst. 2020, 62, 3753–3781. [Google Scholar] [CrossRef]
- Marqués, A.I.; García, V.; Sánchez, J.S. On the suitability of resampling techniques for the class imbalance problem in credit scoring. J. Oper. Res. Soc. 2013, 64, 1060–1070. [Google Scholar] [CrossRef] [Green Version]
- Salzberg, S.L. On Comparing Classifiers: Pitfalls to Avoid and a Recommended Approach. Data Min. Knowl. Discov. 1997, 1, 317–328. [Google Scholar] [CrossRef]
- Bergstra, J.; Bardent, R.; Bengio, Y.; Kégl, B. Algorithms for Hyper-Parameter Optimization. Adv. Neural Inf. Process. Syst. 2011, 24, 2546–2554. [Google Scholar]
- Hsu, F.-J.; Chen, M.-Y.; Chen, Y.-C. The human-like intelligence with bio-inspired computing approach for credit ratings prediction. Neurocomputing 2018, 279, 11–18. [Google Scholar] [CrossRef]
- Jadhav, S.; He, H.; Jenkins, K. Information gain directed genetic algorithm wrapper feature selection for credit rating. Appl. Soft Comput. 2018, 69, 541–553. [Google Scholar] [CrossRef] [Green Version]
- Shen, F.; Zhao, X.; Li, Z.; Li, K.; Meng, Z. A novel ensemble classification model based on neural networks and a classifier optimisation technique for imbalanced credit risk evaluation. Phys. A Stat. Mech. Appl. 2019, 526, 121073. [Google Scholar] [CrossRef]
- Bequé, A.; Lessmann, S.; Bequ, A. Extreme learning machines for credit scoring: An empirical evaluation. Expert Syst. Appl. 2017, 86, 42–53. [Google Scholar] [CrossRef]
- Bologna, G.; Hayashi, Y. A Comparison Study on Rule Extraction from Neural Network Ensembles, Boosted Shallow Trees, and SVMs. Appl. Comput. Intell. Soft Comput. 2018, 2018, 1–20. [Google Scholar] [CrossRef]
- Tai, L.Q.; Vietnam, V.B.A.O.; Huyen, G.T.T. Deep Learning Techniques for Credit Scoring. J. Econ. Bus. Manag. 2019, 7, 93–96. [Google Scholar] [CrossRef]
- Huysmans, J.; Setiono, R.; Baesens, B.; Vanthienen, J. Minerva: Sequential Covering for Rule Extraction. IEEE Trans. Syst. Man Cybern. Part. B (Cybernetics) 2008, 38, 299–309. [Google Scholar] [CrossRef] [PubMed]
- Santana, P.J.; Monte, A.V.; Rucci, E.; Lanzarini, L.; Bariviera, A.F. Analysis of Methods for Generating Classification Rules Applicable to Credit Risk. J. Comput. Sci. Technol. 2017, 17, 20–28. [Google Scholar]
- Kohonen, T.; Somervuo, P. Self-organizing maps of symbol strings. Neurocomputing 1998, 21, 19–30. [Google Scholar] [CrossRef]
- Poli, R.; Kennedy, J.; Blackwell, T. Particle swarm optimization. Swarm Intell. 2007, 1, 33–57. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Data Attributes (Types) | Ref. |
|---|---|---|
| Rule extraction for black box | Numerical/categorical | [4,5,6,7,8] |
| Deep Learning (DL)-inspired rule extractionfor new black box | Images (pixels) | [24,25,26] |
| Numerical/categorical | [1,9,10] | |
| Numerical/ordinal/nominal | The proposed method |
| Dataset | German | Australian |
|---|---|---|
| Pruning stop rate for 1D FCLF-CNN | 0.13 | 0.20 |
| # First layer in hidden units for 1D FCLF-CNN | 4 | 3 |
| Learning rate for 1D FCLF-CNN | 0.0182 | 0.0106 |
| Momentum factor for 1D FCLF-CNN | 0.1154 | 0.7549 |
| # Filters in each branch in the inception module | 19 | 8 |
| # Channels after concatenation | 57 | 24 |
| δ1 in Re-RX with J48graft | 0.08 | 0.39 |
| δ2 in Re-RX with J48graft | 0.12 | 0.10 |
| Dataset | German | Australian |
|---|---|---|
| # Instances | 1000 | 690 |
| # Total features | 20 | 14 |
| Categorical nominal | 10 | 0 |
| Categorical ordinal | 3 | 8 |
| Continuous | 7 | 6 |
| Methods | TS ACC (%) | AUC-ROC (%) |
|---|---|---|
| Neighborhood rough set + multilayer ensemble classification (10CV) (Tripathi et al., 2018) [7] | 86.57 | ---- |
| SVM + metaheuristics (10CV) (Hsu et al., 2018) [47] | 84.00 | ---- |
| Information gain directed feature selection algorithm (10CV) (Jadhav et al., 2018) [48] | 82.80 | 0.753 |
| Ensemble method based on the SMOTE (10CV) (Shen et al., 2019) [49] | 78.70 | 0.810 |
| Extreme Learning Machine (10CV) (Bequé and Lessmann, 2017) [50] | 76.40 | 0.801 |
| Method | Average # TS ACC (%) | Average # Rules | Average #AUC-ROC |
|---|---|---|---|
| Continuous Re-RX with J48graft (10 × 10CV) (Hayashi and Oisi, 2018) [18] | 79.0 | 44.9 | 0.72 |
| Correlated-adjusted decision forest (mixed) (10CV) (Florez-Lopez and Ramon-Jeronimo, 2015) [13] | 77.4 | 49.0 | 0.79 |
| Boosted shallow tree-G1 (10 × 10CV) (Bologna and Hayashi, 2017) [51] | 77.1 | 102.7 | ---- |
| Continuous Re-RX (10 × 10CV) (Hayashi et al., 2015) [30] | 75.22 | 39.6 | 0.692 |
| Electric rule extraction from a neural network with a multihidden layer for a DNN trained by a DBN (5CV) [43] | 74.50 | 8.0 | ----- |
| 1D FCLF-CNN with Re-RX with J48graft (10CV) (present paper) | 73.10 | 6.2 | 0.622 |
| Re-RX with J48graft (10 × 10CV) (Hayashi et al., 2018) [18] | 72.80 | 16.65 | 0.650 |
| Method | TS ACC (%) | AUC-ROC (%) |
|---|---|---|
| Deep genetic cascade ensemble of SVM classifier (10CV) (Pławiak et al., 2019) [1] | 97.39 | ---- |
| Spiking extreme learning machine (10CV) (Kuppili et al., 2019) [8] | 95.98 | 0.970 |
| SVM + metaheuristics (10CV) (Hsu et al., 2018) [47] | 92.75 | ---- |
| DL techniques: SNN and CNN (10CV) (Tai and Huyen, 2019) [52] | 87.54 | ---- |
| Method | TS ACC (%) | # Rules | AUC-ROC (%) |
|---|---|---|---|
| Electric rule extraction from a neural network with a multihidden layer for a DNN trained by a DBN (5CV) [43] | 89.13 | 7.0 | ---- |
| Boosted shallow trees (gentle boosting) BST-G2 (10 × 10CV) (Bologna and Hayashi, 2017) [51] | 87.90 | 73.4 | ---- |
| Continuous Re-RX with J48graft (10 × 10CV) (Hayashi and Oisi, 2018) [18] | 87.82 | 14.1 | 0.870 |
| Cont. Re-RX (10×10CV) (Hayashi et al., 2015) [29] | 86.93 | 14.0 | 0.689 |
| 1D FCLF-CNN with Re-RX with J48graft (10 × 10CV) (present paper) | 86.53 | 2.6 | 0.871 |
| Discretized interpretable MLP (DIMLP)-B (10 × 10CV) (Bologna and Hayashi, 2017) [51] | 86.5 | 21.4 | ---- |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hayashi, Y.; Takano, N. One-Dimensional Convolutional Neural Networks with Feature Selection for Highly Concise Rule Extraction from Credit Scoring Datasets with Heterogeneous Attributes. Electronics 2020, 9, 1318. https://doi.org/10.3390/electronics9081318
Hayashi Y, Takano N. One-Dimensional Convolutional Neural Networks with Feature Selection for Highly Concise Rule Extraction from Credit Scoring Datasets with Heterogeneous Attributes. Electronics. 2020; 9(8):1318. https://doi.org/10.3390/electronics9081318
Chicago/Turabian StyleHayashi, Yoichi, and Naoki Takano. 2020. "One-Dimensional Convolutional Neural Networks with Feature Selection for Highly Concise Rule Extraction from Credit Scoring Datasets with Heterogeneous Attributes" Electronics 9, no. 8: 1318. https://doi.org/10.3390/electronics9081318